Kubernetes Pod 生命周期详解
本文系统介绍了Kubernetes中Pod的生命周期管理。主要内容包括:Pod的5种核心状态(Pending、Running等)及其转换条件;重启策略(Always/OnFailure/Never)及其适用场景;初始化容器(InitContainer)在应用启动前的预处理作用;生命周期钩子(PostStart/PreStop)实现优雅启停;以及三类健康检查探针(Liveness/Readiness
一、引言:Pod 的生命之旅
在 Kubernetes 的世界里,Pod 是最小的部署单元。然而,一个 Pod 的生命并非简单的“启动”与“停止”。它经历一个复杂而精确管理的生命周期,从被定义的那一刻起,到最终被销毁,期间会经历一系列状态和事件。
理解 Pod 的生命周期对于部署健壮、高可用的应用至关重要。它能帮助我们精确控制应用的启动顺序、确保服务在真正就绪后才接收流量、实现优雅下线,以及自动修复故障。
本篇文档将系统性地拆解 Pod 生命周期的各个阶段和关键组件,包括:Pod 状态、初始化容器、生命周期钩子、健康检查探针以及重启策略。
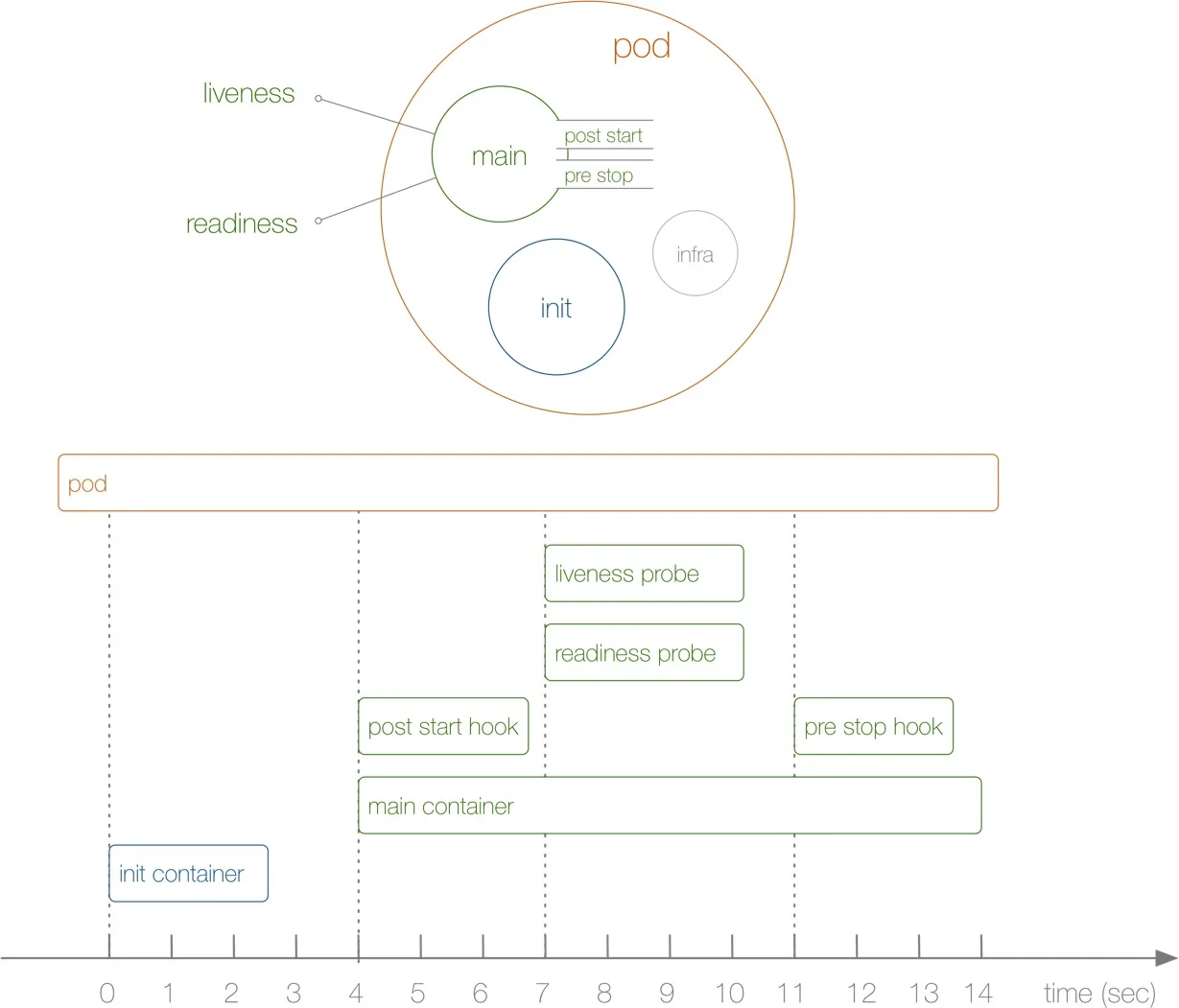
二、 Pod 的核心状态 (Pod Phase)
在了解 Pod 生命周期之前,先了解 Pod 的状态是必要的,因为 Pod 状态反映了当前 Pod 的具体状态信息,是分析排错的基础。Pod 的 phase 是对其当前在生命周期中所处位置的高度概括。我们可以通过 kubectl describe pod <pod-name> 或 kubectl get pod <pod-name> -o yaml查看 status.phase字段。
Pod 状态值
通过 kubectl explain pod.status 命令可以查看 Pod 状态信息,主要包含 phase 字段:
| 状态 (Phase) | 描述 | 常见原因 |
|
Pending (挂起) |
Pod 已被 Kubernetes 系统接受,但有一个或多个容器尚未创建并运行。 |
- 调度器尚未找到合适的节点(资源不足、节点亲和性/污点策略不匹配)。 - 正在从镜像仓库拉取容器镜像。 |
|
Running (运行中) |
Pod 已经绑定到一个节点,并且 Pod 中所有的容器都已经被创建。至少有一个容器正在运行,或者正处于启动或重启状态。 | 这是 Pod 的正常工作状态。 |
|
Succeeded (成功) |
Pod 中的所有容器都已成功终止(退出码为 0),并且不会再被重启。 |
常见于 或一次性任务执行完成后的状态。 |
|
Failed (失败) |
Pod 中的所有容器都已终止,并且至少有一个容器是因失败而终止的(退出码非 0 或被系统终止)。 | 应用程序错误、配置问题等导致容器无法正常运行。 |
|
Unknown (未知) |
由于某种原因,无法获取 Pod 的状态,通常是因为与 Pod 所在节点的 通信失败。 |
节点失联、网络分区等。 |
深入分析: PodConditions除了 phase 之外, pod.status.conditions 数组提供了更细粒度的状态信息。它是一系列描述 Pod 当前状况的“条件断言”。
PodCondition
PodStatus 对象中包含一个 PodCondition 数组,详细描述 Pod 的状态:
| 字段 | 说明 |
|---|---|
| lastProbeTime | 最后一次探测 Pod Condition 的时间戳 |
| lastTransitionTime | 上次 Condition 从一种状态转换到另一种状态的时间 |
| message | 上次 Condition 状态转换的详细描述 |
| reason | Condition 最后一次转换的原因 |
| status | Condition 状态类型("True"、"False"、"Unknown") |
| type | Condition 类型(如 PodScheduled、Ready、Initialized、Unschedulable、ContainersReady) |
三、重启策略(restartPolicy)
Pod 的 spec.restartPolicy字段决定了当 Pod 中的容器退出时,Kubelet 应采取何种行动。
| 策略 (Policy) | 描述 |
|
Always (默认) |
无论容器以何种状态(成功或失败)退出,Kubelet 都会自动重启该容器。 |
| OnFailure | 仅当容器以非零退出码(表示失败)退出时,Kubelet 才重启该容器。 |
| Never | 无论容器以何种状态退出,Kubelet 都不会重启该容器。 |
重要关联:重启策略的选择通常由管理 Pod 的控制器决定,而不是手动设置。
- Deployment, ReplicaSet, DaemonSet: 这些控制器旨在确保持续运行一组 Pod。因此,它们管理的 Pod 的
restartPolicy必须是Always。
- Job:
Job用于执行一次性任务。任务完成后,Pod 不应再重启。因此,Job管理的 Pod 的restartPolicy必须是OnFailure或Never。
不同控制器对重启策略的限制:
-
控制器类型 重启策略限制 适用场景 Job "OnFailure" 或 "Never" 一次性任务(如批量计算) ReplicaSet/Deployment "Always" 希望 Pod 一直运行 DaemonSet "Always" 每个节点上启动一个 Pod
当 Kubelet 重启容器时,它会采用指数退避延迟(Exponential Back-off Delay),例如 10s, 20s, 40s...,延迟上限为 5 分钟,以避免因快速连续失败而对系统造成冲击。
四、Init Container(初始化容器)
初始化容器是在 Pod 的主应用容器(App Containers)启动之前运行的特殊容器。它们按顺序执行,并且必须全部成功完成后,主应用容器才会启动。
核心作用及应用场景
- 前置依赖检查:等待外部服务(如数据库、API)就绪。
- 预处理和配置:从远端获取配置文件、执行数据库迁移脚本、生成动态配置等。
- 权限和环境设置:修改文件系统权限、设置内核参数等。
关键特性
- 顺序执行:如果定义了多个 Init 容器,它们会按照定义的顺序依次执行。
- 必须成功:任何一个 Init 容器失败,Kubernetes 都会根据 Pod 的
restartPolicy重试,直到成功。主容器在此期间绝不会启动。
- 资源隔离:Init 容器与主容器共享相同的网络和存储卷(Volumes),这使得它们之间可以方便地共享文件和进行通信。
应用示例:等待数据库就绪
以下示例展示了一个 Web 应用,它使用一个 Init 容器来检查数据库服务 mydb 是否可用,然后再启动主 nginx 容器。
apiVersion: v1
kind: Pod
metadata:
name: my-webapp
spec:
containers:
- name: web-app
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
# Init 容器在主容器之前运行
initContainers:
- name: wait-for-db
image: busybox:1.28
# 使用 nslookup 命令检查名为 'mydb-service' 的 Service 是否可解析
command: ['sh', '-c', 'until nslookup mydb-service; do echo waiting for mydb; sleep 2; done;']
volumes:
- name: workdir
emptyDir: {}
五、Pod 生命周期钩子 (Pod Hooks)
Kubernetes 允许我们在容器生命周期的关键点执行预定义的操作,这就是生命周期钩子。它们由节点上的 kubelet管理和触发。
两种核心钩子
- PostStart
- 触发时机:在容器创建后立即执行。
- 用途:执行环境准备、依赖注册、预热缓存等启动后任务。
- 注意:此钩子与容器的入口命令(ENTRYPOINT)异步执行。但如果
PostStart钩子执行时间过长或失败,容器将无法进入Running状态。
- PreStop
- 触发时机:在容器被终止之前调用。这是一个阻塞调用。
- 用途:实现优雅关闭(Graceful Shutdown)。例如,通知其他系统下线、保存当前状态、关闭数据库连接等。
- 注意:在
PreStop钩子完成之前,Kubernetes 不会向容器发送SIGTERM信号。如果钩子执行超时,容器将被强制杀死(SIGKILL)。
实现方式
| 方式 | 描述 | 示例 |
| Exec | 在容器内执行一个指定的命令。 | command: ["/bin/sh", "-c", "echo 'Shutting down...' > /proc/1/fd/1"] |
| HTTP | 向容器内的特定端点发送一个 HTTP GET 请求。 | httpGet: { path: "/shutdown", port: 8080 } |
应用示例:使用 PreStop 实现优雅下线
这个 Nginx Pod 在被删除前,会执行一个 PreStop 钩子,优雅地关闭 Nginx 进程,确保所有处理中的连接都完成后再退出。
apiVersion: v1
kind: Pod
metadata:
name: nginx-graceful-shutdown
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
# Nginx 的官方优雅关闭命令
command: ["/usr/sbin/nginx", "-s", "quit"]
优雅关闭与强制删除
- 默认行为:K8s 通知 node 执行容器 stop 命令,向 PID 1 进程发送 SIGTERM,等待 30 秒后发送 SIGKILL
- 使用 PreStop:在发送终止信号前执行,实现优雅关闭
- 强制删除:
kubectl delete pod <name> --force --grace-period=0,会立即删除 Pod
六、健康检查探针 (Probes)
探针是 kubelet对容器进行的周期性诊断,用于判断容器的健康状况,并据此采取相应行动。
三类核心探针
| 探针类型 | 目的:它回答什么问题? | 失败后的行动 | 适用场景 |
|
Liveness Probe (存活探针) |
“你的应用还‘活着’吗?” |
Kubelet 会 杀死并重启 该容器。 |
检测应用是否陷入死锁或无响应状态,通过重启来恢复服务。 |
|
Readiness Probe (就绪探针) |
“你的应用准备好接收流量了吗?” |
Kubelet 会将该 Pod 从对应 Service 的 Endpoints 列表中 移除 。流量将不再转发到此 Pod。 |
应用启动时需要加载大量数据或配置,或应用在运行时因过载而暂时无法处理新请求。 |
|
Startup Probe (启动探针) |
“你的应用启动完成了吗?” |
Kubelet 会 杀死并重启 该容器。在探针成功前, 和 探针都会被禁用。 |
适用于启动时间非常长的应用,防止它们在尚未完全就绪时就被 探针误杀。 |
探针的实现方式
所有探针都支持以下三种检查方法:
-
exec: 在容器内执行命令,如果命令退出码为0则视为成功。
-
httpGet: 向指定的 IP、端口和路径发送 HTTP GET 请求,如果返回的 HTTP 状态码在200-399之间则视为成功。
-
tcpSocket: 尝试与容器的指定端口建立 TCP 连接,如果连接成功则视为成功。
关键配置参数
配置探针时,可以通过以下参数来精确控制其行为:
|
参数 |
描述 |
默认值 |
|
|---|---|---|---|
|
|
容器启动后,首次执行探针前的延迟秒数。 |
0 |
|
|
|
执行探针的频率(间隔秒数)。 |
10 |
|
|
|
探针的超时时间。如果超过此时长仍未返回结果,则视为失败。 |
1 |
|
|
|
在连续多少次失败后,将探针状态标记为失败。 |
3 |
|
|
|
在连续多少次成功后,将探针状态标记为成功(从失败状态恢复)。 |
1 |
应用示例:配置全面的健康检查
apiVersion: v1
kind: Pod
metadata:
name: probe-demo
spec:
containers:
- name: my-app
image: my-slow-starting-app
ports:
- containerPort: 8080
# 就绪探针:检查应用是否准备好接收流量
readinessProbe:
httpGet:
path: /api/ready
port: 8080
initialDelaySeconds: 5 # 启动5秒后开始检查
periodSeconds: 5 # 每5秒检查一次
# 存活探针:检查应用是否还在正常运行
livenessProbe:
httpGet:
path: /api/healthy
port: 8080
periodSeconds: 10 # 每10秒检查一次
failureThreshold: 3 # 连续3次失败后重启
# 启动探针:应对慢启动应用
startupProbe:
tcpSocket:
port: 8080
failureThreshold: 30 # 最多重试30次
periodSeconds: 10 # 每10秒重试一次(总共给300秒启动时间)
七、总结
Pod 生命周期主要包括以下关键部分:
- 状态管理:了解 Pod 的各种状态有助于诊断问题
- 初始化容器:解决服务依赖、配置初始化等问题
- 生命周期钩子:PostStart 和 PreStop 钩子实现容器启动前和终止前的自定义操作
- 健康检查:Liveness Probe 和 Readiness Probe 确保应用健康和可用性
通过合理配置这些组件,可以确保应用在 Kubernetes 集群中稳定运行,实现优雅启动、优雅关闭和自动恢复,从而提高应用的可靠性和可用性。
以上内容基于 Kubernetes 官方文档和实践整理,适用于 Kubernetes 1.16+ 版本,是 Kubernetes 应用部署和运维的核心知识点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)