【Python大数据+AI毕设实战】豆瓣电影排行数据可视化分析系统、计算机毕业设计、包括数据爬取、Spark、数据分析、数据可视化、Hadoop、实战教学
【Python大数据+AI毕设实战】豆瓣电影排行数据可视化分析系统、计算机毕业设计、包括数据爬取、Spark、数据分析、数据可视化、Hadoop、实战教学
🎓 作者:计算机毕设小月哥 | 软件开发专家
🖥️ 简介:8年计算机软件程序开发经验。精通Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等技术栈。
🛠️ 专业服务 🛠️
- 需求定制化开发
- 源码提供与讲解
- 技术文档撰写(指导计算机毕设选题【新颖+创新】、任务书、开题报告、文献综述、外文翻译等)
- 项目答辩演示PPT制作
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅
这里写目录标题
基于大数据的豆瓣电影排行数据可视化分析系统-功能介绍
本系统是一个名为【Python大数据+AI毕设实战】豆瓣电影排行数据可视化分析系统的综合性项目,它旨在利用现代大数据技术对豆瓣电影榜单数据进行深度挖掘与直观呈现。系统整体架构围绕Python语言构建,后端采用Django框架负责业务逻辑与API接口服务,而核心的数据处理与分析能力则由强大的Hadoop生态系统中的Spark框架提供。项目首先对从豆瓣获取的原始电影数据(如电影标题、类型、地区、评分、评分人数等)进行预处理,利用Spark的分布式计算能力高效清洗和转换数据,特别是针对复合型字段(如类型、地区列表)的解析和时间字段的提取。随后,系统通过Spark SQL及Pandas库执行多达16项维度的数据分析,例如全球高分电影出产地分布、不同年代电影产出与评分趋势、电影类型与评分的相关性等,从而揭示隐藏在数据背后的电影产业规律与用户偏好。最终,所有分析结果通过Django提供的RESTful API接口,传递给采用Vue.js和ElementUI构建的前端页面,并借助Echarts图表库将复杂的数据转化为交互式的地图、折线图、柱状图和词云等可视化组件,为用户提供一个全面、直观且易于操作的电影数据分析平台。
基于大数据的豆瓣电影排行数据可视化分析系统-选题背景意义
选题背景
随着互联网的普及和数字娱乐产业的蓬勃发展,在线电影平台积累了海量的用户数据。以豆瓣为例,其庞大的电影库不仅包含了影片的基本信息,更汇聚了数以亿计的用户评分和评论,形成了一个宝贵的文化数据宝库。然而,这些数据通常具有体量大、结构多样、价值密度稀疏等特点,传统的数据处理方法难以高效地对其进行深度分析。如何有效地利用这些数据,从中提炼出有价值的洞见,比如电影产业的发展脉络、不同地域的文化特色、观众的口味变迁等,成了一个具有挑战性且富有意义的课题。在这样的背景下,运用以Hadoop和Spark为代表的大数据技术来处理和分析豆瓣电影数据,不仅顺应了技术发展的趋势,也为探索海量文化数据的潜在价值提供了一种全新的解决方案,这也是本课题选择的初衷。
选题意义
这个项目的意义,对我们学生来说,最直接的就是提供了一个将理论知识付诸实践的完整机会。从用Spark处理海量数据,到用Django搭建后端服务,再到用Vue和Echarts把结果清晰地展示出来,走完这个全流程,能让我们对大数据项目开发有个整体的把握,动手能力也能得到实实在在的锻炼。从另一个角度看,这个系统也给广大电影爱好者提供了一个新颖的数据探索工具。大家不用再费力地逐条翻阅信息,通过这个系统生成的可视化图表,就能很直观地看到不同国家电影的产出情况、高分电影类型的演变趋势,甚至是哪些演员堪称“高分劳模”。虽然它只是一个毕业设计,功能和深度都还有提升空间,但它确实展示了一种用数据说话、以可视化呈现信息的方法,对于我们理解数据分析如何服务于实际应用,是很有帮助的。
基于大数据的豆瓣电影排行数据可视化分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于大数据的豆瓣电影排行数据可视化分析系统-图片展示

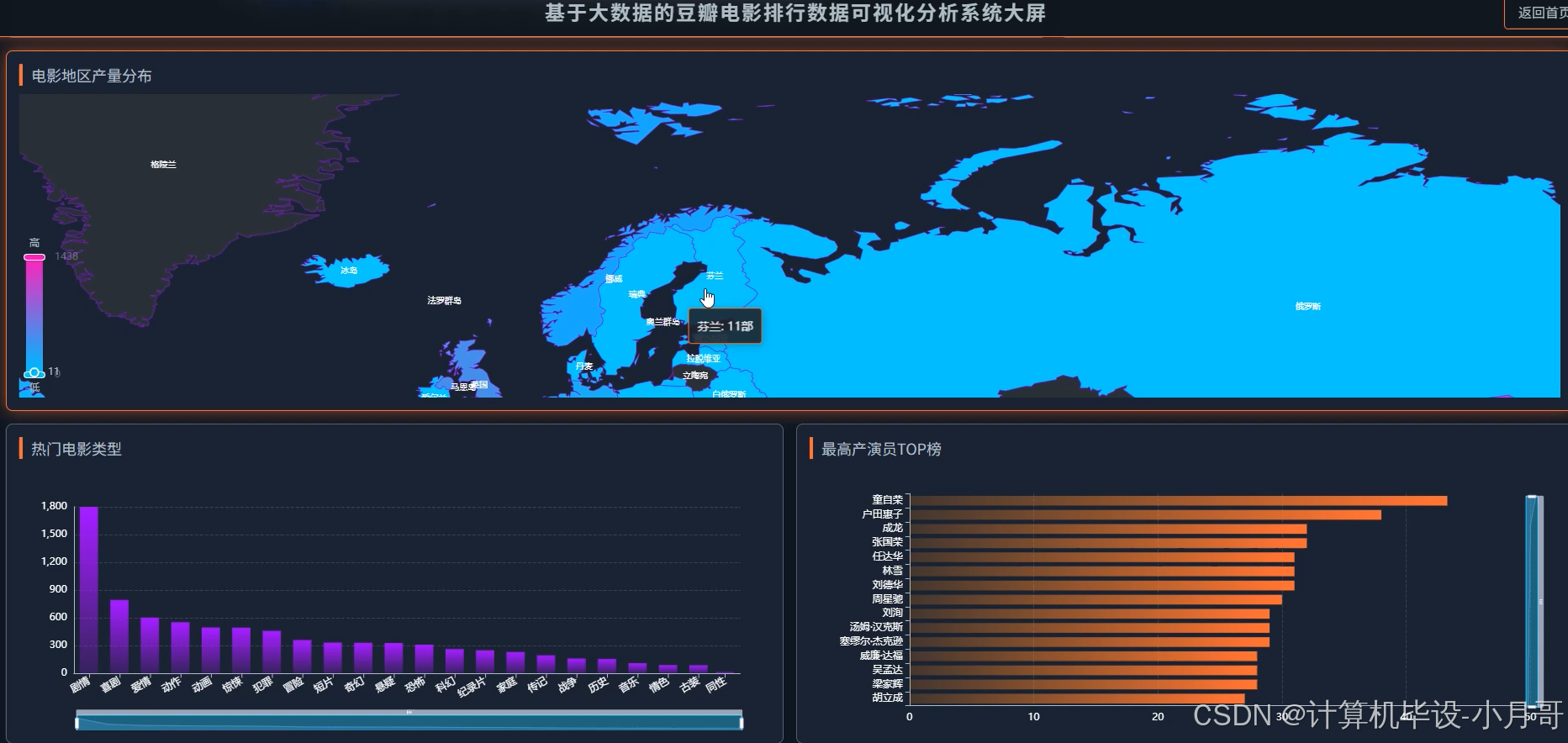
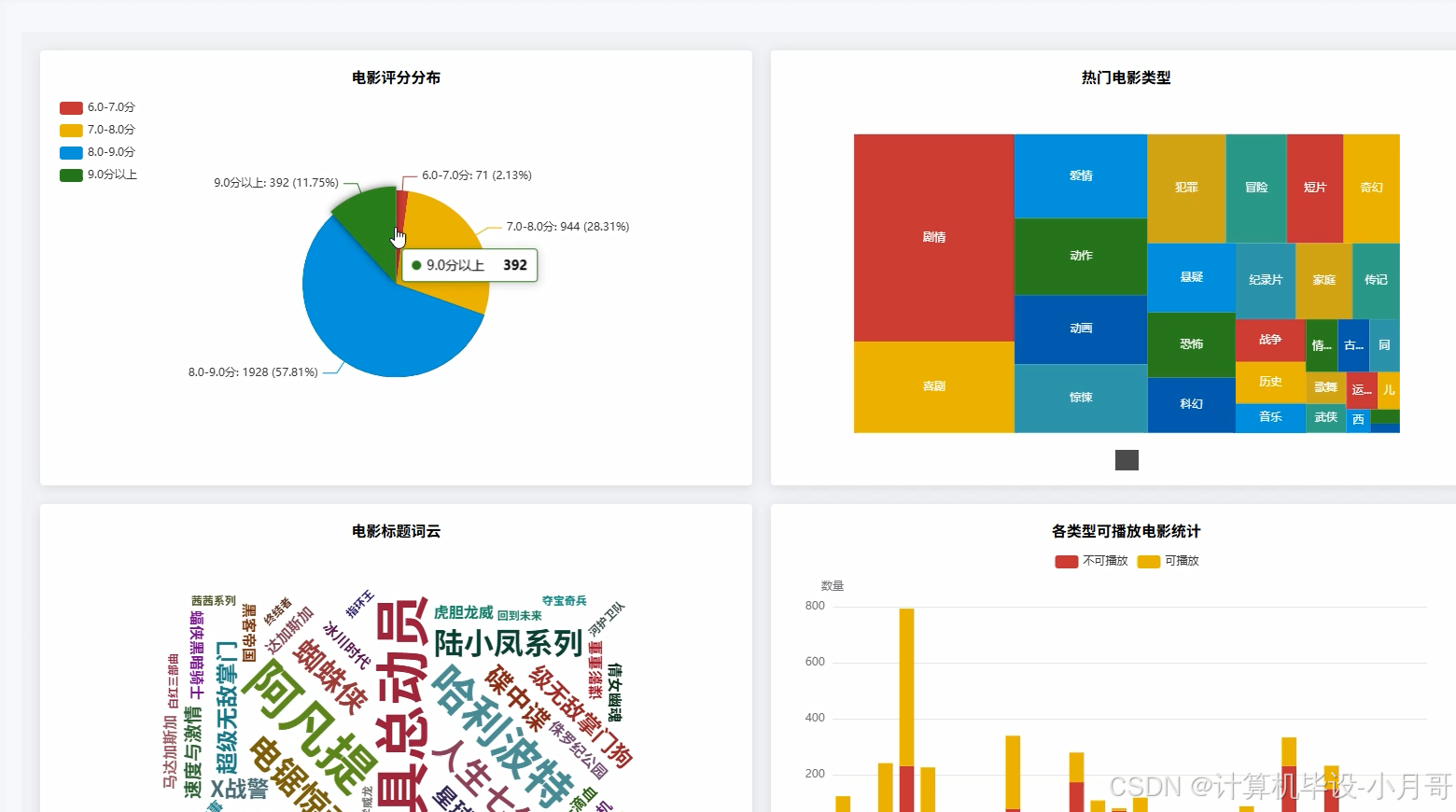
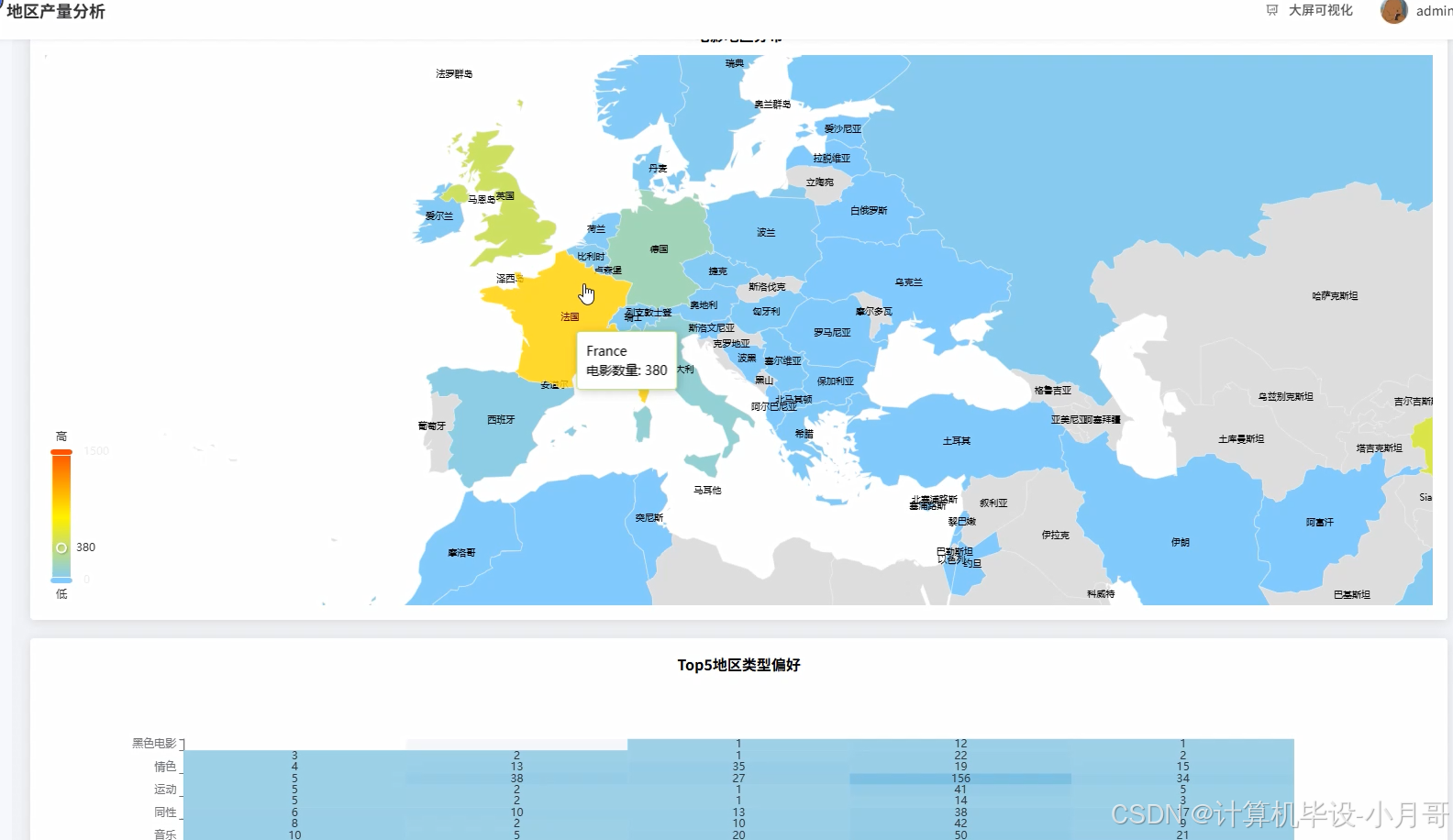
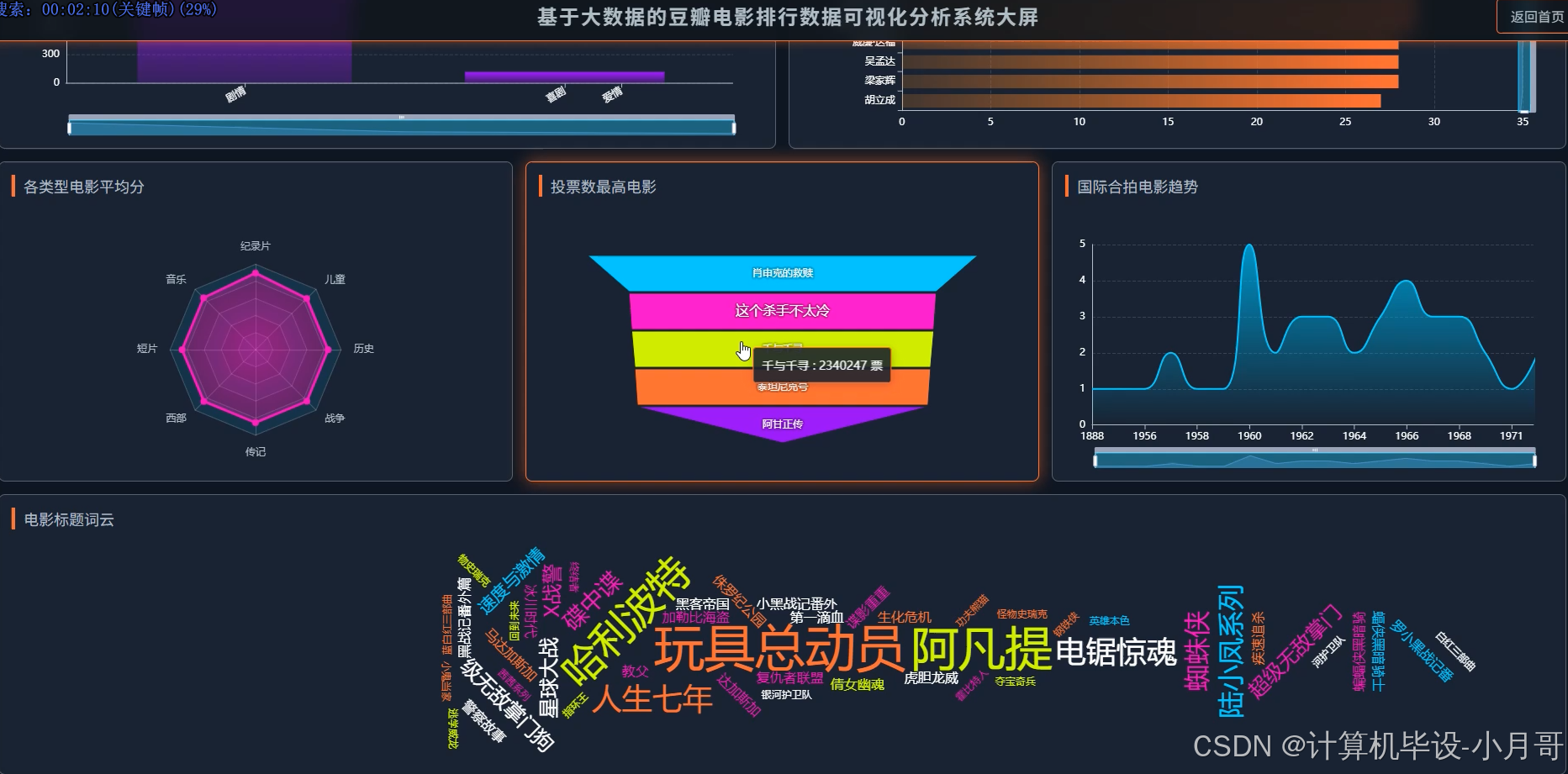
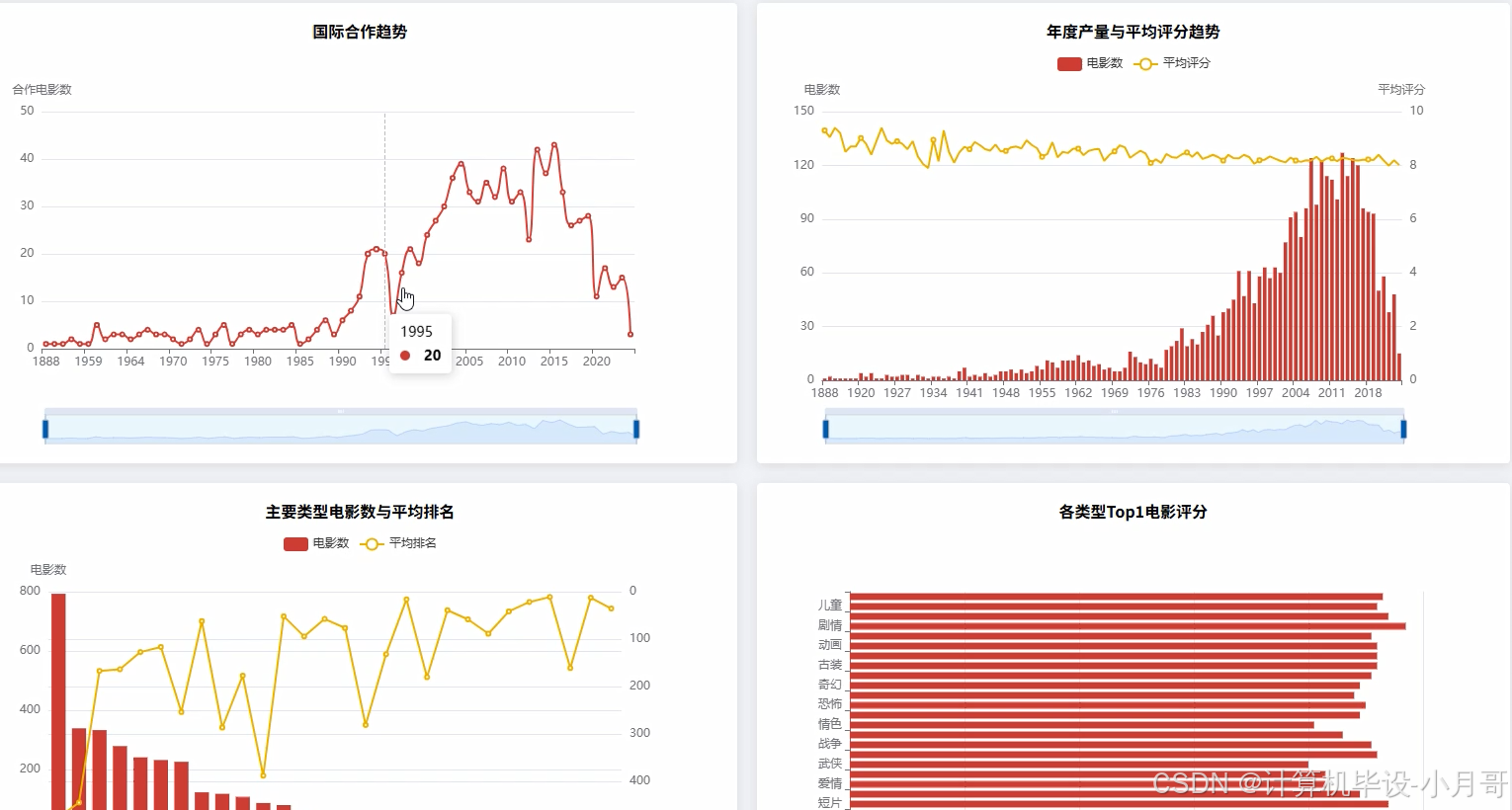
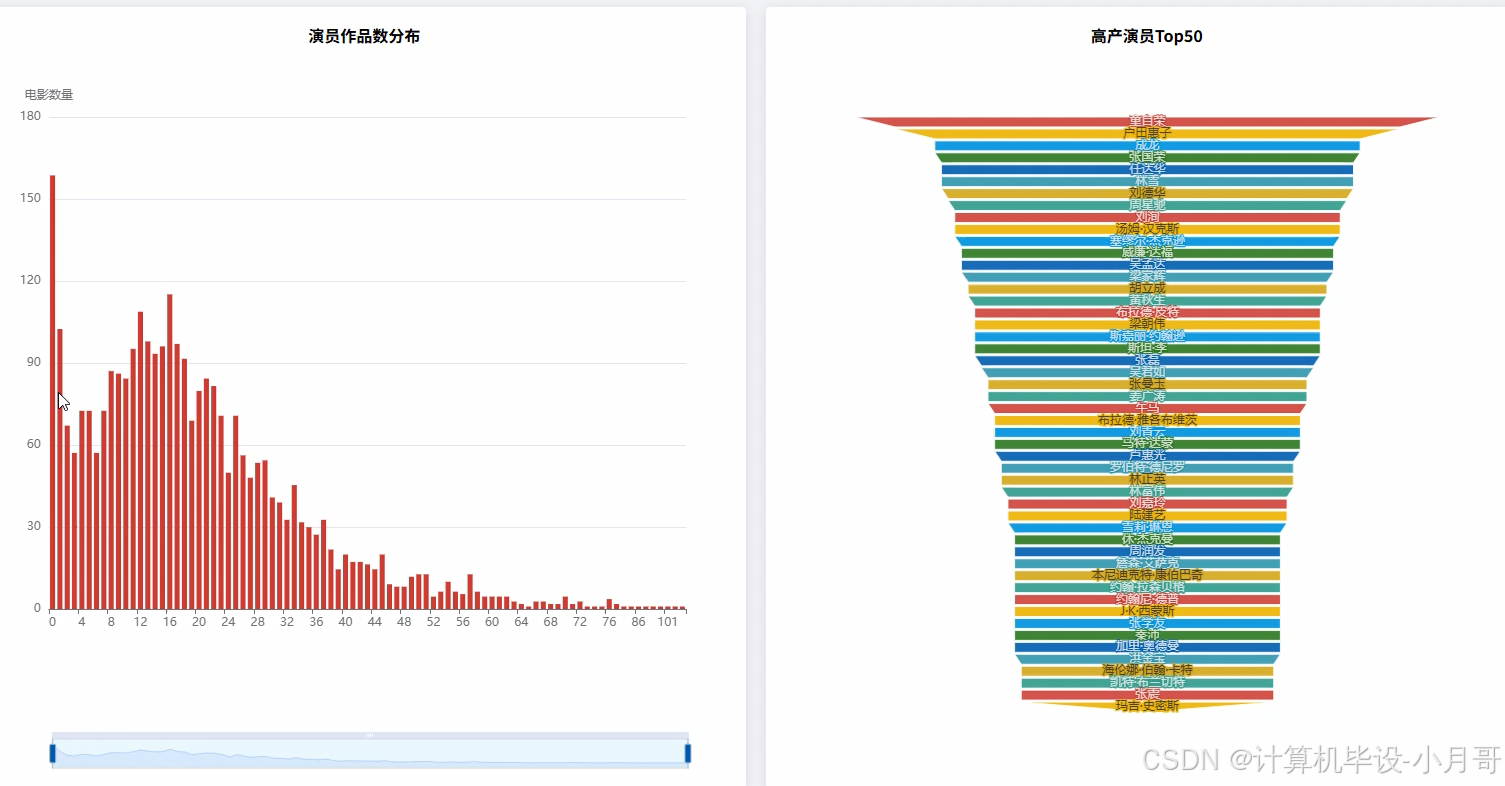
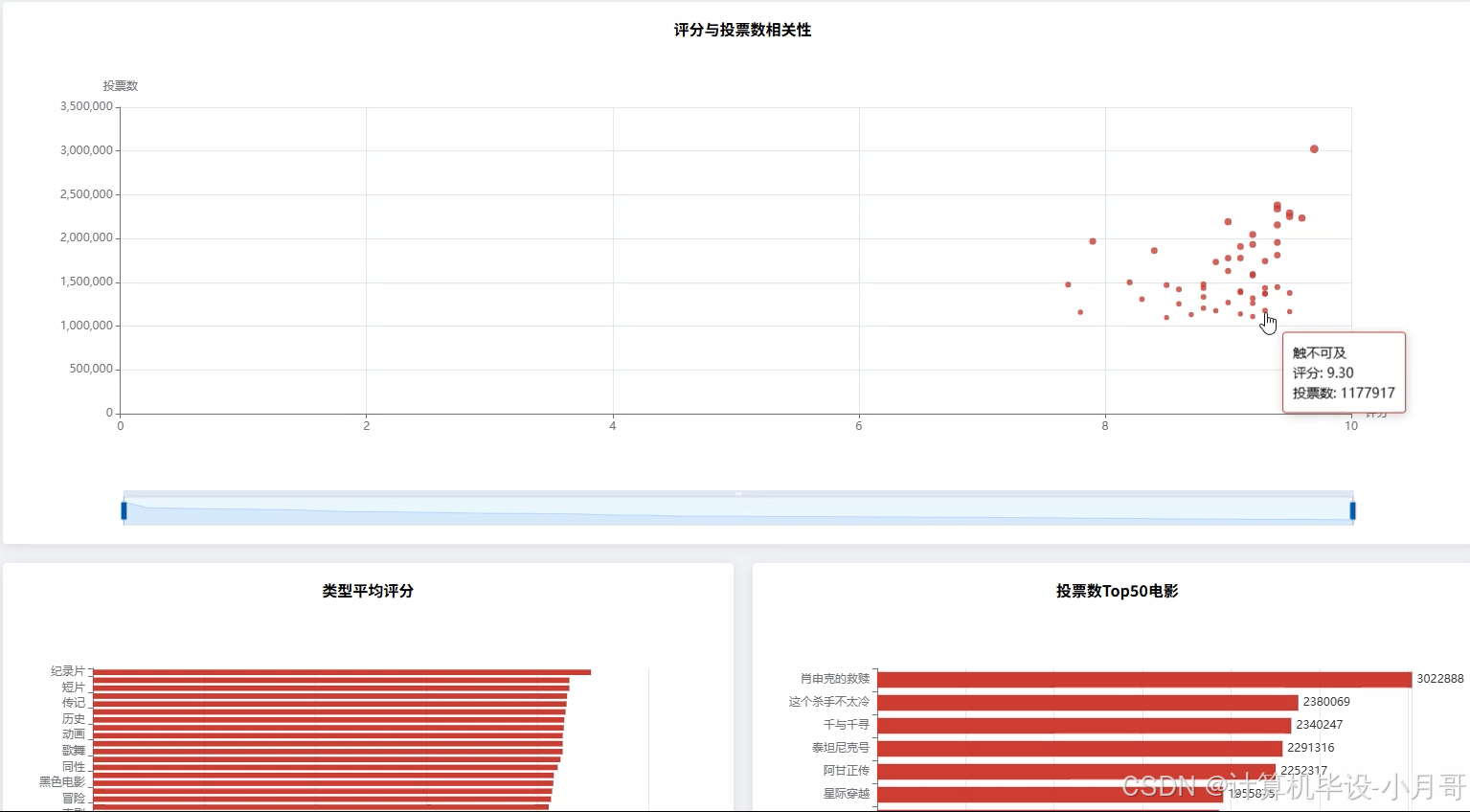
基于大数据的豆瓣电影排行数据可视化分析系统-代码展示
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, explode, split, substring, avg, count, when, floor
spark = SparkSession.builder.appName("DoubanMovieAnalysis").getOrCreate()
df = spark.read.csv("hdfs://path/to/movie_data.csv", header=True, inferSchema=True)
df = df.na.fill({"rating": 0.0, "vote_count": 0, "actor_count": 0, "regions": "未知", "types": "未知", "actors": "未知", "release_date": "未知"})
def region_distribution_analysis(df):
regions_df = df.withColumn("region", explode(split(col("regions"), "'|'|\[|\]")))
regions_df = regions_df.filter(col("region") != "" & col("region") != "未知")
region_count = regions_df.groupBy("region").agg(count("id").alias("movie_count"))
region_count = region_count.orderBy(col("movie_count").desc())
region_count.show()
region_count.write.mode("overwrite").csv("region_distribution_analysis.csv", header=True)
def yearly_production_rating_trend_analysis(df):
yearly_df = df.filter(col("release_date") != "未知" & col("release_date").rlike(r"\d{4}"))
yearly_df = yearly_df.withColumn("year", substring(col("release_date"), 1, 4).cast("int"))
yearly_df = yearly_df.filter((col("year") >= 1900) & (col("year") <= 2024))
yearly_trend = yearly_df.groupBy("year").agg(count("id").alias("movie_count"), avg("rating").alias("avg_rating"))
yearly_trend = yearly_trend.orderBy("year")
yearly_trend.show()
yearly_trend.write.mode("overwrite").csv("yearly_production_rating_trend_analysis.csv", header=True)
def rating_vote_correlation_analysis(df):
correlation_df = df.filter((col("rating") > 0) & (col("vote_count") > 0))
correlation_df = correlation_df.withColumn("rating_bin", floor(col("rating") * 2) / 2)
correlation_analysis = correlation_df.groupBy("rating_bin").agg(avg("vote_count").alias("avg_vote_count"), count("id").alias("movie_number"))
correlation_analysis = correlation_analysis.orderBy(col("rating_bin"))
correlation_analysis.show()
correlation_analysis.write.mode("overwrite").csv("rating_vote_correlation_analysis.csv", header=True)
region_distribution_analysis(df)
yearly_production_rating_trend_analysis(df)
rating_vote_correlation_analysis(df)
spark.stop()
基于大数据的豆瓣电影排行数据可视化分析系统-结语
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)