零基础学AI大模型之Embedding与LLM大模型对比全解析
摘要:本文深入解析文本嵌入(Embedding)与大语言模型(LLM)的核心差异与协作关系。通过类比“语义地图”形象说明Embedding如何将文字转换为可计算的向量坐标,实现语义相似度判断。文章对比了两者的关键特性:Embedding专注语义编码(固定维度、高效检索),LLM侧重文本生成(上下文理解、创造性输出)。结合RAG系统实例,展示了二者如何分工协作——Embedding负责快速筛选知识片
| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析 |
前情摘要
前情摘要
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之大模型的“幻觉”
17、零基础学AI大模型之RAG技术
18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析
本文章目录
零基础学AI大模型之Embedding与LLM大模型对比全解析
一、开篇思考:为什么要区分Embedding和LLM?
在之前的RAG系统学习中,我们提到过“文本转向量”是检索的关键步骤,但很多零基础同学会有疑问:
- 既然GPT-4、Claude这类LLM能理解文本,为什么还要专门用Embedding模型?
- 文本嵌入(Text Embedding)到底是做什么的?和LLM的核心区别在哪里?
其实这就像在餐厅里,你不会让厨师去切菜、摆盘——不是厨师做不到,而是“分工不同”。今天我们就彻底搞懂:Embedding和LLM各自的定位、核心差异,以及它们如何协作打造高效的AI应用。

二、什么是文本嵌入(Text Embedding)?—— 给文字发“数字身份证”
2.1 通俗类比:Java工程师的烦恼
假设你是一名Java工程师,需要把用户评论(比如“这个产品的续航太差了”)存入数据库。
- 传统方式:直接存字符串。但计算机只认识0和1,根本“读不懂”这句话的含义——它不知道“续航差”是负面评价,也分不清和“电池不耐用”是同一个意思。
- Embedding方式:把这句话转换成一串固定长度的数字数组(比如
[0.32, -0.15, 0.78, ..., 0.21]),这串数字就是文本的“向量表示”。
简单说,文本嵌入就是把“不可计算的文字”翻译成“可计算的数字密码”,让计算机能通过数学方式理解语义。
2.2 核心作用:给文字在“语义地图”上标坐标
我们可以把高维向量空间想象成一张“语义地图”:
- 每个词、句子或文档都是地图上的一个点,Embedding就是给这个点分配唯一坐标;
- 语义越接近的文字,坐标距离越近(比如“猫”和“狗”的向量距离<“猫”和“汽车”);
- 即使文字表述不同,只要含义一致,坐标也会相近(比如“如何养小猫咪”和“幼猫护理指南”)。
举个具体例子:
- “猫” →
[0.2, -0.5, 0.8, ..., 0.11](300维向量,维度固定); - “犬” →
[0.18, -0.47, 0.79, ..., 0.12](和“猫”的向量距离极近); - “苹果(水果)” →
[0.5, 0.2, -0.3, ..., 0.08]; - “苹果(手机)” →
[-0.1, 0.6, 0.4, ..., 0.32](和水果“苹果”的向量距离很远)。
2.3 文本嵌入的3个核心特点
- 语义感知:相似文字的向量相似度高,歧义文字的向量差异大(如“苹果”的双关用法);
- 降维表示:把离散的文字(比如“续航差”“电池不耐用”两个不同短语)转化为连续的向量空间;
- 维度固定:无论输入是1个词、1句话还是1段文档,同一个Embedding模型输出的向量长度永远相同(常见384维、768维、1536维)。
2.4 直观案例:3句话的向量分布(二维简化版)
假设我们有3句话,通过Embedding模型转换为二维向量后,在地图上的分布如下:
- 句子1:小帅喜欢吃香蕉 → 向量
(0.6, 0.3) - 句子2:小美喜欢吃苹果 → 向量
(0.58, 0.28) - 句子3:小明在打篮球 → 向量
(-0.4, 0.7)
从坐标能明显看出:句子1和句子2的距离很近(都属于“某人喜欢吃某水果”的语义),而句子3则远离前两者——这就是Embedding的“语义聚类”能力。
2.5 文本嵌入的典型应用场景
- 语义搜索:不依赖关键词匹配,精准找到含义相近的内容(比如搜索“如何修复电脑蓝屏”,匹配到“Windows系统崩溃解决方案”);
- 智能分类:自动识别文本类型/情绪(比如把用户评论分为“正面”“负面”“中性”,无需手动标注关键词);
- 问答系统:快速从海量文档中定位与问题最相关的段落(比如用户问“大模型的上下文窗口是什么”,从1000页手册中精准匹配到相关章节);
- 聚类分析:把海量文本按语义分组(比如把10万条客户反馈分成“价格问题”“质量问题”“售后问题”三类)。
三、什么是Embedding大模型?—— 专注“文本转向量”的专家
3.1 核心定位:只做“翻译官”,不做“创作者”
Embedding模型的唯一核心任务,就是将文本高效、精准地转换为数值向量。它不具备生成自然文本的能力,也无法进行多轮对话——它的价值在于“把文字变成可计算的数学符号”。
3.2 文本嵌入的完整链路
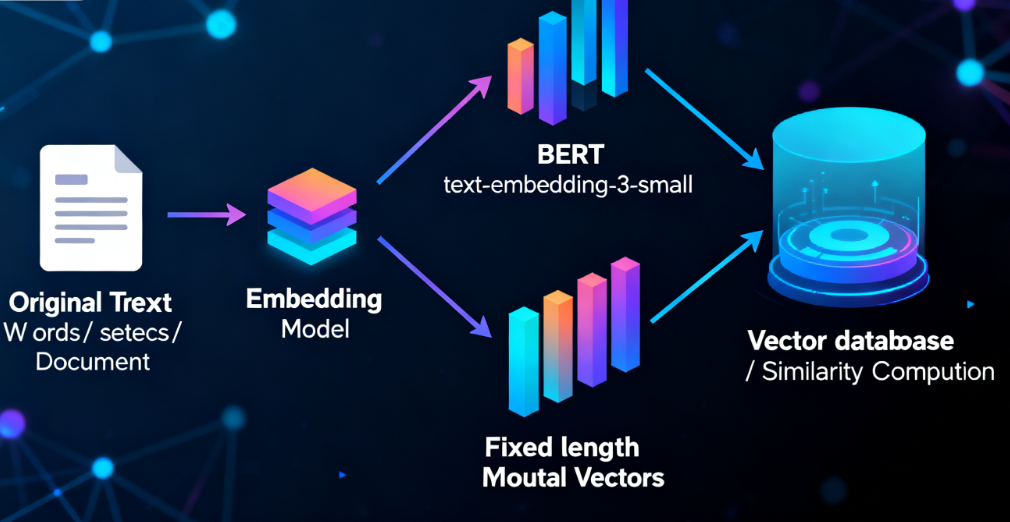
比如在RAG系统中,我们把分割后的文档片段通过Embedding模型转成向量存入向量库,当用户提问时,再把问题转成向量,通过“计算向量距离”快速找到最相关的文档片段——这一步的核心就是Embedding模型的作用。
3.3 常见的Embedding模型
- 开源模型:BERT、RoBERTa、Sentence-BERT(专门优化句子嵌入)、E5;
- 闭源API:OpenAI的text-embedding-3系列、Google的PaLM Embedding、百度文心一言的Embedding API。
四、核心对比:Embedding大模型 vs LLM大模型
很多同学会把两者混淆,其实它们的定位、能力、用法完全不同。我们用一张表清晰对比:
| 对比维度 | LLM大模型(如GPT-4、Claude、Llama 3) | Embedding大模型(如BERT、text-embedding-3、Sentence-BERT) |
|---|---|---|
| 核心能力 | 理解文本+生成文本(内容创作、对话交互) | 仅文本转向量(语义编码、相似度计算) |
| 输出形式 | 自然语言文本(对话、文章、代码、摘要) | 高维数值向量(如1536维浮点数数组) |
| 典型交互 | 多轮对话、持续创作(比如写报告、解难题) | 单次转换、批量处理(比如把1万条文档批量转向量) |
| 计算成本 | 高(参数量千亿级,推理耗资源) | 低(参数量数百万-数十亿级,推理速度快) |
| 适用场景 | 内容生成、逻辑推理、多轮交互 | 语义检索、文本分类、聚类分析、相似度计算 |
4.1 关键联系:同源但分工不同
两者的“知识基础”是相同的——都通过海量文本数据训练,掌握了人类语言的语法、语义规律。这就像作家和图书管理员:都读过很多书,但作家擅长“创作内容”,图书管理员擅长“整理和检索内容”。
4.2 协作关系:1+1>2的黄金搭档
在实际AI应用中,两者几乎都是组合使用的,流程如下:
比如你用智能客服问“我的订单怎么还没到”:
- Embedding模型先把你的问题转成向量,在知识库中快速匹配到“订单查询”相关的10个相似问题(1秒内完成);
- 把这10个问题的答案作为“参考资料”传给LLM;
- LLM基于参考资料,生成个性化回答:“您的订单编号XXX已发货,物流单号XXX,预计明天18:00前送达”。
没有Embedding,LLM就像“大海捞针”——要么找不到精准信息,要么因上下文过长导致回答混乱;没有LLM,Embedding只能返回匹配的原始文本,无法生成自然、易懂的回复。
五、3个常见误区:避开这些认知陷阱
误区1:“Embedding是简化版LLM”
❌ 错误认知:觉得Embedding模型只是参数量小、功能弱的LLM。
✅ 正确理解:两者是“不同工种”,而非“强弱之分”。就像厨师和营养师:厨师擅长做饭,营养师擅长搭配饮食,不能说“营养师是简化版厨师”。
误区2:“LLM可以直接做Embedding的事”
❌ 错误认知:既然LLM能理解语义,直接用LLM生成向量就行,不用单独用Embedding模型。
✅ 正确理解:理论上可以(比如提取LLM中间层的输出作为向量),但就像用跑车送外卖——又贵又慢。LLM推理成本高、速度慢,批量处理1万条文本转向量的成本是Embedding模型的10-100倍,完全没必要。
误区3:“Embedding模型不需要训练”
❌ 错误认知:觉得Embedding只是简单的文本转数字,不用复杂训练。
✅ 正确理解:好的Embedding模型需要海量数据和精细训练。就像优秀的图书管理员,不仅要会整理书籍,还要懂分类逻辑、检索技巧——高质量的Embedding模型能精准捕捉语义差异(比如区分“满意”和“比较满意”的细微情绪),这背后是大量的训练优化。
六、组合应用场景:看两者如何协同工作
场景1:智能客服系统(企业常用)
- Embedding的角色:“问题匹配专家”。把用户咨询(如“退款需要多久”“发票怎么开”)转成向量,快速在知识库中匹配最相似的历史问题和答案模板(毫秒级响应);
- LLM的角色:“回答优化专家”。基于匹配到的答案模板,结合用户订单信息(如订单编号、购买时间),生成个性化、自然的回复,避免机械的模板化语言。
场景2:论文查重与改写系统
- Embedding的角色:“相似度检测器”。把待查重论文的每个段落转成向量,和数据库中的文献向量计算相似度,标记出高重复段落(比传统关键词查重更精准,能识别“ paraphrase 改写”);
- LLM的角色:“改写助手”。对高相似度段落进行语义保留式改写,调整句式和用词,同时给出修改建议(比如“将‘基于深度学习的方法’改为‘采用深度学习技术’”)。
场景3:企业知识库问答(如内部文档查询)
- Embedding的角色:“文档检索员”。把企业内部的员工手册、技术文档、规章制度分割后转成向量存入向量库,用户提问时快速定位相关文档片段;
- LLM的角色:“内容总结员”。把检索到的多个文档片段整合、提炼,生成条理清晰的回答(比如用户问“新员工入职流程”,LLM会把“提交材料”“培训安排”“试用期考核”等相关片段汇总成步骤化回答)。
七、总结:一句话分清两者定位
LLM是“内容生产者”,Embedding是“内容组织者”——就像餐厅里的厨师和配菜员:
- 厨师(LLM):负责把食材做成美味的菜品(把信息变成自然文本);
- 配菜员(Embedding):负责把食材整理、分类、备好(把文本变成可检索的向量)。
没有配菜员,厨师要花大量时间准备食材,效率极低;没有厨师,配菜员备好的食材也无法直接食用。两者协同,才能打造高效、精准的AI应用。
如果觉得本文对你有帮助,欢迎点赞、收藏、关注!有任何问题,评论区留言交流~ 👋


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)