Llama Factory
Llama Factory 是一个"AI模型定制工厂",它让普通人也能轻松地定制和训练自己的大语言模型。LLaMA-Factory 是一个用于训练和微调模型的工具。它支持全参数微调、LoRA 微调、QLoRA 微调、模型评估、模型推理和模型导出等功能。微调的过程模型微调通过在特定任务的数据集上继续训练预训练模型来进行,使得模型能够学习到与任务相关的特定特征和知识。这个过程通常涉及到模型权重的微幅调
1. Llama Factory 到底是什么?
1.1 简单比喻
想象你要定制一辆汽车:
传统方式(没有 Llama Factory):
-
你需要自己造发动机、设计车身、组装零件
-
需要懂机械工程、电子技术、材料科学
-
整个过程复杂、容易出错、耗时很长
使用 Llama Factory:
-
你只需要:
-
选择基础车型(预训练模型)
-
告诉工厂你的需求(训练数据)
-
选择改装方案(训练方法)
-
工厂自动完成所有改装
-
-
你不需要懂技术细节,只需要提需求
1.2 一句话定义
Llama Factory 是一个"AI模型定制工厂",它让普通人也能轻松地定制和训练自己的大语言模型。
2. 为什么需要 Llama Factory?
2.1 传统训练的痛点
假设你想训练一个懂医疗知识的AI助手:
# 传统方式 - 需要写很多复杂代码
import torch
from transformers import AutoModel, AutoTokenizer, TrainingArguments, Trainer
from datasets import load_dataset
import deepspeed
# 1. 数据预处理(很复杂)
def preprocess_function(examples):
# 需要懂分词、填充、截断等技术
pass
# 2. 模型配置(容易出错)
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-5,
# ... 还有几十个参数需要设置
)
# 3. 训练循环(需要深度学习知识)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets,
data_collator=data_collator,
# ... 更多复杂配置
)
# 4. 处理各种错误(内存不足、配置错误等)问题总结:
-
技术门槛高:需要懂编程、深度学习、分布式训练
-
配置复杂:几十个参数需要调优
-
容易出错:内存溢出、配置错误、训练不稳定
-
效率低下:大量时间花在调试上
2.2 Llama Factory 的解决方案
# 使用 Llama Factory 的方式
from llama_factory import TrainArguments, run_train
# 只需要配置几个关键参数
train_args = TrainArguments(
model_name_or_path="Qwen/Qwen2-7B-Instruct", # 基础模型
dataset="my_medical_data", # 你的数据
finetuning_type="lora", # 训练方法
output_dir="./my_medical_ai" # 输出位置
)
# 一键开始训练
run_train(train_args)3. Llama Factory 的核心功能详解
3.1 四种训练方法(像选择汽车改装方案)
方案1:全参数微调 - "整车大改装"
工作原理:更新模型的所有参数
✅ 优点:效果最好,能力最强
❌ 缺点:成本高,需要大量GPU内存
💡 适合:大公司,有充足计算资源
🔧 需求:多张A100/H100显卡
内存需求:模型大小 × 4 × 3 ≈ 12倍模型大小
例如:7B模型需要 7×4×3 = 84GB GPU内存
方案2:LoRA - "加装智能配件"
工作原理:只训练少量新增的参数,不改变原模型
✅ 优点:节省90%内存,训练快,可切换不同任务
❌ 缺点:效果略低于全参数微调
💡 适合:大多数应用场景
🔧 需求:单张RTX 3090/4090即可
内存需求:模型大小 + 少量额外参数
例如:7B模型只需要 7GB + 0.1GB = 7.1GB GPU内存
方案3:QLoRA - "轻量化智能配件"
工作原理:在LoRA基础上,把模型压缩到4位精度
✅ 优点:极省内存,消费级显卡就能训练大模型
❌ 缺点:效果有轻微损失
💡 适合:个人开发者,资源有限
🔧 需求:单张RTX 3080/4060即可
内存需求:模型大小 × 0.5 + 少量参数
例如:7B模型只需要 7×0.5 + 0.1 = 3.6GB GPU内存
方案4:P-Tuning - "只改方向盘"
工作原理:只训练极少量提示参数
✅ 优点:超级省内存,训练极快
❌ 缺点:效果有限,能力提升小
💡 适合:快速实验,极小资源
🔧 需求:几乎任何显卡都能用
内存需求:模型大小 + 极少量参数
4. Llama Factory 的完整工作流程
4.1 第一步:准备数据(像准备菜谱)
数据格式要求:
// 你的训练数据应该长这样
[
{
"instruction": "给以下症状提供医疗建议",
"input": "患者发烧38.5℃,咳嗽,流鼻涕",
"output": "建议多休息、多喝水,可服用退烧药,如症状持续请就医"
},
{
"instruction": "翻译以下英文",
"input": "Hello, how are you?",
"output": "你好,最近怎么样?"
}
]各个字段的含义:
-
instruction:你要AI完成什么任务 -
input:给AI的输入信息 -
output:你期望AI输出的正确答案
数据准备技巧:
-
数量:至少100条,越多越好
-
质量:确保答案准确、专业
-
多样性:覆盖各种场景和问题类型
4.2 第二步:选择基础模型(像选择原材料)
常见基础模型推荐:
中文任务:
- Qwen系列(阿里通义千问):对中文支持最好
- ChatGLM系列(清华):中文理解强
- Baichuan系列(百川):中文优化好
英文任务:
- Llama系列(Meta):生态丰富
- Mistral系列:性能优秀
- Gemma系列(Google):轻量高效
多语言任务:
- Qwen系列:中英文都不错
- Llama系列:通过扩展支持多语言选择原则:
-
任务语言 → 选择对应语言优化好的模型
-
硬件限制 → 选择参数量合适的模型
-
功能需求 → 选择能力匹配的模型
4.3 第三步:配置训练参数(像设置烹饪参数)
# 一个完整的训练配置示例
train_args = TrainArguments(
# 基础配置
model_name_or_path="Qwen/Qwen2-7B-Instruct", # 基础模型
dataset="my_medical_data", # 数据集名称
finetuning_type="lora", # 训练方法
# LoRA 专用配置
lora_target="q_proj,v_proj", # 要改动的模型部件
lora_rank=16, # 改动程度(16-64)
lora_alpha=32, # 学习强度
# 训练参数
output_dir="./my_medical_ai", # 保存位置
per_device_train_batch_size=4, # 批次大小
gradient_accumulation_steps=4, # 梯度累积
learning_rate=2e-4, # 学习率
num_train_epochs=3, # 训练轮数
# 资源优化
fp16=True, # 使用半精度节省内存
logging_steps=10, # 每10步输出日志
)4.4 第四步:开始训练(像启动智能厨房)
from llama_factory import run_train
# 一键开始训练
run_train(train_args)
# 训练过程中你会看到:
# 🔥 开始训练...
# 📊 第1步,损失: 2.3456
# 📊 第10步,损失: 1.2345
# 📊 第20步,损失: 0.8765
# 💾 保存检查点...
# 🎉 训练完成!4.5 第五步:测试和使用(像品尝菜品)
from llama_factory import load_model, get_infer_args
# 加载训练好的模型
infer_args = get_infer_args({
"model_name_or_path": "Qwen/Qwen2-7B-Instruct",
"adapter_name_or_path": "./my_medical_ai", # 你的训练结果
"template": "qwen"
})
model, tokenizer = load_model(infer_args)
# 测试你的AI助手
messages = [
{"role": "user", "content": "我发烧38℃,应该怎么办?"}
]
response = model.chat(tokenizer, messages)
print(f"AI回答: {response}")
# 输出:建议多休息、多喝水,可服用退烧药...5、介绍完,就可以尝试了
LLaMA-Factory 是一个用于训练和微调模型的工具。它支持全参数微调、LoRA 微调、QLoRA 微调、模型评估、模型推理和模型导出等功能。
微调的过程
模型微调通过在特定任务的数据集上继续训练预训练模型来进行,使得模型能够学习到与任务相关的特定特征和知识。这个过程通常涉及到模型权重的微幅调整,而不是从头开始训练一个全新的模型。微调过程主要包括以下几个步骤:
1. 数据准备:收集和准备特定任务的数据集。
2. 模型选择:选择一个预训练模型作为基础模型。
3. 迁移学习:在新数据集上继续训练模型,同时保留预训练模型的知识。
4. 参数调整:根据需要调整模型的参数,如学习率、批大小等。
5. 模型评估:在验证集上评估模型的性能,并根据反馈进行调整。
安装
若电脑没有GPU,可以使用ModelScope云服务
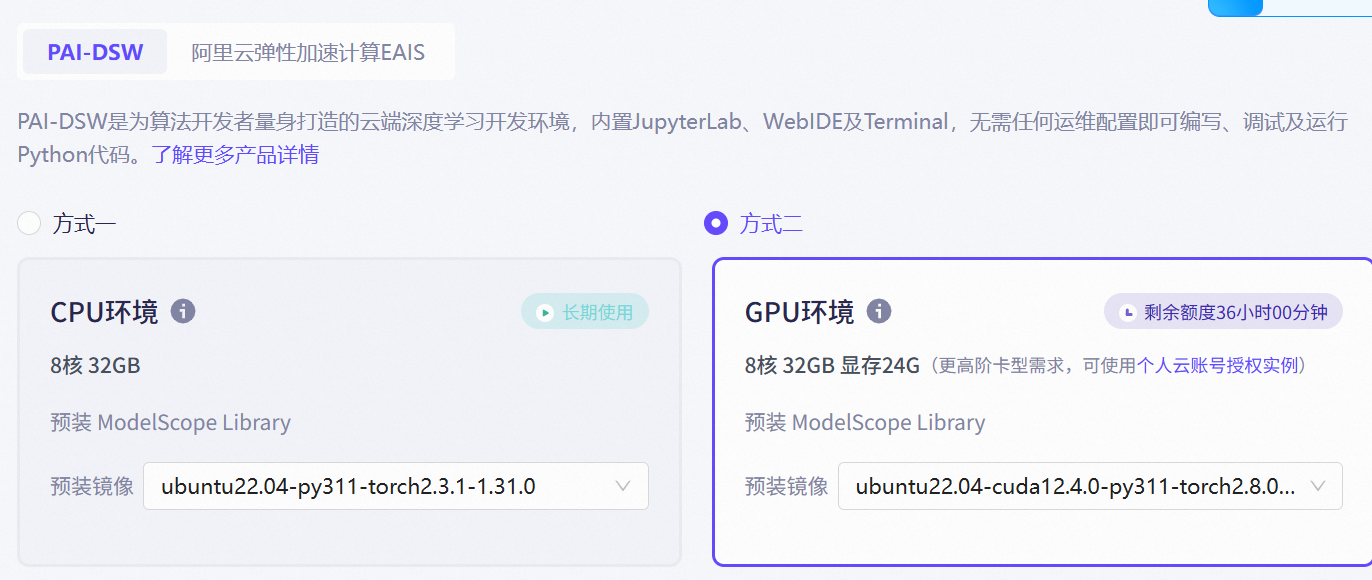
前提CUDA要安装,然后安装llamafactory
# 构建虚拟环境
conda create -n llamafactory python=3.10 -y && conda activate llamafactory
# 下载仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 安装
pip install -e .
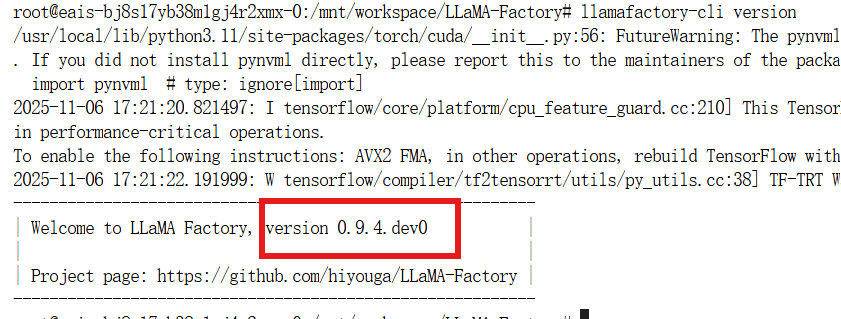
校验
llamafactory-cli version
 安装完成后、可以启动webUI界面配置,也可以直接在示例文件夹下修改。
安装完成后、可以启动webUI界面配置,也可以直接在示例文件夹下修改。
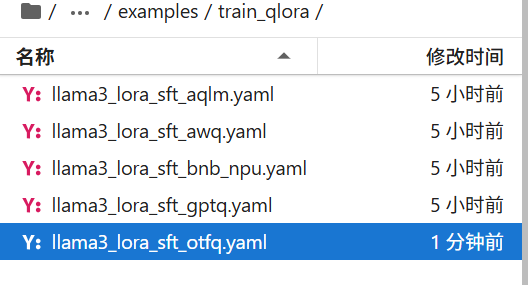
可以读一下readme使用哪个方法训练,有对应命令行的执行命令

打开这个文件有几个配置
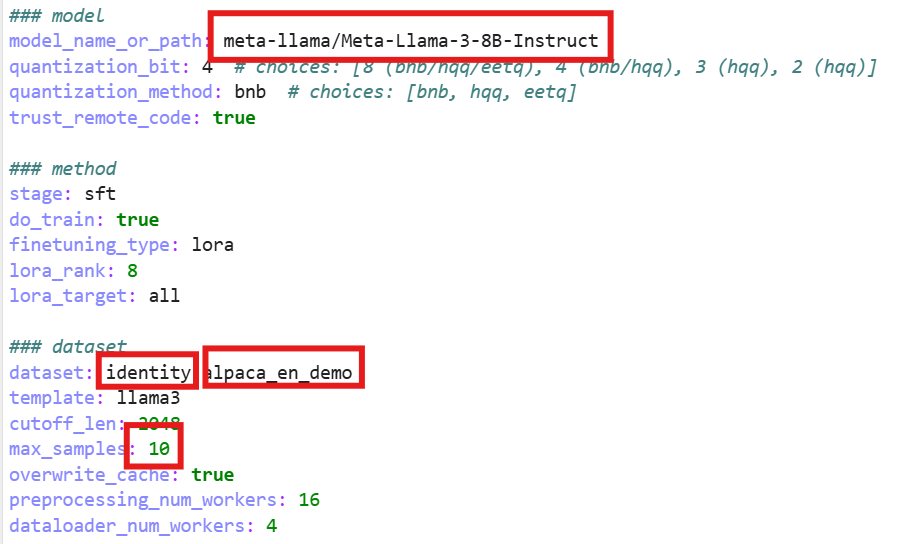
第一个框是它要训练的模型路径,默认模型文件从modelScope上下载
第二个框是用的数据集,有两个,第一个是自我认证:

用户什么都没有输入,只是让模型知道它是谁,一个自我认证的数据集
第二个就是微调的数据集(en证明是英文的)。

第三个框是一次训练最大例子数量,可以调小一点加快训练。
训练配置完成后就可以在命令行执行:
llamafactory-cli train examples/train_qlora/llama3_lora_sft_otfq.yaml
## 官方博客
- 💡 [Easy Dataset × LLaMA Factory: 让大模型高效学习领域知识](https://buaa-act.feishu.cn/wiki/KY9xwTGs1iqHrRkjXBwcZP9WnL9)(中文)
- [使用 LLaMA-Factory 微调心理健康大模型](https://www.lab4ai.cn/project/detail?id=25cce32ec131497b9e06a93336a0817f&type=project&utm_source=LLaMA-Factory)(中文)
- [使用 LLaMA-Factory 构建 GPT-OSS 角色扮演模型](https://docs.llamafactory.com.cn/docs/documents/best-practice/gptroleplay/?utm_source=LLaMA-Factory)(中文)
- [基于 LLaMA-Factory 和 EasyR1 打造一站式无代码大模型强化学习和部署平台 LLM Model Hub](https://aws.amazon.com/cn/blogs/china/building-llm-model-hub-based-on-llamafactory-and-easyr1/)(中文)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)