BRD 技术 —— 让小模型也能拥有大模型的 “阅读能力”
摘要:基础阅读蒸馏(BRD)技术突破传统模型压缩方法的局限,通过让小模型(如564M参量)学习大模型的基础阅读行为(命名实体识别和问答生成),而非直接针对任务训练,实现了跨任务通用能力。实验显示,经BRD训练的小模型在多项NLP任务上超越20倍参量的大模型,零样本测试中情感分析任务提升15.3%,复杂推理任务提升83.25%。这种"能力先行"的蒸馏思路,为轻量化模型部署提供了新
引言
在自然语言处理领域,大型语言模型(LLMs)如 Vicuna-13B、GPT 系列凭借海量参数展现出卓越的文本处理能力,但高计算需求和庞大体积让它们难以在移动端、边缘设备等场景落地。传统蒸馏技术虽试图缩小模型规模,却始终受限于 “任务依赖” 的瓶颈 —— 要么让小模型模仿大模型的内部特征(知识蒸馏),要么直接适配特定下游任务(任务蒸馏),导致小模型缺乏通用文本理解能力。
而近期BRD-基础阅读蒸馏技术的提出,彻底打破了这一局限:通过让小模型学习大模型的 “基础阅读行为”,而非直接针对任务训练,实现了 “一次奠基,多任务受益” 的效果,甚至让 564M 参量的小模型在多项任务上超越 20 倍参量的大模型。
一、传统蒸馏的痛点:为什么小模型总是 “偏科”?
在 BRD 提出之前,主流蒸馏技术分为两类,但都存在明显短板:
- 知识蒸馏:聚焦让小模型(学生)模仿大模型(教师)的内部隐含特征,比如隐藏层输出、注意力图等。但这种方式依赖对大模型内部结构的理解,且容易陷入 “为模仿而模仿”,小模型学到的是 “表层特征” 而非 “理解能力”。
- 任务蒸馏:让小模型直接模仿大模型在下游任务中的输出(如标签预测、推理结果)。这种方式高度依赖特定任务数据,一旦换个任务,小模型性能就大幅下滑,而且教师模型的预测噪声还会进一步影响小模型效果。
两类方法的共同问题是:忽视了小模型的 “基础阅读训练” —— 就像人没学会识字、理解句子,直接去做阅读理解题一样,小模型缺乏处理通用文本的核心能力,自然无法灵活应对不同任务。
二、BRD 的核心思路:先教小模型 “读书”,再让它 “做题”
BRD 的灵感来自人类的学习逻辑:我们先通过基础阅读掌握 “识别关键信息”“理解句子逻辑” 的能力,再用这种能力应对考试、写作等不同任务。对应到模型蒸馏中,BRD 的核心就是让小模型先模仿大模型的基础阅读行为,再将这种能力迁移到下游任务。
这种 “能力先行,任务后置” 的设计,让小模型摆脱了对特定任务数据的依赖,具备了跨任务的通用文本处理能力。
1. 命名实体识别(NER):学会 “抓重点”
BRD 会引导教师模型(如 Vicuna-13B)从通用句子中提取关键实体及属性,比如:
- 输入句子:“贝尔蒙庄园以 6300 万美元挂牌出售,占地 1.28 英亩”
- 教师模型输出:“‘贝尔蒙庄园’属于地理实体,‘6300 万’是价格数值实体,‘1.28 英亩’是面积地理实体”
通过这种训练,小模型能学会从文本中快速定位关键信息 —— 这是后续做推理、问答、情感分析等任务的基础。
2. 问题生成与回答(QRA):学会 “交互式理解”
除了提取信息,BRD 还让小模型学习 “主动提问”:引导教师模型围绕句子的内容、结构或态度生成问题,并从原句中找到答案,比如:
- 输入句子:“为获得优等生毕业资格,他需要在整个大学期间保持高 GPA”
- 教师模型输出:“问题:他需要做什么才能以优异成绩毕业?答案:在整个大学期间保持高 GPA”
这种交互式训练,能让小模型深入理解句子逻辑,而不是简单地 “读文字”。
三、BRD 的实现流程:两步打造 “会阅读” 的小模型
BRD 的实现分为 “教师行为生成” 和 “学生模型训练” 两个阶段,通过引导教师模型进行基础阅读,从而生成大量的基础阅读行为数据去训练学生模型
1. 第一阶段:让教师模型生成 “阅读样本”
首先需要为小模型准备高质量的训练数据,具体步骤如下:
- 数据来源:选用 CC-100 通用语料库(LLM 预训练常用素材),确保数据与下游任务无关,避免 “偏科”;
- 提示模板设计:为 NER 和 QRA 分别设计包含 “任务描述 + 示例 + 输入句” 的模板,引导教师模型生成标准化的阅读行为结果;


- 数据构建:收集教师模型的 NER 和 QRA 输出,与原始句子用<sep>分隔,形成三类训练数据:原始段落(保留基础语言能力)、NER 段落(训练信息提取)、QRA 段落(训练逻辑理解)。
2. 第二阶段:让小模型 “学会阅读”
接下来训练小模型模仿这些阅读行为,关键细节如下:
- 模型初始化:选用小参量预训练模型(如 XGLM-564M,参量仅为教师模型 Vicuna-13B 的 1/23),确保轻量化;
- 训练方式:采用自回归语言建模,损失函数为段落级交叉熵,让小模型能根据前文生成符合阅读逻辑的结果;损失函数:
![]()
- 稳定性保障:混合原始句子与阅读行为数据训练,避免小模型过度聚焦阅读行为而丢失基础语言能力。
四、实验结果:小模型也能 “吊打” 大模型?
论文通过零样本测试、无监督蒸馏等多场景实验,验证了 BRD 的有效性,结果让人眼前一亮 —— 小模型的表现远超预期。
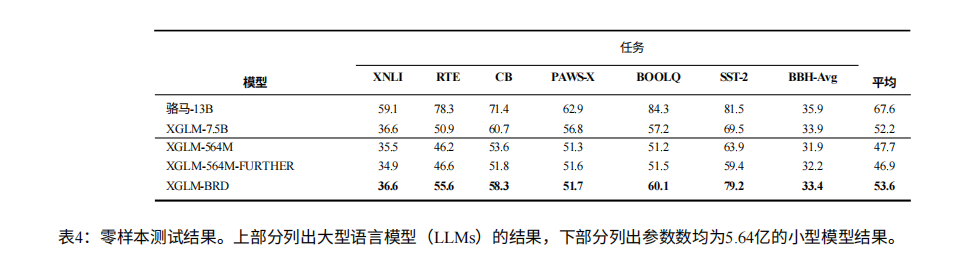
1. 零样本测试:跨任务能力显著提升
在不使用任何下游任务标注数据的情况下,基于 XGLM-564M 训练的 BRD 模型(XGLM-BRD),相比原始模型:
- RTE 任务(语言推理)提升 9.4%,BOOLQ 任务(布尔问答)提升 8.9%,SST-2 任务(情感分析)提升 15.3%;
- 部分任务媲美甚至超越更大模型:在 XNLI 任务上与 75 亿参量的 XGLM-7.5B 持平,SST-2 任务上更是以 79.2 分远超 XGLM-7.5B 的 69.5 分;
- 在复杂的 Big-Bench-Hard 任务中,“几何形状” 子任务相对提升 83.25%,“颜色推理” 子任务提升 59.64%,证明基础阅读能力对复杂推理的支撑作用。
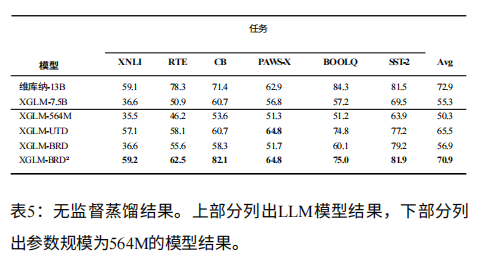
2. 无监督蒸馏:任务适配性再升级
如果用下游任务的无标注数据再做一次 BRD 训练(得到 XGLM-BRD2),性能会进一步爆发:
- CB 任务(因果推理)相对提升 35.26%,RTE 任务提升 7.57%,平均性能达 70.9 分;
- 与 130 亿参量的教师模型 Vicuna-13B 相比,XGLM-BRD2 在 XNLI、CB、PAWS-X、SST-2 四项任务上表现更优,真正实现了 “以小胜大”。
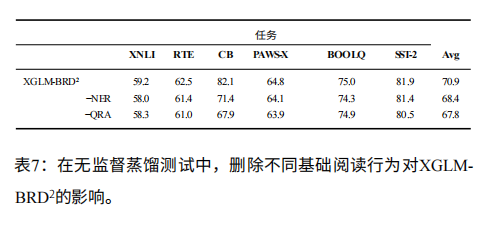
3. 消融实验:哪些阅读行为更重要?
通过消融实验验证了关键设计的必要性:
- 删除 QRA 数据后,模型平均性能下降 3.1 分,远超删除 NER 数据的 2.5 分,说明 “交互式提问与回答” 是基础阅读能力的核心;
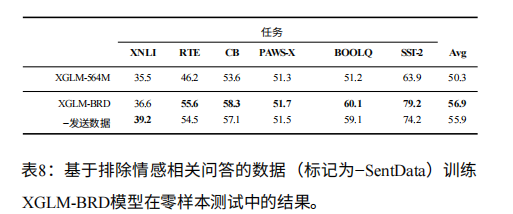
- 排除情感相关的 QRA 数据后,SST-2 任务性能仅下降 5 分,但仍大幅领先原始小模型,证明 BRD 的通用性 —— 不依赖特定任务数据也能起效。
五、BRD 的价值与局限:未来可期,但仍需完善
1. 核心价值
- 降低部署成本:让小模型具备大模型级别的文本处理能力,可直接部署在移动端、边缘设备等资源受限场景;
- 提升开发效率:无需为每个任务单独训练模型,一次 BRD 训练即可支撑多任务,减少重复开发;
- 可解释性更强:通过分层探测发现,BRD 能强化模型各层的句子理解能力,而非仅表层拟合,让模型 “知其然更知其所以然”。
2. 当前局限
- 语言覆盖有限:目前实验仅基于英语数据,尚未验证多语言场景的适配性;
- 教师模型范围窄:未纳入 GPT-4 等更先进的 LLM 作为教师模型(受 API 调用速度限制);
- 部分任务仍有差距:在 “日期理解” 等需要强时间概念的任务上,与教师模型仍存在显著差距,需进一步优化。
六、总结:BRD 为小模型蒸馏打开新思路
基础阅读蒸馏(BRD)技术的提出,在于跳出了 “任务依赖” 的传统蒸馏框架,回归到 “文本理解的本质”—— 让模型先学会 “阅读”,再去应对各类任务。这种 “能力奠基” 的思路,不仅让小模型实现了性能突破,也为后续轻量化模型的研究提供了新方向。
未来,随着多语言数据的补充、教师模型范围的扩大,BRD 有望进一步释放小模型的潜力,让 “高效、通用、低成本” 的 NLP 应用覆盖更多场景。如果你也在做模型轻量化相关工作,不妨试试 BRD 的思路 —— 或许能让你的小模型 “脱胎换骨”。
(本文实验数据与技术细节均来自论文《Basic Reading Distillation》,论文链接为 openreview.net/pdf?id=Tj2nckSejZV,感兴趣的读者可查阅原文获取更多细节。)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)