CAMEL_AI骆驼框架(学习及应用)
这是一篇我最近在学习DataWhale学习的Agent开源框架CAMEL,后续会更新用它来实现业务的开源代码,敬请关注
1,介绍骆驼框架
这是一个搭建Agent的开源框架,将很多工作流相关的内容封装好后,便于开发者们使用。
选择CAMEL Multi-Agent框架,你将获得以下优势:
- 易于上手:CAMEL Multi-Agent提供了丰富的文档和示例,即使是初学者也能快速上手。
- 灵活性:框架支持多种智能体模型和通信协议,可以适应不同的应用场景。
- 可扩展性:随着项目的发展,你可以轻松地扩展你的多智能体系统。
- 社区支持:CAMEL Multi-Agent拥有一个活跃的社区,你可以在这里找到帮助和资源。
以下是开源的CAMEL的github地址:
https://github.com/camel-ai/camel
2,开源项目简介
我们本章学习主要以开源的Agent项目为主去学习,该开源项目名为:
Handy Multi-Agent Tutorial
开源飞书技术文档学习地址为:
https://fmhw1n4zpn.feishu.cn/docx/AF4XdOZpIo6TOaxzDK8cxInNnCe
3,配置CAMEL环境
配置uv来代替pip:
pip install uv激活虚拟环境:
python -m venv venv # 创建一个名为venv的虚拟环境
venv\Scripts\Activate.ps1 # 激活虚拟环境在CAMEL的开源项目代码中下载压缩包然后解压,后期会调用到里面的函数
安装全部的camel相关依赖:
pip install "camel-ai[all]"4,多样式模型
4.1 对话式
通过构建chat-agent来构建对话智能体
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv('DEEPSEEK_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="deepseek-chat", # DeepSeek模型类型
url='https://api.deepseek.com/v1/', # DeepSeek API地址
api_key=api_key
)
# 创建系统消息,告诉ChatAgent自己的角色定位
system_msg = "你是一个乐于助人的助手,能够积极回答用户的问题。"
# 实例化一个ChatAgent
chat_agent = ChatAgent(model=model, system_message=system_msg,output_language='zh')
while True:
# 构造用户消息
user_msg = input("请你输入想要跟‘助手’对话的内容:")
if "结束" in user_msg or "退出" in user_msg:
print("你已结束对话")
break
# 若没关闭对话
# 将用户消息传给ChatAgent,并获取回复
response = chat_agent.step(user_msg)
print("我:", user_msg)
print("助手:", response.msgs[0].content)
4.2 多模态
图片
from camel.models import ModelFactory
from camel.types import ModelPlatformType
from camel.messages import BaseMessage
from PIL import Image
import requests
import os
from dotenv import load_dotenv
# 加载环境变量并检查API密钥
load_dotenv()
api_key = os.getenv('SILICONFLOW_API_KEY')
if not api_key:
raise ValueError("请设置SILICONFLOW_API_KEY环境变量")
# 创建硅基流动视觉模型实例
model = ModelFactory.create(
model_platform=ModelPlatformType.SILICONFLOW,
model_type="Qwen/Qwen2-VL-72B-Instruct",
api_key=api_key,
model_config_dict={"max_tokens": 2048, "temperature": 0.7}
)
# 下载并打开图片
url = "https://img0.baidu.com/it/u=2205376118,3235587920&fm=253&fmt=auto&app=120&f=JPEG?w=846&h=800"
img = Image.open(requests.get(url, stream=True).raw)
# 创建包含图像的消息并直接调用模型
user_image_msg = BaseMessage.make_user_message(
role_name="User",
content="请描述这张图片的内容",
image_list=[img],
image_detail="high"
)
# 正在调用视觉模型进行图片识别...
response = model.run([user_image_msg.to_openai_user_message()])
print("\n图像识别结果:")
print(response.choices[0].message.content)视频
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType
from camel.messages import BaseMessage
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv('MODELSCOPE_SDK_TOKEN')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/QVQ-72B-Preview",
url='https://api-inference.modelscope.cn/v1/',
api_key=api_key
)
# 创建代理
agent = ChatAgent(
model=model,
output_language='中文'
)
# 读取本地视频文件
video_path = "vedio_test.mp4"
with open(video_path, "rb") as video_file:
video_bytes = video_file.read()
# 创建包含视频的用户消息
user_msg = BaseMessage.make_user_message(
role_name="User",
content="请描述这段视频的内容",
video_bytes=video_bytes # 将视频字节作为参数传入
)
# 获取模型响应
response = agent.step(user_msg)
print(response.msgs[0].content)
>>>
这是一幅令人惊叹的超现实主义景观画,画面中有一只狗在一条被雪覆盖的道路上奔跑。整个场景被一种奇幻而美丽的氛围所包围,让人感受到一种超凡脱俗的美。
首先,画面的背景是一片壮丽的天空,天空中布满了浓密的云层,这些云层呈现出丰富的纹理和层次感。云层的颜色以粉色和紫色为主调,其间还夹杂着一些金色和蓝色的光影,形成了一个绚丽多彩的天幕。在云层之间,有一道明亮的光线穿过,这道光线像是从天际线的尽头射来,照亮了整个场景,给人一种希望和温暖的感觉。
地面上是一条被雪覆盖的道路,道路两旁是连绵起伏的雪山和丘陵。雪地上的足迹和轮胎印清晰可见,表明这里虽然人迹罕至,但仍有生命活动的痕迹。一只白色的狗正在这条道路上奔跑,它的姿态轻盈而欢快,仿佛在享受着这美好的一刻。
整个画面的色彩非常丰富,粉色、紫色、金色、蓝色相互交织,营造出一种梦幻般的氛围。这种色彩的运用让画面充满了活力和生命力,令人不禁沉醉其中。
总的来说,这幅画通过超现实主义的手法,创造了一个美轮美奂的幻想世界,让观者在现实与幻想之间徘徊,感受到艺术带来的无限魅力。4.3 元数据
元数据相当于给一些条件限制,限制大模型往你的方向去思考(type:dirt)
在设置好系统的自己身份后(system_msg),然后设置用户的问答的角色信息(BaseMessage.make_user_message),有元数据的话,是这么设置的:
meta_dict={
"user_preference": "初学者",
"language": "中文",
"learning_style": "理论与实践结合",
"favorite_topics": "机器学习,深度学习",
"reading_level": "入门级"
}
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.messages import BaseMessage
from camel.types import ModelPlatformType
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv('DEEPSEEK_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="deepseek-chat",
url='https://api.deepseek.com/v1/',
api_key=api_key
)
# 创建系统消息
system_msg = "你是一个乐于助人的助手,能够积极回答用户的问题。"
# 实例化一个ChatAgent
chat_agent = ChatAgent(model=model, system_message=system_msg, output_language='zh')
while True:
content = input("请输入你的问题:")
if "退出" in content:
break
# 创建带有元数据的用户消息
user_message_with_meta = BaseMessage.make_user_message(
role_name="User",
content=content,
meta_dict={
"user_preference": "初学者",
"language": "中文",
"learning_style": "理论与实践结合",
"favorite_topics": "机器学习,深度学习",
"reading_level": "入门级"
}
)
# 将消息传给ChatAgent
response = chat_agent.step(user_message_with_meta)
print("\n助手1(有元数据)的响应:")
print(response.msg.content)
# 再测试一个不带元数据的消息进行对比
print("\n" + "="*50)
user_message_without_meta = BaseMessage.make_user_message(
role_name="User",
content=content
# 不添加meta_dict
)
response2 = chat_agent.step(user_message_without_meta)
print("\n助手2(无元数据)的响应:")
print(response2.msg.content)
通过以上代码的执行分析,我能够得出有元数据的角色返回的内容是总结比较清晰到位的,没元数据的话,就像无头苍蝇,有点搭边乱输出的感觉:


有个问题,那么多次调用之后,内容能够衔接呢?(是否有相关的记忆)
答:由以下回答也可以看出“有元数据”的回答更加精确。

4.4 OpenAI与ChatAgent比较
Openai是直接的模型接口,是将用户的输入信息直接给到大模型去处理,其好处:
- 每次调用都是独立的,没有历史记录
- 性能更好,开销更小
- 需要自己处理消息格式转换
- 适合一次性请求或自定义对话管理
ChatAgent是CAMEL框架中封装好的模型接口,是将用户的输入信息封装成字典dirt去给大模型处理,其好处:
- 自动管理对话历史
- 每次交互都会保存在内存中
- 提供更丰富的功能(如工具调用)
- 适合复杂的多轮对话应用
- meta_dict 信息通过 to_dict() 方法传递给模型
5,Prompt Engineering
5.1 自带的CoT思维链
CAMEL 提供了一些便捷的工具来帮助用户使用 CoT。我们可以使用 TaskSpecifyAgent 创建一个特定任务Agent,它会自动调用带有 CoT 的模板。
from camel.agents import TaskSpecifyAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType, TaskType
import os
from dotenv import load_dotenv
load_dotenv()
# 使用正确的环境变量名称
api_key = os.getenv('DEEPSEEK_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="deepseek-chat", # DeepSeek模型类型
url='https://api.deepseek.com/v1/', # DeepSeek API地址
api_key=api_key
)
task_specify_agent = TaskSpecifyAgent(
model=model, task_type=TaskType.AI_SOCIETY, output_language='中文'
)
specified_task_prompt = task_specify_agent.run(
task_prompt="教加法运算",
meta_dict=dict(
student_level="小学生",
learning_focus="1到10以内的基本加法"
)
)
print(specified_task_prompt)运行结果:

5.2 自定义CoT思维链
CAMEL 还允许用户创建自己的 Prompt 模板,使得生成的 Prompt 更加符合用户的需求。我们可以编写自己的思维链提示模板,然后将它应用到 TaskSpecifyAgent 中。
from camel.agents import TaskSpecifyAgent
from camel.models import ModelFactory
from camel.prompts import TextPrompt
from camel.types import ModelPlatformType
import os
from dotenv import load_dotenv
load_dotenv()
# 使用正确的环境变量名称
api_key = os.getenv('DEEPSEEK_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="deepseek-chat", # DeepSeek模型类型
url='https://api.deepseek.com/v1/', # DeepSeek API地址
api_key=api_key
)
my_prompt_template = TextPrompt(
'''你是一位数学老师,正在教小学生加法运算。
这是一个数学任务:{task}
请通过以下步骤帮助我将这个任务具体化:
1. 首先,明确说明数学问题
2. 将解题过程分解为简单步骤(思维链方法)
3. 逐步演示如何进行加法运算
4. 给出最终答案
5. 提供简短易懂的解释,适合小学生理解
例如,如果任务是"教1+7",你应该具体说明:
- 问题:"我们来学习1加7等于多少"
- 步骤:"首先,我们数1个物品。然后,我们再数7个物品..."
- 计算:"1 + 7 = ?"
- 答案:"1 + 7 = 8"
- 解释:"当我们有1个东西,再得到7个东西时,把它们放在一起数一数,总共是8个!"
任务:{task}
学生水平:{student_level}
学习重点:{learning_focus}'''
)
task_specify_agent = TaskSpecifyAgent(
model=model, task_specify_prompt=my_prompt_template
)
response = task_specify_agent.run(
task_prompt="教加法运算",
meta_dict=dict(
student_level="小学生",
learning_focus="1到10以内的基本加法"
),
)
print("数学推理教学任务指定:")
print("=" * 40)
print(response)运行结果:
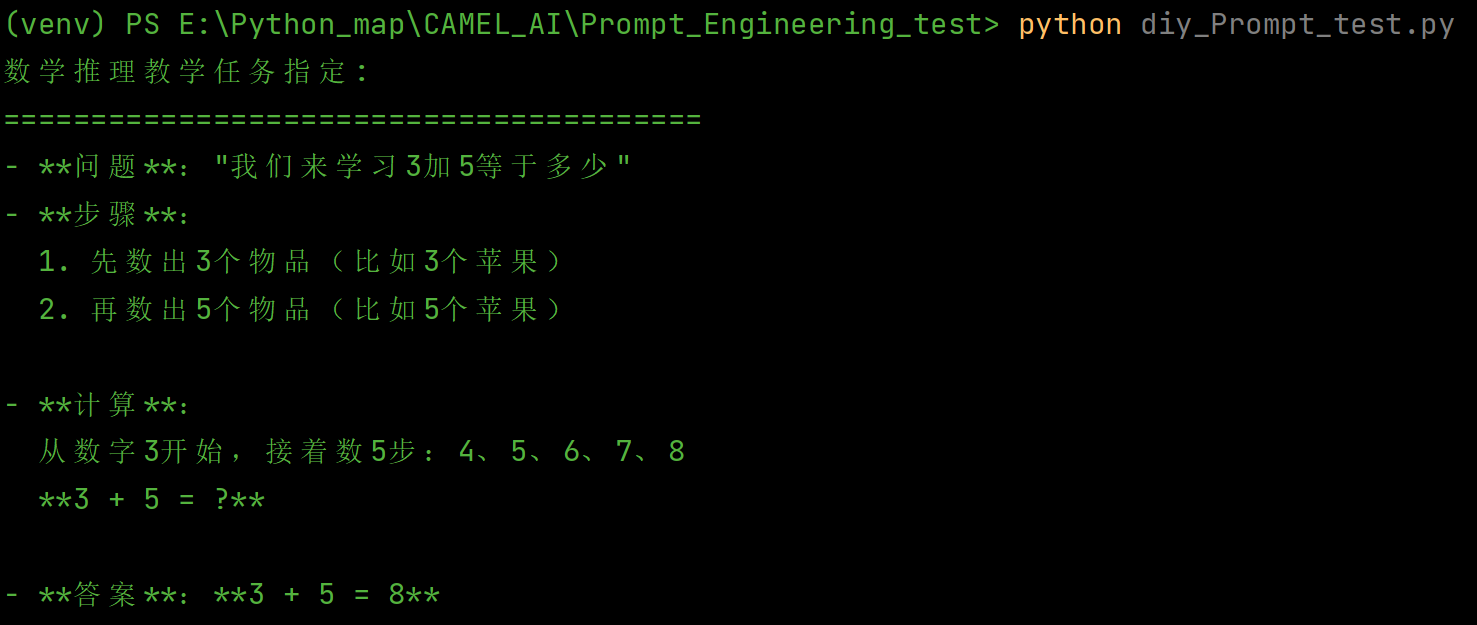
以上的结果对比,很明显地知道,diy前跟diy后之间的区别是很大的,diy的能够满足我们自己的需求。
5.3 Prompt自定义参数
可以通过内置的key_words是能够获取到提示词里面设置的参数,而format方法是能够替换里面的参数。
from camel.prompts import TextPrompt
prompt = TextPrompt('Please enter your name and age: {name}, {age}')
print(prompt.key_words)
>>>
{'name', 'age'}from camel.prompts import TextPrompt
prompt = TextPrompt('Your name and age are: {name}, {age}')
name = 'John'
partial_formatted_prompt = prompt.format(name=name)
print(partial_formatted_prompt)
>>> "Your name and age are: John, {age}"6,Memony
6.1 记忆的几个核心功能
- 信息储存:能够高效存储多种形式的数据,包括事实、事件、规则和上下文信息,以便在需要时快速访问。
- 信息检索:支持根据特定查询或上下文快速检索相关信息,帮助agent在需要时做出准确的判断。
- 记忆更新:能够根据新的信息和经验动态更新存储内容,以反映环境或任务的变化。
- 记忆管理:包括老化机制和优先级管理,确保较重要的信息能够长期保留,而不再需要的信息可以被有效清除,以优化存储资源的使用。
6.2 ChatHistoryBlock
聊天记忆块是一个基于键值KV去实现的。
- 使用键值存储后端(BaseKeyValueStorage)
- 支持窗口式检索
- 实现消息权重衰减机制
初始化参数
storage: 存储后端,默认使用InMemoryKeyValueStoragekeep_rate: 历史消息权重衰减率,默认 0.9 该模块主要实现了以下方法:retrieve():使用可选的窗口大小获取最近的聊天记录write_records():将新记录写入聊天记录clear():删除所有聊天消息
keep_rate概述
keep_rate是 CAMEL 记忆系统中用于控制历史消息权重衰减的重要参数。它主要用于调整历史消息在上下文中的重要性。
- 取值范围: [0,1]
- 默认值: 0.9
- 作用对象: 非system消息(system消息始终保持 score=1.0)
它的工作原理是在检索历史消息时:
- 最新消息的 score 初始值为 1.0
- 每往前一条消息,score 会乘以 keep_rate
- 最终每条消息的 score 值决定了其在上下文中的重要性
现在假设有5条历史消息,keep_rate=0.9:
|
消息位置 |
Score 计算 |
最终 Score |
|
最新消息 |
1.0 |
1.0 |
|
往前1条 |
1.0 * 0.9 |
0.9 |
|
往前2条 |
0.9 * 0.9 |
0.81 |
|
往前3条 |
0.81 * 0.9 |
0.729 |
|
往前4条 |
0.729 * 0.9 |
0.656 |
注意事项:
- score 不影响消息的存储,但它会在总token数超过限制时决定哪些消息在生成下文时应该被保留。
- system消息不受 score 影响,也就是说在生成下文的时候,system_msg会一直保留。
- keep_rate 与 window_size 可以配合使用来更好地控制上下文
- 过低的 keep_rate 可能导致有价值的历史信息被过度弱化
- 过高的 keep_rate 可能导致上下文过于冗长
6.3 VectorDBBlock
是一个基于向量数据库的语义记忆块实现
- 使用向量存储后端(
BaseVectorStorage) - 支持语义相似度检索
- 实现消息的向量化存储
初始化参数
storage:可选 BaseVectorStorage (默认:QdrantStorage)embedding:可选 BaseEmbedding(默认值:OpenAIEmbedding)
该模块主要实现了以下方法:
retrieve():根据关键字获取相似记录write_records():将新记录转换并写入矢量数据库clear():从向量数据库中删除所有记录
该模块的工作流程如下:
- 存储过程:
-
- 将消息内容转换为向量表示
- 生成唯一标识符(UUID)
- 将向量和原始消息存入向量数据库
- 检索过程:
-
- 将查询关键词转换为向量
- 在向量空间中搜索相似向量
- 返回相似度最高的记录
以下提供一个示例代码给你(自己模拟存储以及检索):
from camel.memories.blocks.vectordb_block import VectorDBBlock
from camel.memories.records import MemoryRecord
from camel.messages import BaseMessage
from camel.embeddings import SentenceTransformerEncoder
from camel.types import OpenAIBackendRole
def main():
# 创建嵌入模型编码器
embedding_encoder = SentenceTransformerEncoder(model_name="BAAI/bge-small-zh")
# 创建向量数据库块
vector_db_block = VectorDBBlock(embedding=embedding_encoder)
# 创建测试记录
records = [
MemoryRecord(
message=BaseMessage.make_user_message(role_name="user", content="今天天气真好!"),
role_at_backend=OpenAIBackendRole.USER),
MemoryRecord(
message=BaseMessage.make_user_message(role_name="user", content="你喜欢什么运动?"),
role_at_backend=OpenAIBackendRole.USER),
MemoryRecord(
message=BaseMessage.make_user_message(role_name="user", content="今天天气不错,我们去散步吧。"),
role_at_backend=OpenAIBackendRole.USER),
]
# 写入记录到向量数据库
vector_db_block.write_records(records)
# 使用关键词检索记录
retrieved_records = vector_db_block.retrieve(keyword="天气", limit=3)
# 打印检索结果
for record in retrieved_records:
print(f"消息: {record.memory_record.message.content}, 相似度: {record.score}")
if __name__ == "__main__":
main()
结果如下:

可以看出我们询问了关键词“天气”,跟之前的历史记录消息“今天天气真好!”是最相似度,所以完美地满足了我们的需求。
完整的使用Agent去调用向量模型的示例代码:
from camel.memories import (
LongtermAgentMemory,
MemoryRecord,
ScoreBasedContextCreator,
ChatHistoryBlock,
VectorDBBlock,
)
from camel.messages import BaseMessage
from camel.types import ModelType, OpenAIBackendRole, ModelPlatformType
from camel.utils import OpenAITokenCounter
from camel.embeddings import SentenceTransformerEncoder
from camel.agents import ChatAgent
from camel.models import ModelFactory
import os
from dotenv import load_dotenv
def main():
# 加载环境变量
load_dotenv()
# 设置默认API密钥以防止OpenAI兼容性错误
if not os.getenv('MODELSCOPE_SDK_TOKEN'):
# 使用一个虚拟的API密钥来满足OpenAI兼容客户端的要求
os.environ['MODELSCOPE_SDK_TOKEN'] = 'dummy-token-for-openai-compatibility'
# 1. 初始化内存系统
memory = LongtermAgentMemory(
context_creator=ScoreBasedContextCreator(
token_counter=OpenAITokenCounter(ModelType.GPT_4O_MINI),
token_limit=1024,
),
chat_history_block=ChatHistoryBlock(),
vector_db_block=VectorDBBlock(embedding=SentenceTransformerEncoder(model_name="BAAI/bge-m3")),
)
# 2. 创建记忆记录并写入内存
records = [
MemoryRecord(
message=BaseMessage.make_user_message(
role_name="User",
content="什么是CAMEL AI?"
),
role_at_backend=OpenAIBackendRole.USER,
),
MemoryRecord(
message=BaseMessage.make_assistant_message(
role_name="Agent",
content="CAMEL-AI是第一个LLM多智能体框架,并且是一个致力于寻找智能体 scaling law 的开源社区。"
),
role_at_backend=OpenAIBackendRole.ASSISTANT,
),
]
# 写入记忆
memory.write_records(records)
# 获取并打印上下文信息
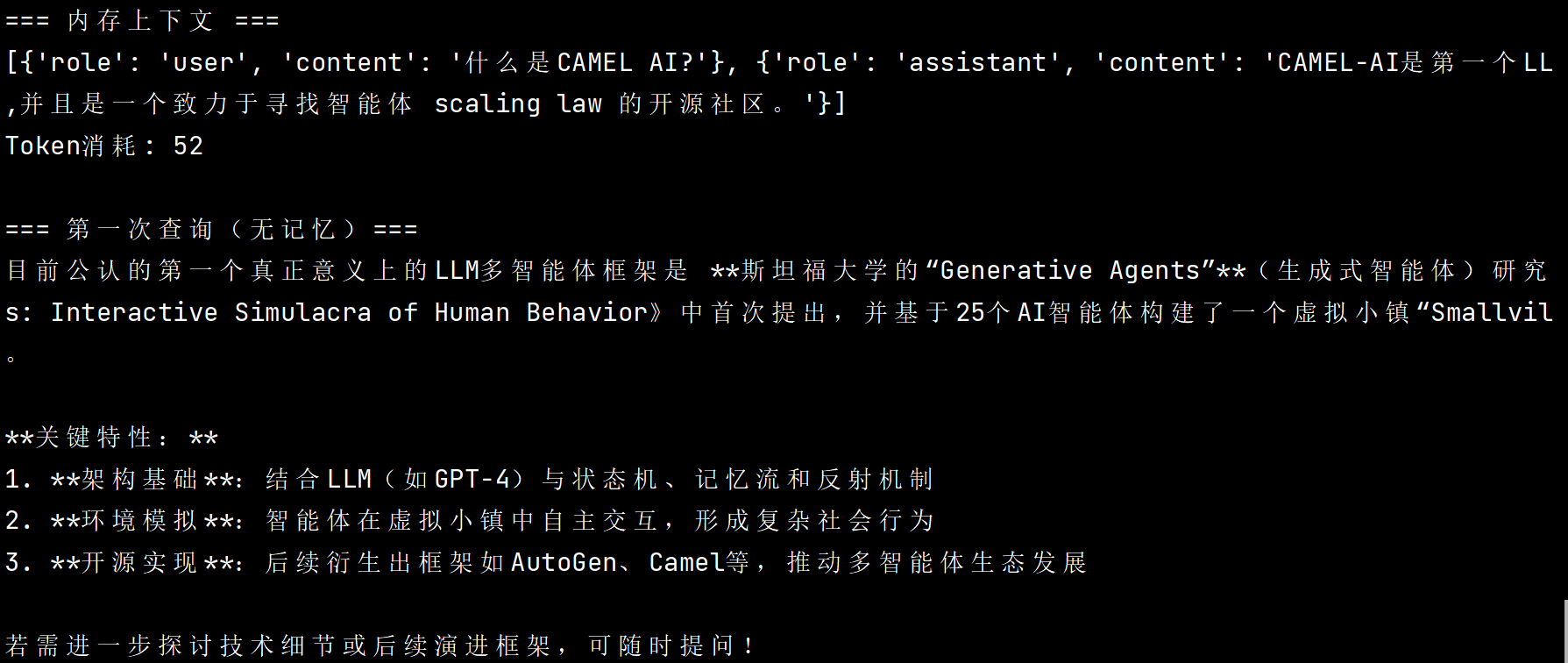
context, token_count = memory.get_context()
print("=== 内存上下文 ===")
print(context)
print(f'Token消耗: {token_count}\n')
# 3. 初始化ChatAgent
sys_msg = "你是一个好奇的智能体,正在探索宇宙的奥秘。"
api_key = os.getenv('DEEPSEEK_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="deepseek-chat", # DeepSeek模型类型
url='https://api.deepseek.com/v1/', # DeepSeek API地址
api_key=api_key
)
agent = ChatAgent(system_message=sys_msg, model=model)
# 4. 第一次查询(无记忆状态)
usr_msg = "告诉我基于我们讨论的内容,哪个是第一个LLM多智能体框架?"
print("=== 第一次查询(无记忆)===")
response = agent.step(usr_msg)
print(response.msgs[0].content)
print()
# 5. 将记忆系统赋给Agent并再次查询
print("=== 第二次查询(使用记忆)===")
agent.memory = memory
response = agent.step(usr_msg)
print(response.msgs[0].content)
if __name__ == "__main__":
main()结果如下:

7,Protocol
“协议”是用来设置标准化的沟通规则,统一交流规范,就跟人跟人之间交流一样,需要一定的沟通固定范式来交流,不然会乱套。
7.1 MCP协议(Model Context Protocol)
7.1.1 介绍
模型上下文协议,你可以把它理解成一个为AI模型(比如我们常说的LLM Agent)与外部数据源和工具进行互动而设计的标准化框架。
它们之间的沟通主要通过 JSON-RPC 2.0 进行。这是一种轻量级的远程过程调用协议,使用JSON这种通用的数据格式进行信息编码,从而确保了不同编程语言开发的系统之间也能相互理解。MCP的通信方式也很灵活,既可以通过计算机程序间标准的输入输出流(Stdio)进行,也可以通过网页中常用的HTTP协议配合服务器发送事件(SSE)技术来实现,以适应不同的部署场景和互动需求。
MCP定义了一套标准化的“原语”(可以理解为基本指令或构件)来进行上下文管理,这些原语分为服务器端和客户端两类:
- 服务器端原语:
-
- 提示 (Prompts): 预先定义好的一些指令或模板。AI客户端可以向服务器请求这些提示,以确保其行为的一致性。
- 资源 (Resources): 可以发送给AI模型的结构化数据或文档,它们通常带有描述信息(元数据),为AI提供必要的背景知识。
- 工具 (Tools): AI可以调用的可执行功能,用来执行某些操作或获取特定信息。每个工具都会清晰地定义其名称、用途描述、需要哪些输入参数以及会返回什么类型的结果。
- 客户端原语:
-
- 根 (Roots): 允许服务器访问客户端特定数据区域的入口点,主要用于设定权限边界,明确服务器可以访问哪些信息。
- 采样 (Sampling): MCP服务器请求AI模型生成一段续写或补全内容的机制。这使得服务器能够利用AI模型的推理能力来完成某些任务。
MCP的“一生”有三个阶段:
初始化阶段:确保版本兼容,各种功能的定义等等,当客户端能够接收到服务器的信息同意初始化的响应之后,会发一个“我准备好了”的通知,标志着双方可以进行业务沟通了。
操作阶段:核心的活动阶段,合作双方通过JSON-RPC格式去调用相应的信息,用户在调用服务器的某个功能时,若未响应时间超时了,用户可以发送个取消操作等。
关闭阶段:保证会话干净利落地结束。
7.1.2 实践
pip install "camel-ai[all]==0.2.71a9"Camel的MCP协议实现原理:
camel.toolkits.mcp_toolkit.MCPToolkit 为 CAMEL 框架提供了“一站式”接入多个 MCP Server 的能力:
- 支持 本地 STDIO 进程、Streamable-HTTP、SSE 传输方式
- 自动探测服务器类型,统一包装为 CAMEL 的 FunctionTool
- 用 AsyncExitStack 统一管理多条连接生命周期
整体的流程:
- Toolkit 初始化:应用端创建 MCPToolkit,传入配置文件,根据配置文件,对每一个MCP Server都生成一个Client
- 连接阶段
-
- Toolkit 使用 AsyncExitStack 顺序进入每个 MCPClient 的 async-context
- MCPClient 根据 ServerConfig 自动选择传输层并建立 ClientSession
- 建链后立即调用 list_tools,缓存工具元数据
- 工具聚合:MCPToolkit.get_tools() 遍历所有 Client,收集并严格化 schema
- 工具调用:call_tool() 根据名称找到对应 Client 并把请求透传到 Server
- 断开连接:Toolkit 退出时,AsyncExitStack 负责依次关闭所有 Client 及底层 transport
配置MCP的json文件:
{
"mcpServers": {
"time": { // 服务端标识名
"command": "uvx", // 启动服务器的命令
"args": ["mcp-server-time", "--local-timezone=Asia/Riyadh"] // 命令参数
}
}
}import asyncio
import sys
import os
import datetime
from dotenv import load_dotenv
# 添加项目根目录到Python路径
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..'))
from camel.toolkits.mcp_toolkit import MCPToolkit
from camel.agents import ChatAgent
# 修改导入语句,从正确的模块导入
from camel.models import ModelFactory
from camel.types import ModelPlatformType
load_dotenv()
# 使用正确的环境变量名称
api_key = os.getenv('DEEPSEEK_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="deepseek-chat", # DeepSeek模型类型
url='https://api.deepseek.com/v1/', # DeepSeek API地址
api_key=api_key
)
async def run_mcp_client_example():
print("Initializing MCP toolkit...")
# 1. 初始化 MCPToolkit,指定配置文件路径
mcp_toolkit = None
tools = []
# 尝试连接MCP服务器,如果失败则继续执行
try:
# 检查配置文件是否存在 (使用绝对路径)
config_path = os.path.join(os.path.dirname(__file__), "mcp_servers_config.json")
print(f"Looking for config file at: {config_path}")
if os.path.exists(config_path):
mcp_toolkit = MCPToolkit(config_path=config_path)
# 2. 异步连接到配置文件中定义的所有 MCP 服务器
await mcp_toolkit.connect()
tools = mcp_toolkit.get_tools()
print(f"Successfully connected to MCP servers with {len(tools)} tools")
# 显示所有可用的工具
for i, tool in enumerate(tools):
print(f" Tool {i+1}: {tool.get_function_name()}")
else:
print(f"Config file not found: '{config_path}', continuing without MCP tools")
except Exception as e:
print(f"Warning: Failed to connect to MCP servers: {e}")
print("Continuing without MCP tools...")
mcp_toolkit = None
print("Creating chat agent...")
# 3. 创建 CAMEL Agent 实例,并将从 MCPToolkit 获取的工具列表传递给 Agent
camel_agent = ChatAgent(
model=model, # Agent 使用的语言模型
tools=[*tools], # 动态获取并解包 MCP 工具列表
)
print("Sending message to agent...")
# 4. Agent 执行任务,可能调用 MCP 工具
try:
# 更明确地请求使用 time 工具
response = await asyncio.wait_for(
camel_agent.astep("Please use the time tool to tell me what time it is right now in Asia/Riyadh timezone."),
timeout=30.0
)
print(f"Agent response: {response.msgs[0].content}")
if response.info and 'tool_calls' in response.info:
print(f"Tool calls: {response.info['tool_calls']}")
else:
print("No tool calls were made.")
except asyncio.TimeoutError:
print("Agent response timed out after 30 seconds")
except Exception as e:
print(f"Error getting agent response: {e}")
# 5. 任务完成后,断开与所有 MCP 服务器的连接
if mcp_toolkit:
await mcp_toolkit.disconnect()
print("Disconnected from MCP servers")
print("Example completed")
def get_current_time():
"""获取当前时间的函数"""
return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
if __name__ == "__main__":
# 如果您只是想获取当前时间,可以直接调用:
print(f"Current time: {get_current_time()}")
# 或者运行完整的MCP示例
asyncio.run(run_mcp_client_example())7.2 将Camel框架的智能体作为MCP服务
7.2.1 CAMEL代理
自定义脚本去暴露:
from camel.agents import ChatAgent
from camel.models import ModelFactory, ModelPlatformType
from camel.toolkits import FunctionTool, SearchToolkit # 假设 SearchToolkit 已定义
# 示例:定义不同功能的 Agent
chat_agent = ChatAgent(model=ModelFactory.create(model_platform=ModelPlatformType.OPENAI, model_type="gpt-3.5-turbo"))
chat_agent_description = "A general-purpose assistant."
reasoning_agent = ChatAgent(
model=ModelFactory.create(model_platform=ModelPlatformType.OPENAI, model_type="deepseek-chat"))
reasoning_agent_description = "A specialized assistant for logical reasoning."
# (后续步骤通常涉及一个服务脚本,例如 agent_mcp_server.py,
# 该脚本负责加载这些 Agent 定义,并以 MCP 服务器模式运行它们。)通过以上这个方式,Agent可以爆露出接口供外部人员使用。
7.2.2 CAMEL工具包(ToolKit)发布的MCP服务:
# arxiv_toolkit_mcp_server.py
import argparse
import sys
from camel.toolkits import ArxivToolkit # 确保 ArxivToolkit 已定义
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Run Arxiv Toolkit in MCP server mode.")
parser.add_argument("--mode", choices=["stdio", "sse"], default="stdio", help="MCP server communication mode.")
parser.add_argument("--timeout", type=float, default=None, help="Timeout for the MCP server.")
args = parser.parse_args()
toolkit = ArxivToolkit(timeout=args.timeout)
toolkit.run_mcp_server(mode=args.mode) # 启动 MCP 服务器7.2.3 自定义MCP服务
【待学习补充】
7.2.4 自定义工具【基础】:
未自定义工具的回答:

加入自定义工具:
# 定义时间函数
def search_time() -> str:
r"""查看当前时间。
Returns:
str: 当前的时间。
"""
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 用 FunctionTool 包装该函数
time_tool = FunctionTool(search_time)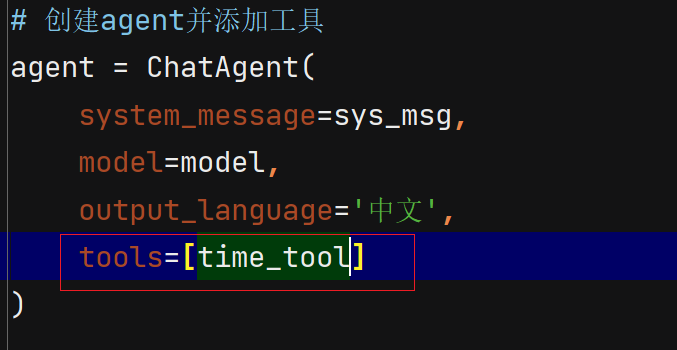
现在自定义完工具后的输出结果:
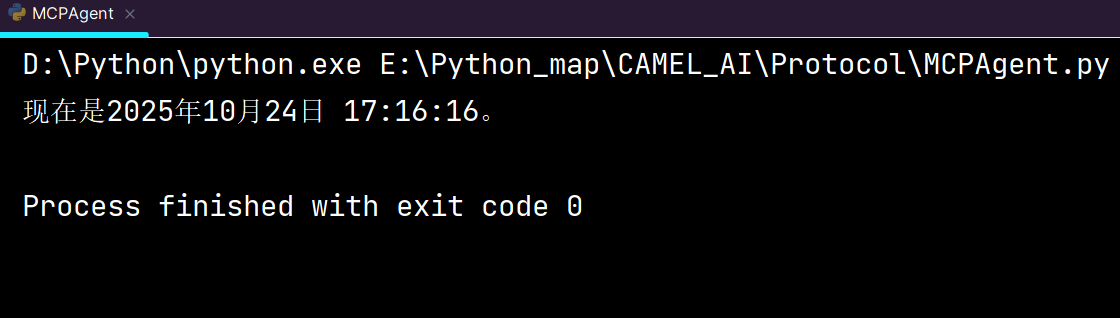
完整的代码:
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType
import os
from dotenv import load_dotenv
from camel.toolkits import FunctionTool
import time
# 定义时间函数
def search_time() -> str:
r"""查看当前时间。
Returns:
str: 当前的时间。
"""
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 用 FunctionTool 包装该函数
time_tool = FunctionTool(search_time)
load_dotenv()
# 定义系统消息
sys_msg = "You are a assistant."
# 初始化agent
load_dotenv()
# 使用正确的环境变量名称
api_key = os.getenv('DEEPSEEK_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="deepseek-chat", # DeepSeek模型类型
url='https://api.deepseek.com/v1/', # DeepSeek API地址
api_key=api_key
)
# 创建agent并添加工具
agent = ChatAgent(
system_message=sys_msg,
model=model,
output_language='中文',
tools=[time_tool]
)
usr_msg = "What time is it now?"
# 发送消息给agent
response = agent.step(usr_msg)
print(response.msgs[0].content)7.2.5 自定义工具【进阶】:
Browser Toolkit
Browser Toolkit是一种强大的搜索工具,其直接使用浏览器的特性为它带来了更高的上限,它几乎可以访问任何网页来为你搜寻相关的信息。
CAMEL 中的实现
混合自动化策略
传统的浏览器自动化工具通常只依赖于 DOM 元素定位,这在面对复杂的现代 Web 应用时存在局限性。
(附:DOM元素是指网页中所有 HTML 标签(以及文本、属性等)在内存中的 “对象化表示” —— 浏览器加载 HTML 页面时,会把整个文档解析成一棵 “DOM 树”,因为在前端界面中有层级结构的,如<div><p>我是盒子里的第二级结构</p></div>,树中的每一个 “节点”(Node),只要是对应 HTML 标签的部分,就是 DOM 元素。)
HybridBrowserToolkit 采用了"混合自动化"的创新理念:
- 结构化操作:基于 DOM 元素的精确定位和操作
- 视觉理解:通过 AI 模型分析页面截图,理解视觉布局
- 智能决策:结合两种方式的优势,提供更可靠的自动化方案
跨语言架构设计
工具包采用了多层架构设计,充分发挥不同编程语言的优势:
┌─────────────────────────────────────┐
│ Python 前端层 │
│ (HybridBrowserToolkit) │
│ - 工具注册和管理 │
│ - 配置管理 │
│ - Agent 集成 │
└─────────────┬───────────────────────┘
│ WebSocket 通信
┌─────────────▼───────────────────────┐
│ TypeScript 后端层 │
│ (WebSocket Server) │
│ - 浏览器引擎控制 │
│ - 页面操作执行 │
│ - 截图和快照生成 │
└─────────────┬───────────────────────┘
│ Playwright API
┌─────────────▼───────────────────────┐
│ 浏览器引擎 │
│ (Chromium/Firefox) │
└─────────────────────────────────────┘相关的进阶例子【重点】:
Brower Toolkit(浏览器工具包):
使用Agent通过CAMEL中的混合自动化策略去搜索浏览器中相关的问题:
import asyncio
import logging
import os
from dotenv import load_dotenv
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.toolkits import HybridBrowserToolkit
from camel.types import ModelPlatformType, ModelType
# Load environment variables
load_dotenv()
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(),
],
)
logging.getLogger('camel.agents').setLevel(logging.INFO)
logging.getLogger('camel.models').setLevel(logging.INFO)
logging.getLogger('camel.models').setLevel(logging.INFO)
logging.getLogger('camel.toolkits.hybrid_browser_toolkit').setLevel(
logging.DEBUG
)
USER_DATA_DIR = "User_Data"
model_backend = ModelFactory.create(
model_platform=ModelPlatformType.DEEPSEEK,
model_type=ModelType.DEEPSEEK_CHAT,
model_config_dict={"temperature": 0.0, "top_p": 1},
)
custom_tools = [
"browser_open",
"browser_close",
"browser_visit_page",
"browser_back",
"browser_forward",
"browser_click",
"browser_type",
"browser_switch_tab",
"browser_enter",
]
# Use python mode instead of typescript mode
web_toolkit_custom = HybridBrowserToolkit(
mode="python", # Use python mode
headless=False,
# user_data_dir=USER_DATA_DIR,
enabled_tools=custom_tools,
browser_log_to_file=True, # generate detailed log file in ./browser_log
stealth=True, # Using stealth mode during browser operation
# Remove viewport_limit as it's not supported in Python mode
default_start_url="https://www.baidu.com/", # Start with Baidu instead of Google
default_timeout=60000, # Increase timeout to 60 seconds
navigation_timeout=60000, # Increase navigation timeout
short_timeout=30000, # Increase short timeout
)
print(f"Custom tools: {web_toolkit_custom.enabled_tools}")
# Use the custom toolkit for the actual task
agent = ChatAgent(
model=model_backend,
tools=[*web_toolkit_custom.get_tools()],
toolkits_to_register_agent=[web_toolkit_custom],
max_iteration=15, # Increase max iterations
)
TASK_PROMPT = r"""
使用百度搜索广州城市理工学院的计算机工程学院黄英源的相关信息,告诉我黄英源有什么成就.
"""
async def main() -> None:
try:
response = await agent.astep(TASK_PROMPT)
print("Task:", TASK_PROMPT)
print(f"Using user data directory: {USER_DATA_DIR}")
print(f"Enabled tools: {web_toolkit_custom.enabled_tools}")
print("\nResponse from agent:")
print(response.msgs[0].content if response.msgs else "<no response>")
except Exception as e:
print(f"Error during execution: {e}")
import traceback
traceback.print_exc()
finally:
# Ensure browser is closed properly
print("\nClosing browser...")
try:
await web_toolkit_custom.browser_close()
except:
pass
print("Browser closed successfully.")
if __name__ == "__main__":
asyncio.run(main())(注:以上代码在使用的使用,遇到的问题:
HybridBrowserToolkit 的模式要从默认的 "typescript" 改为 "python";
依赖有点大,建议激活虚拟环境去开发;
超时时间短,需要改长;
默认Google的主页面为起始页面,大多数国内有限制,应该默认百度为起始页面;
)
Terminal Toolkit(终端工具包):
可以说,几乎所有任务都可以使用Terminal Toolkit来完成,因为Agent可以通过Terminal Toolkit来写代码、执行代码,所以Terminal Toolkit几乎无所不能。
7.2 A2A协议(Agent to Agent Protocol)
该协议是智能体与智能体之间的合作交流规范协议。
他们之间的互动遵循以下步骤:
- 客户端Agent向远程Agent请求
/.well-known/agent.json(代理名片)。 - 远程Agent返回代理名片。
- 客户端Agent进行身份验证后,通过HTTPS向远程Agent的
a2aEndpointUrl发送JSON-RPC请求(可区分tasks.send和tasks.sendSubscribe路径)。 - 远程Agent处理任务,并通过HTTP响应(
tasks.send)或SSE事件(tasks.sendSubscribe)返回任务状态和工件。 - (可选)如果需要输入,客户端Agent发送后续信息。
- 任务完成,最终结果通知客户端。
- (可选)远程Agent通过Webhook发送推送通知。 这个图可以突出HTTPS和JSON-RPC的使用。
总结三大步骤:
“发现”:用户发现有个 Agent Card的东西,是一份JSON格式元数据文件,声明了Agent的基本信息,技能、通信地址以及安全认证等等;
“发起”:客户端Agent根据“Agent名片”上声明的认证方法进行身份验证。成功后,它会通过HTTPS(一种安全的网页传输协议)向远程Agent的a2aEndpointUrl发送一个JSON-RPC请求。主要使用两种方法:
-
tasks.send: 用于那些可能同步完成的任务,或者不需要立即流式传输更新的任务。tasks.sendSubscribe: 用于那些需要长时间运行,并且需要通过服务器发送事件(SSE)在持久的HTTPS连接上持续发送更新的任务。
处理与交互:
- 对于非流式任务(即使用
tasks.send发起的任务),服务器处理完任务后,会在HTTP响应中返回最终的任务对象 (Task object)。 - 对于流式任务(即使用
tasks.sendSubscribe发起的任务),服务器会通过持久连接发送SSE消息。这些消息包括包含更新后任务对象的TaskStatusUpdateEvent,以及包含任务执行过程中生成的工件对象 (Artifact objects)(比如生成的文件或报告)的TaskArtifactUpdateEvent。
A2A的安全性考虑:
安全性是A2A协议设计的核心要素之一,旨在应对多Agent环境中可能出现的各种安全威胁,比如身份冒充、数据泄露、任务被篡改以及未经授权的权限提升等。协议通过以下机制来增强安全性:
- 基于HTTPS的通信: 所有的A2A通信,包括获取“Agent名片”和交换任务信息,都强制使用HTTPS协议。这确保了数据在传输过程中的加密和完整性,防止被窃听或篡改。
- 身份验证: A2A利用“Agent名片”明确声明其支持的身份验证方法,例如常用的OAuth 2.0/OpenID Connect (OIDC) 配合JSON Web Tokens (JWTs)。客户端Agent必须按照“Agent名片”中指定的要求成功进行身份验证后,才能与远程Agent进行交互。
- 签名机制:
-
- 签名的Agent名片 (Signed Agent Cards): 为了防止“Agent名片”被篡改或伪造,建议使用数字签名(例如通过受信任的证书颁发机构CA签发的证书)来确保其真实性和完整性。
- JSON Web Signatures (JWS): 可以用来保护消息内容和任务产物(工件)的完整性,确保它们在传输过程中没有被修改。
- 授权: 虽然协议本身可能不直接规定具体的授权逻辑(即判断一个通过身份验证的Agent是否有权限执行某个操作),但其设计支持基于身份的访问控制。远程Agent应该根据客户端Agent的身份和它所拥有的权限,来决定是否执行其请求的任务。
- 安全的通知渠道: 对于推送通知功能,需要对客户端提供的Webhook URL进行验证,以防止服务器端请求伪造(SSRF)这类常见的网络攻击。同时,建议对发送到Webhook的通知内容进行签名验证,以确保其来源可靠且内容未被篡改。
- 威胁建模与缓解: A2A的设计考虑了多种潜在的安全威胁,并鼓励开发者采用安全开发方法论和架构最佳实践来构建有弹性且有效的A2A系统。
7.3 ANP协议(Agent Network Protocol)
Agent网络协议(ANP)是一项旨在支持在一个开放的网络环境中,让AI Agent能够相互发现并安全协作的协议。
它的核心目标是创建一个开放、安全且高效的协作网络,连接海量的、来自不同提供商、结构也可能各不相同的AI Agent,形成一个所谓的“Agent互联网”(Internet of Agents)。ANP特别关注解决当前互联网主要为人类交互而优化,而非为自主AI Agent优化的局限性。它致力于满足AI Agent对低延迟通信、原生API接口以及去中心化身份验证的需求。通过标准化AI Agent之间的连接机制,ANP希望打破数据孤岛,确保AI能够访问到完整的上下文信息,从而促进更深层次的协作和集体智能的涌现。

7.4 总结Task1
1.角色扮演任务Agent:
使用 AISocietyPromptTemplateDict,创建一个角色扮演任务Agent。假设你想让 AI 扮演一个“健康顾问”,为一个“患者”提供饮食和锻炼建议。请用思维链方式分解整个建议过程,逐步提供健康方案。
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.prompts import TextPrompt, AISocietyPromptTemplateDict
from camel.types import ModelPlatformType, RoleType
import os
from dotenv import load_dotenv
load_dotenv()
# 使用正确的环境变量名称
api_key = os.getenv('DEEPSEEK_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="deepseek-chat", # DeepSeek模型类型
url='https://api.deepseek.com/v1/', # DeepSeek API地址
api_key=api_key
)
# 定义健康顾问角色的系统提示
health_advisor_prompt = TextPrompt("""
你是AI健康顾问,专注于为患者提供专业的饮食和锻炼建议。
你需要运用思维链推理方式,逐步分析患者的情况并提供个性化的健康方案。
思考过程应包括以下步骤:
1. 分析患者的基本信息和健康状况
2. 评估患者的饮食和运动习惯
3. 识别主要健康风险和改善机会
4. 制定具体的饮食建议
5. 制定个性化的锻炼计划
6. 提供实施建议和注意事项
请以专业、细致且富有同理心的方式提供建议。
在与患者对话时,请遵循以下规则:
- 主动询问患者的信息,以便更好地提供个性化建议
- 回答要具体、实用,避免空泛的建议
- 对于严重的健康问题,提醒患者咨询专业医生
- 保持耐心和鼓励的态度,帮助患者建立健康习惯
""")
# 使用AISocietyPromptTemplateDict获取标准模板
prompt_template_dict = AISocietyPromptTemplateDict()
# 创建健康顾问Agent赋予本身的信息
advisor_system_message = BaseMessage.make_assistant_message(
role_name="健康顾问",
content=health_advisor_prompt
)
# 创建健康顾问ChatAgent
health_advisor_agent = ChatAgent(
system_message=advisor_system_message,
model=model
)
print("AI健康顾问已就绪!")
print("=" * 40)
print("您好!我是您的AI健康顾问,我可以为您提供饮食和锻炼方面的专业建议。")
print("请告诉我您的基本情况,比如年龄、性别、身高、体重,以及您目前的健康状况和目标。")
print("输入'退出'或'结束'可以结束对话。")
print("=" * 40)
# 初始化对话
user_input = input("您: ")
while user_input.lower() not in ['退出', '结束', 'quit', 'exit']:
# 创建用户输入的信息
user_message = BaseMessage.make_user_message(
role_name="患者",
content=user_input
)
# 获取健康顾问的回复
advisor_response = health_advisor_agent.step(user_message)
# 检查是否有回复
if advisor_response.msgs:
advisor_message = advisor_response.msgs[0]
print(f"健康顾问: {advisor_message.content}")
else:
print("健康顾问: 抱歉,我没有理解您的问题。请重新描述一下。")
# 获取下一次用户输入
user_input = input("您: ")
print("感谢您使用AI健康顾问服务!祝您身体健康!")总结以上的步骤:
- 写上大模型的APIKey
- 写上agent_prompt的提示词信息
- 定义AI Agent的基本角色信息BaseMessage(role角色、context提示词等)
- 配置AI Agent的配置信息,ChatAgent(systemMessage基本角色信息、model模型等)
- 定义用户的基本角色信息
- 用户input信息
- step传输用户input信息并获取AI Agent的回复信息
- 循环进行交流对话
7.5 总结Task2
1.加入工具供Agent使用
- 创建一个自己的工具,结合CAMEL内置的其他工具,使用RolePlaying并让Agent帮你完成一个任务。
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.prompts import TextPrompt, AISocietyPromptTemplateDict
from camel.types import ModelPlatformType, RoleType
import os
from dotenv import load_dotenv
load_dotenv()
# 使用正确的环境变量名称
api_key = os.getenv('DEEPSEEK_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="deepseek-chat", # DeepSeek模型类型
url='https://api.deepseek.com/v1/', # DeepSeek API地址
api_key=api_key
)
# 定义健康顾问角色的系统提示
health_advisor_prompt = TextPrompt("""
你是AI健康顾问,专注于为患者提供专业的饮食和锻炼建议。
你需要运用思维链推理方式,逐步分析患者的情况并提供个性化的健康方案。
思考过程应包括以下步骤:
1. 分析患者的基本信息和健康状况
2. 评估患者的饮食和运动习惯
3. 识别主要健康风险和改善机会
4. 制定具体的饮食建议
5. 制定个性化的锻炼计划
6. 提供实施建议和注意事项
请以专业、细致且富有同理心的方式提供建议。
在与患者对话时,请遵循以下规则:
- 主动询问患者的信息,以便更好地提供个性化建议
- 回答要具体、实用,避免空泛的建议
- 对于严重的健康问题,提醒患者咨询专业医生
- 保持耐心和鼓励的态度,帮助患者建立健康习惯
当患者提供了身高和体重信息时,你应该使用BMI工具来计算患者的BMI指数,以便更准确地评估他们的健康状况。BMI计算方法如下:
- BMI = 体重(kg) / 身高(m)²
- 根据计算结果判断体重状况:
- BMI < 18.5: 偏瘦我的
- 18.5 <= BMI < 25: 正常
- 25 <= BMI < 30: 超重
- BMI >= 30: 肥胖
请根据BMI计算结果为患者提供更有针对性的建议。
""")
# 自定义BMI计算工具
def BMI(height: float, weight: float) -> str:
"""
计算BMI指数并返回体重状况
Args:
height (float): 身高(米)
weight (float): 体重(千克)
Returns:
str: 体重状况(偏瘦/正常/超重/肥胖)
"""
bmi = weight / (height ** 2)
if bmi < 18.5:
return f"BMI指数为{bmi:.1f},体重状况:偏瘦"
elif bmi < 25:
return f"BMI指数为{bmi:.1f},体重状况:正常"
elif bmi < 30:
return f"BMI指数为{bmi:.1f},体重状况:超重"
else:
return f"BMI指数为{bmi:.1f},体重状况:肥胖"
# 创建健康顾问Agent赋予本身的信息
advisor_system_message = BaseMessage.make_assistant_message(
role_name="健康顾问",
content=health_advisor_prompt
)
# 创建健康顾问ChatAgent
health_advisor_agent = ChatAgent(
system_message=advisor_system_message,
model=model,
tools=[BMI]
)
print("AI健康顾问已就绪!")
print("=" * 40)
print("您好!我是您的AI健康顾问,我可以为您提供饮食和锻炼方面的专业建议。")
print("请告诉我您的基本情况,比如年龄、性别、身高、体重,以及您目前的健康状况和目标。")
print("输入'退出'或'结束'可以结束对话。")
print("=" * 40)
# 初始化对话
user_input = input("您: ")
while user_input.lower() not in ['退出', '结束', 'quit', 'exit']:
# 创建用户输入的信息
user_message = BaseMessage.make_user_message(
role_name="患者",
content=user_input
)
# 获取健康顾问的回复
advisor_response = health_advisor_agent.step(user_message)
# 检查是否有回复
if advisor_response.msgs:
advisor_message = advisor_response.msgs[0]
print(f"健康顾问: {advisor_message.content}")
else:
print("健康顾问: 抱歉,我没有理解您的问题。请重新描述一下。")
# 获取下一次用户输入
user_input = input("您: ")
print("感谢您使用AI健康顾问服务!祝您身体健康!")任何问题欢迎随时留言或者邮箱联系:
yingyuanhuang6@gmail.com
欢迎学习交流

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)