DeepSpeed 分布式训练
DeepSpeed 是一个"魔法工具包",它能让你的小电脑训练超级大的AI模型。DeepSpeed 本质上是一个"内存魔术师":它能让小显卡训练大模型- 通过切分和共享它能让多张显卡协同工作- 像团队合作一样它能在内存不足时借用CPU- 像临时扩展工作台不用买昂贵的专业显卡也能玩大模型现有的硬件能发挥更大价值学习成本相对较低DeepSpeed 就像给你的小书房(GPU)配了一个智能书架系统(内存管
1. DeepSpeed 的简单比喻
1.1 想象一个超大图书馆
传统训练方式(没有 DeepSpeed):
-
你是一个图书管理员
-
要管理一个超大的百科全书(模型)
-
但你的桌子(GPU内存)太小,放不下整本书
-
所以你只能一页一页地看,效率很低
使用 DeepSpeed 后:
-
你有了一个智能助手团队(多个GPU)
-
每个助手只负责书的一部分章节
-
当需要时,助手们互相交流信息
-
这样就能同时处理整本大书
DeepSpeed 分布式训练详解
1. DeepSpeed 核心架构
1.1 DeepSpeed 整体架构图
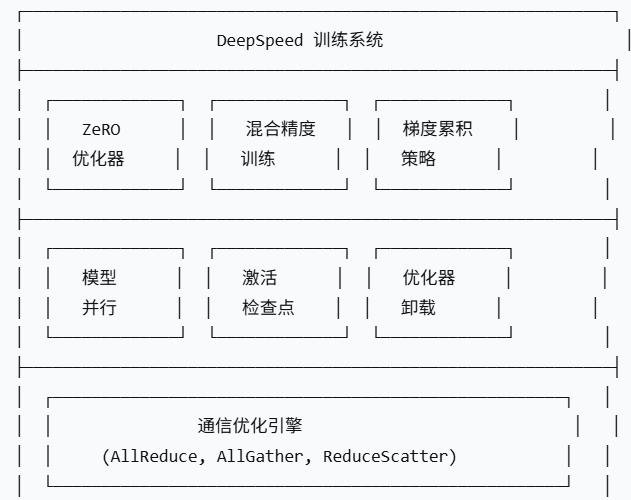
1.2 ZeRO (Zero Redundancy Optimizer) 核心技术
ZeRO 的三个阶段:
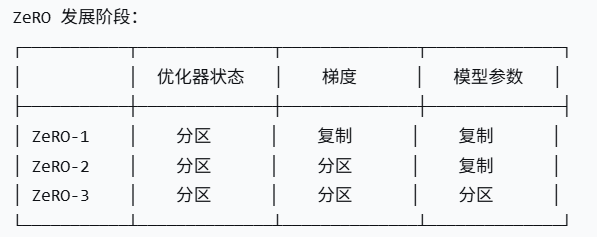
ZeRO 内存优化原理:
传统数据并行 vs ZeRO 数据并行 传统数据并行: 每个GPU都保存: [模型参数] + [优化器状态] + [梯度] + [激活值] ZeRO 数据并行: 每个GPU保存: [1/N 模型参数] + [1/N 优化器状态] + [1/N 梯度] + [激活值] 其中 N = GPU 数量
2. DeepSpeed 到底是什么?
2.1 一句话定义
DeepSpeed 是一个"魔法工具包",它能让你的小电脑训练超级大的AI模型。
2.2 核心问题:为什么需要 DeepSpeed?
问题:模型太大,单个GPU放不下
解决方案:DeepSpeed 把大模型"切碎",分给多个GPU
3. DeepSpeed 的三大魔法
3.1 第一个魔法:ZeRO(零冗余优化器)
传统方式的问题:
每个GPU都保存:
- 完整的模型副本 ✅
- 完整的优化器状态 ✅
- 完整的梯度 ✅
- 完整的激活值 ✅
→ 大量重复存储,浪费内存!
ZeRO 的解决方案:
text
每个GPU只保存: - 1/N 的模型参数 ✅ - 1/N 的优化器状态 ✅ - 1/N 的梯度 ✅ - 根据需要交换信息 🔄 → 几乎没有重复,极大节省内存!
3.2 第二个魔法:CPU Offload(内存借用)
工作原理:
当GPU内存不够时: 1. 把暂时不用的数据"借放"到CPU内存 2. 需要时再"拿回"到GPU 3. 就像你的书桌放不下时,把书暂时放到书架上
实际效果:
-
能用小显卡训练大模型
-
速度会慢一些(因为要来回搬运数据)
-
但至少能训练了!
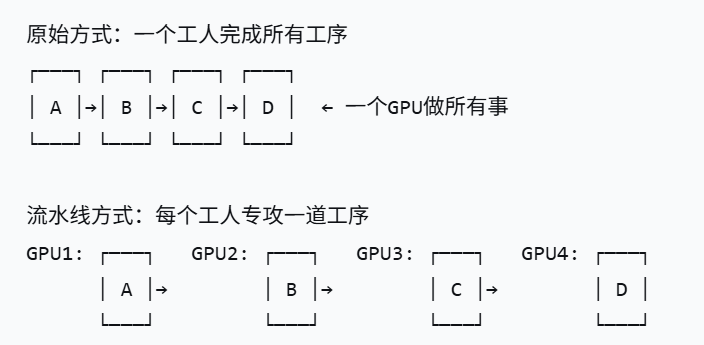
3.3 第三个魔法:Pipeline Parallelism(流水线并行)
就像工厂的流水线:
4. DeepSpeed 的实际效果演示
4.1 内存节省对比
让我们看一个具体的例子:
训练一个 70亿参数的模型:
# 没有 DeepSpeed 时
需要的GPU内存 = 70亿参数 × 4字节 × 4倍 ≈ 112 GB
# 这意味着你需要至少 4张 A100(每张40GB)显卡
# 使用 DeepSpeed ZeRO-3 + CPU Offload
需要的GPU内存 ≈ 70亿参数 × 4字节 ÷ 8张卡 ≈ 3.5 GB
# 这意味着用 8张 RTX 3090(每张24GB)就能轻松训练实际对比表:
| 训练方式 | 需要的显卡 | 成本 | 可行性 |
|---|---|---|---|
| 传统方式 | 4张 A100 | ~40万元 | 大公司才能负担 |
| DeepSpeed | 8张 RTX 3090 | ~10万元 | 中小公司可行 |
| DeepSpeed + CPU Offload | 4张 RTX 3090 | ~5万元 | 研究团队可行 |
4.2 使用 DeepSpeed 的简单例子(如何使用?)
# 不使用 DeepSpeed 的训练代码
import torch
# 假设我们有一个大模型
model = BigLanguageModel() # 这个模型太大,单个GPU放不下
optimizer = torch.optim.Adam(model.parameters())
# 这样训练会报错:CUDA out of memory
# 因为模型参数 + 优化器状态 + 梯度 > GPU内存怎么办呢?引入
# 使用 DeepSpeed 的训练代码
import deepspeed
# 同样的模型,但使用 DeepSpeed 初始化
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
config_params="ds_config.json" # 告诉 DeepSpeed 如何优化
)
# 现在可以正常训练了!
# DeepSpeed 自动把模型分到多个GPU,内存不够时借用CPU5. DeepSpeed 配置文件的通俗解释
// ds_config.json - 用大白话解释每个配置
{
"train_batch_size": 32, // 一次处理32个样本
"train_micro_batch_size_per_gpu": 4, // 每张GPU一次处理4个样本
"zero_optimization": {
"stage": 3, // 使用最强的内存优化(切得最碎)
"offload_optimizer": {
"device": "cpu", // 优化器状态放CPU
"pin_memory": true // 快速存取
},
"offload_param": {
"device": "cpu", // 模型参数也放CPU
"pin_memory": true
}
},
"fp16": {
"enabled": true, // 使用半精度,省一半内存
"loss_scale": 0 // 自动调整精度
}
}6. DeepSpeed 的适用场景
6.1 什么时候需要用 DeepSpeed?
肯定需要:
-
模型参数 > 10亿
-
单个GPU内存 < 24GB
-
想要训练得更快
可以考虑:
-
模型参数 > 1亿
-
有多个GPU但不知道怎么用
-
想要节省电费
不需要:
-
只是用小模型做推理
-
单个GPU就能搞定
-
不想增加学习成本
6.2 实际应用案例
案例1:大学生做研究
-
硬件:1张 RTX 3080(10GB)
-
目标:训练 30亿参数的模型
-
方案:DeepSpeed ZeRO-3 + CPU Offload
-
结果:能训练,但速度较慢
案例2:创业公司
-
硬件:4张 RTX 4090(24GB)
-
目标:训练 70亿参数的模型
-
方案:DeepSpeed ZeRO-2
-
结果:训练速度很快,成本可控
案例3:大公司
-
硬件:64张 A100(80GB)
-
目标:训练 700亿参数的模型
-
方案:DeepSpeed ZeRO-3 + 流水线并行
-
结果:几天就能训练完大模型
7. 学习 DeepSpeed 的路线图

# 最简单的 DeepSpeed 使用示例
from transformers import AutoModel
import deepspeed
# 1. 加载一个中等大小的模型
model = AutoModel.from_pretrained("bert-base-uncased")
# 2. 最简单的 DeepSpeed 配置
deepspeed_config = {
"train_batch_size": 16,
"zero_optimization": {
"stage": 1 # 最简单的优化级别
}
}
# 3. 初始化 DeepSpeed
model_engine, _, _, _ = deepspeed.initialize(
model=model,
config=deepspeed_config
)
print("恭喜!你已经成功使用 DeepSpeed 了!")总结
DeepSpeed 本质上是一个"内存魔术师":
-
它能让小显卡训练大模型 - 通过切分和共享
-
它能让多张显卡协同工作 - 像团队合作一样
-
它能在内存不足时借用CPU - 像临时扩展工作台
对于小白的核心价值:
-
不用买昂贵的专业显卡也能玩大模型
-
现有的硬件能发挥更大价值
-
学习成本相对较低
记住这个核心比喻:
DeepSpeed 就像给你的小书房(GPU)配了一个智能书架系统(内存管理),让你能在有限空间里阅读超大百科全书(训练大模型)。
现在您应该对 DeepSpeed 有了直观的理解。它不是什么神秘的黑科技,而是一套很实用的工具,让普通人也能接触和训练大模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)