《图解大模型:生成式AI原理与实战》摸鱼笔记
词袋模型的第一步是分词(tokenization),即将句子拆分成单个词或子词(词元,token),词袋模型旨在以数字形式创建文本的表示(representation),也称为向量或向量表示。在本书中,我们将这类模型称为表示模型(representation model)。缺点:忽略了文本的语义特性和含义。
上班就是要读书(
第一章 大语言模型简介
1."词袋"
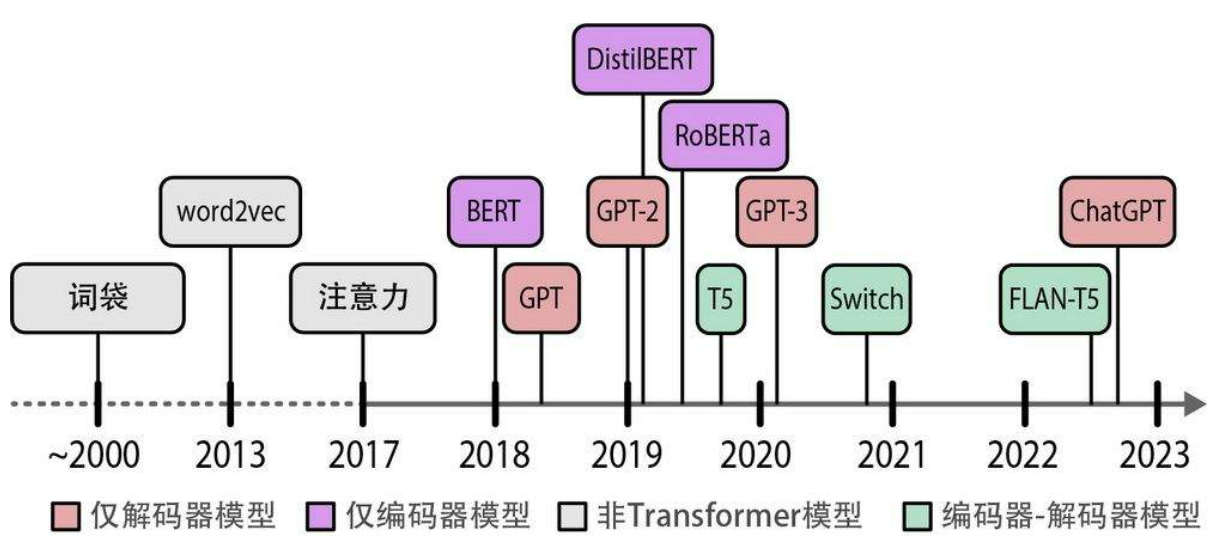
词袋模型的第一步是分词(tokenization),即将句子拆分成单个词或子词(词元,token),词袋模型旨在以数字形式创建文本的表示(representation),也称为向量或向量表示。在本书中,我们将这类模型称为表示模型(representation model)。

缺点:忽略了文本的语义特性和含义
2.word2vec(首次用embedding来捕捉文本的含义)
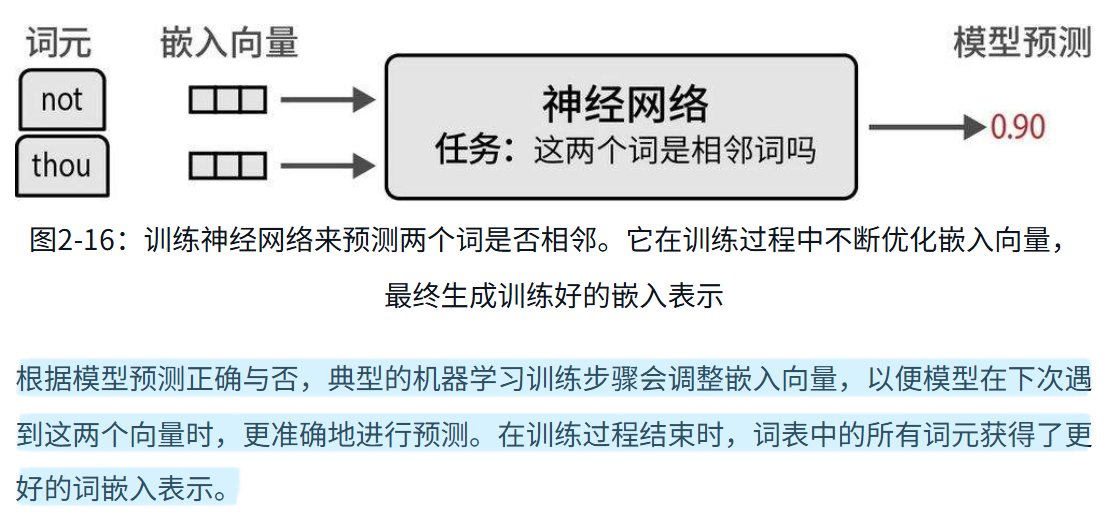
word2vec利用了神经网络(neural network)技术。利用这些神经网络,word2vec观察在给定句子中哪些词倾向于出现在其他词旁边,进而据此生成词嵌入。我们首先为词表中的每个词分配一个向量嵌入,比如说每个词有50个随机初始化的值。然后在每个训练步骤中,我们从训练数据中取出词对(pairs of words),用模型尝试预测它们是否可能在句子中相邻。

词嵌入非常有用,因为它使我们能够衡量两个词的语义相似度。使用各种距离度量方法,我们可以判断一个词与另一个词的接近程度。
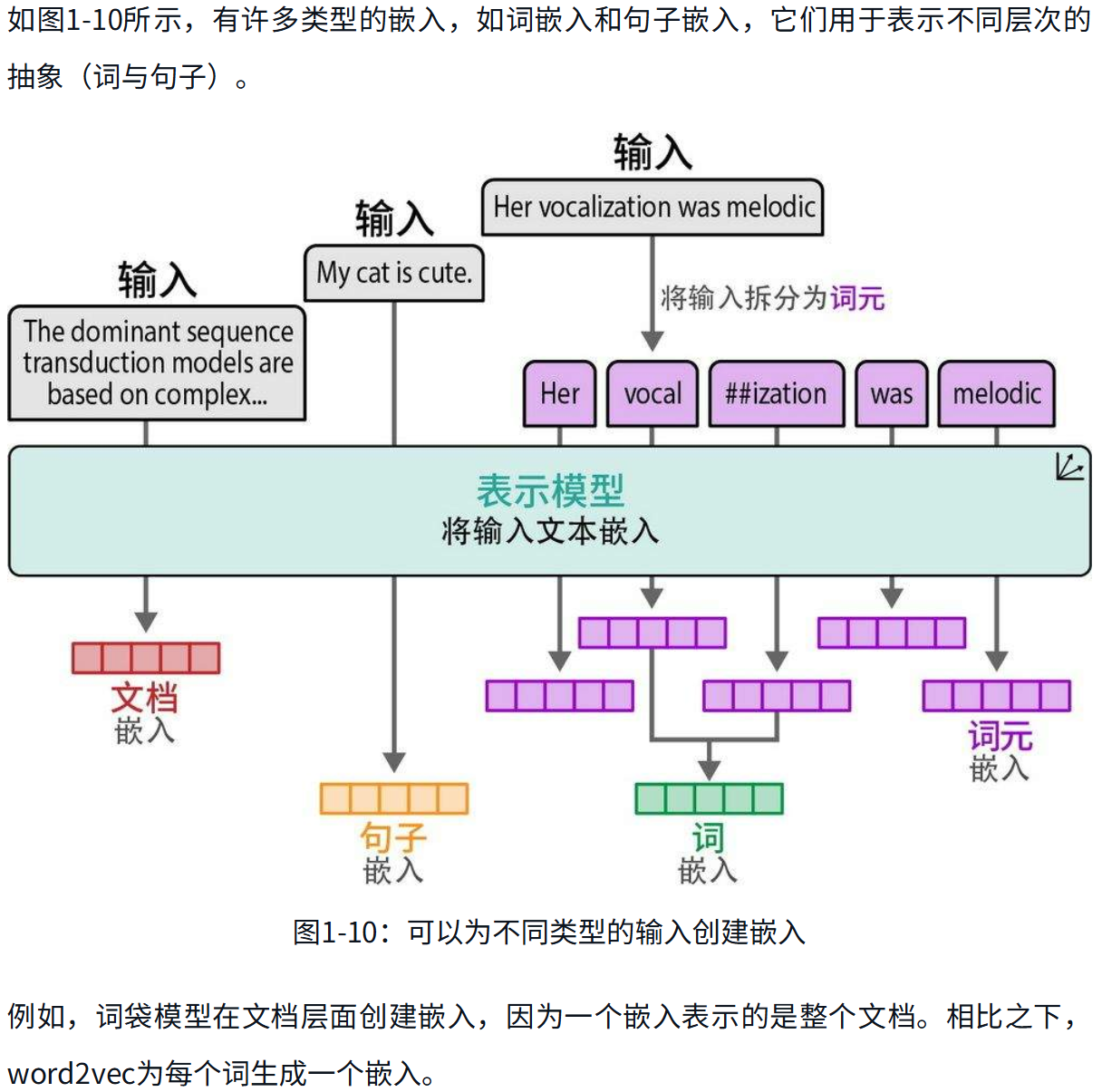
word2vec的训练过程会创建静态的、可下载的词表示。例如,bank这个词无论在什么上下文中使用,都会有相同的词嵌入。然而,bank既可以指银行,也可以指河岸。它的含义应该根据上下文而变化,因此它的嵌入也应该根据上下文而变化。
第二章 词元和嵌入
1.分词
词级分词的一个挑战是,分词器可能无法处理分词器训练完成之后才出现在数据集中的新词。这也导致词表中存在大量仅有细微差别的词元(如apology、apologize、apologetic、apologist)。这个问题可以通过子词级分词来解决,因为它有一个apolog词元,还有后缀词元(如-y、-ize、-etic、-ist),这些后缀词元与许多其他词元共用,从而形成更具表达能力的词表。
2. 特殊词元
[CLS] 和[SEP] 是用于包裹输入文本的功能性词元,各有其用途。[CLS] 代表分类(classification),因为它有时被用于句子分类。[SEP] 代表分隔符(separator),用于在某些需要向模型传递两个句子的应用中分隔句子(例如,在第8章中,我们将使用[SEP] 词元来分隔查询文本和候选结果)。
3. 分词方法
Bert基座模型是WordPiece;GPT基座模型是BPE;FLAN-T5是SentencePiece

4.空白字符有什么意义?
这类字符对于模型理解或生成代码非常重要。一个能够使用单个词元来表示连续四个空白字符的模型,更适合处理Python代码数据集。虽然模型也可以将其表示为四个不同的词元,但这会增加建模的难度,因为模型需要追踪缩进级别,这通常会导致性能下降。

5. word2vec算法与对比训练
嵌入向量是通过分类任务生成的。这种任务用于训练神经网络,以预测词是否经常出现在相同的上下文中(这里的上下文指的是我们建模的训练数据集中的多个句子)。我们可以将其理解为一个神经网络,它接收两个词作为输入,如果这两个词倾向于出现在相同的上下文中则输出1,否则输出0。



我们为每个词元创建一个嵌入向量并随机初始。在实践中,这是一个矩阵,其维度为:词表大小×嵌入向量的维度。
第三章 LLM内部机制
1. Transformer模型概述
语言建模头,它将Transformer块的输出转换为预测下一个词元的概率分数。
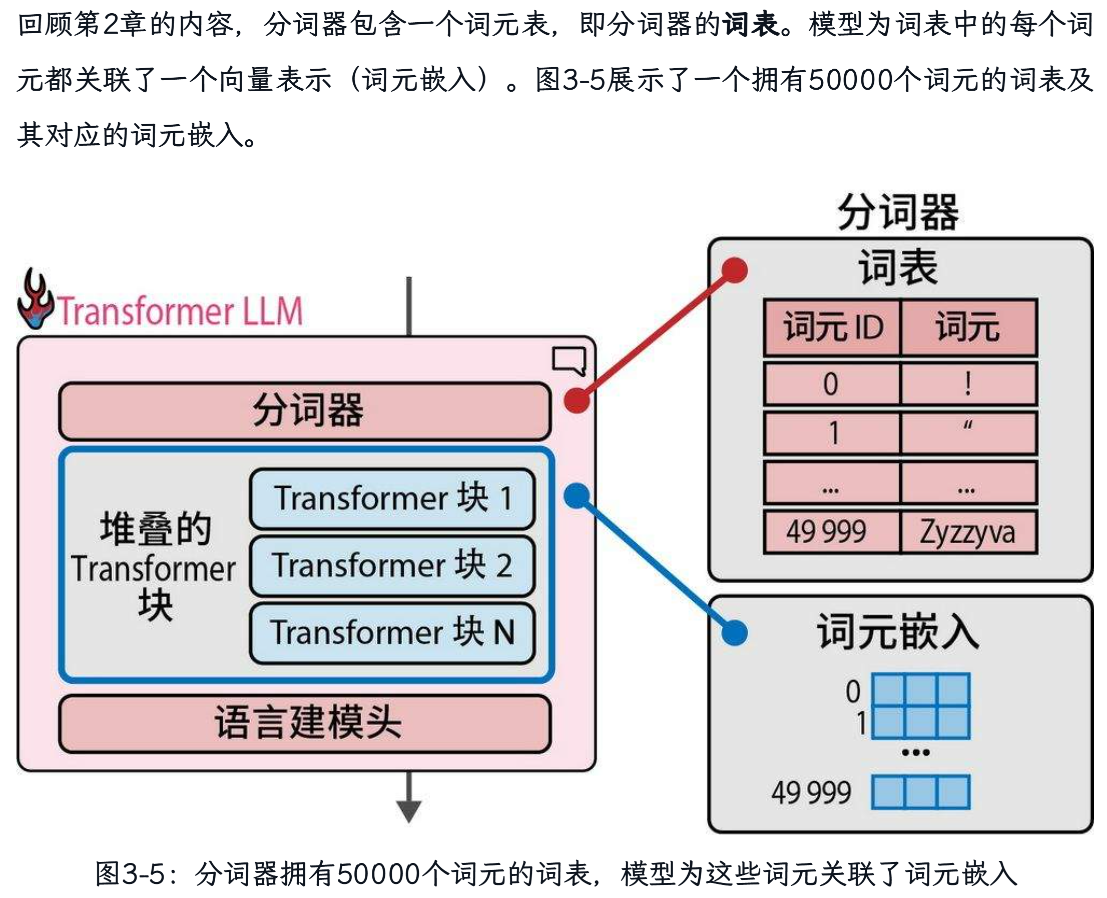

语言建模头本身是一个简单的神经网络层。它可以连接到堆叠的Transformer块上的多种可能的“头”之一,用于构建不同类型的系统。其他类型的Transformer头包括序列分类头和词元分类头。我们只需打印模型变量,就可以按顺序显示所有层。对于这个模型,我们得到:
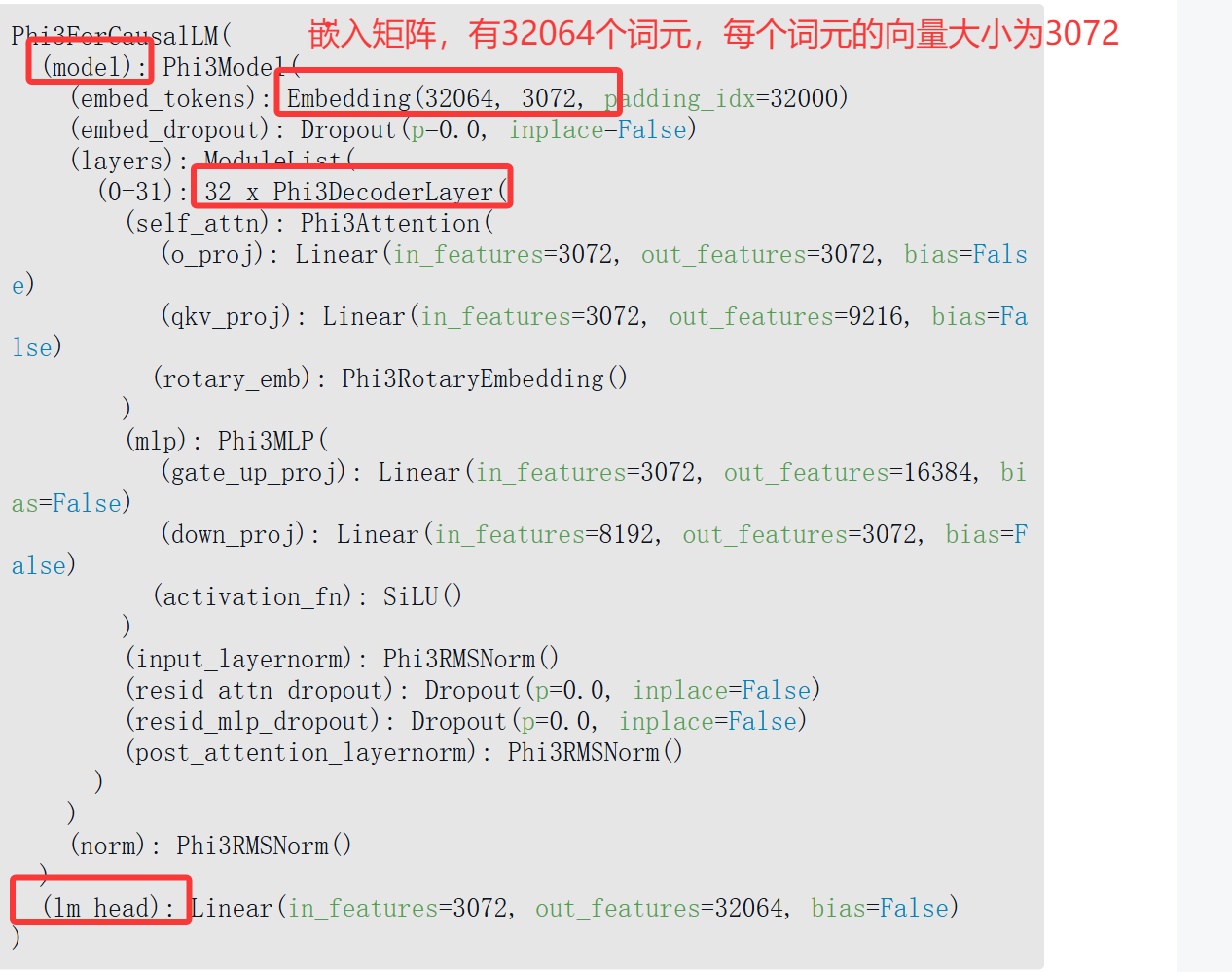
lm_head接收一个大小为3072的向量,并输出一个大小等于模型所知词元数量的向量。该输出是每个词元的概率分数,帮助我们选择输出词元。
2. 贪婪解码和采样
每次都选择概率分数最高的词元的策略被称为贪心解码。这就是在LLM中将温度(temperature)参数设为零时会发生的情况。
一个更好的方法是引入一些随机性,有时选择概率第二高或第三高的词元。用统计学家的话来说,这种思想就是根据概率分数对概率分布进行采样。对于图3-7中的例子来说,如果Dear作为下一个词元的概率为40%,那么它被选中的概率就是40%(而不是像贪心搜索那样,直接选择这个得分最高的词元)。这样,其他词元也有机会根据其分数被选中。
3.KV Cache
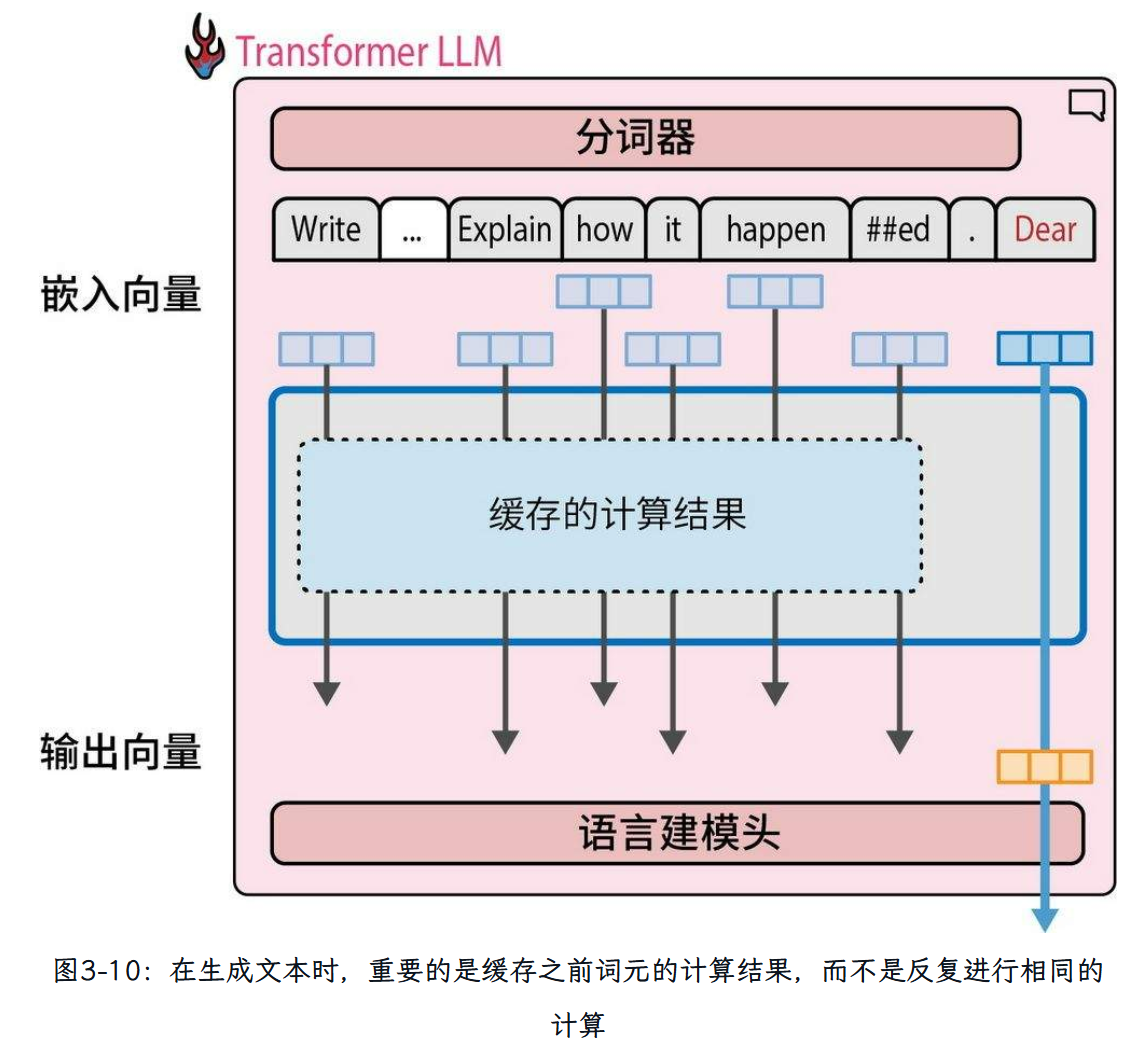
在生成第二个词元时,我们只是简单地将输出词元追加到输入的末尾,然后再次通过模型进行前向传播。如果模型能够缓存之前的计算结果(特别是注意力机制中的一些特定向量),就不需要重复计算之前的流,而只需要计算最后一条流了。这种优化技术被称为键-值(key-value,KV)缓存,它能显著加快生成过程。键和值是注意力机制的核心组件,我们将在本章后面详细介绍。如图3-10所示,在生成第二个词元时,由于我们缓存了之前流的结果,只有一条计算流是活跃的。
4. 注意力机制
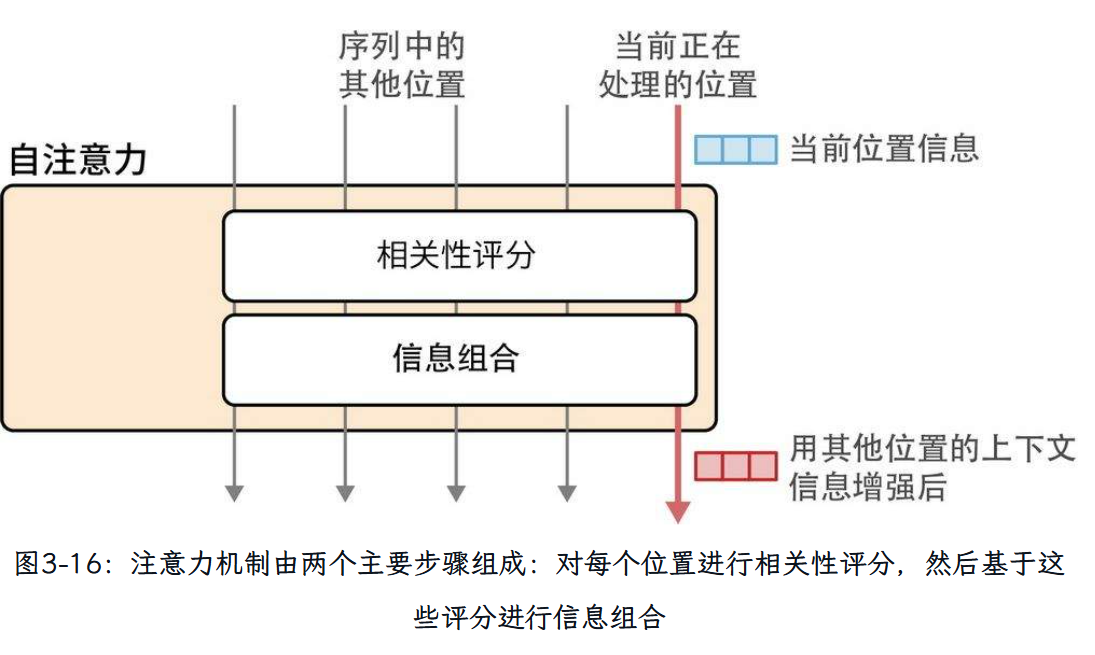
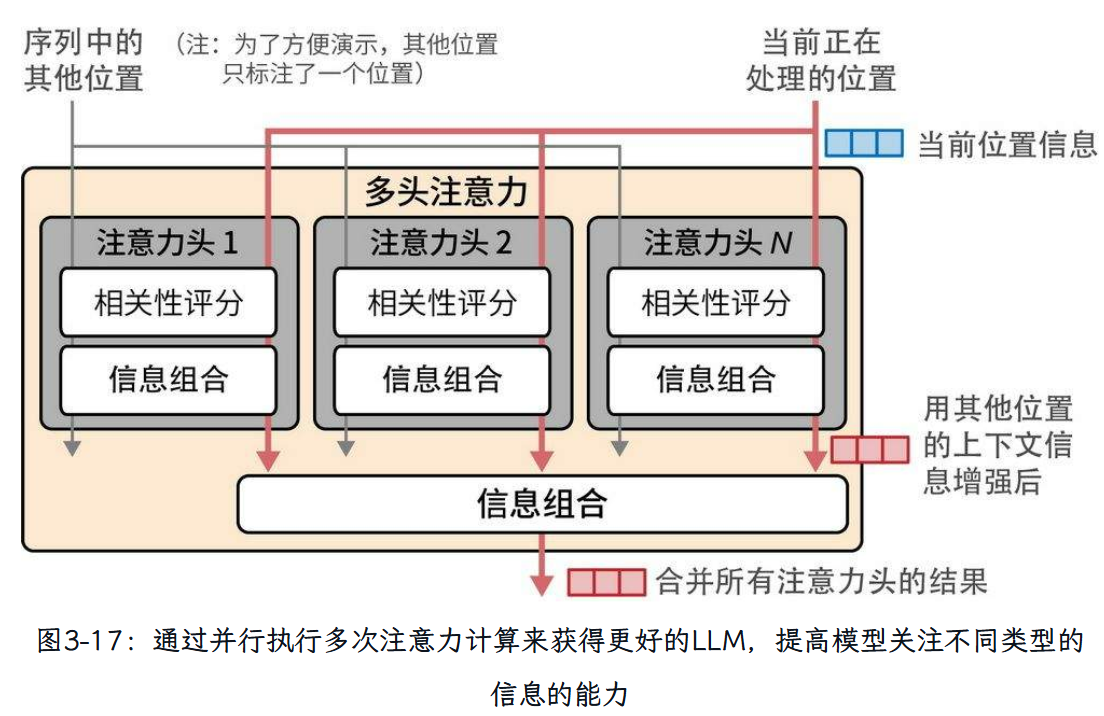
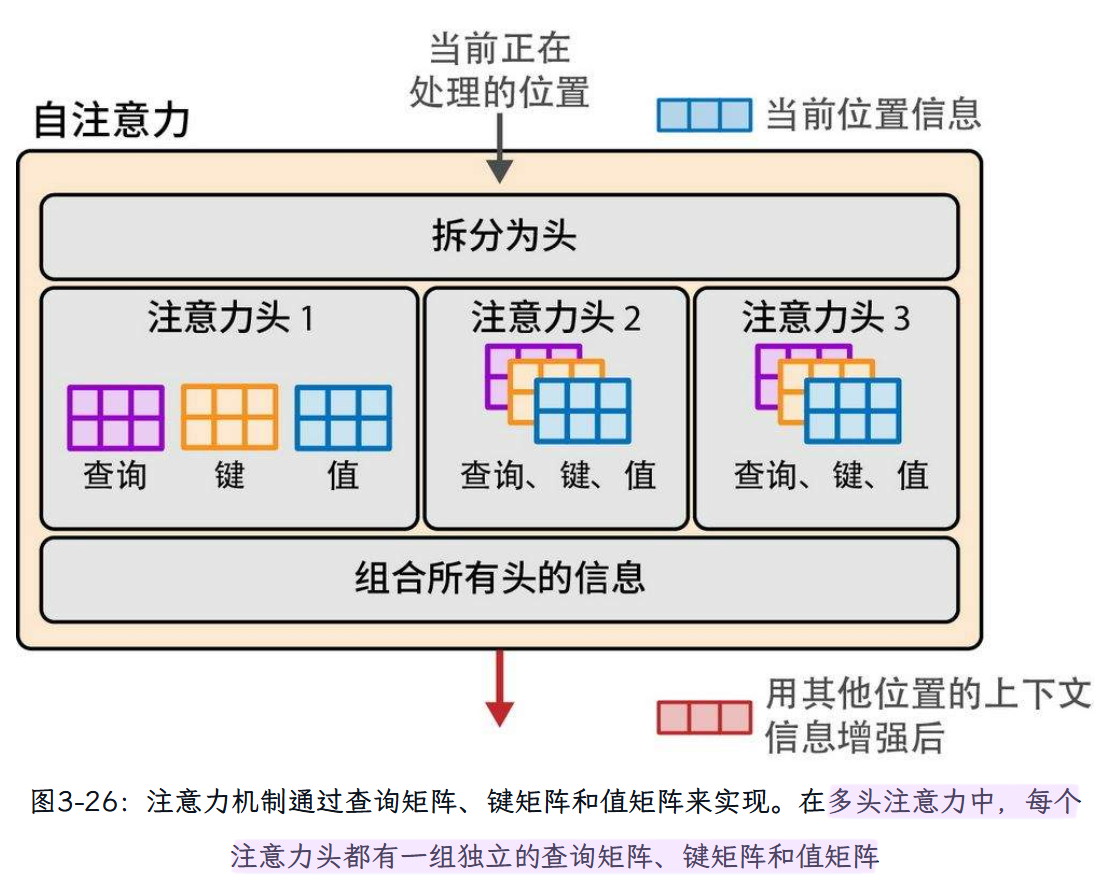
为了赋予Transformer更强大的注意力能力,注意力机制被复制多份,并行执行。这些并行的注意力执行过程被称为注意力头(attention head)。这提高了模型对输入序列中复杂模式的建模能力,使其能够同时关注不同的模式。
目标是为当前位置生成一个新的表示,其中包含来自前序词元的相关信息。例如,我们正在处理句子“Sarah fed the cat because it”(Sarah喂了猫,因为它)的最后一个位置,我们希望it表示那只猫,所以注意力机制会融入来自cat词元的“猫的信息”。
Step 1:相关性评分
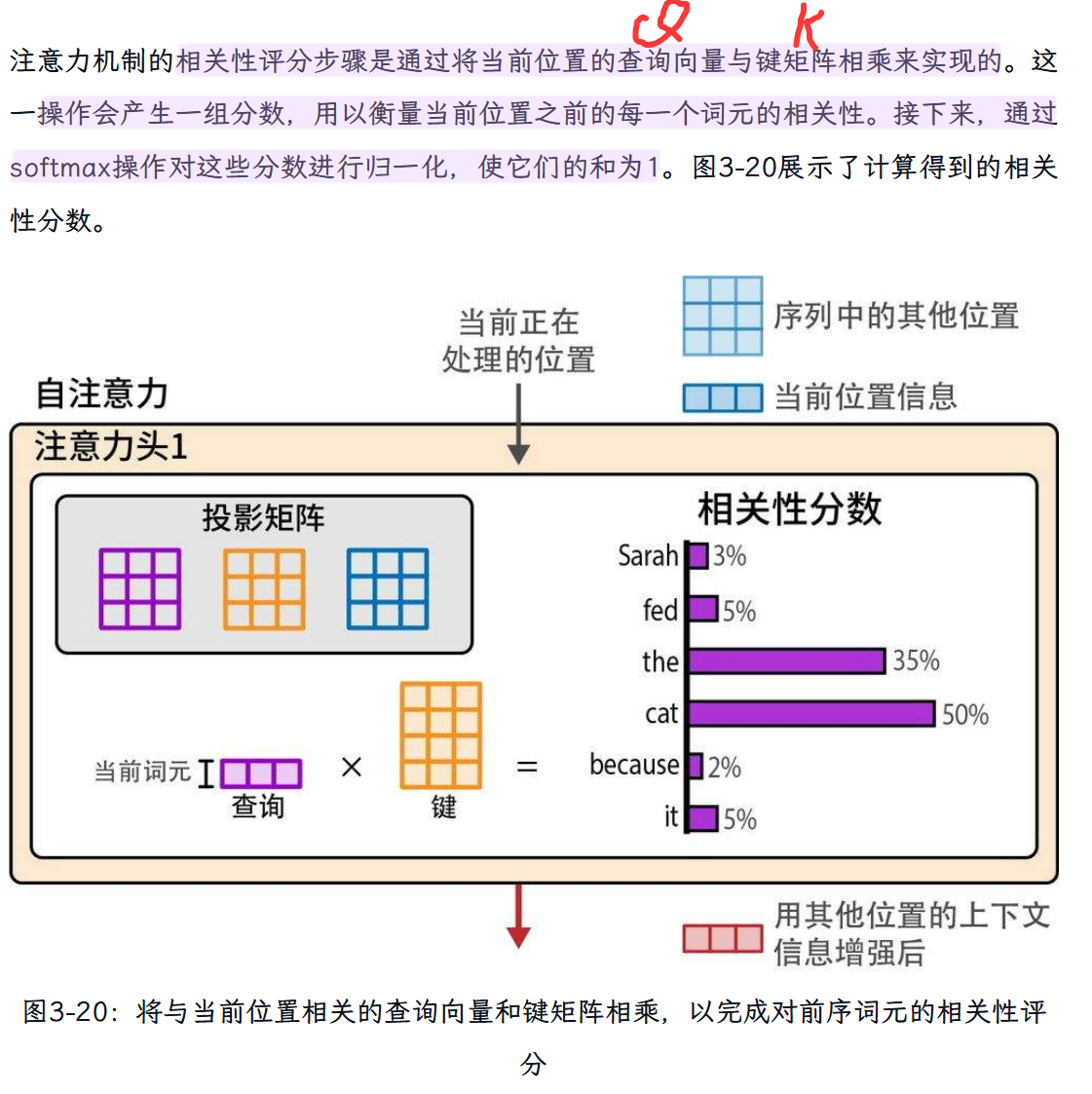
Step 2:信息组合
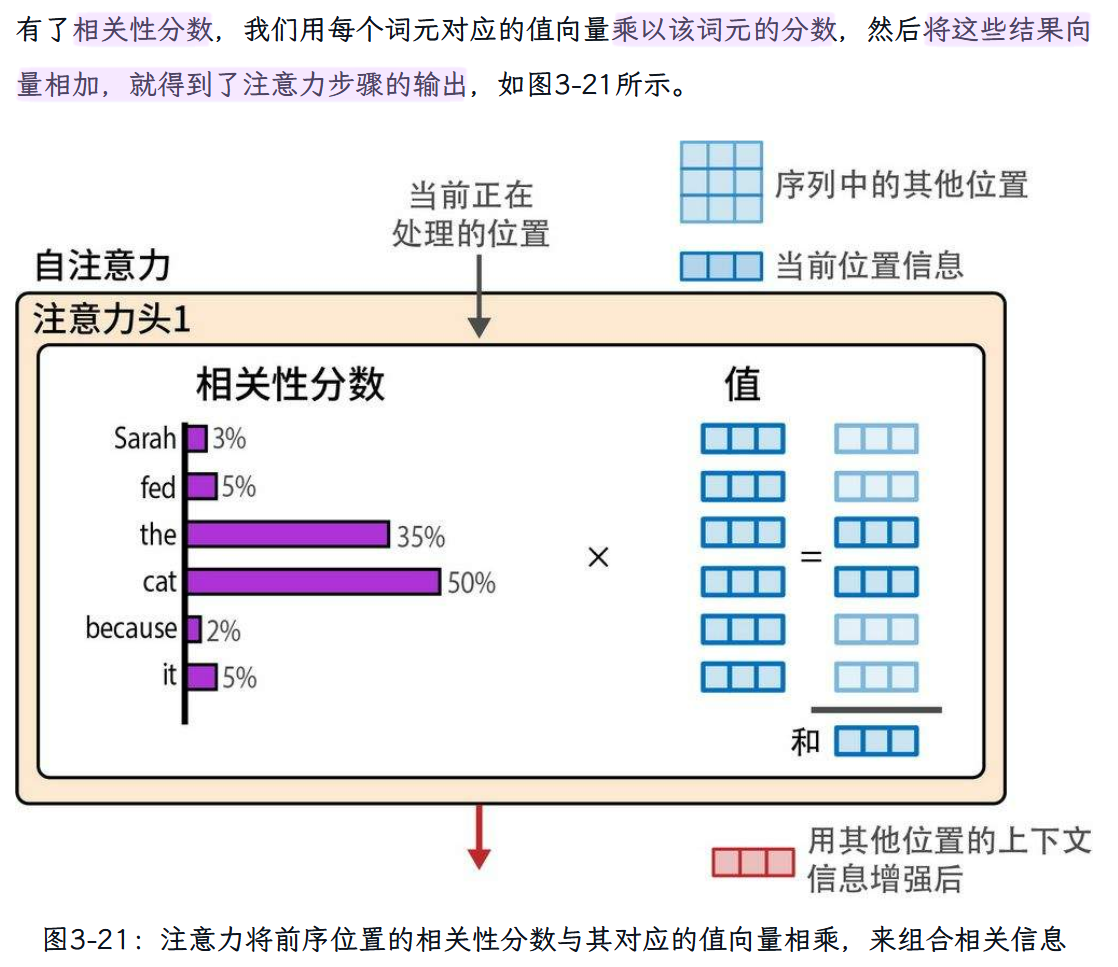
5. Transformer架构的最新改进
(1)更高效的注意力机制
“稀疏注意力机制”
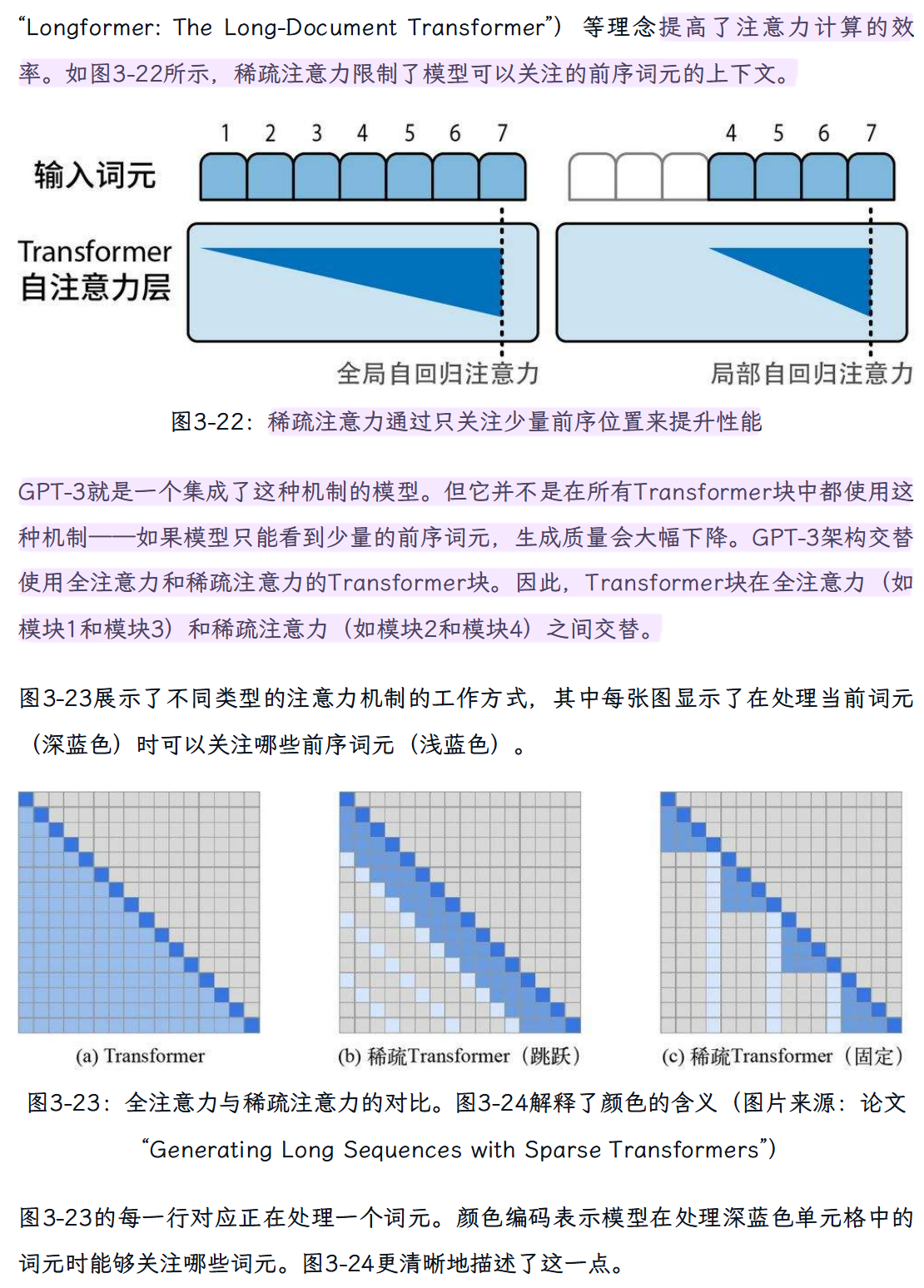
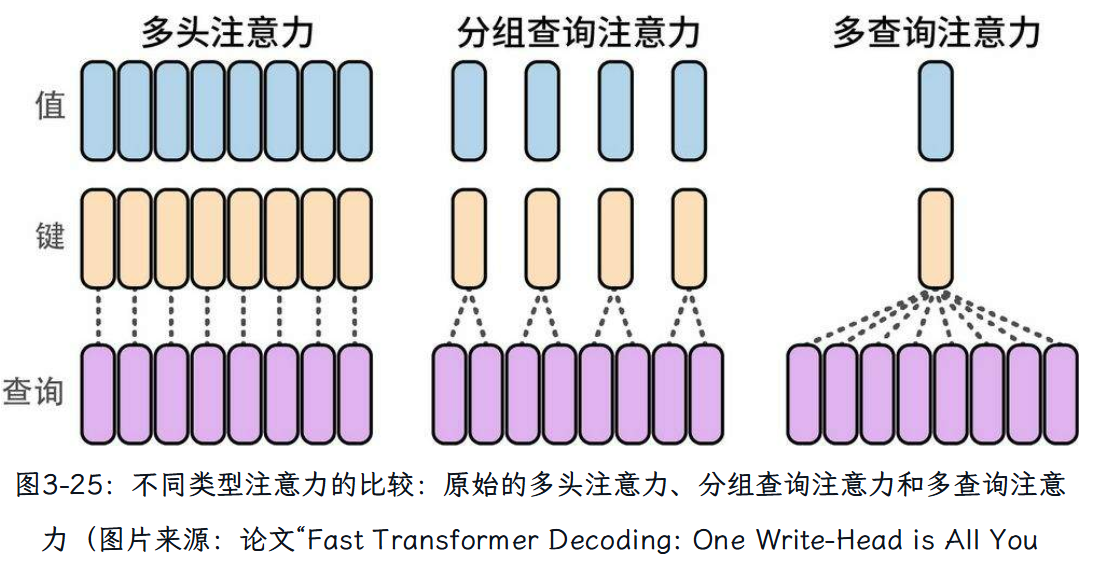
“多查询注意力”
方法通过减小涉及的矩阵的大小来提高大模型推理的可扩展性。
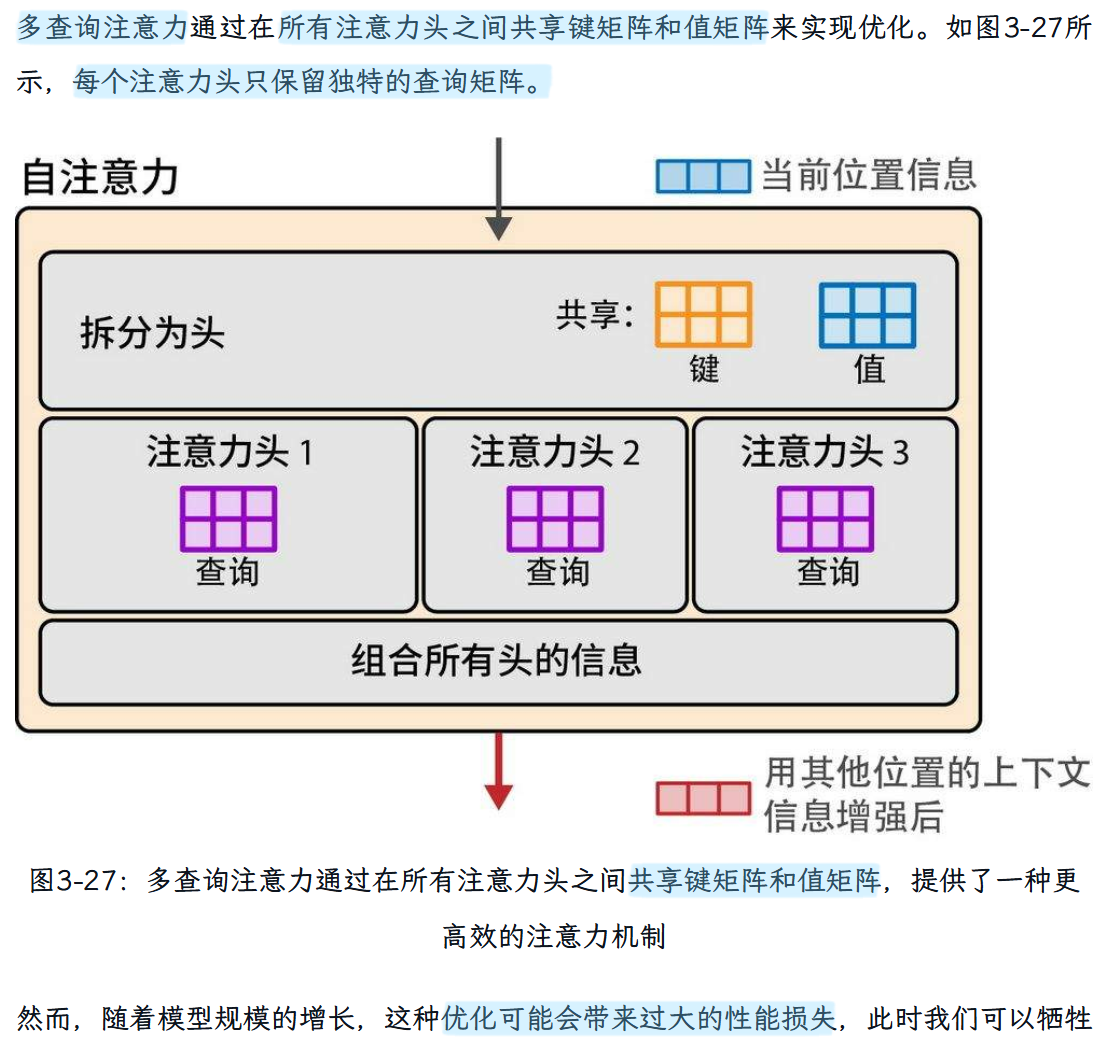
“分组查询注意力” GQA
算是介于多查询注意力和多头注意力机制之间的一种注意力方法。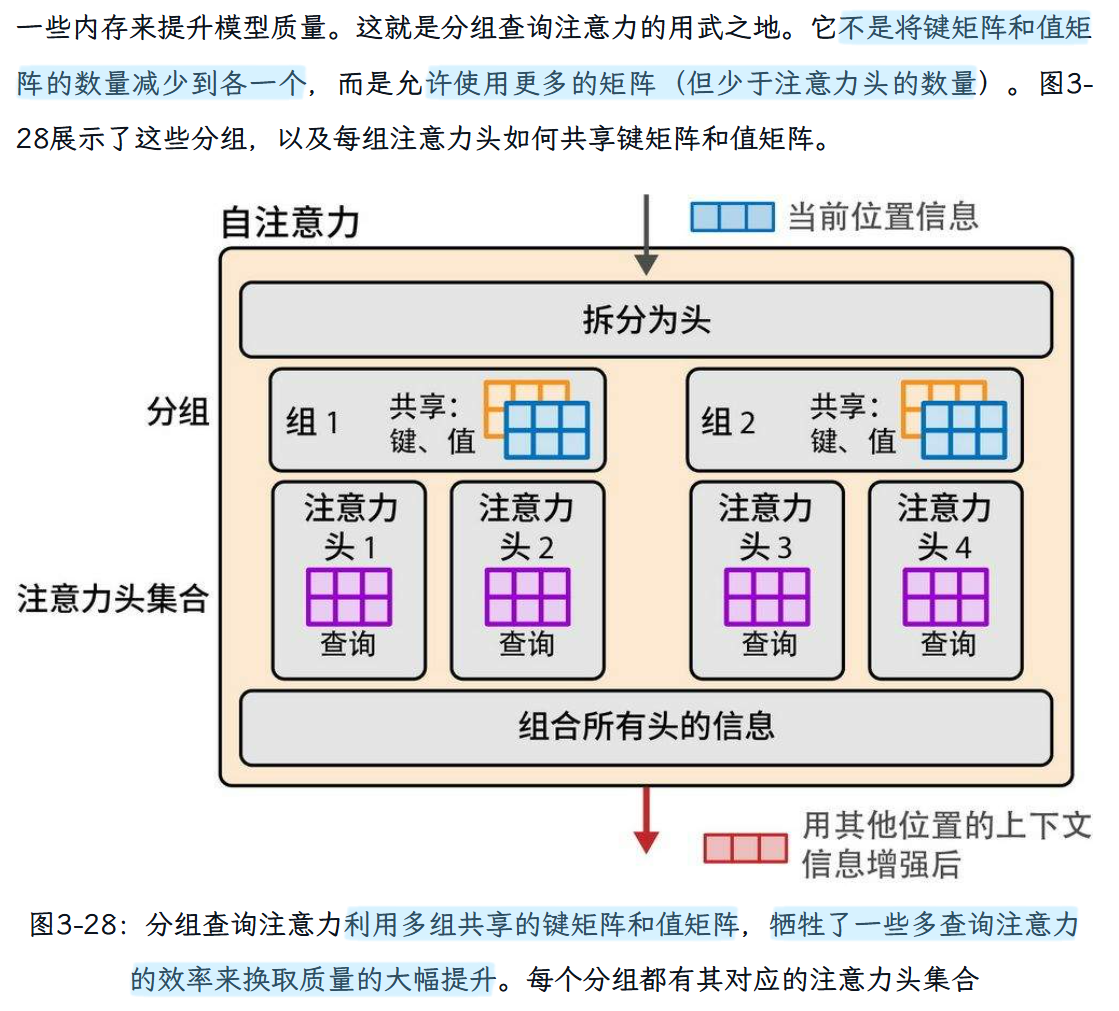
整体三种注意力机制的对比图如下:
“Flash Attention”
Flash Attention是一种广受欢迎的方法和实现,可以显著提升GPU上Transformer LLM的训练和推理速度。它通过优化GPU共享内存(GPU's shared memory,SRAM)和高带宽内存(high bandwidth memory,HBM)之间的数据加载和迁移来加速注意力计算。
相关论文:“FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”以及后续的“FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
(2)Transformer块的改进
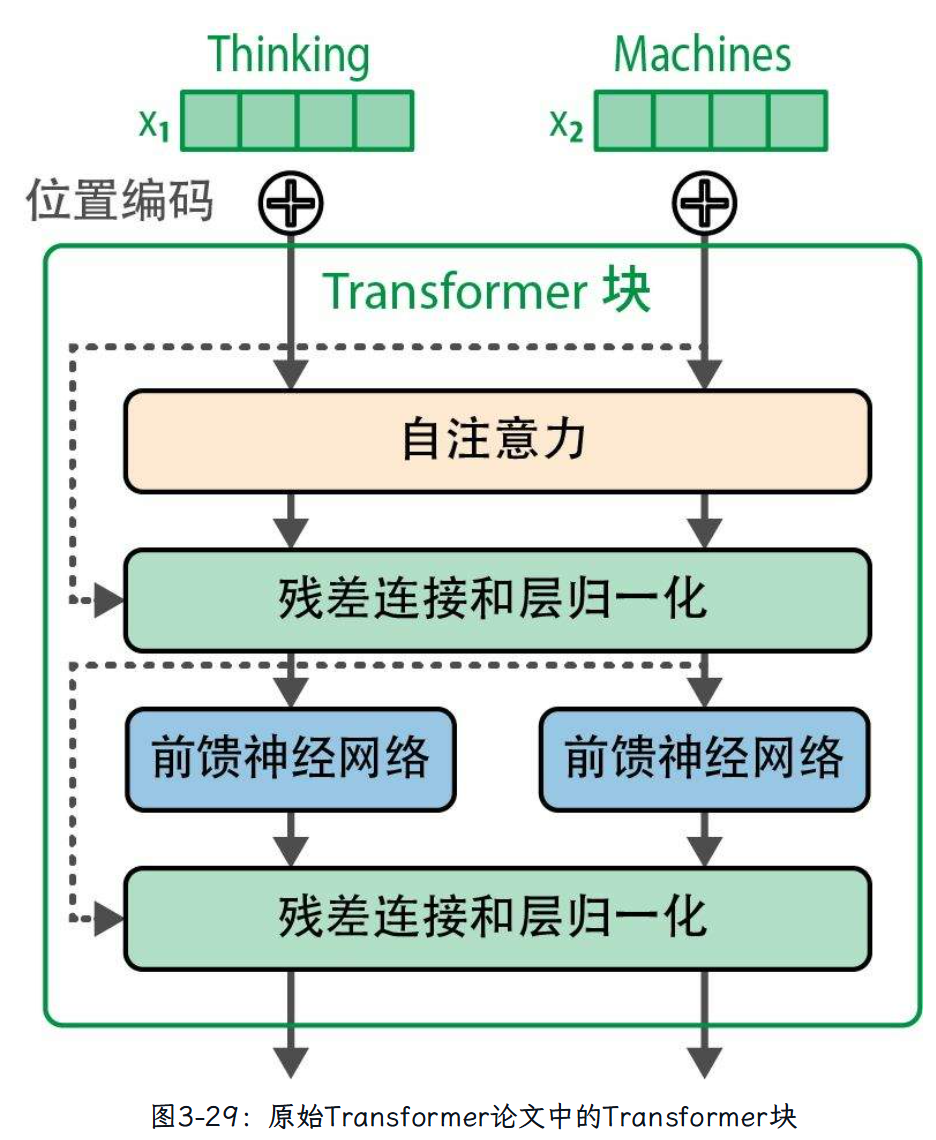

区别:
①归一化的发生时间:归一化发生在自注意力层和前馈神经网络层之前。据称,这种方式可以减少所需的训练时间(参见论文“On Layer Normalization in the Transformer Architecture”)。
②使用RMSNorm,它比原始Transformer中使用的LayerNorm更简单、更高效(参见论文“Root Mean Square Layer Normalization”)。
③相比原始Transformer的ReLU激活函数,现在像SwiGLU这样的新变体(参见论文“GLU Variants Improve Transformer”)更为常见。
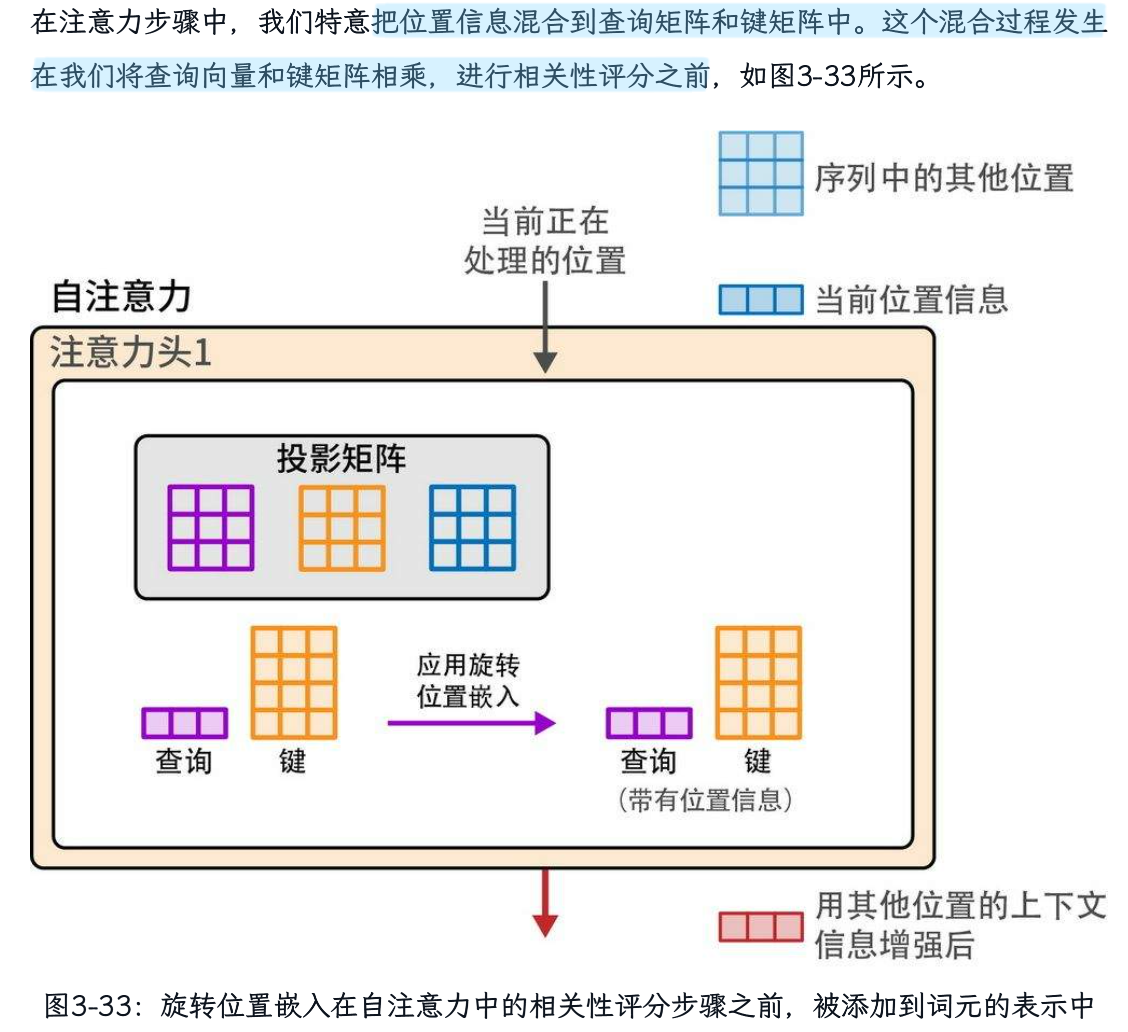
(3)位置嵌入—— ROPE
位置嵌入的作用:
使模型能够跟踪序列/句子中词元/词的顺序,这是语言中不可或缺的信息来源。
ROPE的必要性:
原始Transformer论文和一些早期变体采用绝对位置嵌入,本质上是将第一个词元标记为位置1,第二个标记为位置2,以此类推。这些方法可以是静态的(使用几何函数生成位置向量)或可学习的(模型在训练过程中为它们赋值)。
当我们将模型扩展到更大的规模时,这些方法会带来一些挑战,这要求我们找到提高其效率的途径。例如,在训练长上下文模型时的一个挑战是,训练集中有很多文档的长度都远小于上下文长度。如果为一个只有10个词的短句分配整个4K的上下文空间,这显然是很低效的。因此在模型训练过程中,多个文档会被一同打包到每个训练批次的上下文中。(注:llamafactory在pt阶段,默认是将打包序列的设置为True)。
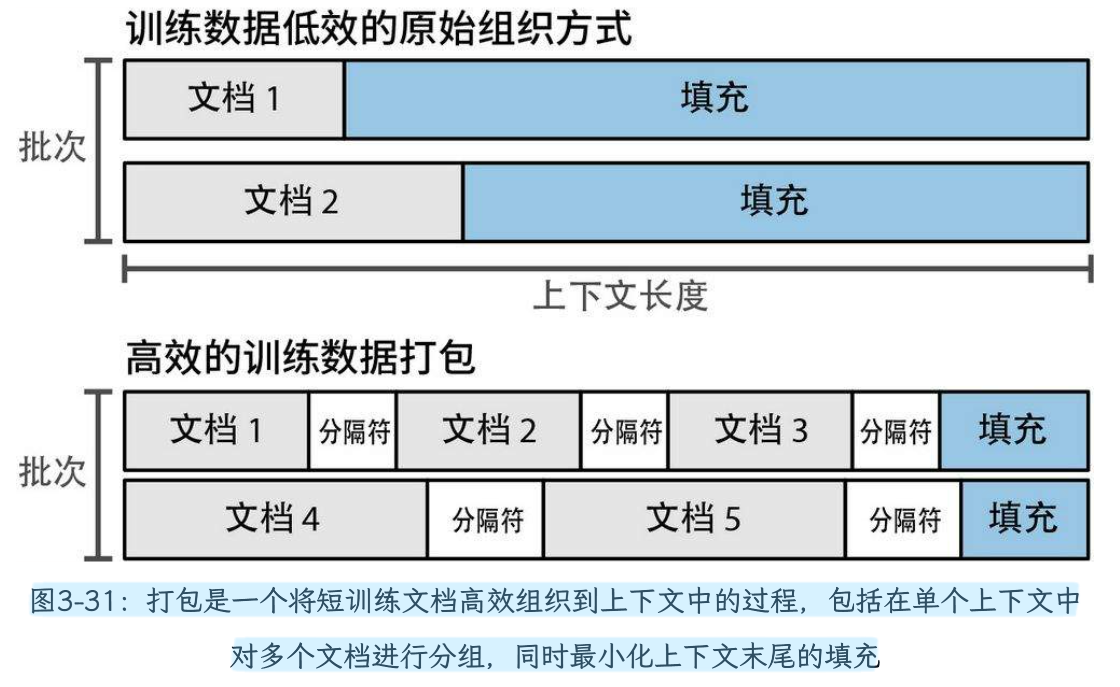
除了必须适应打包过程,位置嵌入方法还需要考虑实践中的其他因素。如果文档50从位置50开始,那么告诉模型第一个词元是第50个就会误导模型,并影响其性能(因为它会假设存在前文,而实际上前面的词元属于另一个无关的文档,模型应该忽略)。
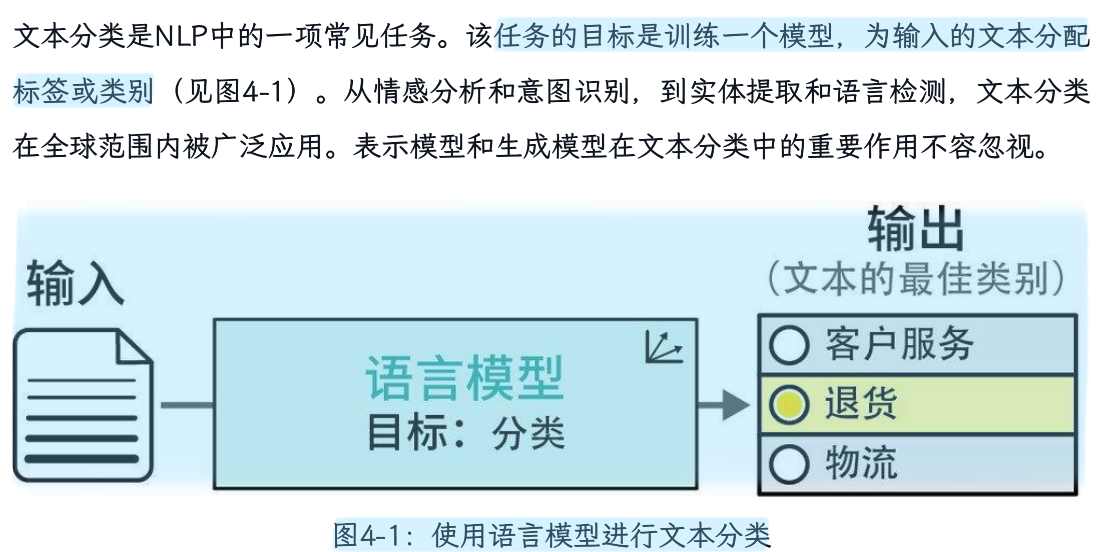
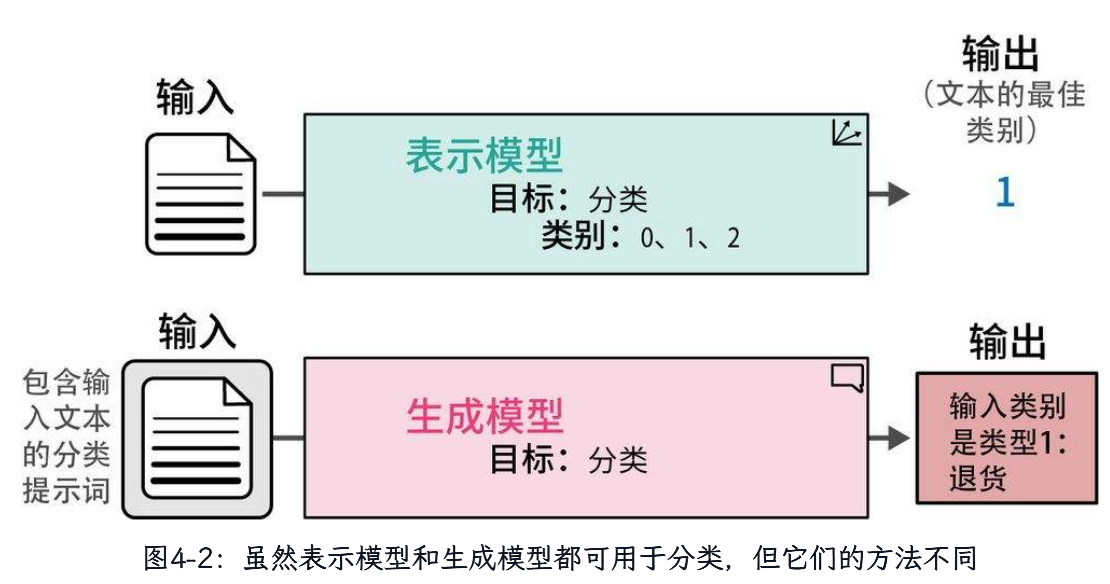
第四章 文本分类
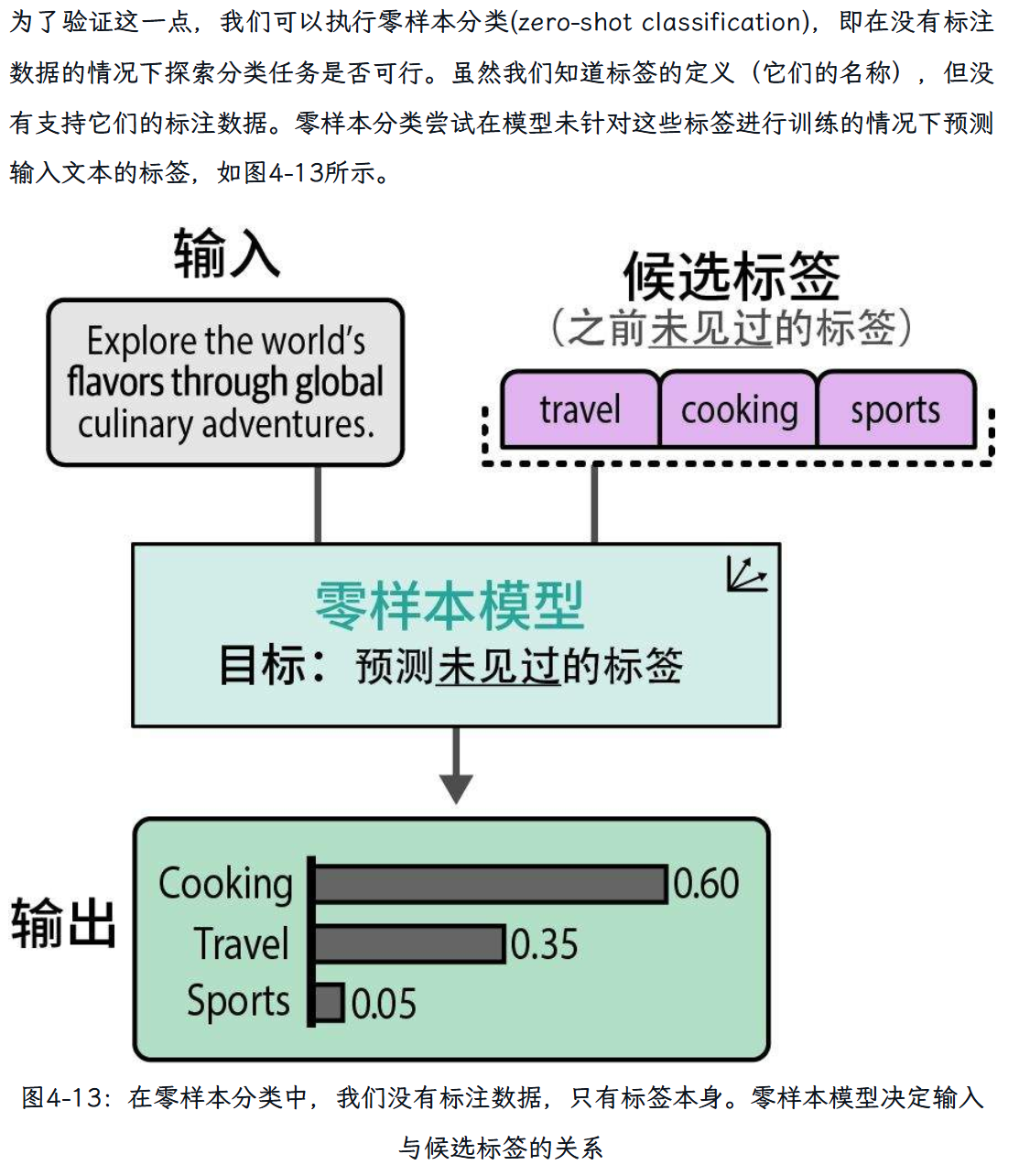
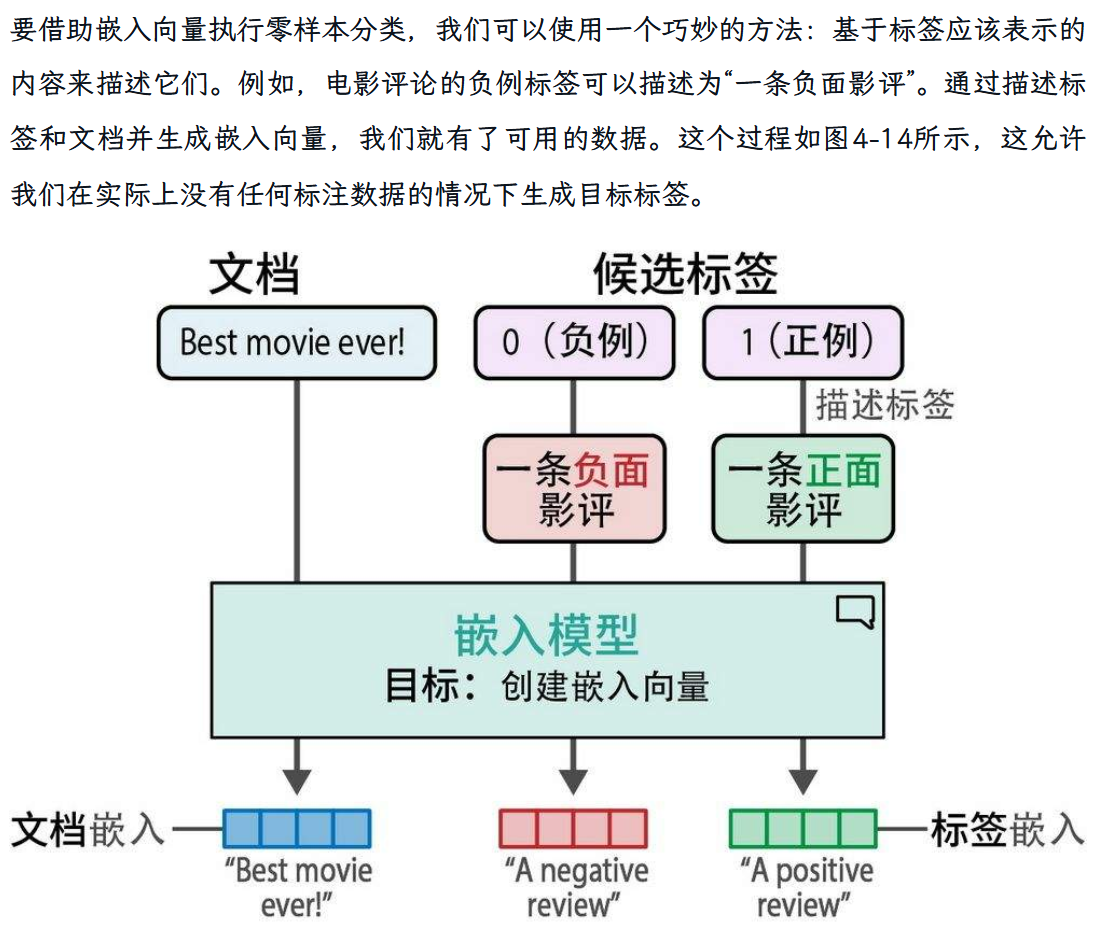
零样本分类:
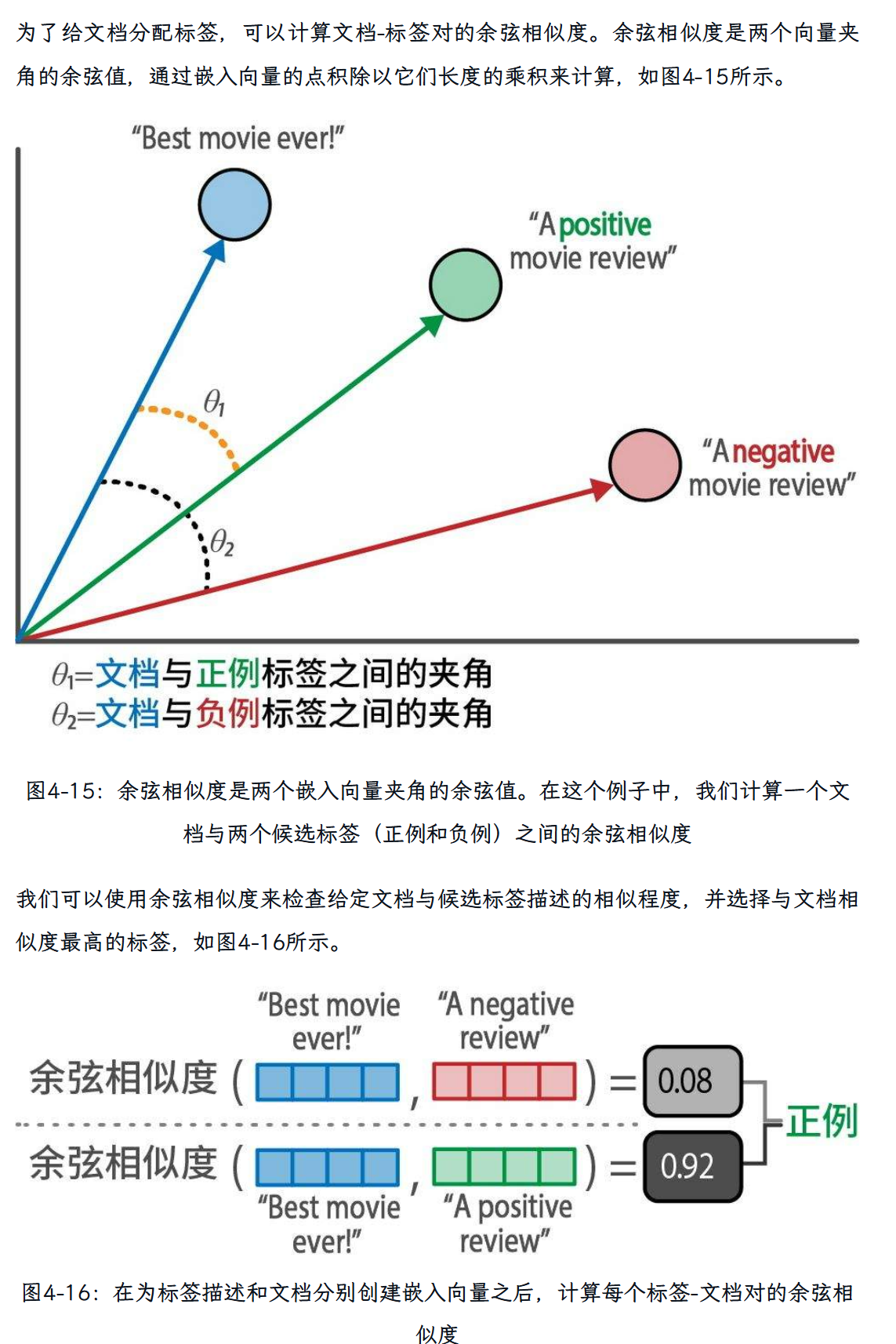
第五章 主题建模
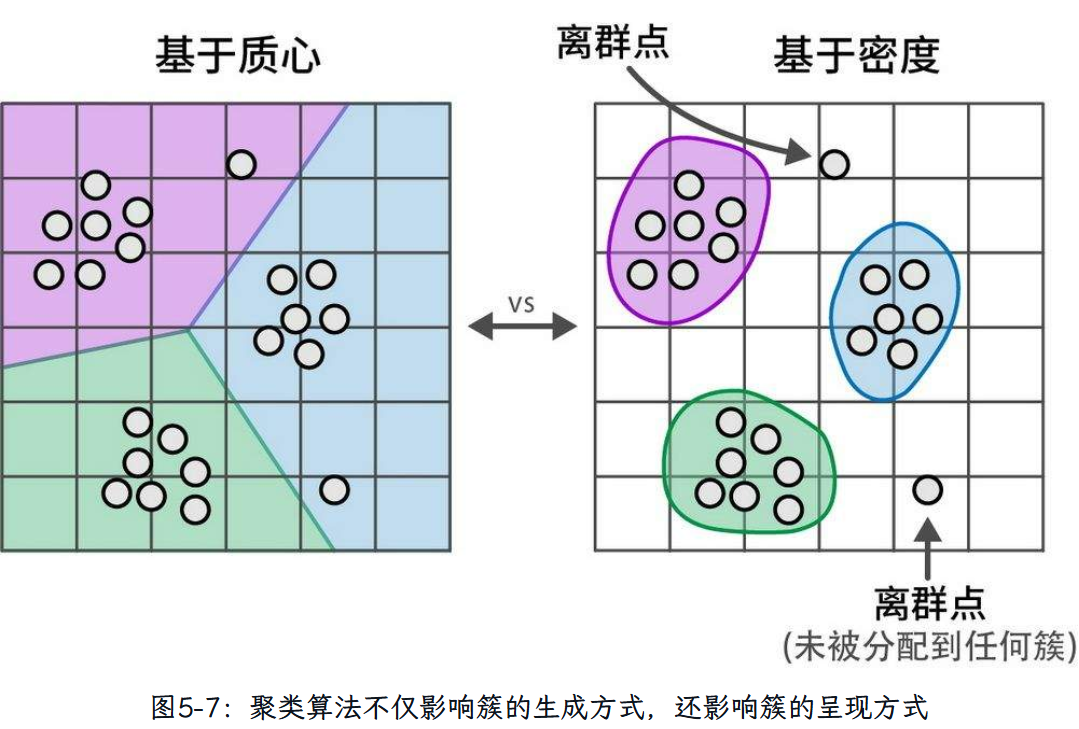
文本聚类方法分类:

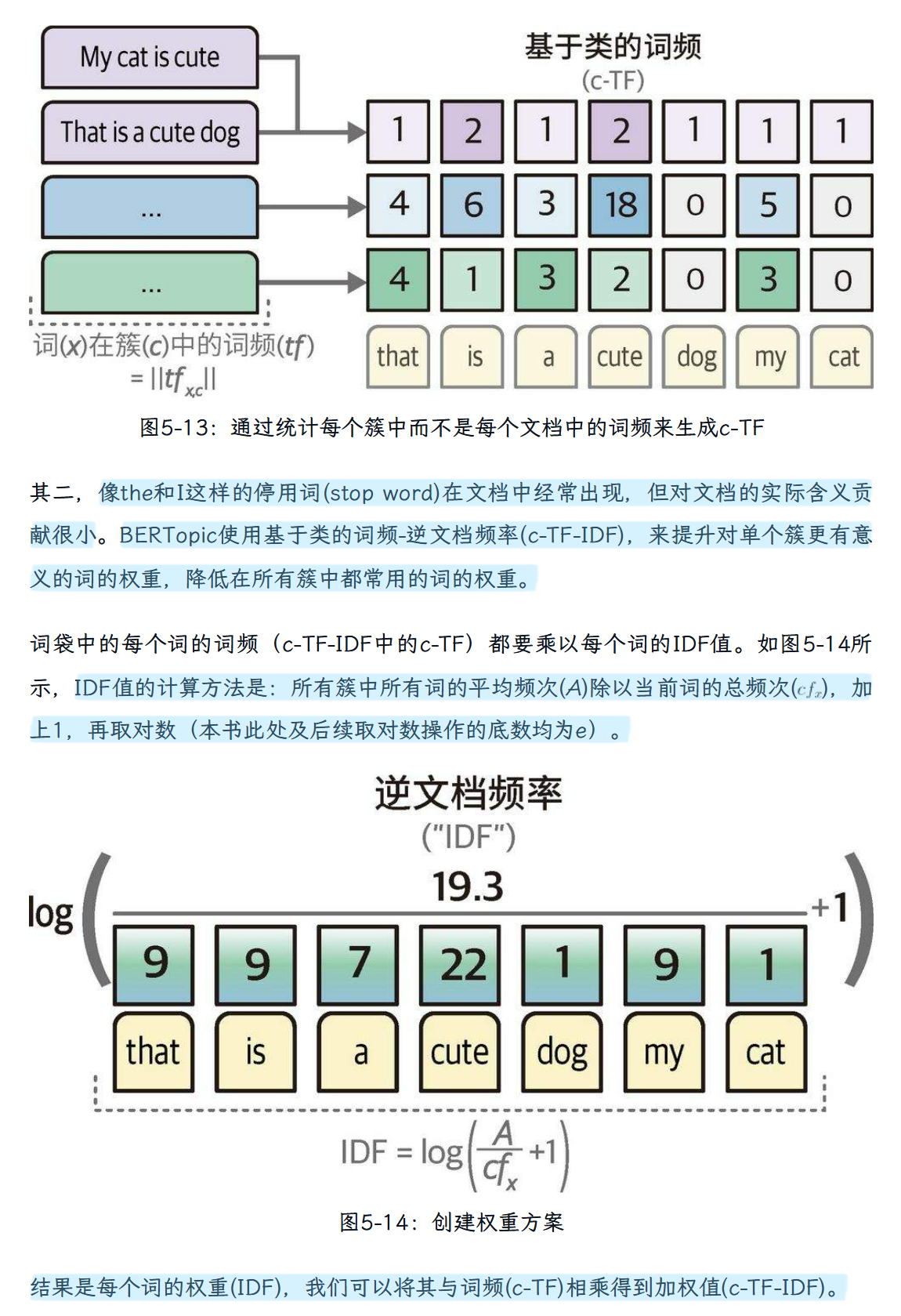
然后,再运用rerank表示模型完成进一步性能的优化。



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)