LLM之Agent(二十七)| Manus 上下文管理经验揭秘
上下文缩减与上下文卸载类似,但它的做法则是对信息进行摘要或压缩。一个直观的方法是摘要工具调用的输出,Open Deep Research 项目中已经采用了该方法。另一个方法是精简 (pruning) 工具调用或工具消息。有趣的是,Claude 3.5 Sonnet 实际上已经内置了这个功能。如果你去看他们最近的发布,会发现它现在原生支持这个特性。所以,精简掉旧的工具调用和输出,已经成为 Claud
近日,LangChain 与 Manus 团队联合举办了一场线上研讨会,主题聚焦于AI Agent 上下文工程。本文将总结一下研讨会上核心观点,尤其是manus的经验之谈:
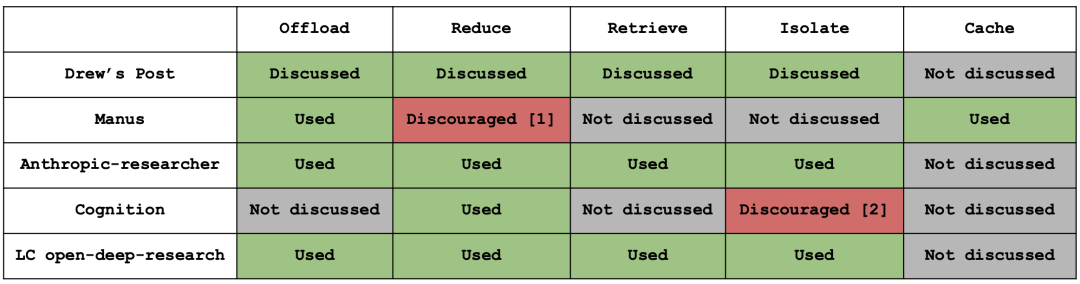
一、上下文卸载:分层式行为空间(Tool Offloading)
上下文卸载 (context offloading)的核心思想是:并非所有上下文都需要保留在 AI Agent 的消息历史中,可以将部分上下文“卸载”到上下文窗口之外,在需要时再去检索。
其中最流行的方法之一就是使用文件系统 (file system)。例如,将工具消息的(完整)输出保存到文件系统中,然后只向 AI Agent 返回一条必要(且简短)的信息(比如文件名)。这样,AI Agent 在需要时可以引用完整的上下文。但像网页搜索结果这种非常消耗 Token (token-intensive)(即非常占空间)的完整内容,就不会永远占据你的上下文窗口。
这个方法在许多项目中都有应用,比如Manus 和LangChain的 Deep Agents 项目。Open Deep Research 项目中,Agent 状态 (AgentState) 实际上也起到了类似外部文件系统的作用。当然,Claude Code 和long-running agents也使用了这种技术。所以,将上下文卸载到文件系统,是当今许多生产级 AI Agent 中非常普遍和流行的做法。
随着系统变得越来越复杂,特别是如果你决定有一天要集成 MCP (Manus Code Playground),你会发现工具本身也会占用大量上下文。上下文中工具过多会导致混乱,我们称之为“上下文混淆”(context confusion),模型可能会调用错误的工具,甚至是不存在的工具。所以我们必须找到一种方法,也能卸载工具。
目前一个常见的方法是,对工具描述进行动态的 RAG (Retrieval-Augmented Generation),例如,根据当前任务或状态按需加载工具。但这也会带来两个问题。首先,由于工具定义位于上下文的前端,每次变动都会导致你的 KV 缓存重置。更重要的是,模型过去对那些已被移除的工具的调用记录仍然存在于上下文中,这可能会误导模型去调用无效的工具或使用无效的参数。
为了解决这个问题,Manus团队试验一种新的分层式行为空间 (layered action space),可以从三个不同层次的抽象中进行选择:第一层是函数调用 (function calling),第二层是沙盒工具 (sandbox utilities),第三层是软件包与 API (packages and API)。让我们深入了解这三个层次。
1. 第一层:函数调用(固定 10–20 个原子函数)
‑ 仅保留读写文件、shell、搜索、浏览器等原子操作;利用约束解码保证 schema是安全的。
2. 第二层:沙盒工具(VM 内 CLI)
‑ 预装了格式转换器、语音识别工具、MCP-CLI 等可执行文件。可以使用shell 在目录/usr/bin 调用这些预装的工具,还可以通过--help查看这些工具的使用方法;对于大输出可以直接写入文件或者分页返回结果,可以使用所有那些 Linux 工具,如 grep、cat、less、more 来二次处理这些结果。
‑ 优点:新增功能不污染函数空间;缺点:高延迟交互需额外可视化。
3. 第三层:软件包与 API(Python 脚本)
‑ Agent 现场写 Python 调用已预授权、预付费的 API(金融、3D 库等);大量内存计算在运行时完成,仅把摘要回写上下文。
‑ 优点:代码可组合,单步完成多跳逻辑;缺点:无约束解码,需沙盒隔离保安全。
4. 统一接口
‑ 三层最终仍封装成标准函数调用(shell→shell()、脚本→execute_python()),对模型透明,KV-cache 友好,保持正交。
二、上下文缩减:压缩 vs 摘要
上下文缩减与上下文卸载类似,但它的做法则是对信息进行摘要或压缩。
一个直观的方法是摘要工具调用的输出,Open Deep Research 项目中已经采用了该方法。另一个方法是精简 (pruning) 工具调用或工具消息。有趣的是,Claude 3.5 Sonnet 实际上已经内置了这个功能。如果你去看他们最近的发布,会发现它现在原生支持这个特性。所以,精简掉旧的工具调用和输出,已经成为 Claude 在其 SDK 中内置的功能。
对完整的消息历史进行摘要或压缩。在 Claude Code 的压缩功能中可以看到,当上下文窗口使用率达到一定百分比时,它就会触发压缩。Cognition 公司也提到了在 AI Agent 交接时进行摘要或精简的想法。因此,缩减上下文是一个非常流行的主题,我们可以在从 Claude Code 到 Open Deep Research 再到 Cognition 等许多案例中看到它的身影,Claude 3.5 Sonnet 也集成了这一功能。
Manus在上下文缩减的经验如下:
1. 双格式机制
‑ 每条工具调用/结果同时存“完整格式”与“紧凑格式”;紧凑版仅保留可重建信息(如文件路径),内容字段直接丢弃。
2. 可逆性优先
‑ 压缩必须可逆,确保十步后模型仍能回溯;摘要不可逆,仅在压缩收益<阈值后触发。
3. 触发策略
‑ 先压缩最旧 50% 历史调用,保留最新少数完整样本防模型“学错格式”;压缩后仍逼近“上下文腐烂”阈值(128k–200k token)才做摘要。
4. 摘要保护
‑ 摘要前把关键上下文整段 dump 到日志文件;
‑ 摘要时仍用完整格式而非紧凑格式,不要使用自由形式 (free-form) 的提示让 AI 生成所有内容,而是定义一个模式 (schema),就像一个有很多字段的表单,让 AI 去填写。例如,“这是我修改过的文件”、“这是用户的目标”、“我上次停在这里”;
‑ 永远保留最近 N 条完整调用,防止风格突变。
三、上下文检索与存储
Cursor 的 Lee Robinson 最近在 OpenAI 的演示日上做了一次非常精彩的演讲,他谈到,Cursor 使用了索引和语义搜索,以及像 glob 和 grep 这样更简单的基于文件的搜索工具。而 Claude Code 则只使用文件系统和简单的搜索工具,主要是 glob 和 grep。所以,为 AI Agent 按需检索上下文有两种不同的方式:一种是索引加语义搜索,另一种是文件系统加简单的文件搜索工具。两者都可以非常有效,各有优劣。
1. 不用向量索引
‑ 每会话全新沙盒,冷启动来不及建索引;依赖 grep/glob 行级纯文本(Markdown 易过度触发列表符号,优先 plain-text)。
2. 长期记忆=显式 Knowledge
‑ 用户显式“记住”→弹窗确认;探索无参数在线学习:利用多用户相同纠正(如 CJK 字体)自动提炼共识。
四、上下文隔离:通信模式 vs 共享内存模式
上下文隔离 (context isolation) 是通过多 Agent (multi-agents) 来划分上下文,每个子 Agent (sub-agent) 都有自己独立的上下文窗口,从而实现关注点分离 (separation of concerns) (一种软件设计原则,指将不同功能模块化,使其互不干扰)。Manus 的 Wide Agents 、LangChain的Deep Agents 项目和Open Deep Research 都采用了该方法。Claude 在其研究中也利用了子 Agent,例如在 Claude 的多 Agent 研究员 (multi-agent researcher) 和 Claude Ghost 中都支持子 Agent。因此,子 Agent 是实现上下文隔离的一种非常常见的方式,我们已在许多不同的项目中见证了它的应用。
1. 通信模式(子 Agent)
‑ 主 Agent 发短指令,子 Agent 零上下文启动,仅返最终结果;适合“搜一段代码”这类明确子任务。
2. 共享内存模式(共享上下文)
‑ 子 Agent 看到全部历史工具记录,但系统提示与行为空间独立;适合需复用中间笔记/搜索结果的深度研究场景。
3. 代价对比
‑ 共享模式输入 token 高且无法复用 KV-cache;通信模式节省 token 但需额外文件交换,权衡点在于“重读文件 vs 多付输入 token”。
五、Manus 多 Agent 与规划
1. 角色分工否定
‑ 拒绝“设计师 Agent+程序员 Agent”拟人拆分;仅保留 3–4 个通用 Agent:执行器、规划器、知识管理器,其余用“Agent-as-Tool”模式。
2. 规划器独立
‑ 用 Haiku 等轻量模型做外部审视;废弃 todo.md,避免 1/3 Token 浪费。
3. Agent-as-Tool MapReduce
‑ 主 Agent 预定义输出 schema,子 Agent 用约束解码 submit_result() 回传,保证结构一致;共享沙盒文件系统作为“shuffle”媒介。
六、Manus 评估与迭代
1. 三维评估
‑ 用户五星评分(黄金标准)
‑ 可验证自动化任务(含执行性/交易性自建数据集)
‑ 真人实习生主观评估(视觉、品味)
2. 架构未来验证
‑ 固定架构,在弱→强模型间切换,若强模型收益大则架构 future-proof;每 1–2 个月用预览模型提前重构。
七、Manus 安全与护栏
1. 沙盒零信任
‑ 出站流量清洗,防 Token 泄露;用户打印内容经脱敏。
2. 浏览器隔离
‑ 登录态可选持久化;敏感操作强制人工确认;与模型方合作做提示注入防护。
八、关键格言
“build less and understand more”——上下文工程目标是为模型减负而非加戏;能删减就删减,相信模型能力上涨带来的收益。
参考文献:
[1] https://www.dbreunig.com/
[2] https://langchain-ai.github.io/langgraph/tutorials/workflows/
[3] https://www.anthropic.com/engineering/built-multi-agent-research-system
[4] https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
[5] https://research.trychroma.com/context-rot
[6] https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html
[7] https://blog.langchain.com/open-deep-research/
[8] https://github.com/langchain-ai/open_deep_research
[9] https://github.com/langchain-ai/how_to_fix_your_context

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)