v降薪跳槽,投身开源!只为 AI 落地 “最后一公里”
很多人可能会问:AI 落地还不简单?不就是调个 API 吗?如果真是这样,那 nndeploy 这种部署框架岂不是多此一举?还真不行。试想一下:自动驾驶汽车在高速上需要紧急刹车,它能等待一个网络 API 返回结果吗?工厂的质检摄像头,能忍受零点几秒的网络延迟吗?更不用说,当你的手机需要人脸解锁时,你敢把自己的信息毫无保留地传到云端吗?延迟、隐私、成本—— 这三座大山,让端侧部署成为 AI 落地的重
这是一款专为 AI 落地最后一公里 而生的易用、高性能端侧 AI 部署框架。它通过可视化⼯作流降低⻔槛,统⼀接⼝搞定多端推理,并提供 LLM、AIGC、换脸、目标检测、图像分割等开箱即用的 AI 模型部署配置文件。让 AI 落地,从数周缩短至几天。

GitHub 地址:github.com/nndeploy/nndeploy
一、AI 落地:被忽视的 “最后一公里”
很多人可能会问:AI 落地还不简单?不就是调个 API 吗?
如果真是这样,那 nndeploy 这种部署框架岂不是多此一举?
尤其是在端侧(On-Device)—— 也就是手机、汽车、摄像头这些设备上 —— 这个问题的答案尤其清晰:还真不行。
试想一下:自动驾驶汽车在高速上需要紧急刹车,它能等待一个网络 API 返回结果吗?工厂的质检摄像头,能忍受零点几秒的网络延迟吗?更不用说,当你的手机需要人脸解锁时,你敢把自己的信息毫无保留地传到云端吗?
延迟、隐私、成本 —— 这三座大山,让端侧部署成为 AI 落地的重要阵地,进一步拓宽了应用的边界。

而 AI 部署工程师的 “战场”,就是要把那些 “聪明模型” 塞进各种资源受限的设备中。他们面对的是发热的芯片、有限的算力、以及五花八门的操作系统…… 他们是把 AI 从 “实验室” 带到更多人身边的幕后英雄。
这批工程师也是 AI 开发岗位中需求量大、门槛相对较低、薪资也同样可观的主流 “AI 饭碗”。

而这,也正是 Always(nndeploy 发起人)想解决的另一个核心问题。他希望 nndeploy 不仅是一个 AI 部署框架,更能为那些想从软件工程师转型到 AI 部署的开发者,提供一套开箱即用的 “武器库”。
二、nndeploy:助力 AI 部署工程师的每个阶段
nndeploy 为什么能成为 AI 部署工程师的 “必备工具箱”?
秘诀在于:它为不同阶段的 AI 部署工程师量身打造了关键能力。
- 新手友好:超低门槛的可视化工具,助你轻松入门。
- 专业进阶:深度优化能力,助力打造高性能解决方案。
- 高效实战:丰富算法库,兼顾效率与学习,开箱即用。
2.1 可视化 “木剑”,轻松上手
nndeploy 的首要目标,是让 AI 落地变得前所未有的简单。对于转行或刚入门的工程师,它提供了极致直观的体验:
- 可视化工作流:拖拽节点即可部署 AI 算法,参数实时可调,效果一目了然。
- 自定义节点:无论是用 Python 实现预处理,还是用 C++/CUDA 编写高性能节点,均可无缝集成于工作流。
- 一键多端部署:工作流支持导出为 JSON,可通过 C++/Python API 调用,适用于 Linux、Windows、macOS、Android、iOS 等平台。

2.2 高性能 “屠龙刀”,攻克生产难题
在高性能需求下,nndeploy 是工程师手中的 “屠龙刀”。它为资深从业者内置了面向 “最后一公里” 的深度优化:
- 并行优化:支持串行、流水线并行和任务并行等多种执行模式。
- 内存优化:零拷贝、内存池、内存复用等优化策略,专为端侧资源优化设计。
- 高性能优化:内置 C++/CUDA/Ascend C/SIMD 等多种高性能节点实现。
- 多端推理:支持 13+ 主流推理框架(TensorRT、ONNXRuntime、OpenVINO 等),无缝适配云、边、端全场景。
以 YOLOv11s 端到端工作流总耗时为例,串行 vs 流水线并行:

2.3 开箱即用的算法库,高效又好学
nndeploy 内含 100+ 常用节点,覆盖主流 AI 应用场景。无需反复造轮子,高频需求一键满足。丰富的案例也是最佳学习资料:拿来即用、跑通即会!

注:nndeploy 专注于端侧,仅支持参数量在 0.3B~7B 级别的大语言模型。
三、五分钟用上你的第一个 AI 应用
nndeploy 的上手体验到底有多丝滑?
无需复杂配置,5 分钟就能启动并部署一个 AI 应用。
1. 一键安装
pip install --upgrade nndeploy
2. 启动可视化编辑器
nndeploy-app --port 8000
启动成功后,打开 http://localhost:8000 即可进入工作流编辑器。在这里,你可以拖拽节点、调整参数、实时预览效果,所见即所得。

3. 保存并执行:从原型到生产
在可视化界面中搭建、调试完成后,点击保存,工作流就会导出为一个 JSON 文件。
这个 JSON 文件就是你的 AI 应用,它封装了你所有的流程和逻辑。你可以用以下两种方式在生产环境中运行它:
方式 1:命令行一键执行
用于快速测试和验证。
# Python 命令行
nndeploy-run-json --json_file path/to/workflow.json
# C++ 命令行
nndeploy_demo_run_json --json_file path/to/workflow.json

方式 2:在 C++/Python 代码中加载
这才是最核心的用法。你可以将这个 JSON 文件无缝集成到你现有的 C++ 或 Python 项目中,以下是一个加载 LLM 工作流的示例代码:
Python 示例
graph = nndeploy.dag.Graph("")
graph.remove_in_out_node()
# 仅需加载导出的 JSON 文件
graph.load_file("path/to/llm_workflow.json")
graph.init()
# 准备输入数据
input = graph.get_input(0)
text = nndeploy.tokenizer.TokenizerText()
text.texts_ = [ "<|im_start|>user\nPlease introduce NBA superstar Michael Jordan<|im_end|>\n<|im_start|>assistant\n" ]
input.set(text)
# 执行并获取结果
status = graph.run()
output = graph.get_output(0)
result = output.get_graph_output()
# 释放资源
graph.deinit()
C++ 示例
std::shared_ptr<Graph> graph = std::make_shared<Graph>("");
// 仅需加载导出的 JSON 文件
base::Status status = graph->loadFile("path/to/llm_workflow.json");
graph->removeInOutNode();
status = graph->init();
// 准备输入数据
Edge* input = graph->getInput(0);
tokenizer::TokenizerText* text = new tokenizer::TokenizerText();
text->texts_ = {
"<|im_start|>user\nPlease introduce NBA superstar Michael Jordan<|im_end|>\n<|im_start|>assistant\n"
};
input->set(text, false);
// 执行并获取结果
status = graph->run();
Edge* output = graph->getOutput(0);
tokenizer::TokenizerText* result = output->getGraphOutput<tokenizer::TokenizerText>();
// 释放资源
status = graph->deinit();
四、技术解读:如何实现简单且高性能?
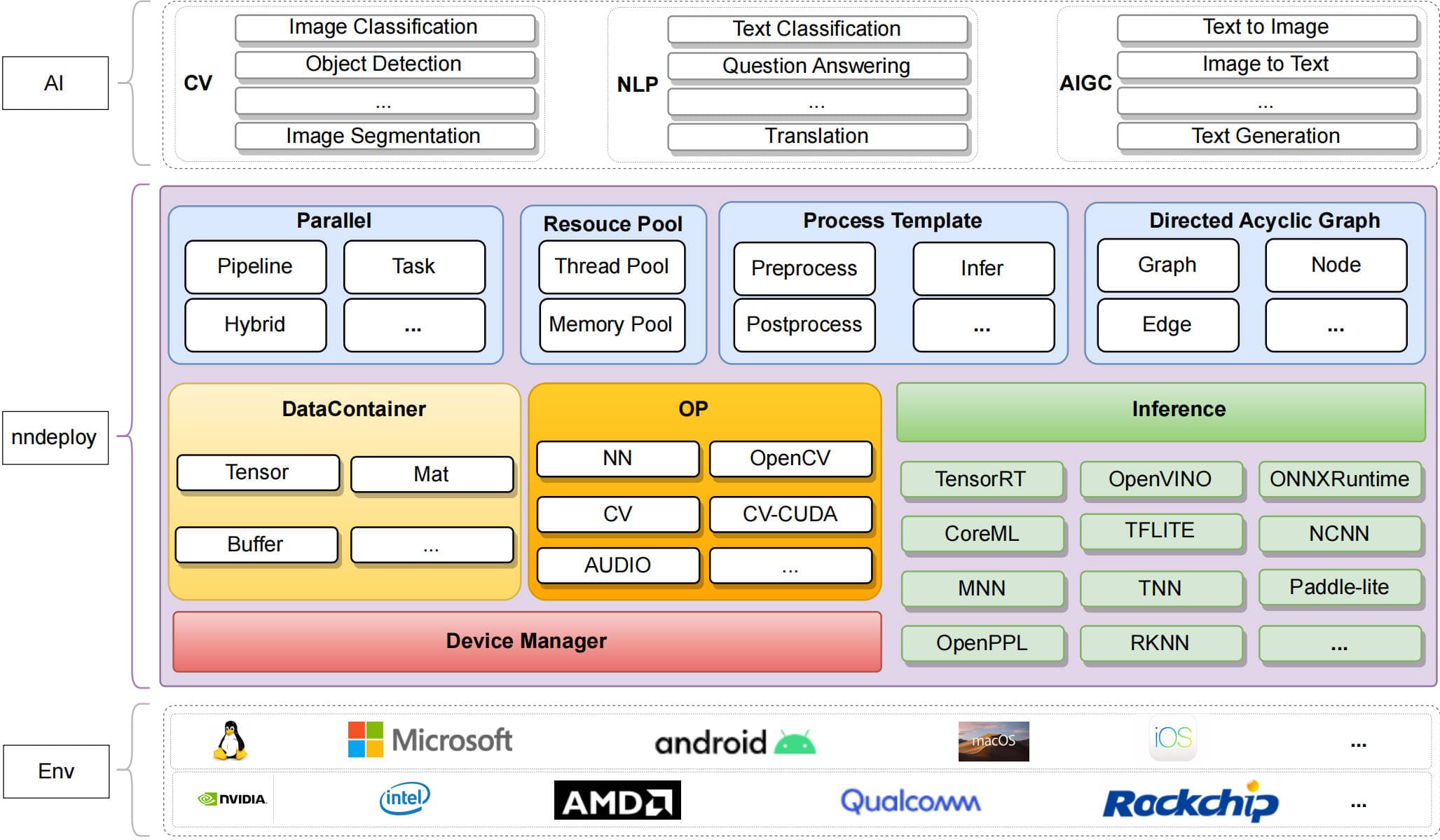
nndeploy 通过将 AI 算法拆解为工作流节点进行部署,采用三层分离架构设计,整体结构如图所示:

三层架构详解如下:

计算执行层是 nndeploy 的高性能核心,由图执行引擎与多端推理两大模块组成:
- 图执行引擎:基于有向无环图(DAG)实现工作流调度,⽀持灵活的串⾏、任务并行、流水线并⾏和组合并行执⾏模式。
- 多端推理:统一封装 10 余种主流推理后端,提供跨平台推理能力。
整体架构如下图所示:
4.1 图执行引擎
Graph 本身继承自 Node,可作为子图嵌套,支持任意层级组合。图执行引擎包含三层抽象:
- Graph(图):工作流容器,负责节点管理、拓扑排序与调度执行。
- Node(节点):独立的计算单元。
- Edge(边):节点间数据传递通道。
这种 “图即节点” 的设计,让用户像搭积木一样自由组合算法节点,构建复杂的 AI 工作流。支持以下执行模式:
- 串行执行:按拓扑顺序逐节点执行。
- 流水线并行:前处理、推理、后处理等环节并行,提升数据吞吐。
- 任务并行:无依赖节点同时运行,缩短整体耗时。
- 组合并行:支持嵌套,灵活组合各种并行方式,充分释放硬件性能。
4.2 多端推理
nndeploy 的多端推理模块为不同推理后端提供统一接口,开发者无需关心底层框架差异。例如,新增 MNN 推理后端的流程包括:
- 理解 MNN 的 API 和推理流程。
- 熟悉 nndeploy 的推理基类与超参数配置类。
- 编写适配器:继承推理基类实现适配逻辑、继承超参数类实现参数配置、实现数据转换⼯具函数。
- 基于新后端运行模型,验证功能完整性。

针对不同推理框架的数据交互方式(如 TensorRT 的 io_binding、OpenVINO 的 ov::Tensor、TNN 的 TNN::Blob),nndeploy 设计了统一的数据容器 Tensor 和 Buffer,彻底屏蔽底层差异。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)