一文速通RAG
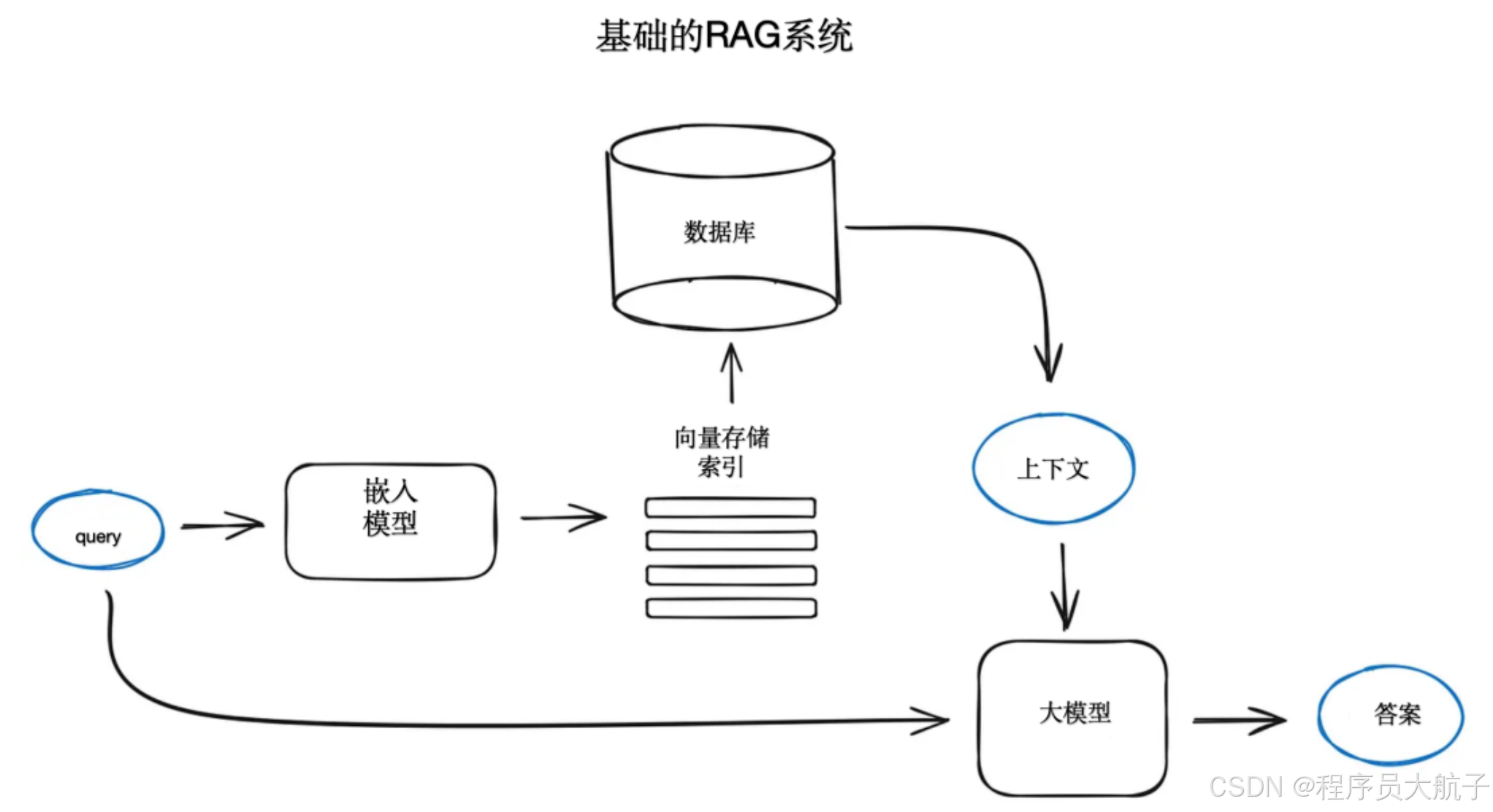
可以理解为,有一个模型,会把一段文本转换成一个高纬度的向量(一般都是1000多维,人是想象不到的),然后这个纬度里面语义越相近的段落,离的会越近。向量数据库在rag中是用来存储向量,然后再有一个同纬度的向量,能快速帮助检索出数据库中和这个向量最相似的topK的向量的,然后这些向量对应的段落就是我们要召回文本内容,当然数据库还要存储这些向量对应的文本,召回的时候直接给文本是最好的嘛。总结下来就是把你
学一门技术,我们首先要了解这门技术是解决什么问题的。Rag(检索增强生成)是当下热门的大模型前沿技术之一。
检索增强生成模型结合了语言模型和信息检索技术。具体来说,当模型需要生成文本或者回答问题时,它会先从一个庞大的文档集合中检索出相关的信息,然后利用这些检索到的信息来指导文本的生成,从而提高预测的质量和准确性。
- 检索:根据用户的查询内容,从外部知识库获取相关信息。具体而言,将用户的查询通过嵌入模型转换为向量,以便与向量数据库中存储的相关知识进行比对。通过相似性搜索,找出与查询最匹配的前 K 个数据。
- 增强:将用户的查询内容和检索到的相关知识一起嵌入到一个预设的提示词模板中。
- 生成:将经过检索增强的提示词内容输入到大型语言模型中,以生成所需的输出。
总结下来就是,大模型在预训练的时候采用的大量数据往往是通用知识,且时效性有限。你要问他一些通用的知识还可以,但是你要问他你们公司的内部知识,比如你们公司员工入职流程,他不是告诉你不知道,就是瞎和你说。因为在他学习知识的时候,你的这些知识压根是不存在的。
那么这个问题应该怎么解决呢?除了Fine-tuning(这个成本比较高,且很容易适得其反),最好的技术方案就是Rag。说白了人和大模型对话的语言就是你的prompt。如果在和大模型对话的时候,你把整个公司的内部文档都放到提示词里面,那大模型自然而然就知道你们公司的内部知识了。那么问题来了,一的公司的内部资料少说几十个G,模型在接受在这么多pe的时候,理解处理速度会变得很慢,再有大模型会抓不住重点。最主要的是,现在的厂商都是按照token算钱的,每次请求都这么多钱,哪个公司都扛不住。
于是,我们可以想一下,每次大模型回答问题,不可能需要你们公司所有的知识,比如入职流程,可能就只需要入职哪一个章节。我们是不是每次拼接pe的时候,只给最相关的知识就好了,这样就保证了我们pe的长度每次不会太离谱。那么我们想象一下,用户问了一个query我们该怎么获取到文本库里面最匹配的那些知识呢?这个就需要Rag技术了。
首先,我们需要将一个大的文档、pdf什么的拆分成若干片段,这个过程叫做分块(chunking)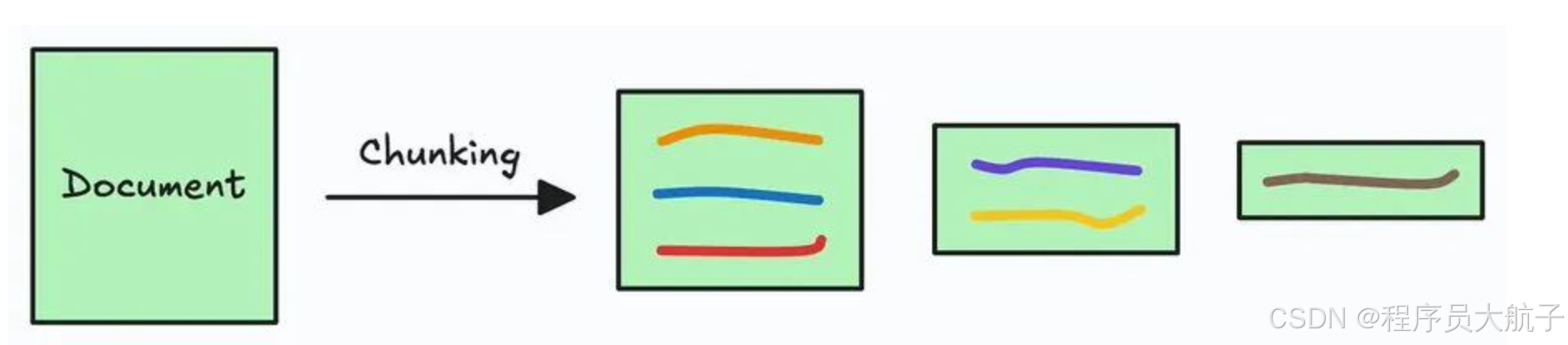
这个分块技术也有很多种,高级点的会根据语义分,也有通过问文档目录,页码分的。总结下来就是把你们公司的知识拆分成一个一个小的部分,我们给大模型的时候,只给一个或者几个小的部分就可以了。
然后我们需要一个Embedding模型,他的的核心是将符号数据(如单词、句子或图像)转换为固定长度的数值向量(称为Embedding),这些向量在连续空间中表示数据的语义特征。说白话,就是给通过这个模型我们能把一个文本或者音频什么提取成一个向量数组。可以简单的理解为一个float数组。可以理解为,有一个模型,会把一段文本转换成一个高纬度的向量(一般都是1000多维,人是想象不到的),然后这个纬度里面语义越相近的段落,离的会越近。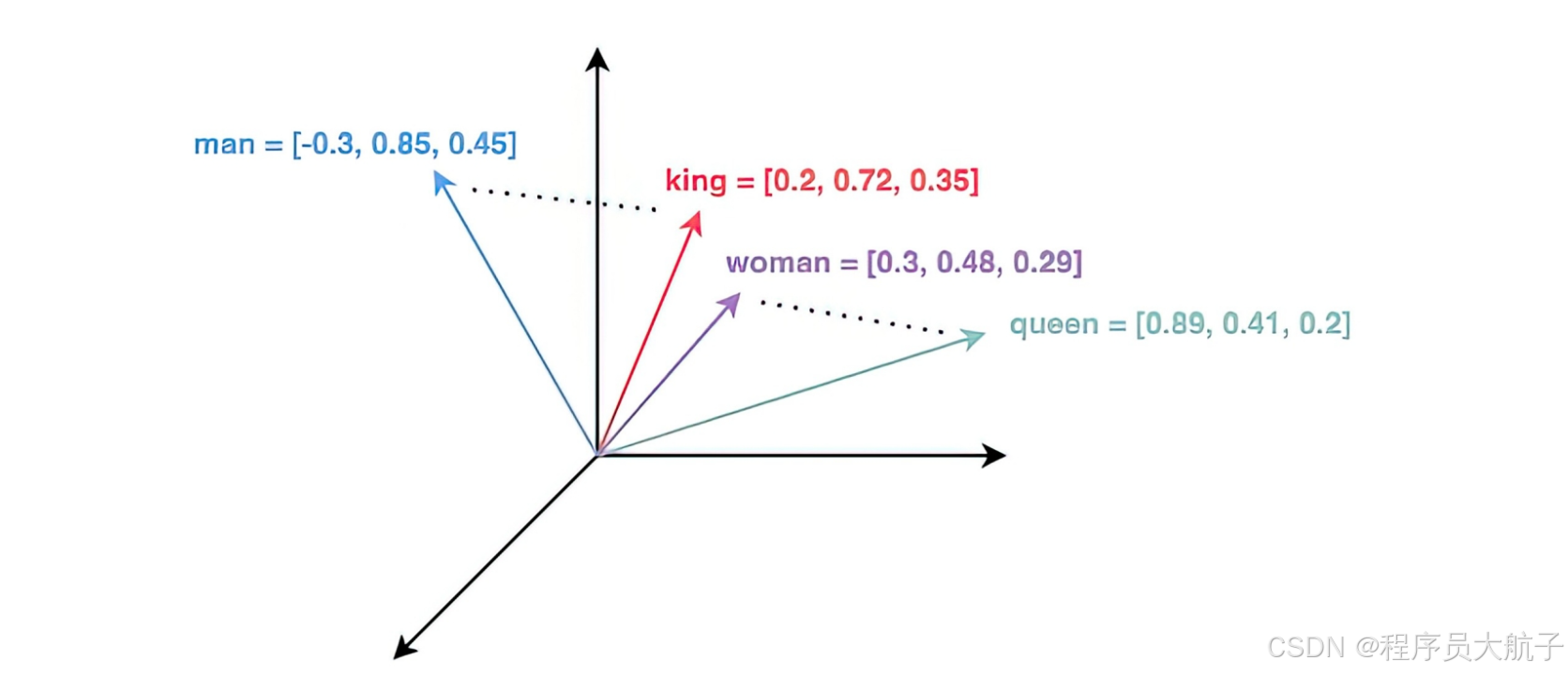
将文本、视频等变成向量的过程就叫做Embedding(向量嵌入)。又了这个,我们就可以把刚才分块之后的结果,每一个都做一次嵌入,我们就会得到很多高纬度的float数组。
有了这些数组,我们需要把他们储存起来,等有query的时候再快速召回,这个时候就需要一个数据库,向量数据库。向量数据库在rag中是用来存储向量,然后再有一个同纬度的向量,能快速帮助检索出数据库中和这个向量最相似的topK的向量的,然后这些向量对应的段落就是我们要召回文本内容,当然数据库还要存储这些向量对应的文本,召回的时候直接给文本是最好的嘛。
常用的向量数据库有Milvus、Pinecone、SingleStore Database、Chroma DB等等,大家使用的时候可以自己评估。
如上,Rag的流程大致可以分成离线准备和在线回答。
离线准备:
把你私有的知识(比如公司文档、行业报告)变成大模型能 “查” 的形式。
- 知识库:你的私有资料(比如 “金融产品手册”“员工培训文档”)。
- 清洗、装载:把这些资料里的 “垃圾内容”(比如重复、无用的话)删掉,整理成干净的文档。
- 切分:把大文档切成小片段(比如一篇 100 页的手册,切成 1000 个小段落),方便后续查找。
- 向量化:把每个小片段变成 “数字向量”(类似把文字翻译成 AI 能理解的数学语言)。
- 向量模型 + 向量库:把这些数字向量存起来,形成一个 “向量数据库”(相当于给知识建一个 “数字图书馆”,方便快速检索)。
在线回答:
目的:用户提问后,让大模型先查 “你的私有知识库”,再结合知识回答。
- 用户请求→Prompt:用户提问(比如 “我们公司新金融产品的收益率是多少?” ),变成大模型能理解的 Prompt。
- 向量化:把用户的问题也变成 “数字向量”(让 AI 理解问题的数学含义)。
- 相似检索:拿着这个 “问题向量”,去向量库里找最相关的知识片段(比如从金融产品手册里找到 “新理财产品收益率” 的段落)。
- 注入背景知识:把找到的相关知识(TopK 最相关的片段),和用户问题一起打包,变成新的 “提示词模版”。
- LLM 生成回答:大模型拿着 “新提示词”(包含用户问题 + 私有知识),生成更准确、更贴合你需求的回答。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)