MiniMax M2刷爆全网,开源模型排名第一!
短短一周,外网上 M2 相关的帖子就跟滚雪球一样,这不仅仅是因为模型的性能突出,也离不开 MiniMax 团队开放、透明、持续分享的态度。这里整理好了 M2 团队相关技术博客的链接,感兴趣的小伙伴可以去看看,我相信一定会受益匪浅。此外,MiniMax Agent 已经上线,由 MiniMax-M2 模型驱动。它提供了包括 pro 专业模式和 lightning 高效两类模式。目前全球正限时免费使用
这几天外网上真的太热闹了。
上周 MiniMax M2 正式开源,我的 X 就被它刷爆了。
MiniMax M2 是一款专为 Max 编码和代理工作流程构建的 Mini 模型,同时保持着强大的通用能力。总参数量 230B ,激活 10B 。
在 Artificial Analysis 榜上排名全球第五,是目前排名最高的开源模型。
在 LMArena 最新的 WebDev 榜单上总排名第四,开源第一。
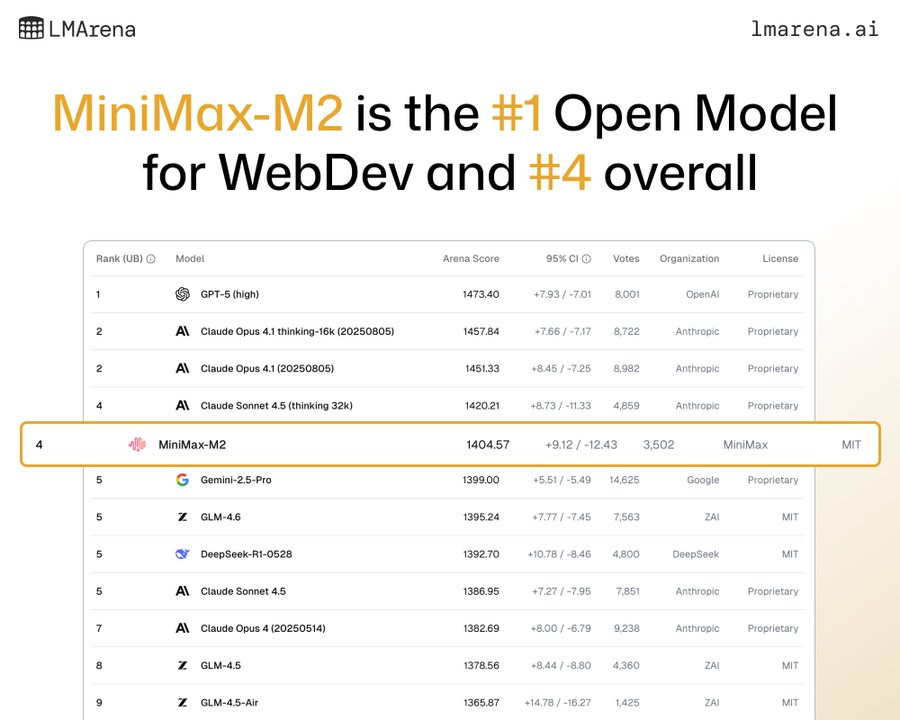
不仅成绩亮眼,热度也持续飙升。在 OpenRouter 上的调用量位列全球第三。
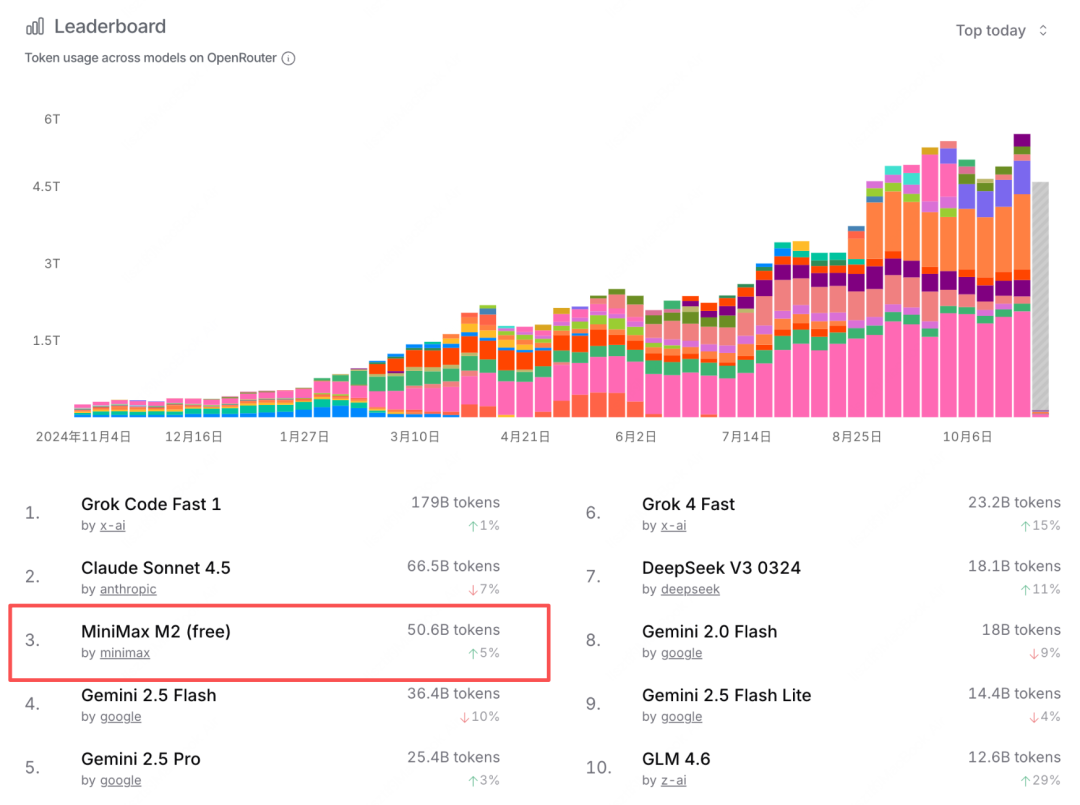
已经有大批开发者上手使用,并分享了体验反馈。先来看看网友评价怎么样。
一、网友评价
Django 创建人之一 Simon Willison 不仅认可了 M2 的表现,甚至已经给它写好了适配插件:

特别是 M2 的编码和代理能力广受好评。
它擅长多文件编辑、编码-运行-修复循环和测试验证修复。
并且能够出色地规划并执行复杂的工具链,协同调用 Shell、浏览器、Python 代码执行器和各种 MCP 工具。

二、技术交流
由于社区讨论过于热烈,M2 技术团队也陆续发布了多篇技术博客,集中回应社区的疑问、方便交流。
-
与什么保持一致?重新思考 MiniMax M2 中的代理泛化。
-
什么是好的推理数据?
-
为什么 M2 最终成为全注意力模型?
引来一众大佬纷纷转发。
Thinking Machine 的研究科学家,
甚至连英伟达的研究总监也亲自下场开麦……
各路大神齐聚讨论,这么热闹的场面我是一定要凑的。第一时间,我就好奇地在瓜田里上蹿下跳(bushi)。

外网上都在热议 M2 什么?
和我一起进入吃瓜第一线~
三、技术亮点讨论
Interleaved Thinking
首先是 M2 引入了 Interleaved Thinking ,交错思维链。
意味着它可以在单个请求中获得多个思考块,在“思考—行动—反思”之间交替循环,并把每一次思考结果都带入下一步行动。
模型会随时重新评估其方法,根据工具输出和新信息进行动态调整,从而充分应对外部干扰。
这样做的原因一个是在处理上下文很长的复杂代理任务时,它可以减少“状态漂移”与重复性错误。它还可以通过推理快照提升可解释性和可调试性。此外,该机制也是为了帮助模型适应外部扰动,增强其泛化能力。
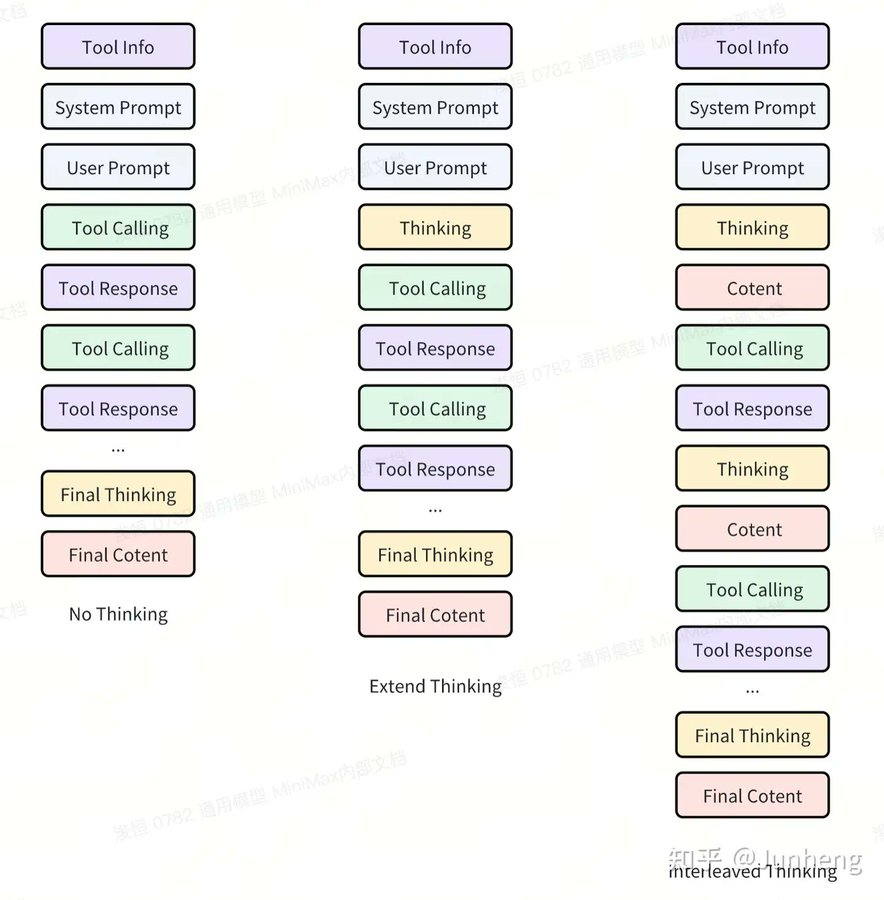
这种机制目前仍然是业界的非共识选择,前沿模型里面只有 Claude 采用了该机制。
但 M2 团队发现:
Anthropic API 虽然原生支持该能力,但社区对 Claude 之外的模型支持得较少,并且许多应用在其 Anthropic API 的实现中仍然没有回传之前的思考过程。这种情况导致 Interleaved Thinking 并没有得到良好的支持。而为了完全释放 M2 的全部能力,在多轮交互中保留思考过程至关重要。
M2 官方多项基准测试数据显示,在保留 Interleaved Thinking 思维状态完整后:
SWE-Bench Verified 提升 +3.3% ,
Tau² 提升 +35.9% ,
BrowseComp 提升 +40.1% 。
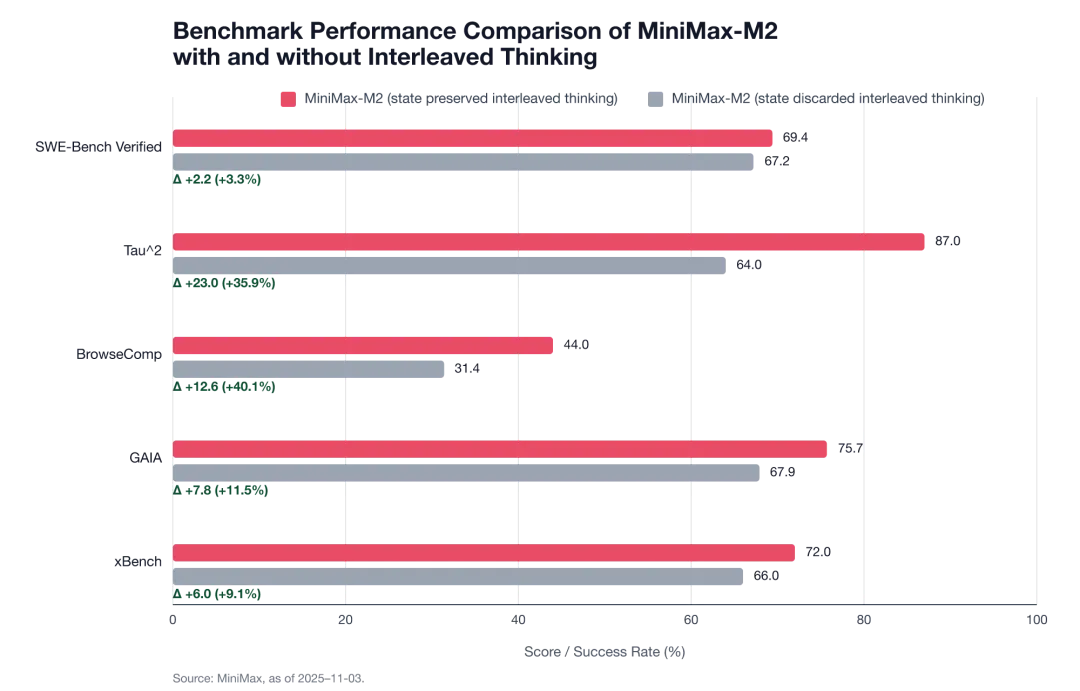
社区里也有相似的声音。

在上图的帖子中,作者同样指出,Interleaved Thinking 这一机制在实际编码任务中非常有效,但由于支持不完善,比如在自托管的情况下,如果缺乏对 Interleaved thinking 的系统支持(如代理框架、模板、工具链),模型的能力容易被削弱。
推文的最后提到需要更多 OSS 工具和社区贡献来真正发挥 Interleaved thinking 方法的潜力。

Full attention
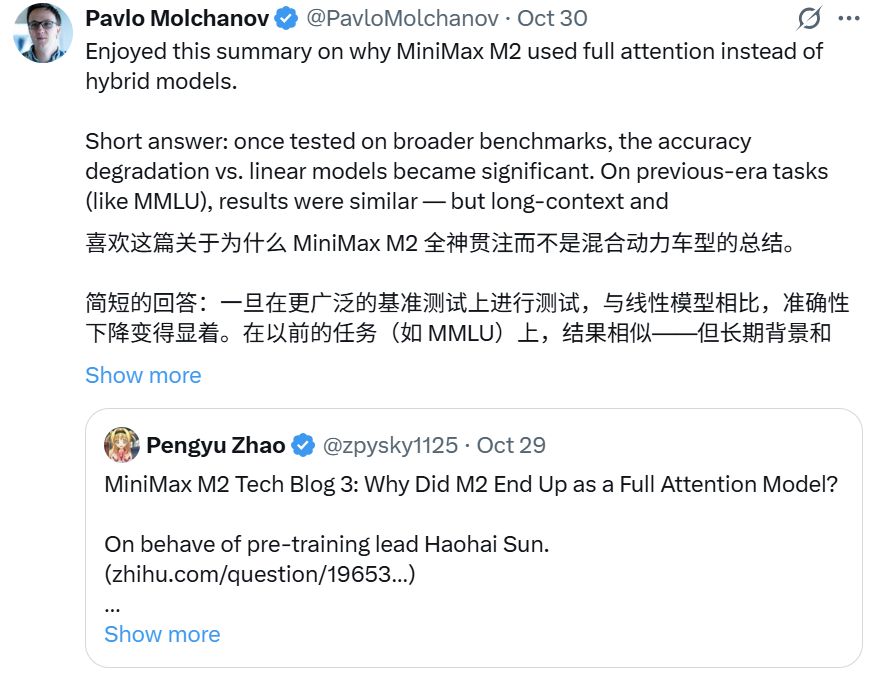
另一个引起社区热议的设计,是 M2 “倒回去”使用 Full Attention ,而几乎其余所有模型都在向高效注意力(如线性/混合注意力)迁移。
对此,M2 团队也专门写了一篇博客。
对旧任务( MMLU 等短上下文任务),线性/混合注意力模型表现差不多。
对新任务(长上下文、agentic 任务),full attention 明显优于线性/混合注意力。
尤其是对于需要长链推理、跨工具操作、agentic 行为的场景,full attention 往往会带来更可靠、更稳健的表现。
因此,即使 full attention 可能会带来更大的计算开销,但对于 M2 这样的长上下文、多任务、agentic 模型,这样的设计决策保证了精度和推理能力。
来看看转帖的英伟达研究总监 Pavlo Molchanov 具体说了什么:

他总结了 M2 选择 full attention 的原因,还提出了层间混合融合在之前的 Hymba 研究中发现能够帮助计算均衡。
还有网友发长文分享自己过去的实验经验,支撑了 M2 的观点:there is no free lunch 。
在 Agent 工作流中,模型需要跨多个工具、跨上下文反复验证与调整。Hybrid Attention 虽然省算力,但容易造成上下文信息缺失,导致逻辑中断。
过去在小规模或传统 benchmark 上,hybrid attention 看起来和 full attention 的表现差不多,但在大模型或更复杂任务(如多跳推理、长上下文)中,hybrid attention 会明显掉性能。
他还通过 Sparse Frontier 研究提出:
压缩注意力会削弱模型容量,压缩越多,模型能力越低。
模型是否能容忍压缩,取决于模型初始能力 C 和 任务难度 D :
如果 C ≫ D → 可以大量压缩而不掉性能
如果 C ≈ D → 小幅压缩也会导致性能崩溃
最后,推文强调了 benchmark 的重要性。很多论文报告 “ no accuracy drop ”,只是因为 benchmark 太简单,没有逼近模型能力上限。
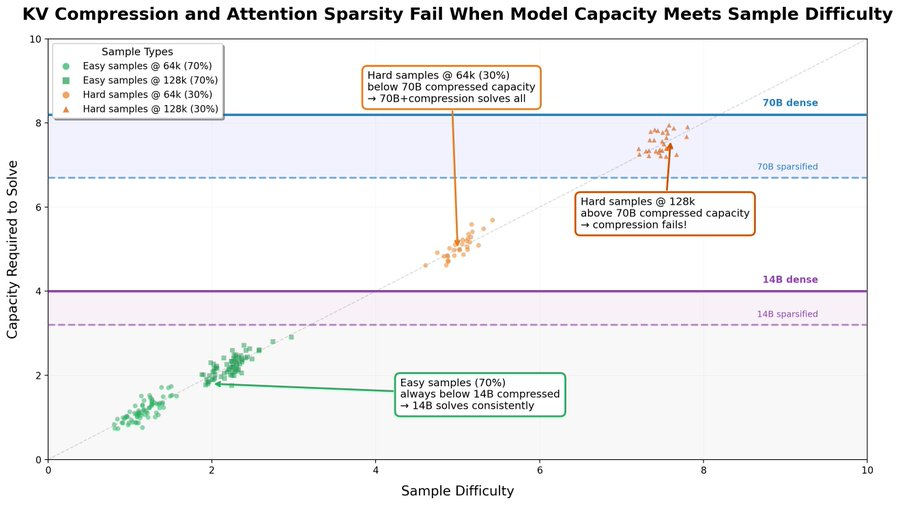
长上下文、多跳推理、agentic 类任务才能真正测试出 full attention 的优势。
对于采用 full attention 之后的下一步,M2 团队已经有所计划:上下文缩放是关键问题之一。
团队也开始着手准备:
-
更好的数据:更多的多模态、信息丰富的长上下文数据。
-
更好的评估:信息更丰富的评估系统和实验范式,以加快迭代速度。
-
更好的基础设施:成熟的训练和推理基础设施,充分榨取 GPU 潜力。
推理数据构造
让社区感到意外的还有 M2 的推理团队几乎完全由实习生组成。

这波实力秀的是真可以。这也体现出可靠的数据管道能够有效保证数据输出的一致性和团队协作的效率。
具体怎么做的?接着往下看。
过去大家提升推理能力时,主要集中在改进 RL 算法或构造可验证的数据(如数学、代码),而 M2 项目进行了更“通用”的探索。
首先,团队对 CoT (思维链)和回答质量的标准进行了探索。
高质量的 CoT 应该逻辑完整且不过分冗余。
关于回复质量,一些模型会为了刷榜成绩而过度拟合某些基准格式模式。而 M2 在合成推理数据时,引入格式多样性,也显著提升了模型的多任务泛化能力。
同时,团队相信,每个坏案例都有其相应的脏训练数据。他们使用规则 + LLM-as-a-judge 进行数据清理并不断迭代这种错位消除管道。
团队还有一个有意思的发现是:更难、更复杂的查询对模型训练更有效。
虽然数学和代码这两类数据带来的推理能力往往有利于所有任务,但模型仍然需要足够多样化的数据来涵盖更多领域,进而实现多样化的推理。
团队也因此针对性地调整了数据的分布,给模型喂更丰富的数据。
三、最后
短短一周,外网上 M2 相关的帖子就跟滚雪球一样,这不仅仅是因为模型的性能突出,也离不开 MiniMax 团队开放、透明、持续分享的态度。
这里整理好了 M2 团队相关技术博客的链接,感兴趣的小伙伴可以去看看,我相信一定会受益匪浅。
https://x.com/olive_jy_song/status/1983094612710568380
https://x.com/JinZhu8614/status/1983171865674920283
https://x.com/zpysky1125/status/1983383094607347992
此外,MiniMax Agent 已经上线,由 MiniMax-M2 模型驱动。
它提供了包括 pro 专业模式和 lightning 高效两类模式。目前全球正限时免费使用中。
机不可失,赶紧亲自体验一下吧~
体验链接:
https://agent.minimax.io/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)