Agent系统评估、错误分析、组件评估、改善效果、成本优化......——吴恩达Agentic AI课程第四节详细解读
在写Agent/LLM应用时,你是否对于何时引入/如何引入评估系统毫无头绪?你是否对于哪里出了问题/效果不好,以及如何提升效果一筹莫展?本文将与你一起探讨如何使用评估系统和错误分析构建出健壮的AI应用,以及如何精准提升系统效果,搭建出高效的AI工作流。
一、 评估(Evals)——构建Agent工作流的实用技巧
在构建Agentflow/Workflow时,如何提升效果是个重要问题。而想提升效果,就要研究到底是哪个环节导致了效果变差——此时,就要请出我们的评估系统了。
和刀耕火种的肉眼观察法不同,构建评估测试集可以让你的Agent系统拥有客观的,可溯源的,易于扩展的评估方式。但是很显然,在项目刚启动时,从哪里开始评估似乎是个模糊的问题。
此时,快速原型和迭代是关键。推荐采用快速而粗糙的迭代方法:
- 先构建一个非常简易,但功能完整的原型系统。
- 试运行并观察输出,找出表现不佳的地方。
- 利用观察结果来确定后续开发工作的优先级和方向,避免脱离实际过度空想。
理论总是抽象的,所以接下来我们看两个构建测试集的例子:
案例一:发票处理工作流程(提取到期日)
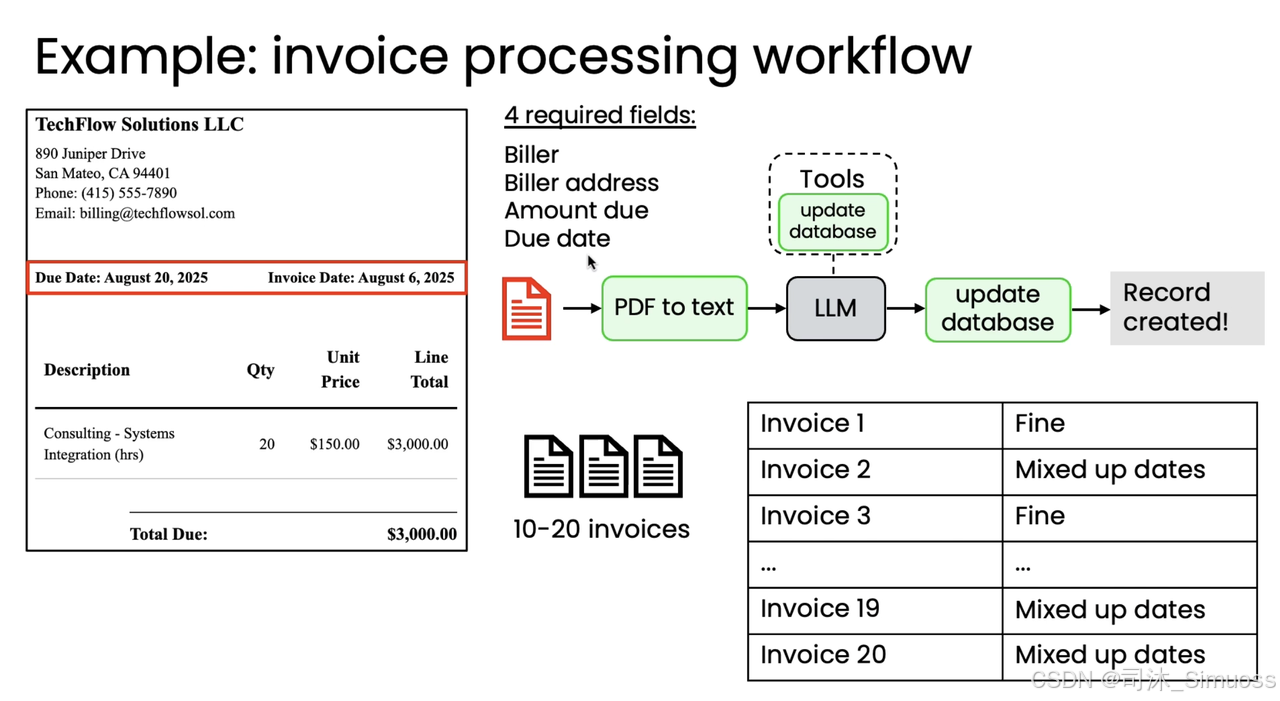
本系统想要从发票中提取四个必填字段并保存,特别是到期日,用于及时付款。
通过手动测试并检查 10-20 张发票的输出,发现一个常见的出错点是系统混淆了发票的开具日期和到期日。

进而,我们需要改进系统以更好地提取到期日,并编写一个评估(Eval)来衡量日期提取的准确性。
具体怎么构建这个评估呢?
- 测试集: 找到 10-20 张发票,人工记录每个发票的正确到期日,作为正确对照。
- 标准化格式: 在提示词中要求 LLM 始终以固定的年-月-日格式输出到期日,便于代码自动检查。
- 评估方式: 编写代码(如正则表达式)提取日期,然后测试提取出的日期是否等于基本事实日期。
- 用途: 调整提示或其他系统组件后,用这个指标的变化来衡量准确率是否有提升。
总结一下我们的改进流程: 构建系统 - 查看输出 - 发现错误 - 针对重要错误建立小型评估 - 调整系统以提高评估指标。
案例二:营销文案助理(限制字数)
本系统希望实现为 Instagram 图片生成标题,要求标题最多 10 个词。
通过观察输出,发现生成的文案内容还不错,但经常超过 10 个词的长度限制。
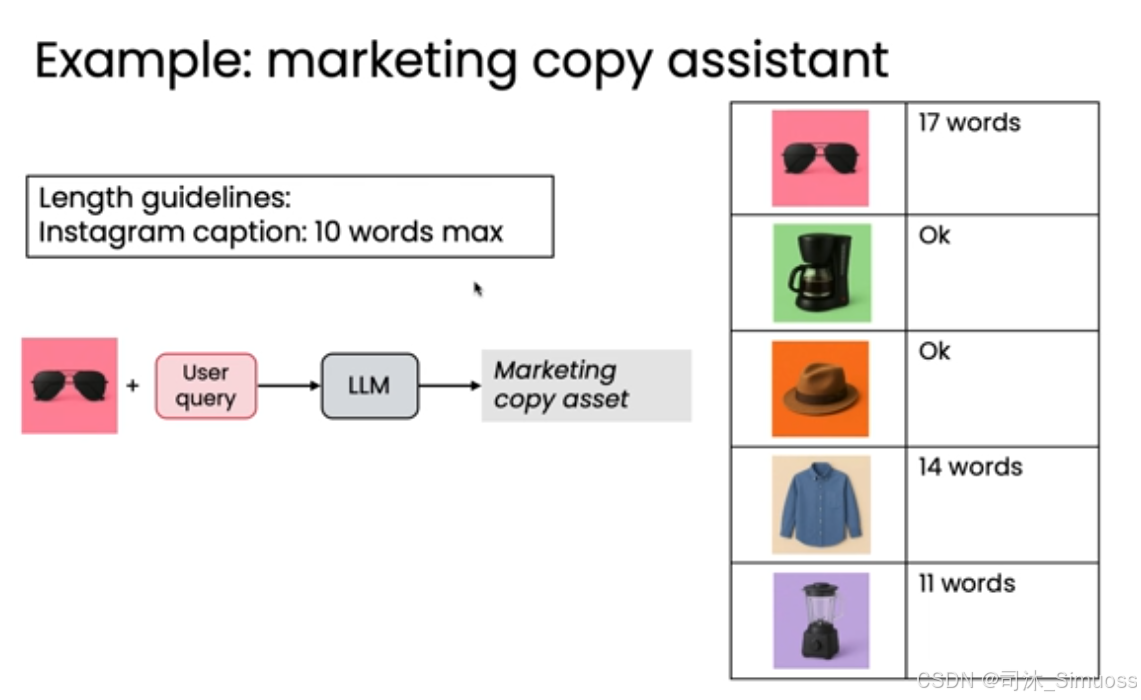
于是很显然的,我们就可以这样构建评估:
- 测试集: 准备 10-20 个测试任务,如太阳镜、咖啡机图片和对应的提示词。
- 评估方式: 编写代码计算输出的词数。
- 判断标准: 将生成的文本长度与 10 个词的目标限制进行比较。
- 与案例一的区别: 这个评估没有每个例子的基本事实,因为目标(10 个词)对所有例子都是一样的。
上面两个案例比较好做,因为AI输出可以被代码格式化,比如判断日期,判断长度。但是如果是“内容讲的对不对”这种比较抽象的评估,如何构建呢?我们来看下一个例子:
案例三:研究Agent(捕捉重要观点)
我们希望Agent能够根据用户输入的主题,如黑洞、机器人采摘,撰写研究文章。
通过检查输出,我们发现对于人类专家撰稿人会捕捉到的高知名度或重要观点,Agent生成的文章有时会遗漏。
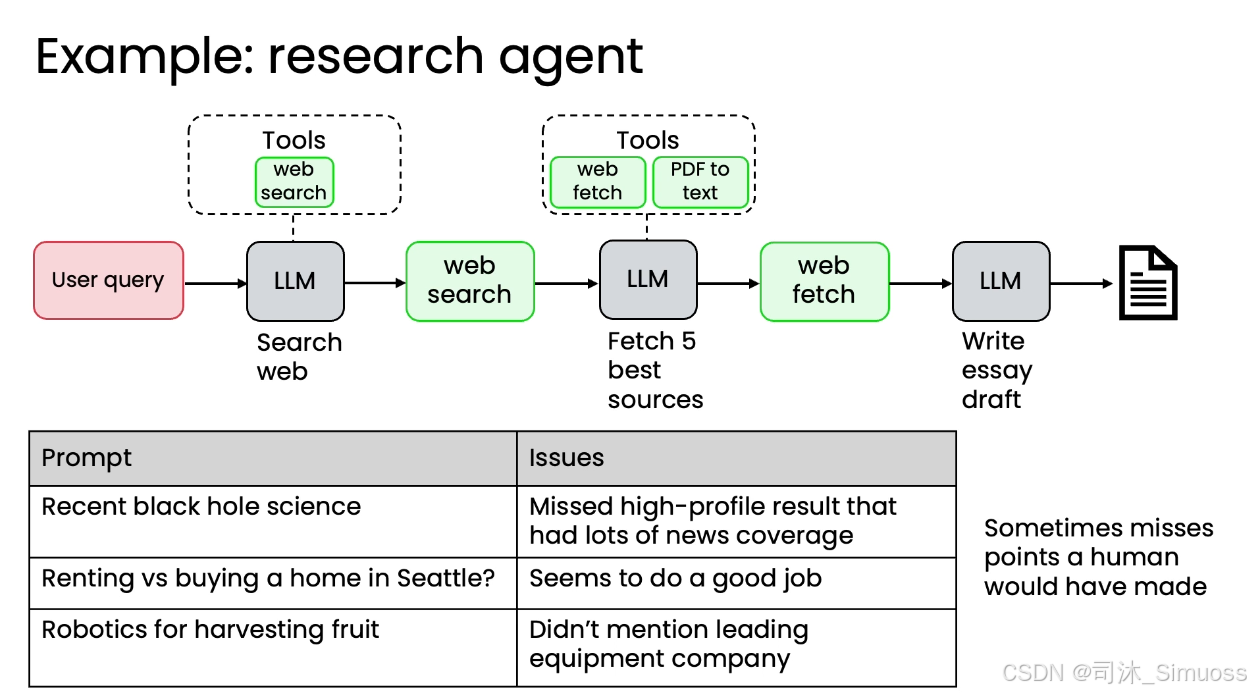
所以我们可以这样构建评估:
- 测试集: 针对每个场景,人工准备 3 到 5 个黄金标准讨论点作为每个例子的正确范例。
- 评估方式: 由于提及这些观点的方式多种多样,简单的代码匹配不可行,因此使用 LLM 作为裁判员。
- LLM 提示词: 要求评判 LLM 统计文章中提到了多少个黄金标准点,并返回得分和解释。
现在,我们基本上了解了如何对系统进行评估。
评估方式可以从两个维度划分,形成一个 2x2 的矩阵,用于指导评估的设计:
| 评估维度 | 客观评估 (Objective Evals) (用代码检查) | 主观评估 (Subjective Evals) (用 LLM 作为评判者) |
|---|---|---|
| 有每个例子的基本事实 (Per-Example Ground Truth) | 案例一:发票日期提取 (每个发票有不同的正确日期,用代码检查是否匹配) | 案例三:统计黄金标准点 (每个主题有不同的重要观点,用 LLM 检查是否充分提及) |
| 无每个例子的基本事实 (No Per-Example Ground Truth) | 案例二:营销文案长度 (所有标题都要求是 10 个词,用代码检查是否符合统一标准) | 评分标准评估 (Rubric Grading) (例如,根据统一的清晰度评分标准来评估图表) |
以及重申一下本节提到过的技巧:
- 从快速而粗糙的评估开始: 不要因为觉得评估是一个大型项目,就不敢轻易建立,或者花漫长的时间去做理论调研。先用 10-20 个例子开始,快速获得一些指标来辅助人工观察。
- 迭代改进评估:
- 随着系统和评估的成熟,可以增加评估集的规模。
- 如果系统改进了但评估分数没有提高,意味着该改进评估本身了。
- 以专业人士的行为为灵感: 对于自动化人类任务的系统,观察系统在哪些方面性能不如人类专家,以此作为下一阶段工作的重点。
二、Agent工作流的错误分析 (Error Analysis)
在复杂的Agent工作流中,通过系统性的错误分析来确定工作重点,是提高系统改进效率的关键。
对大多数初学者而言,错误分析好像并不是一件值得去做的事——我能用半天就搭起一个运行效率不错的Demo系统,为什么还要花更多的时间写一个可维护的错误分析系统呢?
但是,当Agent系统已经MVP,或者即将投入生产时,系统可能已经变得十分复杂。这时候如果仍像Demo阶段依赖直觉,就对直觉准度提出了极大的考验——到底是哪一环节出了影响效果的问题,或者还有提升空间?要不要单独拆出来跑?如果拆出来按单元跑,要不要Mock数据?如果系统需要经常更换底层LLM,风险就更大了。
所以,从一开始就将错误分析纳入计划,有利于在项目复杂化,工程化后仍能很好地管理。比如在多次测试后,发现总有一些组件或步骤很稳定,而另一些很容易受模型或输入格式的影响,这就帮助了我们深入理解系统,也能锻炼我们的Agent直觉。
那么,应该如何进行错误分析?
错误分析的核心是观察和量化,以找出工作流程中表现最差的组件。
- 检查追踪 (Traces) 和中间输出
- 定义: Agent在运行过程中,每一步产生的中间输出的整体集合被称为追踪 (trace)。单个步骤的输出有时被称为 span。
- 方法: 查看追踪,观察每个步骤的输出质量,先笼统了解哪个组件出了问题。
- 示例:比如针对一个科研资料查询的Agent
- 步骤 1:生成搜索词 - 请人类专家判断搜索词是否合理。如果合理,则搜索关键字生成组件没问题。
- 步骤 2:网页搜索结果 - 检查返回的 URL 和文章质量。如果返回了太多非科学的博客或大众媒体文章,则搜索引擎是问题所在。
- 步骤 3:信息筛选 - 如果提供给LLM的文章有好有坏,但LLM选择了其中比较夺人眼球的水文,而不是严肃的科研文章,那LLM的型号或提示词就是问题所在。
- 聚焦错误案例并量化
- 聚焦错误: 将精力集中在最终输出不令人满意的少数案例上,而不是那些运行良好的案例。
- 建立电子表格进行量化: 为了更严谨地分析,可以建立一个电子表格,明确地统计每个组件出现“错误”的频率。
- 错误的定义: 某一步的输出明显差于一个人类专家在给定相同输入时会给出的结果。
- 统计示例: 记录在所有被分析的错误案例中,搜索词不佳的比例、搜索结果不佳的比例等。
- 指导决策: 如果发现对搜索结果不满意的频率远高于对搜索词不满意的频率(如 45% vs 5%),那么工作重点就应放在改进网页搜索引擎或调整其参数上,而不是更改搜索词的生成逻辑。
接下来,我们到一些实际案例里,看看如何做错误分析。
- 案例一:发票处理(也就是我们在第一节见到的)
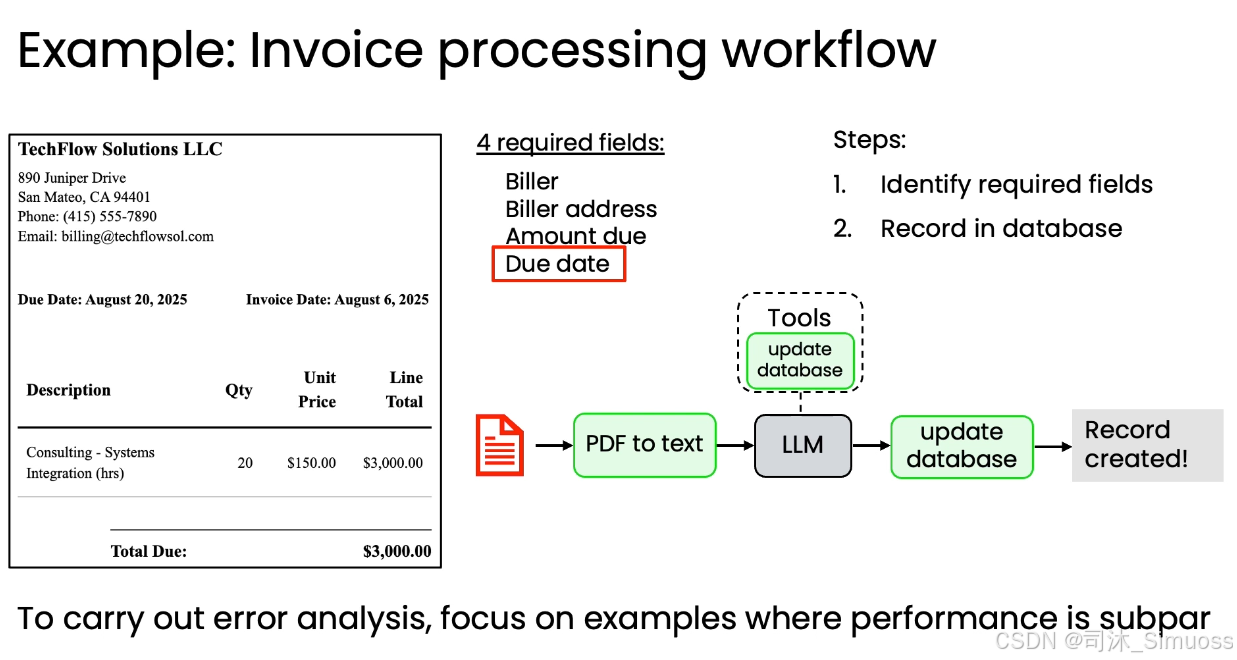
工作流程: PDF - (PDF 转文本) - (LLM 数据提取) - 数据库记录。
发现问题: 提取的到期日经常出错。
收集错误样本: 忽略正确的发票,收集 10 到 100 张到期日提取错误的发票。
定位错误来源:
- PDF 转文本错误: 文本提取太差,导致连人类都无法识别到期日。
- LLM 数据提取错误: PDF 转文本的输出足够好,但 LLM 却错误地拉取了其他日期(如发票日期而非到期日)。
结果指导: 假设统计发现 LLM 数据提取导致了更多的错误。
结论: 应将精力集中在改进 LLM 数据提取组件上(如优化提示词),而不是花费数周时间徒劳地改进 PDF 转文本组件。
- 案例二:回复客户邮件

工作流程: 客户邮件 - (LLM 编写数据库查询) - 数据库 - (LLM 起草回复) - 人工审核。
发现的问题: 最终邮件回复不令人满意。
收集错误样本: 收集最终回复不令人满意的客户邮件。
定位错误来源:
- LLM 查询编写错误: LLM 编写了错误的 SQL 查询,导致无法获取客户信息。
- 数据库数据错误: 数据库数据损坏或不正确,即使查询正确也无法获取正确信息。
- LLM 邮件撰写错误: 即使获取了正确信息,LLM 撰写的邮件内容或语气不妥。
结果指导: 假设统计发现,LLM 编写数据库查询是最常见的错误(例如,占所有问题的 75%),而 LLM 撰写邮件的错误相对较少(例如 30%)。
优先级:首先改进 LLM 编写查询的方式,随后改进撰写最终邮件的提示词。
三、组件级评估 (Component-Level Evals)
在上一节中,我们通过错误分析确定了要改进的单个组件,那么之后就是引入组件级评估针对性改进。
端到端评估和组件级评估的关系有些类似端到端测试/集成测试与单元测试:
- 端到端评估成本高昂,即使是更换搜索引擎这样的小改动,都需要重新运行整个复杂的工作流程进行端到端评估,时间和金钱成本很高。同时,其他组件的随机性或噪声可能会掩盖被改进组件带来的微小、增量改进。
- 组件级评估更高效, 信号更清晰,避免了整体系统的复杂性带来的噪声。还适用于团队分工: 如果有多个团队分别负责不同组件,每个团队可以自行维护指标。
接下来,我们以研究Agent的网页搜索为例,构建组件级评估。
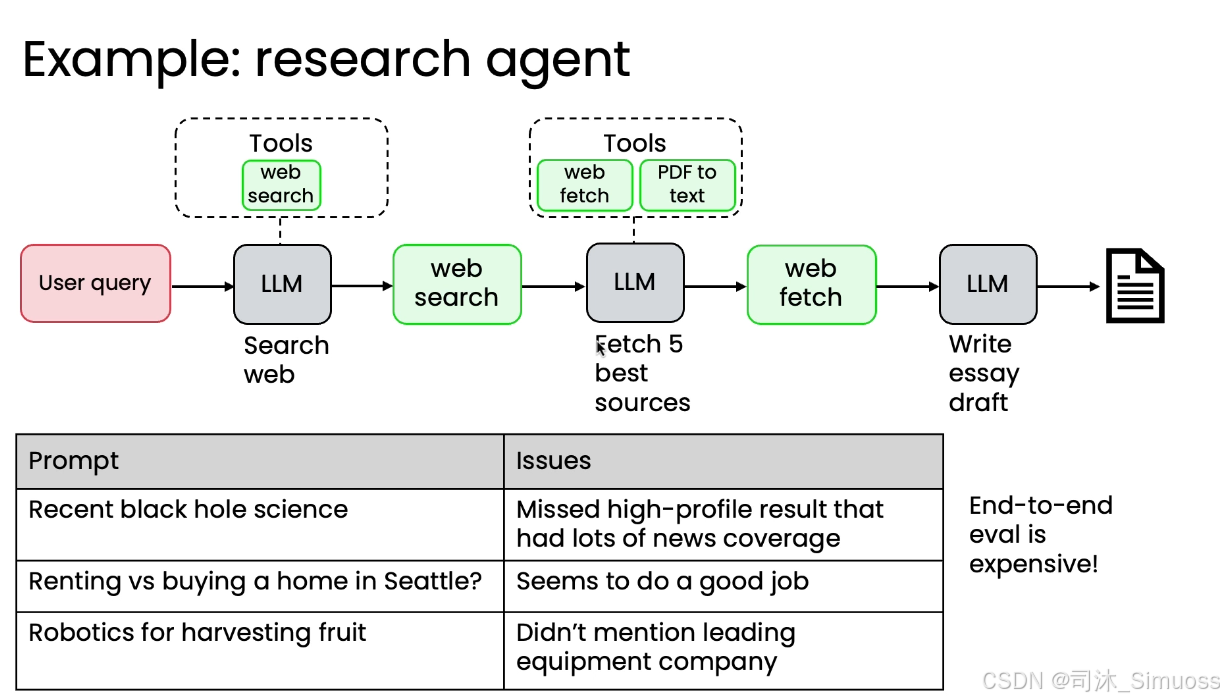
- 问题: 错误分析表明研究Agent遗漏关键点的问题主要出在网页搜索组件上。
- 构建评估方法:
- 创建测试样例: 针对少数几个查询,请人类专家提供一份黄金标准网页资源列表,即最权威、最应该找到的网页。
- 编写评估代码: 使用信息检索领域的标准指标(如 F1 分数),编写代码来衡量网页搜索的输出列表与黄金标准列表之间的重叠程度。
- 用途:
- 利用这个指标,开发者可以快速高效地调整网页搜索组件的参数或超参数,如更换搜索引擎、更改结果数量、调整日期范围。
- 快速实现增量改进:在调优过程中,可以快速判断网页搜索质量是否提高。
组件级评估与端到端评估的关系与顺序如下:
- 通过错误分析确定一个问题组件(如网页搜索)。
- 构建和使用组件级评估来高效地进行调优和增量改进。
- 在调优后,运行最终的端到端评估,以验证组件的改进确实提升了整个系统的整体性能。
四、改进Agent工作流组件的方法与模型选择技巧
在跑了评估,找到问题后,就要开始着手修改了。本节介绍的正是如何改善系统中不同组件的效果。
对于非 LLM 组件,比如网页搜索、RAG 检索、代码执行、传统 ML 模型来说,改进方式非常多样。
- 调整参数或超参数:
- 网页搜索: 调整结果数量、日期范围等。
- RAG 检索: 更改相似度阈值、文本分块大小等。
- 人物检测: 调整检测阈值,以权衡误报和漏报。
- 替换组件: 尝试更换不同的服务提供商,如不同的 RAG 搜索引擎、不同的 Web 搜索 API找到最适合系统的一个。按笔者经验,在国内查询企业营收报表和财务信息,使用百度搜索的效果就远超Bing或Google,但查询学术资源却完全相反。
对于LLM 组件,改进主要围绕输入、模型本身和工作流程结构展开。
- 改进提示词:增加明确指令(在提示词中指明一些资源和任务应有的规划路径,而不是让LLM自己猜);使用少样本提示 (添加具体的输入和期望输出示例)
- 尝试不同的 LLM: 不要嫌麻烦,多测试几款 LLM,并使用评估 (Evals) 来选择最适合特定应用的最佳模型。
- 任务分解:如果单个步骤的指令过于复杂,导致 LLM 难以准确执行,考虑将任务分解为更小的、更易于管理的步骤,比如拆成生成步骤 + 反思步骤,或连续多次调用。
- 微调模型:这是最复杂、成本最高的选项。只有在穷尽所有其他方法后,仍需要挤出最后几个百分点的性能改进时才考虑。它适用于更成熟且性能要求极高的应用。
如果你之前也做过类似工作,那你一定拥有一定程度的模型选择直觉
比如笔者对于当前时间节点(2025年11月初)的模型,就认为Qwen比较嘴硬,Gemini2.5比较逆来顺受,GPT比较言简意赅,DeepSeek比较有创意和鬼点子。不同模型擅长的领域也不一样,比如Gemini对一口气生成上千行代码非常在行,而Claude对在现有系统里做小范围修改更有心得。如果谈到具体任务,那么嘴硬的Qwen就更适合用作一些比较严谨的,比如数据报表查询场景。又比如非常有逻辑但容易过度自信的KimiK2,就能在中低难度场景以简短而有信服力的输出大放异彩,但在比较复杂的场景要做好它过于自信而出错的心理准备。
在模型层面以外,还有其他类型的直觉,比如在笔者感受中,大参数模型通常比小参数模型的情商更高,对模糊指令的理解能力更强。最典型的例子是今年年初发布的昂贵的GPT-4.5,甚至可以在时下流行的“山东饭局”风格高情商场景下讲出让人眼前一亮的回复。
又比如,新架构+大参数量的模型,一般在多步骤复杂指令的任务中,能够完美地列出并编辑所有敏感信息,而较小的模型容易出错或遗漏信息。
拥有对不同 LLM 能力的直觉,能使开发者更高效地选择模型和编写提示词。这样的直觉要如何培养?
- 频繁试玩不同模型: 经常测试新的闭源和开源模型,观察它们在不同查询上的表现。
笔者对自己的要求是,至少有3~5种主力使用的模型(同一提供商只计算一次),并保持一个月内至少使用过10种以上模型,并能报出20种以上模型的型号。
- 建立个人评估集: 使用一套固定的评估任务来校准不同模型的能力。
- 阅读他人的提示词: 大量阅读从业者、专家或开源框架中的提示词,了解不同任务/模型/场景下的最佳实践,提高自己编写提示词的能力。
- 在工作流程中尝试: 实际在Agent工作流程中尝试不同的模型,查看追踪 (Traces) 和组件/端到端评估,观察它们在特定任务中的性能、价格和速度的权衡。
五、Agent工作流的成本与延迟优化( Latency, cost optimization )
在系统输出质量达到要求后,下一个优化重点是:优化工作流程的延迟和成本。
需要强调的是,对于早期团队而言,高质量的输出,比延迟与价格重要得多,不应该首先把时间花在延迟与价格优化上。等系统已经运行良好之后,才应该将精力转向延迟优化;只有当系统有了大量用户,成本成了问题之后,才是开始集中优化成本的理想时机。
- 优化延迟与速度的方法
优化延迟的关键在于进行计时基准测试,找出工作流程中的瓶颈。
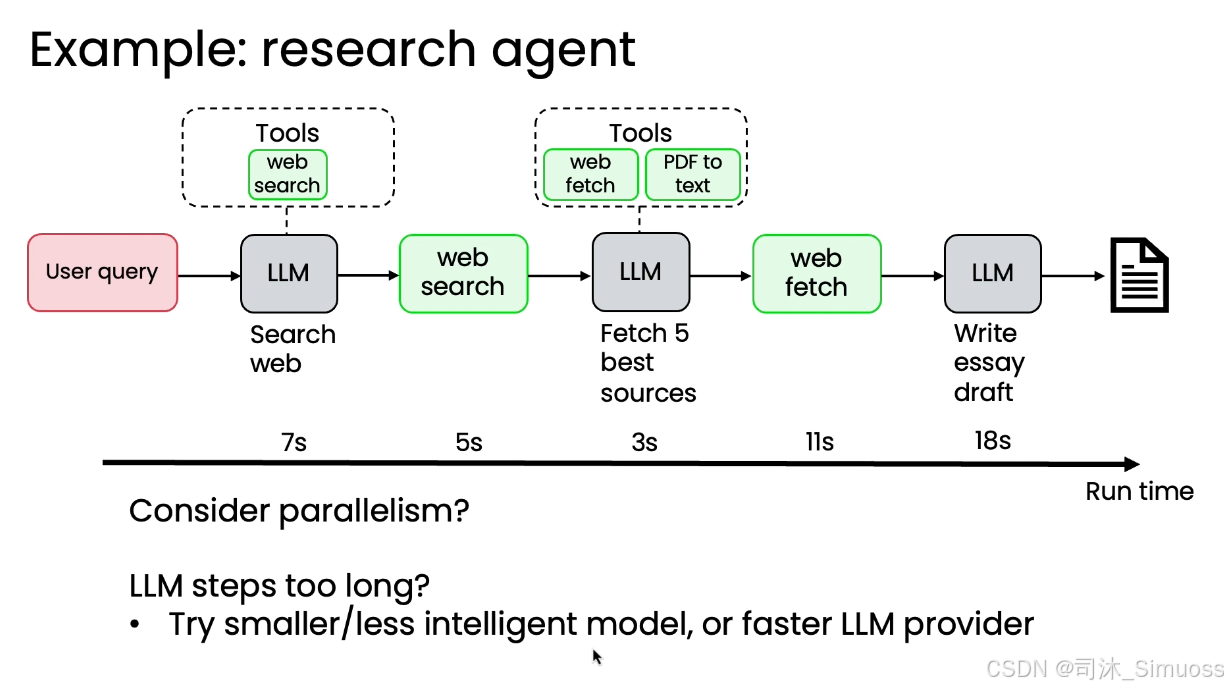
- 计时分析: 详细记录工作流程中每个步骤所花费的时间(例如:LLM 1 耗时 7 秒,LLM 3 耗时 18 秒)。
- 定位瓶颈: 通过时间线分析,确定耗时最长的组件,从而确定最大的提速空间。
- 优化手段:
- 并行化: 考虑将一些像是网页抓取之类的,可以独立进行的步骤并行执行。
- 更换 LLM: 尝试使用更小、更快(尽管可能稍不智能)的模型,或者测试不同的 LLM 提供商,以找到返回 token 最快的服务。
- 优化成本的方法
优化成本的关键在于进行成本基准测试,找出最昂贵的步骤。
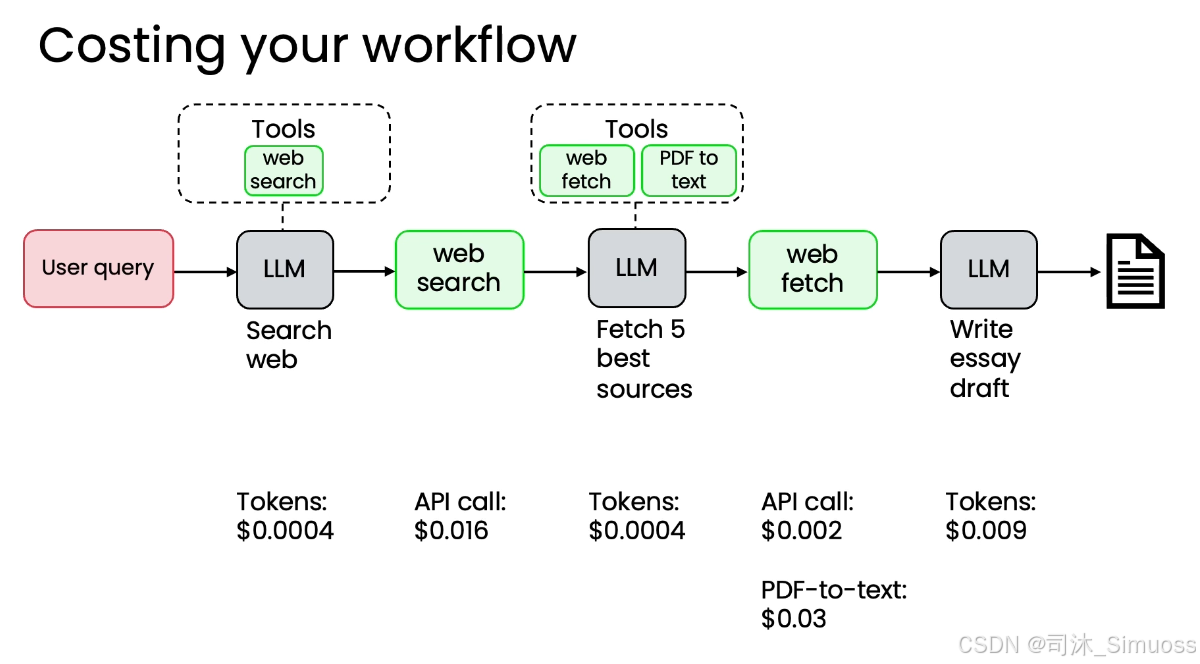
- 成本计算: 计算工作流程中每个步骤的平均成本:
- LLM: 按输入和输出的 Token 长度收费。
- API: 按调用次数收费。
- 计算/服务: 根据服务器容量、服务费等计算。
- 定位瓶颈: 确定成本贡献最大的组件。
- 优化手段: 寻找更便宜的组件或 LLM 来替代高成本的组件,以最大化成本优化机会。
六、详细总结:Agent系统开发流程与迭代循环( Development process summary )
对于我们开发者而言,在开发Agent工作流时,主要精力通常集中在以下两项活动中,并不断来回切换:
- 构建: 编写软件和代码来改进系统。
- 分析: 决定下一步将构建精力集中在哪里的过程,其重要性与构建相当。
而一个Agent系统从初始原型到成熟,分析工作的严谨性也随之提高,通常经历以下迭代阶段:
| 阶段 | 描述 | 主要活动 |
|---|---|---|
| 1. 快速原型 | 快速构建一个端到端系统(所谓的“先做个垃圾出来”)。 | 分析: 手动检查最终输出,通读追踪 (Traces),凭直觉找出性能不佳的组件。 |
| 2. 初步评估 | 系统开始成熟,超越纯手动观察。 | 分析: 构建初步的 端到端评估 (Evals),使用小型数据集(如 10-20 例)计算整体性能指标。 |
| 3. 严谨分析 | 系统需要更精确的改进方向。 | 分析: 进行错误分析,统计和量化各个组件导致次优输出的频率,以做出更集中的决策。 |
| 4. 高效调优 | 系统进一步成熟,需要在组件级别进行高效改进。 | 分析: 构建组件级评估,以便更高效地对单个组件进行调优。 |
显然,开发是一个非线性的过程,需要在调整系统、错误分析、改进组件和调整评估之间反复横跳。
许多经验不足的团队往往花太多时间在构建上,而太少时间在分析上,导致工作重点不集中,效率低下。
在早期,市面上有许多工具可以帮助监控追踪、记录运行时、计算成本等。团队可以尽情使用这些前人造的轮子。但由于大多数Agent工作流程是高度定制化的,所以团队最终仍需要自行构建许多定制化的评估,以准确捕获系统特有的问题。
只有一套系统化的开发流程(评估,错误分析,改进),才能支撑起足够复杂的Agent系统。
-
笔者本文为吴恩达教授在 DeepLearning.AI 推出的 Agentic AI 系列课程 DeepLearning.AI - Agentic-ai中第四模块的详细解读。
-
本文首发于Datawhale共学社区的Agentic-ai——吴恩达Agentic AI 系列课程解读,有兴趣继续学习大模型算法/开发等等其他领域,或深入学习其它AI内容的朋友可以看看Datawhale的仓库,一定会有惊喜~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)