【RL】强化学习基础原理
概念定义
强化学习(reinforcement learning RL) 讨论的问题是一个智能体(agent)如何在复杂不确定的环境(environment)中极大化的获取它能获得的奖励(reward)。通过感知所处环境的状态(state)对动作(action)的反应,来指导更好的动作,从而获得最大的收益(return),这样在交互中学习的方式被称为强化学习。
Reinforcement learning is learning what to do—how to map situations to actions——so as to maximize a numerical reward signal. ----- Richard S. Sutton and Andrew G. Barto 《Reinforcement Learning: An Introduction II》
智能体基于当前时刻从环境获取的状态,来决定采取什么动作。环境基于智能体的动作发生状态的改变,并给智能体一个奖励【可以是负的】,最终是为了获取所有奖励和,即收益的最大。
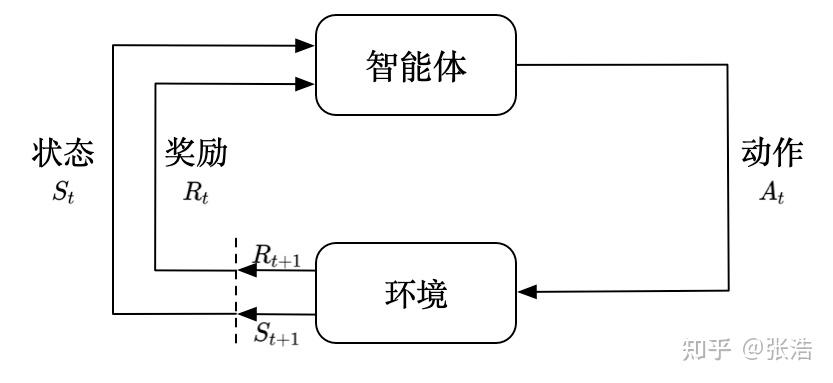
和机器学习的关系
机器学习分为三种方法:监督学习、无监督学习和强化学习
- 监督学习 是从外部监督者提供的带标注训练集中进行学习【任务驱动型】
- 无监督学习 是能从未标注训练集中寻找隐含结构的过程 【数据驱动型】
- 强化学习 侧重于智能体和环境的交互,在试错和开发中权衡,能从已有经验中获取收益,同时也要进行试探,使得未来可以获取更好的动作选择空间【从错误中学习】
强化学习的基础
特点
- 试错学习 强化学习一般没有直接的指导信息(训练数据集),Agent要不断与environment进行交互,通过试错来获得最佳策略(policy)
- 延迟回报 在最后才能做到return,如下围棋,结束时才知道胜负,中间下在位置1和位置2其reward可能都是0.
基本元素
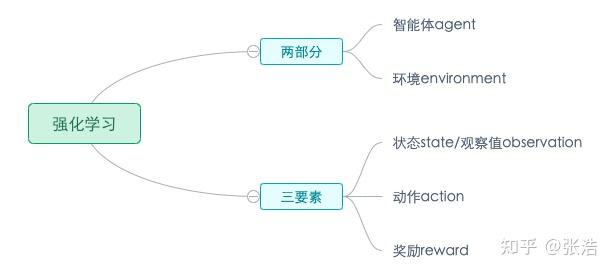
- 智能体 agent 相当于玩游戏的玩家,那个通过动作来使游戏(环境)的状态发生改变。
- 环境 environment 一个外部的系统,智能体在这个系统中能够感知这个系统的状态变化。
- 状态 state/观察值 observation 状态是对环境的完整描述,不会隐藏环境的信息,观察值是对状态的部分描述,可能会遗漏一些信息。
- 动作 action 不同的环境允许不同的动作,在给定的环境中,有效的集合经常被称为 动作空间 包括离散动作空间-走迷宫只有上下左右4种移动方式 和连续动作空间-机器人360度中的任意角度都可以移动。
- 奖励 reward 由环境给的一个标量反馈信号,这个信号表示智能体在状态 s1 下选择的 动作 a1 的表现怎么样
应用场景
- 游戏

- 机器狗
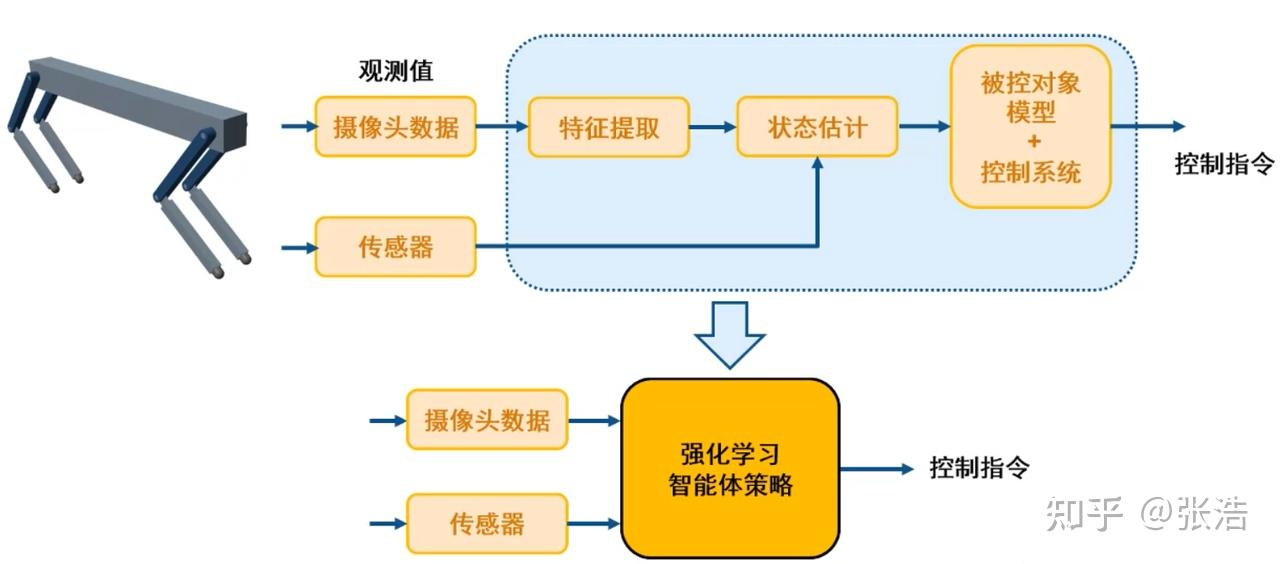
相关术语
-
策略 policy
智能体下一步执行说明动作的规则。可以是确定性的,表示为μ
a t = μ ( s t ) a_t = \mu(s_t) at=μ(st)
也可以随机,表示为 π π π
a t π ( . ∣ s t ) a_t ~ \pi(.|s_t) at π(.∣st) -
状态转移 state transition
可以确定也可以随机,其随机性来源于环境。以状态密度函数表示
p ( s ′ ∣ s , a ) = P ( S ′ = s ′ ∣ S = s , A = a ) p(s^{'}|s,a)=P(S^{'}=s^{'}|S=s,A=a) p(s′∣s,a)=P(S′=s′∣S=s,A=a)
环境是可以变化的 -
回报 return
所有收益的总和,表示为U
U = ∑ γ n r t γ ∈ ( 0 , 1 ] n = [ 0 , . . . , 1 ] U = \sum \gamma^{n} r_t \\ \gamma \in (0,1] \\ n =[0,...,1] U=∑γnrtγ∈(0,1]n=[0,...,1]
γ \gamma γ 为discount rate 折扣率 表示未来的奖励不如当前的等值奖励好 -
价值函数
使用期望对未来的收益进行预测,一方面不必等待未来收益实际发生就可获知当前状态的好坏,另一方面通过期望汇总未来各种可能收益情况,可以综合评价不同策略的好坏。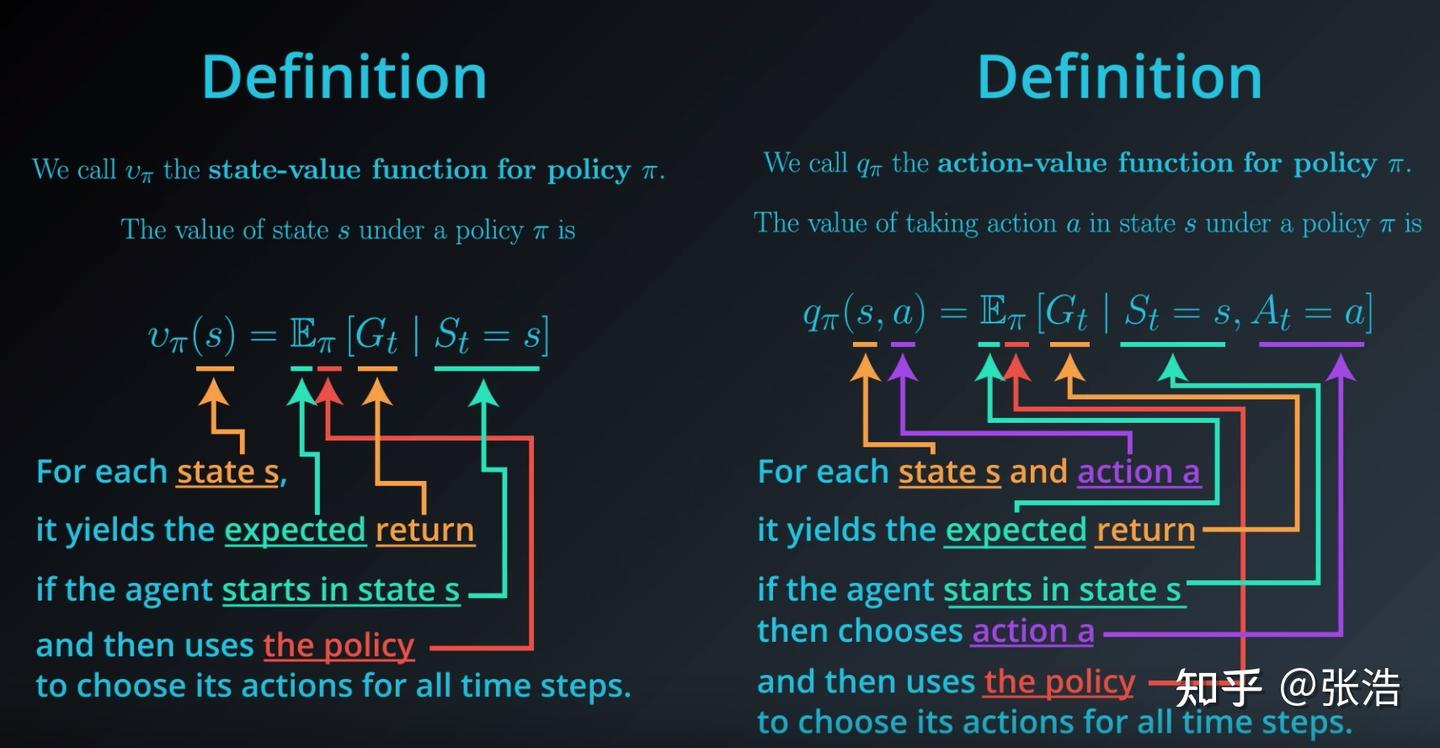
状态价值函数 state-value function 度量给定策略π的情况下,当前状态 s t s_t st的好坏程度
动作价值函数 action-value function 度量给定状态 s t s_t st和策略π的情况下,抽取动作 a t a_t at的好坏程度
算法分类
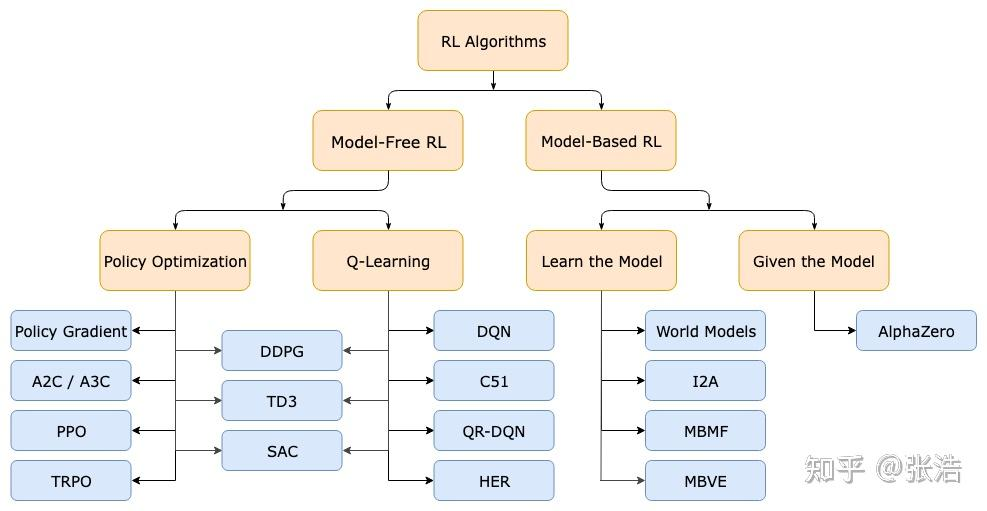
- 按环境是否已知划分 免模型学习 model-free 和有模型学习 model-based
– model-free 指不去学习和理解环境,环境给出什么信息就是什么信息,常见的为policy optimization和Q-learning
– model-based 是需要学习和理解环境,用一个模型来模拟环境,基于这个模拟环境来获取反馈。 - 按学习方式可划分为 在线策略 on-policy和离线策略 off-policy
– on-policy需要agent在场,边玩边学,典型算法是sarsa
– off-policy指agent可以自己玩或者看别人玩,通过看别人玩来学习别人的行为准则。从过往经验中学习,玩和学的时间可以不同。典型方法是Q-learning 及Deep-Q-Network - 按学习目标划分 基于策略 policy-based和基于价值 value-based
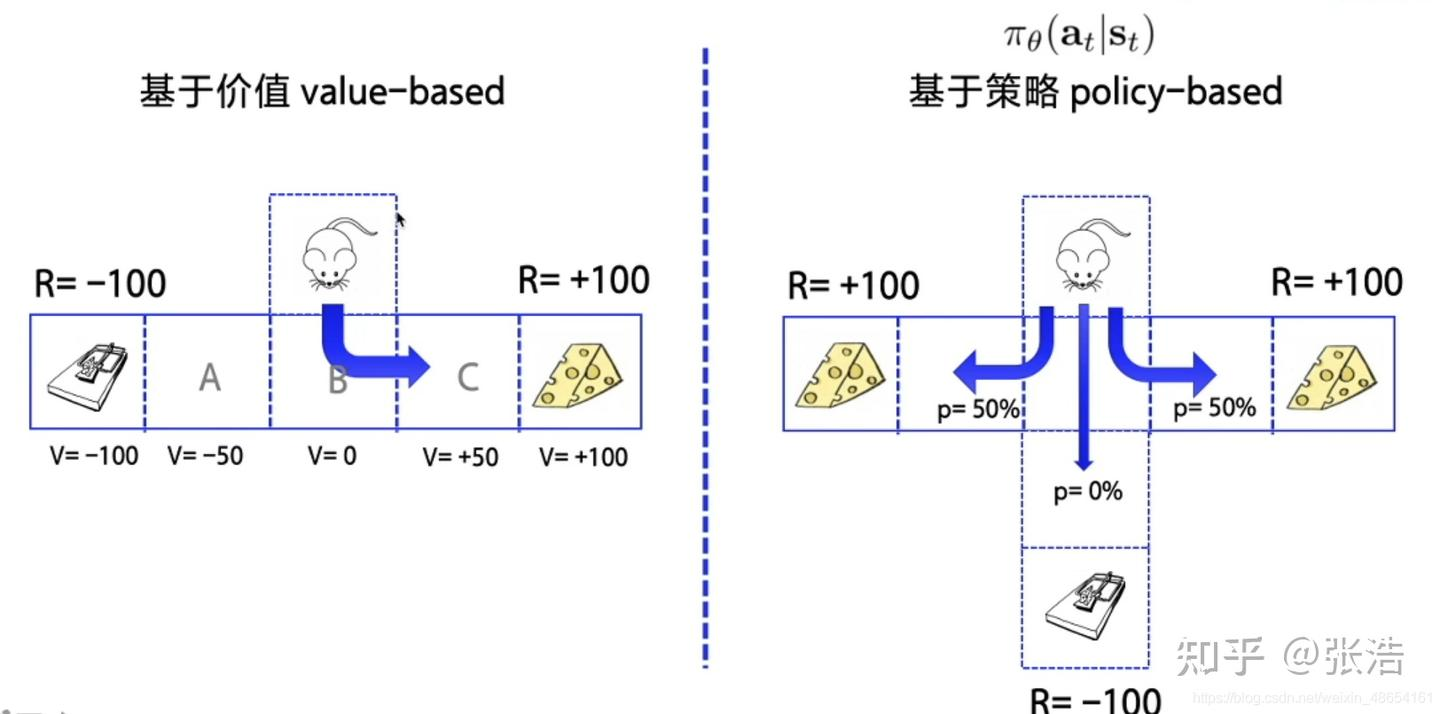
- policy-based 输出下一步动作的概率,根据概率来选取动作。但不一定概率最高就会选择该动作,还是会从整体考虑。适用于非连续和连续的动作。常见的方法有policy gradients
- value-based 输出动作的价值,选择价值最高的动作。适用于非连续的动作,常见算法为Q-learning,DQN和sarsa
- actor critic 结合两者,actor根据概率做动作,critic根据动作给出价值,常见的有A2C,A3C,DDPG等
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)