FlagOS的Triton算子实现RWKV最新模型端到端推理性能提升135%
FlagOS 社区致力于打造相面多种 AI 芯片的统一、开源的系统软件栈,包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离,有效降低开发者的迁移成本。相比普通的神经网络,RNN 最核心和最本质的特征是,它像一个有“记忆”能力的人一样,能够把过去的信息和当前
这两天,LLM 圈儿发布了不少新模型。“后 Transformer 时代”极具潜力的 RWKV 模型代表,接连对外发布并开源了两个模型——RWKV7-G0a3 7.2B 和 RWKV7-G0a3 13.3B。经过评估,RWKV7-G0a3 7.2B 和 RWKV7-G0a3 13.3B 无论是在语言建构和理解力上,数学问题解题能力上,还是多学科综合知识面上,均表现出“最强纯 RNN 语言模型”的实力。
RNN 语言模型是什么?它是指那些采用了“循环神经网络”的语言模型。相比普通的神经网络,RNN 最核心和最本质的特征是,它像一个有“记忆”能力的人一样,能够把过去的信息和当前的信息结合起来,产生更准确的理解能力。而 RWKV 则是 RNN 这个方向上最具代表性、也是最先锋的探索者之一。
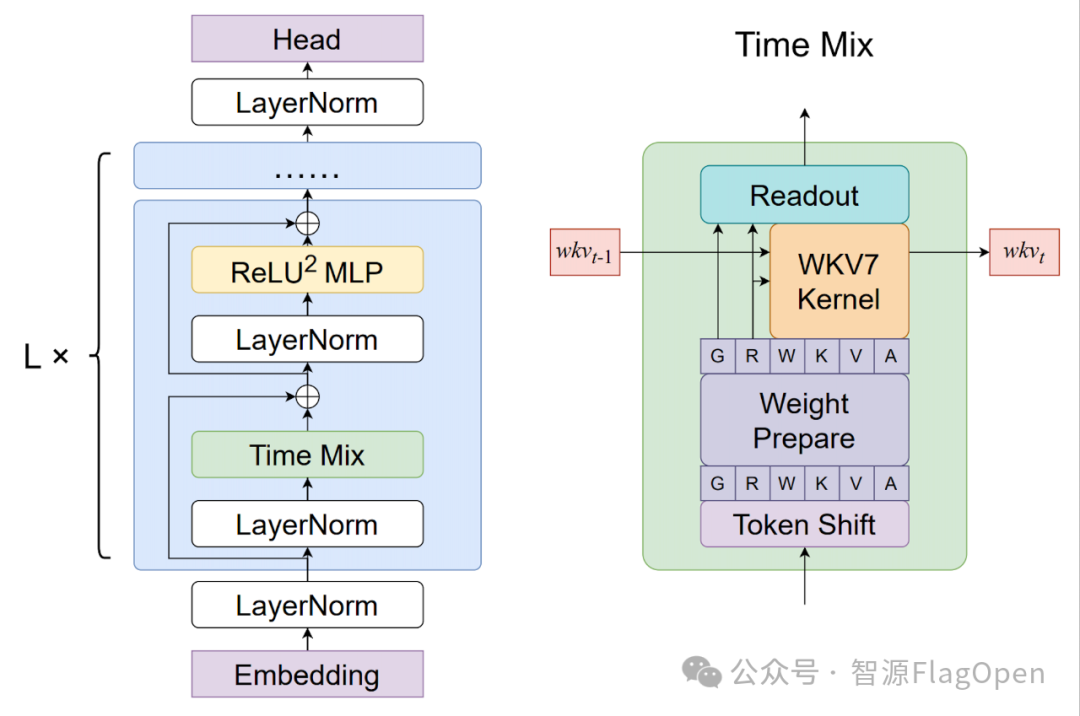
RWKV 模型架构图
RWKV 模型创新性地汲取了 Transformer 和 RNN 两者的精华。通过巧妙的数学设计,将 Transformer 的注意力机制重新表述为一种线性递归的形式。既保持了 Transformer 的并行训练能力,利用 GPU 进行大规模高效训练,同时也汲取了 RNN 的高效序列推理能力,在无限长上下文,可以恒定内存和线性计算的复杂度。

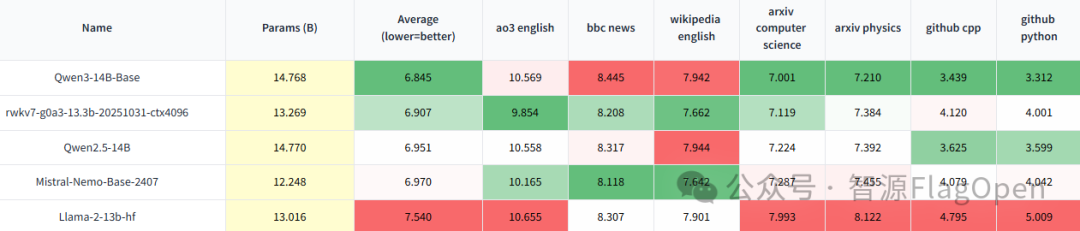
RWKV7-13.3B的模型性能
(图片来自公众号“RWKV元始智能”)
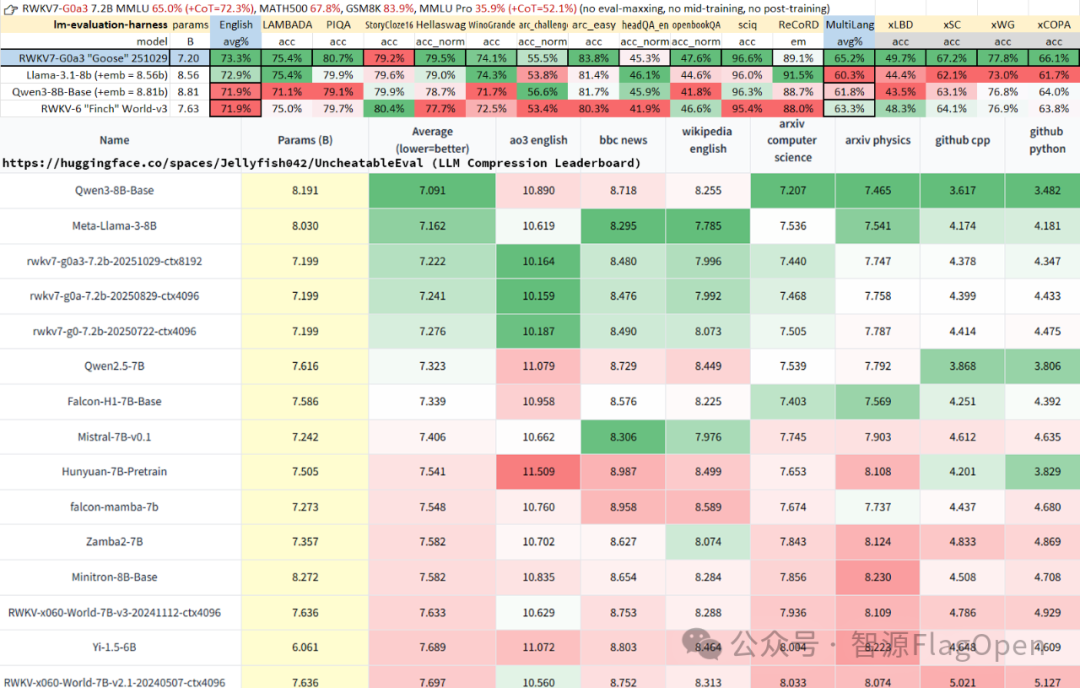
RWKV7-7.2B 的模型性能评估
(图片来自公众号“RWKV元始智能”)
RWKV 最新发布的 RWKV7-G0a3 7.2B 和 RWKV7-G0a3 13.3B 两款模型,都有用到 FlagOS 社区高性能通用算子库 FlagGems 的算子支持。从上图可以看出,RWKV7-7.2B 和 RWKV7-13.3B 在权威基准测试集 MMLU、MATH500、GSM8K 等的得分表现可达到70%左右,在比较难的 “MMLU Pro 竞技场”也获得了35.9%-49.8%的关键表现。
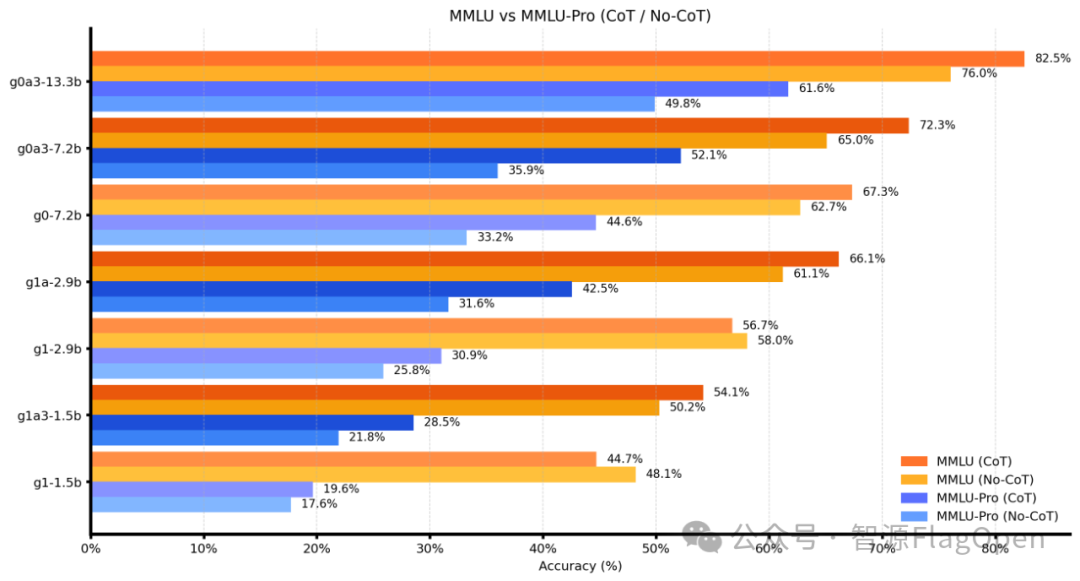
FlagOS 联合 RWKV 优化推理效率,端到端性能大幅提升
此次发布的最新版 RWKV7-G0a3 13.3B 推理模型中,FlagOS 社区和 RWKV 联手优化模型推理效率。通过使用 FlagOS 的 FlagGems Triton 语言算子库,RWKV 模型在保持精度不变的条件下极大提升了模型的推理性能。由于 RWKV 架构在设计时支持 FFN 无损稀疏化,在 bsz = 1 时,FlagGems 算子 rwkv_mm_sparsity 对比 CUDA matmul 算子提升了 74% 到 202% 的速度。
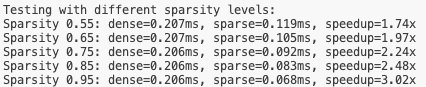
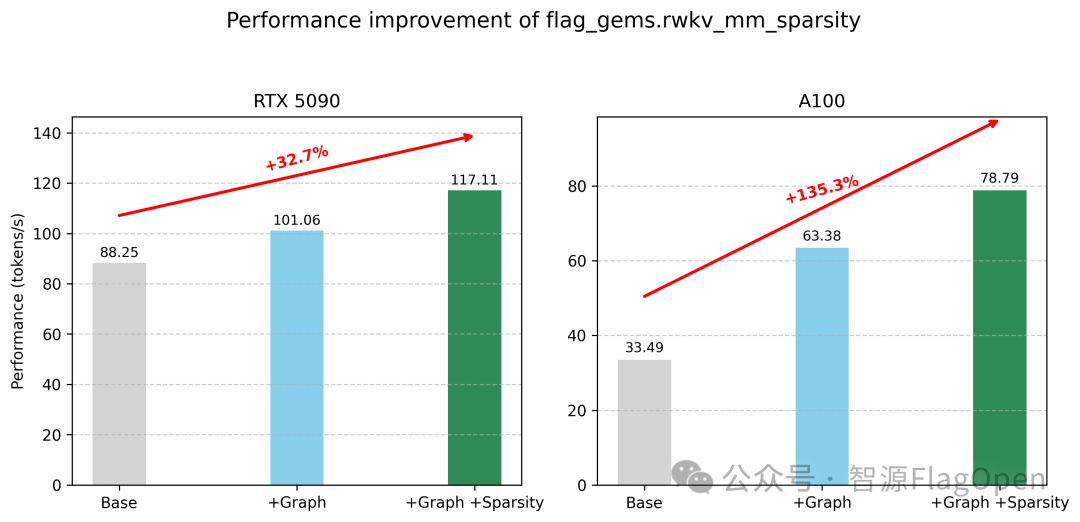
通过进一步配合图优化,推理 Decode 阶段端到端性能在英伟达 RTX5090 上提升 32.7%,在英伟达 A100 上提升 135.3%。
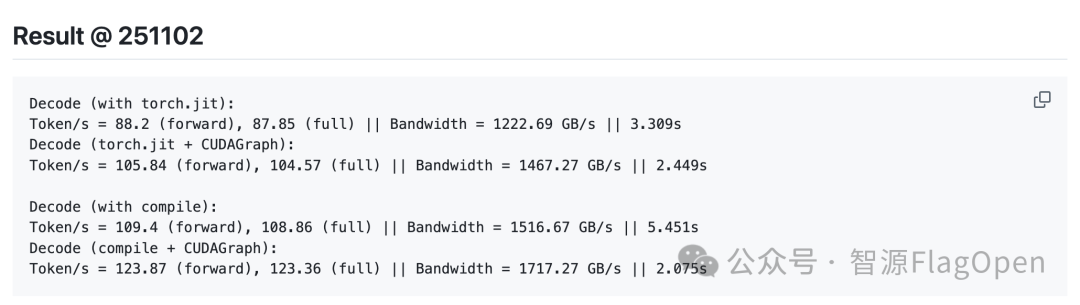
访问推理加速包 Albatross https://github.com/BlinkDL/Albatross/tree/main/faster_251101 可以看到推理速度信息如下。
-
123+ token/s RWKV-7 7.2B fp16 bsz1 @ RTX5090 with CUDAGraph and sparse FFN (lossless)
-
10250+ token/s RWKV-7 7.2B fp16 bsz960 @ RTX5090
下载使用 RWKV7-G0a3 13.3B 推理加速包 Albatross
下载最新版 RWKV7-G0a3 13.3B 模型后,推荐使用最快的 RWKV 推理工具 Albatross https://github.com/BlinkDL/Albatross ,进行本地部署 RWKV 模型。
推理环境
-
python 3.13.2
-
torch 2.9.0+cu130
pip install -U flag_gems
pip install -U triton==3.4.0
# if using conda
export LD_LIBRARY_PATH=$CONDA_PREFIX/lib运行 benchmark 脚本
python benchmark.pyRWKV 模型下载地址
1、下载 .pth 格式
Hugging Face:https://huggingface.co/BlinkDL/rwkv7-g1/resolve/main/rwkv7-g0a3-13.3b-20251031-ctx4096.pth?download=true
魔搭:https://modelscope.cn/models/RWKV/rwkv7-g1/resolve/master/rwkv7-g0a3-13.3b-20251031-ctx4096.pth
2、下载 .gguf 格式
下载地址:https://modelscope.cn/models/shoumenchougou/RWKV7-G0a3-13.3B-GGUF/files
3、下载 Ollama 格式:
下载地址:https://ollama.com/mollysama
如何安装和使用 FlagGems
目前,FlagGems 已提供针对 Python 3.10 - 3.13 的预编译 wheel 包,可直接用于 Linux(glibc ≥ 2.38)操作系统环境。如果 Python 版本在上述范围内,可直接安装对应的包。编译好的FlagGems的wheel包地址是:https://pypi.org/project/flag-gems/#files。
如果 Python 版本不在前面提到的范围内,也可以通过源码进行本地编译与安装。
安装手册:https://github.com/FlagOpen/FlagGems/blob/master/docs/installation.md
使用手册:https://github.com/FlagOpen/FlagGems/blob/master/docs/how_to_use_flaggems.md
关于 FlagOS
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了 FlagOS 开源社区。
FlagOS 社区致力于打造相面多种 AI 芯片的统一、开源的系统软件栈,包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离,有效降低开发者的迁移成本。FlagOS 社区构建人工智能软硬件生态,突破单一闭源垄断,推动AI硬件技术大范围落地发展,立足中国、拥抱全球合作。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)