MTR++:基于对称场景建模和互相引导的意图query的多智能体运动预测
自动驾驶的挑战在于智能体的多样交互和复杂的环境场景大多通过MLP编码的工作通常偏向于预测训练数据中观察到的最常发生的模式,从而产生无法充分提取智能体的多模式行为的同一轨迹因此有方法为了改进涵盖智能体潜在未来行为的轨迹预测,提出一种基于目标的策略,首先选出密集的候选目标作为智能体的目的地,通过预测每个候选目标作为实际目的地相关的概率,为每个选定的候选目标生成完整轨迹。虽然这种策略减少了模型优化期间轨
论文:MTR++: multi-agent motion prediction with symmetric scene modeling and guided intention querying
2024 IEEE
MTR 2022 NeurIPS
1、介绍
自动驾驶的挑战在于智能体的多样交互和复杂的环境场景
大多通过MLP编码的工作通常偏向于预测训练数据中观察到的最常发生的模式,从而产生无法充分提取智能体的多模式行为的同一轨迹
因此有方法为了改进涵盖智能体潜在未来行为的轨迹预测,提出一种基于目标的策略,首先选出密集的候选目标作为智能体的目的地,通过预测每个候选目标作为实际目的地相关的概率,为每个选定的候选目标生成完整轨迹。
虽然这种策略减少了模型优化期间轨迹的不确定性,但此类方法的性能高度依赖于候选目标的密度。较少的候选者会导致性能下降,而过多的候选者会增加计算和内存成本
为了增强多模态运动预测,同时减少对密集候选目标的依赖,提出了一个MTR框架
MTR结构利用具有可学习意图query的 Transformer 编码-解码结构,通过使用每个意图query来代表同一区域的一堆潜在轨迹的行为预测,从而促进高效的运动预测。在这些意图query的指导下,MTR 框架同时优化两个关键任务:全局意图定位,旨在粗略地识别智能体的意图,从而提高整体效率;局部运动细化,致力于自适应地细化每个意图的预测轨迹,从而提高准确性改进了多模态运动预测,同时减少了对密集的候选目标的依赖,能够高效、准确地预测未来轨迹
简单来说,MTR 框架引入不同的可学习意图query来处理不同运动模式的轨迹预测。 为了实现这一点,最初为每个类别生成有限数量的空间分布意图点(论文中为 64 个)。 这些意图点通过包含运动方向和速度,有效减少未来轨迹的不确定性。此外,MTR框架利用所有意图query的分类概率来粗略定位智能体的运动意图,而每个意图query的预测轨迹通过堆叠的transformer解码器进行迭代细化,这种迭代细化过可以不断细致地更新每个轨迹的局部特征
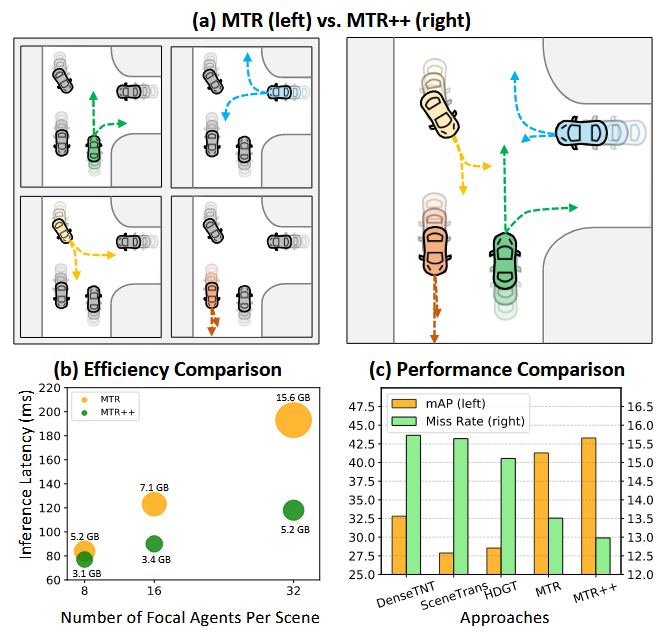
MTR专注于单个智能体的多模态轨迹预测,而本文提出的MTR++具有同时预测多个智能体多模态运动的能力,而不是单独编码每个智能体周围的场景上下文,相比MTR,MTR++在内存效率、计算成本、MAP方面都有很大进步
MTR++提出了一种新颖的对称场景上下文建模策略。 该策略采用共享上下文编码器对每个智能体的整个场景进行对称编码,并结合新颖的以query为中心的自注意力模块来共同捕获各自局部坐标系内复杂的场景上下文信息。此外,在运动解码器网络中引入了相互引导的意图query模块,使智能体能够交互并互相影响,这有利于多个智能体进行更精确且符合场景的联合运动预测
主要贡献在于:
1) 提出了MTR,不仅改进了多模态运动预测,提高准确性,同时减少了对密集的候选目标的依赖
2) 提出了先进的MTR++框架,用于多个智能体的同时多模态运动预测
3) MTR和MTR++分别赢得Waymo运动预测挑战赛冠军
2、基于多模态轨迹预测的MTR
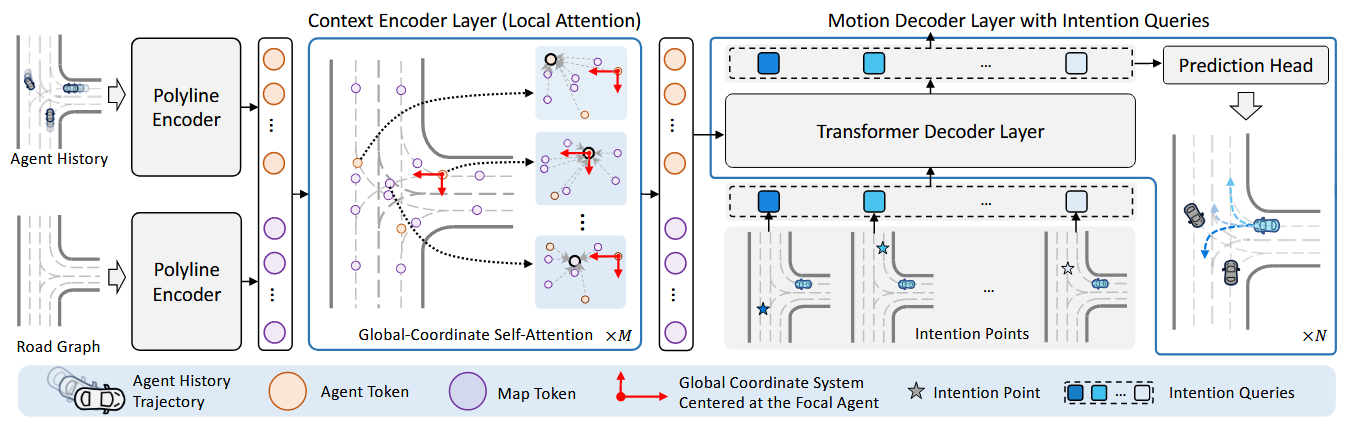
首先分别将智能体历史轨迹和场景图进行polyline encoder分别得到智能体token和地图token(因为历史轨迹为折线,而场景信息这里指的是斑马线,所以也为折线),合并后输入给多个具有局部自注意力的多个transformer编码器,在目标智能体为中心的全局坐标系内,建模不同token之间的关系,全面了解场景上下文的信息。 最后,一组可学习的意图query被集成到堆叠的transformer解码器中,作为运动解码器,以聚合来自编码的上下文特征的信息,最后得到预测轨迹
2.1、场景上下文建模的 Transformer 编码器
保留场景上下文的局部结构,特别是路线图,是至关重要的,因此引入了一个 Transformer 编码器网络,利用局部自注意力来更好地捕获这种结构信息
单目标智能体的输入表示
以目标智能体为中心,将所有输入归一化到以该智能体为中心的全局坐标系
分别将智能体的历史状态和地图的历史状态通过PointNet结构(MLP和MaxPool)编码,再连接合并,同时收集智能体token最新的位置和地图token折线中心的位置
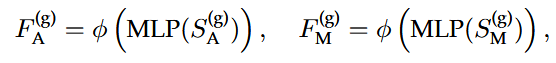
![]()
![]()
局部注意力的 Transformer 编码器进行场景上下文编码
通过采用局部注意力将token和token的位置纳入上下文编码器,更好地保留了局部性结构
注意力模块为:
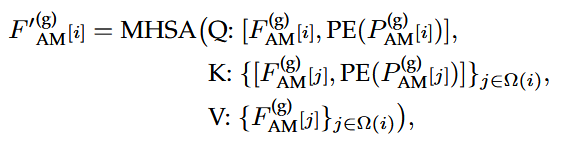
PE为正弦位置编码
按照维度分解可以得到智能体历史token和地图token,其中智能体历史token将通过密集未来预测模块进一步增强为智能体token
![]()
多智能体的密集未来预测
现有方法大多只关注于历史交互,而忽略了未来的轨迹交互
通过MLP来进行密集的预测未来智能体的状态(这里有一个L1回归损失)
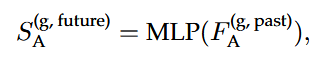
再利用第一步使用的同一个MLP进行编码得到一个智能体未来token
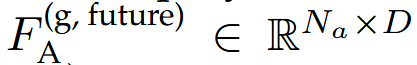
和智能体历史token连接后,通过三个MLP最后得到增强的智能体token
![]()
2.2、意图query的运动解码器
通过全局意图定位和局部运动细化的联合优化来促进多模态运动预测。由堆叠的transformer解码器层组成,这些层利用可学习的意图query迭代细化预测轨迹
可学习的意图query
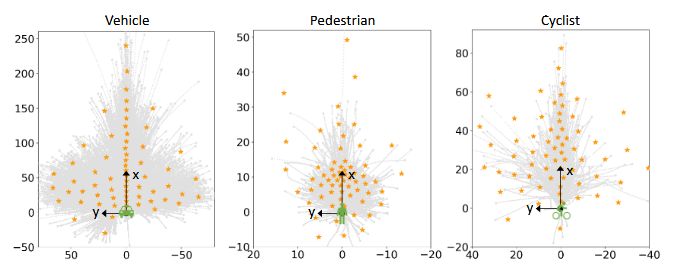
通过对不同的运动模式采用不同的意图query来减少未来轨迹的不确定性,有效、精确地预测智能体的潜在运动意图,对于每个类别,通过在训练数据集中的GT轨迹的终点上利用K-Means聚类生成K个意图点,每个意图点都体现了一种隐式运动模式,同时考虑了运动方向和速度。得到目标智能体的意图点,将每个意图query建模为特定意图点的可学习位置embedding
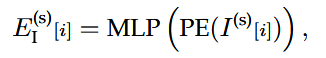
基于意图query的场景信息聚合
首先在每一层解码中,通过自注意力模块在K个意图query间传播信息、相互通信,这有助于模型理解不同运动模式间的区别和联系
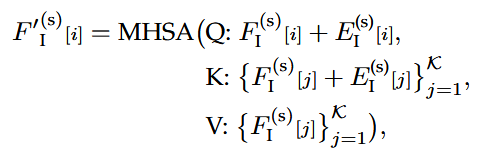
其中F为上一个解码器层输出的query内容特征(第一层初始化为0),用于更新query内容特征
query内容特征可以理解为一份运动计划内容,意图query本身就是运动计划,其位置嵌入为行动计划目标的空间位置
然后再通过一个交叉注意力模块,得到最终更新的query内容特征,连接query和key的内容特征和位置嵌入,以解耦它们对注意力权重的贡献,每个意图query会去“查看”编码器输出的场景信息(其他智能体的状态、地图元素),聚合与自身意图相关的场景信息
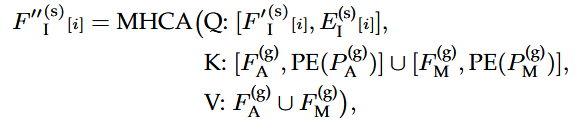
Q:[query内容特征,query位置]
K:[所有元素特征,所有元素位置]
V:所有元素特征
通过这种方式,将智能体和地图token局限在当前的意图query的区域里
全局意图定位&局部运动细化
在每一个解码层,最后得到query内容特征后,分别通过两个MLP进行全局定位,和轨迹细化
全局定位:最后得到一个概率分布,代表真实轨迹终点落在第 k 个意图点的空间区域附近的置信度
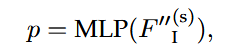
局部细化:进一步预测详细的未来轨迹
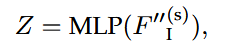
2.3、基于高斯混合模型的多模态预测
每个时间步用高斯混合模型(GMM)表示预测轨迹的分布,采用负对数似然损失,最后的损失值为
![]()
3、基于多智能体轨迹预测的MTR++
MTR为每个目标智能体单独编码场景上下文,导致在预测多个智能体的运动时计算效率低下,MTR++ 框架通过共享对称场景上下文建模和相互引导意图query,实现多个智能体的同步运动预测。
通过借助query-centric自注意力机制,将场景特征和各自局部坐标系下的交互进行编码
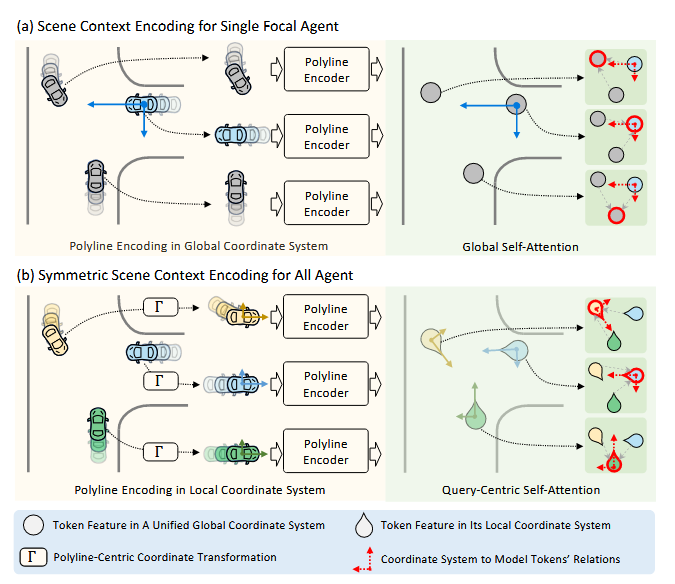
3.1、所有智能体的对称场景上下文建模
提出了一种对称场景上下文建模模块,该模块采用共享上下文编码器为所有智能体编码复杂的多模态场景上下文信息,为每个智能体对称地编码整个场景,通过运动解码器网络直接预测每一个智能体的轨迹
编码输入
类似于MTR的结构,但进行坐标变换后通过PointNet结构,得到相应的局部的token,同时收集这些token的全局位置,同时,每个token还具有全局状态下的方向属性
query-centric的自注意力对称场景上下文建模S
该模块以对称的方式模拟所有token之间的关系,与任何全局坐标系解耦,为了探索每个token和其坐标系下其他token的关系,对每个token分别执行注意机制,例如,对i的token作为query,那么将所有token的坐标和方向转换为该token的本地坐标系下(R表示相对位置和方向),从而实现了对称性(不变性):无论全局坐标系如何,同一个关系在任意一个token的视角下都是一样的
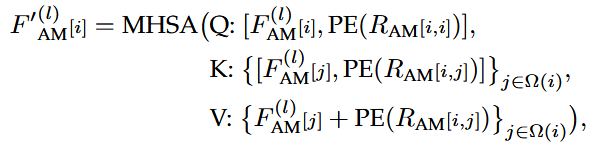
3.2、具有相互引导查询的联合运动解码器
探索智能体之间的未来行为交互,这对于做出更准确且符合场景的运动预测至关重要
多个智能体的相互引导意向图query
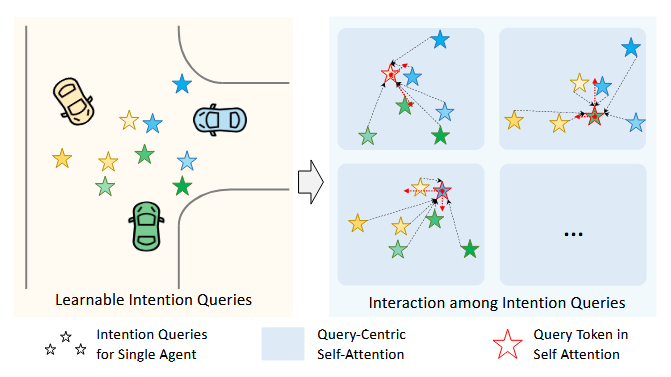
不同智能体的意向图query被编码在它们自己的局部坐标系中,
为了既保持本地编码特征,同时建立它们之间的交互关系,采用了query-centric的自注意力模块,运动解码过程在以每个智能体为中心的局部坐标系中同时进行,分别得到各自局部坐标系下的意图点,再将意图点全部转移到全局坐标系下
因此,当考虑到第i个意图query时,再将其余意图query转移到相应的局部坐标系下,通过MHSA最后得到了包含交互关系的query内容特征,然后将单独用于每个智能体的后续场景上下文聚合,该聚合过程与MTR中描述的相同

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)