JSON太贵了?这个开源项目让你的LLM成本直降50%
还记得第一次看到OpenAI账单的时候吗?我盯着那串数字,心想:"这玩意儿比电费还贵。"欢迎来到2025年,这个Token比黄金还值钱的时代。在大模型成为基础设施的今天,我们面临着一个有趣的悖论:上下文窗口越来越大(动辄百万Token),但Token的价格却让人肉疼。就像高速公路修得越来越宽,但过路费也跟着涨。你看着那100万的上下文窗口,就像看着五星级自助餐厅——看起来什么都能装,但你真敢往里塞
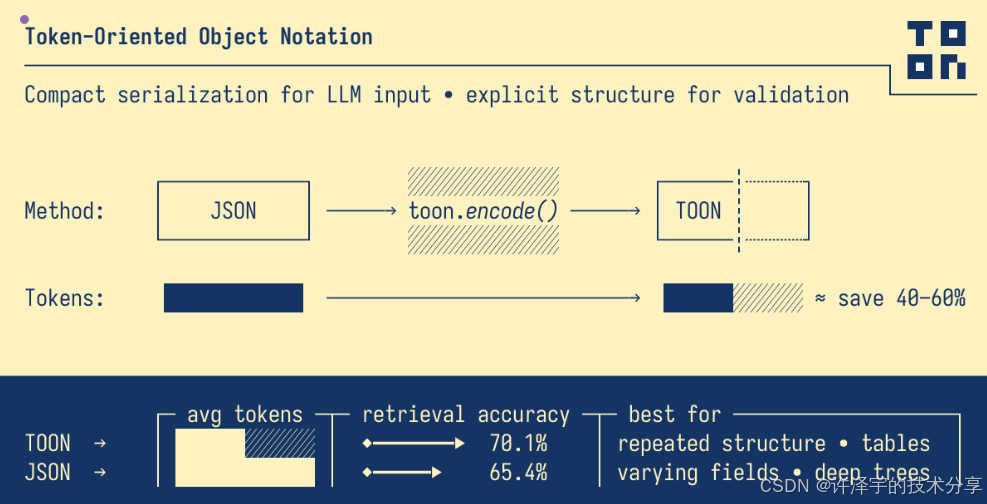
一、前言:当Token成为硬通货
还记得第一次看到OpenAI账单的时候吗?我盯着那串数字,心想:"这玩意儿比电费还贵。"欢迎来到2025年,这个Token比黄金还值钱的时代。
在大模型成为基础设施的今天,我们面临着一个有趣的悖论:上下文窗口越来越大(动辄百万Token),但Token的价格却让人肉疼。就像高速公路修得越来越宽,但过路费也跟着涨。你看着那100万的上下文窗口,就像看着五星级自助餐厅——看起来什么都能装,但你真敢往里塞数据吗?
更要命的是,我们传数据的方式还停留在上个时代。JSON?那玩意儿设计出来的时候,谁能想到有一天我们要按字符收费?它就像一个话痨,明明三句话能说清楚的事儿,非要絮絮叨叨说上十句。
今天要聊的TOON(Token-Oriented Object Notation),就是专门给这个问题打造的解决方案。它不是又一个"重新发明轮子"的项目,而是一个深刻理解了Token经济学的聪明设计。
二、问题的本质:JSON到底贵在哪儿?
2.1 冗余是第一杀手
我们先来看一个最常见的场景——用户数据。用JSON表示长这样:
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin", "active": true },
{ "id": 2, "name": "Bob", "role": "user", "active": true },
{ "id": 3, "name": "Charlie", "role": "user", "active": false }
]
}
看出问题了吗?每个对象都重复了"id"、"name"、"role"、"active"这些键名。三个用户,这些键就重复了三遍。如果是一千个用户呢?这些键名要重复一千遍!
这就像你去餐厅点餐,每次都要完整地说一遍:"我要一份宫保鸡丁,我要一份麻婆豆腐,我要一份鱼香肉丝"。服务员听得耳朵都起茧了——你直接报菜名不就行了?
在Token的世界里,冗余不只是浪费空间,它是在烧钱。而JSON的设计初衷是"人类可读"和"自描述",这在20年前是优点,现在却成了成本陷阱。
2.2 符号密集型语法
再看看JSON里那些符号:大括号{}、方括号[]、双引号""、逗号,、冒号:。这些符号本身就占Token,而且密度很高。
以上面的例子为例,光是格式符号就占了整体的30%以上。这就像快递费比商品还贵——你付钱买的是数据,结果一半成本花在了包装上。
2.3 结构化数据的通病
JSON的另一个问题是它对所有数据一视同仁。不管是深度嵌套的复杂对象,还是简单的表格数据,都用同一套语法。
但实际应用中,有大量数据是结构化表格:电商订单、用户列表、时序数据、日志记录……这些数据的特点是"同一类型的对象批量出现"。用JSON表示,就是在不断重复同样的结构。
这就好比你要运一批规格统一的货物,JSON给你的却是散装快递——每件都要单独打包、贴标签。而你真正需要的是集装箱。
三、TOON的破局之道:Token经济学的优雅答案
3.1 核心思想:表格化与去冗余
TOON的第一个杀手锏是表格格式(Tabular Format)。对于结构相同的对象数组,它只声明一次字段,然后每行只写值:
users[3]{id,name,role,active}:
1,Alice,admin,true
2,Bob,user,true
3,Charlie,user,false
看到差异了吗?字段名只出现了一次,在头部声明。后面的每一行,都只是纯粹的数据。
这就是表格的威力。它借鉴了CSV的思路,但做得更聪明:
-
显式长度标记
[3]:告诉LLM这个数组有3个元素,便于验证 -
字段声明
{id,name,role,active}:明确每列的含义 -
分隔符
,:支持逗号、制表符、管道符三种
这种设计不是拍脑袋想出来的,而是深刻理解了Token化(Tokenization)的机制。现代Tokenizer(比如GPT使用的BPE)会把常见的字符组合压缩成单个Token。\t(制表符)通常是单个Token,而,加空格可能是两个Token。TOON让你自己选分隔符,就是为了针对不同场景优化。
3.2 技术架构:编码器与解码器的艺术
TOON的实现非常克制,整个核心代码不到2000行TypeScript。让我们看看它的技术架构。
3.2.1 编码器(Encoder)的智能判断
编码器的核心逻辑在encodeArray函数中。它会对数组进行分类处理:
export function encodeArray(
key: string | undefined,
value: JsonArray,
writer: LineWriter,
depth: Depth,
options: ResolvedEncodeOptions,
): void {
// 空数组:直接输出头部
if (value.length === 0) {
const header = formatHeader(0, { key, delimiter: options.delimiter })
writer.push(depth, header)
return
}
// 原始值数组:内联格式
if (isArrayOfPrimitives(value)) {
const formatted = encodeInlineArrayLine(value, options.delimiter, key)
writer.push(depth, formatted)
return
}
// 对象数组:尝试表格格式
if (isArrayOfObjects(value)) {
const header = extractTabularHeader(value)
if (header) {
encodeArrayOfObjectsAsTabular(key, value, header, writer, depth, options)
} else {
encodeMixedArrayAsListItems(key, value, writer, depth, options)
}
return
}
// 兜底:列表格式
encodeMixedArrayAsListItems(key, value, writer, depth, options)
}
这段代码体现了TOON的设计哲学:根据数据结构选择最优表示。
判断是否可以使用表格格式的逻辑在isTabularArray中:
export function isTabularArray(
rows: readonly JsonObject[],
header: readonly string[],
): boolean {
for (const row of rows) {
const keys = Object.keys(row)
// 所有对象必须有相同的键(顺序可以不同)
if (keys.length !== header.length) {
return false
}
// 检查所有键是否存在,且值必须是原始类型
for (const key of header) {
if (!(key in row)) {
return false
}
if (!isJsonPrimitive(row[key])) {
return false
}
}
}
return true
}
这个判断非常严格:
-
所有对象的键必须完全一致(数量和名称)
-
所有值必须是原始类型(string/number/boolean/null)
只有满足这两个条件,才会使用表格格式。这就是TOON的"甜蜜点"(Sweet Spot)——uniform arrays of objects。
3.2.2 解码器(Decoder)的鲁棒性
解码器的设计同样精妙。它采用了扫描器-解析器(Scanner-Parser)的经典架构:
-
Scanner(扫描器):负责将输入文本切分成带有深度信息的行对象
-
Parser(解析器):负责根据语法规则解析每一行
扫描器的核心是toParsedLines函数:
export function toParsedLines(source: string, indentSize: number, strict: boolean): ScanResult {
const lines = source.split('\n')
const parsed: ParsedLine[] = []
const blankLines: BlankLineInfo[] = []
for (let i = 0; i < lines.length; i++) {
const raw = lines[i]!
const lineNumber = i + 1
let indent = 0
// 计算缩进
while (indent < raw.length && raw[indent] === ' ') {
indent++
}
const content = raw.slice(indent)
// 跳过空行
if (!content.trim()) {
const depth = computeDepthFromIndent(indent, indentSize)
blankLines.push({ lineNumber, indent, depth })
continue
}
const depth = computeDepthFromIndent(indent, indentSize)
// 严格模式验证
if (strict) {
if (raw.slice(0, indent).includes('\t')) {
throw new SyntaxError(`Line ${lineNumber}: Tabs are not allowed in indentation`)
}
if (indent > 0 && indent % indentSize !== 0) {
throw new SyntaxError(`Line ${lineNumber}: Indentation must be exact multiple of ${indentSize}`)
}
}
parsed.push({ raw, indent, content, depth, lineNumber })
}
return { lines: parsed, blankLines }
}
这里有个细节值得注意:strict模式的验证。TOON默认开启严格模式,会检查:
-
缩进必须是空格,不能用制表符
-
缩进必须是
indentSize的整数倍 -
数组长度必须与实际元素数量一致
这种严格性不是为了刁难开发者,而是为了帮助LLM生成正确的输出。显式的约束比隐式的规则更容易学习和遵守。
3.2.3 字符串处理的魔鬼细节
TOON的另一个巧妙之处在于智能引号(Smart Quoting)。它只在必要时才给字符串加引号:
export function isSafeUnquoted(value: string, delimiter: string): boolean {
if (value.length === 0) return false
if (value.startsWith(' ') || value.endsWith(' ')) return false
// 包含特殊字符需要引号
const needsQuoting =
value.includes(delimiter) ||
value.includes(':') ||
value.includes('"') ||
value.includes('\\') ||
value.includes('\n') ||
value.includes('\r') ||
value.includes('\t')
if (needsQuoting) return false
// 看起来像布尔值、数字、null的需要引号
if (isBooleanOrNullLiteral(value)) return false
if (isNumericLiteral(value)) return false
// 看起来像结构化标记的需要引号
if (value.startsWith('- ')) return false
if (value.match(/^\[.*\]$/)) return false
return true
}
这个函数看似简单,实际上考虑了大量边界情况:
-
空字符串:必须引号(
"") -
首尾空格:必须引号(否则会被trim掉)
-
包含分隔符或冒号:必须引号(否则会被误解析)
-
看起来像关键字:必须引号(
"true"和true是不同的) -
Unicode和Emoji:可以不引号(
hello 👋 world是合法的)
这种设计既减少了Token数量,又保证了歧义性。可以说是在可读性和效率之间找到了最佳平衡点。
3.3 数据流:从JSON到TOON再到LLM
完整的数据流程是这样的:
应用数据(JSON)
↓
[编码器] encode(data, options)
↓
TOON格式字符串
↓
[组装提示词]
↓
LLM输入(减少30-60% Token)
↓
LLM处理 & 响应
↓
[解码器] decode(toon, options)
↓
应用数据(JSON)
关键点是:TOON是翻译层,不是存储格式。你的应用还是用JSON,只是在和LLM交互时临时转换成TOON。这就像出国旅游带个翻译,省钱又高效。
四、TOON vs JSON:数据说话
光说不练假把式。TOON的官方Benchmark测试了三个典型场景,结果相当惊艳。
4.1 GitHub仓库数据(最佳场景)
场景:100个GitHub仓库的元数据,每个包含id、name、stars、forks、description等11个字段。
JSON格式(15,145 Tokens):
{
"repositories": [
{
"id": 28457823,
"name": "freeCodeCamp",
"repo": "freeCodeCamp/freeCodeCamp",
"description": "freeCodeCamp.org's open-source codebase...",
"createdAt": "2014-12-24T17:49:19Z",
"stars": 430886,
"forks": 42146,
...
},
{ ... },
{ ... }
]
}
TOON格式(8,745 Tokens):
repositories[100]{id,name,repo,description,createdAt,updatedAt,pushedAt,stars,watchers,forks,defaultBranch}:
28457823,freeCodeCamp,freeCodeCamp/freeCodeCamp,"freeCodeCamp.org's open-source codebase...","2014-12-24T17:49:19Z",...,430886,...,42146,main
132750724,build-your-own-x,codecrafters-io/build-your-own-x,"Master programming by recreating...",...
...
节省:6,400 Tokens,减少42.3%!
这个场景是TOON的理想战场:结构完全统一的对象数组。11个字段名在JSON中重复了100次,而TOON只声明一次。
4.2 时序分析数据(高密度数值)
场景:180天的网站分析数据,每天包含views、clicks、conversions、revenue、bounceRate等6个指标。
JSON格式(10,977 Tokens):
{
"metrics": [
{
"date": "2025-01-01",
"views": 6890,
"clicks": 401,
"conversions": 23,
"revenue": 6015.59,
"bounceRate": 0.63
},
{
"date": "2025-01-02",
"views": 6940,
"clicks": 323,
"conversions": 37,
"revenue": 9086.44,
"bounceRate": 0.36
},
...
]
}
TOON格式(4,507 Tokens):
metrics[180]{date,views,clicks,conversions,revenue,bounceRate}:
2025-01-01,6890,401,23,6015.59,0.63
2025-01-02,6940,323,37,9086.44,0.36
2025-01-03,4390,346,26,6360.75,0.48
...
节省:6,470 Tokens,减少58.9%!
这个场景展示了TOON处理高密度数值数据的能力。时序数据往往有成百上千条记录,JSON的冗余问题在这里被放大到极致。而TOON的表格格式就像为数据做了压缩,效果惊人。
4.3 电商订单数据(嵌套结构)
场景:一个包含客户信息和商品列表的订单,有嵌套结构。
JSON格式(257 Tokens):
{
"orderId": "ORD-2025-001",
"customer": {
"id": 12345,
"name": "张三",
"email": "zhangsan@example.com"
},
"items": [
{ "sku": "A1", "name": "无线鼠标", "qty": 2, "price": 99.9 },
{ "sku": "B2", "name": "机械键盘", "qty": 1, "price": 399.0 }
],
"total": 598.8
}
TOON格式(166 Tokens):
orderId: ORD-2025-001
customer:
id: 12345
name: 张三
email: zhangsan@example.com
items[2]{sku,name,qty,price}:
A1,无线鼠标,2,99.9
B2,机械键盘,1,399.0
total: 598.8
节省:91 Tokens,减少35.4%!
这个场景展示了TOON的适应性。即使有嵌套对象,它也能识别出数组部分(items)使用表格格式,其他部分用YAML风格的缩进。这种混合策略让TOON在复杂数据结构中依然保持效率。
4.4 综合对比:不只是省Token
让我们把三个场景加起来看总体效果:
| 格式 | 总Token数 | vs TOON | 节省百分比 |
|---|---|---|---|
| TOON | 13,418 | - | - |
| JSON (格式化) | 26,379 | +12,961 | 49.1% |
| JSON (紧凑) | 18,639 | +5,221 | 28.0% |
| YAML | 22,136 | +8,718 | 39.4% |
| XML | 30,494 | +17,076 | 56.0% |
几个关键发现:
-
即使和紧凑JSON比,TOON仍然节省28%。这说明问题不只是格式化,而是结构性的冗余。
-
YAML比JSON好,但不如TOON。YAML解决了一部分符号冗余问题,但没有针对数组优化。
-
XML最贵。标签对的闭合语法让冗余雪上加霜,不适合LLM场景。
-
数据规模越大,优势越明显。GitHub仓库场景(100条记录)节省42.3%,时序数据场景(180条记录)节省58.9%。这证实了TOON的设计假设:它是为大规模表格数据优化的。
五、TOON的独特优势:大模型时代的专用格式
说到这里,你可能会问:既然CSV也是表格格式,为什么不直接用CSV?或者,LLM这么强大,直接喂JSON不就行了?
这两个问题触及了TOON设计的核心洞察。
5.1 相比CSV:结构化的力量
CSV确实简洁,但它有致命缺陷:缺少元数据和类型信息。
看这个CSV:
id,name,active
1,Alice,true
2,Bob,false
LLM看到这个,它知道:
-
第一行是什么?可能是标题,也可能是数据
-
true和false是布尔值还是字符串? -
如果数据里有嵌套对象怎么办?
-
数组有多长?没有明确标记
而TOON的表头设计解决了这些问题:
users[2]{id,name,active}:
1,Alice,true
2,Bob,false
LLM一看就明白:
-
users是键名 -
[2]表示有2条记录(可验证) -
{id,name,active}明确了字段名和顺序 -
冒号后面是数据行
这种显式的结构声明帮助LLM:
-
验证输出:生成数据时可以检查行数是否匹配
-
理解语义:字段名提供了上下文
-
处理嵌套:TOON可以在表格中嵌套表格或对象
CSV是个"哑巴"格式,TOON是"会说话"的格式。
5.2 相比JSON:Token效率 + LLM友好性
JSON虽然通用,但它的设计目标不是"LLM可读",而是"机器可解析 + 人类可读"。在大模型时代,这个设计出现了错位。
5.2.1 Token效率的量级差异
我们用一个实际例子来算账。假设你在做一个电商分析系统,每天要给LLM传100万条订单数据进行分析。每条订单有10个字段。
JSON方案:
-
每条订单约150 tokens
-
100万条 = 1.5亿 tokens
-
按GPT-4o价格($2.5/1M tokens)= $375
TOON方案:
-
每条订单约80 tokens(节省47%)
-
100万条 = 8000万 tokens
-
成本 = $200
一天省

5,250,一年省**$63,750**!
这还只是单一应用的成本。如果是SaaS平台,服务1000个客户,成本差异是千万级别。
5.2.2 LLM的"阅读体验"
大模型不是人,它处理文本的方式和我们不同。JSON对人类友好的特性,对LLM来说是负担:
1. 重复模式会干扰注意力机制
Transformer的自注意力机制会计算每个token与其他token的关系。当同样的键名出现100次,模型要在这些重复项之间建立大量无意义的连接,浪费计算资源。
TOON的表格格式让模式只出现一次,后续都是纯数据。这让模型可以专注于数据本身的关系,而不是被格式噪音干扰。
2. 显式约束降低生成难度
当你让LLM生成JSON时,它需要:
-
记住每个对象的所有键
-
保持括号和引号的平衡
-
处理转义字符
-
维持缩进一致性
而生成TOON时:
-
只需记住一次表头
-
后续行只是逗号分隔的值
-
[N]明确告诉模型要生成多少行 -
缩进规则严格且简单
这就是为什么TOON的准确性测试中,某些模型的表现会更好。不是因为格式更"聪明",而是因为任务更明确。
3. 上下文窗口的有效利用
假设你有100万token的上下文窗口。用JSON,你可能只能塞下5万条记录。用TOON,你能塞下9万条。
这不只是数量差异,而是质量的跃迁。很多分析任务需要"看到全貌"才能做出准确判断。当数据量跨过某个阈值,LLM的洞察力会有质的提升。
TOON让你能在同样的窗口里塞进更多上下文,这相当于给LLM"换了副眼镜",看得更清楚了。
5.3 准确性实验的启示
TOON的官方Benchmark做了一个有趣的实验:给4个不同的大模型提供相同的数据(分别用6种格式),然后问154个检索问题,看谁答得更准。
结果很有意思:
GPT-5-nano:TOON准确率96.1%,JSON只有86.4%
Gemini-2.5-flash:TOON准确率86.4%,CSV 87.7%,JSON 76.6%
Grok-4-fast:TOON准确率49.4%,JSON 48.7%
几个关键发现:
-
TOON在大部分模型上表现更好或相当,尤其是在较新的模型上优势明显。
-
准确率提升 + Token节省 = 双赢。TOON不是用效率换准确度,而是两者兼得。
-
表格格式对"检索型问题"友好。当LLM需要快速定位和比较数据时,表格结构比嵌套对象更直观。
这个实验揭示了一个深层道理:格式不只影响成本,也影响理解质量。好的格式是给大模型的"认知辅助"。
六、实战指南:如何在项目中用好TOON
理论讲完了,我们聊点实在的——如何在真实项目里应用TOON。
6.1 适用场景判断
先问自己三个问题:
❶ 你的数据是"表格型"的吗?
适合TOON:
-
✅ 用户列表、订单记录、日志数据
-
✅ 时序数据、传感器读数、统计指标
-
✅ 数据库查询结果、API响应列表
不太适合:
-
❌ 深度嵌套的配置文件
-
❌ 字段数远大于记录数的单个对象
-
❌ 每条记录结构差异很大的数据
❷ 你的数据规模有多大?
TOON的优势随规模增长:
-
10条记录:节省可能不明显(20-30%)
-
100条记录:节省显著(40-50%)
-
1000条以上:节省巨大(50-60%)
如果每次只传几条数据,JSON就够了。但如果是批量处理或历史数据分析,TOON的价值立刻体现。
❸ 你的Token预算紧张吗?
如果你的应用:
-
每天调用LLM成千上万次
-
需要传输大量上下文数据
-
对成本敏感(比如ToC产品)
-
需要榨干上下文窗口的每一寸空间
那TOON是你的菜。但如果你只是偶尔调用,或者Token成本在总成本中占比很小,那优化的性价比可能不高。
6.2 集成实践
TOON的集成非常简单,以TypeScript为例:
import { encode, decode } from '@toon-format/toon'
// 准备数据(任何JSON兼容的数据)
const data = {
orders: [
{ id: 1, customer: "Alice", amount: 150.0, status: "paid" },
{ id: 2, customer: "Bob", amount: 89.99, status: "pending" },
// ... 更多订单
]
}
// 编码为TOON
const toonString = encode(data, {
delimiter: '\t', // 使用制表符(通常更省Token)
indent: 2, // 缩进空格数
lengthMarker: '#' // 可选:显式长度标记
})
// 组装提示词
const prompt = `
以下是今天的订单数据(TOON格式):
\`\`\`toon
${toonString}
\`\`\`
请分析:
1. 哪些订单还未支付?
2. 总交易额是多少?
`
// 调用LLM
const response = await callLLM(prompt)
// 如果LLM返回TOON格式的数据,可以解码
const parsedData = decode(response, { strict: true })
几个最佳实践:
1. 选择合适的分隔符
// 默认逗号:通用,人类可读
encode(data, { delimiter: ',' })
// 制表符:通常更省Token,但显示不直观
encode(data, { delimiter: '\t' })
// 管道符:折中方案
encode(data, { delimiter: '|' })
建议:优先用制表符,除非你需要人工调试。
2. 告诉LLM格式规则
在提示词中加上简短的说明:
数据以TOON格式提供(类似CSV但带元数据):
- `[N]`表示数组长度
- `{field1,field2}`声明字段名
- 后续行是纯数据,用制表符分隔
虽然大部分模型能自动理解,但显式说明可以提高准确率。
3. 让LLM生成TOON
如果你需要LLM返回结构化数据,可以在提示词中提供期望的格式:
请返回符合条件的用户列表,使用以下TOON格式:
users[N]{id,name,email,score}:
<数据行>
要求:
- [N]必须等于实际行数
- 字段用制表符分隔
- 不要有额外的说明文字
这种约束能显著降低解析失败率。
6.3 性能优化技巧
技巧1:分批编码大数据集
如果数据集非常大(比如10万条记录),不要一次性全部编码:
const BATCH_SIZE = 10000
for (let i = 0; i < records.length; i += BATCH_SIZE) {
const batch = records.slice(i, i + BATCH_SIZE)
const toon = encode({ batch }, { delimiter: '\t' })
// 分批发送给LLM
}
技巧2:缓存编码结果
如果某些数据是静态的(比如产品目录),编码一次后缓存起来:
const productCatalogTOON = encode(products, { delimiter: '\t' })
// 缓存到Redis或内存中
redis.set('product_catalog_toon', productCatalogTOON, 'EX', 3600)
技巧3:混合使用JSON和TOON
不是所有数据都要用TOON。对于小而复杂的配置对象,JSON可能更合适:
const prompt = `
用户配置:
${JSON.stringify(userConfig, null, 2)}
历史订单(TOON格式):
${encode({ orders: orderHistory }, { delimiter: '\t' })}
`
根据数据特性选择格式,而不是教条地"全用TOON"。
6.4 常见陷阱与解决方案
陷阱1:非统一结构的数组
const badData = {
items: [
{ id: 1, name: "A", price: 10 },
{ id: 2, name: "B" }, // 缺少price字段
]
}
TOON会降级到列表格式,失去表格优势。
解决方案:数据标准化
const goodData = {
items: items.map(item => ({
id: item.id,
name: item.name,
price: item.price ?? null // 用null填充缺失字段
}))
}
陷阱2:嵌套对象值
const badData = {
users: [
{ id: 1, profile: { age: 25, city: "Beijing" } } // 嵌套对象
]
}
TOON的表格格式只支持原始值。
解决方案:扁平化或分离
// 方案1:扁平化
const goodData = {
users: users.map(u => ({
id: u.id,
age: u.profile.age,
city: u.profile.city
}))
}
// 方案2:分离嵌套部分
const prompt = `
用户基础信息:
${encode({ users: basicInfo })}
用户详细档案:
${encode({ profiles: detailedProfiles })}
`
陷阱3:过度优化
有些开发者会极端地追求Token节省,比如缩短字段名:
// 不推荐
{ uid: 1, nm: "Alice", st: "active" }
// 推荐:保持可读性
{ userId: 1, name: "Alice", status: "active" }
字段名在TOON表格中只出现一次,缩短几个字符省不了多少Token,反而损害了可读性。记住:可维护性 > 极致优化。
七、更广阔的视野:TOON背后的技术哲学
聊到这里,TOON的实用价值已经很清楚了。但我想往更深处挖一挖——这个项目背后的技术哲学,以及它对我们的启发。
7.1 专用格式的复兴
过去20年,我们见证了"通用格式"的胜利。XML想统一一切,最终败给了JSON。JSON成为了事实标准,从配置文件到API响应,无处不在。
但TOON的出现,标志着一个趋势:专用格式(Domain-Specific Formats)的复兴。
为什么?因为使用场景变了。
JSON诞生于Web 2.0时代,设计目标是"人机协作"——既要让程序好解析,也要让人能看懂。它成功了,但也付出了效率的代价。
到了AI时代,新的参与者登场了:大语言模型。它既不是传统的"机器"(不需要JSON的严格语法来解析),也不完全是"人"(不需要那么多可读性冗余)。LLM是一个新物种,需要新的数据格式。
TOON的专用性体现在:
-
针对LLM的Token化机制优化(分隔符选择)
-
针对Transformer的注意力机制优化(减少重复模式)
-
针对生成任务的显式约束(长度标记、字段声明)
这种"专用"不是局限,而是精准。就像F1赛车不适合越野,但在赛道上无人能敌。
7.2 约束即自由
TOON的另一个哲学是:更严格的约束反而带来更大的自由。
听起来矛盾?看看这两个对比:
**JSON的"自由"**:
[
{ "name": "Alice", "age": 25 },
{ "name": "Bob" }, // age可有可无
{ "age": 30 } // name也可以省略
]
JSON允许你做任何事,但这种自由是有代价的:
-
LLM不知道哪些字段是必需的
-
解析代码要处理各种边界情况
-
数据验证变得复杂
**TOON的"约束"**:
users[3]{name,age}:
Alice,25
Bob,null
null,30
TOON强制你:
-
明确字段列表
-
所有行有相同的列数
-
用null表示缺失值
这些约束看似限制,实则是契约。它告诉所有参与者(人、机器、LLM):"这是我们的协议,大家都遵守它"。
结果是:
-
LLM生成数据时更不容易出错
-
验证逻辑变简单(行数匹配、列数匹配)
-
调试更容易(一眼看出哪行有问题)
这让我想起Go语言的设计哲学。Go也是通过约束(单一错误处理方式、没有泛型等)来换取简洁和可维护性。TOON在数据格式领域做了类似的取舍。
7.3 显式优于隐式
Python的Zen里有句名言:"Explicit is better than implicit"(显式优于隐式)。TOON把这个理念贯彻得很彻底。
看这个对比:
CSV(隐式):
name,age,active
Alice,25,true
Bob,30,false
问题:
-
第一行是数据还是标题?(需要猜)
-
有多少行数据?(需要数)
-
true是布尔值还是字符串?(需要推断)
TOON(显式):
users[2]{name,age,active}:
Alice,25,true
Bob,30,false
一切都明明白白:
-
users是键名 -
[2]明确了数组长度 -
{name,age,active}声明了字段 -
冒号后面才是数据
这种显式性对LLM特别重要。因为LLM本质上是"概率机器",它通过上下文推断意图。当格式本身就明确表达了结构信息,LLM就不需要"猜测",可以把认知资源用在理解数据内容上。
就像给学生一张考试答题卡,如果题号、分数、答题区域都标得清清楚楚,学生就能专注在题目本身,而不是纠结"这道题该写在哪里"。
7.4 未来的想象空间
TOON的成功,开启了一些有趣的可能性:
1. 其他领域的专用格式
既然LLM需要专用的数据格式,那其他场景呢?
-
图数据格式:针对知识图谱和社交网络优化
-
时序数据格式:针对IoT和监控数据优化
-
多媒体描述格式:针对图像、视频元数据优化
每个领域都可能诞生自己的"TOON"。
2. LLM的"母语"
更激进的想法:如果我们从头设计一种"LLM的原生语言",会是什么样?
它可能:
-
完全基于Token效率而非人类可读性
-
内置版本控制和diff能力
-
原生支持不确定性(概率分布而非确定值)
-
与Transformer架构深度耦合
TOON还不是这种"原生语言",但它迈出了第一步。
3. 编译器和工具链的演化
随着专用格式的涌现,我们需要新的工具:
-
格式转换器:在JSON、TOON、CSV等之间自动转换
-
格式推荐器:根据数据特征推荐最优格式
-
混合编码器:在单个文档中混用多种格式
未来的"数据工程师"可能要精通多种格式,就像今天的程序员精通多种语言一样。
八、总结:Token经济学的现实主义
写到这里,已经4500多字了。让我们回到最初的问题:TOON值得关注吗?
我的答案是:看情况,但大概率值得。
如果你应该关注TOON
-
✅ 你的应用需要频繁向LLM传输大量表格数据
-
✅ 你对Token成本敏感(ToC产品、高频调用场景)
-
✅ 你需要榨干上下文窗口的极限
-
✅ 你的数据结构相对规整(数据库查询、日志、统计数据)
-
✅ 你希望提高LLM的数据理解准确率
如果你可以暂时忽略
-
❌ 你的调用量很小(每天几十次)
-
❌ 你的数据深度嵌套、结构复杂多变
-
❌ 你更在乎开发效率而非运行成本
-
❌ 你的团队不愿意引入新格式(学习成本)
关键要记住的事
-
TOON不是银弹。它解决的是特定问题(表格数据的Token效率),不要期待它在所有场景都完美。
-
30-60%的节省是真实的。官方Benchmark的数据经得起考验,但你的实际数据可能有差异,建议先用自己的数据测试。
-
它是翻译层,不是存储格式。你的架构不需要大改,只是在和LLM交互时转换一下。
-
社区生态正在成长。已经有了Python、Go、Rust等十多种语言的实现,工具链在快速完善。
-
这是Token经济学的早期探索。TOON可能不是终点,但它指明了方向——我们需要为AI时代重新思考数据格式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)