YoloV8改进策略:下采样改进|IPFA,下采样|信息保留特征聚合模块|即插即用
IPFAIF-YOLO 的成功,不仅在于性能提升,更在于其系统性思维不是“头痛医头”,而是从特征生成到融合的全链路优化。尽管在极端低光或严重模糊场景下仍有挑战,但该工作为无人机视觉、遥感检测等领域提供了极具价值的技术路径。未来,结合图像增强与轻量化设计,IF-YOLO 有望在边缘设备(如无人机机载芯片)上落地,真正实现“看得清、认得准、飞得稳”。
摘要
本文介绍一种信息保留特征聚合的下采样模块IPFA,用下采样模块替换步长为2的卷积模块,适用于Yolo系列的改进。我本次使用YoloV8演示如何将IPFA加入到Yolo中。
📄 论文信息
- 模型名称:IF-YOLO(Information-preserving and Fine-grained Aggregation YOLO)
- 基础架构:基于当前主流目标检测模型 YOLOv8-s
- 验证数据集:VisDrone2019(权威无人机图像数据集,包含上万张高密度、小目标、遮挡严重的航拍图)
- 核心目标:提升无人机图像中小目标、遮挡目标、复杂背景目标的检测精度
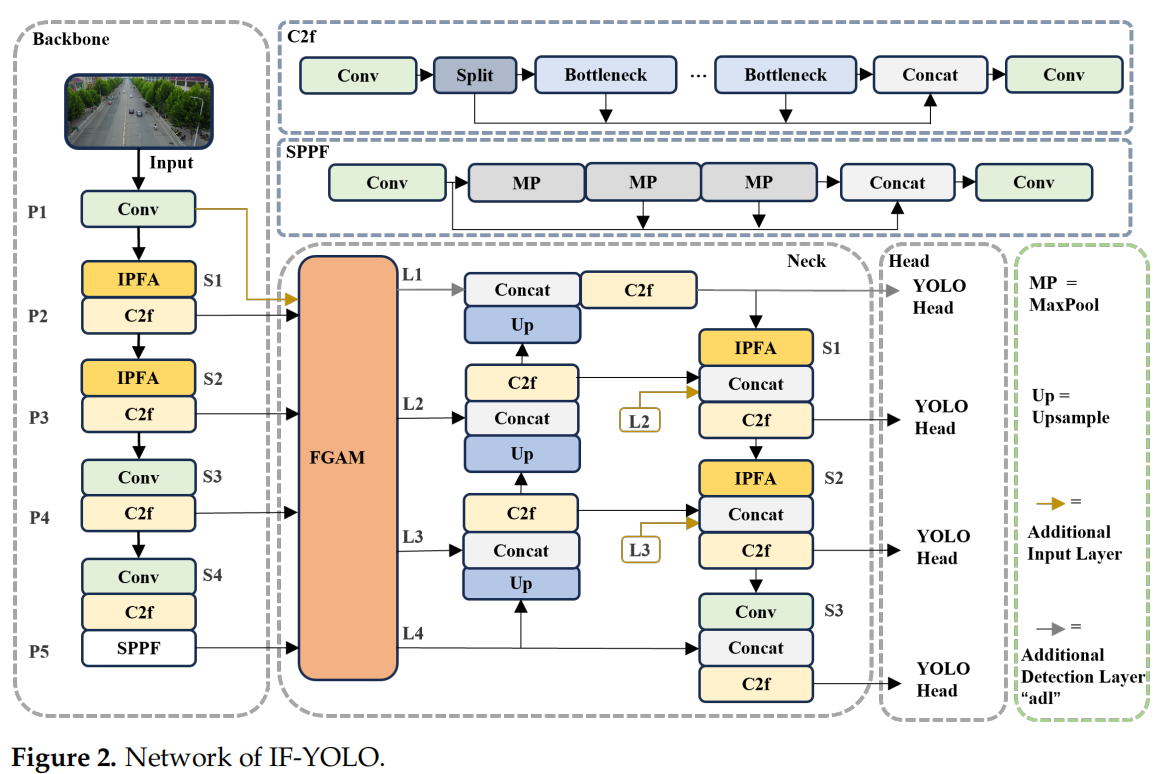
🔧 方法:三大模块协同作战
IF-YOLO 并非简单“堆参数”,而是从特征提取和特征融合两个根本问题入手,设计了三大核心模块:
1. IPFA(信息保留特征聚合模块)
传统下采样(如步长卷积)会“压缩”图像,导致小目标细节丢失。IPFA 则像一位“精细分拣员”:
- 先用 3×3 卷积扩大感受野;
- 再将特征图在空间和通道维度上切成 8 份;
- 重新拼接后,用 1×1 卷积进行信息交互。
✅ 效果:既保留了小目标的原始细节,又构建了高级语义表示。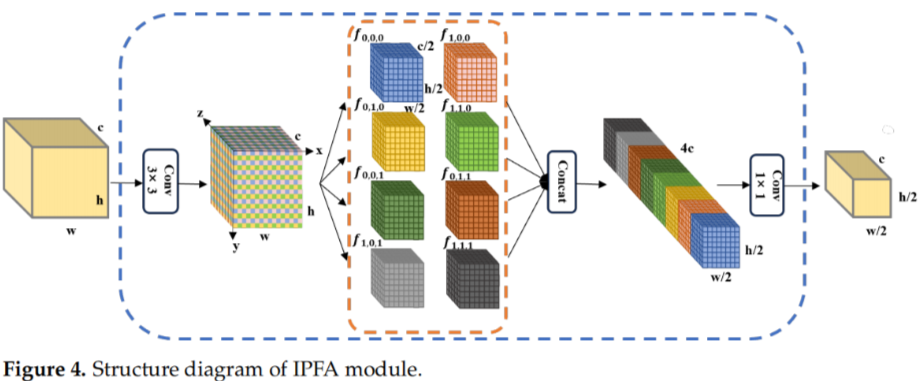
2. CSFM(冲突信息抑制特征融合模块)
不同层级的特征图直接融合,容易“语义打架”(比如浅层说“这是车”,深层说“这是树”)。CSFM 引入双路注意力机制:
- 通道注意力:判断哪些通道更重要;
- 空间注意力:聚焦目标所在区域。
✅ 效果:自动过滤冗余和冲突信息,让融合后的特征更“干净”。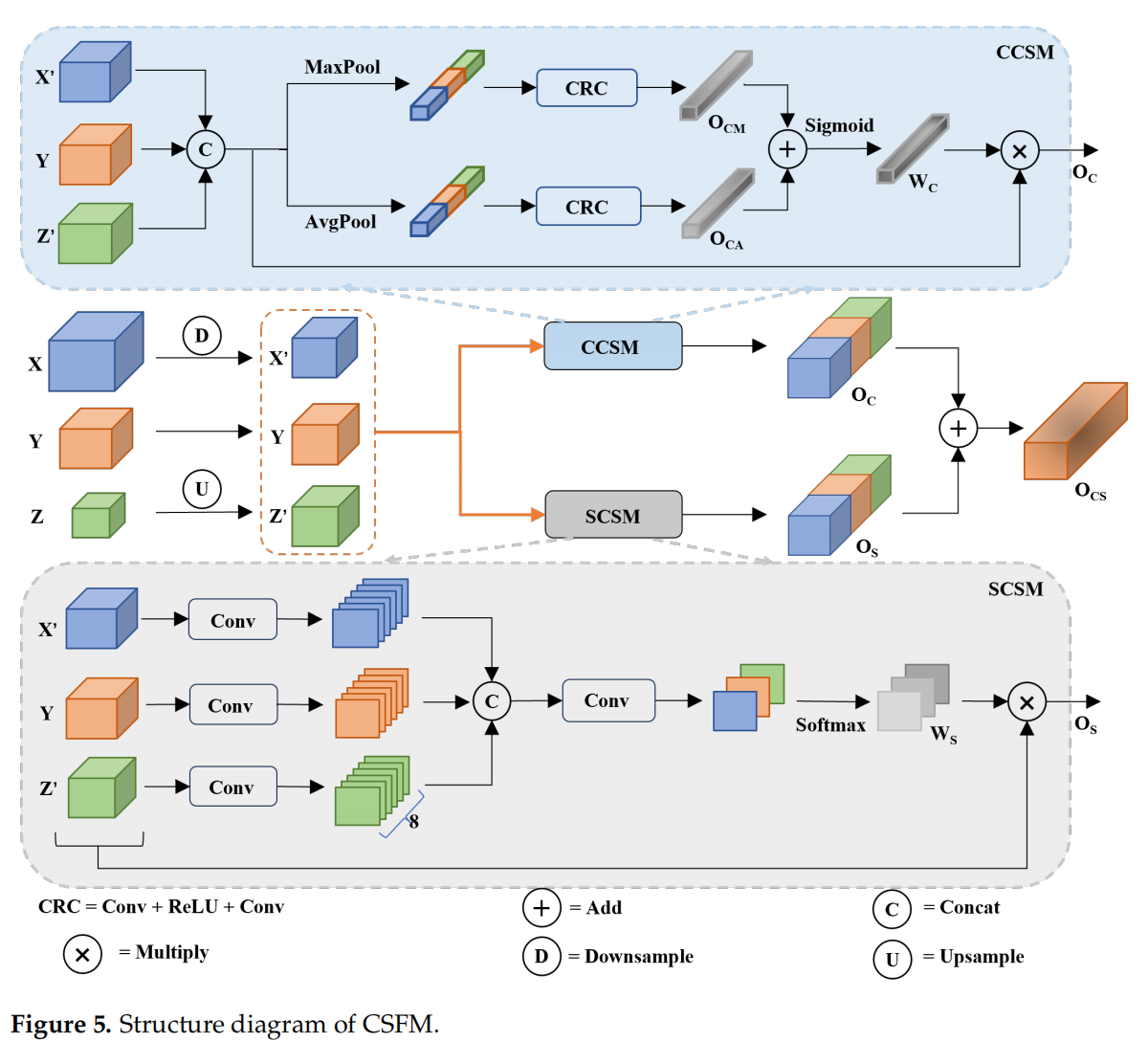
3. FGAFPN(细粒度聚合特征金字塔网络)
在传统 FPN 基础上,加入跨层连接和CSFM 模块,让浅层(细节丰富)和深层(语义强)特征充分交互。
✅ 效果:实现多尺度特征的平衡融合,特别适合无人机图像中目标尺度变化剧烈的场景。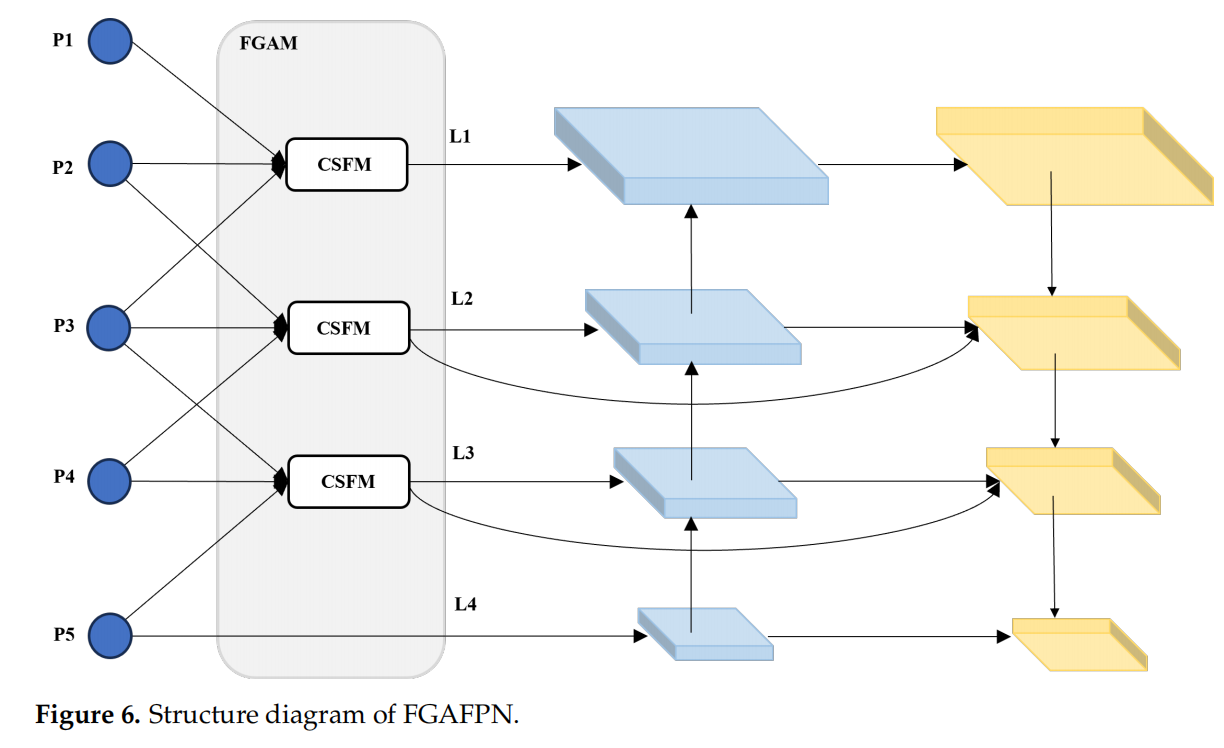
💡 创新点:直击痛点,系统性优化
- 首次系统性解决“下采样信息丢失”问题:IPFA 替代传统步长卷积,从源头保留小目标特征。
- 提出“冲突抑制”融合思想:CSFM 不是简单加权,而是主动“去噪”,提升融合质量。
- 构建更均衡的特征金字塔:FGAFPN 减少语义鸿沟,让模型在复杂背景下依然稳健。
📈 效果:精度显著提升,实测表现亮眼
在 VisDrone2019 数据集上,IF-YOLO 取得了47.3% 的 mAP@0.5,相比原始 YOLOv8-s:
- 平均精度(mAP)↑ 6.9%
- 精确率 ↑ 6.3%
- 召回率 ↑ 5.6%
更直观地说:
- 在昏暗光照下,IF-YOLO 能识别出其他模型完全漏掉的行人;
- 在桥梁遮挡场景中,它能准确框出被遮挡的车辆;
- 在密集人群区域,几乎“一个不漏”。
Grad-CAM 热力图也显示:IF-YOLO 的注意力更集中于小目标本身,而非背景噪声。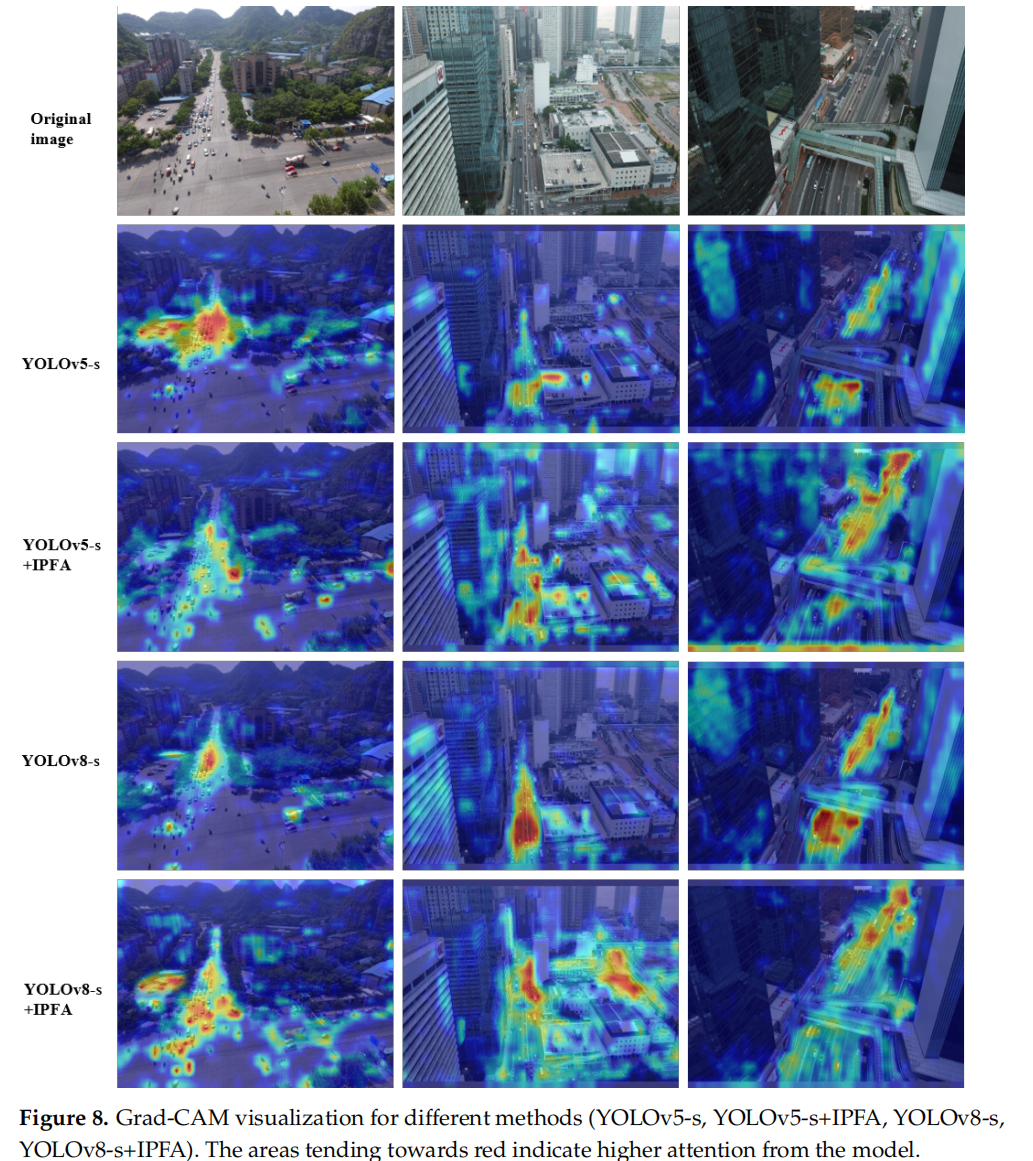
IPFA模块
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch
import torch.nn as nn
class IPFA(nn.Module):
def __init__(self, in_channels, out_channels):
super(IPFA, self).__init__()
self.conv3 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, stride=1)
self.conv1 = nn.Conv2d(4 * in_channels, out_channels, kernel_size=1)
def forward(self, x):
# Step 1: 3x3 conv
y = self.conv3(x) # [B, C, H, W]
# Step 2: 2x2x2 subsampling in H, W, C
# Split along channel first
c_half = y.shape[1] // 2
y0 = y[:, :c_half, :, :] # f_*_0
y1 = y[:, c_half:, :, :] # f_*_1
# Split along H and W (take even and odd indices)
f000 = y0[:, :, 0::2, 0::2]
f001 = y1[:, :, 0::2, 0::2]
f010 = y0[:, :, 0::2, 1::2]
f011 = y1[:, :, 0::2, 1::2]
f100 = y0[:, :, 1::2, 0::2]
f101 = y1[:, :, 1::2, 0::2]
f110 = y0[:, :, 1::2, 1::2]
f111 = y1[:, :, 1::2, 1::2]
# Step 3: Concat along channel dim
concat_feats = torch.cat([f000, f001, f100, f101, f010, f011, f110, f111], dim=1)
# Step 4: 1x1 conv
out = self.conv1(concat_feats)
return out
if __name__ == "__main__":
# 创建测试输入
batch_size, channels, height, width = 4, 64, 32, 32
x = torch.randn(batch_size, channels, height, width)
# 测试 IPFA模块
slcam = IPFA(channels, channels)
out = slcam(x)
print(f"输入形状: {x.shape}")
print(f"输出形状: {out.shape}")
代码详解
1. 导入库
import torch
import torch.nn as nn
标准 PyTorch 深度学习库。
2. 定义 IPFA 类
class IPFA(nn.Module):
def __init__(self, in_channels, out_channels):
super(IPFA, self).__init__()
self.conv3 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, stride=1)
self.conv1 = nn.Conv2d(4 * in_channels, out_channels, kernel_size=1)
in_channels: 输入通道数(如 64)out_channels: 输出通道数(通常设为与输入相同或翻倍)conv3: 一个 3×3 卷积,不改变尺寸(padding=1, stride=1),用于扩大感受野。conv1: 1×1 卷积,用于压缩通道数。注意输入通道是4 * in_channels(见下文解释)。
❓ 为什么是
4 * in_channels?
因为 8 个子特征拼接后,通道数为8 * (in_channels / 2) = 4 * in_channels。
3. forward 前向传播
Step 1: 3×3 卷积
y = self.conv3(x) # [B, C, H, W]
- 输入
x:[B, C, H, W] - 输出
y: 尺寸不变,仍为[B, C, H, W]
Step 2: 在通道维度切分
c_half = y.shape[1] // 2
y0 = y[:, :c_half, :, :] # 前半通道
y1 = y[:, c_half:, :, :] # 后半通道
- 将通道一分为二,得到
y0和y1,每个形状为[B, C/2, H, W]
Step 3: 在空间维度(H, W)进行“棋盘采样”
f000 = y0[:, :, 0::2, 0::2] # H偶, W偶 → (H/2, W/2)
f001 = y1[:, :, 0::2, 0::2]
f010 = y0[:, :, 0::2, 1::2] # H偶, W奇
f011 = y1[:, :, 0::2, 1::2]
f100 = y0[:, :, 1::2, 0::2] # H奇, W偶
f101 = y1[:, :, 1::2, 0::2]
f110 = y0[:, :, 1::2, 1::2] # H奇, W奇
f111 = y1[:, :, 1::2, 1::2]
0::2表示从索引 0 开始,每隔 1 个取 1 个(即取偶数位置)1::2表示从索引 1 开始,每隔 1 个取 1 个(即取奇数位置)- 每个
f***的形状都是[B, C/2, H/2, W/2]
✅ 这相当于对特征图进行了 2×2 的空间下采样 + 2 路通道分割,共得到 2×2×2 = 8 个子特征。
Step 4: 通道拼接(concat)
concat_feats = torch.cat([f000, f001, f100, f101, f010, f011, f110, f111], dim=1)
- 沿
dim=1(通道维度)拼接 8 个张量 - 输出形状:
[B, 8 × (C/2), H/2, W/2] = [B, 4C, H/2, W/2]
Step 5: 1×1 卷积压缩通道
out = self.conv1(concat_feats)
- 输入:
[B, 4C, H/2, W/2] - 输出:
[B, out_channels, H/2, W/2] - 实现了下采样(H, W 减半)+ 通道调整
🌟 总结:小目标检测的“新范式”
IF-YOLO 的成功,不仅在于性能提升,更在于其系统性思维:
不是“头痛医头”,而是从特征生成到融合的全链路优化。
尽管在极端低光或严重模糊场景下仍有挑战,但该工作为无人机视觉、遥感检测等领域提供了极具价值的技术路径。未来,结合图像增强与轻量化设计,IF-YOLO 有望在边缘设备(如无人机机载芯片)上落地,真正实现“看得清、认得准、飞得稳”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)