A Heterogeneous CNN Compilation Framework for RISC-V CPU and NPU Integration Based on ONNX-MLIR 论文解析
介绍
NPU专门用来解决神经网络问题,但是存在通用性的问题,比如有CNN-NPU但是面对CNN的最新算子它无法实现;CPU通用性好但是存在面对复杂计算单位能耗下效率低的问题。但目前学术界几乎没有 架构 和 工具链 解决这个问题。所以本文提出。(flaw Why not GPU)
1 为什么要将NPU与CPU异构(集成),难道NPU不是专门用来处理AI算子的吗?NPU是专门用来处理AI算子的,但是有些最新算子并不能实现。(为什么还有针对CNN的NPU-CPU集成,因为针对不同的CNN也有不同的CNN算子)
2 为什么RISCV?首先,RISCV ISA是论文CPU的架构,而并非NPU ISA,NPU ISA就是不同的CNN算子。采用RISC是因为该ISA有针对特定应用的子ISA设计,所以可以针对CNN设计指令集。但是目前没有针对异构架构的指令集。(flaw 降低CPU的通用性让其他算子的NPU与一块CPU集成成为不可能)
要做的事情
设计CNN RISCV ISA
该ISA的在异构上架构的编译工具链
流程
申请ONNX算子,完善MLIR和LLVM工具链
先通过神经网络得到onnx图
1 算子打包和算子融合
在onnx-mlir编译器中,将图逐步变为(lowering) onnx方言(onnx dialect in mlir) 然后变为(lowering) mlir方言
graph -> onnx dialect 过程,不仅进行了lowering,还有算子打包(分配到不同的设备某号CPU和某号NPU)和算子融合(中间结果采用缓存存储,避免频繁读写内存)

当上述过程进行完成,onnx方言被分为原本就有的cpu设备onnx方言、原本就有的npu设备onnx方言、本文新增的cpu设备onnx方言,这三种不同的指令会按照设备(target)的不同被后文中会提到的任务调度器分配到不同的设备执行(perform)。对于原本就有的cpu设备onnx方言,会按照原本编译流程:lower到 llvm方言,然后通过llvm编译器编译为machine code;对于其余两种均在npu的"黑盒"编译器中运行(因为不开源,而不是因为不可解释)。
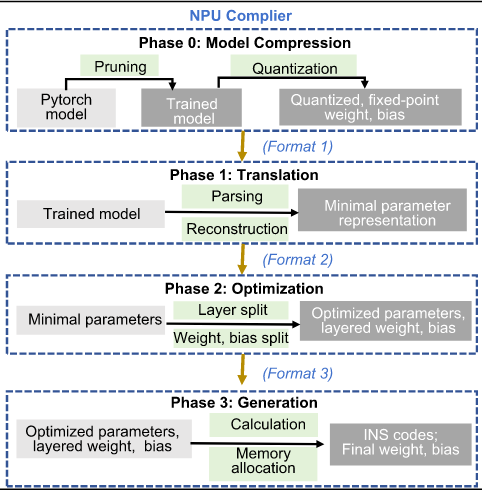
以下是本文新增的所有npu的 onnx 方言

2 平台匹配
数据匹配:
在npu处理的时候,默认进行二次幂的优化操作,一般策略是将非二次幂填补,但在异构架构中我们需要对于填补后的结果删除,所以我们直接修改cpu的数据变成二次幂。除此以外还有其他cpu与npu数据精度不同问题(cpu是float64而NPU是int8),有两种方案。方案一伪定点运算:将输入cpu的npu数据映射为float32,经过cpu的虚假浮点计算后,输出的时候量化为int8;方案二定点运算:将cpu的数据量化为int8,与npu保持一致。但对于不支持定点运算的网络层(如Softmax),cpu不难完全定点,AI给出的结果是在这个未知采用局部浮点。。
内存布局匹配:
将cpu的output简单更改为npu的内存布局,减少内存布局转换的开销
硬件实现
1 任务调度器
该模块分为3个模式。上文提到的将cpu的onnx方言分配到cpu,npu的分配到npu,是默认模式。具体是npu算子会有一个容许列表Td,如果不在这个列表之中就会被分配到cpu。
All_CPU模式:强制所有运算在cpu上进行,以验证(valid)npu运算的正确性;
用户自定义模式:通过运算符指定用户使用的设备,原文是说方便用户尝试各种配置来评估cpu和npu的加速能力。
(感觉其他两个模式根本没有必要,对于ASCI来说,如果npu运算有不正确的可能性,那么这个电路需要重新设计,所以没有ALL_CPU Mode的必要,另一个模式的话评估这个能力来做什么呢(?))
2 权重量化和重排序
对于上文提到的cpu float64转换为int8以适应npu数据格式的实现结构,涉及到动态量化过程,可见reference[1]
另外,还对于npu编译器优化后的网络参数进行重排序,这是编译过程引入了循环平铺,所以需要再排序以为npu定制
将上述得到的两个数据存储到另外开辟的内存以增加访存速度。
3 内存管理
自检模块模拟内存分配,所以计算完成后才会释放内存,以避免读写并发导致的内存,另外使用离散内存,避免带宽的争夺。
关于一些词汇的辨析(What)
overhead 开销:在同一个任务中,由于指令的数量不同,造成的影响,比如资源消耗、数据吞吐量(数据带宽)
latency 延时:通常指系统级延时,而不是单个指令的延时,完成同一个任务所需要的时间。
二者关系:
latency 延时越大即完成同一个任务所需时间越多,证明load/store指令越多(假设是同一个硬件),数据吞吐量也就越小。所以延时和数据吞吐量是正相关的。而overhead则是一个更加宽广的概念,还包括资源的消耗情况,所以与latency没有可比性,或者说latency是overhead的一个属性。
就这篇论文来看,npu相较于cpu gpu等通用asic,更倾向于专用功能ic,所以它的周期更长、迭代速度缓慢,这就要用到通用的ic 比如cpu的协助。
批判性观点
本文的题目是 一个基于 ONNX-MLIR 的用于 RISC-V CPU 与 NPU 集成的异构 CNN 编译框架 ,这个题目看起来CPU和NPU是平级的处理核心(core,即能执行指令流的硬件),可是在架构中NPU往往看作加速器,所以题目更适合为 Integration of a RISC-V CPU core with an NPU accelerator
为什么不将npu看作npu,本质原因是它并非指令通用指令集(如RISCV ARM x86),而执行的领域专用ISA(DSISA)
Reference
这里是论文参考文献中出现的一些重要的文献
[1] Y.-C. Wu and C.-T. Huang, “Efficient dynamic fixed-point quantization of CNN inference accelerators for edge devices,” in Proc. Int. Symp. VLSI Design, Autom. Test (VLSI-DAT), 2019, pp. 1–4.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)