ICCV 2025 |具身智能认知进化全路径!智能体在语义理解、泛化推理和适应开放世界上实现质的飞跃-研梦非凡
如何构建一个真正具有认知鲁棒性的智能体?它不仅要“看得见”,更要“看得懂”,还要“持续学”
【来源:JOJO极智算法微信公众号】
具身智能(Embodied AI)的终极目标是让机器人像人一样在真实世界中感知和交互。但真实世界不是一个封闭的数据集,它充满了未知、模糊和永无止境的新事物。一个智能体如何从“一无所知”开始,学会分割它从未见过的物体?当它不断遇到新类别时,又如何保证“学新不忘旧”?
想要解决这些问题,仅仅在一个封闭数据集上刷高精度是远远不够的。ICCV 2025 上的这五篇重磅论文,为我们完整地描绘了智能体在“开放世界”中实现认知进化的全路径:从“无标签”自学,到“零样本”推理,再到“开放词汇”泛化,最终实现“持续学习”!
从“无标签”开始自学
《AutoQ-VIS: Improving Unsupervised Video Instance Segmentation via Automatic Quality Assessment》
在真实环境中,为视频中的每一帧、每一个物体都打上像素级标签,成本高到难以想象。那么,模型能否从“一无所知”(即无标签视频)中学会分割呢?
AutoQ-VIS巧妙地回答了这个问题。它采用了一种“自力更生”的质量引导自训练(quality-guided self-training)策略。
创新点:整个框架是一个闭环系统。首先,它使用合成数据(如 VideoCutLER)启动一个初始的 VIS 模型。然后,该模型在真实的无标签视频上生成“伪标签”(Pseudo Masks)。
亮点:核心在于引入了一个“掩码质量预测器”(Mask Quality Predictor)。这就像一个“自动助教”,它会给模型自己生成的伪标签打分。只有分数高、质量好的伪标签才会被“过滤”出来,加入到训练集中,用于下一轮的模型迭代。
成果:通过这种“自己教自己,自己给自己打分”的循环,模型从合成数据出发,逐步适应到真实视频,在无监督视频实例分割任务上实现了 SOTA,超越了 VideoCutLER 4.4% 的。
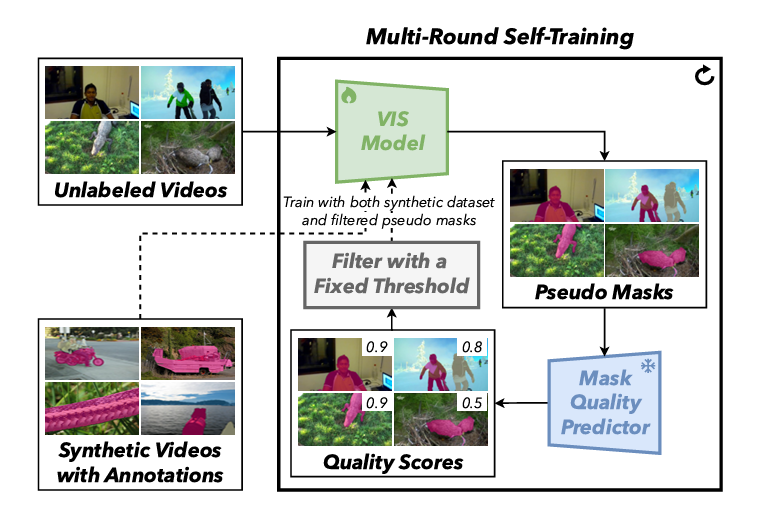
模型(VIS Model)在无标签视频上生成伪掩码,质量预测器(Mask Quality Predictor)对其打分,高质量的掩码被筛选出来反哺模型训练,实现闭环迭代。
给定“模板”的零样本分割
《Conditional Latent Diffusion Models for Zero-Shot Instance Segmentation》
零样本实例分割 (ZSI),即在没有任何训练的情况下,仅凭一个“模板”(template)就分割出特定的目标,实现抓取等任务。
OC-DiT带来了一种全新的思路:用生成模型来做分割。
创新点:论文提出了一种“物体条件扩散模型”(Object-Conditioned Diffusion Transformer, OC-DiT)。它借鉴了 Stable Diffusion 等模型的思想,将分割视为一个“去噪生成”过程。
亮点:整个生成过程是有条件的。模型从一张噪声图开始,同时将“输入图像”和“物体模板”(即你想分割的物体的视觉描述符)作为条件。在扩散模型的引导下,噪声被逐步“去噪”,最终“生成”出你想要的那个特定物体的掩码。
成果:这种生成式分割范式威力巨大。OC-DiT 仅在合成数据上训练,就能直接应用在真实世界的基准测试上,并达到 SOTA 性能,真正实现了“零样本”泛化。
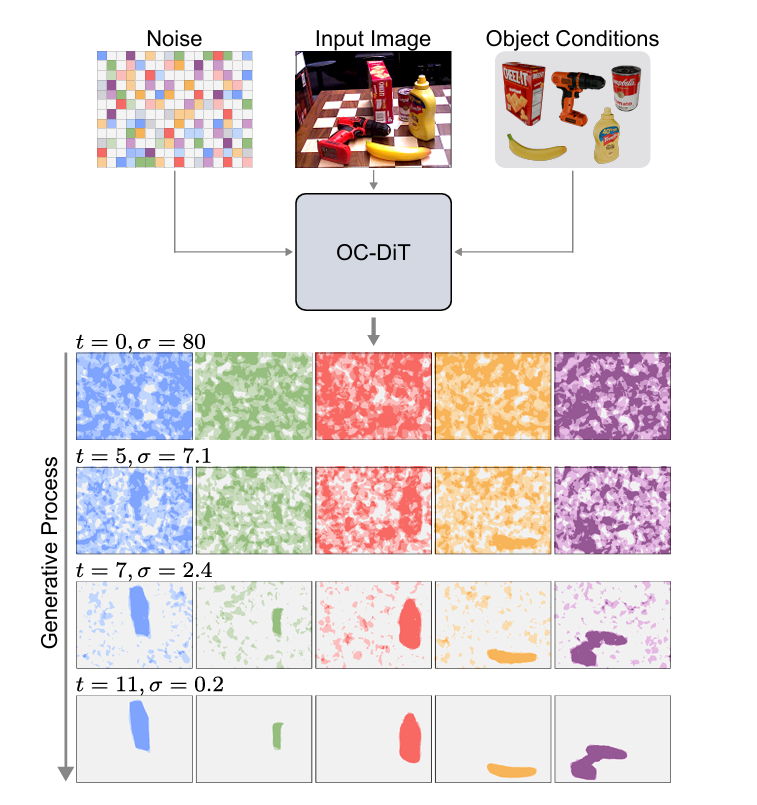
模型从噪声(t=0)开始,在输入图像和物体条件(Object Conditions)的共同引导下,逐步去噪,最终在 t=11 时生成了精确的实例掩码。
分割“任意文本”所描述的物体
从“特定模板”到“任意文本”,是认知泛化的关键一步,即开放词汇(Open-Vocabulary)分割。这意味着机器人可以听懂人话,分割“红色的椅子”或“用来喝水的杯子”。
场景1:2D遥感
《SCORE: Scene Context Matters in Open-Vocabulary Remote Sensing Instance Segmentation》
在无人机、卫星等具身智能体上,开放词汇尤其困难。SCORE指出,在航拍视角下,“汽车”和“轮船”可能看起来非常相似。
创新点:论文的核心洞察是“场景上下文至关重要”(Scene Context Matters)。人类之所以不会搞错,是因为我们知道“汽车”在停车场,而“轮船”在水里。
亮点:SCORE 框架通过两个模块来利用上下文:
- 区域感知集成 (Region-Aware Integration):将物体“周围环境”的区域上下文特征融合到物体的视觉表征中。
- 全局上下文自适应 (Global Context Adaptation):使用“遥感专用”的 CLIP 模型,将整个场景的“全局上下文”注入到文本 embedding 中,让文本理解更“接地气”。
成果:该方法在新建立的开放词汇遥感实例分割基准上实现了 SOTA 性能。与之前的SOTA模型相比,SCORE 在 iSAID 和 SIOR 两个训练集上的跨数据集评估平均分别提升了 5.53% 和 4.32%。在定性对比中(见下图),SCORE 成功分割了基线模型无法识别的“足球场”、“立交桥”等新类别 ,并凭借上下文理解,正确区分了基线会混淆的“轮船”和“车辆”。
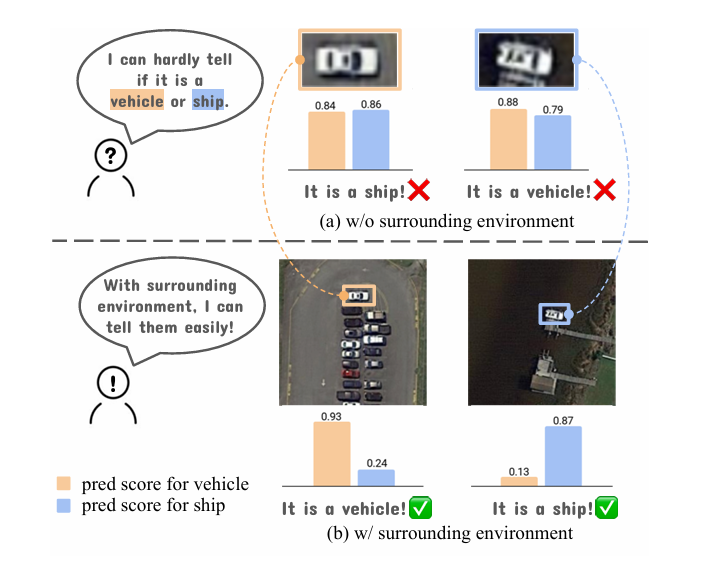
在没有上下文时(a),模型无法区分车辆和轮船。有了上下文(b),模型看到停车场或水域,就能轻松做出正确分类。
场景2:3D室内
《Details Matter for Indoor Open-vocabulary 3D Instance Segmentation》
对于在室内移动的机器人,这个任务必须在 3D 空间中完成。OV-3DIS探索了如何将开放词汇能力从 2D 提升到 3D。
创新点:论文标题就点明了核心——“细节决定成败”(Details Matter)。他们提出了一套精心设计的“秘籍”(recipe),通过优化流程中的关键细节来解决 3D 开放词汇的挑战。
亮点:
- **Alpha-CLIP:**抛弃了标准的 CLIP,转而使用 Alpha-CLIP。它利用 3D 提议(proposal)生成的 2D 掩码作为“alpha 通道”,强制 CLIP 只关注物体本身,消除背景噪声的干扰。
- SMS 分数:提出了一种“标准化最大相似度”(SMS)分数。它通过对场景内的相似度进行标准化,能有效过滤掉那些“看起来有点像但又不是”的假阳性结果,大幅提升了精度。
成果:凭借这些精妙的细节优化,该方法在 ScanNet200 等基准上取得了 SOTA,甚至超越了部分“闭集”方法(即在全监督数据上训练的方法)。

模型不仅能分割“红椅子”(red chair)等带属性的物体,还能理解“用来喝水的”(drink water)或“用来热芝士通心粉的”(heat mac & cheese)等功能性描述。
永不遗忘的“持续学习”
《Hierarchical Visual Prompt Learning for Continual Video Instance Segmentation》
真实世界的智能体必须能“活到老,学到老”,当它今天学会了分割“人”,明天学会了“飞机”,它必须还要记得“人”是什么,而不能发生“灾难性遗忘”(catastrophic forgetting)。这就是具身智能认知挑战的“终局”:持续学习(Continual Learning)。
HVPL首次定义并解决了这个名为“持续视频实例分割”(CVIS)的全新问题。
创新点:论文提出了一种“分层视觉提示学习”(HVPL)框架。它冻结了主模型,仅学习轻量的“提示”(Prompt),并通过两个层级来对抗遗忘。
亮点:
- 帧级别遗忘补偿:这一层的核心是“正交梯度校正”(OGC)模块。在学习新任务(如“飞机”)时,它会把新任务的梯度“投影”到一个与旧任务(如“人”)特征空间“正交”的子空间中。这在数学上保证了学习新知识的同时,对旧知识的干扰降到最低。
- 视频级别遗忘补偿:仅有帧级别还不够,视频任务的关键是时间。HVPL 设计了一个“视频上下文解码器”,它能捕捉跨帧的结构化关系,并将这种“全局视频上下文”传播到一个“视频提示”(Video Prompt)中,从而在时间维度上补偿遗忘。
成果:HVPL 通过这种“帧级正交”+“视频级上下文”的双重保障,在 CVIS 任务上大幅超越了其他基线方法,为实现永不遗忘的具身感知迈出了关键一步。
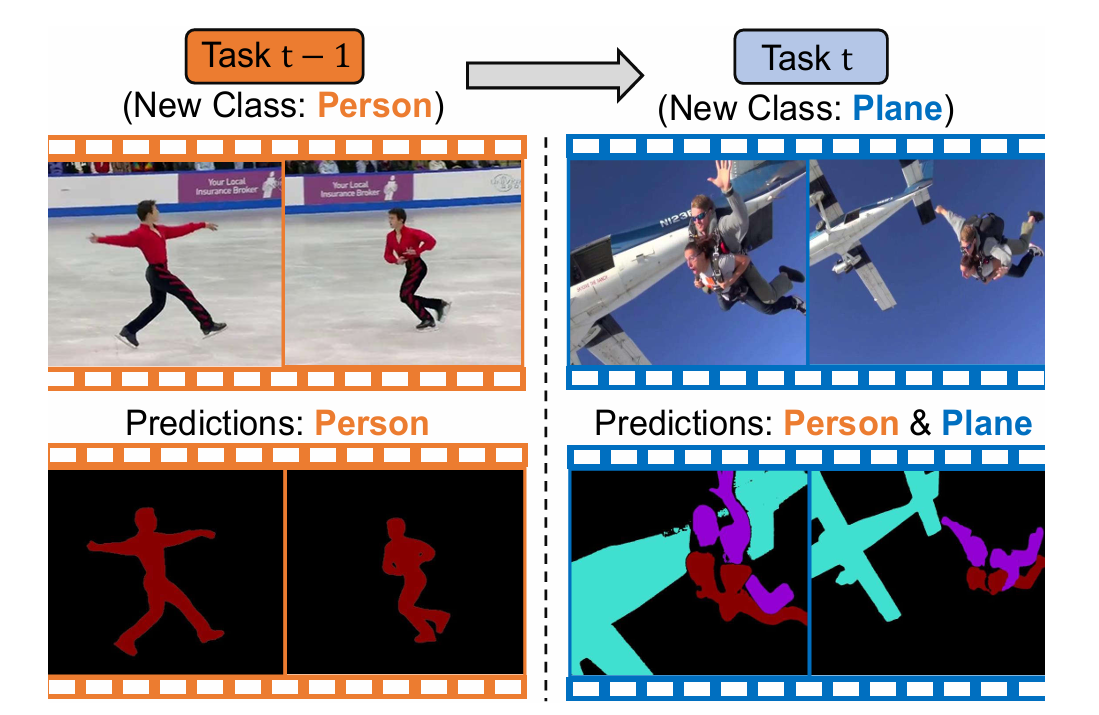
在任务 t-1,模型学习分割“人”。在任务 t,模型学习新类别“飞机”,但必须同时保持对“人”的分割能力,不能遗忘。
迈向真正“看懂”世界的智能
如何构建一个真正具有认知鲁棒性的智能体?它不仅要“看得见”,更要“看得懂”,还要“持续学”。
这五篇论文共同勾勒出了具身智能体“认知进化”的蓝图。从“无师自通”的自训练,到“看版识物”的零样本生成,再到“通晓语言”的开放词汇理解,最后到“终身学习”的持续认知。这不仅仅是分割精度的提升,更是智能体在语义理解、泛化推理和适应开放世界上质的飞跃。未来的具身智能,必将建立在这样坚实的认知基础之上。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)