Matlab一键实现Transformer多输出预测+NSGAII多目标工艺参数优化
工艺参数优化问题有着特定的问题背景和实验设置,很容易发到SCI一区期刊上。因此,今天给大家带来一期工艺参数优化的模型,本期模型也属于尚未发表的创新点,知网和WOS都还没有人用过,能自动保存最优特征组合的Excel,非常适合新手小白。
声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
之前给大家带来过一期NRBO-BP结合NSGAII实现工艺参数优化的推文:
保姆级教程!NRBO-BP回归+NSGAII多目标优化一键实现工艺参数优化!自动保存最优特征组合!
据我所知,这类问题有着特定的问题背景和实验设置,很容易发到SCI一区期刊上。
不过,后来有小伙伴说,想要更加新颖的一些预测模型。因此,今天给大家带来一期基于Transformer多输出回归预测+NSGAII多目标优化的工艺参数优化的模型,本期模型也属于尚未发表的创新点,知网和WOS都还没有人用过。并且,可以自动保存最优特征组合的Excel,使用起来非常简单,非常适合新手小白。
有些小伙伴还不理解工艺参数优化的原理。举个例子,在化工反应工艺优化中,我们需要提高产品纯度和产量,同时降低能耗。这就要求我们首先利用机器学习算法根据反应温度、压力、催化剂用量三个工艺参数特征来预测反应转化率、产品纯度等指标,也就是找到输入与输出之间的关系。因为我们的实验经费是有限的,不可能找到所有的特征组合一组一组去亲自做实验,所以我们需要基于多目标优化算法(比如NSGA-II)找到最优的三个工艺参数特征组合,从而使目标最大或最小化。
您只需做的工作:替换Excel数据,设置好相关参数,一键运行main文件即可!
(Ps:4个目标也可以哦~)
工艺参数优化案例
本期给大家带来的数据是一个工艺参数优化的数据,数据已经进行了脱敏处理,因此用x1-x5代表特征,y1-y4代表输出,也就是5个特征4个输出的问题,这样也方便大家替换成自己的数据。
一般来说,由于需要用到多目标优化算法进行求解,因此各个输出之间最好相互独立,比如刚刚提到的例子,化工反应工艺中,我们不可能在提高产品纯度和产量的同时又能够降低能耗,这是有悖于现实的,因此我们才需要利用多目标优化算法找到一个平衡点,这也是我们找到最优特征组合的目的。
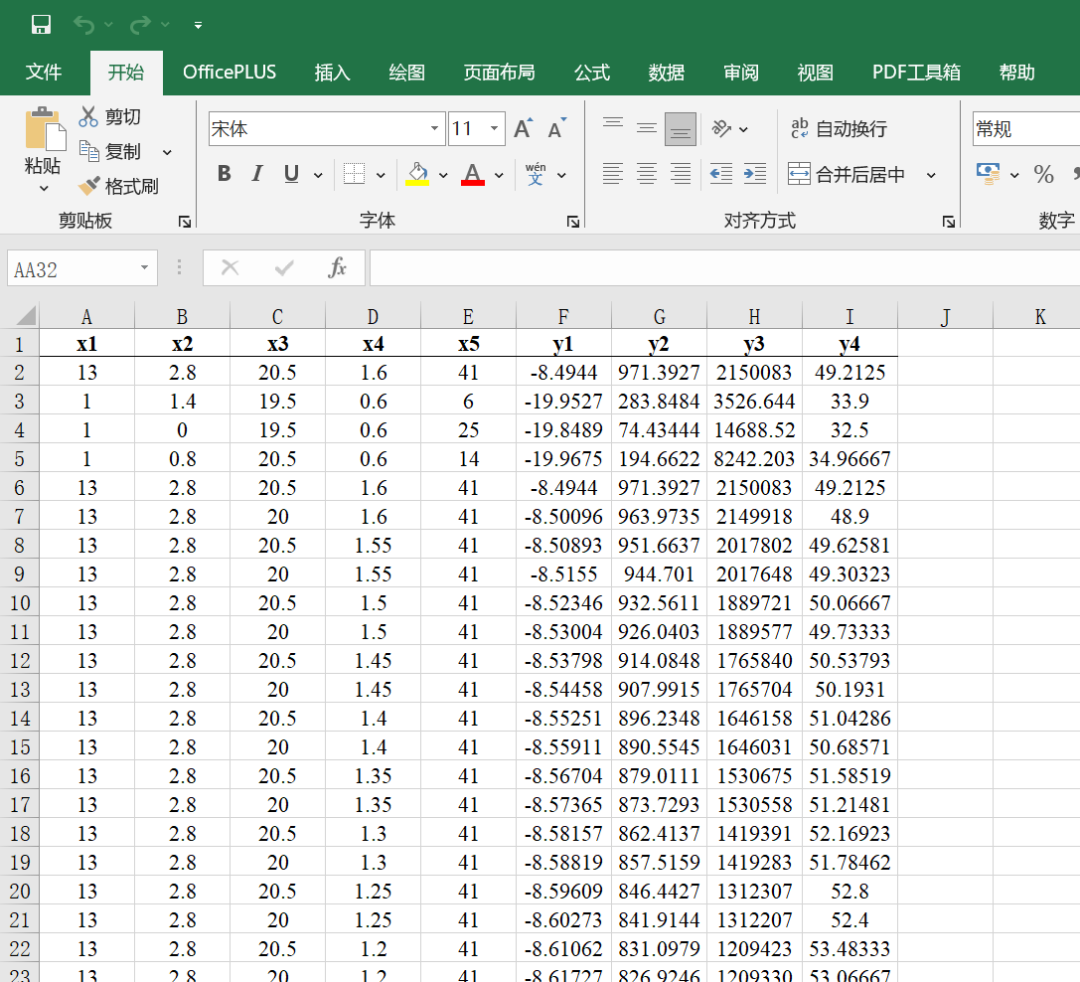
小伙伴们在更换自己的数据时,只需将几个输出变量只需放在最后几列即可,然后更改outdim变量,前面的特征数量放多少都可以。
比如,你有10个特征4个输出变量,只需把这4个变量放在最后4列,前面10列放特征即可,然后在代码里找到outdim变量更改为4即可,其余代码无需更改,非常方便适合新手小白!
%% 导入数据
res = xlsread('数据集.xlsx');
%% 划分训练集和测试集
num_size = 0.7; % 训练集占数据集比例
outdim = 4; % 最后4列为输出
num_samples = size(res, 1); % 样本个数
res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度优化参数设置
替换完自己的数据之后,因为模型不知道你的输出目标是最大还是最小,比如刚刚的例子,你需要告诉模型你的产品纯度和产量是越大越好,而能耗是越小越好,所以需要简单设置一下。
在我们的代码里,第一个需要设置的是objDir变量,设置1或-1即可,1代表最小化,‑1代表最大化,分别对应刚刚案例Excel的4个输出y1-y4。如果你有两个目标,一个目标最大一个目标最小,那你改成[-1;1]即可。
第二个需要设置的是step变量,它代表特征的取值步长,你的数据集有几个特征就需要设置几个值。这里5个值分别对应刚刚案例Excel的5个特征x1-x5,比如你某个特征需要是整数,那你设置为1即可,模型会根据你的步长来生成特征组合。
%% NSGA2多目标算法求解设置
objDir = [-1;1;1;1]; % 目标函数方向,1为最小化,‑1为最大化,可自行设置
varmin = min(res(:, 1:f_)); % 每列最小值,对应约束变量下界,可自行设置
varmax = max(res(:, 1:f_)); % 每列最大值,对应约束变量上界,可自行设置
step = [1, 0.1, 0.5, 0.05, 1]; % 约束变量取值步长
npop = 50; % 种群数量(对应输出的特征组合数量)
maxit = 100; % 迭代次数
pc = 0.85; % 交叉概率
nc = round(pc * npop / 2) * 2; % 交叉的种群数
mu = 0.2; % 变异概率
nvar = f_; % 输入变量个数
numfobj = outdim; % 目标函数个数另外,如果你想改变每个特征的最大最小值约束,可以按照上面的方法更改varmin和varmax变量~
其余参数是关于NSGA-II的,大家可以根据需要自行调整,也可以用我自己设置的默认参数~
模型原理
我们首先用Transformer模型进行预测,随后,用多目标算法中性能较好、非常受专家认可的NSGA-II算法进行求解,得到帕累托最优特征组合。当然,如果想给Transformer模型增加优化算法(比如黑翅鸢算法BKA、冠豪猪算法CPO,也可以后台私信我)。具体的模型流程如下所示:
1)数据导入与预处理。导入工艺参数与输出指标数据,划分训练集与测试集。随后对数据进行归一化处理,以便于模型的训练,同时设置算法参数。
2)Transformer神经网络训练与预测。利用训练好的模型分别对训练集和测试集数据进行预测,并对预测结果进行反归一化。
3)模型评估与可视化。计算模型预测的各项精度指标,包括RMSE、MAE、MSE、MAPE和决定系数R²,绘制拟合曲线、误差曲线、误差直方图和线性回归图,直观评估模型的预测性能。
4)多目标优化算法(NSGA-II)求解与最优工艺参数组合确定。通过NSGA-II多目标优化算法,迭代生成多个参数组合解,并计算相应的多目标函数值,获得非支配解集(Pareto前沿),并将最优参数组合导出到Excel文件中。
结果展示
废话不多说,最后展示一下我们的结果~
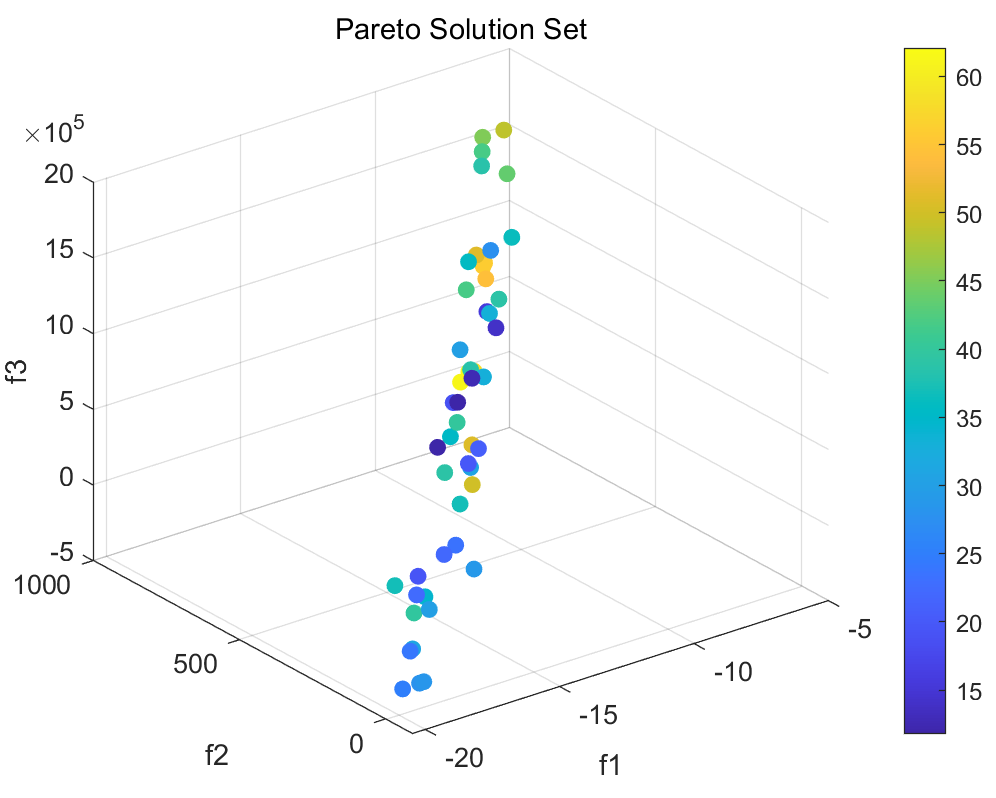
首先是帕累托解集图,如果你只有1-2个目标,那帕累托解集图就是二维的,3个目标就是三维的,我们的案例数据是4个目标,4个目标不大好可视化,因此用颜色表示第四个目标(超过4个目标就不好绘制了):
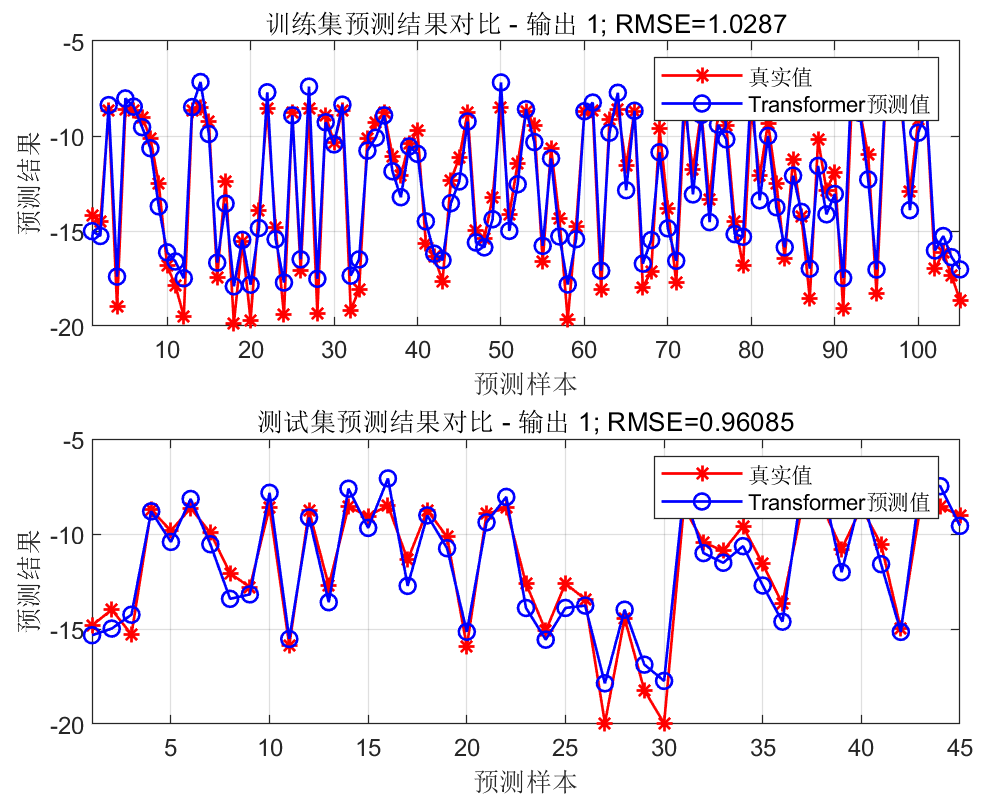
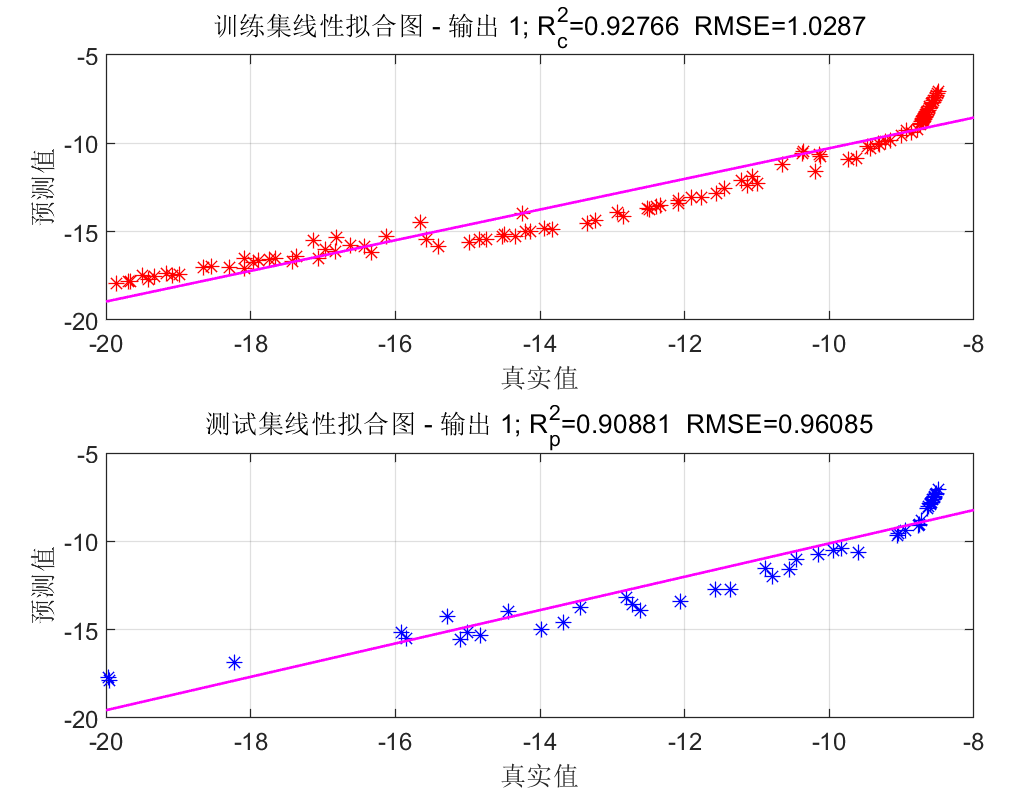
每个输出的预测结果图(几个输出就有几张这种图):
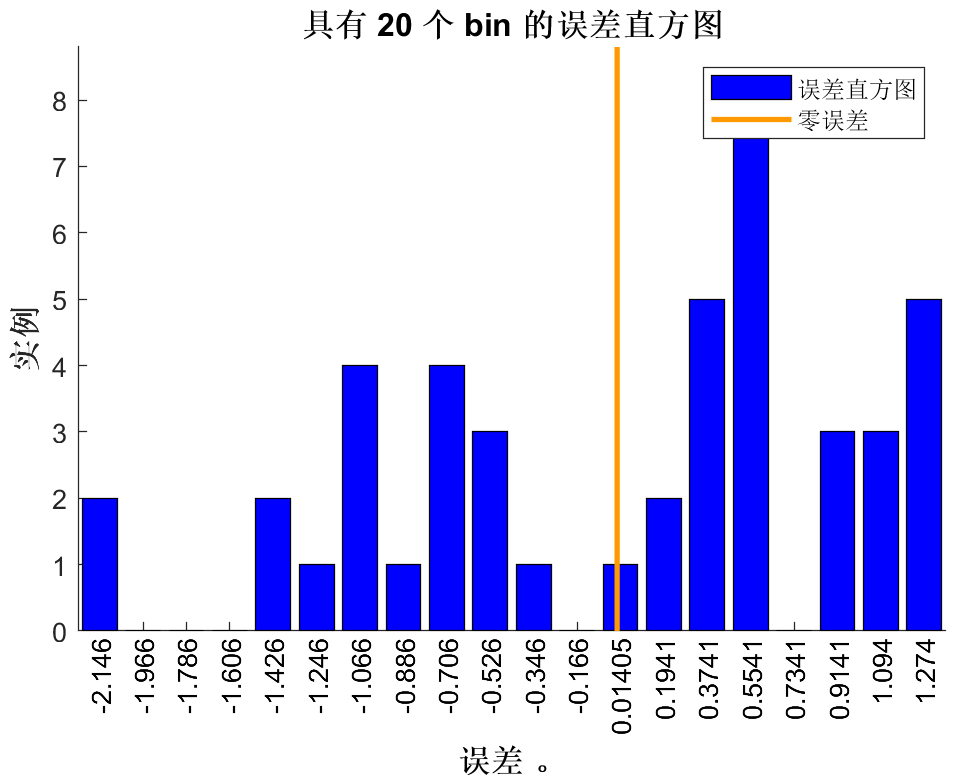
误差直方图(几个输出就有几张这种图):
回归拟合图:
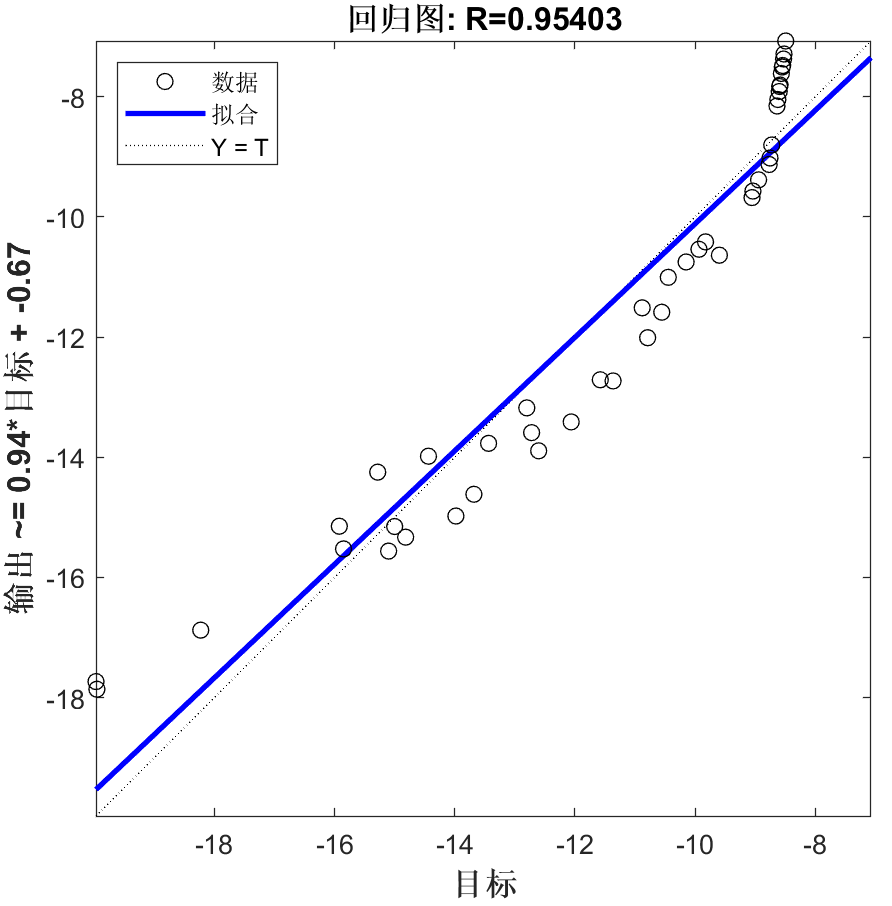
线性拟合图:
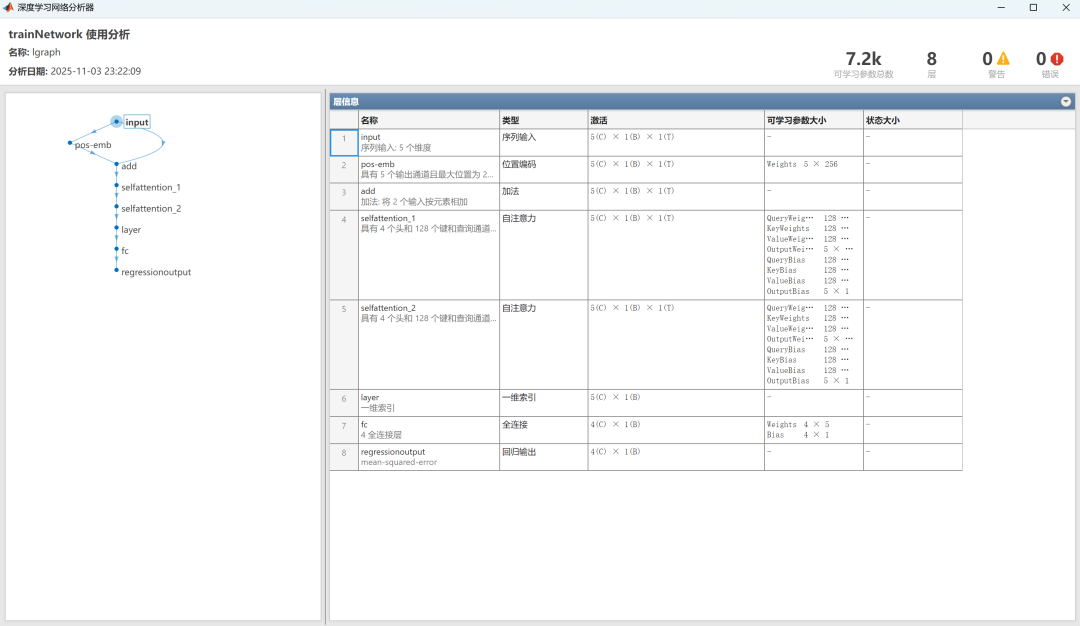
网络结构图:
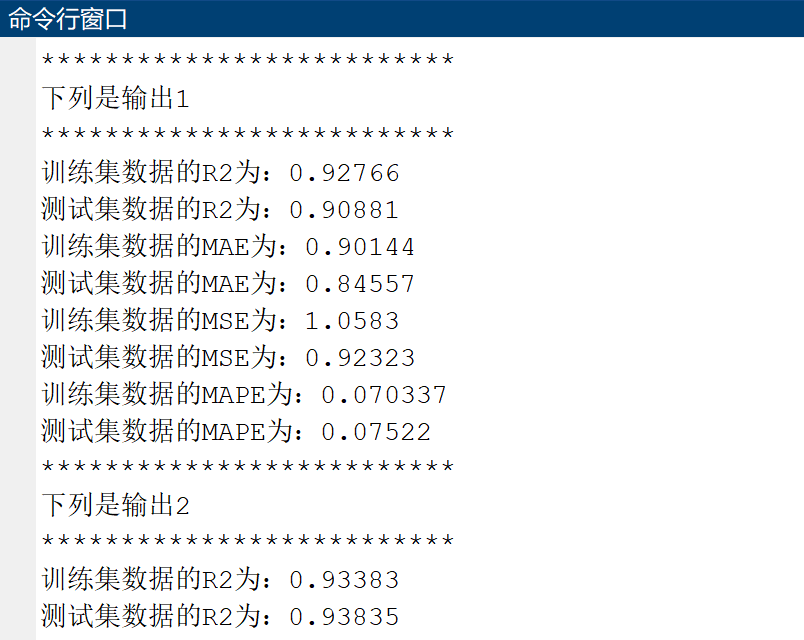
最后命令行窗口也会清晰地显示各个输出的误差指标:
以及生成一个最优特征组合的Excel,方便大家自行选择合适的帕累托解集~
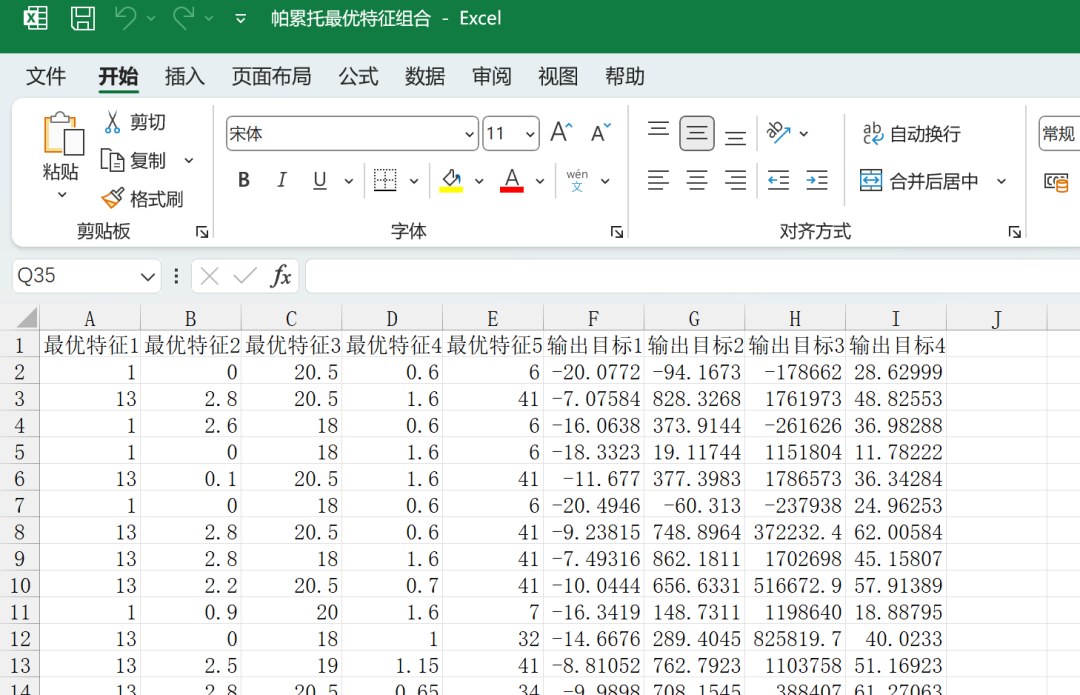
文件夹内也非常清晰,没有什么乱七八糟的文件!您需要运行的文件只有main脚本一个!!
以上所有图片,替换Excel后均可一键运行main生成,Matlab无需配置环境!比Python什么方便多了!非常适合新手小白!
完整代码
如果需要以上完整代码,只需点击下方小卡片,再后台回复关键字,不区分大小写:
工艺02

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)