LLM - AI-Video-Transcriber:用 Faster-Whisper 高效实现多语言视频自动转写
AI视频转录器是一款支持多平台的智能转录工具,具备30+视频平台兼容性(如YouTube、B站、抖音)。核心功能包括高精度语音转文字(基于Faster-Whisper模型)、AI文本优化(自动纠错/分段)、多语言摘要生成及条件式翻译(当转录与摘要语言不一致时自动调用GPT-4o)。提供三种部署方式:自动安装脚本、Docker容器化部署(推荐)和手动安装,需配置Python 3.8+和FFmpeg环
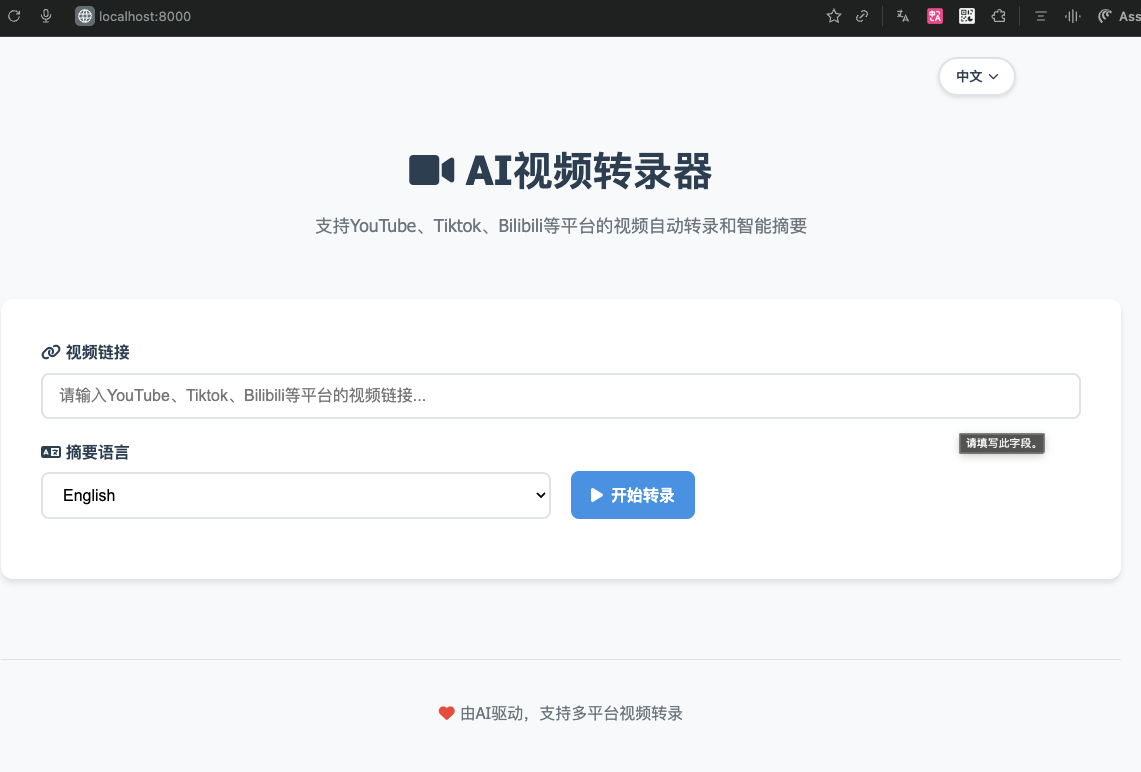
AI视频转录器
✨ 功能特性
- 🎥 多平台支持: 支持YouTube、Bilibili、抖音等30+平台
- 🗣️ 智能转录: 使用Faster-Whisper模型进行高精度语音转文字
- 🤖 AI文本优化: 自动错别字修正、句子完整化和智能分段
- 🌍 多语言摘要: 支持多种语言的智能摘要生成
- ⚡ 实时进度: 实时进度跟踪和状态更新
- ⚙️ 条件式翻译: 当所选摘要语言与检测到的转录语言不一致时,自动调用GPT‑4o生成翻译
- 📱 移动适配: 完美支持移动设备
🚀 快速开始
环境要求
- Python 3.8+
- FFmpeg
- 可选:OpenAI API密钥(用于智能摘要功能)
安装方法
方法一:自动安装
# 克隆项目
git clone https://github.com/wendy7756/AI-Video-Transcriber.git
cd AI-Video-Transcriber
# 运行安装脚本
chmod +x install.sh
./install.sh
方法二:Docker部署
# 克隆项目
git clone https://github.com/wendy7756/AI-Video-Transcriber.git
cd AI-Video-Transcriber
# 使用Docker Compose(最简单)
cp .env.example .env
# 编辑.env文件,设置你的OPENAI_API_KEY
docker-compose up -d
# 或者直接使用Docker
docker build -t ai-video-transcriber .
docker run -p 8000:8000 -e OPENAI_API_KEY="你的API密钥" ai-video-transcriber
方法三:手动安装
- 安装Python依赖(建议使用虚拟环境)
# 创建并启用虚拟环境(macOS推荐,避免 PEP 668 系统限制)
python3 -m venv venv
source venv/bin/activate
python -m pip install --upgrade pip
pip install -r requirements.txt
- 安装FFmpeg
# macOS
brew install ffmpeg
# Ubuntu/Debian
sudo apt update && sudo apt install ffmpeg
# CentOS/RHEL
sudo yum install ffmpeg
- 配置环境变量(摘要/翻译功能需要)
# 必需:启用智能摘要/翻译
export OPENAI_API_KEY="your_api_key_here"
# 可选:如使用自建/代理的OpenAI兼容网关,按需设置
export OPENAI_BASE_URL="https://oneapi.basevec.com/v1"
启动服务
python3 start.py
服务启动后,打开浏览器访问 http://localhost:8000
生产模式(推荐用于长视频)
为了避免在处理长视频时SSE连接断开,建议使用生产模式启动(禁用热重载):
python3 start.py --prod
这样可以在长时间任务(30-60+分钟)中保持SSE连接稳定。
使用显式环境变量启动(示例)
source venv/bin/activate
export OPENAI_API_KEY=your_api_key_here
# export OPENAI_BASE_URL=https://oneapi.basevec.com/v1 # 如使用自定义端点
python3 start.py --prod
📖 使用指南
- 输入视频链接: 在输入框中粘贴YouTube、Bilibili等平台的视频链接
- 选择摘要语言: 选择希望生成摘要的语言
- 开始处理: 点击"开始"按钮
- 监控进度: 观察实时处理进度,包含多个阶段:
- 视频下载和解析
- 使用Faster-Whisper进行音频转录
- AI智能转录优化(错别字修正、句子完整化、智能分段)
- 生成选定语言的AI摘要
- 查看结果: 查看优化后的转录文本和智能摘要
- 如果转录语言 ≠ 所选摘要语言,会显示第三个标签页"翻译",包含翻译后的转录文本
- 下载文件: 点击下载按钮保存Markdown格式的文件(转录/翻译/摘要)
🛠️ 技术架构
后端技术栈
- FastAPI: 现代化的Python Web框架
- yt-dlp: 视频下载和处理
- Faster-Whisper: 高效的语音转录
- OpenAI API: 智能文本摘要
前端技术栈
- HTML5 + CSS3: 响应式界面设计
- JavaScript (ES6+): 现代化的前端交互
- Marked.js: Markdown渲染
- Font Awesome: 图标库
项目结构
AI-Video-Transcriber/
├── backend/ # 后端代码
│ ├── main.py # FastAPI主应用
│ ├── video_processor.py # 视频处理模块
│ ├── transcriber.py # 转录模块
│ ├── summarizer.py # 摘要模块
│ └── translator.py # 翻译模块
├── static/ # 前端文件
│ ├── index.html # 主页面
│ └── app.js # 前端逻辑
├── temp/ # 临时文件目录
├── Docker相关文件 # Docker部署
│ ├── Dockerfile # Docker镜像配置
│ ├── docker-compose.yml # Docker Compose配置
│ └── .dockerignore # Docker忽略规则
├── .env.example # 环境变量模板
├── requirements.txt # Python依赖
└── start.py # 启动脚本
⚙️ 配置选项
环境变量
| 变量名 | 描述 | 默认值 | 必需 |
|---|---|---|---|
OPENAI_API_KEY |
OpenAI API密钥 | - | 否 |
HOST |
服务器地址 | 0.0.0.0 |
否 |
PORT |
服务器端口 | 8000 |
否 |
WHISPER_MODEL_SIZE |
Whisper模型大小 | base |
否 |
Whisper模型大小选项
| 模型 | 参数量 | 英语专用 | 多语言 | 速度 | 内存占用 |
|---|---|---|---|---|---|
| tiny | 39 M | ✓ | ✓ | 快 | 低 |
| base | 74 M | ✓ | ✓ | 中 | 低 |
| small | 244 M | ✓ | ✓ | 中 | 中 |
| medium | 769 M | ✓ | ✓ | 慢 | 中 |
| large | 1550 M | ✗ | ✓ | 很慢 | 高 |
🔧 常见问题
Q: 为什么转录速度很慢?
A: 转录速度取决于视频长度、Whisper模型大小和硬件性能。可以尝试使用更小的模型(如tiny或base)来提高速度。
Q: 支持哪些视频平台?
A: 支持所有yt-dlp支持的平台,包括但不限于:YouTube、抖音、Bilibili、优酷、爱奇艺、腾讯视频等。
Q: AI优化功能不可用怎么办?
A: 转录优化和摘要生成都需要OpenAI API密钥。如果未配置,系统会提供Whisper的原始转录和简化版摘要。
Q: 出现 500 报错/白屏,是代码问题吗?
A: 多数情况下是环境配置问题,请按以下清单排查:
- 是否已激活虚拟环境:
source venv/bin/activate - 依赖是否安装在虚拟环境中:
pip install -r requirements.txt - 是否设置
OPENAI_API_KEY(启用摘要/翻译所必需) - 如使用自定义网关,
OPENAI_BASE_URL是否正确、网络可达 - 是否已安装 FFmpeg:macOS
brew install ffmpeg/ Debian/Ubuntusudo apt install ffmpeg - 8000 端口是否被占用;如被占用请关闭旧进程或更换端口
Q: 如何处理长视频?
A: 系统可以处理任意长度的视频,但处理时间会相应增加。建议对于超长视频使用较小的Whisper模型。
Q: 如何使用Docker部署?
A: Docker提供了最简单的部署方式:
前置条件:
- 从 https://www.docker.com/products/docker-desktop/ 安装Docker Desktop
- 确保Docker服务正在运行
快速开始:
# 克隆和配置
git clone https://github.com/wendy7756/AI-Video-Transcriber.git
cd AI-Video-Transcriber
cp .env.example .env
# 编辑.env文件设置你的OPENAI_API_KEY
# 使用Docker Compose启动(推荐)
docker-compose up -d
# 或手动构建运行
docker build -t ai-video-transcriber .
docker run -p 8000:8000 --env-file .env ai-video-transcriber
常见Docker问题:
- 端口冲突:如果8000端口被占用,可改用
-p 8001:8000 - 权限拒绝:确保Docker Desktop正在运行且有适当权限
- 构建失败:检查磁盘空间(需要约2GB空闲空间)和网络连接
- 容器无法启动:验证.env文件存在且包含有效的OPENAI_API_KEY
Docker常用命令:
# 查看运行中的容器
docker ps
# 检查容器日志
docker logs ai-video-transcriber-ai-video-transcriber-1
# 停止服务
docker-compose down
# 修改后重新构建
docker-compose build --no-cache
Q: 内存需求是多少?
A: 内存使用量根据部署方式和工作负载而有所不同:
Docker部署:
- 基础内存:空闲容器约128MB
- 处理过程中:根据视频长度和Whisper模型,需要500MB - 2GB
- Docker镜像大小:约1.6GB磁盘空间
- 推荐配置:4GB+内存以确保流畅运行
传统部署:
- 基础内存:FastAPI服务器约50-100MB
- Whisper模型内存占用:
tiny:约150MBbase:约250MBsmall:约750MBmedium:约1.5GBlarge:约3GB
- 峰值使用:基础 + 模型 + 视频处理(额外约500MB)
内存优化建议:
# 使用更小的Whisper模型减少内存占用
WHISPER_MODEL_SIZE=tiny # 或 base
# Docker部署时可限制容器内存
docker run -m 1g -p 8000:8000 --env-file .env ai-video-transcriber
# 监控内存使用情况
docker stats ai-video-transcriber-ai-video-transcriber-1
Q: 网络连接错误或超时怎么办?
A: 如果在视频下载或API调用过程中遇到网络相关错误,请尝试以下解决方案:
常见网络问题:
- 视频下载失败,出现"无法提取"或超时错误
- OpenAI API调用返回连接超时或DNS解析失败
- Docker镜像拉取失败或极其缓慢
解决方案:
- 切换VPN/代理:尝试连接到不同的VPN服务器或更换代理设置
- 检查网络稳定性:确保你的网络连接稳定
- 更换网络后重试:更改网络设置后等待30-60秒再重试
- 使用备用端点:如果使用自定义OpenAI端点,验证它们在你的网络环境下可访问
- Docker网络问题:如果容器网络失败,重启Docker Desktop
快速网络测试:
# 测试视频平台访问
curl -I https://www.youtube.com/
# 测试OpenAI API访问(替换为你的端点)
curl -I https://api.openai.com
# 测试Docker Hub访问
docker pull hello-world
如果问题持续存在,尝试切换到不同的网络或VPN位置。
🎯 支持的语言
转录
- 通过Whisper支持100+种语言
- 自动语言检测
- 主要语言具有高准确率
摘要生成
- 英语
- 中文(简体)
- 日语
- 韩语
- 西班牙语
- 法语
- 德语
- 葡萄牙语
- 俄语
- 阿拉伯语
- 以及更多…
📈 性能提示
-
硬件要求:
- 最低配置: 4GB内存,双核CPU
- 推荐配置: 8GB内存,四核CPU
- 理想配置: 16GB内存,多核CPU,SSD存储
-
处理时间预估:
视频长度 预估时间 备注 1分钟 30秒-1分钟 取决于网络和硬件 5分钟 2-5分钟 推荐首次测试使用 15分钟 5-15分钟 适合日常使用
🤝 源码地址
https://github.com/wendy7756/AI-Video-Transcriber
致谢
- yt-dlp - 强大的视频下载工具
- Faster-Whisper - 高效的Whisper实现
- FastAPI - 现代化的Python Web框架
- OpenAI - 智能文本处理API
实战部署
克隆项目
# 克隆项目
git clone https://github.com/wendy7756/AI-Video-Transcriber.git

切换模型到DeepSeek
修改 summarizer.py 的 model 为 deepseek-chat
完整源码如下:
import os
import openai
import logging
from typing import Optional
logger = logging.getLogger(__name__)
class Summarizer:
"""文本总结器,使用OpenAI API生成多语言摘要"""
def __init__(self):
"""初始化总结器"""
# 从环境变量获取OpenAI API配置
api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_BASE_URL")
if not api_key:
logger.warning("未设置OPENAI_API_KEY环境变量,将无法使用摘要功能")
if api_key:
if base_url:
self.client = openai.OpenAI(api_key=api_key, base_url=base_url)
logger.info(f"OpenAI客户端已初始化,使用自定义端点: {base_url}")
else:
self.client = openai.OpenAI(api_key=api_key)
logger.info("OpenAI客户端已初始化,使用默认端点")
else:
self.client = None
# 支持的语言映射
self.language_map = {
"en": "English",
"zh": "中文(简体)",
"es": "Español",
"fr": "Français",
"de": "Deutsch",
"it": "Italiano",
"pt": "Português",
"ru": "Русский",
"ja": "日本語",
"ko": "한국어",
"ar": "العربية"
}
async def optimize_transcript(self, raw_transcript: str) -> str:
"""
优化转录文本:修正错别字,按含义分段
支持长文本自动分块处理
Args:
raw_transcript: 原始转录文本
Returns:
优化后的转录文本(Markdown格式)
"""
try:
if not self.client:
logger.warning("OpenAI API不可用,返回原始转录")
return raw_transcript
# 预处理:仅移除时间戳与元信息,保留全部口语/重复内容
preprocessed = self._remove_timestamps_and_meta(raw_transcript)
# 使用JS策略:按字符长度分块(更贴近tokens上限,避免估算误差)
detected_lang_code = self._detect_transcript_language(preprocessed)
max_chars_per_chunk = 4000 # 对齐JS:每块最大约4000字符
if len(preprocessed) > max_chars_per_chunk:
logger.info(f"文本较长({len(preprocessed)} chars),启用分块优化")
return await self._format_long_transcript_in_chunks(preprocessed, detected_lang_code, max_chars_per_chunk)
else:
return await self._format_single_chunk(preprocessed, detected_lang_code)
except Exception as e:
logger.error(f"优化转录文本失败: {str(e)}")
logger.info("返回原始转录文本")
return raw_transcript
def _estimate_tokens(self, text: str) -> int:
"""
改进的token数量估算算法
更保守的估算,考虑系统prompt和格式化开销
"""
# 更保守的估算:考虑实际使用中的token膨胀
chinese_chars = sum(1 for char in text if '\u4e00' <= char <= '\u9fff')
english_words = len([word for word in text.split() if word.isascii() and word.isalpha()])
# 计算基础tokens
base_tokens = chinese_chars * 1.5 + english_words * 1.3
# 考虑markdown格式、时间戳等开销(约30%额外开销)
format_overhead = len(text) * 0.15
# 考虑系统prompt开销(约2000-3000 tokens)
system_prompt_overhead = 2500
total_estimated = int(base_tokens + format_overhead + system_prompt_overhead)
return total_estimated
async def _optimize_single_chunk(self, raw_transcript: str) -> str:
"""
优化单个文本块
"""
detected_lang = self._detect_transcript_language(raw_transcript)
lang_instruction = self._get_language_instruction(detected_lang)
system_prompt = f"""你是一个专业的文本编辑专家。请对提供的视频转录文本进行优化处理。
特别注意:这可能是访谈、对话或演讲,如果包含多个说话者,必须保持每个说话者的原始视角。
要求:
1. **严格保持原始语言({lang_instruction}),绝对不要翻译成其他语言**
2. **完全移除所有时间戳标记(如 [00:00 - 00:05])**
3. **智能识别和重组被时间戳拆分的完整句子**,语法上不完整的句子片段需要与上下文合并
4. 修正明显的错别字和语法错误
5. 将重组后的完整句子按照语义和逻辑含义分成自然的段落
6. 段落之间用空行分隔
7. **严格保持原意不变,不要添加或删除实际内容**
8. **绝对不要改变人称代词(如I/我、you/你、he/他、she/她等)**
9. **保持每个说话者的原始视角和语境**
10. **识别对话结构:访谈者用"you",被访者用"I/we",绝不混淆**
11. 确保每个句子语法完整,语言流畅自然
处理策略:
- 优先识别不完整的句子片段(如以介词、连词、形容词结尾)
- 查看相邻的文本片段,合并形成完整句子
- 重新断句,确保每句话语法完整
- 按主题和逻辑重新分段
分段要求:
- 按主题和逻辑含义分段,每段包含1-8个相关句子
- 单段长度不超过400字符
- 避免过多的短段落,合并相关内容
- 当一个完整想法或观点表达后分段
输出格式:
- 纯文本段落,无时间戳或格式标记
- 每个句子结构完整
- 每个段落讨论一个主要话题
- 段落之间用空行分隔
重要提醒:这是{lang_instruction}内容,请完全用{lang_instruction}进行优化,重点解决句子被时间戳拆分导致的不连贯问题!务必进行合理的分段,避免出现超长段落!
**关键要求:这可能是访谈对话,绝对不要改变任何人称代词或说话者视角!访谈者说"you",被访者说"I/we",必须严格保持!**"""
user_prompt = f"""请将以下{lang_instruction}视频转录文本优化为流畅的段落文本:
{raw_transcript}
重点任务:
1. 移除所有时间戳标记
2. 识别并重组被拆分的完整句子
3. 确保每个句子语法完整、意思连贯
4. 按含义重新分段,段落间空行分隔
5. 保持{lang_instruction}语言不变
分段指导:
- 按主题和逻辑含义分段,每段包含1-8个相关句子
- 单段长度不超过400字符
- 避免过多的短段落,合并相关内容
- 确保段落之间有明确的空行
请特别注意修复因时间戳分割导致的句子不完整问题,并进行合理的段落划分!"""
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
max_tokens=4000, # 对齐JS:优化/格式化阶段最大tokens≈4000
temperature=0.1
)
return response.choices[0].message.content
async def _optimize_with_chunks(self, raw_transcript: str, max_tokens: int) -> str:
"""
分块优化长文本
"""
detected_lang = self._detect_transcript_language(raw_transcript)
lang_instruction = self._get_language_instruction(detected_lang)
# 按段落分割原始转录(保留时间戳作为分割参考)
chunks = self._split_into_chunks(raw_transcript, max_tokens)
logger.info(f"分割为 {len(chunks)} 个块进行处理")
optimized_chunks = []
for i, chunk in enumerate(chunks):
logger.info(f"正在优化第 {i+1}/{len(chunks)} 块...")
system_prompt = f"""你是专业的文本编辑专家。请对这段转录文本片段进行简单优化。
这是完整转录的第{i+1}部分,共{len(chunks)}部分。
简单优化要求:
1. **严格保持原始语言({lang_instruction})**,绝对不翻译
2. **仅修正明显的错别字和语法错误**
3. **稍微调整句子流畅度**,但不大幅改写
4. **保持原文结构和长度**,不做复杂的段落重组
5. **保持原意100%不变**
注意:这只是初步清理,不要做复杂的重写或重新组织。"""
user_prompt = f"""简单优化以下{lang_instruction}文本片段(仅修错别字和语法):
{chunk}
输出清理后的文本,保持原文结构。"""
try:
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
max_tokens=1200, # 适应4000 tokens总限制
temperature=0.1
)
optimized_chunk = response.choices[0].message.content
optimized_chunks.append(optimized_chunk)
except Exception as e:
logger.error(f"优化第 {i+1} 块失败: {e}")
# 失败时使用基本清理
cleaned_chunk = self._basic_transcript_cleanup(chunk)
optimized_chunks.append(cleaned_chunk)
# 合并所有优化后的块
merged_text = "\n\n".join(optimized_chunks)
# 对合并后的文本进行二次段落整理
logger.info("正在进行最终段落整理...")
final_result = await self._final_paragraph_organization(merged_text, lang_instruction)
logger.info("分块优化完成")
return final_result
# ===== JS openaiService.js 移植:分块/上下文/去重/格式化 =====
def _ensure_markdown_paragraphs(self, text: str) -> str:
"""确保Markdown段落空行、标题后空行、压缩多余空行。"""
if not text:
return text
formatted = text.replace("\r\n", "\n")
import re
# 标题后加空行
formatted = re.sub(r"(^#{1,6}\s+.*)\n([^\n#])", r"\1\n\n\2", formatted, flags=re.M)
# 压缩≥3个换行为2个
formatted = re.sub(r"\n{3,}", "\n\n", formatted)
# 去首尾空行
formatted = re.sub(r"^\n+", "", formatted)
formatted = re.sub(r"\n+$", "", formatted)
return formatted
async def _format_single_chunk(self, chunk_text: str, transcript_language: str = 'zh') -> str:
"""单块优化(修正+格式化),遵循4000 tokens 限制。"""
# 构建与JS版一致的系统/用户提示
if transcript_language == 'zh':
prompt = (
"请对以下音频转录文本进行智能优化和格式化,要求:\n\n"
"**内容优化(正确性优先):**\n"
"1. 错误修正(转录错误/错别字/同音字/专有名词)\n"
"2. 适度改善语法,补全不完整句子,保持原意和语言不变\n"
"3. 口语处理:保留自然口语与重复表达,不要删减内容,仅添加必要标点\n"
"4. **绝对不要改变人称代词(I/我、you/你等)和说话者视角**\n\n"
"**分段规则:**\n"
"- 按主题和逻辑含义分段,每段包含1-8个相关句子\n"
"- 单段长度不超过400字符\n"
"- 避免过多的短段落,合并相关内容\n\n"
"**格式要求:**Markdown 段落,段落间空行\n\n"
f"原始转录文本:\n{chunk_text}"
)
system_prompt = (
"你是专业的音频转录文本优化助手,修正错误、改善通顺度和排版格式,"
"必须保持原意,不得删减口语/重复/细节;仅移除时间戳或元信息。"
"绝对不要改变人称代词或说话者视角。这可能是访谈对话,访谈者用'you',被访者用'I/we'。"
)
else:
prompt = (
"Please intelligently optimize and format the following audio transcript text:\n\n"
"Content Optimization (Accuracy First):\n"
"1. Error Correction (typos, homophones, proper nouns)\n"
"2. Moderate grammar improvement, complete incomplete sentences, keep original language/meaning\n"
"3. Speech processing: keep natural fillers and repetitions, do NOT remove content; only add punctuation if needed\n"
"4. **NEVER change pronouns (I, you, he, she, etc.) or speaker perspective**\n\n"
"Segmentation Rules: Group 1-8 related sentences per paragraph by topic/logic; paragraph length NOT exceed 400 characters; avoid too many short paragraphs\n\n"
"Format: Markdown paragraphs with blank lines between paragraphs\n\n"
f"Original transcript text:\n{chunk_text}"
)
system_prompt = (
"You are a professional transcript formatting assistant. Fix errors and improve fluency "
"without changing meaning or removing any content; only timestamps/meta may be removed; keep Markdown paragraphs with blank lines. "
"NEVER change pronouns or speaker perspective. This may be an interview: interviewer uses 'you', interviewee uses 'I/we'."
)
try:
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}
],
max_tokens=4000, # 对齐JS:优化/格式化阶段最大tokens≈4000
temperature=0.1
)
optimized_text = response.choices[0].message.content or ""
# 移除诸如 "# Transcript" / "## Transcript" 等标题
optimized_text = self._remove_transcript_heading(optimized_text)
enforced = self._enforce_paragraph_max_chars(optimized_text.strip(), max_chars=400)
return self._ensure_markdown_paragraphs(enforced)
except Exception as e:
logger.error(f"单块文本优化失败: {e}")
return self._apply_basic_formatting(chunk_text)
def _smart_split_long_chunk(self, text: str, max_chars_per_chunk: int) -> list:
"""在句子/空格边界处安全切分超长文本。"""
chunks = []
pos = 0
while pos < len(text):
end = min(pos + max_chars_per_chunk, len(text))
if end < len(text):
# 优先句子边界
sentence_endings = ['。', '!', '?', '.', '!', '?']
best = -1
for ch in sentence_endings:
idx = text.rfind(ch, pos, end)
if idx > best:
best = idx
if best > pos + int(max_chars_per_chunk * 0.7):
end = best + 1
else:
# 次选:空格边界
space_idx = text.rfind(' ', pos, end)
if space_idx > pos + int(max_chars_per_chunk * 0.8):
end = space_idx
chunks.append(text[pos:end].strip())
pos = end
return [c for c in chunks if c]
def _find_safe_cut_point(self, text: str) -> int:
"""找到安全的切割点(段落>句子>短语)。"""
import re
# 段落
p = text.rfind("\n\n")
if p > 0:
return p + 2
# 句子
last_sentence_end = -1
for m in re.finditer(r"[。!?\.!?]\s*", text):
last_sentence_end = m.end()
if last_sentence_end > 20:
return last_sentence_end
# 短语
last_phrase_end = -1
for m in re.finditer(r"[,;,;]\s*", text):
last_phrase_end = m.end()
if last_phrase_end > 20:
return last_phrase_end
return len(text)
def _find_overlap_between_texts(self, text1: str, text2: str) -> str:
"""检测相邻两段的重叠内容,用于去重。"""
max_len = min(len(text1), len(text2))
# 逐步从长到短尝试
for length in range(max_len, 19, -1):
suffix = text1[-length:]
prefix = text2[:length]
if suffix == prefix:
cut = self._find_safe_cut_point(prefix)
if cut > 20:
return prefix[:cut]
return suffix
return ""
def _apply_basic_formatting(self, text: str) -> str:
"""当AI失败时的回退:按句子拼段,段落≤250字符,双换行分隔。"""
if not text or not text.strip():
return text
import re
parts = re.split(r"([。!?\.!?]+\s*)", text)
sentences = []
current = ""
for i, part in enumerate(parts):
if i % 2 == 0:
current += part
else:
current += part
if current.strip():
sentences.append(current.strip())
current = ""
if current.strip():
sentences.append(current.strip())
paras = []
cur = ""
sentence_count = 0
for s in sentences:
candidate = (cur + " " + s).strip() if cur else s
sentence_count += 1
# 改进的分段逻辑:考虑句子数量和长度
should_break = False
if len(candidate) > 400 and cur: # 段落过长
should_break = True
elif len(candidate) > 200 and sentence_count >= 3: # 中等长度且句子数足够
should_break = True
elif sentence_count >= 6: # 句子数过多
should_break = True
if should_break:
paras.append(cur.strip())
cur = s
sentence_count = 1
else:
cur = candidate
if cur.strip():
paras.append(cur.strip())
return self._ensure_markdown_paragraphs("\n\n".join(paras))
async def _format_long_transcript_in_chunks(self, raw_transcript: str, transcript_language: str, max_chars_per_chunk: int) -> str:
"""智能分块+上下文+去重 合成优化文本(JS策略移植)。"""
import re
# 先按句子切分,组装不超过max_chars_per_chunk的块
parts = re.split(r"([。!?\.!?]+\s*)", raw_transcript)
sentences = []
buf = ""
for i, part in enumerate(parts):
if i % 2 == 0:
buf += part
else:
buf += part
if buf.strip():
sentences.append(buf.strip())
buf = ""
if buf.strip():
sentences.append(buf.strip())
chunks = []
cur = ""
for s in sentences:
candidate = (cur + " " + s).strip() if cur else s
if len(candidate) > max_chars_per_chunk and cur:
chunks.append(cur.strip())
cur = s
else:
cur = candidate
if cur.strip():
chunks.append(cur.strip())
# 对仍然过长的块二次安全切分
final_chunks = []
for c in chunks:
if len(c) <= max_chars_per_chunk:
final_chunks.append(c)
else:
final_chunks.extend(self._smart_split_long_chunk(c, max_chars_per_chunk))
logger.info(f"文本分为 {len(final_chunks)} 块处理")
optimized = []
for i, c in enumerate(final_chunks):
chunk_with_context = c
if i > 0:
prev_tail = final_chunks[i - 1][-100:]
marker = f"[上文续:{prev_tail}]" if transcript_language == 'zh' else f"[Context continued: {prev_tail}]"
chunk_with_context = marker + "\n\n" + c
try:
oc = await self._format_single_chunk(chunk_with_context, transcript_language)
# 移除上下文标记
oc = re.sub(r"^\[(上文续|Context continued):?:?.*?\]\s*", "", oc, flags=re.S)
optimized.append(oc)
except Exception as e:
logger.warning(f"第 {i+1} 块优化失败,使用基础格式化: {e}")
optimized.append(self._apply_basic_formatting(c))
# 邻接块去重
deduped = []
for i, c in enumerate(optimized):
cur_txt = c
if i > 0 and deduped:
prev = deduped[-1]
overlap = self._find_overlap_between_texts(prev[-200:], cur_txt[:200])
if overlap:
cur_txt = cur_txt[len(overlap):].lstrip()
if not cur_txt:
continue
if cur_txt.strip():
deduped.append(cur_txt)
merged = "\n\n".join(deduped)
merged = self._remove_transcript_heading(merged)
enforced = self._enforce_paragraph_max_chars(merged, max_chars=400)
return self._ensure_markdown_paragraphs(enforced)
def _remove_timestamps_and_meta(self, text: str) -> str:
"""仅移除时间戳行与明显元信息(标题、检测语言等),保留原文口语/重复。"""
lines = text.split('\n')
kept = []
for line in lines:
s = line.strip()
# 跳过时间戳与元信息
if (s.startswith('**[') and s.endswith(']**')):
continue
if s.startswith('# '):
# 跳过顶级标题(通常是视频标题,可在最终加回)
continue
if s.startswith('**检测语言:**') or s.startswith('**语言概率:**'):
continue
kept.append(line)
# 规范空行
cleaned = '\n'.join(kept)
return cleaned
def _enforce_paragraph_max_chars(self, text: str, max_chars: int = 400) -> str:
"""按段落拆分并确保每段不超过max_chars,必要时按句子边界拆为多段。"""
if not text:
return text
import re
paragraphs = [p for p in re.split(r"\n\s*\n", text) if p is not None]
new_paragraphs = []
for para in paragraphs:
para = para.strip()
if len(para) <= max_chars:
new_paragraphs.append(para)
continue
# 句子切分
parts = re.split(r"([。!?\.!?]+\s*)", para)
sentences = []
buf = ""
for i, part in enumerate(parts):
if i % 2 == 0:
buf += part
else:
buf += part
if buf.strip():
sentences.append(buf.strip())
buf = ""
if buf.strip():
sentences.append(buf.strip())
cur = ""
for s in sentences:
candidate = (cur + (" " if cur else "") + s).strip()
if len(candidate) > max_chars and cur:
new_paragraphs.append(cur)
cur = s
else:
cur = candidate
if cur:
new_paragraphs.append(cur)
return "\n\n".join([p.strip() for p in new_paragraphs if p is not None])
def _remove_transcript_heading(self, text: str) -> str:
"""移除开头或段落中的以 Transcript 为标题的行(任意级别#),不改变正文。"""
if not text:
return text
import re
# 移除形如 '## Transcript'、'# Transcript Text'、'### transcript' 的标题行
lines = text.split('\n')
filtered = []
for line in lines:
stripped = line.strip()
if re.match(r"^#{1,6}\s*transcript(\s+text)?\s*$", stripped, flags=re.I):
continue
filtered.append(line)
return '\n'.join(filtered)
def _split_into_chunks(self, text: str, max_tokens: int) -> list:
"""
将原始转录文本智能分割成合适大小的块
策略:先提取纯文本,按句子和段落自然分割
"""
import re
# 1. 先提取纯文本内容(移除时间戳、标题等)
pure_text = self._extract_pure_text(text)
# 2. 按句子分割,保持句子完整性
sentences = self._split_into_sentences(pure_text)
# 3. 按token限制组装成块
chunks = []
current_chunk = []
current_tokens = 0
for sentence in sentences:
sentence_tokens = self._estimate_tokens(sentence)
# 检查是否能加入当前块
if current_tokens + sentence_tokens > max_tokens and current_chunk:
# 当前块已满,保存并开始新块
chunks.append(self._join_sentences(current_chunk))
current_chunk = [sentence]
current_tokens = sentence_tokens
else:
# 添加到当前块
current_chunk.append(sentence)
current_tokens += sentence_tokens
# 添加最后一块
if current_chunk:
chunks.append(self._join_sentences(current_chunk))
return chunks
def _extract_pure_text(self, raw_transcript: str) -> str:
"""
从原始转录中提取纯文本,移除时间戳和元数据
"""
lines = raw_transcript.split('\n')
text_lines = []
for line in lines:
line = line.strip()
# 跳过时间戳、标题、元数据
if (line.startswith('**[') and line.endswith(']**') or
line.startswith('#') or
line.startswith('**检测语言:**') or
line.startswith('**语言概率:**') or
not line):
continue
text_lines.append(line)
return ' '.join(text_lines)
def _split_into_sentences(self, text: str) -> list:
"""
按句子分割文本,考虑中英文差异
"""
import re
# 中英文句子结束符
sentence_endings = r'[.!?。!?;;]+'
# 分割句子,保留句号
parts = re.split(f'({sentence_endings})', text)
sentences = []
current = ""
for i, part in enumerate(parts):
if re.match(sentence_endings, part):
# 这是句子结束符,加到当前句子
current += part
if current.strip():
sentences.append(current.strip())
current = ""
else:
# 这是句子内容
current += part
# 处理最后没有句号的部分
if current.strip():
sentences.append(current.strip())
return [s for s in sentences if s.strip()]
def _join_sentences(self, sentences: list) -> str:
"""
重新组合句子为段落
"""
return ' '.join(sentences)
def _basic_transcript_cleanup(self, raw_transcript: str) -> str:
"""
基本的转录文本清理:移除时间戳和标题信息
当GPT优化失败时的后备方案
"""
lines = raw_transcript.split('\n')
cleaned_lines = []
for line in lines:
# 跳过时间戳行
if line.strip().startswith('**[') and line.strip().endswith(']**'):
continue
# 跳过标题行
if line.strip().startswith('# ') or line.strip().startswith('## '):
continue
# 跳过检测语言等元信息行
if line.strip().startswith('**检测语言:**') or line.strip().startswith('**语言概率:**'):
continue
# 保留非空文本行
if line.strip():
cleaned_lines.append(line.strip())
# 将句子重新组合并智能分段
text = ' '.join(cleaned_lines)
# 更智能的分句处理,考虑中英文差异
import re
# 按句号、问号、感叹号分句
sentences = re.split(r'[.!?。!?]', text)
sentences = [s.strip() for s in sentences if s.strip()]
paragraphs = []
current_paragraph = []
for i, sentence in enumerate(sentences):
if sentence:
current_paragraph.append(sentence)
# 智能分段条件:
# 1. 每3个句子一段(基本规则)
# 2. 遇到话题转换词汇时强制分段
# 3. 避免超长段落
topic_change_keywords = [
'首先', '其次', '然后', '接下来', '另外', '此外', '最后', '总之',
'first', 'second', 'third', 'next', 'also', 'however', 'finally',
'现在', '那么', '所以', '因此', '但是', '然而',
'now', 'so', 'therefore', 'but', 'however'
]
should_break = False
# 检查是否需要分段
if len(current_paragraph) >= 3: # 基本长度条件
should_break = True
elif len(current_paragraph) >= 2: # 较短但遇到话题转换
for keyword in topic_change_keywords:
if sentence.lower().startswith(keyword.lower()):
should_break = True
break
if should_break or len(current_paragraph) >= 4: # 最大长度限制
# 组合当前段落
paragraph_text = '. '.join(current_paragraph)
if not paragraph_text.endswith('.'):
paragraph_text += '.'
paragraphs.append(paragraph_text)
current_paragraph = []
# 添加剩余的句子
if current_paragraph:
paragraph_text = '. '.join(current_paragraph)
if not paragraph_text.endswith('.'):
paragraph_text += '.'
paragraphs.append(paragraph_text)
return '\n\n'.join(paragraphs)
async def _final_paragraph_organization(self, text: str, lang_instruction: str) -> str:
"""
对合并后的文本进行最终的段落整理
使用改进的prompt和工程验证
"""
try:
# 估算文本长度,如果太长则分块处理
estimated_tokens = self._estimate_tokens(text)
if estimated_tokens > 3000: # 对于很长的文本,分块处理
return await self._organize_long_text_paragraphs(text, lang_instruction)
system_prompt = f"""你是专业的{lang_instruction}文本段落整理专家。你的任务是按照语义和逻辑重新组织段落。
🎯 **核心原则**:
1. **严格保持原始语言({lang_instruction})**,绝不翻译
2. **保持所有内容完整**,不删除不添加任何信息
3. **按语义逻辑分段**:每段围绕一个完整的思想或话题
4. **严格控制段落长度**:每段绝不超过250词
5. **保持自然流畅**:段落间应有逻辑连接
📏 **分段标准**:
- **语义完整性**:每段讲述一个完整概念或事件
- **适中长度**:3-7个句子,每段绝不超过250词
- **逻辑边界**:在话题转换、时间转换、观点转换处分段
- **自然断点**:遵循说话者的自然停顿和逻辑
⚠️ **严禁**:
- 创造超过250词的巨型段落
- 强行合并不相关的内容
- 打断完整的故事或论述
输出格式:段落间用空行分隔。"""
user_prompt = f"""请重新整理以下{lang_instruction}文本的段落结构。严格按照语义和逻辑进行分段,确保每段不超过200词:
{text}
重新分段后的文本:"""
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
max_tokens=4000, # 对齐JS:段落整理阶段最大tokens≈4000
temperature=0.05 # 降低温度,提高一致性
)
organized_text = response.choices[0].message.content
# 工程验证:检查段落长度
validated_text = self._validate_paragraph_lengths(organized_text)
return validated_text
except Exception as e:
logger.error(f"最终段落整理失败: {e}")
# 失败时使用基础分段处理
return self._basic_paragraph_fallback(text)
async def _organize_long_text_paragraphs(self, text: str, lang_instruction: str) -> str:
"""
对于很长的文本,分块进行段落整理
"""
try:
# 按现有段落分割
paragraphs = [p.strip() for p in text.split('\n\n') if p.strip()]
organized_chunks = []
current_chunk = []
current_tokens = 0
max_chunk_tokens = 2500 # 适应4000 tokens限制的chunk大小
for para in paragraphs:
para_tokens = self._estimate_tokens(para)
if current_tokens + para_tokens > max_chunk_tokens and current_chunk:
# 处理当前chunk
chunk_text = '\n\n'.join(current_chunk)
organized_chunk = await self._organize_single_chunk(chunk_text, lang_instruction)
organized_chunks.append(organized_chunk)
current_chunk = [para]
current_tokens = para_tokens
else:
current_chunk.append(para)
current_tokens += para_tokens
# 处理最后一个chunk
if current_chunk:
chunk_text = '\n\n'.join(current_chunk)
organized_chunk = await self._organize_single_chunk(chunk_text, lang_instruction)
organized_chunks.append(organized_chunk)
return '\n\n'.join(organized_chunks)
except Exception as e:
logger.error(f"长文本段落整理失败: {e}")
return self._basic_paragraph_fallback(text)
async def _organize_single_chunk(self, text: str, lang_instruction: str) -> str:
"""
整理单个文本块的段落
"""
system_prompt = f"""You are a {lang_instruction} paragraph organization expert. Reorganize paragraphs by semantics, ensuring each paragraph does not exceed 200 words.
Core requirements:
1. Strictly maintain the original {lang_instruction} language
2. Organize by semantic logic, one theme per paragraph
3. Each paragraph must not exceed 250 words
4. Separate paragraphs with blank lines
5. Keep content complete, do not reduce information"""
user_prompt = f"""Re-paragraph the following text in {lang_instruction}, ensuring each paragraph does not exceed 200 words:
{text}"""
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
max_tokens=1200, # 适应4000 tokens总限制
temperature=0.05
)
return response.choices[0].message.content
def _validate_paragraph_lengths(self, text: str) -> str:
"""
验证段落长度,如果有超长段落则尝试分割
"""
paragraphs = [p.strip() for p in text.split('\n\n') if p.strip()]
validated_paragraphs = []
for para in paragraphs:
word_count = len(para.split())
if word_count > 300: # 如果段落超过300词
logger.warning(f"检测到超长段落({word_count}词),尝试分割")
# 尝试按句子分割长段落
split_paras = self._split_long_paragraph(para)
validated_paragraphs.extend(split_paras)
else:
validated_paragraphs.append(para)
return '\n\n'.join(validated_paragraphs)
def _split_long_paragraph(self, paragraph: str) -> list:
"""
分割过长的段落
"""
import re
# 按句子分割
sentences = re.split(r'[.!?。!?]\s+', paragraph)
sentences = [s.strip() + '.' for s in sentences if s.strip()]
split_paragraphs = []
current_para = []
current_words = 0
for sentence in sentences:
sentence_words = len(sentence.split())
if current_words + sentence_words > 200 and current_para:
# 当前段落达到长度限制
split_paragraphs.append(' '.join(current_para))
current_para = [sentence]
current_words = sentence_words
else:
current_para.append(sentence)
current_words += sentence_words
# 添加最后一段
if current_para:
split_paragraphs.append(' '.join(current_para))
return split_paragraphs
def _basic_paragraph_fallback(self, text: str) -> str:
"""
基础分段fallback机制
当GPT整理失败时,使用简单的规则分段
"""
import re
# 移除多余的空行
text = re.sub(r'\n\s*\n\s*\n+', '\n\n', text)
paragraphs = [p.strip() for p in text.split('\n\n') if p.strip()]
basic_paragraphs = []
for para in paragraphs:
word_count = len(para.split())
if word_count > 250:
# 长段落按句子分割
split_paras = self._split_long_paragraph(para)
basic_paragraphs.extend(split_paras)
elif word_count < 30 and basic_paragraphs:
# 短段落与上一段合并(如果合并后不超过200词)
last_para = basic_paragraphs[-1]
combined_words = len(last_para.split()) + word_count
if combined_words <= 200:
basic_paragraphs[-1] = last_para + ' ' + para
else:
basic_paragraphs.append(para)
else:
basic_paragraphs.append(para)
return '\n\n'.join(basic_paragraphs)
async def summarize(self, transcript: str, target_language: str = "zh", video_title: str = None) -> str:
"""
生成视频转录的摘要
Args:
transcript: 转录文本
target_language: 目标语言代码
Returns:
摘要文本(Markdown格式)
"""
try:
if not self.client:
logger.warning("OpenAI API不可用,生成备用摘要")
return self._generate_fallback_summary(transcript, target_language, video_title)
# 估算转录文本长度,决定是否需要分块摘要
estimated_tokens = self._estimate_tokens(transcript)
max_summarize_tokens = 4000 # 提高限制,优先使用单文本处理以获得更好的总结质量
if estimated_tokens <= max_summarize_tokens:
# 短文本直接摘要
return await self._summarize_single_text(transcript, target_language, video_title)
else:
# 长文本分块摘要
logger.info(f"文本较长({estimated_tokens} tokens),启用分块摘要")
return await self._summarize_with_chunks(transcript, target_language, video_title, max_summarize_tokens)
except Exception as e:
logger.error(f"生成摘要失败: {str(e)}")
return self._generate_fallback_summary(transcript, target_language, video_title)
async def _summarize_single_text(self, transcript: str, target_language: str, video_title: str = None) -> str:
"""
对单个文本进行摘要
"""
# 获取目标语言名称
language_name = self.language_map.get(target_language, "中文(简体)")
# 构建英文提示词,适用于所有目标语言
system_prompt = f"""You are a professional content analyst. Please generate a comprehensive, well-structured summary in {language_name} for the following text.
Summary Requirements:
1. Extract the main topics and core viewpoints from the text
2. Maintain clear logical structure, highlighting the core arguments
3. Include important discussions, viewpoints, and conclusions
4. Use concise and clear language
5. Appropriately preserve the speaker's expression style and key opinions
Paragraph Organization Requirements (Core):
1. **Organize by semantic and logical themes** - Start a new paragraph whenever the topic shifts, discussion focus changes, or when transitioning from one viewpoint to another
2. **Each paragraph should focus on one main point or theme**
3. **Paragraphs must be separated by blank lines (double line breaks \\n\\n)**
4. **Consider the logical flow of content and reasonably divide paragraph boundaries**
Format Requirements:
1. Use Markdown format with double line breaks between paragraphs
2. Each paragraph should be a complete logical unit
3. Write entirely in {language_name}
4. Aim for substantial content (600-1200 words when appropriate)"""
user_prompt = f"""Based on the following content, write a comprehensive, well-structured summary in {language_name}:
{transcript}
Requirements:
- Focus on natural paragraphs, avoiding decorative headings
- Cover all key ideas and arguments, preserving important examples and data
- Ensure balanced coverage of both early and later content
- Use restrained but comprehensive language
- Organize content logically with proper paragraph breaks"""
logger.info(f"正在生成{language_name}摘要...")
# 调用OpenAI API
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
max_tokens=3500, # 控制在安全范围内,避免超出模型限制
temperature=0.3
)
summary = response.choices[0].message.content
return self._format_summary_with_meta(summary, target_language, video_title)
async def _summarize_with_chunks(self, transcript: str, target_language: str, video_title: str, max_tokens: int) -> str:
"""
分块摘要长文本
"""
language_name = self.language_map.get(target_language, "中文(简体)")
# 使用JS策略:按字符进行智能分块(段落>句子)
chunks = self._smart_chunk_text(transcript, max_chars_per_chunk=4000)
logger.info(f"分割为 {len(chunks)} 个块进行摘要")
chunk_summaries = []
# 每块生成局部摘要
for i, chunk in enumerate(chunks):
logger.info(f"正在摘要第 {i+1}/{len(chunks)} 块...")
system_prompt = f"""You are a summarization expert. Please write a high-density summary for this text chunk in {language_name}.
This is part {i+1} of {len(chunks)} of the complete content (Part {i+1}/{len(chunks)}).
Output preferences: Focus on natural paragraphs, use minimal bullet points if necessary; highlight new information and its relationship to the main narrative; avoid vague repetition and formatted headings; moderate length (suggested 120-220 words)."""
user_prompt = f"""[Part {i+1}/{len(chunks)}] Summarize the key points of the following text in {language_name} (natural paragraphs preferred, minimal bullet points, 120-220 words):
{chunk}
Avoid using any subheadings or decorative separators, output content only."""
try:
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
max_tokens=1000, # 提升分块摘要容量以涵盖更多细节
temperature=0.3
)
chunk_summary = response.choices[0].message.content
chunk_summaries.append(chunk_summary)
except Exception as e:
logger.error(f"摘要第 {i+1} 块失败: {e}")
# 失败时生成简单摘要
simple_summary = f"第{i+1}部分内容概述:" + chunk[:200] + "..."
chunk_summaries.append(simple_summary)
# 合并所有局部摘要(带编号),如分块较多则分层整合(不引入小标题)
combined_summaries = "\n\n".join([f"[Part {idx+1}]\n" + s for idx, s in enumerate(chunk_summaries)])
logger.info("正在整合最终摘要...")
if len(chunk_summaries) > 10:
final_summary = await self._integrate_hierarchical_summaries(chunk_summaries, target_language)
else:
final_summary = await self._integrate_chunk_summaries(combined_summaries, target_language)
return self._format_summary_with_meta(final_summary, target_language, video_title)
def _smart_chunk_text(self, text: str, max_chars_per_chunk: int = 3500) -> list:
"""智能分块(先段落后句子),按字符上限切分。"""
chunks = []
paragraphs = [p for p in text.split('\n\n') if p.strip()]
cur = ""
for p in paragraphs:
candidate = (cur + "\n\n" + p).strip() if cur else p
if len(candidate) > max_chars_per_chunk and cur:
chunks.append(cur.strip())
cur = p
else:
cur = candidate
if cur.strip():
chunks.append(cur.strip())
# 二次按句子切分过长块
import re
final_chunks = []
for c in chunks:
if len(c) <= max_chars_per_chunk:
final_chunks.append(c)
else:
sentences = [s.strip() for s in re.split(r"[。!?\.!?]+", c) if s.strip()]
scur = ""
for s in sentences:
candidate = (scur + '。' + s).strip() if scur else s
if len(candidate) > max_chars_per_chunk and scur:
final_chunks.append(scur.strip())
scur = s
else:
scur = candidate
if scur.strip():
final_chunks.append(scur.strip())
return final_chunks
async def _integrate_chunk_summaries(self, combined_summaries: str, target_language: str) -> str:
"""
整合分块摘要为最终连贯摘要
"""
language_name = self.language_map.get(target_language, "中文(简体)")
try:
system_prompt = f"""You are a content integration expert. Please integrate multiple segmented summaries into a complete, coherent summary in {language_name}.
Integration Requirements:
1. Remove duplicate content and maintain clear logic
2. Reorganize content by themes or chronological order
3. Each paragraph must be separated by double line breaks
4. Ensure output is in Markdown format with double line breaks between paragraphs
5. Use concise and clear language
6. Form a complete content summary
7. Cover all parts comprehensively without omission"""
user_prompt = f"""Please integrate the following segmented summaries into a complete, coherent summary in {language_name}:
{combined_summaries}
Requirements:
- Remove duplicate content and maintain clear logic
- Reorganize content by themes or chronological order
- Each paragraph must be separated by double line breaks
- Ensure output is in Markdown format with double line breaks between paragraphs
- Use concise and clear language
- Form a complete content summary"""
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
max_tokens=2500, # 控制输出规模,兼顾上下文安全
temperature=0.3
)
return response.choices[0].message.content
except Exception as e:
logger.error(f"整合摘要失败: {e}")
# 失败时直接合并
return combined_summaries
def _format_summary_with_meta(self, summary: str, target_language: str, video_title: str = None) -> str:
"""
为摘要添加标题和元信息
"""
language_name = self.language_map.get(target_language, "中文(简体)")
meta_labels = self._get_summary_labels(target_language)
# 不加任何小标题/免责声明,可保留视频标题作为一级标题
if video_title:
prefix = f"# {video_title}\n\n"
else:
prefix = ""
return prefix + summary
try:
resp = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
max_tokens=1200,
temperature=0.2,
)
return resp.choices[0].message.content
except Exception:
return text
def _generate_fallback_summary(self, transcript: str, target_language: str, video_title: str = None) -> str:
"""
生成备用摘要(当OpenAI API不可用时)
Args:
transcript: 转录文本
video_title: 视频标题
target_language: 目标语言代码
Returns:
备用摘要文本
"""
language_name = self.language_map.get(target_language, "中文(简体)")
# 简单的文本处理,提取关键信息
lines = transcript.split('\n')
content_lines = [line for line in lines if line.strip() and not line.startswith('#') and not line.startswith('**')]
# 计算大概的长度
total_chars = sum(len(line) for line in content_lines)
# 使用目标语言的标签
meta_labels = self._get_summary_labels(target_language)
fallback_labels = self._get_fallback_labels(target_language)
# 直接使用视频标题作为主标题
title = video_title if video_title else "Summary"
summary = f"""# {title}
**{meta_labels['language_label']}:** {language_name}
**{fallback_labels['notice']}:** {fallback_labels['api_unavailable']}
## {fallback_labels['overview_title']}
**{fallback_labels['content_length']}:** {fallback_labels['about']} {total_chars} {fallback_labels['characters']}
**{fallback_labels['paragraph_count']}:** {len(content_lines)} {fallback_labels['paragraphs']}
## {fallback_labels['main_content']}
{fallback_labels['content_description']}
{fallback_labels['suggestions_intro']}
1. {fallback_labels['suggestion_1']}
2. {fallback_labels['suggestion_2']}
3. {fallback_labels['suggestion_3']}
## {fallback_labels['recommendations']}
- {fallback_labels['recommendation_1']}
- {fallback_labels['recommendation_2']}
<br/>
<p style="color: #888; font-style: italic; text-align: center; margin-top: 16px;"><em>{fallback_labels['fallback_disclaimer']}</em></p>"""
return summary
def _get_current_time(self) -> str:
"""获取当前时间字符串"""
from datetime import datetime
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def get_supported_languages(self) -> dict:
"""
获取支持的语言列表
Returns:
语言代码到语言名称的映射
"""
return self.language_map.copy()
def _detect_transcript_language(self, transcript: str) -> str:
"""
检测转录文本的主要语言
Args:
transcript: 转录文本
Returns:
检测到的语言代码
"""
# 简单的语言检测逻辑:查找转录文本中的语言标记
if "**检测语言:**" in transcript:
# 从Whisper转录中提取检测到的语言
lines = transcript.split('\n')
for line in lines:
if "**检测语言:**" in line:
# 提取语言代码,例如: "**检测语言:** en"
lang = line.split(":")[-1].strip()
return lang
# 如果没有找到语言标记,使用简单的字符检测
# 计算英文字符、中文字符等的比例
total_chars = len(transcript)
if total_chars == 0:
return "en" # 默认英文
# 统计中文字符
chinese_chars = sum(1 for char in transcript if '\u4e00' <= char <= '\u9fff')
chinese_ratio = chinese_chars / total_chars
# 统计英文字母
english_chars = sum(1 for char in transcript if char.isascii() and char.isalpha())
english_ratio = english_chars / total_chars
# 根据比例判断
if chinese_ratio > 0.3:
return "zh"
elif english_ratio > 0.3:
return "en"
else:
return "en" # 默认英文
def _get_language_instruction(self, lang_code: str) -> str:
"""
根据语言代码获取优化指令中使用的语言名称
Args:
lang_code: 语言代码
Returns:
语言名称
"""
language_instructions = {
"en": "English",
"zh": "中文",
"ja": "日本語",
"ko": "한국어",
"es": "Español",
"fr": "Français",
"de": "Deutsch",
"it": "Italiano",
"pt": "Português",
"ru": "Русский",
"ar": "العربية"
}
return language_instructions.get(lang_code, "English")
def _get_summary_labels(self, lang_code: str) -> dict:
"""
获取摘要页面的多语言标签
Args:
lang_code: 语言代码
Returns:
标签字典
"""
labels = {
"en": {
"language_label": "Summary Language",
"disclaimer": "This summary is automatically generated by AI for reference only"
},
"zh": {
"language_label": "摘要语言",
"disclaimer": "本摘要由AI自动生成,仅供参考"
},
"ja": {
"language_label": "要約言語",
"disclaimer": "この要約はAIによって自動生成されており、参考用です"
},
"ko": {
"language_label": "요약 언어",
"disclaimer": "이 요약은 AI에 의해 자동 생성되었으며 참고용입니다"
},
"es": {
"language_label": "Idioma del Resumen",
"disclaimer": "Este resumen es generado automáticamente por IA, solo para referencia"
},
"fr": {
"language_label": "Langue du Résumé",
"disclaimer": "Ce résumé est généré automatiquement par IA, à titre de référence uniquement"
},
"de": {
"language_label": "Zusammenfassungssprache",
"disclaimer": "Diese Zusammenfassung wird automatisch von KI generiert, nur zur Referenz"
},
"it": {
"language_label": "Lingua del Riassunto",
"disclaimer": "Questo riassunto è generato automaticamente dall'IA, solo per riferimento"
},
"pt": {
"language_label": "Idioma do Resumo",
"disclaimer": "Este resumo é gerado automaticamente por IA, apenas para referência"
},
"ru": {
"language_label": "Язык резюме",
"disclaimer": "Это резюме автоматически генерируется ИИ, только для справки"
},
"ar": {
"language_label": "لغة الملخص",
"disclaimer": "هذا الملخص تم إنشاؤه تلقائياً بواسطة الذكاء الاصطناعي، للمرجع فقط"
}
}
return labels.get(lang_code, labels["en"])
def _get_fallback_labels(self, lang_code: str) -> dict:
"""
获取备用摘要的多语言标签
Args:
lang_code: 语言代码
Returns:
标签字典
"""
labels = {
"en": {
"notice": "Notice",
"api_unavailable": "OpenAI API is unavailable, this is a simplified summary",
"overview_title": "Transcript Overview",
"content_length": "Content Length",
"about": "About",
"characters": "characters",
"paragraph_count": "Paragraph Count",
"paragraphs": "paragraphs",
"main_content": "Main Content",
"content_description": "The transcript contains complete video speech content. Since AI summary cannot be generated currently, we recommend:",
"suggestions_intro": "For detailed information, we suggest you:",
"suggestion_1": "Review the complete transcript text for detailed information",
"suggestion_2": "Focus on important paragraphs marked with timestamps",
"suggestion_3": "Manually extract key points and takeaways",
"recommendations": "Recommendations",
"recommendation_1": "Configure OpenAI API key for better summary functionality",
"recommendation_2": "Or use other AI services for text summarization",
"fallback_disclaimer": "This is an automatically generated fallback summary"
},
"zh": {
"notice": "注意",
"api_unavailable": "由于OpenAI API不可用,这是一个简化的摘要",
"overview_title": "转录概览",
"content_length": "内容长度",
"about": "约",
"characters": "字符",
"paragraph_count": "段落数量",
"paragraphs": "段",
"main_content": "主要内容",
"content_description": "转录文本包含了完整的视频语音内容。由于当前无法生成智能摘要,建议您:",
"suggestions_intro": "为获取详细信息,建议您:",
"suggestion_1": "查看完整的转录文本以获取详细信息",
"suggestion_2": "关注时间戳标记的重要段落",
"suggestion_3": "手动提取关键观点和要点",
"recommendations": "建议",
"recommendation_1": "配置OpenAI API密钥以获得更好的摘要功能",
"recommendation_2": "或者使用其他AI服务进行文本总结",
"fallback_disclaimer": "本摘要为自动生成的备用版本"
}
}
return labels.get(lang_code, labels["en"])
def is_available(self) -> bool:
"""
检查摘要服务是否可用
Returns:
True if OpenAI API is configured, False otherwise
"""
return self.client is not None
配置DeepSeek
cd AI-Video-Transcriber
# 使用Docker Compose(最简单) 配置 DeepSeek
cp .env.example .env
# 编辑.env文件,设置你的OPENAI_API_KEY
比如
OPENAI_API_KEY=sk-xxxx
OPENAI_BASE_URL=https://api.deepseek.com/v1
Docker启动
docker-compose up -d
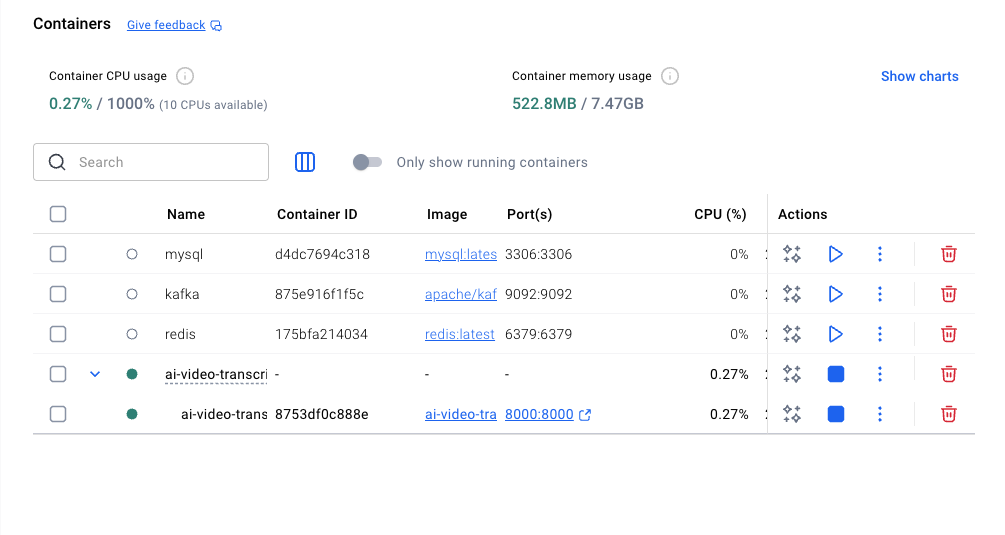
访问页面
测试
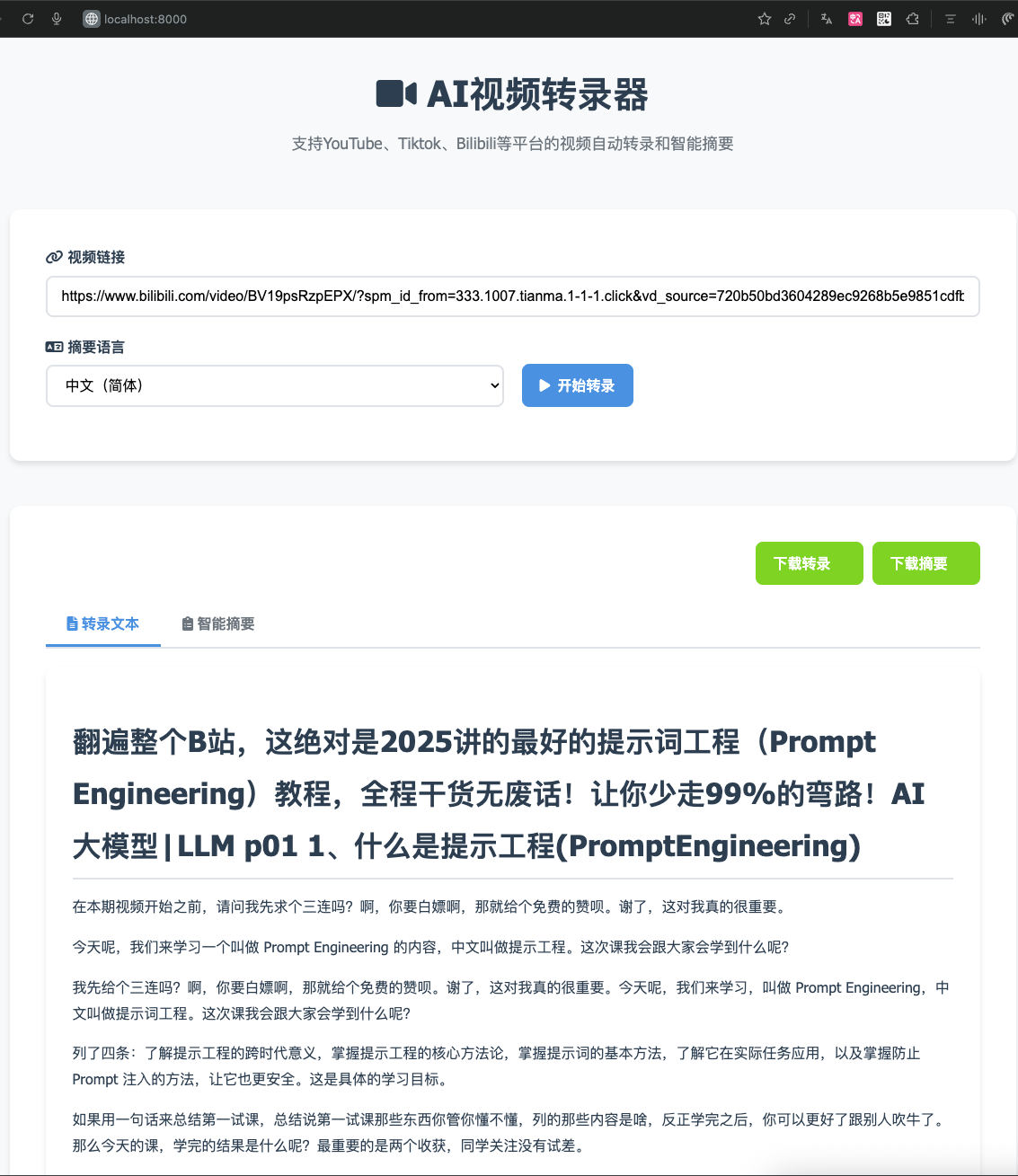
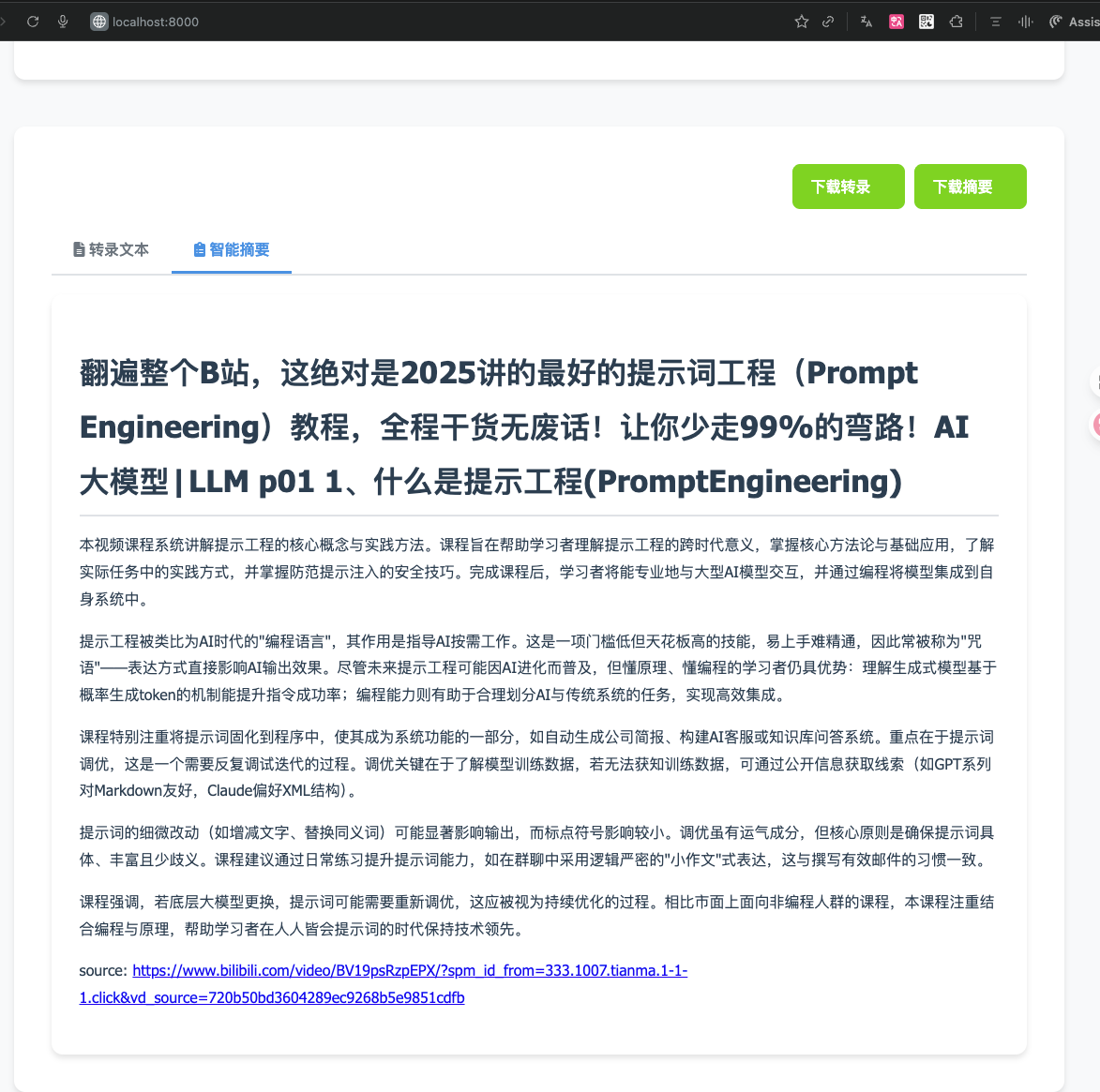
日志信息
2025-11-01 19:40:04.030 | INFO:summarizer:OpenAI客户端已初始化,使用自定义端点: https://api.deepseek.com/v1
2025-11-01 19:40:04.033 | INFO:translator:OpenAI客户端初始化成功
2025-11-01 19:40:04.035 | INFO: Started server process [17]
2025-11-01 19:40:04.035 | INFO: Waiting for application startup.
2025-11-01 19:40:04.035 | INFO: Application startup complete.
2025-11-01 19:40:04.036 | INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
2025-11-01 19:40:08.168 | INFO: 127.0.0.1:57180 - "GET / HTTP/1.1" 200 OK
2025-11-01 19:40:27.544 | INFO: 192.168.65.1:41496 - "GET / HTTP/1.1" 200 OK
2025-11-01 19:40:27.580 | INFO: 192.168.65.1:41496 - "GET /static/app.js?v=20250829 HTTP/1.1" 304 Not Modified
2025-11-01 19:40:32.904 | INFO:main:广播任务更新: 2c6e6d7b-e7f7-4502-9659-96c392e931ff, 状态: processing, 连接数: 0
2025-11-01 19:40:32.904 | INFO: 192.168.65.1:45309 - "POST /api/process-video HTTP/1.1" 200 OK
2025-11-01 19:40:32.910 | INFO: 192.168.65.1:45309 - "GET /api/task-stream/2c6e6d7b-e7f7-4502-9659-96c392e931ff HTTP/1.1" 200 OK
2025-11-01 19:40:33.011 | INFO:main:广播任务更新: 2c6e6d7b-e7f7-4502-9659-96c392e931ff, 状态: processing, 连接数: 1
2025-11-01 19:40:33.011 | INFO:video_processor:开始下载视频: https://www.bilibili.com/video/BV19psRzpEPX/?spm_id_from=333.1007.tianma.1-1-1.click&vd_source=720b50bd3604289ec9268b5e9851cdfb
2025-11-01 19:40:33.017 | Deprecated Feature: Support for Python version 3.9 has been deprecated. Please update to Python 3.10 or above
2025-11-01 19:40:34.235 | INFO:video_processor:视频标题: 翻遍整个B站,这绝对是2025讲的最好的提示词工程(Prompt Engineering)教程,全程干货无废话!让你少走99%的弯路!AI大模型|LLM p01 1、什么是提示工程(PromptEngineering)
2025-11-01 19:40:38.222 |
2025-11-01 19:40:38.279 | INFO:video_processor:音频文件已保存: /app/temp/audio_55907a1e.m4a
2025-11-01 19:40:38.280 | INFO:main:广播任务更新: 2c6e6d7b-e7f7-4502-9659-96c392e931ff, 状态: processing, 连接数: 1
2025-11-01 19:40:38.284 | INFO:main:广播任务更新: 2c6e6d7b-e7f7-4502-9659-96c392e931ff, 状态: processing, 连接数: 1
2025-11-01 19:40:38.284 | INFO:transcriber:正在加载Whisper模型: base
2025-11-01 19:40:39.215 | INFO:httpx:HTTP Request: GET https://huggingface.co/api/models/Systran/faster-whisper-base/revision/main "HTTP/1.1 200 OK"
2025-11-01 19:40:39.900 | INFO:httpx:HTTP Request: HEAD https://huggingface.co/Systran/faster-whisper-base/resolve/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/model.bin "HTTP/1.1 302 Found"
2025-11-01 19:40:40.074 | INFO:httpx:HTTP Request: HEAD https://huggingface.co/Systran/faster-whisper-base/resolve/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/tokenizer.json "HTTP/1.1 307 Temporary Redirect"
2025-11-01 19:40:40.077 | INFO:httpx:HTTP Request: HEAD https://huggingface.co/Systran/faster-whisper-base/resolve/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/vocabulary.txt "HTTP/1.1 307 Temporary Redirect"
2025-11-01 19:40:40.126 | INFO:httpx:HTTP Request: HEAD https://huggingface.co/Systran/faster-whisper-base/resolve/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/config.json "HTTP/1.1 307 Temporary Redirect"
2025-11-01 19:40:40.190 | INFO:httpx:HTTP Request: GET https://huggingface.co/api/models/Systran/faster-whisper-base/xet-read-token/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66 "HTTP/1.1 200 OK"
2025-11-01 19:40:40.241 | INFO:httpx:HTTP Request: HEAD https://huggingface.co/api/resolve-cache/models/Systran/faster-whisper-base/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/tokenizer.json "HTTP/1.1 200 OK"
2025-11-01 19:40:40.263 | INFO:httpx:HTTP Request: HEAD https://huggingface.co/api/resolve-cache/models/Systran/faster-whisper-base/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/vocabulary.txt "HTTP/1.1 200 OK"
2025-11-01 19:40:40.300 | INFO:httpx:HTTP Request: HEAD https://huggingface.co/api/resolve-cache/models/Systran/faster-whisper-base/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/config.json "HTTP/1.1 200 OK"
2025-11-01 19:40:40.489 | INFO:httpx:HTTP Request: GET https://huggingface.co/api/resolve-cache/models/Systran/faster-whisper-base/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/tokenizer.json "HTTP/1.1 200 OK"
2025-11-01 19:40:40.647 | INFO:httpx:HTTP Request: GET https://huggingface.co/api/resolve-cache/models/Systran/faster-whisper-base/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/vocabulary.txt "HTTP/1.1 200 OK"
2025-11-01 19:40:41.039 | INFO:httpx:HTTP Request: GET https://huggingface.co/api/resolve-cache/models/Systran/faster-whisper-base/ebe41f70d5b6dfa9166e2c581c45c9c0cfc57b66/config.json "HTTP/1.1 200 OK"
2025-11-01 19:41:13.070 | INFO:transcriber:模型加载完成
2025-11-01 19:41:13.070 | INFO:transcriber:开始转录音频: /app/temp/audio_55907a1e.m4a
2025-11-01 19:41:13.076 | INFO: 127.0.0.1:43226 - "GET / HTTP/1.1" 200 OK
2025-11-01 19:41:14.259 | INFO:faster_whisper:Processing audio with duration 24:08.554
2025-11-01 19:41:16.759 | INFO:faster_whisper:VAD filter removed 00:35.610 of audio
2025-11-01 19:41:17.537 | INFO:faster_whisper:Detected language 'zh' with probability 0.99
2025-11-01 19:41:17.539 | INFO:transcriber:检测到的语言: zh
2025-11-01 19:41:17.539 | INFO:transcriber:语言检测概率: 0.99
2025-11-01 19:42:18.768 | INFO:transcriber:转录完成
2025-11-01 19:42:18.769 | INFO:main:广播任务更新: 2c6e6d7b-e7f7-4502-9659-96c392e931ff, 状态: processing, 连接数: 1
2025-11-01 19:42:18.775 | INFO:main:广播任务更新: 2c6e6d7b-e7f7-4502-9659-96c392e931ff, 状态: processing, 连接数: 1
2025-11-01 19:42:18.776 | INFO:summarizer:文本较长(8011 chars),启用分块优化
2025-11-01 19:42:18.777 | INFO:summarizer:文本分为 4 块处理
2025-11-01 19:42:18.989 | INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-11-01 19:42:22.184 | INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-11-01 19:43:28.760 | INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-11-01 19:44:20.236 | INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-11-01 19:44:39.864 | INFO:main:检测到的语言: zh, 摘要语言: zh
2025-11-01 19:44:39.865 | INFO:main:不需要翻译: detected_language=zh, summary_language=zh, should_translate=False
2025-11-01 19:44:39.867 | INFO:main:广播任务更新: 2c6e6d7b-e7f7-4502-9659-96c392e931ff, 状态: processing, 连接数: 1
2025-11-01 19:44:39.869 | INFO:summarizer:文本较长(12739 tokens),启用分块摘要
2025-11-01 19:44:39.869 | INFO:summarizer:分割为 2 个块进行摘要
2025-11-01 19:44:39.870 | INFO:summarizer:正在摘要第 1/2 块...
2025-11-01 19:44:39.935 | INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-11-01 19:44:50.870 | INFO:summarizer:正在摘要第 2/2 块...
2025-11-01 19:44:50.921 | INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-11-01 19:45:01.956 | INFO:summarizer:正在整合最终摘要...
2025-11-01 19:45:02.014 | INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-11-01 19:45:17.787 | INFO: 127.0.0.1:44406 - "GET / HTTP/1.1" 200 OK
2025-11-01 19:45:17.788 | INFO: 127.0.0.1:49030 - "GET / HTTP/1.1" 200 OK
2025-11-01 19:45:17.788 | INFO: 127.0.0.1:54308 - "GET / HTTP/1.1" 200 OK
2025-11-01 19:45:17.789 | INFO: 127.0.0.1:47682 - "GET / HTTP/1.1" 200 OK
2025-11-01 19:45:17.799 | INFO:main:任务完成,准备广播最终状态: 2c6e6d7b-e7f7-4502-9659-96c392e931ff
2025-11-01 19:45:17.799 | INFO:main:广播任务更新: 2c6e6d7b-e7f7-4502-9659-96c392e931ff, 状态: completed, 连接数: 1
2025-11-01 19:45:17.799 | INFO:main:最终状态已广播: 2c6e6d7b-e7f7-4502-9659-96c392e931ff
2025-11-01 19:45:43.520 | INFO: 127.0.0.1:36922 - "GET / HTTP/1.1" 200 OK


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 31
31 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)