OUC AI Lab第五章:生成式对抗网络 & Diffusion
例如你的数据集有花和草,在之前的时候,模型会告诉你e(x) 100%是花,但是e(x)变成概率之后,模型告诉你,e(x)有0.8的概率是花,0.2的概率是草,那么就可能会生成一张带草的花;2.尽可能使p(z)和p(z|x)是平滑的,使p(z)平滑也就是让先验分布平滑,也就是为了确保任意的x都能有一个合理的输出,而不是出现一个从没有出现的x,就会落入z中的一个孤立的点,从而生成无意义的图片;使p(z
GAN
gan的思想就是创造一个生成器和判别器,生成器生成图像给判别器判别真假,同时判别器也要去判别真实图像,生成器和判别器一起学习
大体的目标函数就是如上所示,对判别器而言,要最大化给真实图像的概率和最小化生成图像的概率,对生成器而言,就是要最大化生成图像的概率。
再将这三个目标函数经过变化就可以得到如下的目标函数
在这里真实图像服从Pdata,从标准正态分布Pz中取样送入生成网络中生成的图像服从Pg分布,我们想要让Pg尽可能靠近Pdata。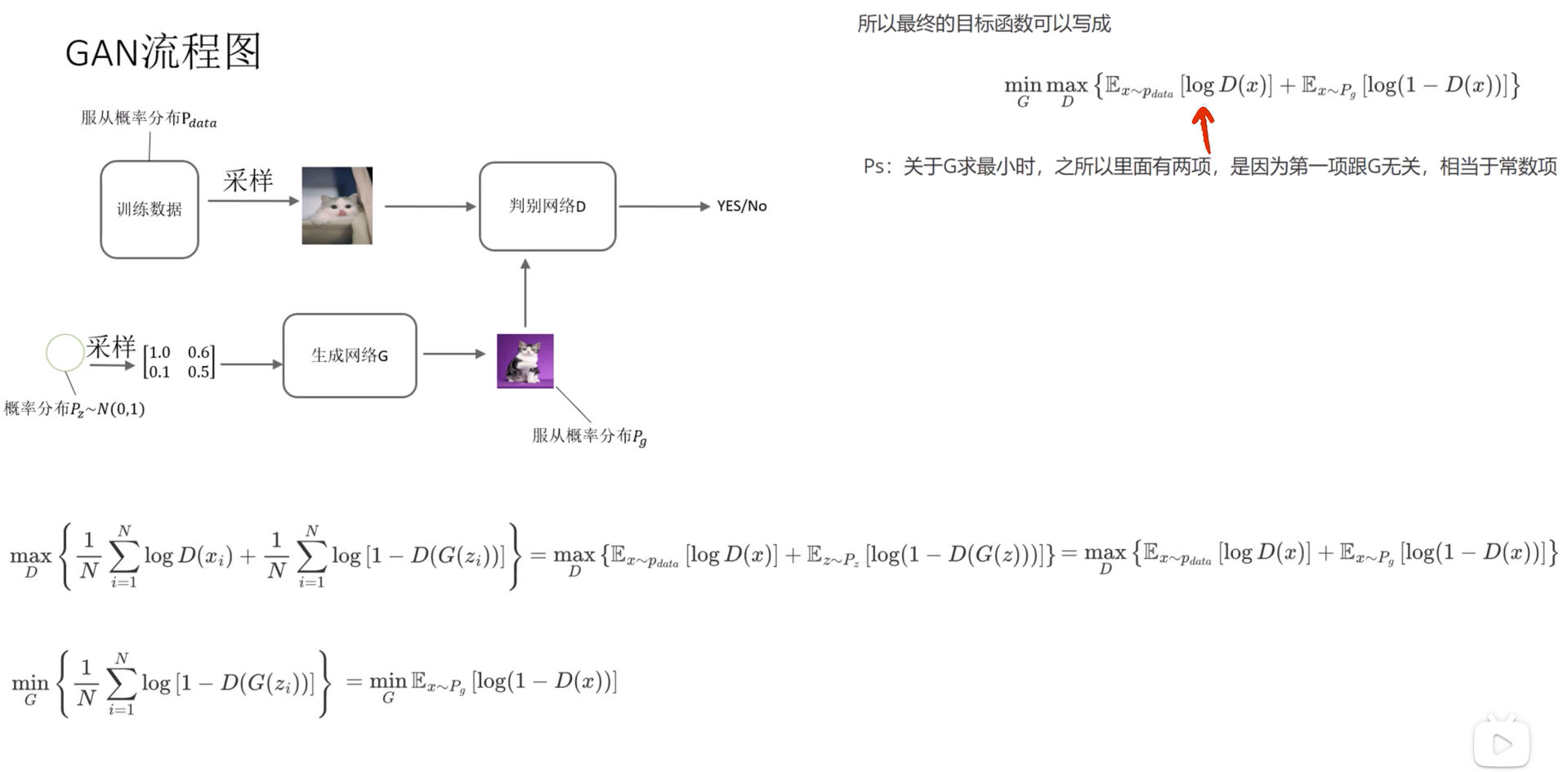
这里x~Pdata代表图片是从训练数据中取得的,而x ~Pg代表是图片是从生成网络中取得的。而训练生成网络G时又和x ~Pdata无关,所以最终目标函数可以写为一个式子。
CGAN
在GAN中没有办法生成指定的图像,因为判别器只会输出输入图像是否是真实数据,也就是不管是哪种标签都可以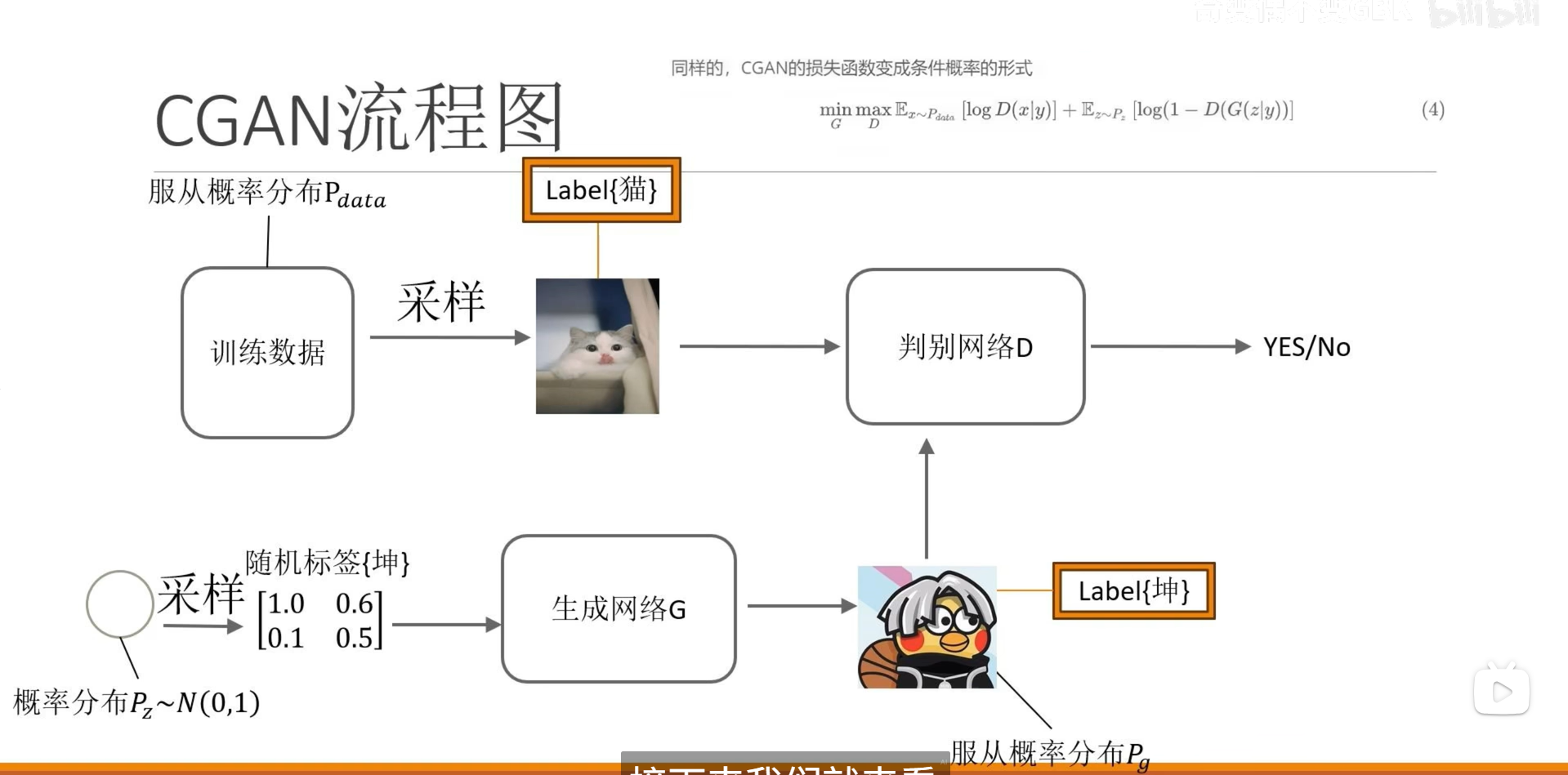
因此cgan的判别网络不仅要求输入图像,还要要求输入标签,所以判别器不仅要判别这个图片是不是“真的”,还要判别是不是属于类别的。而生成网络不仅要生成图像,还要根据采样的标签生成图像。
DCGAN
DCGAN是CGAN的一个变体,具体来说就是引入了深度卷积网络,以提高模型的稳定性和生成质量,使用了卷积层和反卷积层来替代GAN中的全连接层。
Diffusion
很喜欢老师的一句话,扩散模型很难,不知道大家到底是出于什么目的来学习Diffusion,但都希望大家坚持下去,扩散领域不能没有你,就像西方不能失去耶路撒冷
一、VAE
根据某位老师的介绍,想要了解diffusion,首先需要了解VAE。
那什么是VAE呢?如下图所示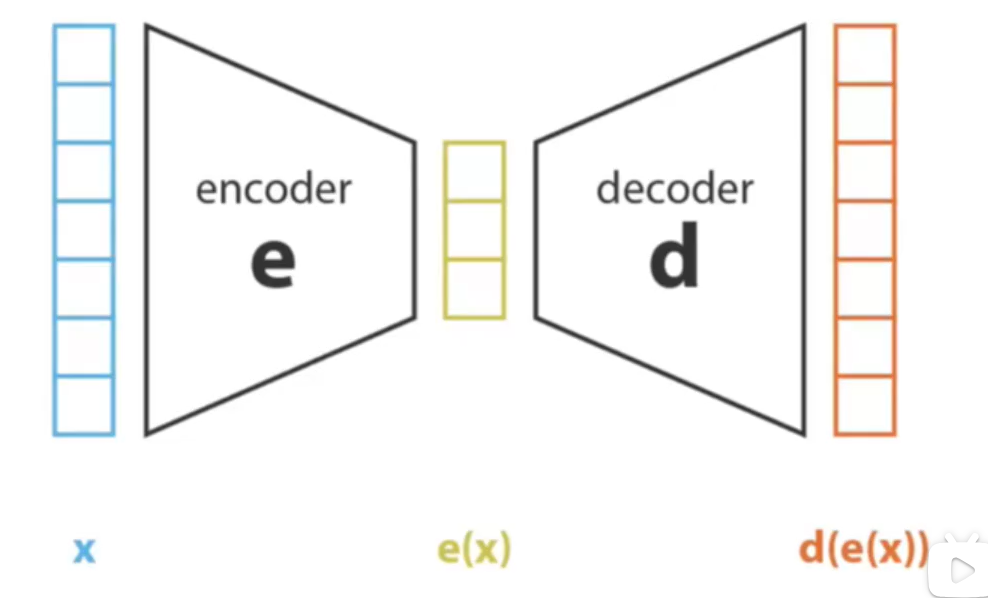
x可以理解为输入的图片,而encoder呢,就是神经网络,最后经过降维得到了e(x)
在之前做各种分类网络的时候,e(x)就是我们提取到的特征,下一步就是要进行再降维和输出类别了,但在这里,我们要将得到的含有信息的e(x)经过decoder进行升维,恢复到原来的维度,并且越像真实图像就越好。
但是有一个问题,如果是按照传统思路,encoder是一个神经网络,decoder是一个神经网络,loss就是一个绝对误差,那么会导致一个后果,就是超级过拟合。
举个例子,如果你的训练集里有一朵花,经过特征提取后就会映射到某一个点,而decoder就会根据你这个点生成一个图像;又因为你使用的是绝对误差,也就是生成图像和原始图像越像越好——这就会导致,你只能够生成那一朵花。也就是在你测试时,只要让e(x)中包含了“花”的信息,好了,你就等着吧,你将会收获无数张训练集中的那朵花——这何尝不算是一种过拟合呢?
这不是我们想要的结果,诚然,我们想生成花,但是我们想生成的是各种各样鲜艳的花,我们希望的是我给你一朵花你能够还我一整片花海——因此,我们必须要做出一点改变。
我们要让e(x)并不是包括着一些点(类别),而是概率,也就是说,你输入一张x图像,得到的e(x)并不是确定的,不是映射到一个点,而是一个范围,这样是不是每次输入得到的输出都不一样?那也就实现了再经过decoder恢复的结果不一样。例如你的数据集有花和草,在之前的时候,模型会告诉你e(x) 100%是花,但是e(x)变成概率之后,模型告诉你,e(x)有0.8的概率是花,0.2的概率是草,那么就可能会生成一张带草的花;如果e(x)只有0.5的概率是花了,0.5的概率靠近草,可能会生成一张绿色的花。
因此,VAE的目的有两个:
1.尽可能让p(x|z)和p(z|x)接近,也就是让给定隐含信息后生成图片x的概率 和 给定图片x生成有关于x的隐含信息z 尽可能接近;
2.尽可能使p(z)和p(z|x)是平滑的,使p(z)平滑也就是让先验分布平滑,也就是为了确保任意的x都能有一个合理的输出,而不是出现一个从没有出现的x,就会落入z中的一个孤立的点,从而生成无意义的图片;使p(z|x)平滑也就是让后验分布平滑,为了使近似的x落入近似的z中,也让相同的x落入近似的z中。
实际上,不同的视频对VAE目的的讲解有一些细微的差异,但总的来说,VAE一个目标是使解码器能够还原出原图像,一个目标是使p(z|x)输出平滑。
要是两个概率接近,就要考虑一个问题:如何去计算两个概率的距离呢?在这里我们使用KL散度
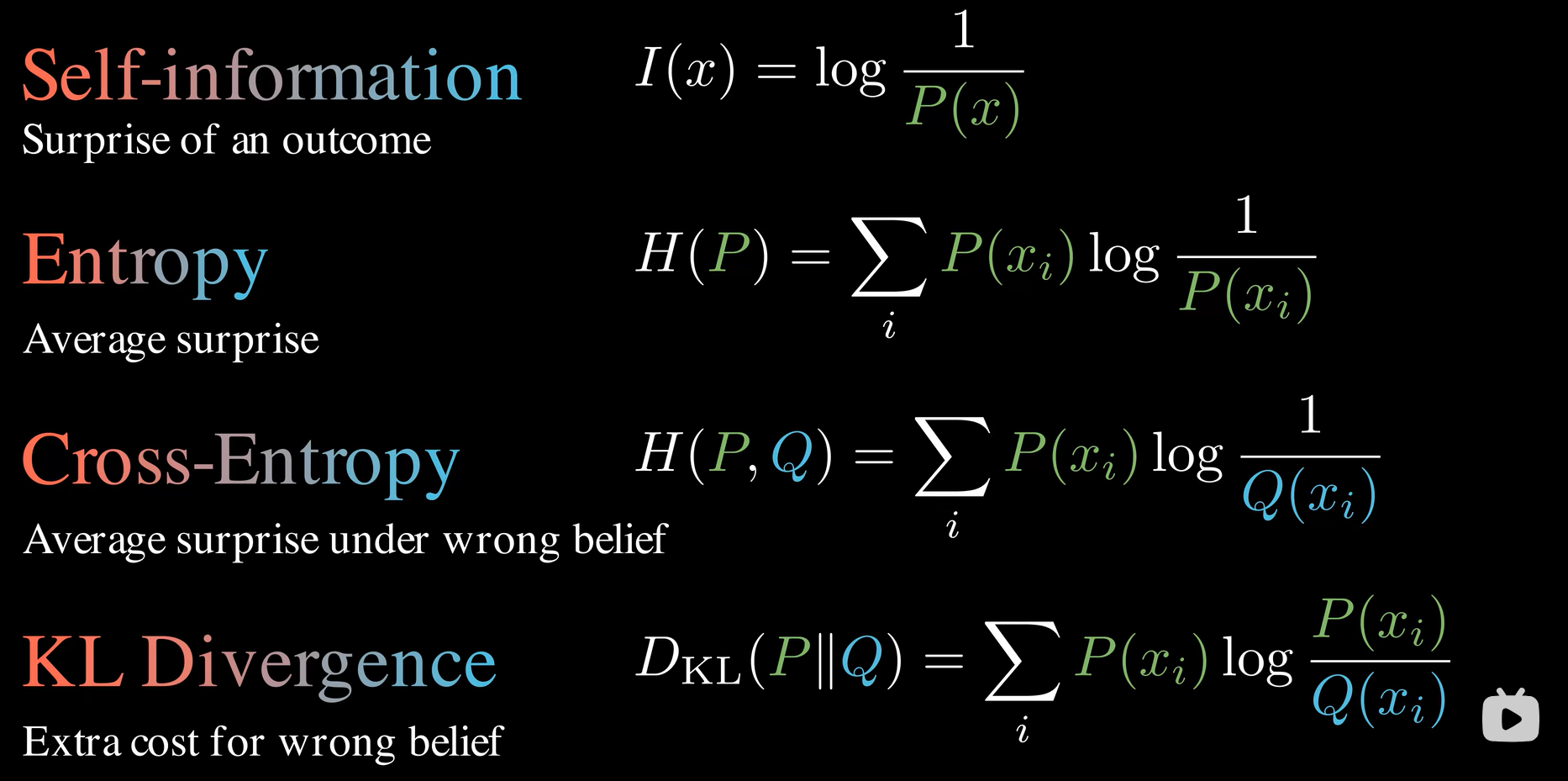
最后一行就是计算公式了,KL散度实际上是衡量交叉熵与熵的差值,即使用近似的概率(模型的概率)Q比使用真实概率P多浪费的信息,实际上就是可以用来去衡量两个概率分布有多相像。
VAE的详细推导请看VAE
在这里我记录一下我的几点理解
首先为什么要引入q(z|x),这里并没有提到特殊的为什么,而是说,这样处理后可以恰好得到我们想让VAE做的事,并且推导到后面发现,前面引入的q(z|x)应该是近似P(z|x)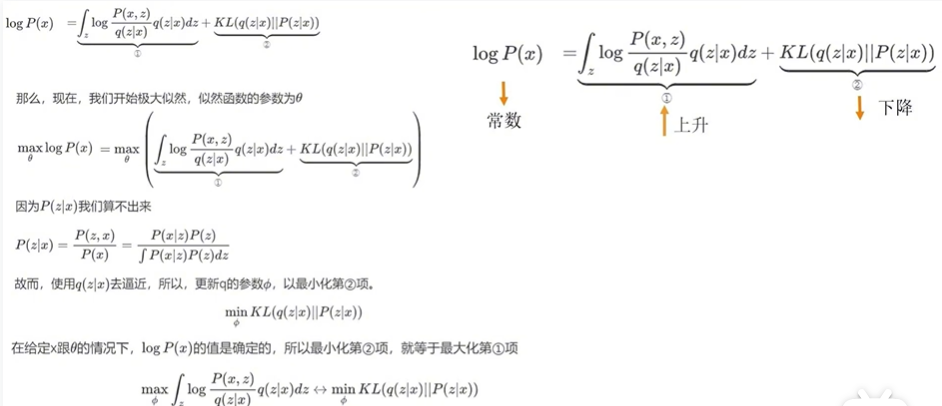
上图中实际是讲,因为要求极大似然估计,所以要求使lnP(x)最大的θ,所以要最大化后面两项,但是因为P(z|x)要遍历所有的x,x是现实生活中的所有图片,所以P(z|x)算不出来,因此不能计算KL散度。那怎么办呢?
1、我们就只计算第一项,第二项呢?第二项等于0就好了,就不用计算KL散度了。
2、那么如何使第二项为零呢?我们知道,两个分布越相近,KL散度就越接近于0,那么我们这里就要让q(z|x)去逼近P(z|x)。
3、再换一个思路,因为q分布的参数是φ,所以更新q分布的时候θ是固定的,也就是说!lnP(x)是确定的,所以只需要让第一项尽量大,那么KL散度就会尽量小,也就实现了q(z|x)去逼近P(z|x)。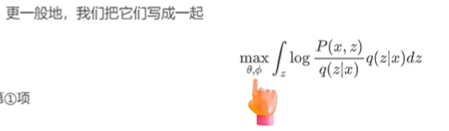
目标也就变为了上图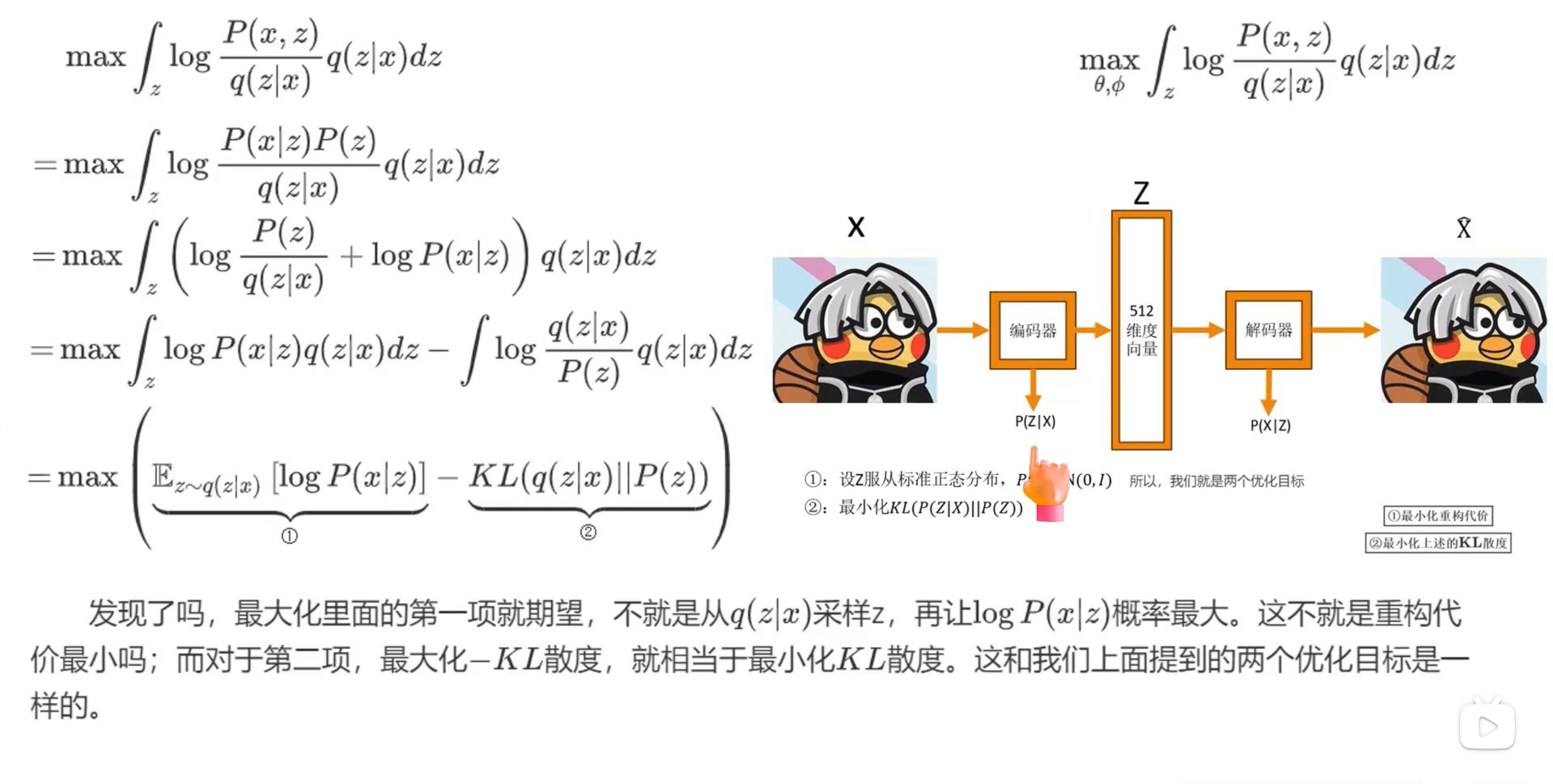
再经过变化可以得到上图,第一项就是,从编码器中取出z,再通过解码器生成原图像x的概率最大,第二项是使q(z|x)接近标准正态分布,为什么?因为我们让P(z)服从标准正态分布,所以最小化KL散度就相当于是使q(z|x)接近标准正态分布。那么我们就把这两项当作我们的原始目标,好像这么解释颇有种先果后因的感觉
第二项推导如下所示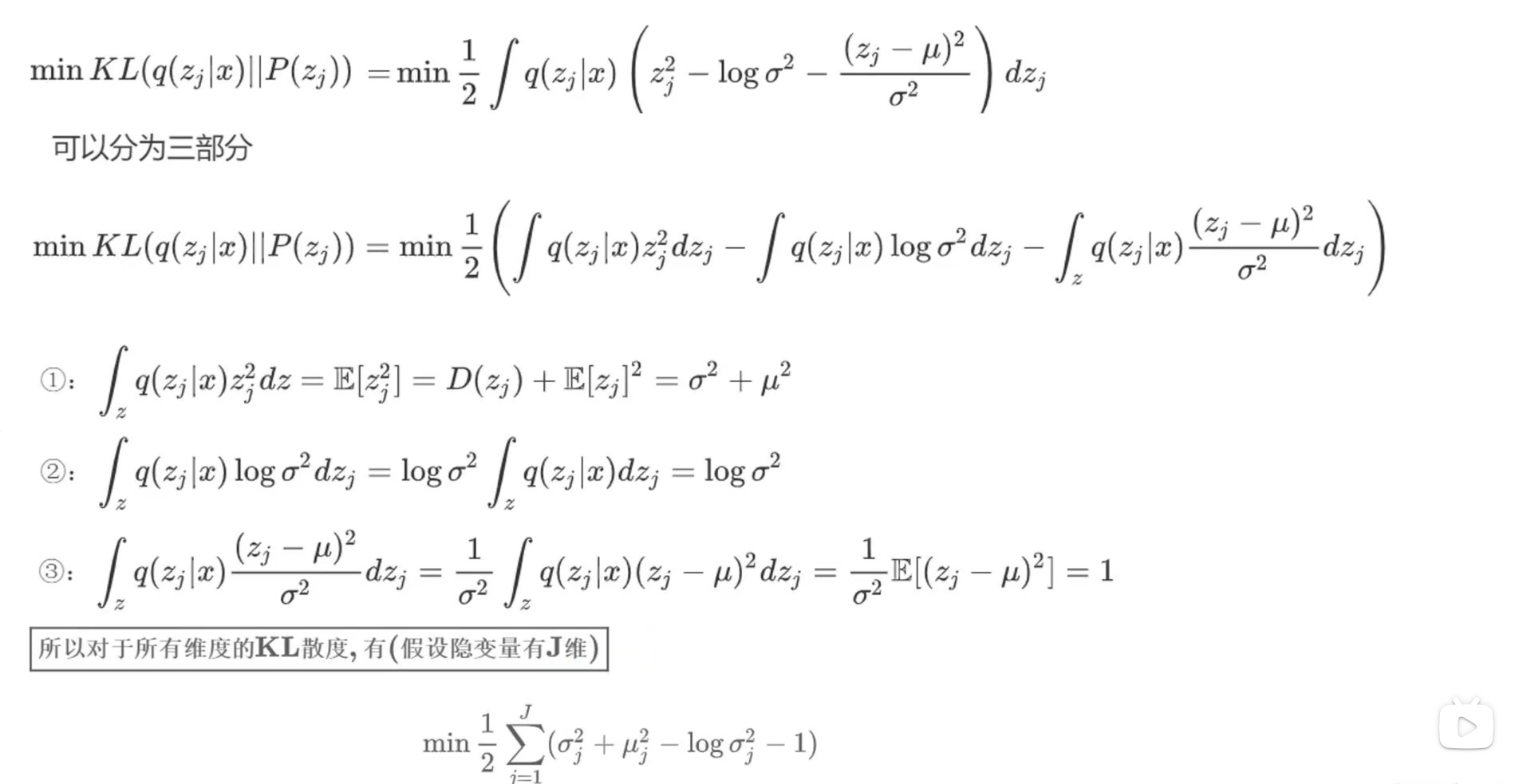
第一项推导如下所示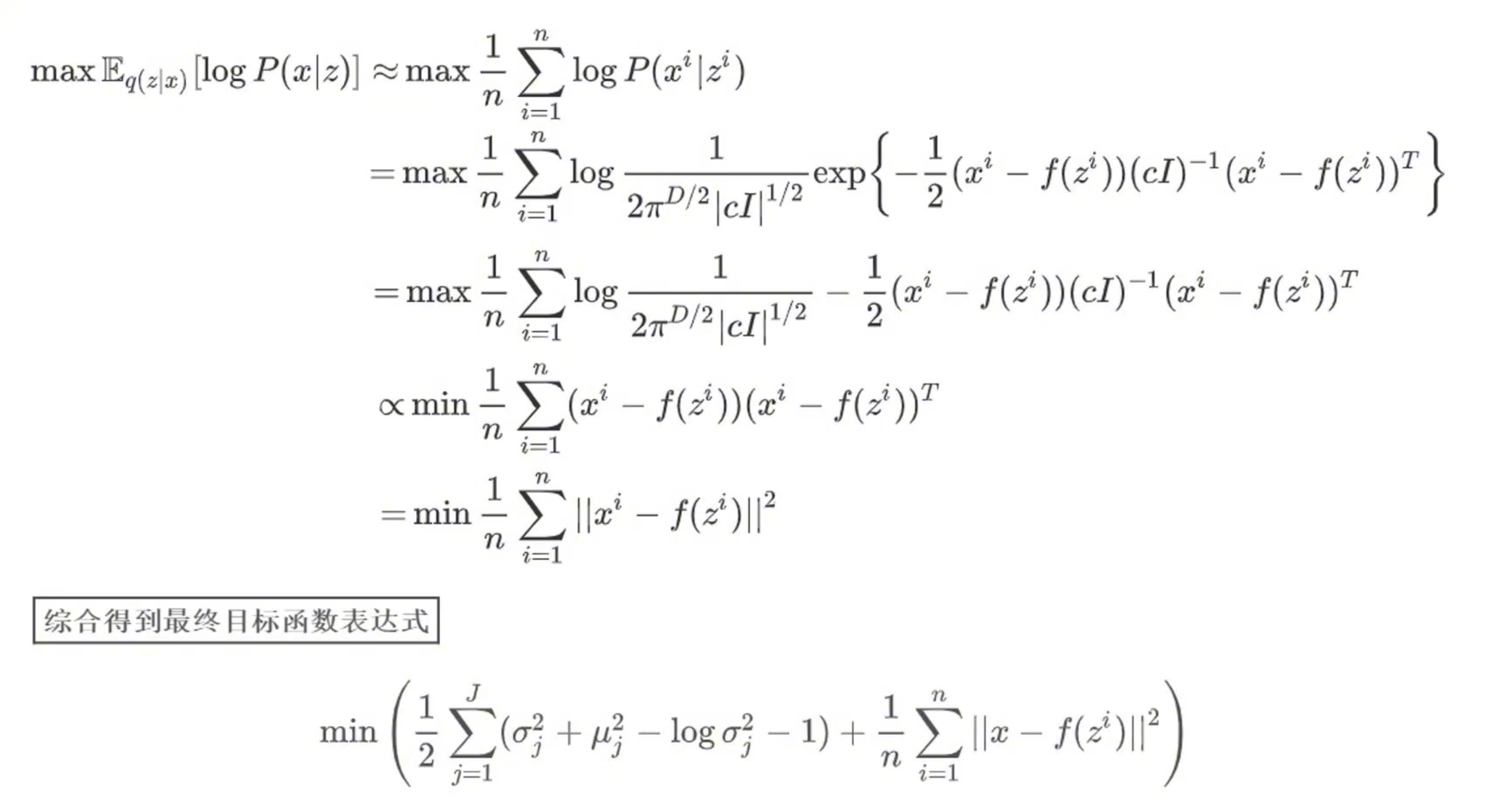
又因为z是取样得到的,没办法进行反向传播
因此需要用到重参数化技巧,这里的z可以证明就相当于从q(z|x)中取样得到,模型图就如下所示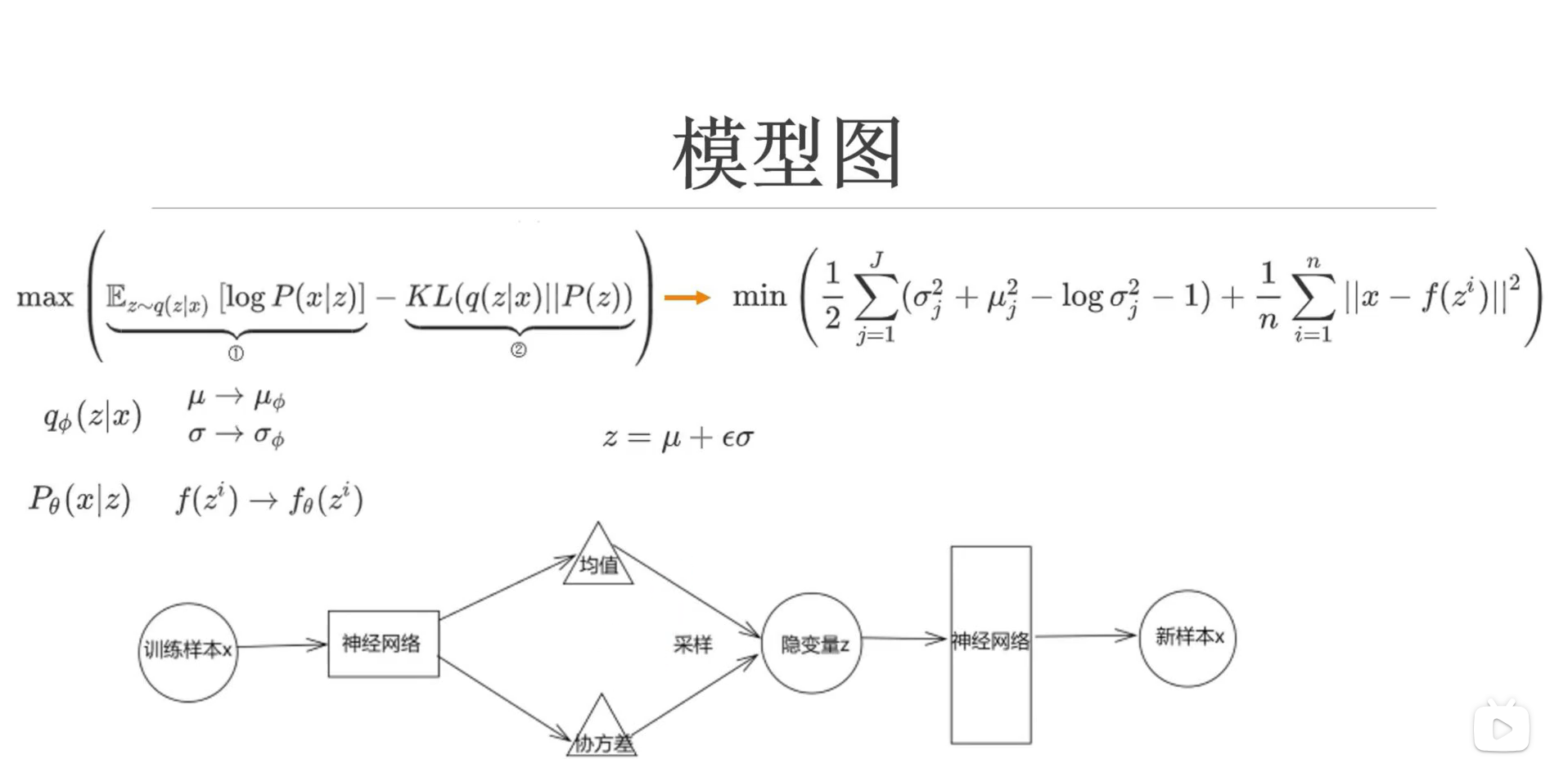
二、Diffusion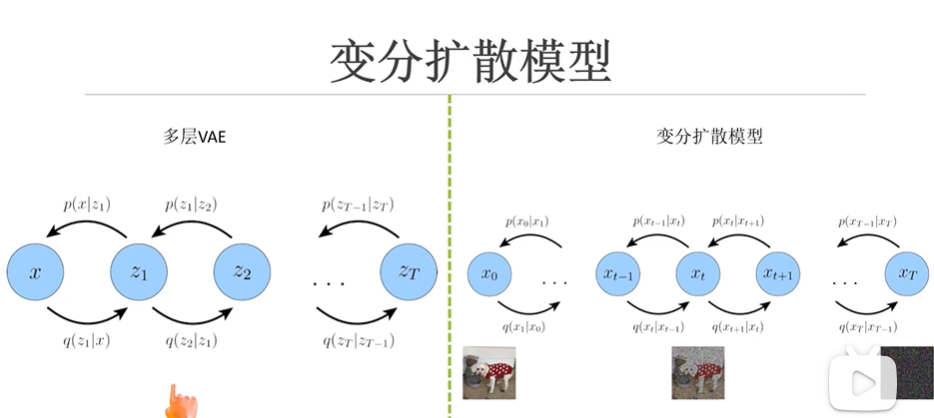
从单层VAE到多层VAE,就是添加了好几个编码过程,一直编码到zt,在经过相同数量的解码器解码到原始图像x,这种多层VAE要比单层的VAE效果要好一点
而diffusion模型和多层VAE有些相似,不同的地方在于diffusion模型是的编码过程是不断给原始图像x0加高斯白噪声的过程,因此x的维度都是一样的,直到最后服从一个高斯分布。而且这里的q分布,也就是给x0加噪的分布是设定好的,相对加噪的一个过程,因此也不需要让神经网络去逼近了。还有一点,这里从x0加噪到xt的过程其实还可以一步完成,具体的推导请看视频Diffusion
代码
GAN:关于GAN的代码中,我认为值得一讲的就是更新参数部分,事实上我认为不管是gan还是diffusion的重点都在“如何进行反向传播”上,而至于网络——它仍然是一个黑盒子,我们赋予了它的生成结果以“label”的含义,相信它能够生成“label”,于是它生成的就是“label”;我们赋予了它的生成结果以“噪声”的含义,因为将它经过加乘得到的结果当作生成的图像,相信它能够生成“噪声”——它生成的就是噪声。
至于GAN的损失函数,这几段代码需要好好理解
fake_images = generator(z)
# 计算判别器损失,并优化判别器
real_loss = bce(discriminator(real_images), ones)
fake_loss = bce(discriminator(fake_images.detach()), zeros)
d_loss = real_loss + fake_loss
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# 计算生成器损失,并优化生成器
g_loss = bce(discriminator(fake_images), ones)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
1.在代码计算real_loss和fake_loss部分,因为这里是“固定生成器,训练判别器”的部分,所以对于判别器,要计算真实图像 real_images 与1的差值,计算生成图像fake_images与0的差值;而在优化生成器的阶段,自然就要计算生成图像与1的loss。
2.这里的detach是什么意思?这里的detach的作用是为了“阻止反向传播到生成器”。当调用d_loss.backward(),梯度从损失函数反向传播到判别器,从而达到了训练判别器将真实图像判别为1,生成图像判别为0。而传播到生成器就停下来了——我只是告诉判别器要着重识别你生成的图像,但你没必要知道这件事
3.在优化生成器时,就需要计算生成图像与1的loss了,那么我们如何仅仅根据discriminator结果与生1的差值,生成器就能知道如何调整参数?也就是生成器竟然知道如何调整参数才能使得另一个网络结果变好?因为反向传播不仅仅可以沿着加减乘除传播,从fake_images = generator(z)——g_loss = bce(discriminator(fake_images), ones)的过程中generator和discriminator也会建立联系,所以生成器就可以根据这个loss更新自己的参数了。又因为这里仅仅是g_loss.backward(),所以只有生成器更新自己的参数。
4.至于为什么这里判别器会生成0,1去判别生成图像的真假,而不是0-9的标签——正如我们前面所说,因为我们相信它会生成真假,而不是标签
CGAN:我对CGAN也有几点见解
1.代码中输入到判别器中的标签时使用one-hot向量,但这里也可以不用one-hot向量,直接使用标签也可以
2.我一直以为生成器是要生成图像的同时生成标签,看了代码才知道,是根据随机生成的标签生成对应的图像
3.对应的代码和GAN很相像,像损失函数什么的都很类似,有区别的地方就是需要在生成器和判别器的初始输入要+10,这是因为也要把标签给输入,至于为什么网络就能知道这28*28+10的后面10个的意义是标签呢?因为我们相信它。
DCGAN:这里的代码并没有将标签也当作输入,其他的除了网络变为卷积网络其他的和GAN差不多。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)