我用AI做了一个1978年至2019年中国大陆企业注册的查询网站
本文介绍了一个基于AI编程工具构建的中国大陆企业注册信息查询网站项目。该项目利用GitHub开源数据集(1978-2019年全国企业工商数据),通过腾讯CodeBuddy智能编程助手自动生成代码,实现数据导入和网站搭建。技术实现包括:获取免费云服务器、安装宝塔面板配置Web环境、使用Shell脚本批量导入588万条CSV数据到MySQL数据库,并建立关键字段索引。最终构建一个支持模糊搜索企业名称、
我用AI做了一个1978年至2019年中国大陆企业注册的查询网站
最近星哥在GitHub上偶然发现了一个宝藏仓库——Enterprise-Registration-Data-of-Chinese-Mainland。这个包含1978到2019年全国企业注册信息的数据集,像一座尘封的经济档案库,静静躺在代码海洋里。588万条记录、31个省份、10个核心字段,从"东方华脉建筑设计"到"冷酸灵互娱科技",这些带着时代印记的企业名称背后,藏着中国改革开放42年的经济密码。
数据源来自 GitHub 上的开源项目 Enterprise-Registration-Data-of-Chinese-Mainland 。
全程不使用手写代码,仅使用AI编程工具。

技术实现思路
获取免费服务器
-
申请免费服务器(一个月)
-
最好有域名
-
我这里申请的是腾讯云的,如果你有其他的云服务器或者虚拟机都行。
数据准备
- 原始数据来自 GitHub 仓库,格式为 CSV。
- 新建数据表、合理索引
- 将csv数据导入
- 数据量较大,需要进行清洗、索引和分库处理。
检索条件
- 检索公司名、法人、地址得出结果
- 支持模糊搜索,例如输入“华为”即可匹配“华为技术有限公司”。
前端交互
- 简洁的搜索框 + 结果列表。
- 支持按年份、地区分类筛选。
1.下载csv文件
大家可以使用github或者夸克下载。
数据源来自github: https://github.com/kinginsun/Enterprise-Registration-Data-of-Chinese-Mainland
夸克下载:
我用夸克网盘给你分享了「1978-2019新注册的企业工商信息.zip」链接:https://pan.quark.cn/s/efd621e2c4f9
提取码:DLFT
文件夹以年份命名,随便进入一个文件夹打开文件夹中的文档
如图表格

2.连接服务器
这步不是必须,也可以在本地电脑或者虚拟机上安装
我这里使用的是腾讯的CodeBuddy1024送的免费1个月的轻量云
3.安装宝塔
具体可以看一下星哥之前写的 宝塔面板从零搭建个人博客新手也能轻松上手
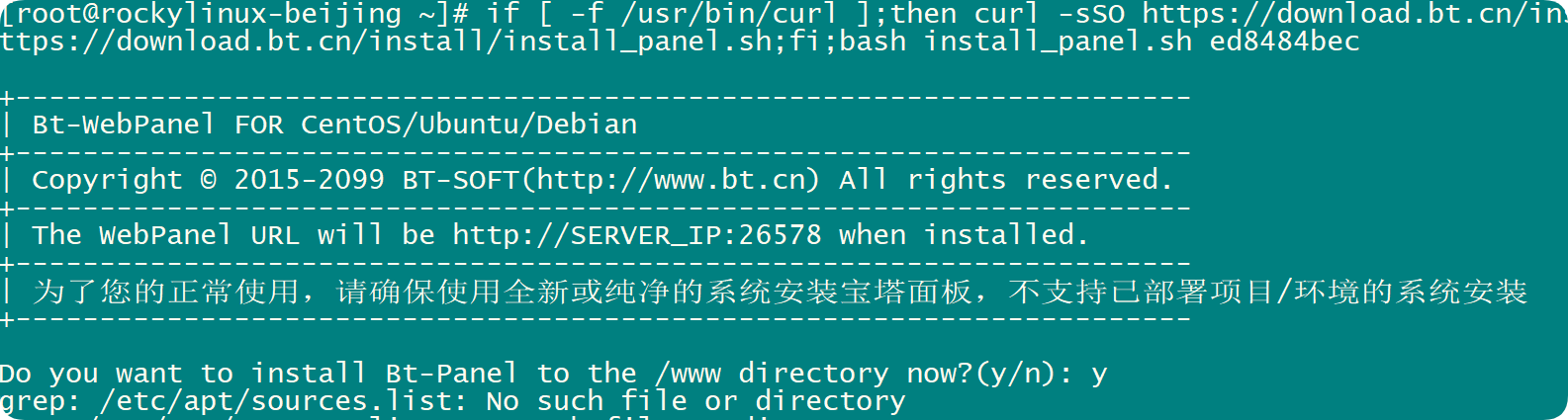
安装宝塔命令
if [ -f /usr/bin/curl ];then curl -sSO https://download.bt.cn/install/install_panel.sh;else wget -O install_panel.sh https://download.bt.cn/install/install_panel.sh;fi;bash install_panel.sh ed8484bec
进入宝塔
安装WEB环境
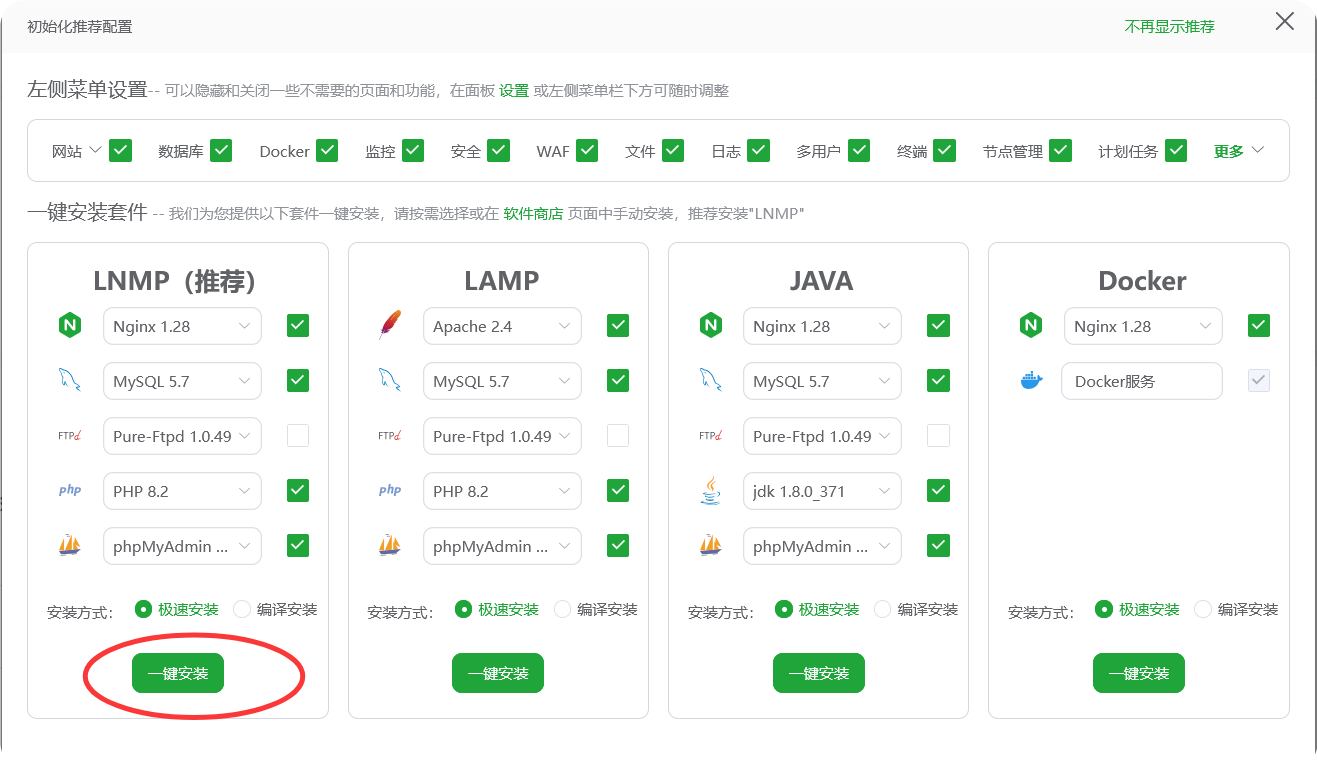
WEB环境安装成功
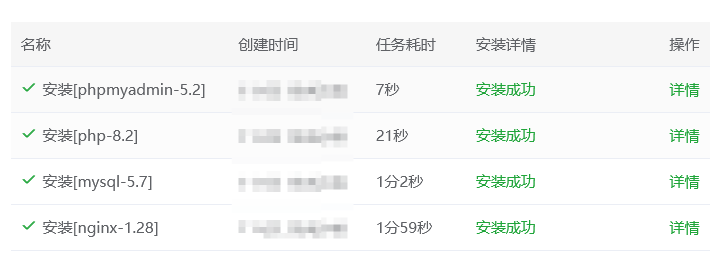
记住mysql密码
记住mysql的密码,以后要用的
4.下载CodeBuddy编程工具
腾讯 CodeBuddy 是一款由腾讯云推出的智能编程助手,定位为“AI时代的编程伙伴”,通过自然语言交互帮助开发者更高效地完成从需求到上线的全流程开发。
再到本地开发电脑上安装CodeBuddy
下载:
浏览器打开 https://copilot.tencent.com/
点击安装IDE

安装之后
新建项目文件夹
新建文件夹,命名为“AI-1978-and-2019-register-company”将csv文件放到目录中
把zip解压
$ ll
total 16
drwxr-xr-x 1 Administrator 197121 0 Feb 22 2020 Enterprise-Registration-Data-of-Chinese-Mainland-master/
使用CodeBuddy
打开文件夹AI-1978-and-2019-register-company
导入数据库提示词
写一个shell脚本,将Enterprise-Registration-Data-of-Chinese-Mainland-master目录中的csv文件批量导入到mysql数据库中
表索引要有企业名称、法人代表、所在省份
结果得到import_to_mysql.sh文件
import_to_mysql.sh

提示词输入之后,生成了三个文件

将文件上传到轻量云服务器中,修改root密码
新建数据库
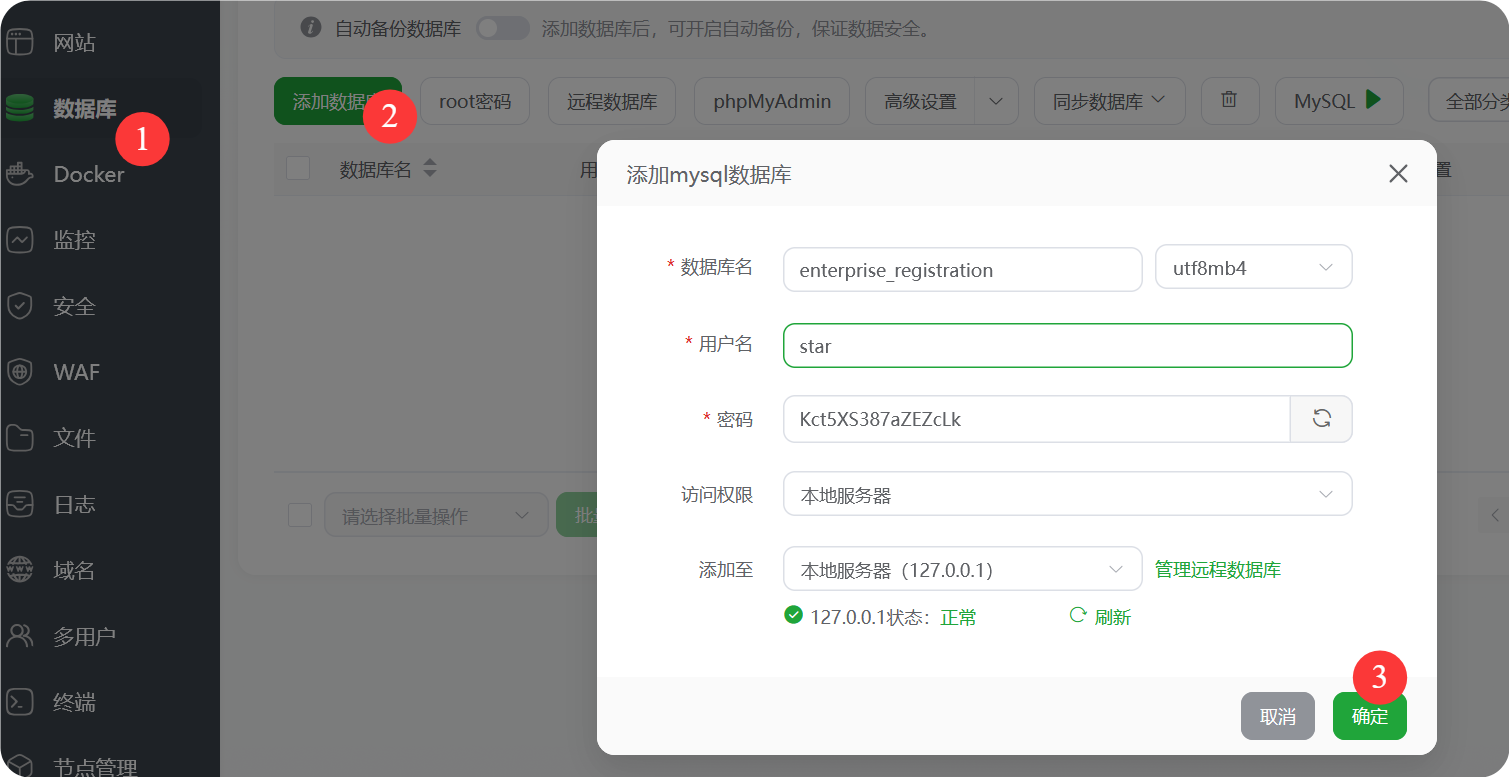
运行
sh import_to_mysql.sh
#!/bin/bash
# MySQL数据库配置
DB_HOST="localhost"
DB_USER="改成你的用户名"
DB_PASS="改成你的密码"
DB_NAME="enterprise_registration"
# CSV文件目录
CSV_DIR="Enterprise-Registration-Data-of-Chinese-Mainland-master/1978-2019新注册的企业工商信息"
# 创建数据库和表
create_database_and_table() {
echo "创建数据库和表..."
mysql -h $DB_HOST -u $DB_USER -p$DB_PASS << EOF
CREATE DATABASE IF NOT EXISTS $DB_NAME CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
USE $DB_NAME;
DROP TABLE IF EXISTS enterprise_data;
CREATE TABLE enterprise_data (
id INT AUTO_INCREMENT PRIMARY KEY,
企业名称 VARCHAR(500) NOT NULL,
统一社会信用代码 VARCHAR(100),
注册日期 DATE,
企业类型 VARCHAR(100),
法人代表 VARCHAR(100),
注册资金 VARCHAR(100),
经营范围 TEXT,
所在省份 VARCHAR(50),
地区 VARCHAR(100),
注册地址 TEXT,
年份 INT,
省份 VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- 创建索引以提高查询性能
CREATE INDEX idx_year ON enterprise_data(年份);
CREATE INDEX idx_province ON enterprise_data(省份);
CREATE INDEX idx_reg_date ON enterprise_data(注册日期);
EOF
}
# 导入单个CSV文件
import_csv_file() {
local csv_file="$1"
local year="$2"
local province="$3"
echo "导入文件: $csv_file (年份: $year, 省份: $province)"
# 提取文件名中的省份信息(去掉.csv后缀)
local province_name=$(basename "$csv_file" .csv)
# 使用LOAD DATA INFILE导入CSV文件
mysql -h $DB_HOST -u $DB_USER -p$DB_PASS $DB_NAME << EOF
LOAD DATA LOCAL INFILE '$csv_file'
INTO TABLE enterprise_data
CHARACTER SET utf8mb4
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(企业名称, 统一社会信用代码, 注册日期, 企业类型, 法人代表, 注册资金, 经营范围, 所在省份, 地区, 注册地址)
SET 年份 = $year, 省份 = '$province_name';
EOF
}
# 批量导入所有CSV文件
batch_import() {
echo "开始批量导入CSV文件..."
# 查找所有年份目录
for year_dir in "$CSV_DIR"/*/; do
if [ -d "$year_dir" ]; then
# 提取年份
local year=$(basename "$year_dir")
echo "处理年份: $year"
# 查找该年份下的所有CSV文件
for csv_file in "$year_dir"/*.csv; do
if [ -f "$csv_file" ]; then
# 提取省份名称
local province=$(basename "$csv_file" .csv)
import_csv_file "$csv_file" "$year" "$province"
fi
done
fi
done
}
# 显示导入统计信息
show_statistics() {
echo "导入完成,统计信息:"
mysql -h $DB_HOST -u $DB_USER -p$DB_Pass $DB_NAME << EOF
SELECT
年份,
COUNT(*) as 企业数量,
COUNT(DISTINCT 省份) as 省份数量
FROM enterprise_data
GROUP BY 年份
ORDER BY 年份;
SELECT
COUNT(*) as 总企业数量,
COUNT(DISTINCT 省份) as 总省份数量,
MIN(年份) as 最早年份,
MAX(年份) as 最晚年份
FROM enterprise_data;
EOF
}
# 主函数
main() {
echo "=== 企业工商信息数据导入MySQL数据库 ==="
# 检查MySQL连接
if ! mysql -h $DB_HOST -u $DB_USER -p$DB_PASS -e "SELECT 1;" > /dev/null 2>&1; then
echo "错误:无法连接到MySQL数据库,请检查配置"
exit 1
fi
# 检查CSV目录是否存在
if [ ! -d "$CSV_DIR" ]; then
echo "错误:CSV目录不存在: $CSV_DIR"
exit 1
fi
# 执行导入流程
create_database_and_table
batch_import
show_statistics
echo "=== 导入完成 ==="
}
# 使用说明
usage() {
echo "使用方法:"
echo " ./import_to_mysql.sh # 执行完整导入流程"
echo ""
echo "配置说明:"
echo " 请修改脚本开头的数据库配置:"
echo " - DB_HOST: MySQL服务器地址"
echo " - DB_USER: MySQL用户名"
echo " - DB_PASS: MySQL密码"
echo " - DB_NAME: 数据库名称"
}
# 参数处理
case "$1" in
-h|--help)
usage
exit 0
;;
*)
main
;;
esac
导入数据库
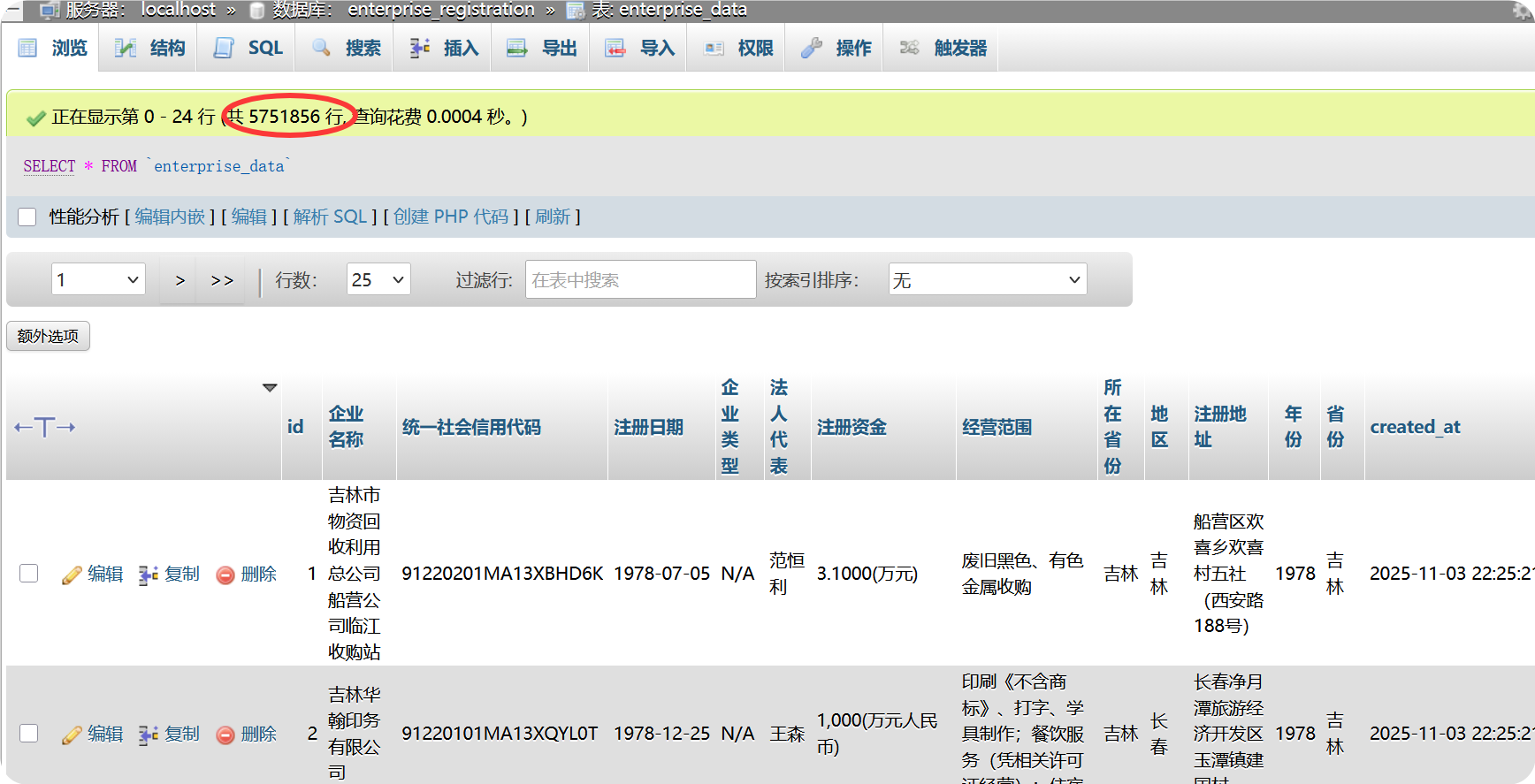
数据库导入成功之后,用宝塔自带的phpmyadmin查看数据。
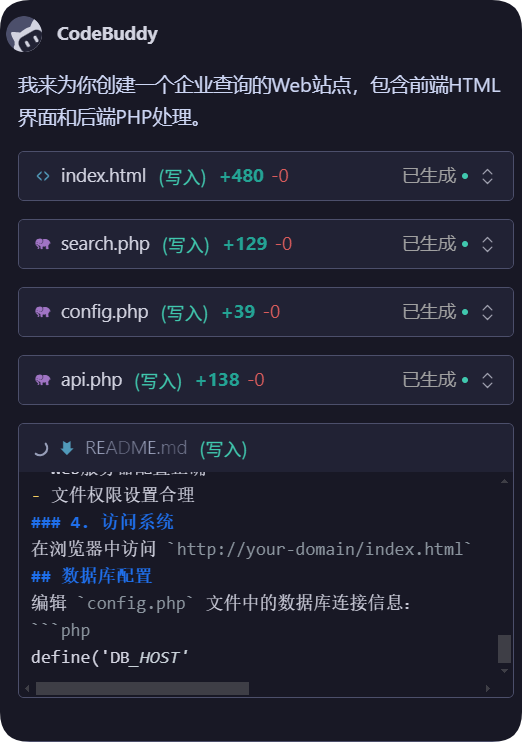
创建web站点的提示语
演示提示词,你也可以使用其他技术栈。
请帮我创建一个web站点
前端使用 html ,前端界面要美观大方、自适应移动端
后端使用 php8.2
数据库配置如下:
用户名:star
密码是:改成你自己密码
主机:127.0.0.1
端口是:3306
数据库名:enterprise_registration
做一个企业查询的站点
可以根据企业名称、法人姓名、查询公司详情
最后给我创建了如下的文件
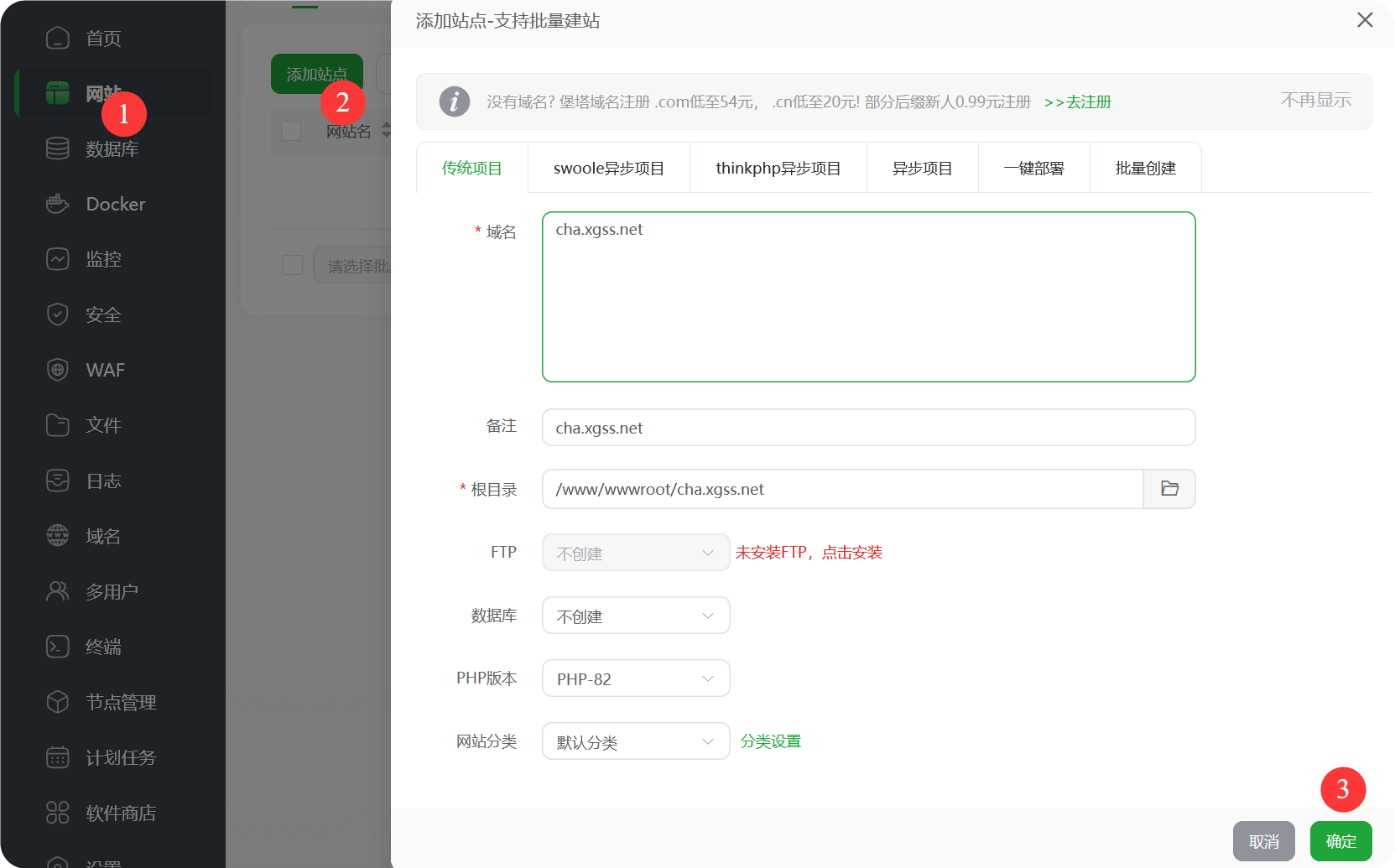
宝塔新建站点
新建站点
使用域名:cha.xgss.net
如图新建站点
上传文件
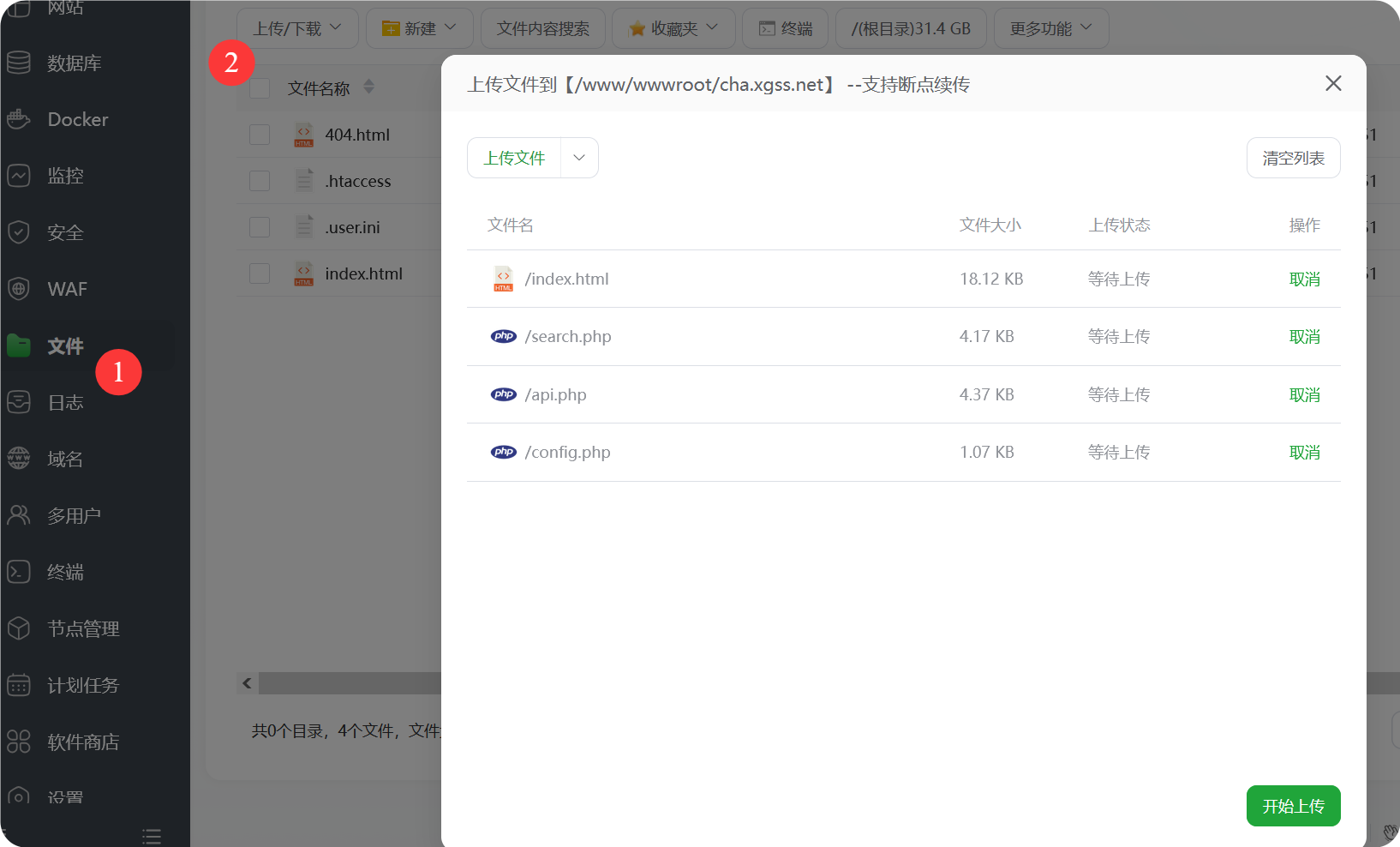
域名解析到轻量云
调试结果
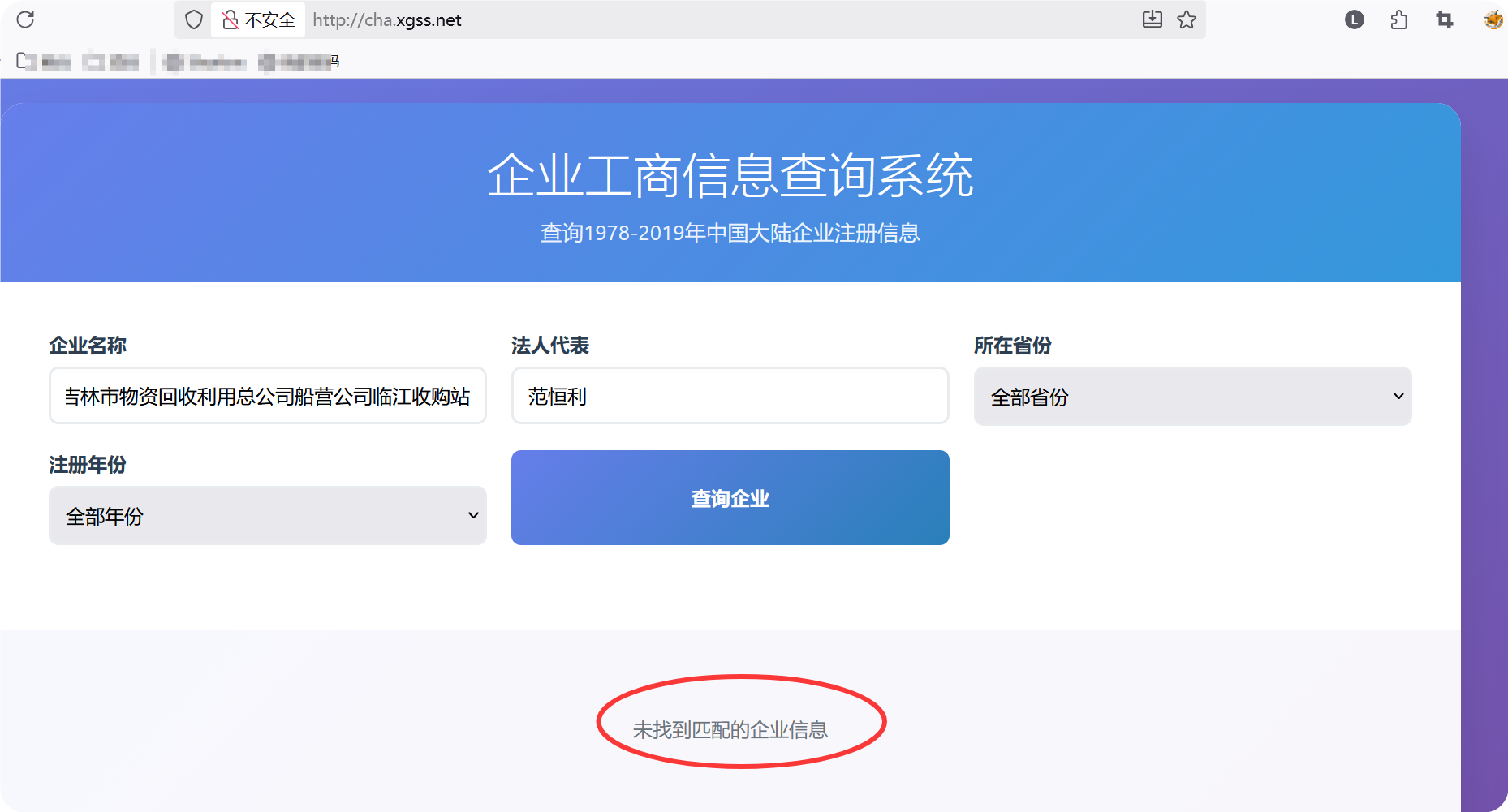
有如下bug
有如下BUG,请帮我解决
1.点击查询按钮数据查不到
2.输入法人代表或者企业名称需要查询到相关信息
把提示词喂给CodeBuddy,让CodeBuddy来调试
应用场景
- 学术研究:经济学、社会学研究者可用来分析企业发展趋势。
- 商业分析:投资人或咨询公司可快速定位目标企业。
- 个人兴趣:普通用户也能一窥中国企业发展的历史脉络。
#CodeBuddy
#CodeBuddyIDE
#CodeBuddyCode
#无界生成力
一点小感想
做这个网站的过程,让我再次体会到:数据只有被激活,才真正有价值。AI不是替代人,而是帮助我们提高效率的工具。
如果你也对这个项目感兴趣,可以去 GitHub 上看看原始数据,或者尝试自己搭建一个查询工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)