MagicTailor: Component-Controllable Personalization in Text-to-Image Diffusion Models
摘要: MagicTailor提出了一种文本到图像扩散模型中的组件可控个性化新任务,支持用户对概念内的单个组件进行细粒度定制。针对语义污染(非期望元素干扰)和语义失衡(学习比例失调)两大挑战,该框架采用动态掩码退化(DM-Deg)自适应扰动无关语义,并通过双流平衡(DS-Bal)实现均衡学习。实验表明,MagicTailor能有效整合目标组件与概念,生成更具创造力的个性化图像。代码已开源,论文发表

标题:MagicTailor:文本到图像扩散模型中的组件可控个性化
原文连接:https://www.ijcai.org/proceedings/2025/1136.pdf
源码连接:https://github.com/Correr-Zhou/MagicTailor
发表:IJCAI-2025
摘要
文本到图像扩散模型能够生成高质量图像,但缺乏对视觉概念的细粒度控制,限制了其创造性。为此,我们提出组件可控个性化这一新任务,允许用户对概念内的单个组件进行定制和重新配置。该任务面临两大挑战:一是语义污染,即非期望元素会干扰目标概念;二是语义失衡,导致模型对目标概念和组件的学习比例失调。为解决这些问题,我们设计了MagicTailor框架,该框架采用动态掩码退化(Dynamic Masked Degradation)自适应地扰动非期望视觉语义,并通过双流平衡(Dual-Stream Balancing)实现对期望视觉语义的更均衡学习。实验结果表明,MagicTailor在该任务中取得了卓越性能,能够支持更具个性化和创造性的图像生成。
1 引言
文本到图像(T2I)扩散模型[Rombach et al., 2022; Ramesh et al., 2022; Chen et al., 2023]已展现出令人瞩目的能力,能够根据文本描述生成高质量图像。尽管这些模型生成的图像能较好地契合给定提示词,但当某些视觉概念难以用自然语言表达时,它们往往表现不佳。为解决这一问题,[Gal et al., 2022; Ruiz et al., 2023]等方法使文本到图像模型能够从参考图像中学习特定概念,从而更准确地将这些概念融入生成的图像中。如图1(a)所示,这一过程被称为个性化。
图1:(a) 个性化:文本到图像模型从参考图像中学习,然后生成预定义的视觉概念。(b) 组件可控个性化(本文方法):文本到图像模型从额外的视觉参考中学习,进而能够将特定组件整合到给定概念中,进一步释放创造力。© MagicTailor生成的图像:MagicTailor能够有效实现组件可控个性化。注:红色圆圈和蓝色圆圈分别表示目标概念和组件。
然而,现有个性化方法仅限于复制预定义概念,缺乏对这些概念的灵活细粒度控制。这一局限阻碍了它们在实际应用中的使用,限制了其创造性表达的潜力。基于“概念通常由多个组件构成”这一观察,个性化的核心问题在于如何有效控制和操纵这些单个组件。
在本文中,我们提出组件可控个性化这一新任务,允许通过额外的视觉参考对个性化概念内的特定组件进行重新配置(图1(b))。在该方法中,文本到图像模型通过参考图像和相应的类别标签进行微调,使其能够学习并生成带有给定组件的期望概念。这种能力使用户能够以精确控制的方式优化和定制概念,在从艺术品到发明创造等多个领域促进创造力和创新。
该任务面临的一个挑战是语义污染(图2(a)),即非期望的视觉元素会不经意地出现在生成图像中,“污染”个性化概念。这是因为文本到图像模型在训练过程中常常会混合不同区域的视觉语义。遮挡参考图像中的非期望元素并不能解决该问题,因为这会破坏视觉上下文并导致非预期的构图。另一个挑战是语义失衡(图2(b)),即模型会过度强调某些方面,导致个性化结果不真实。这是由于概念和组件之间存在语义差异,需要一种更均衡的学习方法来管理概念级(如人物)和组件级(如头发)语义。
图2:组件可控个性化的主要挑战。(a) 语义污染:(i) 非期望元素可能会干扰个性化概念。(ii) 简单的遮挡策略会导致非预期结果,而(iii) 动态掩码退化(DM-Deg)能有效抑制非期望语义。(b) 语义失衡:(i) 同时学习概念和组件可能会导致其中一方失真。(ii) 双流平衡(DS-Bal)确保均衡学习,提升个性化效果。
为解决这些挑战,我们提出了MagicTailor,这一新颖框架能够为文本到图像模型提供组件可控个性化能力(图1©)。我们首先使用文本引导的图像分割器生成概念和组件的分割掩码,然后设计动态掩码退化(DM-Deg)将参考图像转换为随机退化版本,以扰动非期望视觉语义。该方法有助于抑制模型对无关细节的敏感性,同时保留整体视觉上下文,有效缓解语义污染。接下来,我们对文本到图像模型进行预热阶段训练,使用退化图像通过掩码扩散损失(masked diffusion loss)聚焦于期望语义,并通过交叉注意力损失(cross-attention loss)加强这些语义与伪词(pseudo-words)之间的关联。为解决语义失衡问题,我们提出双流平衡(DS-Bal)这一双流学习范式,以平衡视觉语义的学习。在该阶段,在线去噪U-Net(online denoising U-Net)执行样本级极小极大优化(sample-wise min-max optimization),而动量去噪U-Net(momentum denoising U-Net)应用选择性保留正则化(selective preservation regularization)。这确保了目标概念和组件的个性化结果更真实,使输出更符合预期目标。
在实验中,我们通过各种定性和定量比较验证了MagicTailor的优越性,证明其在组件可控个性化任务中达到了当前最优(SOTA)性能。此外,详细的消融实验和分析进一步证实了MagicTailor的有效性。我们还展示了其在广泛创意应用中的潜力。
2 方法
令 I = ( I n k k = 1 K , c n ) n = 1 N I={({I_{nk}}_{k=1}^{K}, c_{n})}_{n=1}^{N} I=(Inkk=1K,cn)n=1N表示概念-组件对,其中包含N个概念和组件样本,每个样本包含K张参考图像 I ˙ n k k = 1 K {\dot{I}_{nk}}_{k=1}^{K} I˙nkk=1K以及对应的类别标签 c n c_{n} cn。在本文中,我们聚焦于包含一个概念和一个组件的实际场景。具体而言,我们设置 N = 2 N=2 N=2,将第一个样本定义为概念(如狗),第二个样本定义为组件(如耳朵)。此外,这些样本与作为文本标识符的伪词 P = p n n = 1 N P={p_{n}}_{n=1}^{N} P=pnn=1N相关联。组件可控个性化的目标是微调文本到图像(T2I)模型,使其能够从I中准确学习概念和组件。利用包含P的文本提示词,微调后的模型应能生成将个性化概念与指定组件整合的图像。
本节首先在2.1节概述MagicTailor的流程,然后在2.2节和2.3节深入介绍其两大核心技术。
2.1 整体流程
MagicTailor的整体流程如图3所示。该过程首先在每张参考图像 I n k I_{nk} Ink中识别期望的概念或组件,利用现成的文本引导图像分割器,基于 I n k I_{nk} Ink及其相关类别标签 c n c_{n} cn生成分割掩码 M n k M_{nk} Mnk。以 M n k M_{nk} Mnk为条件,我们设计动态掩码退化(DM-Deg)来扰动 I n k I_{nk} Ink中的非期望视觉语义,以解决语义污染问题。在每个训练步骤中,动态掩码退化(DM-Deg)将 I n k I_{nk} Ink转换为随机退化图像 I ^ n k \hat{I}_{nk} I^nk,退化强度会动态调整。随后,这些退化图像与结构化文本提示词一起用于微调文本到图像扩散模型,以促进概念和组件的学习。该模型形式化为 ϵ θ , τ θ , E , D {\epsilon_{\theta}, \tau_{\theta}, E, D} ϵθ,τθ,E,D,其中 ϵ θ \epsilon_{\theta} ϵθ表示去噪U-Net, τ θ \tau_{\theta} τθ是文本编码器,E和D分别表示图像编码器和解码器。为促进期望视觉语义的学习,我们采用掩码扩散损失,其定义为:
L d i f f = E n , k , ϵ , t [ ∥ ϵ n ⊙ M n k ′ − ϵ θ ( z n k ( t ) , t , e n ) ⊙ M n k ′ ∥ 2 2 ] , ( 1 ) \mathcal{L}_{diff }=\mathbb{E}_{n, k, \epsilon, t}\left[\left\| \epsilon_{n} \odot M_{nk}'-\epsilon_{\theta}\left(z_{nk}^{(t)}, t, e_{n}\right) \odot M_{nk}'\right\| _{2}^{2}\right],(1) Ldiff=En,k,ϵ,t[
ϵn⊙Mnk′−ϵθ(znk(t),t,en)⊙Mnk′
22],(1)
其中 ϵ n N ( 0 , 1 ) \epsilon_{n} ~ N(0,1) ϵn N(0,1)是未缩放噪声, z n k ( t ) z_{nk}^{(t)} znk(t)是带有随机时间步t的退化图像 I ^ n k \hat{I}_{nk} I^nk的含噪潜变量图像, e n e_{n} en是对应文本提示词的文本嵌入, M n k ′ M_{nk}' Mnk′是从 M n k M_{nk} Mnk下采样得到的,以匹配 ϵ \epsilon ϵ和 z n k z_{nk} znk的形状。此外,我们引入交叉注意力损失以加强期望视觉语义与其对应伪词之间的关联,其公式为:
L a t t n = E n , k , t [ ∥ A θ ( p n , z n k ( t ) ) − M n k ′ ′ ∥ 2 2 ] , \mathcal{L}_{attn }=\mathbb{E}_{n, k, t}\left[\left\| A_{\theta}\left(p_{n}, z_{nk}^{(t)}\right)-M_{nk}''\right\| _{2}^{2}\right], Lattn=En,k,t[
Aθ(pn,znk(t))−Mnk′′
22],
其中 A θ ( p n , z n k ( t ) ) A_{\theta}(p_{n}, z_{nk}^{(t)}) Aθ(pn,znk(t))是伪词 p n p_{n} pn与含噪潜变量图像 z n k ( t ) z_{nk}^{(t)} znk(t)之间的交叉注意力图, M n k ′ ′ M_{nk}^{\prime \prime} Mnk′′是从 M n k M_{nk} Mnk下采样得到的,以匹配 A θ ( p n , z n k ( t ) ) A_{\theta}(p_{n}, z_{nk}^{(t)}) Aθ(pn,znk(t))的形状。
利用 L d i f f L_{diff } Ldiff和 L a t t n L_{attn } Lattn,我们首先对文本到图像模型进行预热训练,通过联合学习所有样本来初步注入视觉语义知识。预热阶段的损失定义为:其中 λ a t t n = 0.01 \lambda_{attn }=0.01 λattn=0.01是 L a t t n L_{attn } Lattn的损失权重。为实现高效微调,我们仅以低秩适配(LoRA)[Hu et al., 2021]的方式训练去噪U-Net ϵ θ \epsilon_{\theta} ϵθ和伪词P的文本嵌入,其余部分保持冻结。之后,我们采用双流平衡(DS-Bal)来解决语义失衡问题。在该范式中,在线去噪U-Net ϵ θ \epsilon_{\theta} ϵθ对最难学习的样本执行样本级极小极大优化,同时动量去噪U-Net ϵ ~ θ \tilde{\epsilon}_{\theta} ϵ~θ对其他样本应用选择性保留正则化。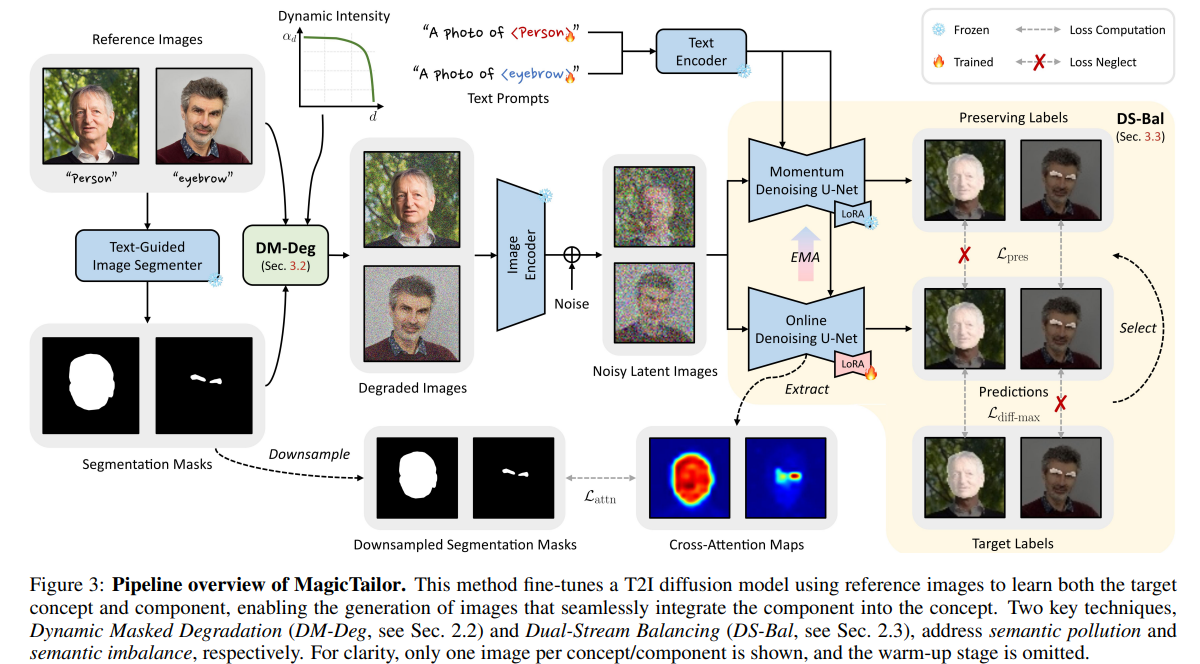
图3:MagicTailor的流程概述。该方法利用参考图像微调文本到图像扩散模型,以同时学习目标概念和组件,从而能够生成将组件无缝整合到概念中的图像。两大核心技术——动态掩码退化(DM-Deg,见2.2节)和双流平衡(DS-Bal,见2.3节)分别用于解决语义污染和语义失衡问题。为清晰起见,每个概念/组件仅展示一张图像,且省略了预热阶段。
2.2 动态掩码退化
语义污染是组件可控个性化面临的重大挑战。如图2(a.i)所示,目标概念(如人物)可能会被目标组件(如眼睛)的所属者干扰,导致生成混合人物图像。遮挡目标概念和组件之外的区域会破坏整体上下文,导致过拟合和不合理的构图(图2(a.ii))。为解决这一问题,必须妥善处理参考图像中的非期望视觉语义。我们提出动态掩码退化(DM-Deg),该方法动态扰动非期望语义,以抑制其对文本到图像模型的影响,同时保留整体视觉上下文(图2(a.iii))。
退化施加
在每个训练步骤中,动态掩码退化(DM-Deg)在每张参考图像的掩码外区域施加退化。我们采用高斯噪声进行退化,因其实现简单。对于参考图像 I n k I_{nk} Ink,我们随机采样一个与 I n k I_{nk} Ink形状相同的高斯噪声矩阵 G n k N ( 0 , 1 ) G_{nk} ~ N(0,1) Gnk N(0,1),其中 I n k I_{nk} Ink的像素值范围为-1至1。退化施加方式如下:其中 ⊙ \odot ⊙表示逐元素乘法, α d ∈ \alpha_{d} \in αd∈ [0, 1]是控制退化强度的动态权重。尽管已有研究[Xiao et al., 2023; Li et al., 2023]使用噪声完全覆盖背景或增强数据多样性,但动态掩码退化(DM-Deg)的目标是生成保留原始视觉上下文的退化图像 I ^ n k \hat{I}_{nk} I^nk。通过引入 I ^ n k \hat{I}_{nk} I^nk,可以抑制文本到图像模型感知掩码外区域的非期望视觉语义,因为这些语义在每个训练步骤都会被随机噪声扰动。
动态强度
遗憾的是,文本到图像模型在学习有意义的视觉语义时,可能会逐渐记住引入的噪声,导致生成图像中出现噪声(图4(a))。这一现象与已有关于深度网络的观察结果一致[Arpit et al., 2017]。为解决这一问题,我们提出一种衰减方案,在训练过程中动态调整施加噪声的强度。该方案遵循指数曲线,在训练初期保持较高强度,在后期快速衰减。令d表示当前训练步骤,D表示总训练步骤。动态强度曲线定义为:
α d = α i n i t ( 1 − ( d D ) γ ) , \alpha_{d}=\alpha_{init }\left(1-\left(\frac{d}{D}\right)^{\gamma}\right), αd=αinit(1−(Dd)γ),
其中 α i n i t \alpha_{init } αinit是 α d \alpha_{d} αd的初始值, γ \gamma γ控制衰减速率。我们通过实验设置 α i n i t = 0.5 \alpha_{init }=0.5 αinit=0.5, γ = 32 \gamma=32 γ=32(在2的幂次范围内调优)。这种动态强度方案有效防止了语义污染,并显著减轻了对引入噪声的记忆,从而提升了生成性能(图4(b))。
图4:动态强度的设计动机。(a) 固定强度(此处 α d = 0.5 \alpha_{d}=0.5 αd=0.5)可能导致生成图像含噪。(b) 我们提出的动态强度能够减轻噪声记忆问题。
2.3 双流平衡
另一个核心挑战是语义失衡,这源于目标概念与其组件之间的视觉语义差异。具体而言,概念通常比组件具有更丰富的视觉语义(如人物vs.头发),但在某些情况下,组件可能具有更复杂的语义(如简单的塔楼vs.复杂的屋顶)。这种失衡使联合学习变得复杂,导致模型过度强调概念或组件中的一方,进而生成不连贯的图像(图5(a))。为解决这一问题,我们设计了双流平衡(DS-Bal),这一双流学习范式整合了在线去噪U-Net和动量去噪U-Net(图3),用于均衡语义学习,旨在提升个性化保真度(图5(b))。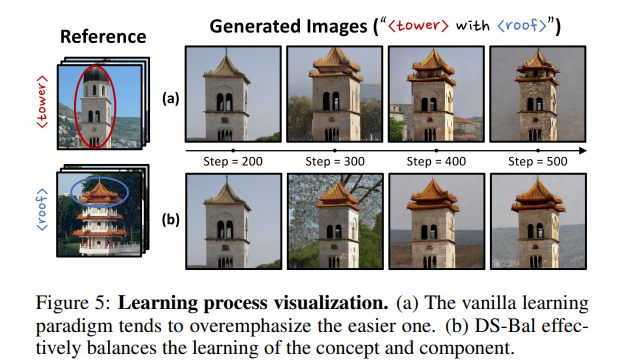
图5:学习过程可视化。(a) 传统学习范式倾向于过度强调较易学习的一方。(b) 双流平衡(DS-Bal)有效平衡了概念和组件的学习。
样本级极小极大优化
从损失角度来看,概念和组件的视觉语义是通过优化所有样本的掩码扩散损失 L d i f f L_{diff } Ldiff来学习的。然而,这种无差别优化无法为更具挑战性的样本分配足够的学习资源,导致学习过程失衡。为解决这一问题,双流平衡(DS-Bal)利用在线去噪U-Net在每个训练步骤聚焦于学习最难学习的样本。在线去噪U-Net ϵ θ \epsilon_{\theta} ϵθ继承了通过联合学习预热后的原始去噪U-Net权重,仅优化掩码扩散损失最高的样本,其公式为: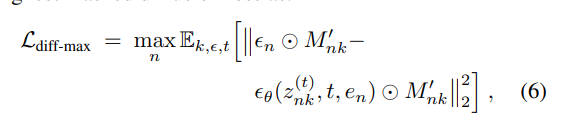
其中最小化 L d i f f − m a x L_{diff-max } Ldiff−max可被视为一种极小极大优化形式[Razaviyayn et al., 2020]。 ϵ θ \epsilon_{\theta} ϵθ的学习目标可能在不同训练步骤之间切换,不会始终被概念或组件主导。这种优化方案能够有效调节多个样本的学习动态,避免过度强调任何单一样本。
选择性保留正则化
在某个训练步骤中,被 L d i f f − m a x L_{diff-max } Ldiff−max忽略的样本可能会遭遇知识遗忘。这是因为 L d i f f − m a x L_{diff-max } Ldiff−max的优化目标是增强特定样本的知识,可能会不经意地掩盖其他样本的知识。有鉴于此,双流平衡(DS-Bal)同时利用动量去噪U-Net ϵ ~ θ \tilde{\epsilon}_{\theta} ϵ~θ在每个训练步骤中保留其他样本的已学习视觉语义。具体而言,我们首先选择在 L d i f f − m a x L_{diff-max } Ldiff−max中被排除的样本,其表示为 S = n ∣ n = 1 , . . . , N − n m a x S={n | n=1, ..., N}-{n_{max }} S=n∣n=1,...,N−nmax,其中 n m a x n_{max } nmax是 L d i f f − m a x L_{diff-max } Ldiff−max中目标样本的索引,S是所选索引集。然后,我们使用 ϵ ~ θ \tilde{\epsilon}_{\theta} ϵ~θ对S应用正则化,掩码保留损失定义为:
L p r e s = E n ∈ S , k , t [ ∥ ϵ ‾ θ ( z n k ( t ) , t , e n ) ⊙ M n k ′ − ϵ θ ( z n k ( t ) , t , e n ) ⊙ M n k ′ ∥ 2 2 \begin{aligned} \mathcal{L}_{pres }=\mathbb{E}_{n \in S, k, t}[ & \| \overline{\epsilon}_{\theta}\left(z_{nk}^{(t)}, t, e_{n}\right) \odot M_{nk}'- \\ & \left.\epsilon_{\theta}\left(z_{nk}^{(t)}, t, e_{n}\right) \odot M_{nk}'\right\| _{2}^{2} \end{aligned} Lpres=En∈S,k,t[∥ϵθ(znk(t),t,en)⊙Mnk′−ϵθ(znk(t),t,en)⊙Mnk′
22
其中 ϵ ˉ θ \bar{\epsilon}_{\theta} ϵˉθ通过指数移动平均(EMA)[Tarvainen and Valpola, 2017]从 ϵ θ \epsilon_{\theta} ϵθ更新而来,平滑系数 β = 0.99 \beta=0.99 β=0.99,从而在每个训练步骤中维持 ϵ θ \epsilon_{\theta} ϵθ先前积累的知识。通过在 L p r e s L_{pres } Lpres中鼓励 ϵ θ \epsilon_{\theta} ϵθ和 ϵ ˉ θ \bar{\epsilon}_{\theta} ϵˉθ输出的一致性,我们能够在 L d i f f − m a x L_{diff-max } Ldiff−max中学习特定样本的同时,促进其他样本的知识保留。总体而言,双流平衡(DS-Bal)可被视为一种机制,为不同样本自适应分配目标标签 ϵ n \epsilon_{n} ϵn或保留标签 ϵ ˉ θ ( z n k ( t ) , t , e n ) \bar{\epsilon}_{\theta}(z_{nk}^{(t)}, t, e_{n}) ϵˉθ(znk(t),t,en),实现动态损失监督(图3)。设置损失权重 λ p r e s = 0.2 \lambda_{pres }=0.2 λpres=0.2,双流平衡(DS-Bal)阶段的总损失公式为:
3 实验结果
3.1 实验设置
数据集、实现与评估
为进行系统性研究,我们从人物、动画、建筑、物体和动物等多个领域收集了数据集。我们采用Stable Diffusion(SD)2.1[Rombach et al., 2022]作为预训练文本到图像模型。在预热阶段和双流平衡(DS-Bal)阶段,我们分别设置训练步数为200和300,学习率分别为 1 × 1 0 − 4 1 ×10^{-4} 1×10−4和 1 × 1 0 − 5 1 ×10^{-5} 1×10−5。每个概念-组件对在A100 GPU上的训练时间约为5分钟。在评估方面,我们设计了20个涵盖多种场景的文本提示词,为每种方法生成14720张图像。为确保公平性,训练和推理过程中的所有随机种子均固定。实验设置的更多细节见附录A。
对比方法
我们将MagicTailor与多种个性化方法进行对比,包括Textual Inversion(TI)[Gal et al., 2022]、DreamBooth(DB)[Ruiz et al., 2023]、Custom Diffusion(CD)[Kumari et al., 2023]、Break-A-Scene(BAS)[Avrahami et al., 2023]以及CLiC[Safaee et al., 2024]。选择这些方法是因为它们代表了主流个性化框架,或与细粒度元素学习相关。为保证公平对比,我们对这些方法进行了最小化修改以适配我们的任务,具体而言是引入了掩码扩散损失(公式1)。除方法特定配置外,所有方法均采用相同设置实现,以确保一致性。
3.2 定性比较
定性结果如图6所示。可以观察到,TI、CD和CLiC主要受语义污染影响,非期望视觉语义会严重扭曲个性化概念。此外,DB和BAS在这一具有挑战性的任务中也表现不佳,由于语义失衡,它们会过度强调概念或组件中的一方,有时甚至导致目标组件完全缺失。一个有趣的发现是,失衡学习会加剧语义污染,导致目标概念或组件的颜色和纹理被错误地迁移到生成图像的非预期部分。相比之下,MagicTailor能够有效生成与文本对齐的图像,准确呈现目标概念和组件。为进一步展示MagicTailor的性能,附录B提供了更多对比结果。
图6:定性比较。我们展示了MagicTailor与其他方法在多个领域生成的图像。MagicTailor在文本对齐、身份保真度和生成质量方面表现更优。由于篇幅限制,请放大查看以获得更佳效果。更多结果见附录D。
3.3 定量比较
自动指标
我们从文本对齐(CLIP-T[Gal et al., 2022])和身份保真度(CLIP-I[Radford et al., 2021]、DINO[Oquab et al., 2023]、DreamSim[Fu et al., 2023])两个维度,采用四种自动指标进行评估。为精确衡量身份保真度,我们对每张参考图像和评估图像中的概念与组件进行分割,并从分割后的概念中剔除目标组件。如表1所示,即使对于当前最优的个性化方法,组件可控个性化仍然是一项艰巨的任务。相比之下,MagicTailor在身份保真度和文本对齐方面均取得了最佳结果,这得益于其为该特定任务量身设计的高效框架。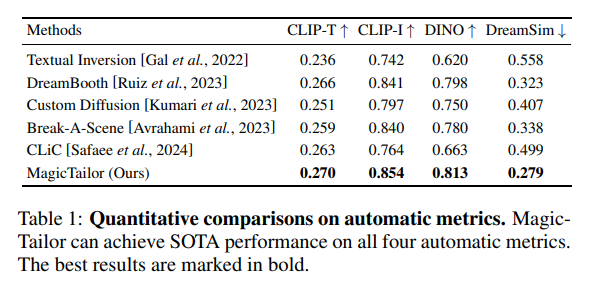
(表1:自动指标定量比较。MagicTailor在所有四种自动指标上均达到当前最优(SOTA)性能。最佳结果以粗体标注。)
用户研究
我们通过用户研究进一步评估各方法。具体而言,我们设计了详细的问卷,展示20组评估图像以及对应的文本提示词和参考图像。要求用户从每组图像中,针对文本对齐、身份保真度和生成质量三个维度选择最佳结果。最终,我们收集到3180份有效回答,并在表2中报告了各方法的被选率。结果显示,MagicTailor在人类偏好方面也表现出优越性,进一步验证了其有效性。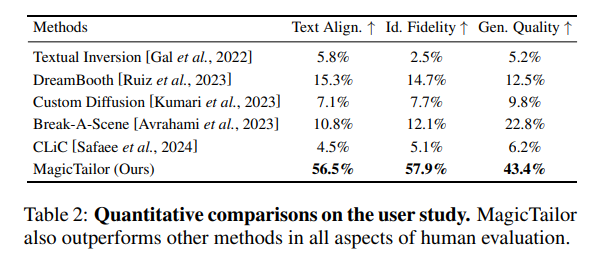
(表2:用户研究定量比较。MagicTailor在人类评估的所有维度上均优于其他方法。)
3.4 消融研究与分析
我们对MagicTailor进行了全面的消融研究与分析,以验证其性能。更多消融研究与分析内容见附录C。
关键技术有效性
在表3中,我们基于2.1节描述的基线框架,对两种关键技术(动态掩码退化DM-Deg和双流平衡DS-Bal)的效果进行了研究。即使不使用DM-Deg和DS-Bal,该基线框架仍能取得具有竞争力的性能,证明了其可靠性。在此基础上引入DM-Deg和DS-Bal后,模型实现了更优的性能权衡,表明这两项技术的重要性。定性结果可参考图2。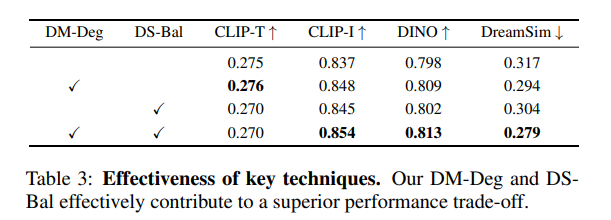
(表3:关键技术有效性。我们提出的DM-Deg和DS-Bal有效实现了更优的性能权衡。)
不同骨干网络兼容性
MagicTailor是一种模型无关的方法,因此可与其他文本到图像扩散模型结合使用。如图7所示,我们将MagicTailor应用于SD 1.5[Rombach et al., 2022]和SDXL[Podell et al., 2023]等其他骨干网络,结果表明MagicTailor仍能取得优异性能。值得注意的是,我们直接使用原始超参数值,未进行额外调优,这体现了MagicTailor的泛化能力。
图7:不同骨干网络兼容性。我们将MagicTailor与SD 1.5[Rombach et al., 2022]、SD 2.1[Rombach et al., 2022]和SDXL[Podell et al., 2023]结合。结果表明,MagicTailor可推广到多种骨干网络,且更优的骨干网络能带来更优的生成质量。
损失权重鲁棒性
在图8中,我们分析了公式8中损失权重(即 λ p r e s \lambda_{pres } λpres和 λ a t t n \lambda_{attn } λattn)的敏感性,因为损失权重通常对模型训练至关重要。可以看到,当 λ p r e s \lambda_{pres } λpres和 λ a t t n \lambda_{attn } λattn在合理范围内变化时,MagicTailor始终能达到当前最优性能,这表明其在这些超参数上具有鲁棒性。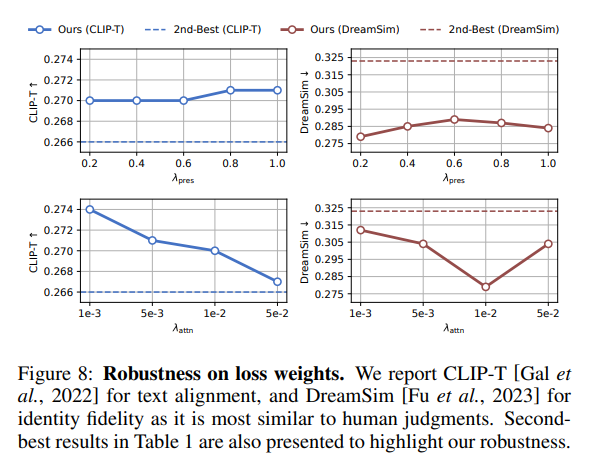
图8:损失权重鲁棒性。我们采用CLIP-T[Gal et al., 2022]评估文本对齐性能,采用DreamSim[Fu et al., 2023]评估身份保真度(因其与人类判断最接近)。同时展示表1中的次优结果,以突出我们方法的鲁棒性。
不同参考图像数量性能
在图9中,我们通过减少参考图像数量来分析性能变化。即使参考图像数量较少,MagicTailor仍能呈现令人满意的结果。虽然更多参考图像可提升模型的泛化能力,但对于MagicTailor而言,每个概念/组件仅需1张参考图像即可获得良好结果。
图9:不同参考图像数量性能。我们通过定性结果表明,当每个概念和组件仅提供1张或2张参考图像时,MagicTailor仍能取得满意性能。
复杂提示词泛化能力
在之前的对比中,我们使用分类清晰的文本提示词进行系统性评估。此处,我们进一步评估MagicTailor在包含更复杂上下文的复杂文本提示词上的性能。如图11所示,MagicTailor在进行保真度个性化时,能有效生成与文本对齐的图像,证明其能够满足多样化的用户需求。
困难对泛化能力
我们进一步评估MagicTailor在困难概念-组件对(简称“困难对”)上的性能,重点关注两种情况:1)几何差异较大的情况,例如“上身肖像中的人物”与“侧面照片中的头发”;2)跨领域交互的情况,例如“人物”与“狗的耳朵”。如图12所示,即使面对这些困难情况,MagicTailor仍能有效对目标概念和组件进行个性化,且具有较高保真度。
图11:复杂提示词泛化能力。我们展示了使用复杂文本提示词生成的定性结果。除分类清晰的文本提示词外,MagicTailor也能遵循更复杂的提示词生成与文本对齐的图像。
图12:困难对泛化能力。我们展示了两种困难情况(几何差异较大和跨领域交互)的结果,表明MagicTailor能有效处理此类具有挑战性的场景。
3.5 进一步应用
解耦生成
在学习概念-组件对后,MagicTailor还能实现解耦生成。如图10(a)所示,MagicTailor可在多种甚至跨领域的上下文中,分别生成目标概念和组件。这得益于其捕捉不同层级视觉语义的出色能力,该能力拓展了概念与组件之间可能组合的灵活性。
多组件控制
本文中,我们聚焦于单一概念和单一组件的个性化,因为这种设置已能覆盖大量场景,且可通过迭代过程进一步扩展到多组件重新配置。然而,如图10(b)所示,MagicTailor也展现出同时控制两个组件的潜力。如何处理更多组件,以实现对单一概念中多种元素的更优控制,仍是未来值得探索的方向。
图10:MagicTailor的进一步应用。(a) 解耦生成:MagicTailor可分别生成目标概念和组件,丰富潜在的组合方式。(b) 多组件控制:MagicTailor展现出处理不止一个组件的潜力,凸显其有效性。© 增强其他生成工具:MagicTailor可与多种生成工具无缝集成,为它们的生成流程增添组件控制能力。
增强其他生成工具
如图10©所示,我们展示了MagicTailor如何增强ControlNet[Zhang et al., 2023]、CSGO[Xing et al., 2024]和InstantMesh[Xu et al., 2024]等其他生成工具。MagicTailor可与之无缝集成,为这些工具的流程增添概念组件控制能力。例如,与MagicTailor结合后,InstantMesh可便捷地实现细粒度3D网格设计,体现了MagicTailor在更多创意应用中的实用性。
4 结论
我们提出了组件可控个性化这一任务,能够对概念内的单个组件进行精确定制。所提出的 MagicTailor 框架采用动态掩码退化(DM-Deg)抑制非期望语义,通过双流平衡(DS-Bal)确保均衡学习。实验表明,MagicTailor 为该任务设立了新的标准,并在创意应用方面展现出良好前景。未来,我们计划将该方法扩展到更广泛的图像和视频生成领域,实现对多层级视觉语义的更精细控制,以增强创意生成能力。
思考:
生成的图片与原始图出现不一致的现象,比如左图中人物的肤色,发型,右图中塔的颜色。这种情况是不是因为细节的丢失所导致的?我之前有了解过虚拟试衣的任务,需要尽可能地保留原始图片的人物和衣服的细节信息。在这篇虚拟试衣的论文中,作者认为是因为注意力在空间上没有聚焦于正确区域导致的,所以出现细节丢失的问题。论文中,把原始图特征和参考图特征进行点乘得到注意力图,然后与位置坐标图加权,让模型关注正确的位置。从空间位置的角度上考虑可能是可以尝试的。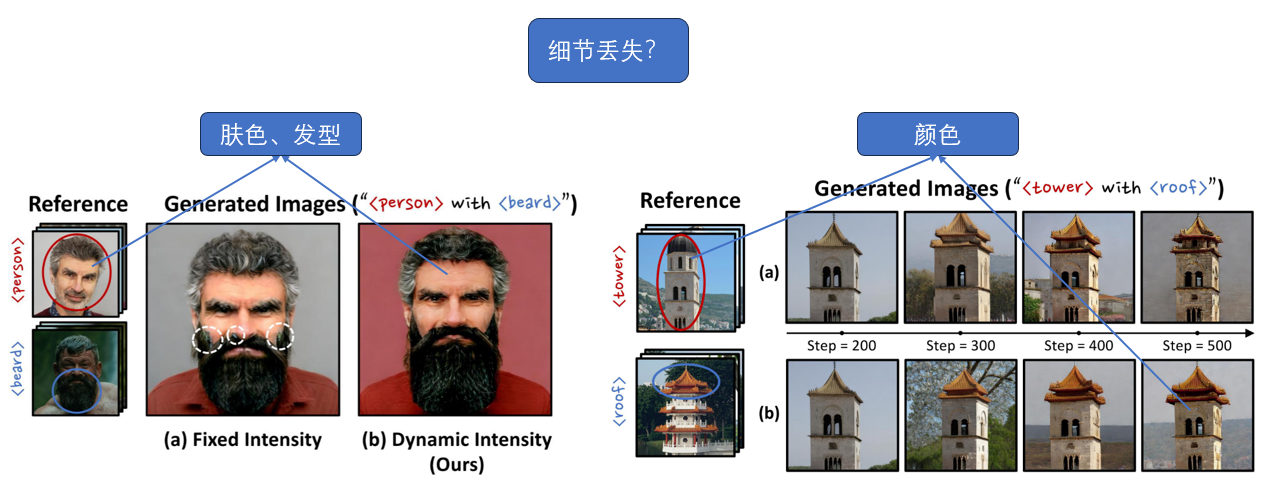

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)