Langfuse-GitHub 上星标最多的开源 LLMOps 工具
Langfuse是一款开源LLM工程平台,专注于AI应用全生命周期管理,包括开发、监控、评估和调试。其核心优势在于轻量化部署(几分钟内完成自托管)和实战可靠性,已在大量实际场景中验证。平台提供三大核心功能:可观测性(Trace/Session/User三级追踪)、提示词管理(版本控制/动态拉取)和自动化评估(LLM-as-a-Referee评分)。技术栈采用NextJS14前端+PostgreSQ
项目简介
Langfuse 是一个开源 LLM 工程平台,专注于帮助团队协作完成 AI 应用的全生命周期管理,包括开发、监控、评估及调试。其核心优势在于轻量化部署(可在几分钟内完成自托管)和实战可靠性,已在大量实际场景中得到验证。
平台涵盖的主要领域
-
可观测性:查看 LLM 运行时发生的情况。追踪成本、发现错误并了解用户如何与您的应用交互。无需再猜测故障原因或 OpenAI 上个月向您收取了多少费用。
-
提示管理:将所有提示集中存储并进行版本控制,而不是分散在代码库各处。您的团队无需修改生产代码即可测试不同版本。
-
评估:衡量您的学习领导力模型 (LLM) 的性能。设置自动化测试,检查回复是否合理、是否切题或是否符合质量标准。
开源代码地址
https://github.com/langfuse/langfuse
项目技术栈
-
前端与框架:
-
NextJS 14(基于 pages router)
-
tRPC:用于前端 API 通信
-
Tailwind CSS:样式框架
-
shadcn/ui 组件库(基于 Radix 和 tanstack)
-
NextAuth.js/ Auth.js:身份认证
-
-
后端与数据处理:
-
Prisma ORM:数据库对象关系映射
-
Zod v4:类型验证
-
Fern:生成 OpenAPI 规格和 Pydantic 模型
-
-
基础设施与存储
-
数据库:
-
Postgresql(主数据库):用于事务性数据(OLTP)
-
Clickhouse(分析数据库):用于可观测性数据(OLAP)
-
-
缓存与队列:Redis / Valkey
-
存储:S3(如minio) / Blob Storage(用于原始事件、多模态附件等)
备注:Langfuse 的数据库架构(PostgreSQL + ClickHouse)是其设计的核心部分,深度依赖两者的特性,官方未提供对 类似MySQL 或其他数据库的支持。若强行替换,需进行大量定制开发,可能导致功能不稳定或性能下降,因此不建议更换。
langfuse SDK(支持的语言)
-
JS/TypeScript SDK(langfuse/langfuse-js)
-
Python SDK(langfuse/langfuse-python)
核心功能
可观测性
Langfuse 的可观测性与可追踪性,核心是为 LLM 应用提供全链路、可视化的运行状态监控方案,解决传统日志无法覆盖的 LLM 专属需求,适配复杂场景的调试与优化。
-
弥补传统日志短板:传统日志仅能记录函数是否运行,无法捕捉 LLM 应用的关键细节(如文档检索是否准确、提示词格式是否合规、哪个中间步骤耗时)。
-
适配复杂架构:针对生产级 RAG 等多步骤场景(文档加载、分块、多检索器、重排、生成),实现全链路无遗漏追踪。
可追踪性的核心价值
-
高效调试:快速定位错误根源(如检索错误、提示词格式问题),替代 “猜测式排查”。
-
性能优化:精准识别 latency 瓶颈(嵌入查询、向量搜索、LLM 调用等环节)。
-
成本管控:实时追踪单个模型调用的具体成本,便于预算管理。
-
评估支撑:为 LLM 应用效果评估提供数据基础。
-
客服提效:通过会话快速还原用户问题场景,节省排查时间。
三大维度
Langfuse 的可观测性能力包含三个层级的追踪体系,实现了从单轮执行到多轮对话再到用户全局行为的全维度覆盖:
-
Trace(单轮执行追踪):聚焦单条 LLM 请求的完整执行链路,记录从输入、中间步骤到输出的全量数据,包括层级化执行树、耗时分布、Token 与成本消耗等细节,为单轮问题的根因分析提供颗粒度最细的依据。
-
Session(多轮对话追踪):将同一上下文的关联请求(如用户的多轮连续问答)聚合为会话,还原完整对话逻辑,解决 “单轮 Trace 孤立无关联” 的问题,便于复盘用户多轮交互中的行为模式与问题。
-
User(用户维度追踪):基于用户唯一 ID 聚合其所有 Session 和 Trace,实现 “用户 - 对话 - 单轮执行” 的三层关联,支持从用户视角全局分析行为特征、问题分布,是面向真实业务场景(如用户留存、个性化优化)的顶层观测维度。
追踪(Traces):单轮问答的完整执行记录
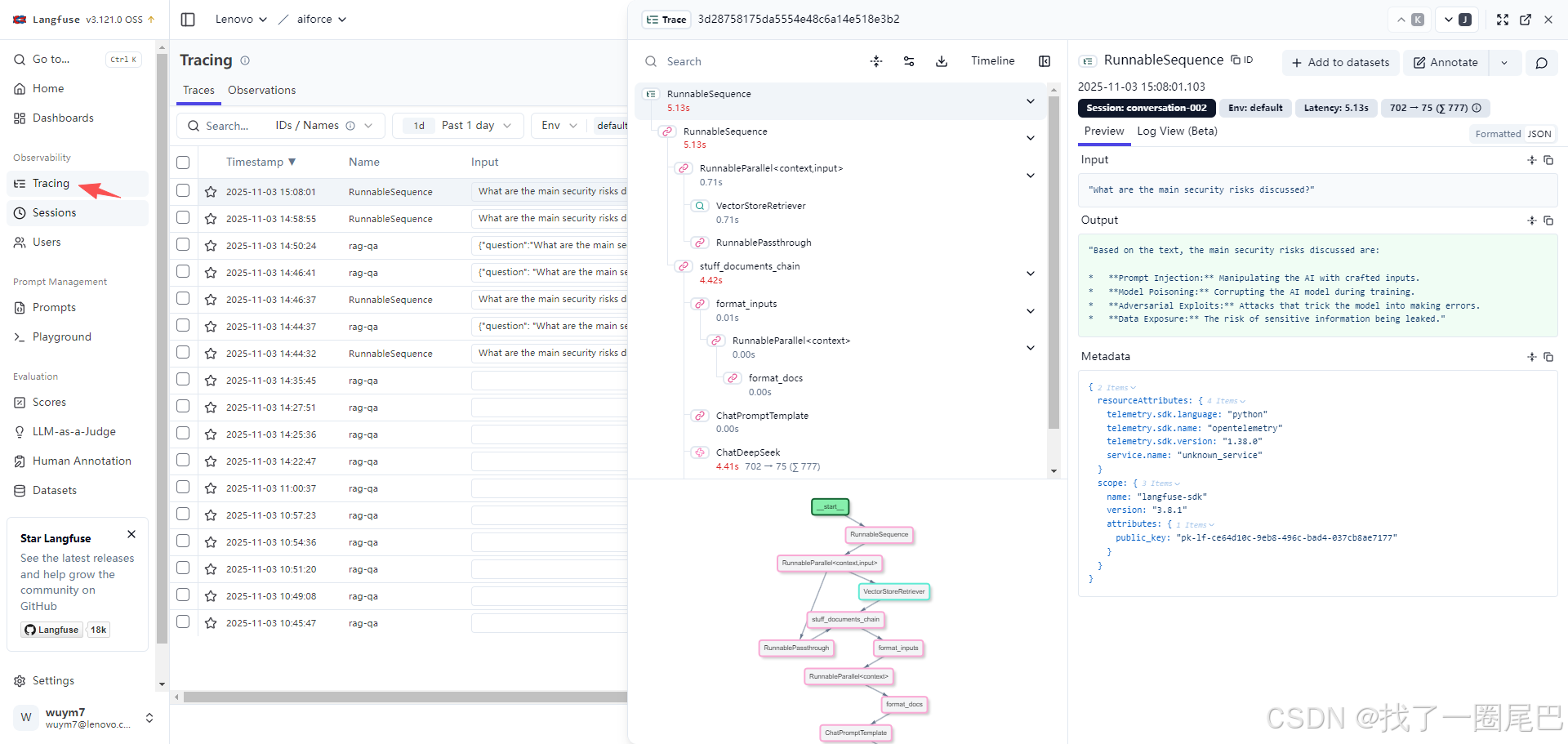
langfuse Tracing页面展示
-
层级化执行树:展示从根节点(如 retrieval_chain)到子步骤(文档检索、向量搜索、答案生成)的层级关系,明确各步骤耗时。
-
关键指标可视化:直接呈现 latency(总耗时)、单调用成本、Token 使用量(输入 / 输出分别统计)。
-
全量数据留存:包含输入输出内容、中间结果(如检索到的文档片段),以及多分支复杂链的流程图。
会话(Sessions):多轮对话的追踪聚合
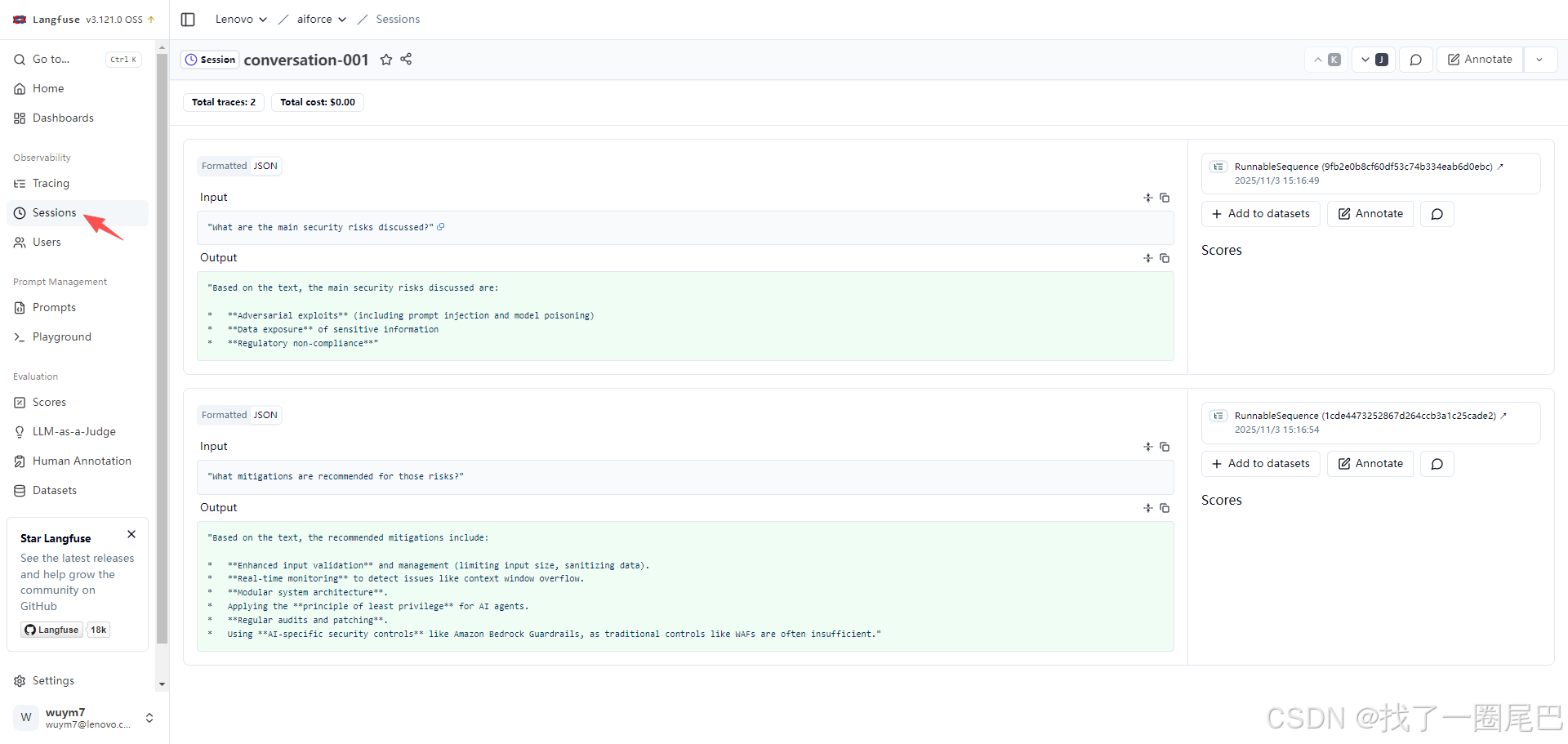
langfuse sessions 页面展示
-
核心作用:将同一用户的关联对话(如 3 个相关的安全风险问题)对应的多个 Traces 分组,形成完整对话线程。
-
价值:用户反馈问题时,可通过会话复盘全部交互过程,无需单独查看零散追踪。
用户追踪(Tracking users):用户维度的数据组织能力
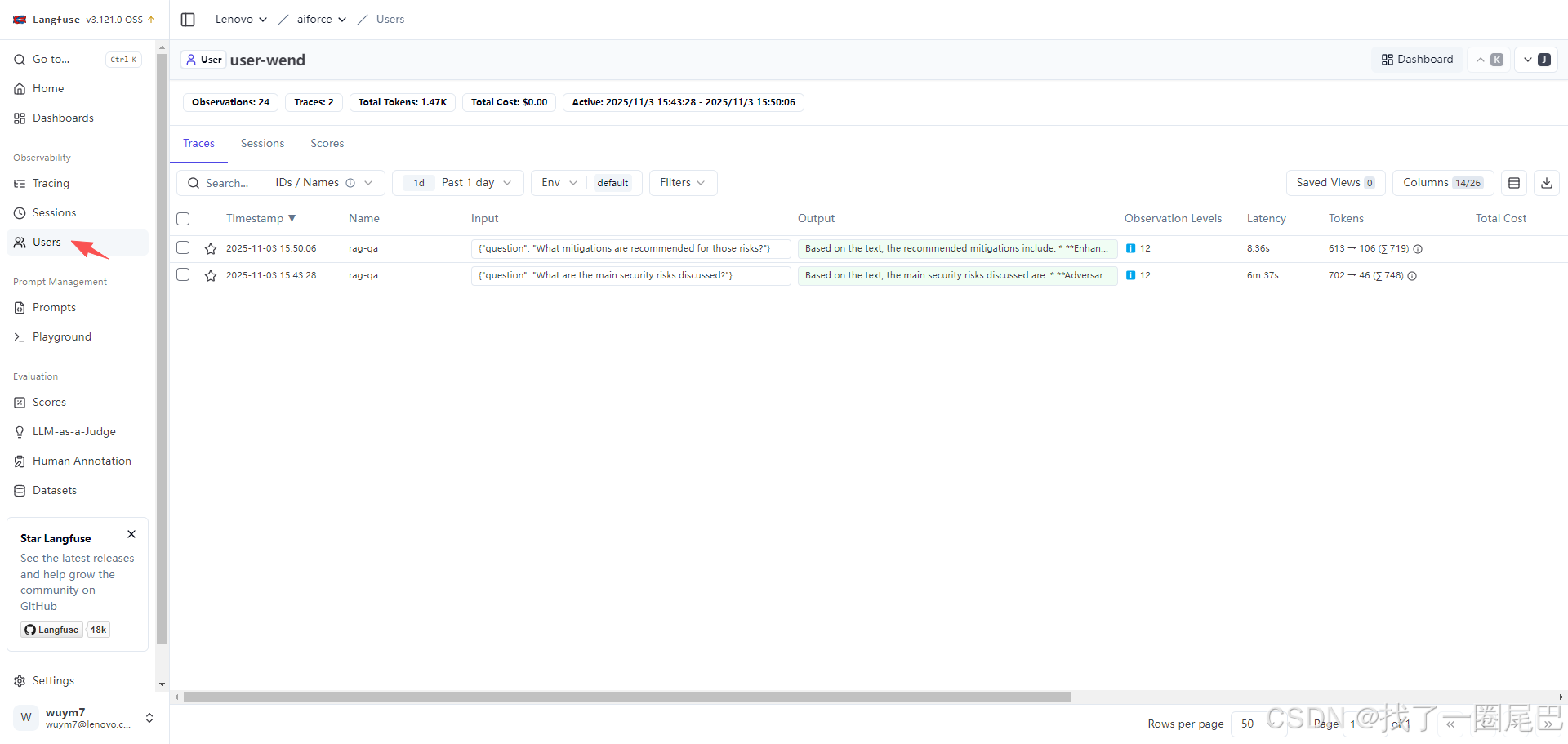
langfuse 用户追踪页面展示
Langfuse 的用户追踪是在会话(Sessions)追踪基础上,新增的 “用户维度” 数据组织能力,核心是关联单个用户与他们的所有 LLM 应用请求,适配真实应用的用户级观测需求。
核心目的:真实 LLM 应用需要明确 “哪个用户发起了哪些请求”,用户追踪正是为了建立 “用户 ID - 相关请求 - 会话 - 追踪(Traces)” 的关联链路,让观测数据能按用户维度聚合。
实现方式:
-
给每个注册用户生成唯一用户 ID。
-
将该唯一 ID 附加到该用户发起的每一次 LLM 调用中,实现用户与请求的绑定。
核心价值:
-
补充数据组织维度:在 “会话分组” 之外,新增 “用户分组”,可按用户 ID 筛选其所有会话和追踪记录。
-
精准定位用户问题:当用户反馈使用问题时,能通过用户 ID 快速调取该用户的全部交互数据(所有会话、单轮追踪),全面复盘其使用场景。
简单代码示例
from build_chain import build_qa_chain
from langfuse.langchain import CallbackHandler
# Build the Q&A chain
qa_chain = build_qa_chain()
# Set up LangFuse handler
langfuse_handler = CallbackHandler()
# Simulate a new user asking a question
user_response = qa_chain.invoke(
{"input": "What security controls are recommended for AI systems?"},
config={
"callbacks": [langfuse_handler], # langchain 框架的接入方式
"metadata": {
"langfuse_session_id": "conversation-003", # 接入会话追踪
"langfuse_user_id": "user-12345" # 接入用户追踪
}
}
)
print(f"Response: {user_response['answer']}")提示词管理
在 LLM 驱动的应用(如问答系统、智能助手)中,提示词是连接业务逻辑与模型能力的核心桥梁。然而,传统 “硬编码提示词” 的方式,正成为团队迭代效率、协作体验与生产稳定性的瓶颈。Langfuse 推出的提示词管理功能,通过 “将提示词视为数据而非代码” 的核心理念,彻底解决了这一痛点,为 LLM 应用的全生命周期管理提供了完整方案。
传统硬编码提示词的四大痛点
在 solo 开发或小型项目中,将提示词直接写在代码里(如 qa_chain.py)或许可行,但进入团队协作或生产环境后,问题会集中爆发:
-
部署摩擦:改提示词 = 重部署:若想调整提示词表述(比如将 “保持回答简洁” 改为 “简洁且符合事实”),需修改代码、本地测试、提交 Git、触发部署流程 —— 整个过程耗时且繁琐,无法快速响应业务需求。更关键的是,A/B 测试不同提示词版本时,必须改动应用代码,成本极高。
-
版本失控:无法关联 “效果与版本”:Git 虽能追踪代码变更,却无法直观展示 “哪个提示词版本在生产中表现更好”。你看不到 “prompt v1” 与 “prompt v2” 的 Token 消耗、响应 latency、用户满意度差异,也无法快速回滚到上周的稳定版本(除非翻阅复杂的 Git 历史并重新部署)。
-
团队瓶颈:非技术角色无法参与:产品经理、运营等非技术人员常能提出更贴合用户的提示词优化思路,但因提示词嵌在代码中,他们必须依赖工程师修改 —— 这不仅拉长了迭代周期,也限制了 “提示词工程” 的协作广度。
-
测试困难:多版本对比需手动操作:若想测试 “简洁回答” 与 “详细回答” 两种提示词的效果,需运行多版代码、手动记录结果,无法在统一界面中直观对比输出差异,效率低下且易出错。
Langfuse 提示词管理:核心理念与价值
Langfuse 针对上述痛点,提出了 “提示词全生命周期管理” 方案,核心是将提示词从代码中剥离,集中存储、版本化管理、动态拉取。这一设计带来三大核心价值:
-
迭代无代码依赖:更新提示词无需修改应用代码,通过 UI 即可完成,秒级生效;
-
协作无角色壁垒:非技术人员可在可视化界面中编辑、测试提示词,无需接触代码;
-
效果可追溯:自动关联提示词版本与生产数据(如 Token 成本、 latency、用户反馈),支持版本对比与快速回滚。
Langfuse 提示词管理的核心功能
Langfuse 围绕 “创建 - 版本 - 测试 - 使用” 的流程,打造了一套易用且强大的功能体系。
1. 自动版本控制与标签管理:精准控制生产与测试
Langfuse 会为每一次提示词编辑自动生成版本(如 v1、v2、v3),旧版本永久保留,支持随时回溯。同时,通过 “标签(Label)” 机制,可灵活管理不同环境的提示词版本:
-
production:生产环境使用的稳定版本,应用代码默认拉取该标签对应的提示词; -
staging:预发布环境测试版本,验证通过后可直接将标签迁移到新版本; -
latest:系统自动维护的 “最新版本” 标签,适合快速迭代的测试场景。
例如,当你优化提示词后,可先将 staging 标签指向新版本,在预发布环境验证效果;确认无误后,只需将 production 标签迁移到该版本,生产应用会自动拉取更新 —— 全程无需修改一行代码。
2. 可视化 Playground:测试与对比更高效
Langfuse 内置 “提示词 playground”,解决了 “手动测试繁琐” 的问题。在 Playground 中,你可以:
-
快速填充
{{context}}、{{input}}等变量,预览提示词编译后的效果; -
同时加载多个提示词版本(如 v1 与 v3), side-by-side 对比模型输出差异;
-
分享测试结果给团队成员,同步讨论优化方向。
这一功能让非技术人员也能独立完成提示词测试,极大提升了协作效率。
3. 多方式创建:适配不同开发场景
Langfuse 支持通过 UI 或 SDK 两种方式创建提示词,满足不同团队的工作流:
(1)UI 创建:零代码快速上手
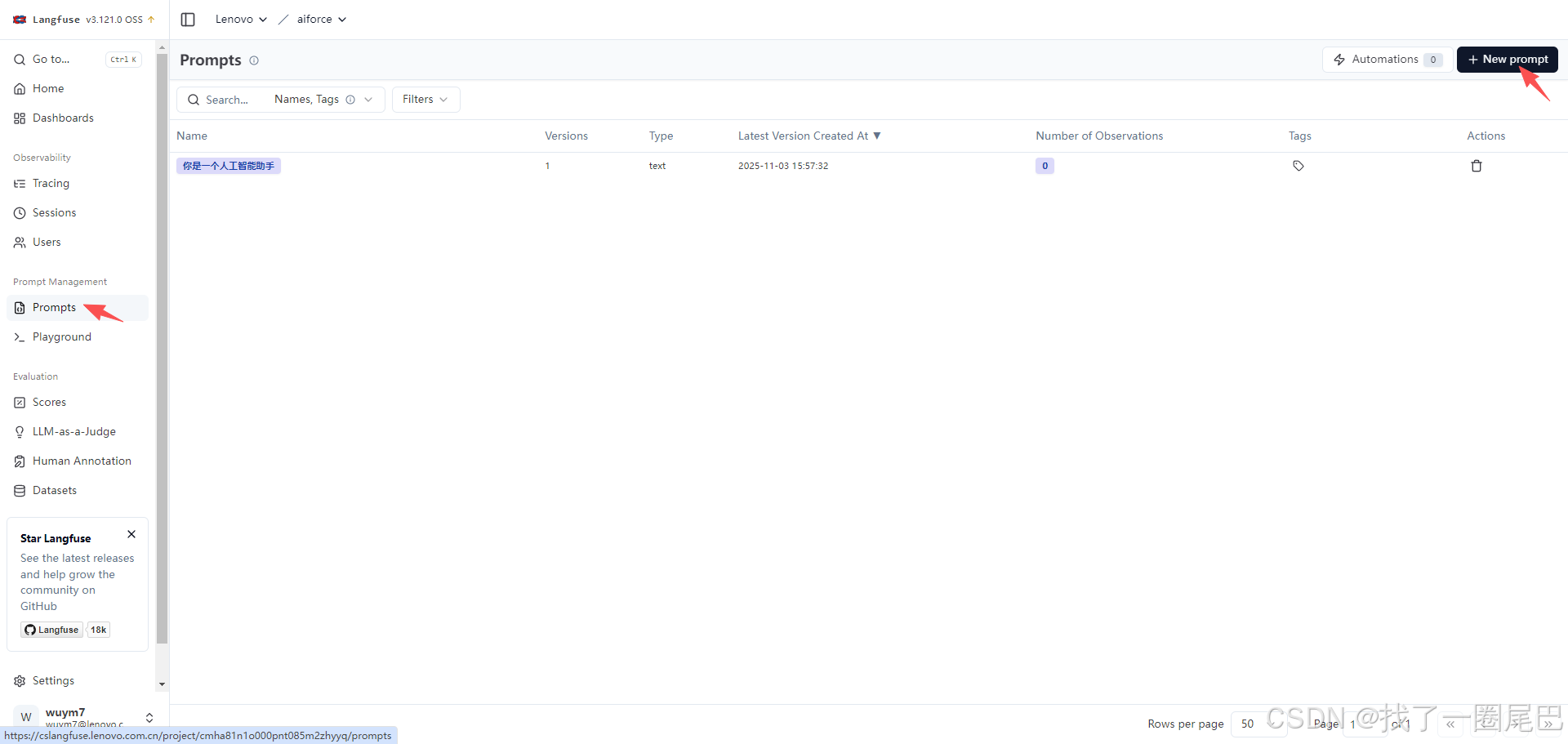
进入 Langfuse 控制台 “Prompts” 模块,点击 “New Prompt” 即可创建:
-
定义提示词名称(如
document-qa-prompt); -
选择类型(文本
text或对话chat,适配不同 LLM 接口); -
编写带变量的模板(如系统消息 “使用 {{context}} 回答 {{input}},未知答案需说明”);
-
配置模型参数(如
model: gpt-4、temperature: 0.0); -
添加标签(如
production)。
系统会自动识别模板中的变量(如 {{context}}),无需手动配置。
(2)SDK 创建:适配程序化工作流
若需通过代码批量创建或集成到 CI/CD 流程,可使用 Langfuse SDK(以 Python 为例):
from langfuse import Langfuse
langfuse = Langfuse()
# 创建对话类型提示词,自动生成 v1 版本
langfuse.create_prompt(
name="document-qa-prompt",
type="chat",
prompt=[
{"role": "system", "content": "Use {{context}} to answer {{input}}. Say 'I don't know' if unsure.\n\n{{context}}"},
{"role": "user", "content": "{{input}}"}
],
labels=["production"] # 直接标记为生产版本
)
若再次调用 create_prompt 且名称相同,Langfuse 会自动生成新版本(如 v2),避免覆盖旧数据。
如何在代码中集成 Langfuse 提示词?
Langfuse 提供了极简的集成流程,只需 4 步即可让应用动态拉取提示词,且后续迭代无需改代码。
步骤 1:拉取指定版本的提示词
在应用代码中,通过 Langfuse SDK 拉取提示词(默认拉取 production 标签版本):
from langfuse import Langfuse
langfuse = Langfuse()
# 方式1:拉取 production 标签的提示词
prompt = langfuse.get_prompt("document-qa-prompt", type="chat")
# 方式2:拉取指定版本(如 v2)
# prompt = langfuse.get_prompt("document-qa-prompt", version=2, type="chat")
# 方式3:拉取 staging 标签的测试版本
# prompt = langfuse.get_prompt("document-qa-prompt", label="staging", type="chat")
Langfuse 会在客户端缓存提示词,避免频繁请求导致的 latency 问题。
步骤 2:编译提示词变量
拉取的提示词是 “模板”,需用实际业务数据替换 {{context}}、{{input}} 等变量:
# 用真实数据编译提示词(如检索到的文档上下文、用户问题)
compiled_messages = prompt.compile(
context="2024年企业网络安全风险主要包括:数据泄露、勒索软件攻击、API 漏洞...",
input="2024年企业网络安全的主要风险有哪些?"
)
编译后会生成 LLM 可直接使用的消息格式:
[
{
"role": "system",
"content": "Use 2024年企业网络安全风险主要包括:数据泄露、勒索软件攻击、API 漏洞... to answer 2024年企业网络安全的主要风险有哪些?. Say 'I don't know' if unsure.\n\n2024年企业网络安全风险主要包括:数据泄露、勒索软件攻击、API 漏洞..."
},
{
"role": "user",
"content": "2024年企业网络安全的主要风险有哪些?"
}
]
步骤 3:关联提示词与追踪(Traces)
为了追踪 “哪个提示词版本对应哪次 LLM 调用”,需将提示词与 Langfuse 的 Trace 功能关联。以 LangChain 为例,通过 CallbackHandler 自动完成关联:
from langfuse.langchain import CallbackHandler
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
# 初始化 Langfuse 回调器
langfuse_handler = CallbackHandler()
# 初始化 LLM 链
llm = ChatOpenAI(model="gpt-4")
chain = LLMChain(llm=llm, prompt=prompt.to_langchain_prompt()) # 直接转换为 LangChain Prompt
# 调用链时传入回调器,自动关联 Trace 与提示词版本
response = chain.invoke(
{"context": "...", "input": "..."},
config={"callbacks": [langfuse_handler]}
)
此后,在 Langfuse 控制台的 “Tracing” 模块中,你能清晰看到每条 Trace 使用的提示词名称、版本,以及该版本的 Token 消耗、 latency 等指标。
步骤 4:迭代与回滚:全程无代码
当需要优化提示词时,只需:
-
在 Langfuse UI 中编辑提示词(自动生成新版本,如 v3);
-
在 Playground 中测试 v3 效果;
-
将
staging标签指向 v3,在预发布环境验证; -
验证通过后,将
production标签迁移到 v3—— 生产应用自动拉取新版本。
若新版本效果不佳,只需将 production 标签迁回旧版本(如 v2),无需任何代码部署,秒级完成回滚。
进阶能力:支撑大规模团队协作
除了核心功能,Langfuse 还提供了面向企业级场景的进阶能力:
-
A/B 测试:自动将流量分配给不同提示词版本,基于 Token 成本、响应质量等指标选择最优版本;
-
Webhooks 通知:当提示词版本或标签变更时,触发自定义 Webhook(如通知测试团队、更新文档);
-
团队协作:支持提示词评论、审批流程,多人可共同编辑并记录修改意图,避免版本混乱。
Langfuse 提示词管理的核心价值
Langfuse 提示词管理并非简单的 “存储工具”,而是一套 “分离提示词工程与软件工程” 的解决方案:
-
对开发者:无需频繁修改代码,专注于业务逻辑,降低维护成本;
-
对非技术角色:可独立参与提示词优化,释放 “提示词工程” 的潜力;
-
对团队:实现提示词版本的可视化管理、效果追溯与快速迭代,提升协作效率;
-
对生产:支持安全回滚、A/B 测试,保障 LLM 应用的稳定性与效果。
对于需要长期迭代、团队协作的 LLM 应用而言,Langfuse 提示词管理无疑是提升效率、降低风险的关键工具。
评估
在 LLM 应用开发中,“如何判断回答质量” 是绕不开的核心问题 —— 传统手动测试(人工提问、主观判断)仅能覆盖少量案例,既无法应对迭代后的全量回归测试,也无法量化生产环境中不同版本的性能差异。Langfuse 的评估功能正是为解决这一痛点而生,通过系统化、自动化的性能衡量方案,帮助开发者从 “我觉得好” 升级为 “数据证明好”,在迭代中稳定保障 LLM 应用质量。
核心定位:解决传统手动测试的 “不可扩展性” 痛点
当 LLM 应用从 “原型” 走向 “生产”,手动测试的局限会完全暴露:
-
迭代成本高:修改提示词 / 模型后,需重新手动测试所有历史案例,无法高效回归;
-
边缘案例遗漏:人工难以覆盖 “答案不在文档中”“提问模糊” 等边缘场景,生产中易出问题;
-
性能无法量化:无法对比 “提示词 v1” 与 “v2” 的客观差异(如相关性、正确性),只能依赖主观感受;
-
生产监控缺失:部署后无法持续衡量应用性能,用户遇到低质量回答时难以及时发现。
Langfuse 评估的核心价值,就是通过标准化的评估流程 + 自动化评分工具,将 LLM 应用的质量判断从 “人工抽样” 升级为 “全量数据驱动”,覆盖 “开发测试→版本对比→生产监控” 全链路。
核心逻辑:系统化评估的 6 步闭环
Langfuse 遵循 “从案例到结论” 的系统化流程,让评估可复现、可对比,具体分为 6 个关键步骤:
1. 构建测试数据集:覆盖真实与边缘场景
首先收集 20-50 个能代表真实 usage 的测试案例,需包含:
-
常规场景(如 “文档中明确有答案的提问”);
-
边缘场景(如 “答案不在文档中”“提问歧义”“多轮对话上下文关联”);
-
核心指标关联(每个案例需明确 “期望评估的维度”,如 “是否防幻觉”“是否贴合上下文”)。
数据集是评估的基础 —— 只有覆盖真实场景,评估结果才对生产有参考价值。
2. 选择评分方法:聚焦核心质量维度
根据应用场景定义 “什么是好的回答”,Langfuse 支持两类评分方式:
-
自动化评分:通过 “LLM-as-a-Referee(LLM 裁判员)” 自动打分,适合主观维度(如相关性、语气);
-
确定性检查:通过代码逻辑硬校验,适合客观维度(如 “回答长度是否<100 字”“是否包含指定关键词”)。
例如 Q&A 系统常见的核心维度:“正确性”“相关性”“依据性(防幻觉)”,需针对性选择评分方法。
3. 运行测试数据集:关联追踪(Traces)记录全量数据
将测试数据集中的每个案例输入 LLM 应用,Langfuse 会自动将 “提问→上下文→回答” 等全量信息记录为追踪(Traces) —— 既保留原始数据用于后续分析,也为后续 “评分关联” 打下基础。
这一步无需额外开发,只需确保应用已集成 Langfuse 追踪功能,测试过程中会自动同步数据。
4. 自动评分:用 LLM 裁判员替代人工
Langfuse 最核心的评估能力是 “LLM-as-a-Referee”—— 通过一个 LLM裁判员(如 GPT-4、Claude)自动为回答打分,无需人工介入。评分逻辑是:给 “裁判员 LLM” 提供 “原始问题 + 应用回答 + 评分标准”,由其按规则输出分数。
常见 “裁判员” 类型(以 Q&A 系统为例):
|
裁判员类型 |
评分标准示例 |
核心作用 |
|---|---|---|
|
正确性裁判员 |
“1 分:完全符合文档信息;0.5 分:部分符合;0 分:矛盾或编造” |
防 “回答与文档冲突” |
|
相关性裁判员 |
“1 分:精准回应问题;0.5 分:部分相关;0 分:偏离主题(如答非所问)” |
防 “正确但无用的回答” |
|
依据性裁判员 |
“1 分:所有信息来自文档;0.5 分:部分来自文档;0 分:包含文档外信息(幻觉)” |
防 “无中生有” 的幻觉 |
|
风格裁判员 |
“1 分:简洁(<50 字);0.5 分:中等长度;0 分:冗长(>100 字)” |
保障回答符合风格要求 |
开发者可根据需求自定义裁判员(如 “拒绝处理裁判员”“语气正式度裁判员”),覆盖专属业务场景。
5. 分析结果:聚合数据定位问题
Langfuse 会在 dashboard 中聚合所有测试案例的评分结果:
-
整体指标:展示全量案例的 “平均正确性”“平均相关性” 等,快速判断应用整体性能;
-
案例拆解:按 “评分高低” 筛选案例,直接定位 “低分案例”(如 “依据性 0 分” 的幻觉回答),查看原始提问、上下文、回答,分析问题根源;
-
维度对比:同一案例的多维度评分并行展示(如 “正确性 1 分,但相关性 0.5 分”),明确改进优先级。
6. 迭代对比:用数据证明优化效果
当修改提示词 / 模型后,重新运行测试数据集,Langfuse 会自动对比两次评估的核心指标 —— 例如 “提示词 v2 的平均相关性从 0.72 提升至 0.85,幻觉率从 15% 降至 5%”,让迭代效果有明确数据支撑,避免 “越改越差” 的风险。
实操关键:如何在 Langfuse 中配置 “LLM 裁判员”
Langfuse 支持通过 UI 或 API 配置裁判员,流程简洁且可灵活调整,核心步骤如下:
1. 定义裁判员提示词:明确、无歧义的评分规则
裁判员的准确性依赖 “清晰的评分标准”—— 需避免模糊表述,明确每个分数对应的具体场景。例如 “依据性裁判员” 的提示词需包含:
你是 LLM 回答的依据性裁判员,请根据以下规则评分:
- 评分范围:0 分、0.5 分、1 分
- 1 分:回答中所有信息均来自提供的“文档上下文”,无任何额外信息;
- 0.5 分:回答中大部分信息来自“文档上下文”,但包含 1-2 处轻微的、不影响核心结论的额外信息;
- 0 分:回答中包含关键信息(如数据、结论)来自“文档上下文”之外,存在明显幻觉。
请先判断回答是否符合规则,再输出最终分数(仅需数字,无需额外解释)。
【文档上下文】:{context}
【用户提问】:{input}
【LLM 回答】:{output}
2. 选择裁判员模型:平衡 “准确性” 与 “成本”
Langfuse 支持对接主流 LLM 作为裁判员,选择时需权衡两点:
-
准确性:更强的模型(如 GPT-4、Claude 3)评分更精准,尤其适合复杂场景(如多轮对话的上下文关联);
-
成本:基础模型(如 GPT-3.5)成本更低,适合简单维度(如回答长度、语气)的评分。
3. 测试与调整:确保裁判员 “评分可靠”
裁判员并非 “即开即用”,需先通过已知结果的案例验证:
-
选择 5-10 个 “明确知道评分” 的案例(如 “回答完全幻觉,应得 0 分”);
-
让裁判员为这些案例打分,若出现偏差(如将 0 分案例评 0.5 分),需优化提示词(如补充反例);
-
反复调整至裁判员评分与人工判断一致,再应用到全量数据集。
4. 异步运行:不影响主应用性能
裁判员评分采用 “异步执行” 机制 —— 测试案例运行时,主应用仅需处理核心逻辑,评分任务在后台自动完成,避免因评估拖慢应用响应速度。评分结果生成后,会直接关联到对应的 Trace,在 dashboard 中实时查看。
裁判员的 “适用场景” 与 “局限性”:合理使用更高效
Langfuse 的 “LLM-as-a-Referee” 并非万能,需明确其适用边界,避免误用:
适用场景:主观维度的自动化评分
当评估维度难以用代码硬校验时,裁判员优势显著,例如:
-
语气 / 风格(如 “回答是否专业”“是否简洁”);
-
相关性(如 “回答是否紧扣提问核心”);
-
拒绝处理(如 “答案不存在时,是否正确回复‘不知道’”)。
局限性:客观维度需用 “确定性检查”
对于有明确标准答案的客观维度,裁判员效率低于代码校验,例如:
-
事实准确性(如 “回答中‘2024 年’是否与文档中的‘2024 年’一致”);
-
格式合规性(如 “回答是否包含指定格式的链接”);
-
数值正确性(如 “计算结果是否等于 100”)。
此时应优先使用 Langfuse 的 “自定义评分函数”—— 通过代码逻辑直接校验,结果更精准、成本更低。
规避局限的技巧
为减少裁判员的偏差(如评分分歧、风格偏见),可采用以下方法:
-
多裁判员 averaging:对同一案例用 2-3 个裁判员评分,取平均值;
-
定期抽查:每批次评估后,人工抽查 10%-20% 的案例,验证裁判员准确性;
-
提示词优化:在提示词中补充 “反例”(如 “错误案例:回答包含文档外数据,评 0 分”),减少裁判员误解。
进阶能力:支撑大规模应用的 “全链路评估”
除核心的 “LLM-as-a-Referee” 外,Langfuse 还提供一系列进阶功能,满足生产级需求:
-
数据集管理:统一组织测试案例,支持按 “场景标签”(如 “常规提问”“边缘案例”)分类,方便版本化管理;
-
自定义评分函数:对于客观维度,通过代码编写自定义评分逻辑(如 “回答长度<100 字得 1 分”),与裁判员评分互补;
-
持续评估:对接生产流量,自动抽取部分请求进行评分,持续监控应用性能,发现问题及时告警;
-
版本对比报告:自动生成 “提示词 v1 vs v2”“模型 A vs B” 的评估报告,包含核心指标(正确率、幻觉率、成本)的差异,辅助决策。
Langfuse 评估的核心价值
Langfuse 评估功能的本质,是为 LLM 应用搭建了一套 “质量保障体系”—— 它将 “评估” 从 “开发后的附加步骤” 融入 “迭代全流程”,让开发者:
-
迭代时 “敢改”:有全量测试数据集支撑,不怕改坏;
-
优化时 “知效”:有客观指标对比,明确改进方向;
-
生产时 “可控”:有持续评估监控,及时发现质量问题。
最终,通过 “系统化流程 + 自动化工具”,让 LLM 应用的质量从 “不可控的主观感受”,转变为 “可衡量、可优化、可保障” 的数据指标,为生产级应用保驾护航。
性能基准与现状分析
基础性能表现
-
稳定负载(100 TPS):平均处理延迟 127ms(P99: 213ms),资源占用可控(CPU 35%、内存 4.2GB),ClickHouse 写入速度稳定在 300-400 行 / 秒,满足中小型业务场景需求。
-
极限压力(1000 TPS):最大延迟 892ms(P99: 1.2s),服务无宕机且支持自动降级非核心功能,数据完整性达 99.98%(20 万事件仅 37 条重试),具备较强的抗冲击能力。
高性能保障
-
高效的底层架构:Langfuse采用PostgreSQL和ClickHouse的组合来应对不同需求。PostgreSQL适用于核心业务的高效查询,而列式数据库ClickHouse则擅长处理海量的时序数据和分析工作负载。这种混合架构是其高性能的基石。
-
可扩展性与稳定性保障:其组件化设计(如分离的
langfuse-worker)支持水平扩展。在面对极限压力时,系统能通过自动降级非核心功能来保障核心服务的稳定性,确保了高可用性。 -
细致的配置调优:Langfuse提供了丰富的配置选项以供性能调优,例如调整事件批处理大小、批量写入间隔和并发写入线程数等,这些都能显著提升数据摄取和处理的效率。
性能瓶颈
-
Redis 队列:高负载下堆积峰值达 12 万条,需依赖自动扩容缓解压力。
-
ClickHouse 写入:MergeTree 表引擎在高写入场景下出现短暂延迟,影响实时性。
核心优化策略
1. 架构层面优化
(1)读写分离设计
-
实现目标:主库专注写入,只读副本分担查询压力,避免读写冲突。
-
技术参考:基于
packages/shared/src/server/repositories/observations.ts中的查询逻辑,将查询流量导向 ClickHouse 只读副本,写入流量保留在主库。// 示例:查询路由到只读副本 const getObservations = async (params) => { return queryClickhouse({ ...params, preferredClickhouseService: PreferredClickhouseService.ReadReplica // 优先使用只读副本 }); };
(2)数据分层存储
-
分层策略:
-
热数据(7 天内):存储于 ClickHouse 本地表,保障低延迟查询;
-
冷数据(>7 天):迁移至 S3 对象存储,通过 ClickHouse 外部表接口访问。
-
-
配置参考:基于
worker/src/ee/dataRetention/的 Retention Policy 配置,自动触发冷热数据迁移:// 冷数据迁移配置示例 const dataRetentionConfig = { hotDataTTL: "7d", // 热数据保留7天 coldStoragePath: "s3://langfuse-cold-data/{projectId}/{date}/", // S3路径 migrationSchedule: "0 0 * * *" // 每日凌晨执行迁移 };
2. 配置参数优化
通过调整核心参数平衡吞吐量与延迟,推荐配置如下(参考worker/src/env.ts):
| 参数 | 推荐值 | 作用 |
|---|---|---|
BATCH_SIZE |
500-1000 | 批量写入大小,增大可提升吞吐量(需结合内存) |
WRITE_INTERVAL_MS |
1000 | 批量写入间隔,缩短可降低延迟(需避免频繁 IO) |
CONCURRENT_WRITERS |
8-16 | 并发写入线程数,根据 CPU 核心数调整 |
CACHE_TTL_SECONDS |
300 | 查询缓存时间,减少重复计算 |
MAX_QUEUE_SIZE |
100000 | 队列最大容量,触发扩容阈值 |
配置原则:
-
高 TPS 场景(如 1000+)优先调大
BATCH_SIZE和CONCURRENT_WRITERS; -
低延迟场景(如实时监控)缩短
WRITE_INTERVAL_MS。
3. 关键技术实现优化
(1)批量写入机制
-
核心逻辑:基于
packages/shared/src/server/ingestion/processEventBatch.ts,将分散的事件按批次聚合后写入,减少 IO 次数。 -
优化点:
-
动态调整批次大小(如根据队列长度自动扩容至 1000);
-
优先处理 oldest 事件,避免队列尾部数据过期。
-
(2)连接池管理
-
实现参考:
worker/src/database.ts中的连接池配置,控制 ClickHouse/Redis 连接数,避免资源耗尽。// 连接池优化示例 const clickhousePoolConfig = { maxOpenConns: 20, // 最大连接数 maxIdleConns: 10, // 空闲连接数 connMaxLifetime: 300000 // 连接存活时间(5分钟) };
(3)非核心功能降级
-
触发条件:当 Redis 队列堆积超过
MAX_QUEUE_SIZE的 80% 时,自动降级非核心功能(如非关键指标计算、历史数据统计)。 -
恢复机制:队列长度低于阈值后,逐步恢复功能,避免流量突增再次压垮系统。
常见问题解决方案
1. 队列堆积(Redis 队列长度异常增长)
-
临时处理:调整
worker/src/queues/workerManager.ts中的concurrency参数(如从 4 增至 8),提升消费速度; -
长期优化:水平扩展 worker 实例,通过 K8s HPA(基于队列长度)自动扩缩容。
2. 查询缓慢(ClickHouse 响应延迟)
-
索引优化:基于
packages/shared/src/server/queries/clickhouse-sql/,为高频过滤字段(如project_id、start_time)创建NGramBF或Range索引; -
物化视图:通过
worker/src/backgroundMigrations/migrateObservationsFromPostgresToClickhouse.ts的迁移逻辑,预计算常用聚合结果(如每日请求量、平均延迟)。
参考文献
langfuse 教程
https://www.datacamp.com/tutorial/langfuse
性能测试
https://blog.csdn.net/gitblog_00342/article/details/150961332
官网文档

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)