Ollama部署微调后的大模型
文章目录
1. QLoRA与LoRA
1.1 概念
LoRA:LoRA是一种用于微调大型语言模型的技术,通过低秩近似方法降低适应数十亿参数模型(如GPT-3)到特定任务或领域。
QLoRA:QLoRA是一种高效的大型语言模型微调方法,它显著降低了内存使用量,同时保持了全16位微调的性能。它通过在固定的、4位量化的预训练语言模型中反向传播梯度到低秩适配器来实现这一目标。
其中, Q在AI领域加在某个词的前面一般指量化
LoRA和QLoRA微调语言大模型:数百次实验后的见解
1.2 什么是量化?
- 概念
量化是模型(性能)优化的方法之一。
量化是通过对模型参数的精度进行压缩(例如之前存储一个参数需要32bit,量化后只要8bit或者4bit。简单理解,就是降低数据的存储精度),从而达到减少模型体积,降低模型计算复杂度的效果。 - 量化可以用在两个方面:
量化技术最早用在模型部署时,主要解决模型体积过大和对算力依赖过高问题。
目前量化计算也被大量用于大模型的训练过程中,主要降低模型对设备的依赖性和降低训练时长问题。 - 量化和选一个小模型有什么区别?
小模型的特点时参数量少,例如0.5B模型,参数量是5亿参数,每个参数的存储空间是32bit。
而量化不改变模型的参数量,只改变每个参数的存储空间。
对于大模型而言,它的效果取决于模型的参数量,而非参数的精度。例如,同系列模型中,32B的模型一定优于7B的模型。
2. 模型转换为GGUF格式
2.1 什么是GGUF?
GGUF格式的全名是GPT-Generated Unified Format
在传统的Deep Learning Model开发中大多使用PyTorch来进行开发,但因为在部署时会面临相依 Lirbrary太多、版本管理的问题,才有了GGML、GGMF、GGJT等格式,而在开源社群不停的迭代后GGUF就诞生了。
GGUF实际上是基于GGJT的格式进行优化的,并解决了GGML当初面临的问题,包括:
1)可扩展性:轻松为GGML架构下的工具添加新功能,或者向GGUF模型添加新Feature,不会破坏与现有模型的兼容性。
2)对mmap(内存映射)的兼容性:该模型可以使用mmap进行加载,实现快速载入和存储。
3)易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的Library,同时对于不同编程语言支持程度也高。
4)模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件。
5)有利于模型量化:GGUF支持模型量化(4位、8位、F16),在GPU变得越来越昂贵的情况下,节省VRAM成本也非常重票。
模型后缀区分:
Instruct:标准版的,有人工干预
Chat:有人工干预的
Base:原生训练之后,没有人工干预的,无校准的
2.2 使用QLoRA微调Qwen2.5-1.5B-Instruct进行训练
参考LLama Factory使用LoRA微调Qwen进行部署
启用web服务:
cd LLaMA-Factory
llamafactory-cli webui

开始训练之后出现错误: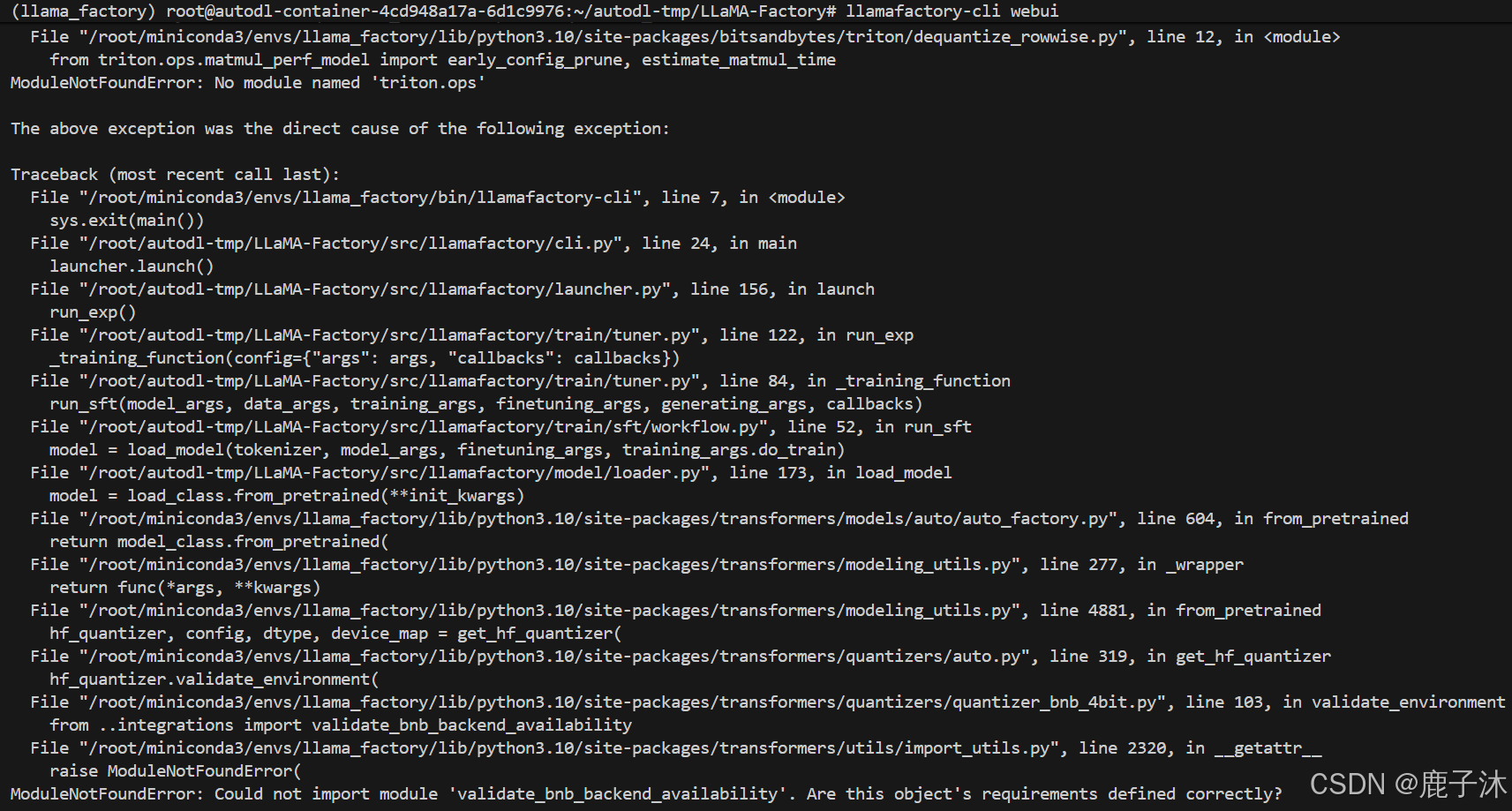
这是bitsandbytes版本没装对,这个依赖的作用是训练过程中量化,重新安装包:
pip install bitsandbytes==0.46.0
补充:gptq是推理时的量化
2.3 将hf模型转换为GGUF
- 将训练结束后的检查点导出为一个权重文件
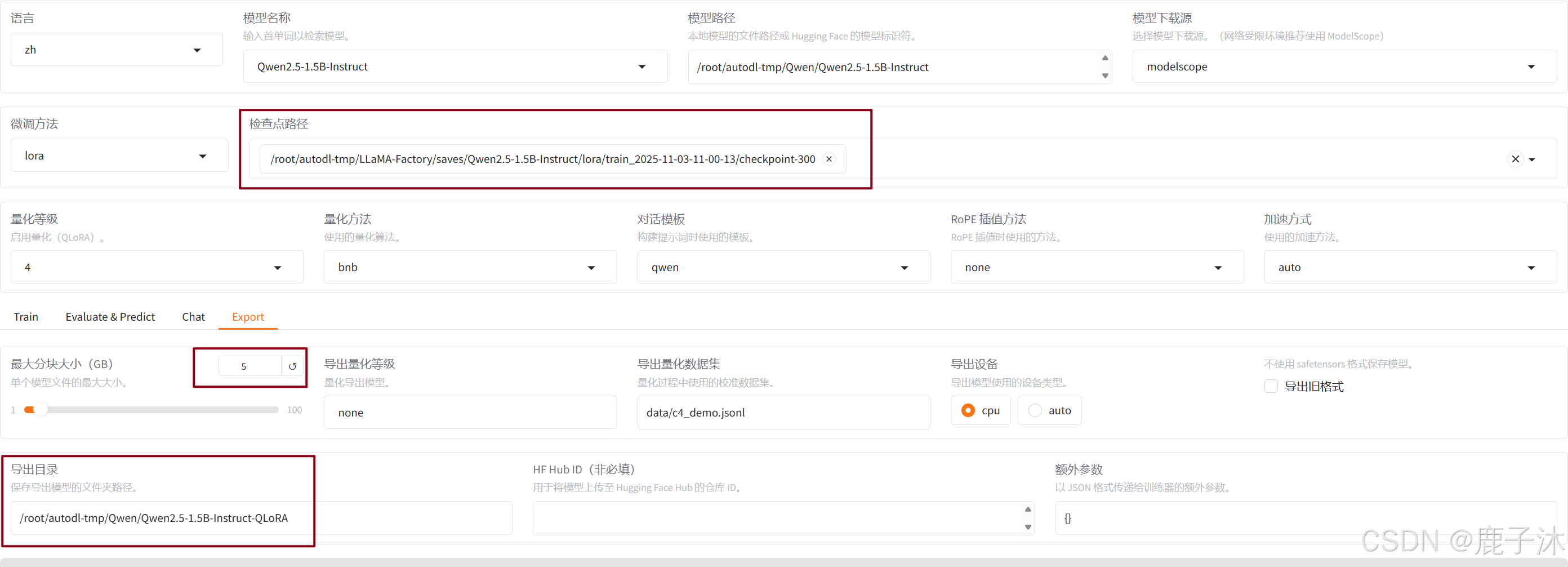
- 使用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换为gguf文件
其中llama.cpp是个框架
git clone https://github.com/ggerganov/llama.cpp.git
pip install -r llama.cpp/requirements.txt
第一个参数传的是被转换的模型, --outtype 后指定输出类型, --outfile时保存的量化后的模型
不做量化:
python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct QLoRA
--outtype f16 --verbose --outfile /root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct-QLoRA-f16.gguf
量化:
python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct-QLoRA
--outtype q8_0 --verbose --outfile /root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct-QLoRA-q8.gguf
这里–outtype是输出类型,代表含义:
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别。
q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。
q4_0:这是最初的量化方案,使用 4 位精度。
q4_1 和 q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景。
q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较
慢。
q6_k 和 q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户。
fp16 和 f32: 不量化,保留原始精度
2.4 使用ollama运行gguf
- 先建立一个配置文件qwen2.5_1.8b_q8,内容为:
FROM /root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct-QLoRA-q8.gguf
- 使用ollama create命令创建自定义模型
ollama create qwen2.5_1.8b_q8 --file /root/autodl-tmp/qwen2.5_1.5b_q8

- 启用服务
ollama run qwen2.5_1.8b_q8:latest


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)