Apache Paimon 写入流程
Apache Paimon 作为下一代流式数据湖存储的杰出代表,通过其创新的“湖格式 + LSM-Tree”架构,成功地解决了传统数据湖在实时更新和流批一体处理上的诸多痛点。本报告系统性地剖析了 Paimon 从顶层架构设计到底层技术实现,再到生产环境性能优化的完整技术栈,旨在为广大数据从业者提供一份全面而深入的实践指南。1.统一的流批存储:Paimon 的核心价值在于其原生支持流式和批量读写。
目录
2.2.2. 快照(Snapshot)与清单(Manifest)
4.2.1. 快照(Snapshot)与清单(Manifest)的内部结构
5.2.1. 写缓冲与溢出(Write Buffer & Spill)
操作步骤:如何启动 Dedicated Compaction 作业
5.5.1. Flink SQL:从 Kafka 实时同步到 Paimon
5.5.2. Flink DataStream API (Java) 示例
5.5.3. Dedicated Compaction 作业的完整脚本
1. 引言
Apache Paimon(原名 Flink Table Store)是下一代流式数据湖存储技术。它创新性地将传统数据湖的开放文件格式与日志结构化合并树(Log-Structured Merge-Tree, LSM-Tree)的存储结构相结合,原生支持海量数据的实时更新、高吞吐写入和高效查询。Paimon 不仅与 Apache Flink 和 Apache Spark 等计算引擎深度集成,还兼容 Hive 生态,使其成为构建现代化实时数据仓库和数据湖仓一体平台的理想选择。
理解 Paimon 的写入流程是掌握其核心能力的关键。数据写入的效率、稳定性和一致性直接影响到整个数据平台的性能和可靠性。本报告将从 Paimon 的架构设计入手,系统性地解析其写入流程的每一个环节,深入探讨其背后的技术实现、事务机制和性能优化策略。
本报告的目标读者包括:
-
• 数据架构师:负责技术选型和平台设计的专业人士。
-
• 数据工程师:从事数据管道开发和维护的工程师。
-
• Flink/Spark 开发者:使用流处理或批处理引擎与 Paimon 交互的开发者。
-
• 运维工程师/SRE:负责保障数据平台稳定运行的运维专家。
通过阅读本报告,您将全面了解 Paimon 的写入机制,并获得在生产环境中应用和优化 Paimon 的实用知识。
2. Paimon 核心架构与组件
Apache Paimon 的架构设计精巧,旨在通过分层和模块化的方式,实现流批一体的高效数据处理。其核心思想是将数据湖的开放文件格式与 LSM-Tree 的高效更新能力相结合,构建一个既能支持高吞吐流式写入,又能进行快速分析查询的统一存储底座。
2.1. 整体架构分层
Paimon 的架构可以分为以下几个层次:
-
• 存储层(Storage Layer):Paimon 可构建于多种底层文件系统之上,如 HDFS、Amazon S3、Google Cloud Storage、阿里云 OSS 等。这使其能够充分利用云存储的弹性、可扩展性和低成本优势。
-
• 文件布局层(File Layout Layer):在存储层之上,Paimon 定义了一套标准化的目录和文件组织结构。数据按照
库/表/分区/桶的层次进行组织,主要包含 Schema 文件、快照(Snapshot)文件、清单(Manifest)文件和数据文件(Data Files)等。 -
• 核心引擎层(Core Engine Layer):这是 Paimon 的核心,主要由 LSM-Tree 存储引擎、事务管理器、合并(Compaction)调度器、缓存管理器等组件构成。LSM-Tree 负责处理数据的写入、更新和合并,而事务管理器则通过快照机制保证操作的 ACID 特性。
-
• 计算引擎集成层(Engine Integration Layer):Paimon 与多种主流计算引擎深度集成。其中,与 Apache Flink 的集成为其提供了强大的实时流处理能力;与 Apache Spark 的集成为批处理和数据分析提供了支持。此外,Paimon 还支持 Hive、Trino、Presto、StarRocks、Doris 等查询引擎,方便用户进行即席查询和 OLAP 分析。
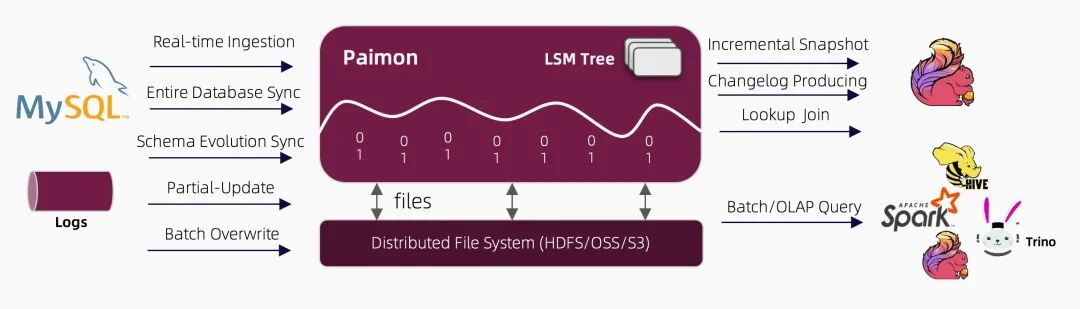
Paimon 架构总览图
图 1: Paimon 架构总览 (来源: Paimon 中文文档) [21]
2.2. 核心组件解析
理解 Paimon 的核心组件是掌握其工作原理的基础。
2.2.1. 文件系统与目录结构
Paimon 的数据统一存放在一个表目录下,其结构清晰,便于管理和追溯。
-
•
schema/:存放表的元数据信息(Schema),每个版本一个文件,记录了字段、类型、分区键等定义。 -
•
snapshot/:存放快照文件。每次数据提交(Commit)都会生成一个新的快照,它代表了表在某个时间点的完整状态。 -
•
manifest/:存放清单文件。清单文件是快照的“目录”,记录了哪些数据文件属于该快照。 -
• 分区和桶目录:在表目录下,数据会根据分区键和桶(Bucket)ID 进一步组织。例如,
/dt=2023-11-11/bucket-0/。
2.2.2. 快照(Snapshot)与清单(Manifest)
快照和清单是 Paimon 实现 ACID 事务和时间旅行(Time Travel)功能的核心。
-
• 快照(Snapshot):一次完整的写入操作最终会形成一个快照。它是一个 JSON 文件,包含了此次提交的元数据,如提交类型(追加、合并、覆盖)、时间戳,以及指向相关清单文件的指针。Paimon 通过维护一个连续的快照列表,来记录表的完整历史状态。
-
• 清单列表(Manifest List)和清单文件(Manifest File):为了管理大量的数据文件,Paimon 引入了清单文件。一个清单文件记录了一批数据文件的元数据(如文件名、文件大小、数据行数、主键范围等)。一个快照可以关联多个清单文件,这些清单文件的列表就构成了清单列表。这种分层结构大大提高了元数据管理的效率。
2.2.3. LSM-Tree 与数据文件
对于支持主键更新的表(Primary-Key Table),Paimon 采用 LSM-Tree 结构来组织数据文件。
-
• LSM-Tree(Log-Structured Merge-Tree):这是一种为高频写入和更新场景优化的存储结构。数据写入时,首先进入内存中的写缓冲(MemTable)。当 MemTable 写满后,其中的数据会被排序并刷写(Flush)到磁盘,形成一个有序的数据文件,称为 Sorted Run。这些文件最初位于 L0 层。随着文件增多,后台的合并(Compaction)进程会将多个 Sorted Run 合并成更大、更高效的文件,并迁移到更高的层级(L1, L2, ...)。
-
• 数据文件(Data Files):Paimon 支持 Parquet、ORC、Avro 等多种列式或行式存储格式。对于主键表,数据文件中会包含特殊的系统列,如
_KEY_(主键)、_SEQUENCE_NUMBER_(序列号)和_VALUE_KIND_(数据类型:ADD 或 DELETE),用于在合并时处理数据的更新和删除。
2.3. 表类型:主键表 vs. 追加表
Paimon 提供两种主要的表类型,以适应不同的业务场景。
-
• 主键表(Primary-Key Table):定义了主键,支持数据的
INSERT、UPDATE和DELETE操作。它使用 LSM-Tree 结构存储数据,非常适合需要实时更新的场景,如数据库 CDC(Change Data Capture)数据的同步。 -
• 追加表(Append-Only Table):没有主键,只支持
INSERT操作。数据被直接追加到文件中,写入开销更低,吞吐量更高。它适合存储日志、事件流等不需要更新的数据。
2.4. 分区(Partition)与桶(Bucket)
分区和桶是 Paimon 进行数据组织和并行处理的关键机制。
-
• 分区:与 Hive 类似,Paimon 支持按一个或多个列对数据进行分区。分区可以有效地将数据分割成更小的、可管理的数据集,查询时可以根据分区条件进行裁剪(Pruning),只读取需要的分区,从而大大提高查询性能。
-
• 桶(Bucket):在每个分区内部,数据会根据主键(或指定的分桶键)的哈希值被分配到不同的桶中。桶是 Paimon 进行读写的最小单元。一个桶内的数据保证按主键排序。这种设计使得 Paimon 可以对不同的桶进行并行读写,从而提高了整体的吞吐量。对于主键表,桶的数量在表创建时指定,并且建议 sink 的并行度与桶数保持一致,以达到最佳性能。
通过以上架构设计,Paimon 构建了一个强大而灵活的存储底座,为上层的流批计算引擎提供了统一、高效、可靠的数据访问能力。
3. Paimon 写入流程详解
Paimon 的写入流程是一条精心设计的流水线,确保了数据写入的高效性、原子性和持久性。对于主键表,其写入流程充分体现了 LSM-Tree 的核心思想。本章节将详细拆解从数据进入 Paimon 到最终可见的全过程。
3.1. 写入流程概览
主键表的写入流程可以概括为以下几个关键阶段:
-
1. 数据摄入与分发:Flink 或 Spark 作业将数据记录发送到 Paimon 的 Sink 算子。
-
2. 写缓冲(Write Buffer):记录首先被写入位于内存中的写缓冲(MemTable)。
-
3. 排序与刷盘(Sort & Flush):当写缓冲满足特定条件(如大小阈值、Checkpoint 触发)时,其中的数据会被排序,并刷写到磁盘,形成 L0 层的有序文件(Sorted Run)。
-
4. 后台合并(Compaction):独立的后台线程会持续监控 LSM-Tree 的状态,将 L0 层和其它层级的多个文件合并成更大、更有序的新文件,以控制文件数量和读放大。
-
5. 提交(Commit):当 Flink 的 Checkpoint 完成时,Paimon 的提交器(Committer)会收集本次写入生成的数据文件信息,更新清单文件(Manifest),并最终生成一个新的快照(Snapshot)。
-
6. 可见性:一旦新的快照文件被原子性地创建,本次写入的数据就对外部的读取者可见。
3.2. 阶段化写入详解
3.2.1. 数据分发与写缓冲
当数据记录到达 Paimon Sink 时,会首先根据记录的主键计算其所属的桶(Bucket)。然后,记录被发送到处理该桶的 конкреtnym Writer 实例。每个 Writer 内部都维护着一个或多个内存写缓冲(MemTable)。数据被缓存在 MemTable 中,直到触发刷盘操作。这种缓冲机制可以有效地将多次小规模的写入合并成一次较大规模的磁盘 I/O,从而提高写入吞吐量。
关键参数:
-
•
write-buffer-size: 控制每个 Writer 的写缓冲大小。增大此值可以减少刷盘频率,提升吞吐,但会增加内存消耗和 Checkpoint 的时长。 -
•
write-buffer-spillable: 当设置为true时,如果写缓冲耗尽,数据可以被溢出(Spill)到本地磁盘,避免因反压(Back-Pressure)导致整个流处理作业阻塞。
3.2.2. 排序与刷盘 (Flush)
刷盘操作在以下几种情况下被触发:
-
• 写缓冲(MemTable)已满。
-
• Flink 作业触发 Checkpoint。
刷盘时,MemTable 中的所有数据会按照主键进行排序。排序后的数据被写入一个新的数据文件,这个文件被称为一个 Sorted Run,并被放置在 LSM-Tree 的 L0 层。L0 层的特点是其内部的文件之间可能存在主键范围的重叠。这意味着查询一条记录时,可能需要检查 L0 层中的所有文件。
3.2.3. 后台合并 (Compaction)
随着写入的持续进行,L0 层的文件数量会不断增加。过多的文件不仅会降低查询性能(读放大),还会增加元数据管理的开销。因此,Paimon 引入了后台合并(Compaction)机制。
-
• 合并过程:Compaction 进程会选择多个 Sorted Run(可能来自同一层或不同层),读取它们的数据,进行多路归并排序,然后将合并后的、主键唯一的有序结果写入一个新的、更大的文件中。旧的、被合并的文件随后会被标记为删除。
-
• 合并策略:Paimon 采用类似于 RocksDB 的 Universal Compaction 策略。该策略旨在平衡写放大(Write Amplification,数据被反复写入的次数)、读放大(Read Amplification,查询时需要读取的文件数)和空间放大(Space Amplification,存储空间中存在多个版本的数据)。
-
• 异步合并:Compaction 操作通常是资源密集型的。为了不影响正常的写入流程,Paimon 支持将 Compaction 操作与写入操作解耦,在独立的线程甚至独立的 Flink 作业(Dedicated Compaction Job)中异步执行。
关键参数:
-
•
num-sorted-run.compaction-trigger: 当一个桶内的 Sorted Run 文件数量达到此阈值时,触发一次合并操作。这是控制合并频率的核心参数。 -
•
num-sorted-run.stop-trigger: 当文件数量达到此阈值时,会暂停写入,以强制等待合并完成。这是防止文件数量失控、导致查询性能严重下降的保护机制。
3.3. 事务管理与一致性保证
Paimon 通过快照机制实现 ACID 事务保证,特别是原子性(Atomicity)和隔离性(Isolation)。
3.3.1. 提交 (Commit) 过程
在 Flink 等流处理引擎中,Paimon 的提交操作与引擎的 Checkpoint 机制紧密绑定。
-
1. 预提交(Pre-Commit):当 Flink 开始一个 Checkpoint 时,所有的 Paimon Writer 会刷盘(Flush)其内存缓冲中的数据,生成新的 L0 层文件。这些文件及其元数据(被称为
DataFileMeta)被发送给提交器(Committer)。 -
2. 全局提交(Global Commit):当 Flink 的所有算子都成功完成 Checkpoint 后,JobManager 会通知 Paimon 的全局提交器(Global Committer)。全局提交器会执行以下原子操作:
a. 生成新的 Manifest:将本次 Checkpoint 产生的所有新数据文件的元数据写入一个新的清单文件(Manifest File)。
b. 创建新的 Snapshot:创建一个新的快照文件,该文件指向新生成的清单文件,并记录本次提交的其它元信息。
3.3.2. 原子性与可见性
Paimon 的原子性保证体现在快照文件的创建上。只有当快照文件被成功创建并写入文件系统后,本次提交的所有数据才被认为是“已提交”的,并对外部查询可见。如果在提交过程中发生任何失败(例如,JobManager 崩溃),快照文件不会被创建,因此部分写入的数据不会对用户可见,从而避免了“脏读”。
读取数据的查询引擎总是通过一个特定的快照来访问数据。这保证了查询的快照隔离级别,即一个查询只能看到某个特定快照所代表的、一致的数据视图,不会受到正在进行的写入操作的干扰。
3.3.3. 时间旅行 (Time Travel)
由于 Paimon 保留了历史的快照文件,用户可以通过指定快照 ID 或时间戳来查询表的历史状态。这为数据回滚、问题排查和历史分析提供了极大的便利。
通过上述写入流程和事务机制,Paimon 不仅实现了高效的数据写入,还保证了数据的一致性和可靠性,使其成为构建实时数据湖的坚实基础。
4. Paimon 技术实现细节
在前两章对 Paimon 的宏观架构和写入流程有了整体认识后,本章将深入其内部,探讨关键技术组件的实现细节,包括数据格式、存储结构、内存管理、并发控制和压缩机制。这些细节共同决定了 Paimon 的性能、成本和可靠性。
4.1. 数据格式与编码
Paimon 支持多种主流的数据文件格式,允许用户根据读写负载和存储成本进行权衡。
-
• Parquet:默认的列式存储格式。它具有出色的压缩率和查询性能,尤其适合分析型场景,因为查询时只需读取所需的列,大大减少了 I/O。Paimon 利用 Parquet 的字典编码、行程长度编码(RLE)和位打包等技术来优化存储和读取效率。
-
• ORC (Optimized Row Columnar):另一种高效的列式存储格式,与 Hive 生态兼容性良好。在某些场景下,ORC 也能提供与 Parquet 相媲美的性能。
-
• Avro:一种行式存储格式。与列式存储相比,Avro 在写入密集型或需要频繁读取整行数据的场景中可能更具优势。它的 Schema 演进能力也做得非常出色。
-
• CSV / JSON:主要用于调试和实验目的,不建议在生产环境中使用,因为它们的存储效率和查询性能远低于列式格式。
选型建议:对于大多数生产环境中的读多写少场景,推荐使用 Parquet。如果业务需要频繁地进行全行更新或读取,可以考虑使用 Avro。
类型映射与精度问题:Paimon 在不同文件格式之间定义了详细的类型映射规则。需要特别注意的是时间戳(TIMESTAMP)类型。例如,在 Parquet 中,高精度(纳秒)的时间戳可能会使用 INT96 类型存储,这在跨系统读取时可能需要进行特殊的时区处理。在 Avro 中,时间戳的精度则有限制。因此,在设计表结构时,需要明确业务对时间精度和时区的要求。
4.2. 存储结构详解
4.2.1. 快照(Snapshot)与清单(Manifest)的内部结构
如前所述,快照和清单是 Paimon 事务与元数据管理的核心。它们的内部结构设计得非常高效。
-
• 快照文件 (Snapshot File):是一个 JSON 文件,其核心内容包括:
-
•
id: 快照的唯一、单调递增的 ID。 -
•
schemaId: 关联的 Schema 版本 ID。 -
•
baseManifestList/deltaManifestList: 指向基础清单列表和增量清单列表的文件路径。增量设计使得元数据追踪更为高效。 -
•
changelogManifestList: 指向变更日志(Changelog)的清单列表,用于支持流式消费。 -
•
commitKind: 提交类型,如APPEND,COMPACT,OVERWRITE。
-
-
• 清单文件 (Manifest File):通常是一个 Avro 文件,包含一个
ManifestEntry列表。每个ManifestEntry描述了一个数据文件的状态,其核心字段包括:-
•
kind: 文件状态,ADD或DELETE。 -
•
partition: 文件所属的分区。 -
•
bucket: 文件所属的桶。 -
•
totalBuckets: 表的总桶数。 -
•
file: 数据文件的详细元数据,包括文件名、大小、行数、最小/最大主键值、列级别的统计信息等。
-
这些详细的元数据,特别是列级别的统计信息(Min/Max 值),是 Paimon 实现高效数据跳过(Data Skipping)和谓词下推(Predicate Pushdown)的关键。
4.2.2. LSM-Tree 的实现细节
Paimon 的主键表是基于 LSM-Tree 实现的。其核心组件包括:
-
• WriteBuffer / SortBuffer:即内存中的 MemTable。数据写入时首先进入这里。
-
• Sorted Run:从内存刷盘后形成的有序数据文件。每个 Sorted Run 内部按主键排序。
-
• Levels:LSM-Tree 的分层结构。L0 层的文件之间主键范围可能重叠,而 L1 及更高层的文件之间主key范围互不重叠。这种结构使得查询在高层级可以非常高效地定位数据。
-
• MergeTreeWriter:负责将内存中的数据刷写到磁盘,形成新的 Sorted Run。
-
• MergeTreeCompactManager:后台合并任务的调度中心。它会根据预设的策略(如文件数量、空间放大率),不断地触发合并任务,维持 LSM-Tree 的健康状态。
归并算法:在执行 Compaction 时,需要对多个 Sorted Run 进行多路归并。Paimon 在实现上提供了**最小堆(Min-Heap)和败者树(Loser Tree)**两种算法。在多路归并的场景下,败者树通常能提供更好的性能,因为它减少了比较的次数。
4.3. 内存管理与缓存策略
Paimon 在读写路径上都设计了精细的内存管理和缓存机制,以减少对磁盘 I/O 的依赖。
-
• 写路径:核心是
WriteBuffer的管理。通过write-buffer-size和write-buffer-spillable等参数,可以平衡内存使用和写入性能。 -
• 读路径:Paimon 实现了多级缓存机制来加速数据读取。
-
• 块缓存(Block Cache):将从数据文件中读取的数据块(Block)缓存在内存中。Paimon 的
CacheManager负责管理这些缓存页,并采用 LRU(Least Recently Used)等淘汰策略。 -
• 内存切片(MemorySlice):为了避免不必要的内存拷贝,Paimon 广泛使用
MemorySlice技术,它提供了对底层内存(如byte[]或ByteBuffer)的零拷贝视图。这在数据序列化/反序列化和比较操作中大大提升了效率。 -
• 文件索引缓存:如布隆过滤器(Bloom Filter)等文件索引也会被缓存在内存中,以加速文件过滤的过程。
-
4.4. 并发控制与事务
Paimon 采用**乐观并发控制(Optimistic Concurrency Control, OCC)**机制来处理多个写入者同时修改同一张表的情况。
-
1. 读取当前状态:每个写入任务开始时,都会基于当前最新的快照进行操作。
-
2. 执行写入:任务在本地执行写入逻辑,生成新的数据文件。
-
3. 提交与冲突检测:在提交阶段,提交器会尝试创建一个新的快照。在创建之前,它会检查自任务开始以来,是否有其他写入者已经提交了新的快照。冲突检测主要关注是否有对相同分区或桶的并发修改。
-
4. 重试:如果检测到冲突,提交会失败,然后任务会根据配置的重试策略(如指数回退)进行重试。重试时,任务会重新读取最新的快照,并再次应用其变更。
这种无锁化的设计避免了传统数据库中锁带来的性能瓶颈和死锁问题,使得 Paimon 能够支持高并发的写入场景。
4.5. 文件索引与查询优化
为了加速查询,Paimon 在数据文件级别提供了丰富的索引机制。
-
• 布隆过滤器(Bloom Filter):一种空间效率极高的数据结构,用于快速判断一个元素是否可能存在于一个集合中。Paimon 可以为指定列创建布隆过滤器,在查询时,如果查询条件中的值在布隆过滤器中不存在,就可以直接跳过整个数据文件,避免无效的 I/O。
-
• 位图索引(Bitmap Index):适用于基数(Cardinality)较低的列。它为每个唯一的列值创建一个位图,记录该值出现在哪些行。位图索引在处理等值查询和
IN子句时非常高效。 -
• 范围位图索引(Range Bitmap Index):对位图索引的扩展,支持范围查询(如
>、<)。
这些文件索引与数据文件中存储的列级别统计信息(Min/Max 值)共同构成了 Paimon 强大的数据跳过能力,使其在处理大规模数据集时依然能保持较低的查询延迟。
5. Paimon 写入性能优化与最佳实践
在生产环境中部署和运维 Paimon,性能调优是确保系统稳定、高效运行的核心环节。本章节将提供一套系统化的写入性能优化指南和最佳实践,覆盖从表设计到作业配置,再到监控与诊断的全过程。
5.1. 表设计与分区策略
良好的表设计是性能优化的基础。
5.1.1. 操作步骤:如何创建一张优化的主键表
创建一张结构良好的 Paimon 表是所有优化的前提。以下是使用 Flink SQL 创建一张典型的用户维表(user_profile)的步骤和 DDL 示例。
步骤:
-
1. 确定主键:选择能够唯一标识一条记录的字段,如
user_id。 -
2. 选择分区键:通常选择日期或时间字段,如
dt,用于数据生命周期管理和查询加速。 -
3. 估算并设置桶数:根据每日增量数据和单桶数据量建议(200MB-1GB),计算出合理的桶数。例如,日增量 10GB,建议桶数可设置为 20 (
10 * 1024 / 500)。 -
4. 编写 DDL:在 Flink SQL 客户端中执行
CREATE TABLE语句。
DDL 示例:
CREATE TABLE user_profile (
user_id BIGINT,
user_name STRING,
gender STRING,
age INT,
city STRING,
last_modified_time TIMESTAMP(3),
dt STRING,
PRIMARY KEY (user_id, dt) NOT ENFORCED
) PARTITIONED BY (dt)
WITH (
'bucket' = '20',
'changelog-producer' = 'input',
'write-buffer-size' = '512mb',
'target-file-size' = '256mb',
'num-sorted-run.compaction-trigger' = '8'
);-
• 解读:
-
•
PRIMARY KEY (user_id, dt) NOT ENFORCED: 定义了联合主键。在固定桶模式下,主键必须包含全部分区键。 -
•
PARTITIONED BY (dt): 按日期dt进行分区。 -
•
'bucket' = '20': 设置了 20 个桶,意味着写入并行度最高可达 20。 -
•
'changelog-producer' = 'input': 假设上游 Kafka 是 CDC 数据,包含了完整的变更日志。 -
•
'write-buffer-size' = '512mb': 增大了写缓冲,以提高吞吐。
-
5.1.2. 选择合适的表类型
-
• 主键表(Primary-Key Table):适用于需要频繁更新的业务场景,如 CDC 数据同步、实时维表等。这是 Paimon 的核心优势所在。
-
• 追加表(Append-Only Table):适用于日志、事件流等只需追加写入的场景。其写入性能更高,资源消耗更低。
5.1.2. 合理规划分区(Partition)
-
• 按时间分区:对于大多数业务,按天(
dt=yyyy-MM-dd)或按小时(hr=HH)分区是最佳实践。这不仅便于数据管理和生命周期控制,还能在查询时有效进行分区裁剪。 -
• 避免分区过多或过小:单个作业处理的分区过多会增加 JobManager 的元数据管理压力。单个分区数据量过小则可能导致大量小文件。需要根据数据量和业务需求找到平衡。
-
• 分区自动管理:利用
partition.expiration-time参数可以实现分区的自动过期和清理,是生产环境必备的治理手段。
5.1.3. 精心设计分桶(Bucket)
分桶是主键表性能调优的重中之重。
-
• 桶是并发单元:Paimon 的写入并行度直接受桶数限制。最佳实践是将 Sink 算子的并行度设置为与桶数相等。
-
• 桶数设置:桶数的选择应保证每个桶在单个 Checkpoint 周期内处理的数据量适中,建议在 200MB 到 1GB 之间。桶数过多会导致元数据管理开销增大和潜在的小文件问题;桶数过少则会限制写入的并行能力。
-
• 固定桶 vs. 动态桶:
-
• 固定桶:在表创建时指定桶数。适用于数据量和主键分布相对稳定的场景。
-
• 动态桶 (
'bucket' = '-1'):Paimon 会根据数据量自动分裂和调整桶。适用于数据量波动较大或存在严重数据倾斜的场景。但动态桶会引入额外的索引维护开销,且对并发写入有限制。
-
5.2. 写入路径关键参数调优
Paimon 提供了丰富的参数来精细化控制写入行为。
完整的 Table Properties 配置示例
以下是一个高度优化的 Paimon 主键表的完整 WITH 子句示例,它整合了多项最佳实践,可作为生产环境的参考模板。
WITH (
-- 核心设置
'bucket' = '50',
'file.format' = 'parquet',
'changelog-producer' = 'input',
-- 写入与缓冲优化
'write-buffer-size' = '1024mb',
'write-buffer-spillable' = 'true',
'sink.parallelism' = '50',
-- 合并 (Compaction) 策略
'write-only' = 'true', -- 解耦写入与合并
'num-sorted-run.compaction-trigger' = '10',
'num-sorted-run.stop-trigger' = '30',
'compaction.max.file-num' = '50',
'target-file-size' = '512mb',
-- 文件索引与查询加速
'file-index.bloom-filter.columns' = 'user_id',
'file-index.bloom-filter.fpp' = '0.001',
-- 生命周期管理
'snapshot.time-retained' = '7d',
'partition.expiration-time' = '30d',
'partition.expiration-check-interval' = '1d'
);5.2.1. 写缓冲与溢出(Write Buffer & Spill)
-
•
write-buffer-size:写缓冲大小。增大此值可以合并更多的小写入,减少刷盘次数,提高吞吐量。但过大的值会增加 Flink TaskManager 的内存压力和 Checkpoint 时长。建议根据 TaskManager 的内存大小和数据到达速率进行调整,通常可以设置为256MB到1GB。 -
•
write-buffer-spillable:是否允许缓冲溢出到磁盘。在生产环境中强烈建议设置为true。这可以有效防止写缓冲用尽时导致的反压,提高作业的稳定性。
5.2.2. 压缩与合并(Compaction)
Compaction 是平衡写放大和读放大的关键,也是最需要精细调优的部分。
-
•
num-sorted-run.compaction-trigger:触发合并的文件数量阈值。默认值为5。减小此值会使合并更频繁,有利于控制文件数量和读放大,但会增加写放大和 CPU/IO 消耗。增大此值则反之。对于写入密集型场景,可以适当增大此值(如6-8)。 -
•
num-sorted-run.stop-trigger:暂停写入的文件数量阈值。这是一个保护机制,防止文件数量失控。如果写入速度远超合并速度,达到此阈值后写入将会被阻塞。在启用了异步合并后,可以适当调大此值。 -
• 解耦写入与合并:生产环境最佳实践是将写入和合并操作解耦。
-
• 在 Flink 写入作业中设置
'write-only' = 'true'。这使得写入作业只负责生成 L0 层的 Sorted Run 文件,不执行任何合并操作,从而最大化写入吞吐量和稳定性。 -
• 另外启动一个独立的 Flink 批作业或流作业(Dedicated Compaction Job),专门负责对表进行合并操作。这个作业可以在业务低峰期运行,使用独立的资源池,避免与写入作业争抢资源。
-
操作步骤:如何启动 Dedicated Compaction 作业
当写入作业设置为 write-only 模式后,必须启动一个独立的合并作业来维护表的健康状态。
步骤:
-
1. 创建一个 Flink SQL 脚本 (
compact_job.sql)。 -
2. 使用
CALL语句:在脚本中,使用 Paimon 提供的compact系统过程。 -
3. 提交 Flink 作业:将此脚本作为一个 Flink SQL 作业提交到集群,并让它长期运行。
SQL 脚本示例 (compact_job.sql):
-- 设置作业为流模式
SET 'execution.runtime-mode' = 'streaming';
-- 设置作业名称
SET 'pipeline.name' = 'paimon_compaction_job_for_my_table';
-- 调用 compact 过程,为指定表启动一个持续运行的合并作业
-- 'default.my_table' 是你需要合并的表的全名
CALL sys.compact('default.my_table', 'streaming', 'default_catalog');你也可以在 CALL 语句中直接指定表属性来覆盖合并策略,例如 CALL sys.compact('my_table', 'streaming', 'default_catalog', 'compaction.max.file-num=30')。
5.2.3. 文件大小与格式
-
•
target-file-size:目标文件大小。Paimon 在合并时会尽量使生成的文件大小接近此值。更大的文件有利于顺序读,减少文件打开开销,但不利于数据跳过和负载均衡。建议根据存储系统特性(如 HDFS 的块大小)和查询模式进行设置,通常128MB到1GB是一个合理的范围。 -
•
file.format和压缩:如前所述,parquet是大多数场景下的推荐格式。可以使用file.compression和parquet.compression.codec来选择压缩算法(如zstd,snappy,lz4)。zstd提供了很好的压缩比和性能平衡。
5.3. 监控与诊断
持续的监控是主动发现和解决性能问题的前提。Paimon 提供了丰富的 Metrics 指标。
操作步骤:如何监控写入性能
有效的监控是性能调优和问题诊断的前提。
步骤:
-
1. 确保 Flink 指标上报:在 Flink 的配置文件
flink-conf.yaml中,配置好指标上报器(Metrics Reporter),如 Prometheus, InfluxDB, or JMX。 -
2. 访问 Flink Web UI:在 Flink 作业的 Web UI 界面,找到 Paimon Sink 算子。
-
3. 查看 Metrics 标签页:在算子的 "Metrics" 标签页,你可以找到 Paimon 暴露的所有指标。使用搜索框可以快速过滤,例如输入
paimon.table.write或paimon.table.compaction。 -
4. 建立 Dashboard:将关键指标(如下文所述)接入你的监控系统(如 Grafana),并建立趋势分析和告警规则。例如,当
run-count持续增长并接近stop-trigger时,发送告警。
-
• 核心监控指标:
-
•
write-buffer-used:写缓冲的使用情况。持续处于高位可能意味着需要增大缓冲或检查下游瓶颈。 -
•
spill-ops:缓冲溢出操作的次数。频繁的溢出可能表明磁盘 I/O 成为瓶颈。 -
•
run-count:每个桶内的 Sorted Run 文件数量。如果此值持续增长并接近stop-trigger,说明合并速度跟不上写入速度。 -
•
compaction-bytes/compaction-files:合并任务处理的数据量和文件数。可以用来评估合并的压力和效率。 -
•
commit-attempts/commit-failures:提交的尝试和失败次数。失败率升高可能指向元数据冲突或文件系统问题。
-
-
• 问题定位手册 (Troubleshooting Playbook):
-
• 小文件过多:检查
target-file-size是否设置过小,或者compaction-trigger是否设置过大。确认是否已启用 Dedicated Compaction Job。 -
• 写放大严重:
compaction-bytes指标远大于实际写入数据量。可能是compaction-trigger设置过小,导致过于频繁的合并。 -
• Checkpoint 超时:通常与
write-buffer-size过大,导致刷盘时间过长有关。也可能是文件系统或网络延迟导致。检查 Checkpoint 详细日志中的syncDuration和asyncDuration。 -
• 热点桶(数据倾斜):观察不同 TaskManager 的
write-rows指标,如果存在显著不均,则表明存在数据倾斜。可以考虑使用动态桶,或检查主键的设计是否合理。
-
5.4. 生产环境部署建议
-
1. 资源隔离:将 Flink 写入作业和 Dedicated Compaction 作业部署在不同的资源池中。
-
2. 启用高可用:为 Flink JobManager 和 Paimon 的元数据(如 Hive Metastore)配置高可用方案。
-
3. 快照生命周期管理:合理配置
snapshot.time-retained和snapshot.num-retained.min,定期清理过期的快照和数据文件,控制存储成本。 -
4. 版本控制:Paimon 仍在快速发展中,升级版本时务必仔细阅读发布说明(Release Notes),并在预生产环境中进行充分测试。
-
5. 充分测试:在上线前,务必在与生产环境相似的规模和负载下进行压力测试和稳定性测试,找到最适合您业务场景的参数配置。
通过遵循以上最佳实践,您可以构建一个稳定、高效、可扩展的 Paimon 数据写入服务,为您的实时数据湖仓平台打下坚实的基础。
5.5. 实战代码示例
本节提供完整的、可运行的代码示例,帮助您快速上手 Paimon 的开发。
5.5.1. Flink SQL:从 Kafka 实时同步到 Paimon
这是一个非常典型的 CDC 场景,将 Kafka 中的业务数据库变更日志(以 Debezium JSON 格式为例)实时同步到 Paimon 主键表中。
-- 步骤 1: 创建 Kafka CDC 源表
CREATE TABLE kafka_users_source (
`user_id` BIGINT,
`user_name` STRING,
`city` STRING,
-- Debezium 需要主键来生成正确的 changelog
PRIMARY KEY (`user_id`) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'topic' = 'mysql.users.cdc',
'properties.bootstrap.servers' = 'kafka-broker:9092',
'properties.group.id' = 'paimon-sync-group',
'scan.startup.mode' = 'latest-offset',
'value.format' = 'debezium-json'
);
-- 步骤 2: 创建 Paimon 目标表 (与 5.1.1 节示例类似)
CREATE TABLE paimon_users_sink (
`user_id` BIGINT,
`user_name` STRING,
`city` STRING,
`dt` STRING,
PRIMARY KEY (`user_id`, `dt`) NOT ENFORCED
) PARTITIONED BY (`dt`)
WITH (
'bucket' = '10',
'changelog-producer' = 'input',
'write-only' = 'true' -- 生产环境推荐
);
-- 步骤 3: 启动 Flink 写入作业
-- 这里我们假设源数据中没有分区键 dt,使用系统函数来生成
INSERT INTO paimon_users_sink
SELECT
user_id,
user_name,
city,
DATE_FORMAT(NOW(), 'yyyy-MM-dd') as dt
FROM kafka_users_source;5.5.2. Flink DataStream API (Java) 示例
对于更复杂的业务逻辑,您可以使用 DataStream API。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.Table;
public class PaimonDataStreamJob {
public static void main(String[] args) throws Exception {
// 1. 初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 2. 创建源表 (这里简化,实际可从 Kafka, etc. 创建)
// 假设源数据流已经转换成 DataStream<Row>
// DataStream<Row> sourceStream = ...;
// tableEnv.createTemporaryView("my_source", sourceStream);
// 或者直接用 SQL 创建源表
tableEnv.executeSql("CREATE TEMPORARY TABLE my_source (...) WITH (...)");
// 3. 创建 Paimon Catalog
tableEnv.executeSql("CREATE CATALOG paimon WITH ('type'='paimon', 'warehouse'='file:/path/to/warehouse')");
tableEnv.executeSql("USE CATALOG paimon");
// 4. 创建 Paimon 目标表 (如果不存在)
tableEnv.executeSql("CREATE TABLE IF NOT EXISTS my_paimon_table (...) WITH (...)");
// 5. 执行写入
// 使用 SQL
tableEnv.executeSql("INSERT INTO my_paimon_table SELECT * FROM my_source");
// 或者使用 Table API
// Table sourceTable = tableEnv.from("my_source");
// sourceTable.executeInsert("my_paimon_table").await();
// 在 DataStream API 中,通常推荐使用 SQL 来执行最终的 INSERT 操作,
// 因为它能更好地利用 Flink 的优化。
}
}5.5.3. Dedicated Compaction 作业的完整脚本
如 5.2.2 节所述,这是一个独立运行的 Flink 作业,用于处理后台合并。
-- flink-sql-client -f compact_job.sql
-- ############# compact_job.sql #############
-- 设置作业为流模式,使其长期运行
SET 'execution.runtime-mode' = 'streaming';
-- 设置一个清晰的作业名,便于在 Flink UI 中识别
SET 'pipeline.name' = 'paimon_compaction_users_table';
-- 设置 Compaction 作业的资源
-- 可以为它分配合理的并行度和内存
SET 'parallelism.default' = '4';
SET 'taskmanager.memory.process.size' = '4g';
-- 创建 Paimon Catalog (如果 Flink SQL Client 的默认配置中没有)
CREATE CATALOG paimon WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///paimon/warehouse'
);
USE CATALOG paimon;
-- 调用系统过程,为 'default' 数据库下的 'user_profile' 表
-- 启动一个 'streaming' 模式的合并作业。
CALL sys.compact('default.user_profile', 'streaming', 'paimon');
将此脚本保存为 compact_job.sql,然后通过 flink-sql-client 提交即可。
6. 总结
Apache Paimon 作为下一代流式数据湖存储的杰出代表,通过其创新的“湖格式 + LSM-Tree”架构,成功地解决了传统数据湖在实时更新和流批一体处理上的诸多痛点。本报告系统性地剖析了 Paimon 从顶层架构设计到底层技术实现,再到生产环境性能优化的完整技术栈,旨在为广大数据从业者提供一份全面而深入的实践指南。
核心要点总结:
-
1. 统一的流批存储:Paimon 的核心价值在于其原生支持流式和批量读写。主键表基于 LSM-Tree 实现了高效的实时更新(UPSERT/DELETE),而追加表则为高吞吐的事件流数据提供了低成本的存储方案。
-
2. 精巧的写入流程:Paimon 的写入路径是一条经过精心优化的流水线,通过写缓冲、排序刷盘、后台合并等机制,实现了高吞吐和低延迟。其与 Flink Checkpoint 机制的紧密结合,以及基于快照的原子提交,为数据写入提供了强有力的 ACID 保证。
-
3. 可控的性能调优:Paimon 提供了丰富的配置参数,允许用户在写入吞吐量、查询延迟、资源消耗和存储成本之间进行灵活的权衡。通过合理设计表结构(分区与分桶),并精细调优写缓冲、合并策略、文件大小等核心参数,可以在生产环境中实现可预测的性能表现。
-
4. 生产级运维能力:通过解耦写入与合并(Write-only + Dedicated Compaction)、内置丰富的监控指标体系以及完善的快照和分区生命周期管理,Paimon 已经具备了在复杂生产环境中大规模部署和稳定运行的能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)