ValueError: Worker failed with error ‘base_model.model.lm_head.weight is unsupported LoRA weight‘
在qwen3-8B模型微调过程中出现vLLM报错,提示"base_model.model.model.embed_tokens.weight is unsupported LoRA weight"。原因是训练时先注入LoRA后调整embedding层大小,导致LoRA权重包含不支持的embedding层。解决方法包括:1)检查并过滤safetensors文件中含"lm
问题出现
最近在qwen3-8B上做为微调结束后出现了一个错误
File "/opt/miniconda3/envs/unsloth/lib/python3.11/site-packages/vllm/entrypoints/openai/api_server.py", line 1791, in run_server await run_server_worker(listen_address, sock, args, **uvicorn_kwargs) File "/opt/miniconda3/envs/unsloth/lib/python3.11/site-packages/vllm/entrypoints/openai/api_server.py", line 1816, in run_server_worker await init_app_state(engine_client, vllm_config, app.state, args) File "/opt/miniconda3/envs/unsloth/lib/python3.11/site-packages/vllm/entrypoints/openai/api_server.py", line 1624, in init_app_state await state.openai_serving_models.init_static_loras() File "/opt/miniconda3/envs/unsloth/lib/python3.11/site-packages/vllm/entrypoints/openai/serving_models.py", line 85, in init_static_loras raise ValueError(load_result.message) ValueError: Call to add_lora method failed: Worker failed with error 'base_model.model.model.embed_tokens.weight is unsupported LoRA weight', please check the stack trace above for the root cause
查了下是说
LoRA 权重里还有 嵌入层(embed_tokens / embed) 的 adapter,被 vLLM 判定为“不支持的 LoRA 权重”。要解决,思路是把 LoRA 权重里不被 vLLM 支持的层删除 / 导出成不包含这些层的 LoRA。
先备份
cd /opt/chenrui/qwen3_sft/lora_think_sft/checkpoint-1500
mkdir -p backups
cp adapter_model.safetensors backups/adapter_model.safetensors.bak
cp adapter_config.json backups/adapter_config.json.bak1) 检查 safetensors 中有哪些键(快速定位哪些层被打了 LoRA)
Python 打印含 lm_head / embed / embed_tokens 等关键字的键:
from safetensors.torch import load_file
p = "/opt/chenrui/dataprepare/qwen3_sft/triage_sft/ucit_triage_lora_think/checkpoint-1500/adapter_model.safetensors"
w = load_file(p)
bad = [k for k in w.keys() if ("lm_head" in k) or ("embed" in k) or ("embed_tokens" in k) or ("embeddings" in k)]
print("Found keys count:", len(bad))
for k in bad:
print(k)
这一步会明确显示哪些不支持的层存在(例如 base_model.model.model.embed_tokens.weight.lora_A 之类)。
2) 如果确认存在 embed / lm_head 相关键 —— 过滤掉这些键并保存新的 safetensors
下面脚本会生成一个新的 adapter_model_vllm.safetensors(只保留安全的 LoRA 权重),并显示删除了多少行:
from safetensors.torch import load_file, save_file
import os
lora_dir = "/opt/chenrui/dataprepare/qwen3_sft/triage_sft/ucit_triage_lora_think/checkpoint-1500"
src = os.path.join(lora_dir, "adapter_model.safetensors")
dst = os.path.join(lora_dir, "adapter_model_vllm.safetensors")
weights = load_file(src)
print("Total keys before:", len(weights))
# 下面的 pattern 列表按需扩展;常见需要过滤的有 lm_head, embed, embeddings, word_embeddings
forbidden_patterns = ["lm_head", "embed_tokens", "embeddings", "word_embeddings", "embed"]
cleaned = {k: v for k, v in weights.items() if not any(p in k for p in forbidden_patterns)}
print("Total keys after:", len(cleaned))
print("Removed keys:", len(weights) - len(cleaned))
save_file(cleaned, dst)
print("Saved cleaned safetensors to", dst)
然后备份并替换(小心操作):
mv adapter_model.safetensors adapter_model.safetensors.bak mv adapter_model_vllm.safetensors adapter_model.safetensors
注意:上面过滤是“粗暴但有效”的做法——它把所有包含这些关键字的 LoRA 权重都删掉。通常我们只想删
lm_head和embed_tokens。如果你只想删lm_head与embed_tokens,把forbidden_patterns调整为["lm_head","embed_tokens"]即可。
3) 检查 adapter_config.json
打开看一下 adapter_config.json,确认 target_modules(如果有)是否列了不合适的模块,或者 base_model_name_or_path 是否正确。例如:
{
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj"],
"peft_type": "LORA"
}
如果 target_modules 中包含 lm_head 或 embed 之类的,需删除它们然后保存。
4) 重新启动 vLLM(使用原命令)
确保你替换后再启动:
python -m vllm.entrypoints.openai.api_server \
--model /opt/chenrui/qwq32b/base_model/Qwen3-8B \
--tensor-parallel-size 4 \
--quantization fp8 \
--dtype half \
--trust-remote-code \
--max-model-len 16384 \
--enforce-eager \
--host 0.0.0.0 \
--port 8100 \
--enable-lora \
--max-lora-rank 16 \
--lora-modules ucit_triage=/opt/chenrui/qwen3_sft/checkpoint-1500 \
--served-model-name Qwen3-8B-FP8
在日志中应不再看到 embed_tokens 或 lm_head 的 unsupported 错误;如果还有别的层提示 “unsupported”,重复检查并删除那些键(同上步骤)
启动正常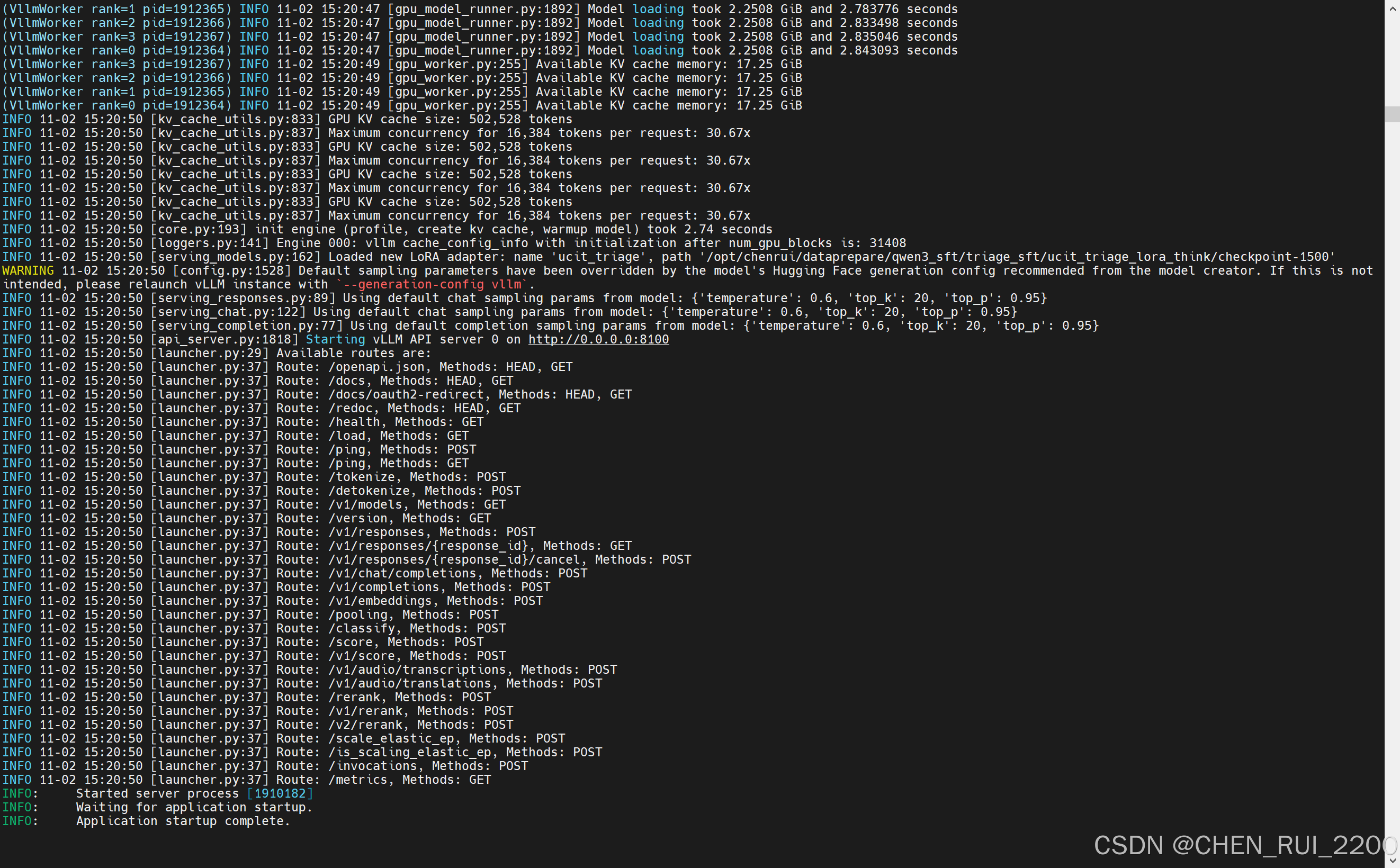
调试小工具:查找所有“不安全”键并列出(单行脚本)
python - <<'PY'
from safetensors.torch import load_file
w = load_file("adapter_model.safetensors")
for k in w:
if any(x in k for x in ("lm_head","embed","embeddings","word_embeddings","embed_tokens")):
print(k)
PY
后来我检查了下训练脚本有下面逻辑是改动后的,猜测原因出在这里
if __name__ == "__main__":
# ==============================
# 5. 加载模型和 tokenizer
# ==============================
print("Loading model and tokenizer...")
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=MODEL_PATH,
max_seq_length=MAX_SEQ_LENGTH,
dtype=None, # 自动选择最佳精度
load_in_4bit=True, # 4bit 量化以节省显存
)
# Qwen3 ChatML 配置
tokenizer.padding_side = "left"
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
special_tokens = ["<think>", "</think>"]
tokenizer.add_special_tokens({"additional_special_tokens": special_tokens})
# 调整 model embedding 大小
model.resize_token_embeddings(len(tokenizer))问题的根本原因:embedding resize + LoRA = 权重映射错位
执行的逻辑:
special_tokens = ["<think>", "</think>"] tokenizer.add_special_tokens({"additional_special_tokens": special_tokens}) model.resize_token_embeddings(len(tokenizer))
在 PEFT/Unsloth + LoRA 训练场景中 会产生如下连锁反应:
| 步骤 | 影响 |
|---|---|
1️⃣ add_special_tokens |
tokenizer 的词表变大了,比如从 151936 → 151938。 |
2️⃣ resize_token_embeddings |
这一步在 base model 上执行,会创建一个 新的 embedding 层,并随机初始化新增 token 的 embedding。 |
| 3️⃣ LoRA 训练开始时 | LoRA 会 hook(注入)进模型各个 target_modules。但如果你的脚本执行 resize_token_embeddings 之后,embedding 层对象的引用发生了变化。 |
| 4️⃣ LoRA 层被错误地附着到新的 embedding 层上 | 一旦 PEFT 发现有新层,它可能误以为需要在 embedding 层上也注入 LoRA 权重。 |
| 5️⃣ 保存 adapter 时 | adapter_model.safetensors 里就会包含 base_model.model.model.embed_tokens.* 或 lm_head.* 的 LoRA 权重。 |
| 6️⃣ 加载进 vLLM 时 | vLLM 检查时发现 embedding 层不是支持的 LoRA 目标(仅支持 transformer 内部投影层),于是报错:unsupported LoRA weight。 |
为什么 lm_head 也会出现
lm_head(语言建模输出层)通常 共享 embedding 权重(即 weight tying)。
当你调用 resize_token_embeddings() 后:
-
embedding 层变了;
-
lm_head.weight同步指向新的 embedding; -
如果你的 LoRA 配置是自动发现
target_modules,它会连lm_head一起打 LoRA(尤其是在使用 Unsloth/PEFT 自动 wrap 模式下); -
结果就是 adapter 里多出
lm_head.lora_A、lm_head.lora_B之类的键。
vLLM 为什么不支持这些层的 LoRA
vLLM 为了高性能推理,会对 embedding + lm_head 层做高度优化和并行映射。
这些层在加载阶段直接转成 CUDA 内核或 Triton 内核,不走通用 LoRA 路径,因此:
-
不允许在 embedding / lm_head 层上注入 LoRA;
-
只能在 attention 和 feedforward 模块(比如 q_proj、v_proj、up_proj 等)上打 LoRA。
所以只要 LoRA adapter 里包含这两类权重,vLLM 就拒绝加载。
建议修改训练
可以在训练时重新调整操作顺序,确保不污染 LoRA 层:
# 1. 先加载 tokenizer 并扩展特殊 token
special_tokens = ["<think>", "</think>"]
tokenizer.add_special_tokens({"additional_special_tokens": special_tokens})
# 2. 加载 base model 并立即调整 embedding 大小
model = AutoModelForCausalLM.from_pretrained(base_model_path, torch_dtype=torch.bfloat16)
model.resize_token_embeddings(len(tokenizer))
# 3. 再 wrap LoRA(重要!LoRA 要在 resize 之后)
model = FastLanguageModel.get_peft_model(
model,
target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj"],
r=16,
lora_alpha=32,
lora_dropout=0.05
)
# 4. 再进行训练 + save_pretrained
不要在 LoRA 已经注入后再执行 resize_token_embeddings,那样就会把 embedding 层也“污染”进 adapter。
总结
| 问题来源 | 说明 |
|---|---|
tokenizer.add_special_tokens + model.resize_token_embeddings |
导致 embedding 层对象被替换 |
| LoRA 注入时机错误 | 在 resize 之后再注入 LoRA 才安全 |
| 结果 | adapter_model.safetensors 中包含了 embed_tokens / lm_head LoRA |
| 解决方案 | ① 修改训练顺序 ② 清理不支持的层 ③ 避免在 embedding/lm_head 打 LoRA |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)