多智能体系统事件触发一致性控制仿真分析
本文分析了一个基于事件触发策略的线性多智能体系统一致性控制仿真代码。该实现针对一般有向图拓扑结构下的多智能体系统,设计了一种去中心化的事件触发控制机制,旨在实现所有智能体状态的一致性收敛,同时减少不必要的控制更新次数。
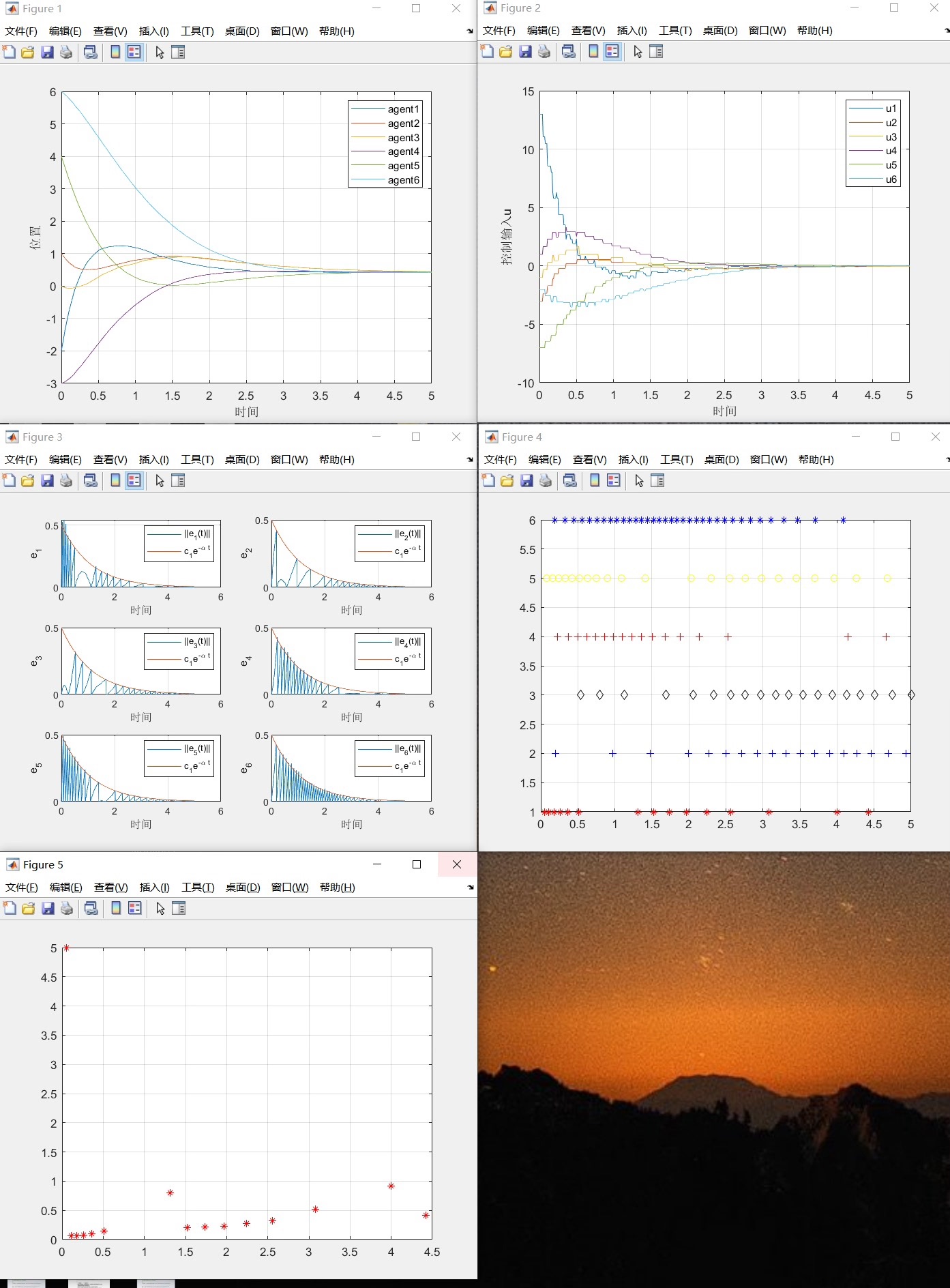
多智能体事件触发、一致性控制 状态轨迹图、控制输入图、事件触发图… 易于上手,有注释,有参考文献(与参考文献略有区别,适当变换能得到与参考文献相应的图形) 与文章不完全一致 图一:程序运行后的图形 图二:原文图形 图三:参考文献标题
1. 系统概述
本文分析了一个基于事件触发策略的线性多智能体系统一致性控制仿真代码。该实现针对一般有向图拓扑结构下的多智能体系统,设计了一种去中心化的事件触发控制机制,旨在实现所有智能体状态的一致性收敛,同时减少不必要的控制更新次数。
2. 系统架构与数学模型
2.1 通信拓扑结构
系统采用图论中的拉普拉斯矩阵描述智能体间的通信关系。代码中定义的拉普拉斯矩阵L为6×6矩阵,表示六个智能体构成的网络拓扑。该矩阵的非零非对角元素表征了智能体之间的信息传递方向与权重,对角线元素则代表每个智能体的入度信息。
2.2 控制策略核心思想
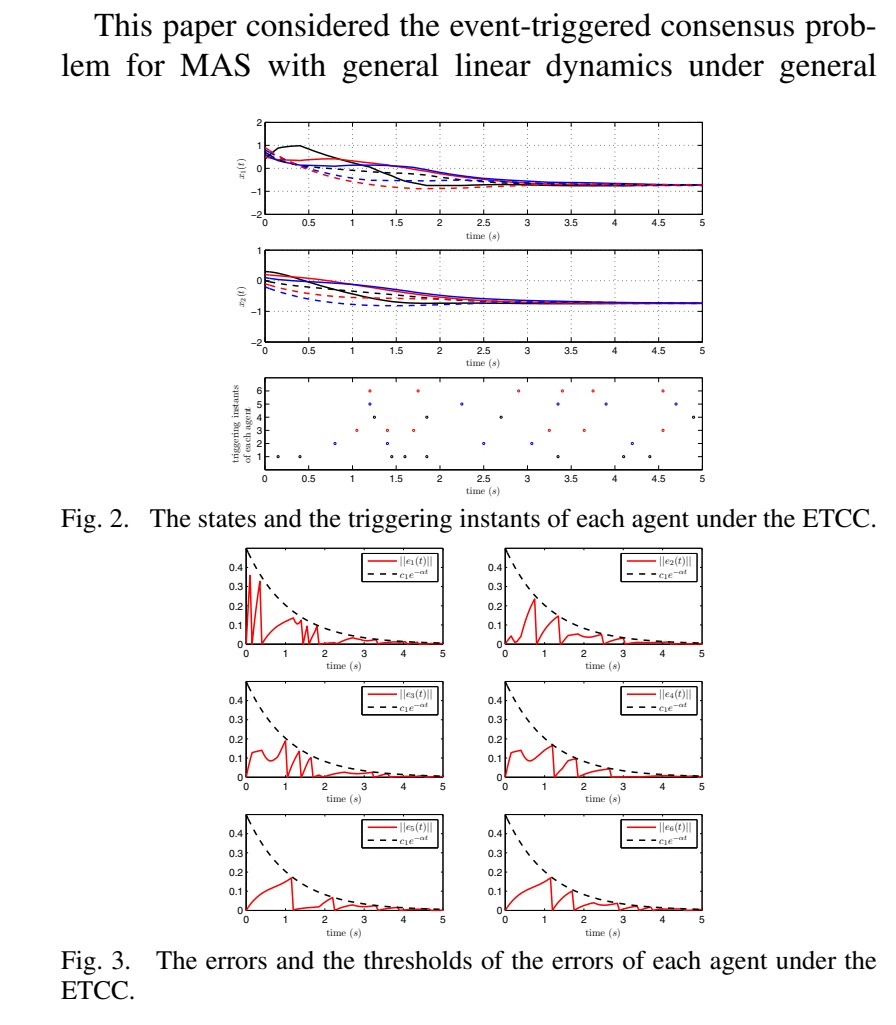
系统采用事件触发控制机制,与传统的时间触发控制不同,事件触发控制仅在特定条件满足时才执行控制更新,从而显著减少通信与计算资源消耗。每个智能体独立监测自身的状态误差,当误差超过动态阈值时触发控制更新。
3. 核心算法实现
3.1 初始化设置
系统初始化阶段设置了关键参数:
- 初始状态向量:定义六个智能体的初始位置
- 控制增益参数:α和c₁,用于调节收敛速度和触发阈值
- 仿真时间参数:总仿真时长T和离散时间步长dt
3.2 主循环逻辑
仿真采用离散时间步进方式,在每个时间步内执行以下关键操作:
状态监测与误差计算
每个智能体持续监测当前状态与最近触发时刻状态之间的差异,形成测量误差向量。这一误差是判断是否触发控制更新的关键指标。

动态触发阈值机制
系统采用指数衰减的触发阈值函数:c₁·exp(-α·t)。这种设计在系统初始阶段允许较大的误差容忍度,随着时间推移逐渐收紧触发条件,既保证了初始阶段的快速响应,又确保了最终的控制精度。
事件触发判断逻辑
每个智能体独立判断是否满足触发条件:
if 测量误差范数 ≥ 动态阈值 then
更新触发状态
记录触发时刻
end这种分散决策机制避免了中心协调器的需求,增强了系统的鲁棒性。
状态更新策略
控制输入基于拉普拉斯矩阵与触发状态的乘积计算,采用欧拉法进行状态更新。仅当事件触发时,智能体才广播其状态信息,显著降低了通信负担。
4. 数据记录与分析
4.1 关键数据采集
系统在仿真过程中详细记录多类数据用于性能评估:
- 状态轨迹数据:记录所有智能体在全部时间点的状态演化
- 控制输入序列:保存各时刻的控制作用量
- 触发时间序列:标记每个智能体的具体触发时刻
- 误差演化数据:跟踪测量误差与阈值的相对关系
4.2 可视化分析
代码提供了全面的可视化功能,包括:
- 状态收敛曲线:展示多智能体状态趋于一致的过程
- 控制输入变化:呈现控制信号的时序特性
- 误差阈值比较:直观显示事件触发条件的满足情况
- 触发时刻分布:以散点图形式展示各智能体的触发模式
5. 算法优势与特点
5.1 资源效率
通过事件触发机制,系统大幅减少了不必要的控制更新和通信传输。仿真结果显示,智能体仅在误差积累到一定程度时才进行状态传输和控制计算,有效节约了网络带宽和计算资源。
5.2 收敛保证
尽管采用间断的触发更新方式,系统仍能保证所有智能体状态渐近趋于一致。动态阈值的指数衰减特性确保了最终的控制精度。
5.3 分散化特性
每个智能体仅依赖本地信息和邻居的触发状态信息,无需全局通信或中心协调,增强了系统的可扩展性和可靠性。
6. 应用前景
这种事件触发控制框架适用于各类资源受限的多智能体应用场景,如无人机编队控制、分布式传感器网络、智能电网协调控制等。其平衡性能与资源消耗的设计理念为实际工程应用提供了有价值的参考。
该仿真代码完整实现了一个理论算法从数学模型到数值仿真的全过程,为研究分布式事件触发控制提供了实用的实验平台和验证工具。通过调整拓扑结构、控制参数和触发条件,可以进一步探索不同场景下的系统性能边界和优化策略。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)