李宏毅机器学习笔记33-38
本周继续学习李宏毅老师2025春季机器学习课程,学习内容是adversarial attack的相关概念以及进行白盒,黑盒攻击的相关原理及方法;domain shift问题的概念以及部分解决办法domain adversarial training;Deep reinforcement Learning相关基本概念,训练的过程及如何控制actor的行为,policy gradient中评价A的定义
目录
Fast gradient sign method(FGSM)
7. Deep reinforcement Learning(RL)
Monte-Carlo(MC) based apporach
Temporal-difference(TD) apporach
13.inverse reinforcement learning(IRL)
摘要
本周继续学习李宏毅老师2025春季机器学习课程,学习内容是adversarial attack的相关概念以及进行白盒,黑盒攻击的相关原理及方法;domain shift问题的概念以及部分解决办法domain adversarial training;Deep reinforcement Learning相关基本概念,训练的过程及如何控制actor的行为,policy gradient中评价A的定义及计算方法和需要注意的问题以及exploration的概念;RL中的Critic,包括critic的基本概念,两种训练方法和差异,如何应用在actor上以及应用在actor后计算方式,reward shaping和inverse reinforcement learning(IRL)的基本概念及相关知识。
Abstract
This week, I continued studying Prof. Hung-yi Lee's 2025 Spring Machine Learning Course. The learning content covered adversarial attack concepts along with principles and methods for conducting white-box and black-box attacks; the concept of domain shift problems and partial solutions including domain adversarial training; fundamental concepts of Deep Reinforcement Learning, its training process, methods for controlling actor behavior, the definition and calculation of advantage (A) in policy gradient along with related considerations, and the concept of exploration; the Critic in RL, including its basic concepts, two training methods and their differences, application on actors and corresponding computational approaches, as well as fundamental concepts and relevant knowledge of reward shaping and Inverse Reinforcement Learning (IRL).
1.adversarial attack概念
在实际应用中,network不仅仅需要正确率高,还需要能够应付人类故意骗过network的行为。举一个例子,我们有一个影像辨识系统,给他一张照片begin image,可以告诉我们这张照片属于什么类别,下图示例中begin image属于猫的类别。现在我们在照片上加入非常小的杂讯,即一张照片可以看作是一个非常长的向量,我们在向量的每一个维度上加入一点小小的杂讯。加入杂讯的照片(attacked image)一般用肉眼无法辨别,我们期待attacked image丢入network输出不是猫。攻击可以分为两种攻击,一种是无目标攻击,只要让network输出不是猫就算成功。
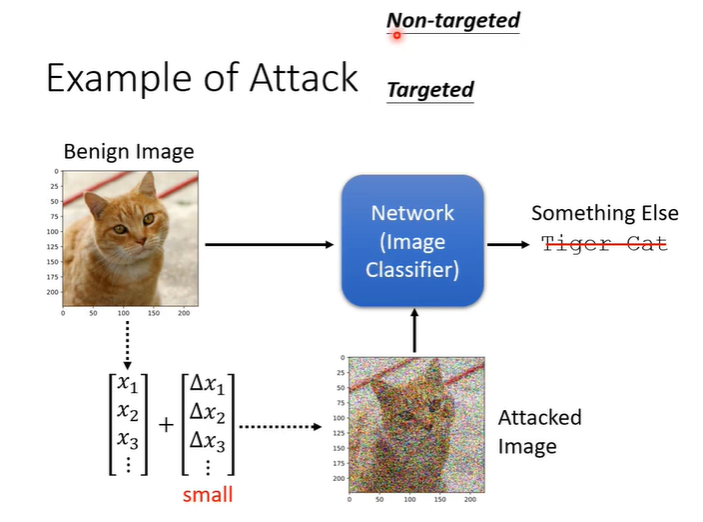
另一种更困难的攻击是有目标的攻击,此时我们需要network输出不是猫而是别的东西,比如说加入杂讯后希望network输出海星,把猫误判为海星才算成功。在一个50层的ResNet中,输入begin image,输出是tiger cat,信心分数为0.64。在加入杂讯后在让ResNet判断,输出是Star Fish,且信心分数为1。

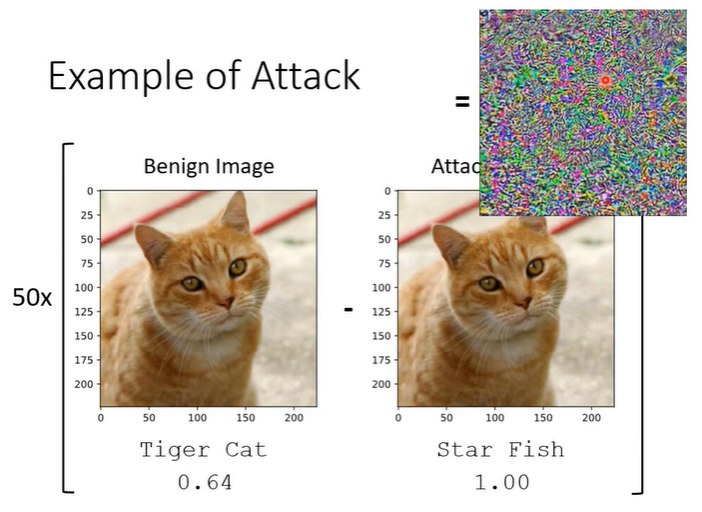
将两张照片相减并将差距放大50倍会得到下图的结果。
2.如何做到adversarial attack
输入是一张图片X0,network是一个function称为f,输出是一个distribution成为value。假设network参数是固定的,我们要找出无目标攻击的杂讯,需要一张新的图片X,作为输入时它的输出为y,我们希望y与正确答案的差距越大越好。定义一个loss function为L,L是y与正确答案的差距取一个负号,这样得到最小的L就是y与正确答案的差距最大值。如果是有目标的攻击,就不仅需要y与正确答案的差距越大越好,还需要y与目标答案越近越好,此时的L就可以写为y与正确答案的差距的负值与y与目标答案的差距相加。
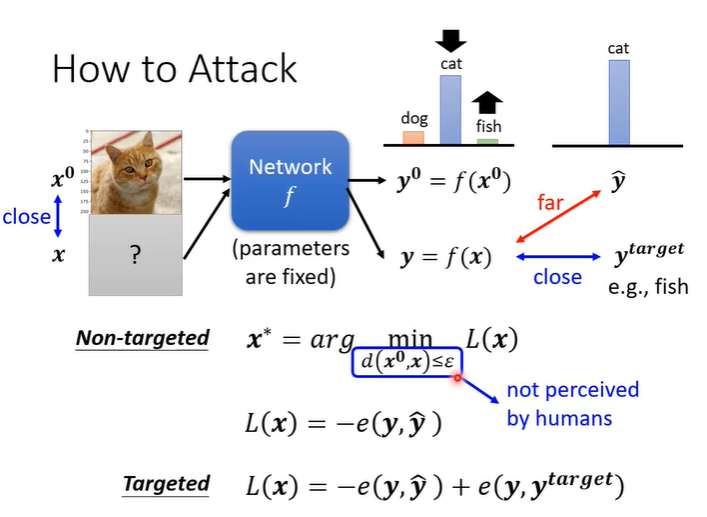
除此之外还有一个限制,就是X与X0之间的差距要小到人眼无法察觉。如何计算两张图片的差距呢?两张图片都视为一个很长的向量,X与X0相减得到。一种L2-norm是将
的每一个数值拿出来取平方在做加法的和作为距离。另一种L-infinity,是取
中绝对值最大的数值作为距离。

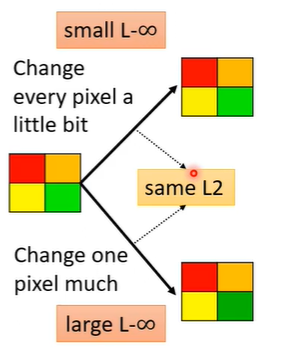
对于人类的感知来说,我们选择L-infinity更好。举一个例子,下图中的四色方块,一个是四个颜色都做了一点微小的改变,一个是集中改变绿色的小块,他们的L2-norm是相同的,但是集中改变颜色的L-infinity更大,从这个例子中L-infinity更接近人类的感知,更适合做攻击。
3.Attack approach
我们首先要找一个X去minimize loss的值,先去除掉X的限制,这就普通的训练模型没有差别,只是从调整参数变为调整输入(加色参数是固定的),用的一样是gradient descent。初始化的值为X0,之后就和普通的gradient相同,只是gradient不是network的参数,而是输入的图片对loss的gradient,输入的图片视为向量也就是去计算向量X中每一个数值对L的偏微分,然后用gradient去更新image就结束了。
接下来我们将X的限制加入。方法很简单,我们更新完image之后,发现X与X0的差距过大,我们就把X更改为符合限制的Xt。举例来说,如下图中右侧,方框为最大差距,更新完之后处于方框外,将点拉回到方框内即可。
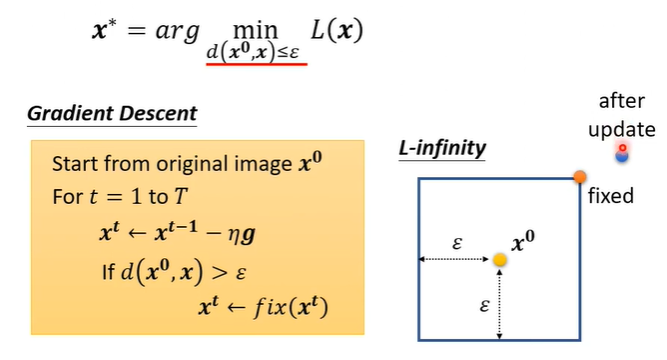
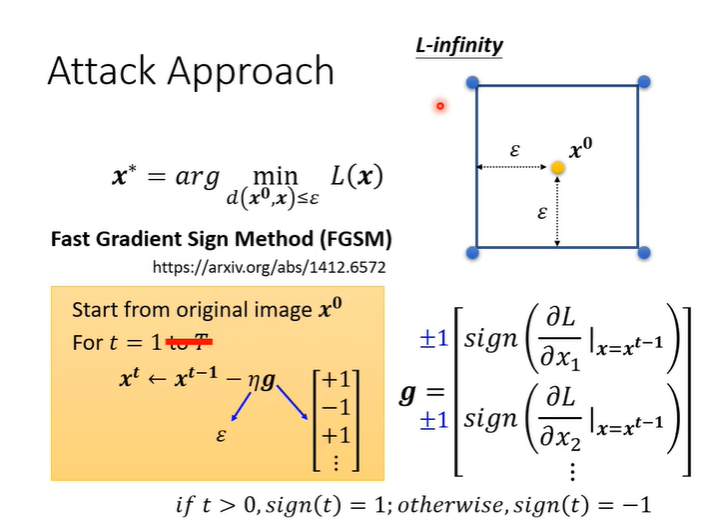
Fast gradient sign method(FGSM)
FGSM是一种最简单的attack的方法,它只更新一次。在g这边做了一个特别的设计,它不直接使用gradient descent的值而是取一个sign,sign()的意思是如果括号内的值小于0就输出-1,括号内的值大于0就输出1,最后得到的效果就是,一定会落在蓝色方框内的四个角落。
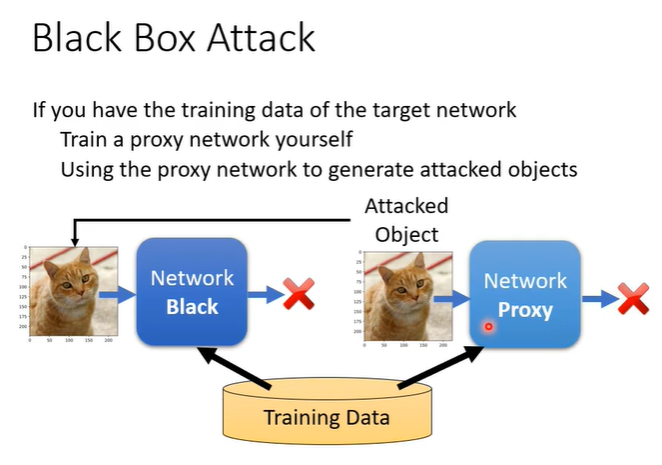
4.Black Box attack
知道模型参数的叫做白箱攻击,不知道模型参数的叫做黑箱攻击。黑箱攻击如何实现?假设知道是用什么资料训练的,我们就可以训练一个proxy network去模拟我们要攻击的对象,可以成功攻击proxy network也许就能攻击我们不知到的black network。
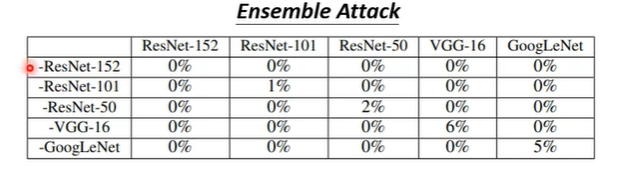
如果没有训练资料的情况下,就可以自己输入一堆图片,获得输出,用这些当作训练资料去训练一个proxy network进行攻击。Black Box attack的成功率还是很高的,下图所示的数据中,非对角线的表示黑箱攻击,数据表示模型正确的概率,概率越低表示攻击越成功。在黑箱攻击时,无目标攻击的成功率还是很高的。

另一种攻击方法成功率更高,行代表被攻击的模型,列代表5个模型中被去除的模型,即对角线为黑箱攻击。不难看出,当一个image可以同时骗过多个network时,骗过一个不知道参数的黑箱network也很容易成功。
5.domain shift
假设训练资料与测试资料分布不同会怎么样呢?举一个例子,假设数字辨识模型训练时是黑白的数字,但测试时是彩色的会发生什么事情?在黑白测试资料上会有很高的正确率,但是在彩色测试资料上就达不到及格分数。所以一旦训练资料与测试资料存在差异,训练出来的模型很可能会“坏掉”。这种问题叫作domain shift。

domain shift其实有很多类型,刚刚提到的是模型输入的资料分布有变化,还有另外一种输出的分布也有变化,举例来说就是,在训练资料上,每个数字的输出可能是一样的,但是在测试资料上某个数字的输出可能性特别大。此外还有一种特别罕见的,输入输出分布虽然一样,但是他们的关系变了。
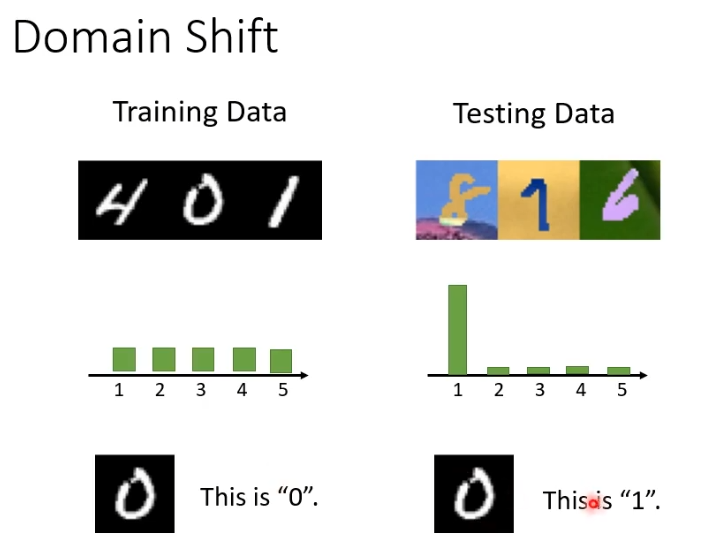
6.domain adversarial training
训练资料称为source domain,测试资料称为target domain,假设有一些标注过的资料,我们希望可以通过这些资料训练出一个模型,这个模型可以用在不一样的domain上。

想要做到把模型用在不一样的domain上,在训练时就需要对target domain有一定的了解。一种情况是在target domain上有少量标注的资料,这种情况就可以用target domain来微调在source domain上训练出来的模型(类似BERT),但是要注意overfitting的情况。

另一种情况是,在target domain上有大量的资料,但是没有标注。例如有很多有颜色的数字图片,但是没有标注。
解决这个问题的基本想法是找一个feature extractor(本身是network),它以图片作为输入,输出一个向量。虽然source domain和target domain的图片表面不一样,但是期望feature extractor可以把他们不一样的部分去掉,抽取出共同部分,无视掉颜色的差异。这样就可以用这些feature训练一个模型直接用在target domain上。
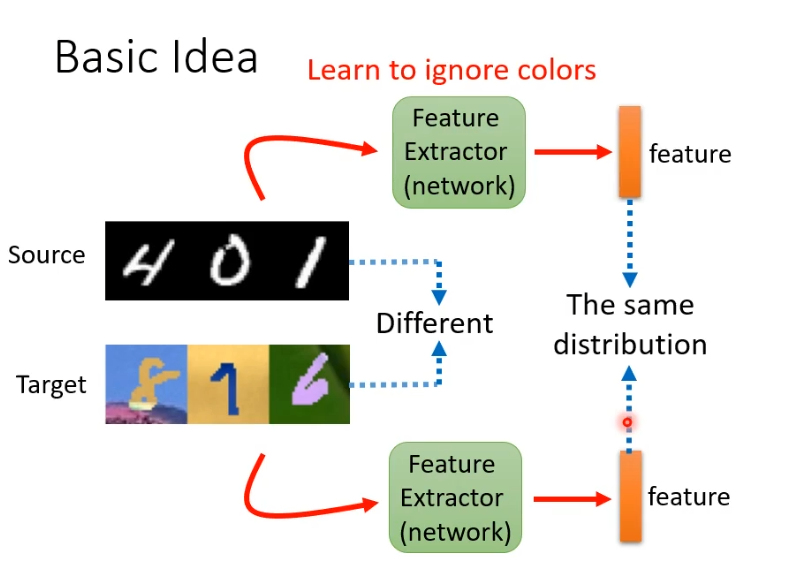
如何找出这样的feature extractor?可以把一个一般的classify分为feature extractor和label predictor两个部分。我们将source domain和target domain的图片丢进去把feature extractor的输出拿出来看。要让他们的输出看不出差异,即红色和蓝色的点分不出差异。
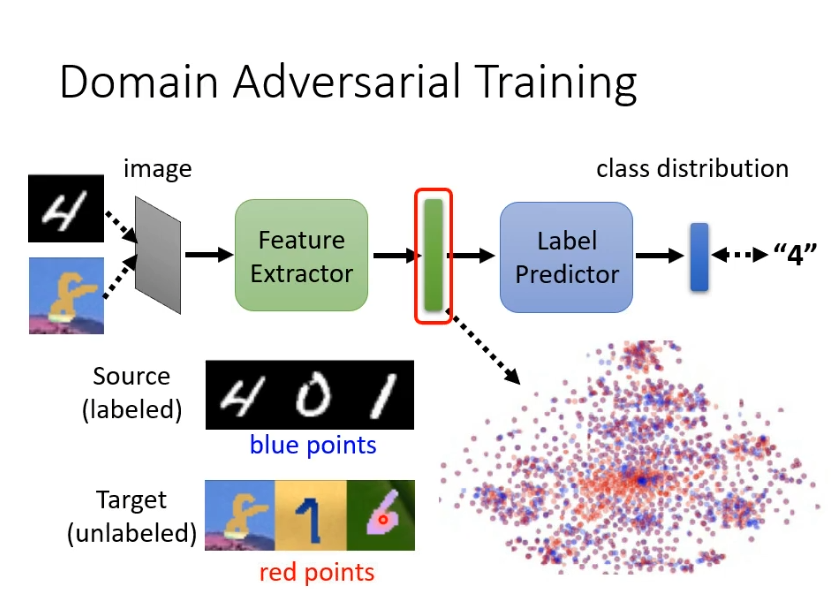
想要红色和蓝色的点分不出差异就需要domain adversarial training技术,要做的是训练一个domain的分类器,即一个二元分类器,判断输入的向量来自于source domain还是target domain。feature extractor的训练目标就是去骗过这个domain的分类器。
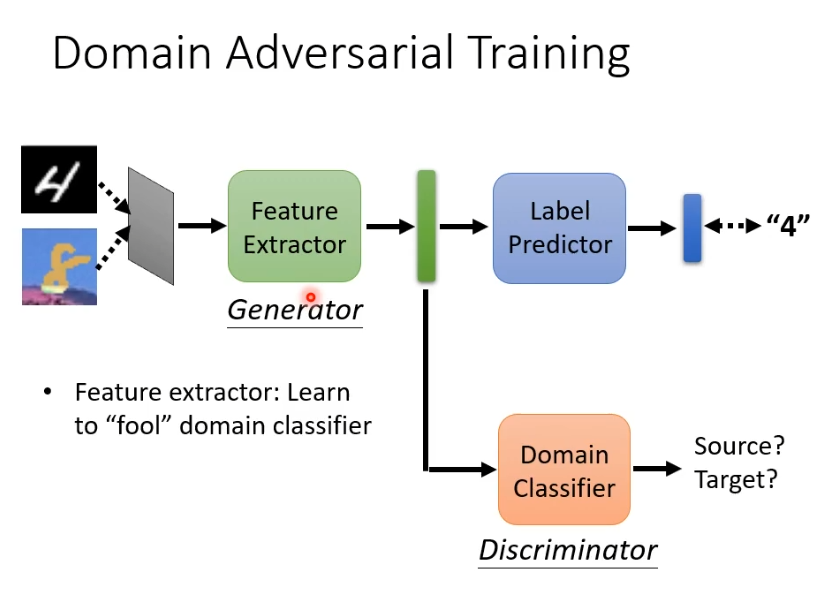
但是这样的方法存在一点问题,我们训练的目标是蓝色与红色的点分布接近,在下图中的两种情况,更希望右侧的情况发生,那么我们需要让红色的点远离分界线。
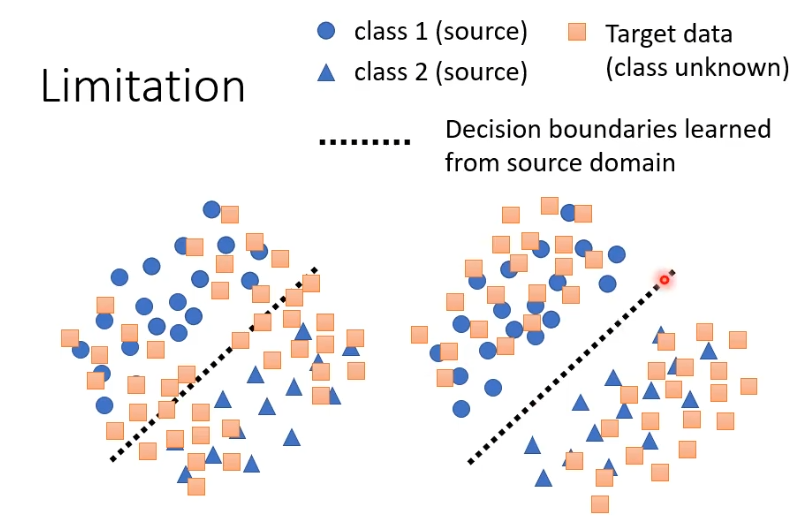
举例来说,一个简单的做法是一张未标注的图片虽然我不知道它属于哪个类别,但是希望它离分界线越远越好。如果输出的结果特别集中,就离分界线远,输出结果每个类别都非常接近,就离分界线近。
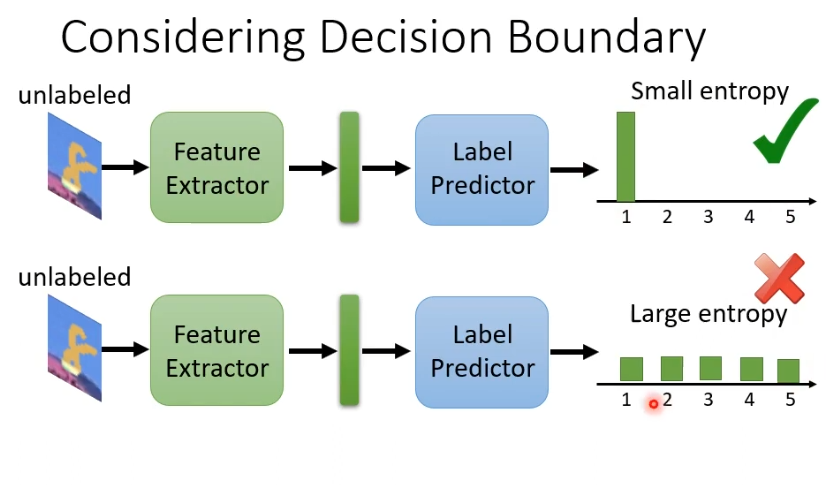
7. Deep reinforcement Learning(RL)
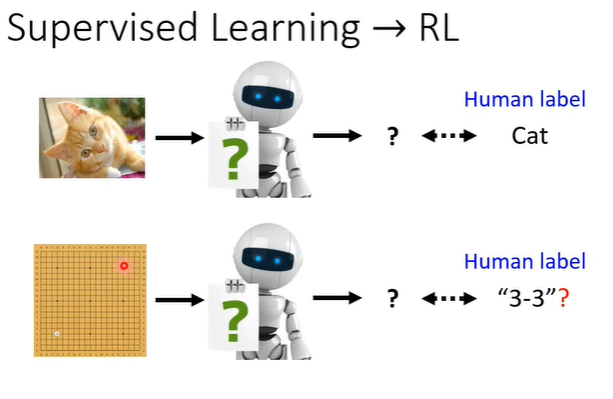
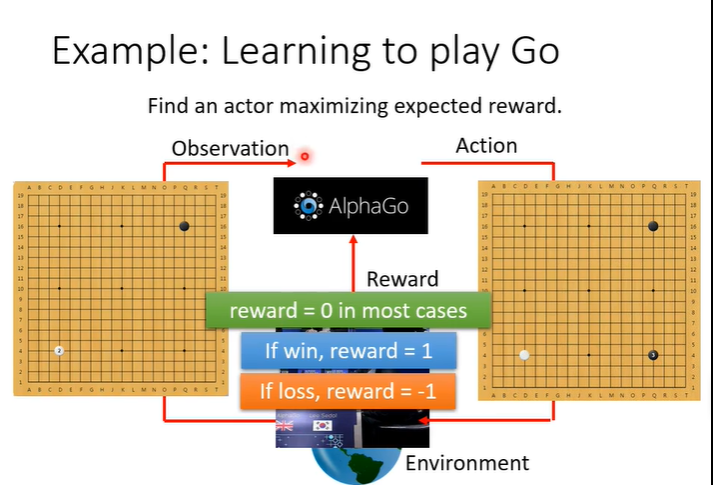
RL面向的问题与我们之前所学的supervised learning不同,supervised learning是给一个输入,告诉它应该输出什么。而RL是当给机器一个输入时,我们不知道最佳输出是什么。假设教机器下围棋,我们根本不知道下一步下在哪里是最好的。当收集标注资料很困难,或者正确答案人类也不知道时,就可以考虑使用RL。
机器学习就是找function,RL找的函数就是下图中的actor,在RL中有actor和environment,他们会进行交互,environment会给actor一个observation作为actor输入,action作为输出会影响environment,这个过程中environment还会不断给actor一些reward(让actor判断action是好是坏),而actor这个function的目标是maximize从environment获得的reward的总和。
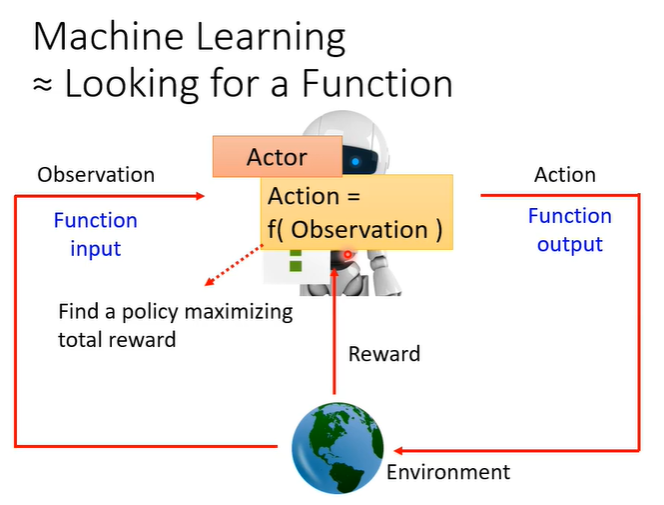
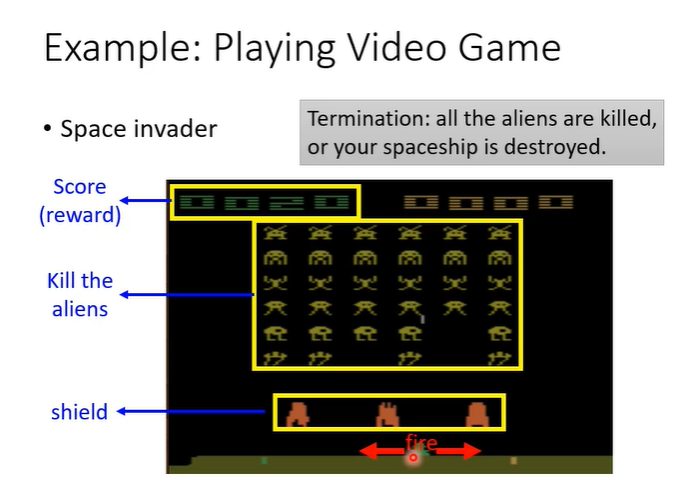
以space invader为例,让机器去玩这个简单的小游戏。游戏玩法:下图中,绿色的部分是被操纵的东西,可以左右移动和射击(action),要做的事情就是击杀上面的外星人(黄色部分),橙色部分是防护罩,会被自己射击打掉,也会抵挡外星人攻击,击杀外星人会得到分数(reward),当所有外星人被击杀时或绿色部分被击杀时,游戏结束。
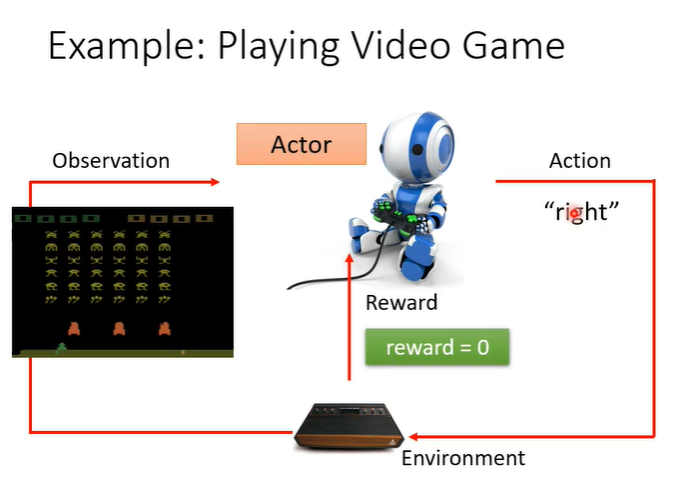
actor就是机器,environment就是游戏,observation是游戏画面,可以采取的行为action是“左”“右”“开火”,得到的分数为reward。当action为“右”,reward则为0(向右并不会击杀外星人)。
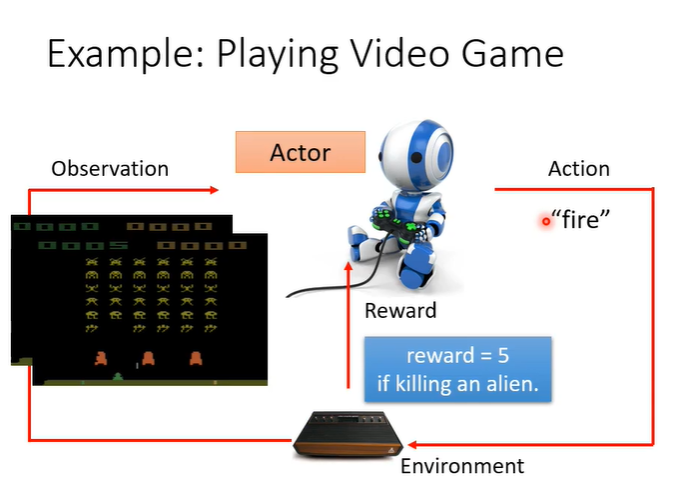
此时有新的画面作为输入,那么会输出新的action为“开火”,假设杀掉一个外星人为5分,得到分数,此时reward为5。学习的目标就是使用actor在游戏中可以得到的reward总和最大。
对于下围棋来说,输入就是棋盘,输出就是下一步落子的位置,然后环境在下白子,作为新的输入,这样反复下去可以让机器下围棋。但是在下围棋时,我们采取的任何行为都没办法得到reward,通常会定义赢了得到1分,输了得到-1分,只有在游戏结束时才能得到reward。
8.训练方法
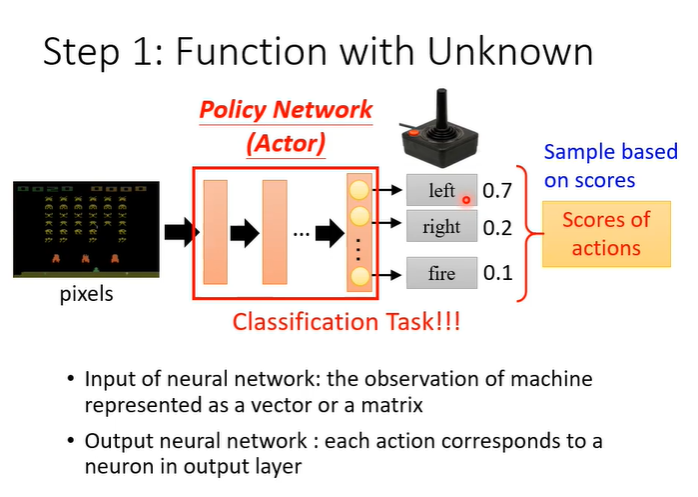
在RL中,actor就是network,通常称为policy network,输入就是游戏画面,输出就是每一个可以采取的行为的分数,根据分数采取行为,通常将分数当作几率,如下图所示70%向左,20%向右,10%开火,这样的好处是,当遇到同样的游戏画面时,做出的行为略有不同,这样的随机性对游戏也许是重要的。
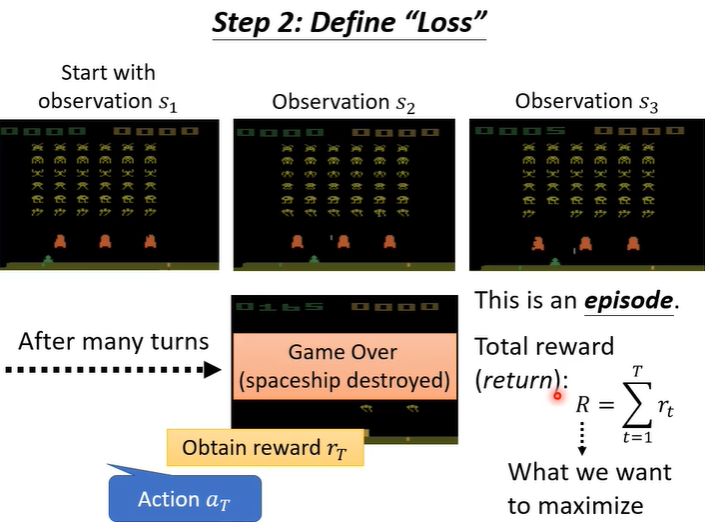
从游戏开始到结束(称为episode),游戏会采取很多行为,,每一个行为都可能得到reward,所有的reward集合起来得到total reward(R)。我们训练的目标就是R越大越好。那我们定义RL的loss就可以是-R。
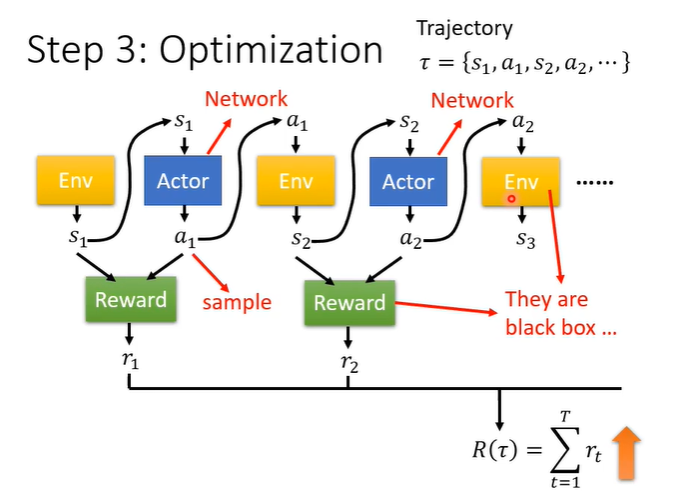
整个游戏过程如下图所示,环境env把画面s1输入actor,actor输出a1给env,env在输出s2给actor作为输入,如此反复直到游戏结束,这个过程产生的序列称为trajectory,根据互动过程会得到reward,将reward作为一个函数,输入是画面s和行为a,输出为r,所有的r集合起来得到R。optimization的问题是找一组actor的参数,让R越大越好。但是存在其他的问题,首先是actor的输出是随机的,同样的s不一定产生一样的a;还有一个更大的问题是,env和reward不算network且也可能具有随机性,他们只是一个黑盒子。
解决问题之前,先看我们如何控制actor。假设我们想要让actor看到s就向左,距离用cross-entropy计算,我们就会定义一个loss,让输出a与“向左”之间的loss最小;如果我们不想让actor做什么,就可以反过来,定义loss为-L,让输出与行为之间的loss最大。
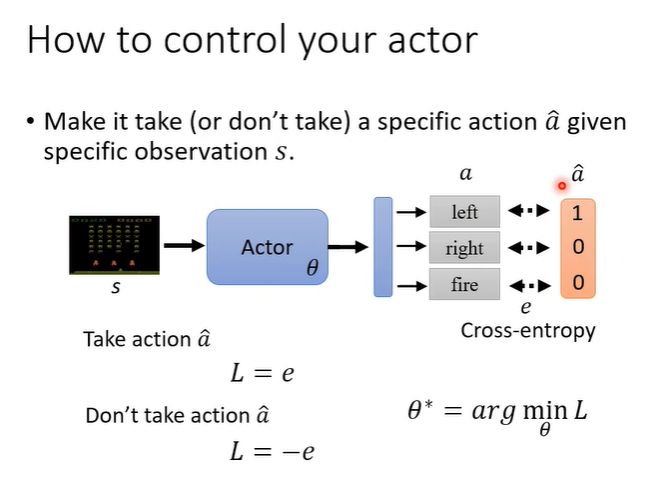
将这两种loss相加就可以达成控制actor的效果。
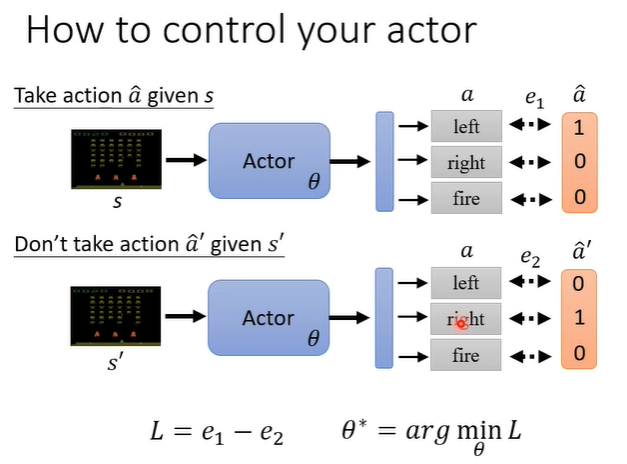
也可以进行扩展,不在局限于1和-1,希望在两种行为之间有更强烈的偏向意愿。在L求和前,乘上An。这样训练下去就得到一个我们期待行为的actor。
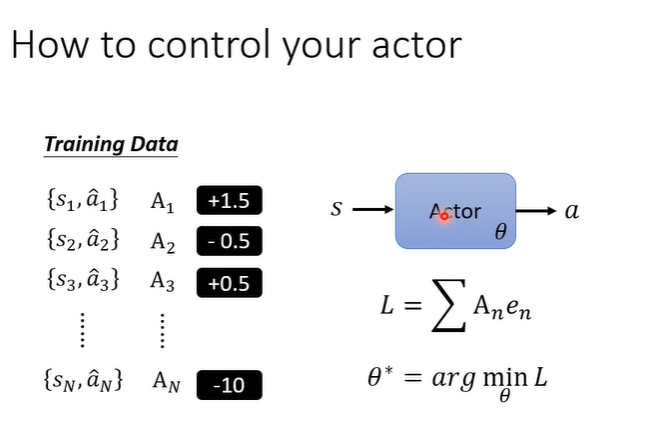
9.policy gradient A
控制actor的行为,重点在我们如何定义A
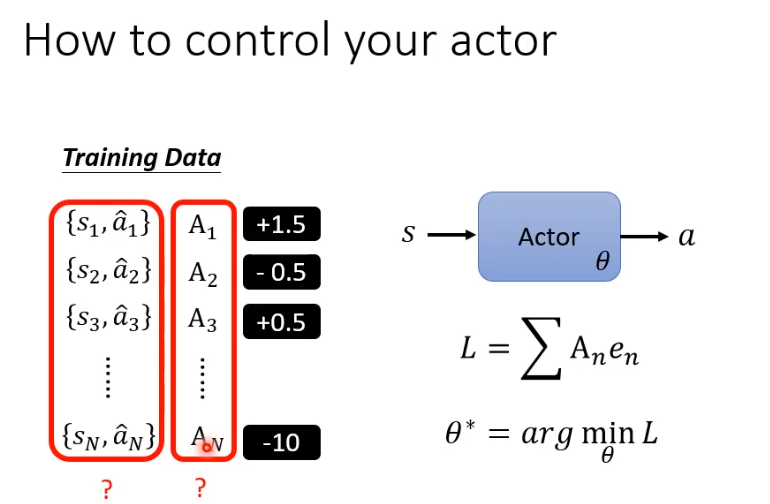
先用一个最简单但不正确的方法帮助理解,收集到足够多的s和a的资料后,用A对他们进行评价,将reward作为A的评价,reward为正就希望偏向做这样的行为,为负就不希望做这样的行为。
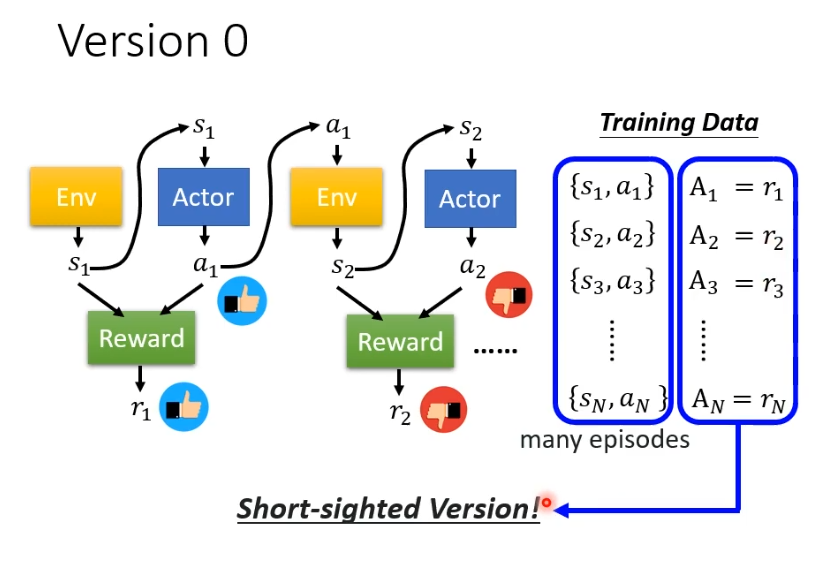
但这样训练得到的actor并不好,因为我们可能需要左右移动之后射击才会得到reward,但是左右移动的reward为0,这并不代表左右移动不重要。如果照这样训练,得到的actor只会开火。
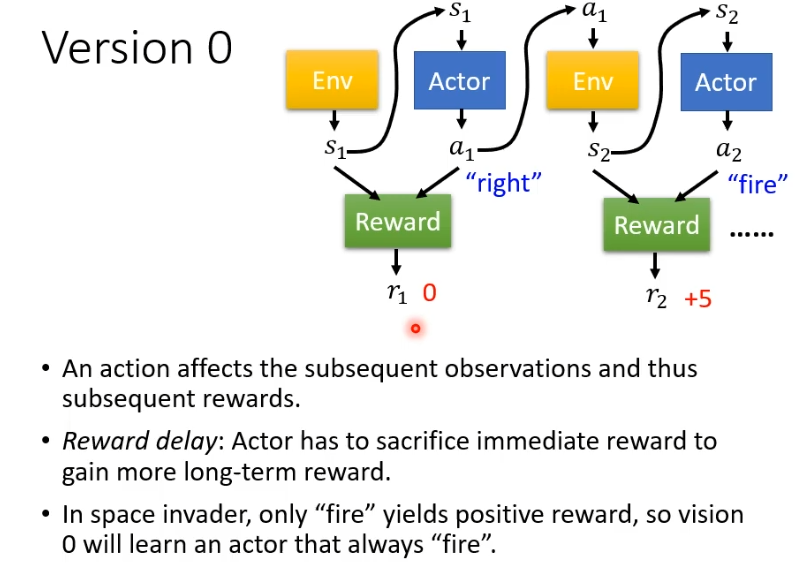
正确的做法是,a1有多好不取决于r1而是取决于r1之后的所有r,把他们加起来得到一个数值G1,把G1作为A,A2,A3以此类推。
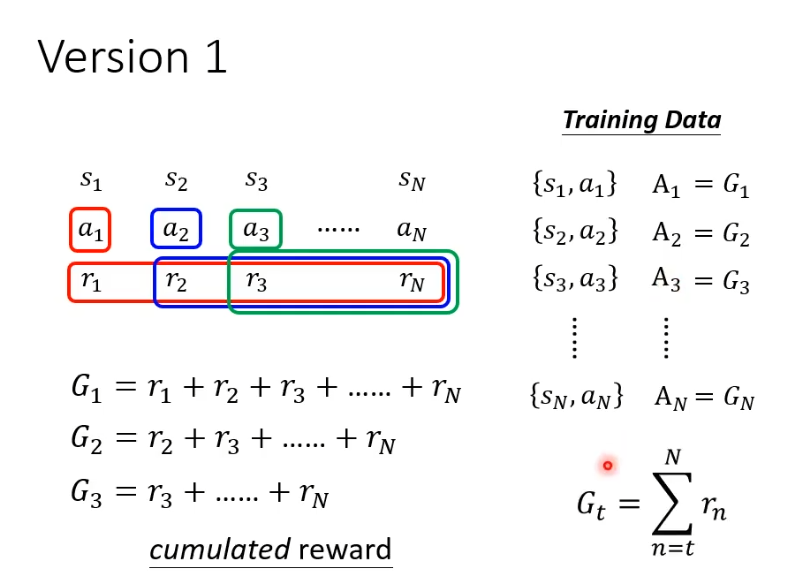
当游戏非常长时,a1的影响力可能并不会影响到全部reward,因此对G进行改进得到G',在之后的r增加系数,每到下一个就多乘一次系数
,这样越远影响力就越小。

但好或坏是相对的,可能所有的行为得到分数都是正的,就会导致有些不好的行为,仍然鼓励actor去做,因此需要做标准化,还需要让所有的G'减去一个baseline B,目的是为了让A有正有负。

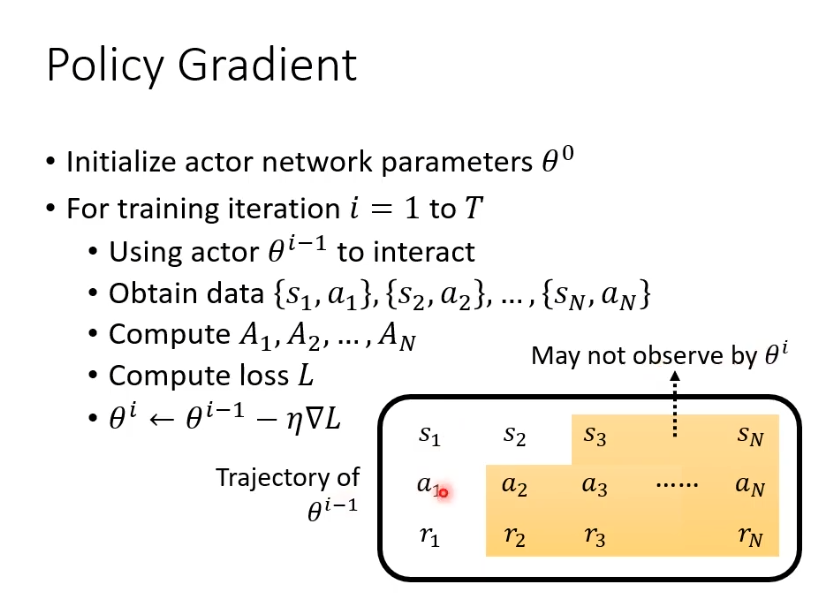
整个过程总结一下,首先需要定义初始参数,假设训练T轮,用actor与环境互动得到s和a,计算评价A,计算loss去更新参数。

复杂的是收集资料在循环内,也就是我们每一次更新参数都需要重新收集资料,每次收集的资料只能更新一次参数。
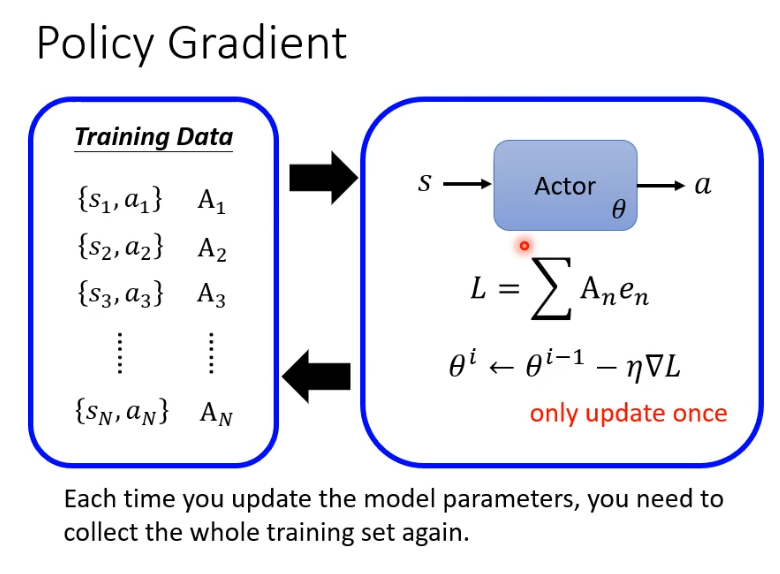
出现这样状况的原因是,每一轮的行为不同。假设第i轮和第i-1轮他们在s1都会采取a1,但是在s2时他们采取的行为就不一样了,所以一轮的资料只能训练一次。
10.exploration
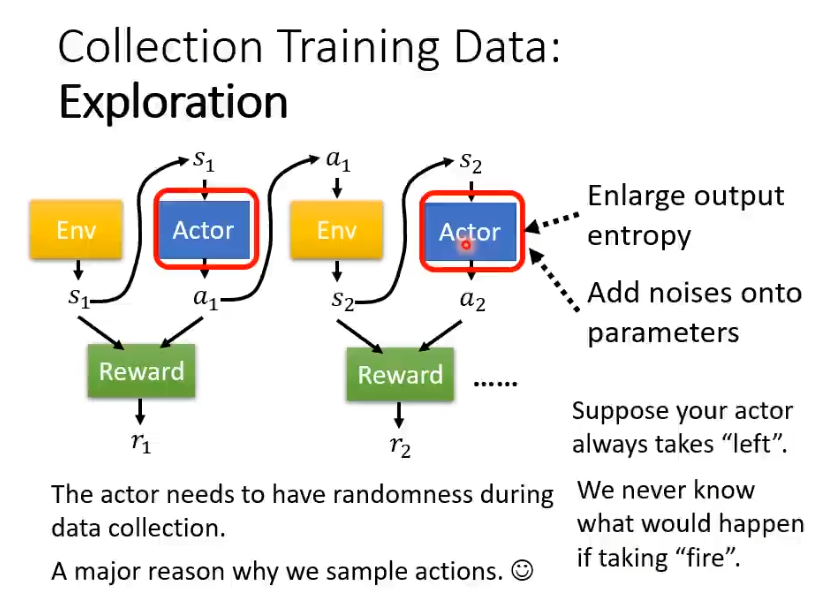
actor执行行为是需要一定的随机性的,随机性不够可能会导致无法训练起来。假设actor只会向右移动,从来不知道开火,如果它从来不开火就永远不会知道开火这件事情是好还是不好。所有在训练过程中,是需要一定的随机性的,这样才能收集到更多的资料。为了加大随机性,可能会主动采取一些行为,比如刻意加大输出的entropy或者在参数上加入噪声让actor每次的行为都不一样,这就是exploration。
11.Critic
critic给作用是评估一个actor的好坏,定义一个函数V(s),输入是游戏状况s,输出是上一节提到的G'(discounted cumulated reward),但此时游戏并未结束,V(s)是预测actor得到什么样的reward。下图中表示不同轮次的actor。

critic有两种训练方法
Monte-Carlo(MC) based apporach
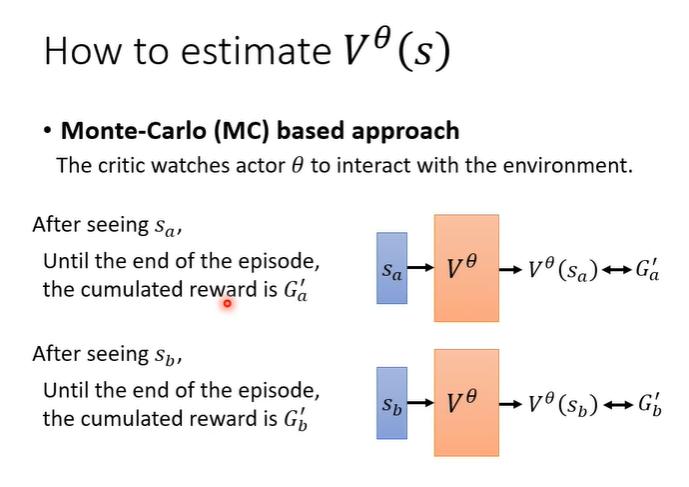
MC方法是将actor与环境互动很多轮,得到很多训练资料,当看见s_a时输出应该与G'_a越近越好,这是一种很直观的做法。
Temporal-difference(TD) apporach
TD方法是希望不用玩完整场游戏才能得到训练资料,而是看见s_t,a_t,r_t,s_t+1就可以拿来更新V(s)的参数。这样的好处是当游戏时间较长甚至不会结束时,同样可以训练V(s)。观察V(s_t)与V(s_t+1),不难看出他们的关系,训练方法就是计算V(s_t)与V(s_t+1),虽然不知道他们应该是多少,但是知道他们应该符合他们的关系式。所以可以通过{s_t,a_t,r_t,s_t+1}这样一笔资料进行训练。

MC与TD存在一些差异,下图所示的8个episodes用于计算V(s),用MC会自然而然的得到1,而用TD会得到3/4,原因在于假设不同,MC假设是s_a与s_b是有关联的,而TD是假设s_a与s_b是无关联的,只是关于s_a的资料太少只看见了s_a使得r=0的情况.

Critic应用在actor
A做标准化时,需要让所有的G'减去一个baseline b为了让A有正有负。

这个b的值应该设为V(s)的值。
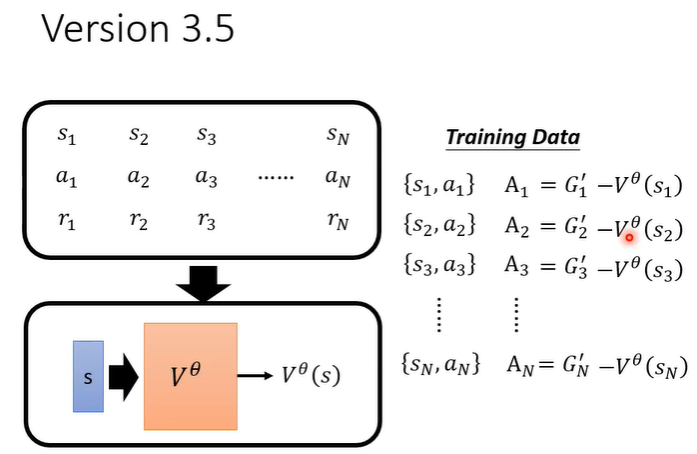
为什么它是合理的呢?V(s)的值实际上是看见画面s得到的reward的期望值,actor具有随机性做出的行为会有很多的可能,把这些可能的行为得到的分数平均起来就是V(s)的值。G'的含义是在画面s下执行行为a得到的评价分数,如果A大于0就代表G'大于V(s),说明行为a得到的分数高于平均,认为这个行为a是好的,所以我们鼓励actor执行a。如果A小于0就代表G'小于V(s),说明行为a得到的分数低于平均,认为这个行为a是不好的,所以我们不鼓励actor执行a。
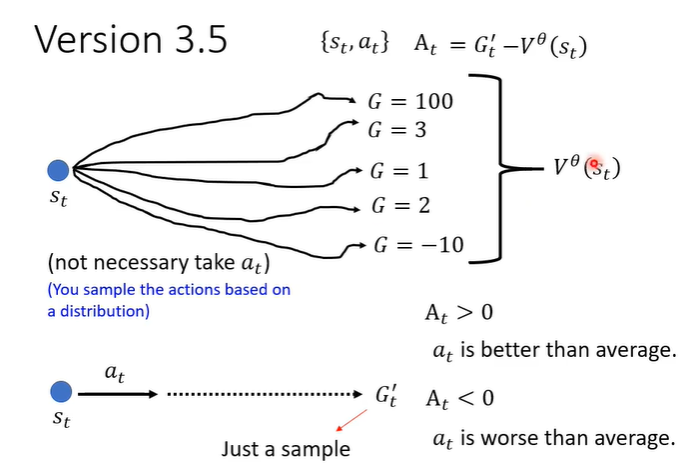
Advantage Actor-Critic
但是G'是一个sample的结果,即执行a后一直到游戏结束的一个结果,把一个sample减去平均并不合理。所以需要“平均减平均”,执行完a_t后得到r_t,在s_t的后一个画面s_t+1一直玩下去就得到很多可能,平均起来就是V(s_t+1),再加上r_t,代表原来的G'。
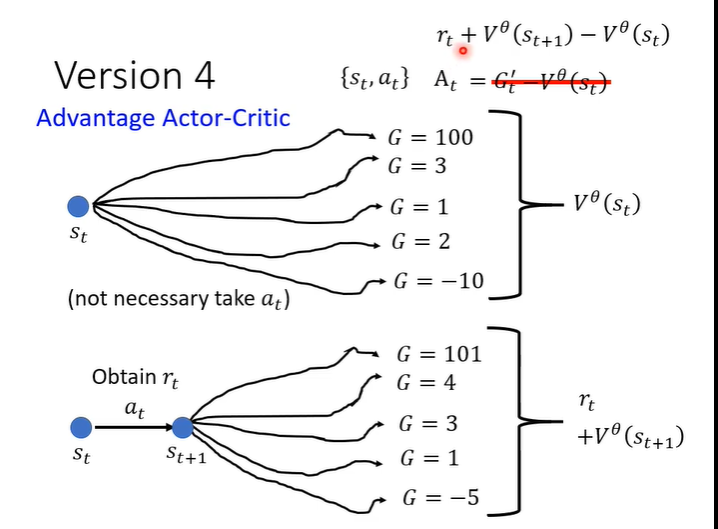
12.reward shaping
评价分数A的计算方式是,这样公式,很怕遇见一种情况,假设reward多数时候是0,只有很小的概率会得到一个巨大的reward,这意味着A无论怎么算都是0,这样就没办法确认actor,这就是sparse reward问题。
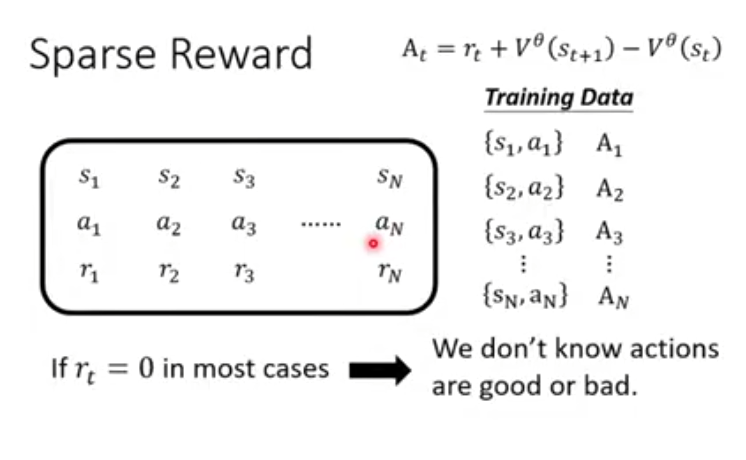
遇到这种情况有一个解法是,想办法提供额外的reward帮助agent学习,这就叫reward shaping。以vizdoom(第一人称射击游戏)为例,被杀掉就扣分,杀了敌人就加分。只靠这样的规则很难训练起来。假设在游戏中扣血没用惩罚,死掉才会扣分,这样机器可能很久才学到扣血和死掉之间的关联,所以我们人为给机器增加一些对游戏分数没有影响但是会利于得到分数的规则帮助机器学习。比如下图中捡到医疗包是正的reward,原地不动是负的reward等。

13.inverse reinforcement learning(IRL)
在真实的环境中,定义reward有可能是很困难的,假设用RL让自驾车学会在路上走,那做什么样的事情会得到什么reward呢,这是很难定义的。如果reward没定义好,可能会产生很奇怪的行为。例如机械公敌电影中,机器被定义三个规则1.不可以伤害人类,也不能不管人类被伤害;2.不违反第一条的前提下,必须听人类的命令;3.不违反第一,第二条的前提下,必须要保护自己。可以认为如果不违反这三条规则,就会得到positive reward;违反就得到negative reward。最终机器把人类监禁起来,因为人类会自我伤害,这同样符合三个规则,可以得到positive reward。

在没有reward时,有一种方法叫imitation learning,假设actor仍然可以跟环境互动,但是不会得到reward。找一些expert示范,找很多人类跟这个环境互动并记录下来,用这些让机器学习。
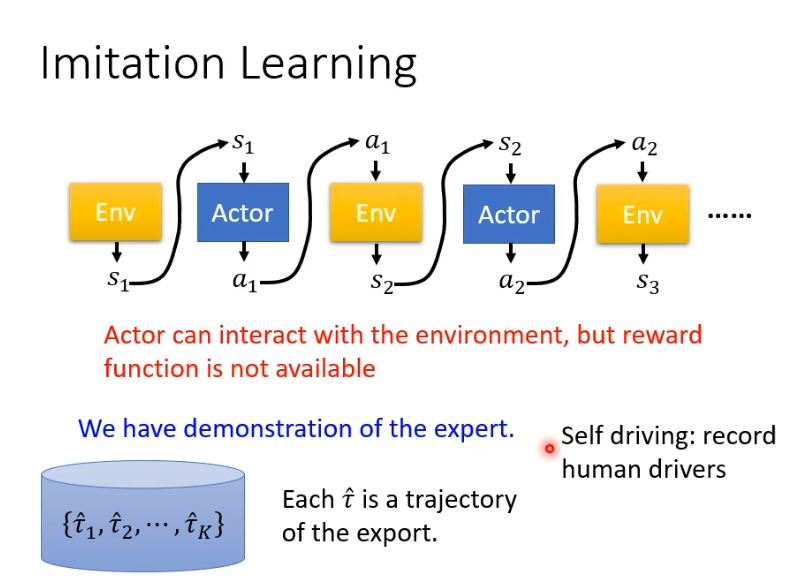
学习的方式就类似supervised learning,同样是自动驾驶的例子,将expert示范作为标准答案让模型的预测输出尽可能接近expert动作。但是存在的问题是测试时可能会进入一个它从未见过的状态,比如示范中不会撞到墙,在实际测试中要撞到墙机器就会不知所措。
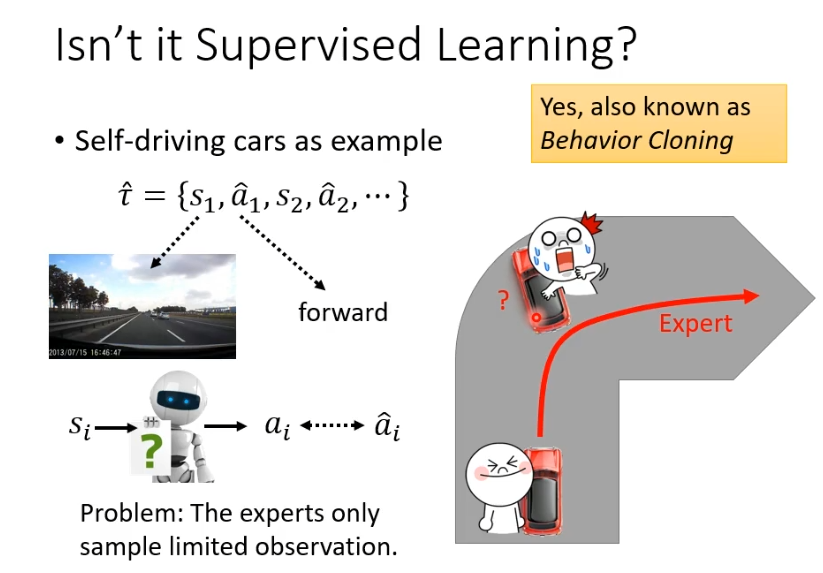
没有reward也可以采用inverse reinforcement learning的方法,这个方法不是根据reward学习,而是从expert的示范和环境反推reward是什么样的。这样学出一个reward function之后,就可以直接用一般的RL来训练actor。
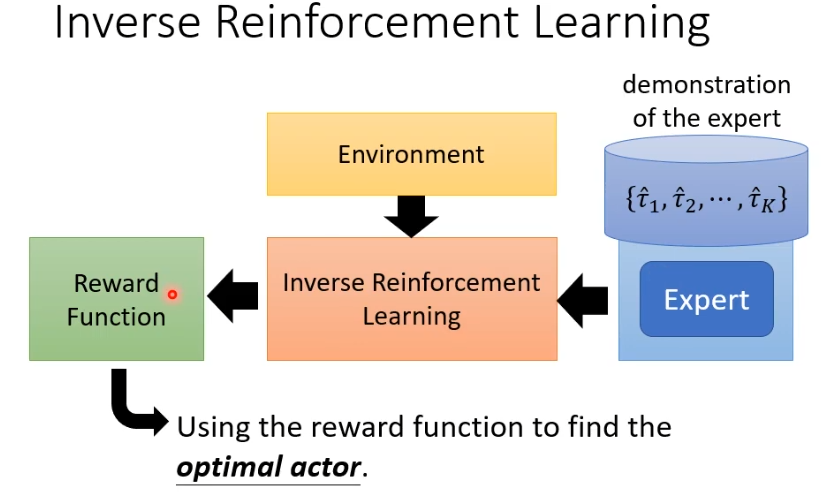
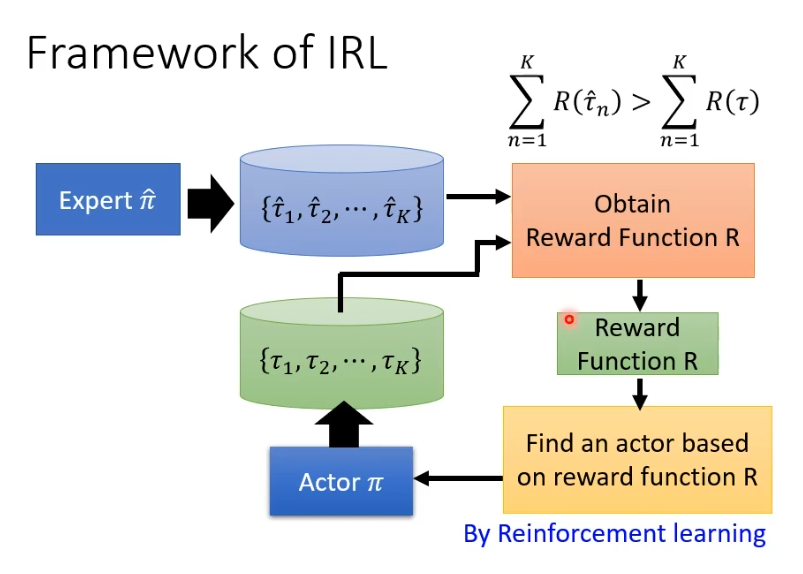
inverse reinforcement learning(IRL)的概念是,假设老师的行为可以取得最高的reward,有一个什么都不会的actor跟环境互动得到收集一些trajectory,接下来要定义reward function,训练的条件是老师的行为得到的reward必须高于学生的行为得到的reward,然后更新actor参数,接下来反复执行这个过程,最总得到一个reward function。

下图是IRL的架构图

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)