拆解 CUDA 线程架构:GPGPU 征服大规模数据的底层逻辑
而当我们把目光投向如今最受推崇的GPGPU时,一个关键问题自然浮现:明明最初GPU是为图像处理设计的,为何它能摇身一变,成为科学计算、AI 训练的"算力猛兽"?接下来,咱们就从最基础的线程结构划分开始,揭开GPGPU高效并行的秘密。
各位书友大家好,欢迎做客我的栏目。
前面的文章中我们一起学习了向量体系架构和SIMD指令集多媒体扩展两种数据级并行架构的特点、优势,以及实现细节。
而当我们把目光投向如今最受推崇的GPGPU时,一个关键问题自然浮现:明明最初GPU是为图像处理设计的,为何它能摇身一变,成为科学计算、AI 训练的"算力猛兽"?
接下来,咱们就从最基础的线程结构划分开始,揭开GPGPU高效并行的秘密。
目录
2.1 三级线程结构揭秘: Grid/Block/Thread协同作战
导图
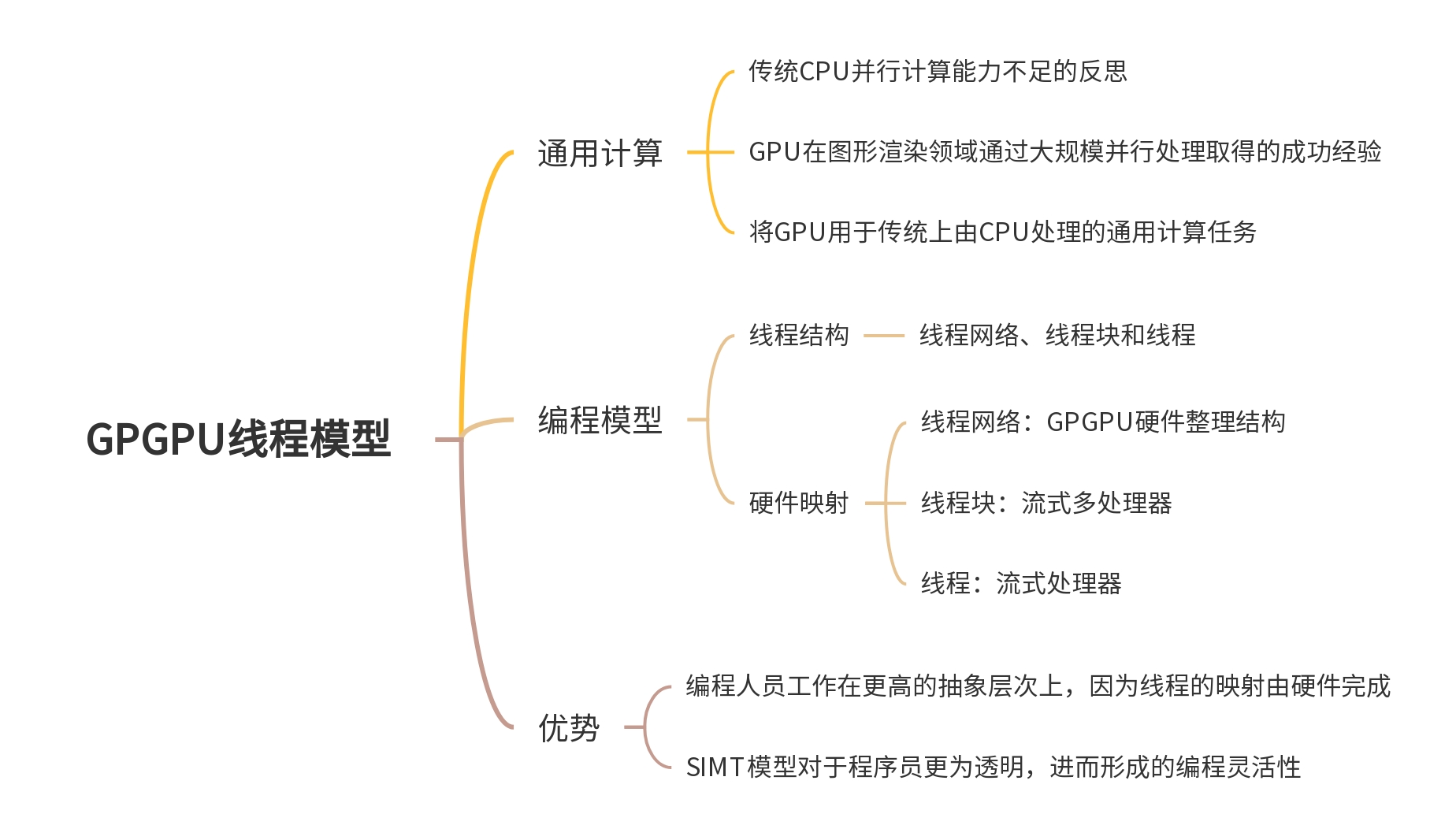
一、从GPU到GPGPU: 通用计算的突破
GPU(Graphic Process Unit)的出现是为了满足图像处理和显示性能不断增长的需求,计算机显示过程中将三维立体模型转化为屏幕上的二维图像,转换的一系列步骤组成了图形处理流水线。
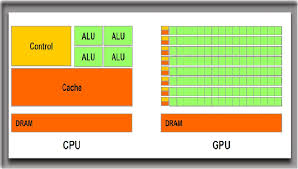
图1 CPU vs GPU
GPU 的核心优势在于其高度并行的架构,它具有许多更小、更专业的内核。这些内核通过协同工作,并同时(或并行)在多个内核(kernel)之间分配处理任务来提供强大的性能,这使其在处理需要同时操作大量数据块的算法时比CPU更高效。
随着硬件的发展,GPU的并行处理能力显著增强,而CPU的单核性能提升遭遇瓶颈。并且随着可编程着色器的引入到GPU中,开发者能够编写自定义代码来实现更复杂的效果,这种可编程性为GPU的通用计算之路奠定基础。
同时科学计算、数据分析和机器学习等领域对并行计算的强烈需求,开发者探索将GPU的计算能力应用于这些领域。
对传统CPU并行计算能力不足的反思,以及GPU在图形渲染领域通过大规模并行处理取得的成功经验的启发,使得GPGPU(General-Purpose Computing on GPU)概念出现,用于描述将GPU用于传统上由CPU处理的通用计算任务的做法。

图2 NVIDIA CUDA
为了进一步支持通用计算,NVIDIA在2006年推出CUDA,这加速了通用并行计算的发展。CUDA是一种将GPU作为数据并行计算设备的软硬件体系,让开发者无需深入硬件细节,使用比较容易掌握的类C语言进行开发。
它在某种方式上与我们的思考与编码方式相吻合,可以更轻松、更自然地表达超越任务级别的并行。
二、GPGPU线程模型: 用“线程矩阵”征服大规模数据
GPU几乎拥有所有可以由编程环境捕获的并行类型:多线程、MIMD、SIMD,甚至是指令级并行。NVIDIA认为,所有这些并行形式的统一主题就是CUDA线程。
GPGPU并行计算是以CUDA线程为基础进行组织的,分配的所有线程执行同一内核函数。线程的重要性体现在:
-
GPGPU线程模型定义了如何利用大规模多线程索引到计算任务中的不同数据
-
线程组织形式与GPGPU层次化硬件结构相对应
下面我将通过一个程序示例进行说明

图3 CUDA优化DAXPY程序
图3中展示DAXPY(向量x与常数相乘后再与向量y相加)程序的不同实现版本。左侧是传统C代码实现版本,右侧是CUDA实现版本。
CUDA编程模型常将代码划分为主机端代码和设备端代码,分别运行在CPU和GPU上,这个划分通过编程模型提供的关键字手动标定。
CUDA使用__device__或__global__关键字表示运行在设备端的代码,使用__host__关键字表示运行再主机端的代码。
编译器分别调用CPU和GPGPU编译器进行各自代码的编译,执行时通过运行时库(一组在程序执行过程中提供支持的函数和程序库)完成主机端和设备端代码的分配。
2.1 三级线程结构揭秘: Grid/Block/Thread协同作战
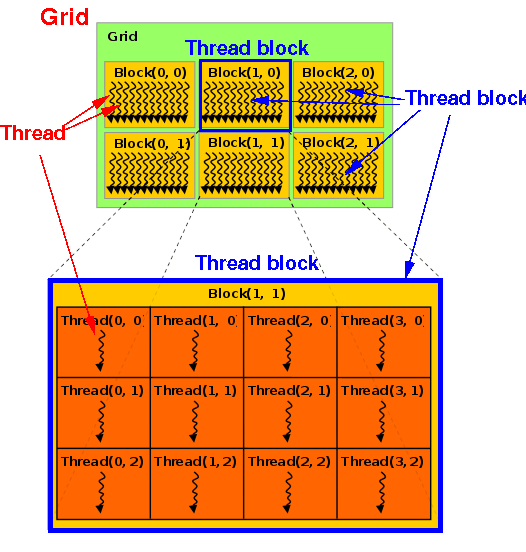
图4 CUDA二维线程结构
主机端代码使用<<< >>>关键字启动内核函数时传递了两个参数gridDim和blockDim,这两个参数确定了本次GPGPU计算所采用的线程结构。
CUDA采用层次化线程结构,CUDA定义的线程分为三级:线程网络、线程块和线程。
⭐线程网络: 算力宇宙搭建⭐
线程网络(Grid)是最大的线程范围,包含主机端代码启动内核函数时所唤醒的所有线程。
线程网络由多个线程块组合,可以是一维、二维或三维,其结构由gridDim参数指定。
gridDim参数是一种dim3数据类型(CUDA关键字),该数据类型本质上是一个数组,由3个无符号数代表三个维度,其中x表示行、y表示列、z表示高。
⭐线程块: 基础作战单元⭐
线程块(Block)是线程网络内线程的基本调度单位,它是线程的集合。
线程块同样可以是是一维、二维或三维,其结构由blockDim参数指定。
blockDim也是dim3数据类型。
⭐线程: 最小执行实体⭐
线程(Thread)是最小的执行实体,对应内核函数中的一个实例,每个线程并行执行相同的指令流。每个线程拥有唯一的索引,根据其在线程层次结构中的位置获取计算数据。
在多维Block/Grid中,线程可通过内建变量threadIdx.{x,y,z}和blockIdx.{x,y,z},结合前文介绍的blockDim和gridDim进行全局数据索引与寻址。
blockIdx和threadIdx也是dim3数据类型,包含三个属性,x、y和z。blockIdx描述线程块在线程网络中的位置,threadIdx描述线程在线程块中的位置。
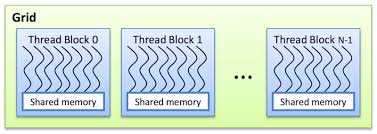
图5 CUDA线程一维结构
先考虑图5中一维线程结构,每个线程都有自己的索引值
![]()
假设一维线程结构中,线程网络包含4个线程块,线程块包含512个线程,则线程块1中的线程2的索引值为1*512+2 = 514
再考虑图4的二维线程结构,线程块索引和线程索引分别计算
![]()
![]()
2.2 从代码到芯片: CUDA线程与GPGPU硬件的映射
在GPGPU编程模型中,应用程序的大规模数据根据编程人员所描述的线程和数据索引关系被分配到了每个线程。
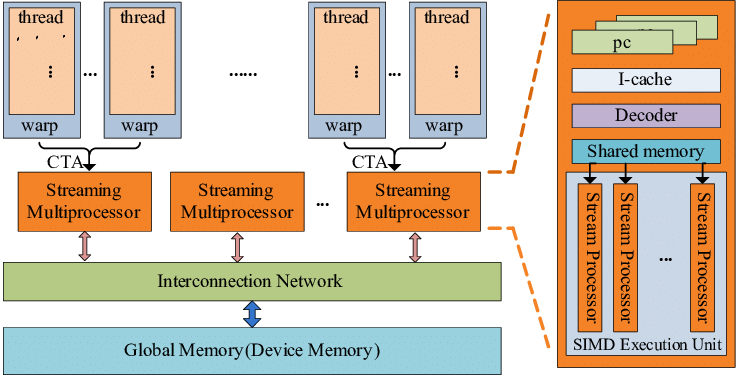
图6 GPGPU架构
为了实现线程到硬件功能单元的映射/分配,GPGPU对硬件进行了层次化组织。层次化硬件主要有流式多处理器(Streaming Multiprocessor,SM)阵列和存储系统构成。
每个SM内部有多个流式处理器(Streaming Processor, SP)单元,构成一套完整的指令流水线,包含取指、译码、寄存器文件、运算单元和载入/存储单元。
SP以单指令多线程架构(SIMT,类似SIMD)进行组织,每个线程执行相同的代码,但处理不同的数据,通过开启足够多的线程获得可观的吞吐率。
GPGPU硬件整体结构、SM阵列和SP单元分别对应编程模型中的线程网络、线程块和线程,实现了线程到硬件的映射/分配。
每次内核启动会在GPGPU上生成一个Grid,其中包含若干个 Block。CUDA 程序启动时的Grid只是一个逻辑集合,真正的调度单位是Block。
通过增加 Grid 的维度与大小,可扩展到任意多的线程块,从而利用所有可用的SM并行处理大规模数据集。
每个Block会被分配到某个SM上执行,并且在执行期间不会迁移至其它 SM。一个SM上可以同时映射多个Block,具体的数量取决于Block大小和SM的资源限制。
每个 Block 内部的Thread按行优先线性编号,然后被分组为大小固定(比如32 线程)的 Warp,并由 SM中的 SP以单指令多线程的方式并行执行。
三、程序员不用"硬刚硬件"的并行计算革命
我们先根据前文的介绍分析下SIMT架构与SIMD架构之间的不同,后续随着对GPGPU架构介绍不断深入,我们会对这部分内容进行补充。
从并行的数据处理来看两者没有本质区别,区别在于编程人员看到的硬件抽象程度不同。
对于SIMT,编程人员工作在更高的抽象层次上,因为线程的映射由硬件完成;而对于SIMD,编程人员需要根据硬件架构去向量化程序。
这使得SIMT模型对于程序员更为透明,进而形成的编程灵活性是相较于SIMD最大的优势。
感谢您的阅读和陪伴。本文对GPGPU线程模型进行了全面介绍,希望对您有所帮助。如有任何疑问或建议,欢迎在评论区留言交流。
关注我 每周日做知识分享
微信公众号(欢迎关注):我想成为大佬


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)