【无标题】py线性回归模型学习
print(f"训练集均方根误差: {np.sqrt(mean_squared_error(y_train, y_train_pred)):.4f}")print(f"测试集均方根误差: {np.sqrt(mean_squared_error(y_test, y_test_pred)):.4f}")print(f"测试集均方误差: {mean_squared_error(y_test, y_tes
# 导入必要的库
# pandas用于数据处理和分析
import pandas as pd
# numpy用于数值计算
import numpy as np
# matplotlib用于数据可视化
from matplotlib import pyplot as plt
# 导入线性回归模型
from sklearn.linear_model import LinearRegression
# 用于划分训练集和测试集
from sklearn.model_selection import train_test_split
# 用于特征标准化
from sklearn.preprocessing import StandardScaler
# 导入模型评估指标
from sklearn.metrics import mean_squared_error, r2_score
# 1. 数据加载与初步探索
# 读取CSV格式的房价数据集
# 修复:添加异常处理,应对文件读取可能出现的错误
try:
data = pd.read_csv('house_price.csv')
except FileNotFoundError:
print("错误:找不到house_price.csv文件,请检查文件路径是否正确")
# 可以添加退出程序或其他处理逻辑
exit(1)
except Exception as e:
print(f"读取文件时发生错误:{e}")
exit(1)
# 查看数据集前10条记录,了解数据结构
print("数据集中的前10条记录:")
print(data.head(10))
# 查看数据集基本信息,包括列名、数据类型和缺失值情况
print("\n数据集基本信息:")
print(data.info())
# 查看数据集的统计描述,包括均值、标准差、最值等
print("\n数据集统计描述:")
print(data.describe())
# 修复:检查并处理缺失值
print("\n缺失值情况:")
print(data.isnull().sum())
# 对于数值型特征,使用均值填充缺失值
data = data.fillna(data.select_dtypes(include=[np.number]).mean())
# 2. 数据可视化 - 探索特征与目标变量的关系
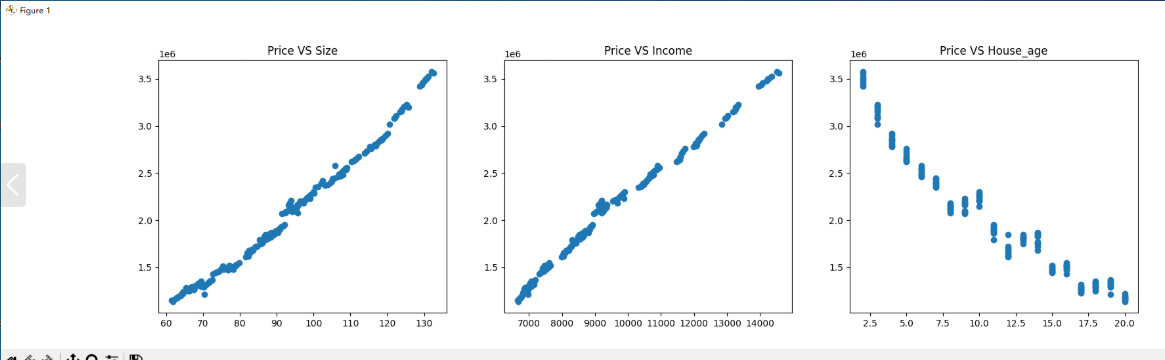
# 创建画布,设置大小为20x5
plt.figure(figsize=(20, 5))
# 第一个子图:面积与价格的散点图
plt.subplot(131) # 1行3列中的第1个位置
plt.scatter(data['面积'], data['价格'], alpha=0.5) # alpha设置点的透明度
plt.title('Price VS Size') # 设置图表标题
plt.xlabel('面积') # x轴标签
plt.ylabel('价格') # y轴标签
# 第二个子图:人均收入与价格的散点图
plt.subplot(132) # 1行3列中的第2个位置
plt.scatter(data['人均收入'], data['价格'], alpha=0.5)
plt.title('Price VS Income')
plt.xlabel('人均收入')
plt.ylabel('价格')
# 第三个子图:平均房龄与价格的散点图
plt.subplot(133) # 1行3列中的第3个位置
plt.scatter(data['平均房龄'], data['价格'], alpha=0.5)
plt.title('Price VS House_age')
plt.xlabel('平均房龄')
plt.ylabel('价格')
# 自动调整子图间距,避免重叠
plt.tight_layout()
# 显示图形
plt.show()
# 3. 数据预处理
# 分离特征变量(X)和目标变量(y)
# X:所有特征列(排除价格列)
X = data.drop(['价格'], axis=1)
# y:目标变量,即房价
y = data['价格']
# 将数据集划分为训练集(80%)和测试集(20%)
# random_state=42:设置随机种子,保证结果可复现
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# 特征标准化处理
# 标准化可以使不同量级的特征具有可比性,便于解释模型系数
scaler = StandardScaler()
# 对训练集进行拟合和转换
X_train_scaled = scaler.fit_transform(X_train)
# 使用相同的标准化器转换测试集(避免数据泄露)
X_test_scaled = scaler.transform(X_test)
# 4. 建立并训练多因子线性回归模型
# 初始化线性回归模型
model_multi = LinearRegression()
# 使用训练集数据训练模型
model_multi.fit(X_train_scaled, y_train)
# 输出模型参数,解释各特征对房价的影响
print("\n回归模型系数 (特征重要性):")
# 遍历每个特征及其对应的系数
for i, feature in enumerate(X.columns):
# 系数表示:在其他特征不变的情况下,该特征每变化1个标准差,房价的平均变化量
print(f"{feature}: {model_multi.coef_[i]:.4f}")
# 输出截距项:当所有特征为0时的预测房价
print(f"截距: {model_multi.intercept_:.4f}")
# 5. 模型评估
# 使用训练好的模型对训练集和测试集进行预测
y_train_pred = model_multi.predict(X_train_scaled) # 训练集预测结果
y_test_pred = model_multi.predict(X_test_scaled) # 测试集预测结果
# 输出模型评估指标
print("\n模型评估:")
# R²分数:越接近1表示模型拟合越好
print(f"训练集R²分数: {r2_score(y_train, y_train_pred):.4f}")
print(f"测试集R²分数: {r2_score(y_test, y_test_pred):.4f}")
# 均方误差:值越小表示预测越准确
print(f"训练集均方误差: {mean_squared_error(y_train, y_train_pred):.4f}")
print(f"测试集均方误差: {mean_squared_error(y_test, y_test_pred):.4f}")
# 修复:添加均方根误差,更直观地理解误差大小
print(f"训练集均方根误差: {np.sqrt(mean_squared_error(y_train, y_train_pred)):.4f}")
print(f"测试集均方根误差: {np.sqrt(mean_squared_error(y_test, y_test_pred)):.4f}")
# 6. 房价预测 - 使用训练好的模型预测新数据
# 新数据:面积150,人均收入60000,平均房龄5
new_data = np.array([[150, 60000, 5]])
# 对新数据进行标准化(使用与训练数据相同的标准化器)
new_data_scaled = scaler.transform(new_data)
# 预测房价
y_test_predict = model_multi.predict(new_data_scaled)
# 输出预测结果,保留两位小数
print(f"\n预测房价: {y_test_predict[0]:.2f}")
————————————————
版权声明:本文为CSDN博主「Eallaine」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Eallaine/article/details/154172261

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)