【AI论文】DeepSeek-OCR:基于上下文的光学压缩
本文提出DeepSeek-OCR模型,探索通过光学压缩实现长上下文高效处理。模型采用DeepEncoder和DeepSeek3B-MoE解码器架构,支持多分辨率输入,在高压缩比下保持OCR精度:10倍压缩比时精度达97%,20倍时仍保持60%。在OmniDocBench基准测试中,仅用100个视觉标记即超越现有方法,且单块A100可日处理20万页数据。研究验证了光学压缩的可行性,同时指出压缩比与精
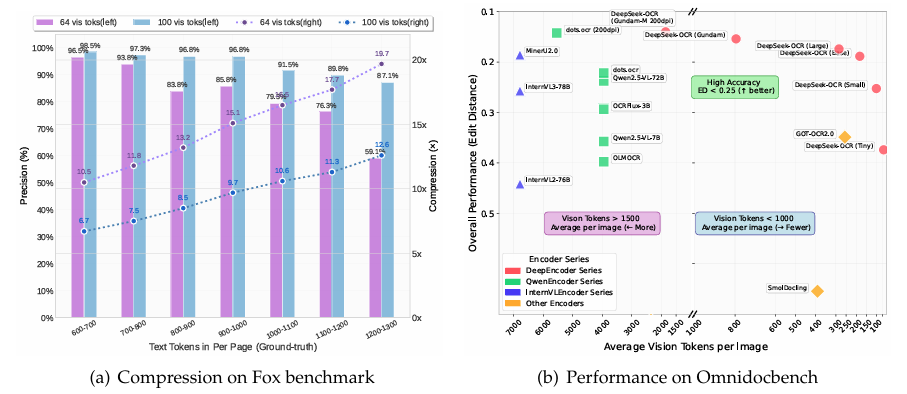
摘要:我们推出DeepSeek-OCR,作为对通过光学二维映射压缩长上下文可行性的初步探索。DeepSeek-OCR由两个组件构成:DeepEncoder作为编码器,DeepSeek3B-MoE-A570M作为解码器。具体而言,DeepEncoder是核心引擎,其设计能够在高分辨率输入下保持低激活量,同时实现高压缩比,以确保视觉标记(vision tokens)的数量达到最优且可控。实验表明,当文本标记数量不超过视觉标记数量的10倍时(即压缩比<10倍),模型解码(OCR)精度可达97%。即使在压缩比达到20倍的情况下,OCR准确率仍保持在60%左右。这表明,该技术在历史长上下文压缩和大语言模型(LLMs)的记忆遗忘机制等研究领域具有巨大潜力。除此之外,DeepSeek-OCR还展现出极高的实用价值。在OmniDocBench基准测试中,该模型仅使用100个视觉标记便超越了GOT-OCR2.0(每页256个标记),且在视觉标记使用量少于800个的情况下,表现优于MinerU2.0(平均每页6000多个标记)。在实际应用中,DeepSeek-OCR可在单块A100-40G显卡上,每日生成20万页以上规模的LLMs/VLMs训练数据。代码和模型权重已在Github公开获取。Huggingface链接:Paper page,论文链接:2510.18234
研究背景和目的
研究背景:
随着人工智能技术的飞速发展,大语言模型(LLMs)和视觉语言模型(VLMs)在处理文本和图像信息方面展现出了强大的能力。
然而,在处理长上下文信息时,这些模型往往面临计算资源消耗大、处理效率低下等问题。特别是在处理包含大量文本信息的图像时,传统的OCR(光学字符识别)方法往往需要将图像中的每个字符逐一识别,导致生成的视觉令牌(vision tokens)数量庞大,增加了后续处理的复杂性和计算成本。
此外,随着数据量的爆炸式增长,如何高效地压缩和存储这些长上下文信息,以便后续模型能够快速访问和处理,成为了亟待解决的问题。
传统的文本压缩方法虽然在一定程度上减少了存储空间,但往往以牺牲信息精度为代价,难以满足高精度OCR任务的需求。
研究目的:
本研究旨在探索一种通过光学压缩实现长上下文高效压缩的方法,以减少视觉令牌的数量,同时保持OCR任务的精度。
具体而言,研究目的包括:
- 开发高效的光学压缩模型:设计一种能够通过光学2D映射压缩长上下文信息的模型,减少视觉令牌的数量,同时保持较高的OCR解码精度。
- 验证光学压缩的可行性:通过实验验证光学压缩在OCR任务中的可行性和有效性,探索不同压缩比下模型的性能表现。
- 推动实际应用:将开发的光学压缩模型应用于实际场景中,如大规模预训练数据的生成,为LLMs和VLMs提供高效的数据支持。
研究方法
1. 模型架构设计:
本研究提出了DeepSeek-OCR模型,该模型由DeepEncoder和DeepSeek-3B-MoE-A570M解码器两部分组成。
DeepEncoder作为核心引擎,负责在保持低激活内存的同时实现高分辨率输入下的高压缩比,确保视觉令牌数量的优化。解码器部分则采用DeepSeek-3B-MoE架构,利用混合专家(MoE)模型的优势,在保持模型表达能力的同时提高推理效率。
2. 多分辨率支持:
为了适应不同分辨率的输入图像,DeepEncoder设计了多种分辨率模式,包括原生分辨率和动态分辨率。
通过动态插值位置编码,模型能够支持可变数量的视觉令牌输入,从而实现单一模型对多种分辨率的支持。这一设计使得模型在处理不同尺寸和复杂度的图像时更加灵活和高效。
3. 数据构建与训练:
为了训练DeepSeek-OCR模型,研究团队构建了复杂且多样的训练数据集,包括传统OCR任务数据(如场景图像OCR和文档OCR)、复杂人工图像解析任务数据(如图表、化学公式和平面几何解析数据)、通用视觉数据以及纯文本数据。
通过多阶段训练策略,首先独立训练DeepEncoder,然后将其与解码器结合进行端到端训练,确保模型在OCR任务中的高性能表现。
4. 评估与测试:
研究团队在多个基准测试集上对DeepSeek-OCR模型进行了全面评估,包括Fox基准测试集和OmniDocBench等。
通过比较不同压缩比下模型的OCR解码精度和实际性能表现,验证光学压缩的可行性和有效性。
研究结果
1. 光学压缩的可行性:
实验结果表明,DeepSeek-OCR模型在保持较高OCR解码精度的同时,实现了显著的视觉令牌数量减少。
在Fox基准测试集上,当文本令牌数量是视觉令牌数量的10倍以内时,模型能够实现97%的OCR解码精度;即使在20倍压缩比下,模型的OCR准确率仍保持在60%左右。这一结果初步验证了光学压缩在OCR任务中的可行性和潜力。
2. 实际性能表现:
在OmniDocBench基准测试集上,DeepSeek-OCR模型展现了卓越的实际性能。
仅使用100个视觉令牌,模型就超越了GOT-OCR2.0(256个令牌/页)的性能;使用不到800个视觉令牌时,模型性能优于MinerU2.0(平均每页6000多个令牌)。在生产环境中,DeepSeek-OCR每天能够为LLMs/VLMs生成20万页以上的训练数据,显著提高了数据生成效率。
3. 多语言与多任务支持:
DeepSeek-OCR模型不仅支持中英文等多种语言的OCR任务,还具备解析图表、化学公式、简单几何图形和自然图像的能力。
通过统一的提示词,模型能够实现对复杂文档结构的深度解析和多语言识别,进一步拓展了模型的应用范围。
研究局限
1. 压缩比与精度的平衡:
尽管DeepSeek-OCR在较高压缩比下仍能保持一定的OCR精度,但随着压缩比的进一步提高,模型性能会出现明显下降。
如何在保持高压缩比的同时进一步提高OCR精度,是未来研究需要解决的问题之一。
2. 复杂文档结构的处理:
对于包含复杂布局和大量文本的文档图像,DeepSeek-OCR模型在解析过程中仍面临一定挑战。
如何进一步优化模型结构以提高对复杂文档结构的处理能力,是未来研究的重要方向。
3. 实际应用场景的拓展:
虽然DeepSeek-OCR在OCR任务中展现了卓越的性能,但其在实际应用场景中的拓展仍需进一步探索。
如何将模型应用于更多领域和场景中,如医疗、金融等,以发挥其更大的价值,是未来研究需要关注的问题。
未来研究方向
1. 更高压缩比与精度的追求:
未来研究可以进一步探索如何在保持高OCR精度的同时实现更高的压缩比。
这可能涉及对模型架构的进一步优化、训练数据的增强以及训练策略的改进等方面。
2. 复杂文档结构的深度解析:
针对复杂文档结构的解析问题,未来研究可以探索更先进的模型架构和算法,以提高模型对复杂布局和大量文本的处理能力。
例如,可以引入图神经网络(GNN)等结构来更好地捕捉文档中的空间关系和层次结构。
3. 多模态融合与跨领域应用:
未来研究可以进一步探索多模态融合技术在OCR任务中的应用,将文本、图像、语音等多种模态信息融合到一个统一的模型中,以提高模型对复杂场景的理解和处理能力。同时,可以探索将DeepSeek-OCR模型应用于更多领域和场景中,如医疗影像分析、金融文档处理等,以拓展模型的应用范围和价值。
4. 持续学习与自适应优化:
为了应对不断变化的数据分布和任务需求,未来研究可以探索持续学习(Continual Learning)和自适应优化(Adaptive Optimization)技术在OCR模型中的应用。通过持续学习,模型能够不断适应新的数据和任务;通过自适应优化,模型能够根据实际性能表现动态调整参数和策略,以保持最佳性能状态。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献178条内容
已为社区贡献178条内容

所有评论(0)