使用LangChain+LangGraph自定义AI工作流,实现音视频字幕生成工具
摘要 本文介绍了使用LangChain和LangGraph构建AI工作流的方法,实现一个音视频字幕生成工具。文章首先对比了coze、dify等AI工作流产品,选择使用LangGraph进行开发。通过流程图展示了从音视频到字幕文件的转换流程,并拆解为两个智能体:音视频转文本和文本总结。作者演示了用LangChain创建简单智能体(如获取天气)的代码示例,以及LangGraph构建工作流的基本方法。最
1. 前言
前段时间做了几个短视频,之后总想着拍短视频给忘了发博客写文章了。
趁着最近AI工作流很火,趁热打铁,结合前段时间的生活,今天出一篇短文:用AI工作流做一个AI小工具,实现音视频的字幕生成。
2. langgraph简介
coze、dify、n8n都是AI工作流中的代表产品,界面炫酷且开源,在很多场景中也都得到了广泛的应用。
作为后端程序员的我,为了快速体验AI工作流带来的魅力,本文中决定使用最近同样很流行的LangChain + LangGraph来试一下。
langgraph的开源仓库地址为:https://github.com/langchain-ai/langgraph
与LangChain不同的是,LangGraph具有以下特性:
- 人机交互(Human-in-the-loop)
- 长短期记忆(Comprehensive memory)
- 简单易用的调试与部署(Debugging with LangSmith、Production-ready deployment)
- 长期运行(Durable execution)
简单总结就是LangChain可以让我们很方便的构建出一个智能体,而遇到比较复杂的处理流程时,则需要使用LangGraph来管理这些流程,特别是在构建多智能应用时非常有用。
关于LangGraph的详细细节这里不再展开,相关说明可移步LangGraph官方说明:LangGraph overview
3. 示例–音视频字幕生成工具流程
先用draw.io画一个流程图: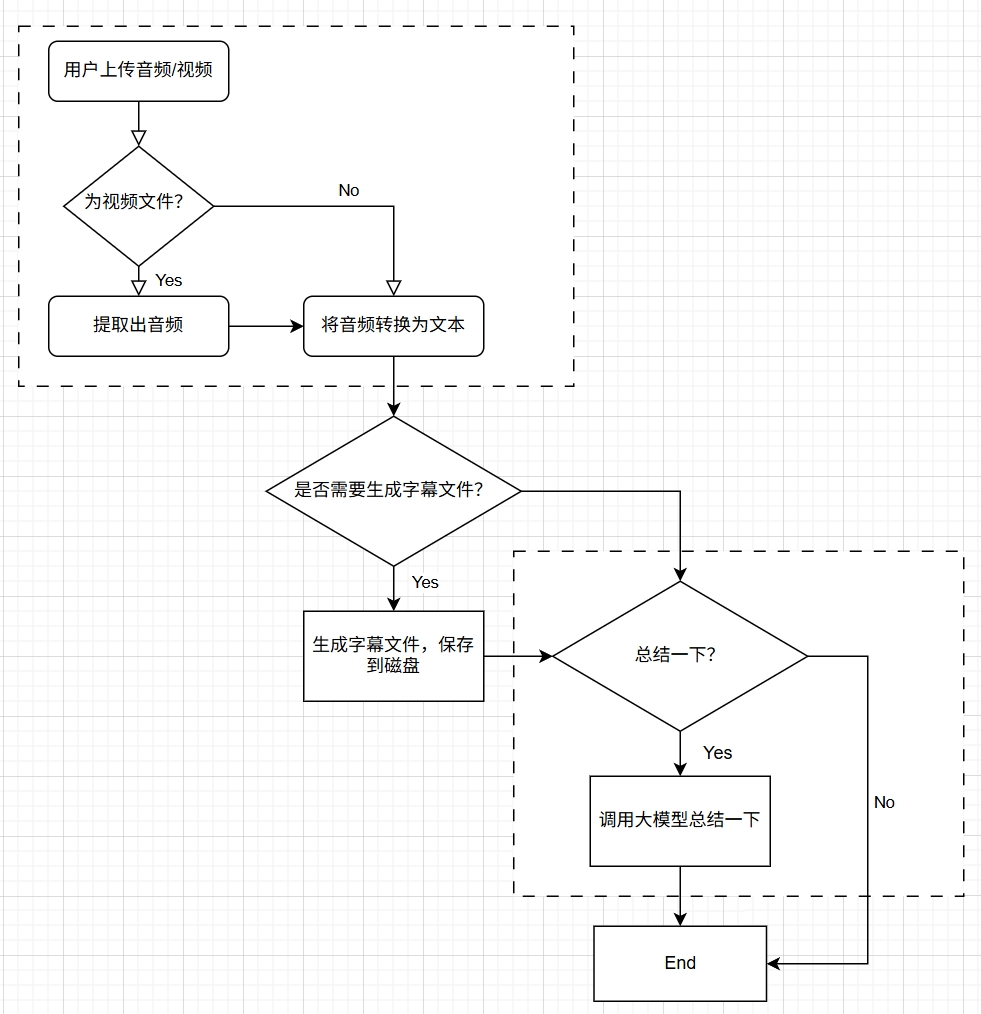
上图展示了一个将音视频转为字幕文件,并提炼总结的一个示例。
其中我们可以划分为两个智能体:
- 音视频转文本——智能体
- 总结一下——智能体
是否需要调用“总结一下”智能体由用户交互决定。
4. LangChain+LangGraph入门(可跳过)
此案例中使用的大模型为阿里的通义千问,API_KEY获取地址:https://bailian.console.aliyun.com/
4.1 LangChain构建一个智能体(HelloWorld)
在编码之前,先看一下LangChain构建一个智能体应用的代码是多么短:
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
llm = ChatTongyi(
model="qwen-plus",
temperature=0,
verbose=True,
)
def get_weather(city: str) -> str:
"""根据指定的城市名称获取对应的天气"""
return f"今天{city}的天气很好,是一个大晴天!"
agent = create_agent(
model=llm,
tools=[get_weather],
system_prompt="你是一个非常有用的信息查询助手"
)
# Run the agent
answer = agent.invoke(
{"messages": [{"role": "user", "content": "今天成都的天气怎么样?"}]}
)
# print(answer)
for i in answer["messages"]:
print(i)
print()
定义好DASHSCOPE_API_KEY变量后再运行: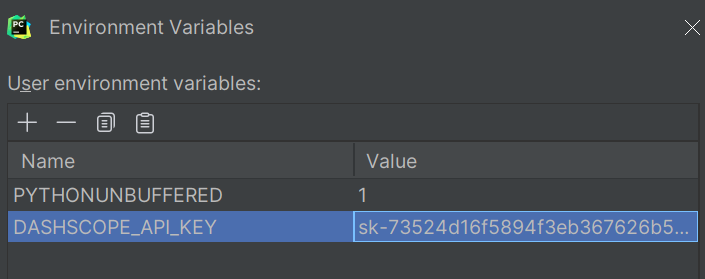
输出结果如下:
content='今天成都的天气怎么样?' additional_kwargs={} response_metadata={} id='b57bb281-6f0b-4581-a3ab-2e3619516de2'
content='' additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_fb87d30b624f4e49a380ed', 'type': 'function', 'function': {'name': 'get_weather', 'arguments': '{"city": "成都"}'}}]} response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'tool_calls', 'request_id': 'ea2d43ee-1562-4bd6-99be-05c07fc6fb00', 'token_usage': {'input_tokens': 161, 'output_tokens': 19, 'total_tokens': 180, 'prompt_tokens_details': {'cached_tokens': 0}}} id='lc_run--cd6032b8-63e0-4e5c-a945-a2c4d4f4660f-0' tool_calls=[{'name': 'get_weather', 'args': {'city': '成都'}, 'id': 'call_fb87d30b624f4e49a380ed', 'type': 'tool_call'}]
content='今天成都的天气很好,是一个大晴天!' name='get_weather' id='36c1c579-c201-443a-b3d5-df1061d1c94d' tool_call_id='call_fb87d30b624f4e49a380ed'
content='今天成都的天气很好,是一个大晴天!适合外出活动哦!' additional_kwargs={} response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'stop', 'request_id': '59130a05-e0b6-4c90-9191-643d35a9b5fc', 'token_usage': {'input_tokens': 204, 'output_tokens': 16, 'total_tokens': 220, 'prompt_tokens_details': {'cached_tokens': 0}}} id='lc_run--211eeb8f-f77b-4037-85f3-89d682cb5ef5-0'
4.2 LangGraph-HelloWold
from langgraph.graph import StateGraph, MessagesState, START, END
def mock_llm(state: MessagesState):
return {"messages": [{"role": "ai", "content": "你好,世界!"}]}
graph = StateGraph(MessagesState)
graph.add_node(mock_llm)
graph.add_edge(START, "mock_llm")
graph.add_edge("mock_llm", END)
graph = graph.compile()
answer = graph.invoke({"messages": [{"role": "user", "content": "hi!"}]})
for i in answer["messages"]:
print(i)
print()
# Show the workflow
# png = graph.get_graph().draw_mermaid_png()
# with open("workflow.png", "wb") as f:
# f.write(png)
# print("流程图已保存为 workflow.png")
上面代码中构建的工作流程图为: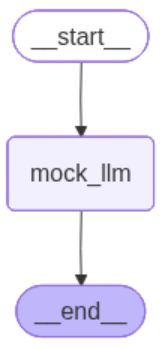
输出为:
content='hi!' additional_kwargs={} response_metadata={} id='6e5648f2-f755-4c1d-84ee-e3481e595ccb'
content='你好,世界!' additional_kwargs={} response_metadata={} id='b2ede0ed-0881-420b-a971-4eb2dc93e6b0'
5. 智能体实现
5.1 实现步骤
在掌握了LangChain和LangGraph的基本用法后,根据上面的目标进行拆解,并制定出以下开发步骤:
- 第1个智能体: 读取指定的文件,并让大模型来判断调用哪个工具(直接转为字幕文件,还是先转为音频后再转为字幕文件)。
此智能体中包含一个LLM和以下两个工具:- 将视频文件提取出音频
- 将音频文件转为LRC字幕文件
- 开发磁盘写入工具,将指定文件写入到磁盘
- 第2个智能体: 总结一下文本内容,并输出
- 根据应用需求,将上面的每个节点构建为一个图
- 运行构建好的图,并测试
5.2 实现代码
梳理出了实现步骤后,再编写以下代码,可以手写也可能AI辅助。上述流程的代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
LangGraph 流程:
1) 判断文件类型 → 提取音频(如是视频)
2) Whisper → LRC 字幕
3) Qwen Plus 文本总结
4) 写入文件
"""
import json
import os, re, subprocess, logging
import uuid
from pathlib import Path
from langgraph.checkpoint.memory import MemorySaver
from langgraph.types import Command
from opencc import OpenCC
from faster_whisper import WhisperModel
import dashscope
from http import HTTPStatus
from langgraph.graph import StateGraph, END
from typing import TypedDict, Optional, Literal
# ========== 配置 ==========
dashscope.api_key = os.getenv("DASHSCOPE_API_KEY")
if not dashscope.api_key:
raise RuntimeError("❗请先设置: export DASHSCOPE_API_KEY=你的key")
logging.basicConfig(level=logging.INFO, format="%(asctime)s [%(levelname)s] %(message)s")
# ========== 工具函数 ==========
def ensure_file(f):
if not Path(f).exists():
raise FileNotFoundError(f"文件不存在: {f}")
def extract_audio(video_path, wav_path):
ensure_file(video_path)
# 🚨 创建目录
Path(wav_path).parent.mkdir(parents=True, exist_ok=True)
cmd = [
"ffmpeg", "-y", "-i", video_path,
"-vn", "-acodec", "pcm_s16le",
"-ar", "16000", "-ac", "1", wav_path
]
result = subprocess.run(cmd, stderr=subprocess.PIPE, stdout=subprocess.PIPE, text=True)
if result.returncode != 0:
raise RuntimeError(f"FFmpeg failed:\n{result.stderr}")
if not Path(wav_path).exists():
raise FileNotFoundError(f"FFmpeg failed to create audio file: {wav_path}")
return wav_path
def whisper_to_lrc(audio_path, model_size="medium", device="cpu"):
# 加载模型
model = WhisperModel(model_size, device=device)
# 繁体转简体工具
cc = OpenCC('t2s')
# 转写
segments, info = model.transcribe(audio_path)
# seg → LRC 格式函数
def seg_to_lrc(seg):
t = seg.start
m = int(t // 60)
s = t - m * 60
# 👇 这里对字幕文字做繁转简
text = cc.convert(seg.text.strip())
return f"[{m:02d}:{s:05.2f}]{text}"
# 拼接 LRC
lrc_lines = [seg_to_lrc(seg) for seg in segments]
lrc = "\n".join(lrc_lines)
return lrc
def save_text(path, txt):
Path(path).parent.mkdir(parents=True, exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(txt)
logging.info(f"✅ 文件写入: {path}")
def qwen_summarize(text: str):
text_clean = re.sub(r"\[\d{2}:\d{2}\.\d{2}\]", "", text).replace("\n", " ")
prompt = (
"总结以下字幕内容,要求简洁、中文,不超过200字,列出关键要点:\n\n"
f"{text_clean}"
)
resp = dashscope.Generation.call(
model="qwen-plus",
messages=[{"role": "user", "content": prompt}],
temperature=0.2
)
if resp.status_code != HTTPStatus.OK:
raise RuntimeError(f"Qwen 调用失败: {resp}")
return resp.output["text"].strip()
# ========== LangGraph 状态 ==========
class State(TypedDict):
input_file: str
audio_file: Optional[str]
lrc_text: Optional[str]
summary: Optional[str]
output_dir: str
save_lrc: Optional[bool] # ← 由用户决定是否需要将字幕文件写入到磁盘
need_call_summarize: Optional[bool] # ← 由用户决定是否需要总结一下
# ========== 节点函数 ==========
def decide_and_extract(state: State):
f = state["input_file"]
suffix = Path(f).suffix.lower()
out_dir = state["output_dir"]
wav = f"{out_dir}/{Path(f).stem}.wav"
if suffix in {".mp4", ".mkv", ".mov", ".avi"}:
logging.info("🎬 检测到视频 → 提取音频")
audio = extract_audio(f, wav)
else:
logging.info("🎧 音频文件,跳过提取")
audio = f
state["audio_file"] = audio
logging.info("📝 Whisper 转字幕中...")
lrc = whisper_to_lrc(state["audio_file"])
state["lrc_text"] = lrc
logging.info("转换字幕文件已完成")
return state
def generate_lrc(state: State):
logging.info("📝 Whisper 转字幕中...")
lrc = whisper_to_lrc(state["audio_file"])
state["lrc_text"] = lrc
return state
def ask_save_lrc(state: State):
from langgraph.types import interrupt
decision = interrupt("📌 是否保存 LRC 文件? 输入 yes / no :")
print(decision)
# ✅ 支持布尔 或 字符串
if isinstance(decision, bool):
state["save_lrc"] = decision
else:
state["save_lrc"] = decision.lower() in ["yes", "y"]
return state
def ask_summarize(state: State):
from langgraph.types import interrupt
decision = interrupt("📌 是否需要总结一下? 输入 yes / no :")
print(decision)
# ✅ 支持布尔 或 字符串
if isinstance(decision, bool):
state["need_call_summarize"] = decision
else:
state["need_call_summarize"] = decision.lower() in ["yes", "y"]
return state
def save_lrc_if_needed(state: State):
if state.get("save_lrc"):
path = f"{state['output_dir']}/{Path(state['input_file']).stem}.lrc"
save_text(path, state["lrc_text"])
else:
logging.info("🚫 用户选择不保存字幕文件")
return state
def summarize(state: State):
logging.info("🤖 Qwen 总结中...")
summary = qwen_summarize(state["lrc_text"])
state["summary"] = summary
return state
def should_save_lrc(state: State) -> Literal["save_lrc", "ask_summarize"]:
# If the LLM makes a tool call, then perform an action
if state["save_lrc"]:
return "save_lrc"
return "ask_summarize"
def should_call_summarize(state: State) -> Literal["summarize", END]:
# If the LLM makes a tool call, then perform an action
if state["need_call_summarize"]:
return "summarize"
return END
# ========== LangGraph 构建 ==========
workflow = StateGraph(State)
# 添加节点
workflow.add_node("extract_wav", decide_and_extract)
workflow.add_node("ask_save_lrc", ask_save_lrc)
workflow.add_node("save_lrc", save_lrc_if_needed)
workflow.add_node("ask_summarize", ask_summarize)
workflow.add_node("summarize", summarize)
# 添加节点的的关系
workflow.set_entry_point("extract_wav")
workflow.add_edge("extract_wav", "ask_save_lrc")
workflow.add_conditional_edges("ask_save_lrc",
should_save_lrc,
["save_lrc", "ask_summarize"])
workflow.add_edge("save_lrc", "ask_summarize")
workflow.add_conditional_edges("ask_summarize",
should_call_summarize,
["summarize", END])
workflow.add_edge("summarize", END)
# Use a more durable checkpointer in production
checkpointer = MemorySaver()
graph = workflow.compile(checkpointer=checkpointer)
# Show the workflow
png = graph.get_graph().draw_mermaid_png()
with open("workflow.png", "wb") as f:
f.write(png)
print("流程图已保存为 workflow.png")
# ========== 运行入口 ==========
def run_pipeline(file, out="./output"):
config = {"configurable": {"thread_id": "thread-1"}}
# 第一次执行
step = graph.invoke(input={"input_file": file, "output_dir": out},
config=config)
while "__interrupt__" in step:
prompt = step["__interrupt__"][0].value
answer = input(prompt)
# 继续执行
step = graph.invoke(Command(resume=answer), config=config)
# 全流程结束
print("✅ 完成")
if step.get("summary"):
print("\n📘 总结内容:\n", step["summary"])
if __name__ == "__main__":
import argparse
p = argparse.ArgumentParser()
p.add_argument("--out", default="./output")
args = p.parse_args()
run_pipeline("F:/tmp/videos/1.mp4", args.out)
这里以我在抖音上的发布的一条视频为例进行测试,视频地址为:
3.87 复制打开抖音,看看【IT男海洋哥的作品】划船158公里从成都到乐山大佛 # 皮划艇 # 乐... https://v.douyin.com/zqqcl_cEhzY/ jCU:/ 09/06 f@O.XM
代码运行生,会生成以上代码对应的流程图,如下: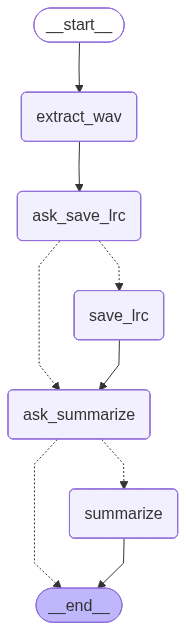
当用户输入yes,yes时,运行结果为: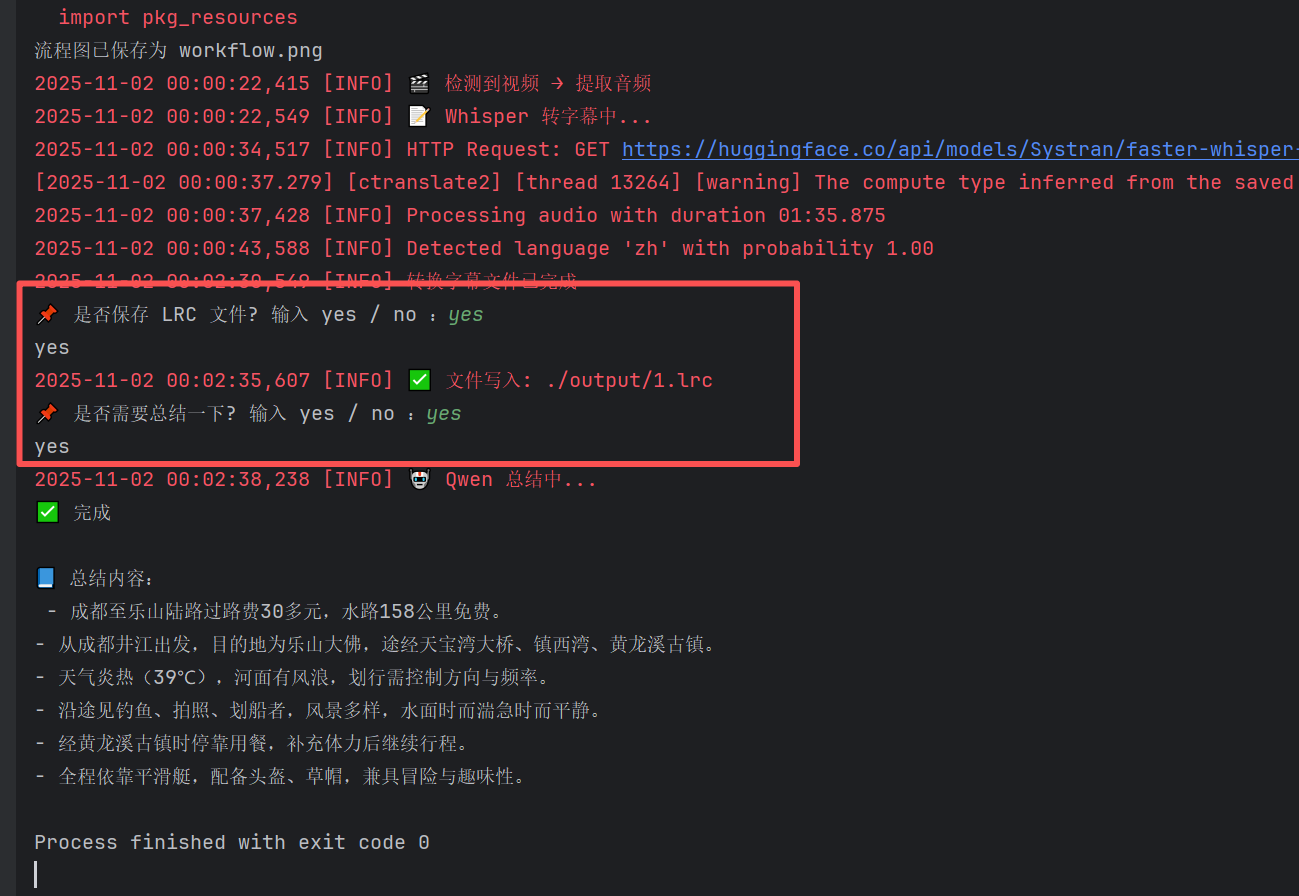
当用户输入yes,no时,运行结果为: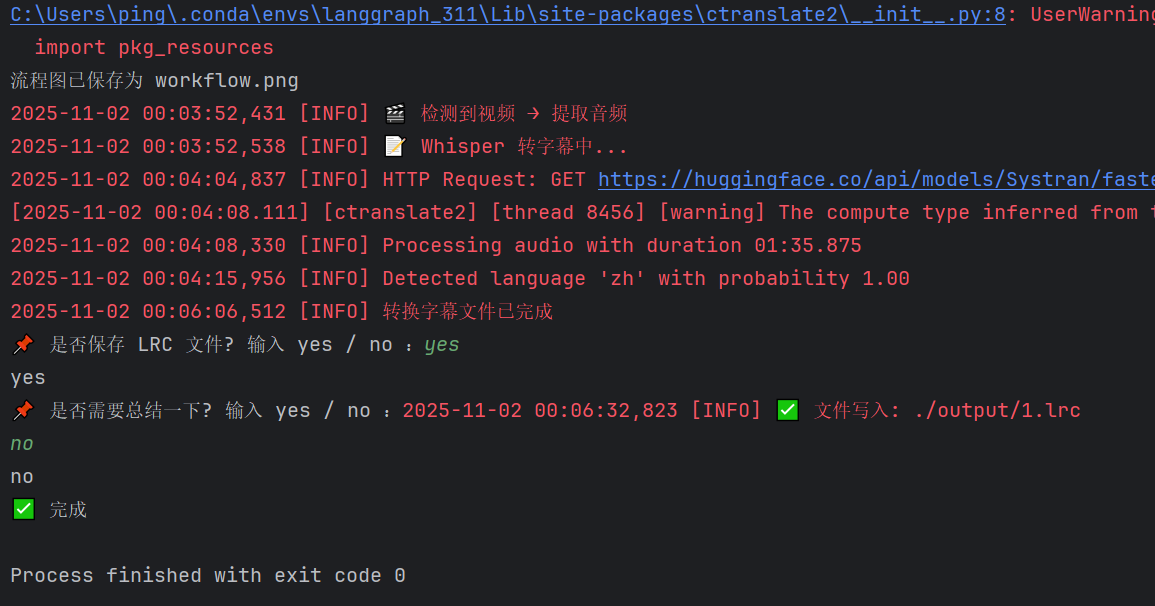
当用户输入no,no时,运行结果为: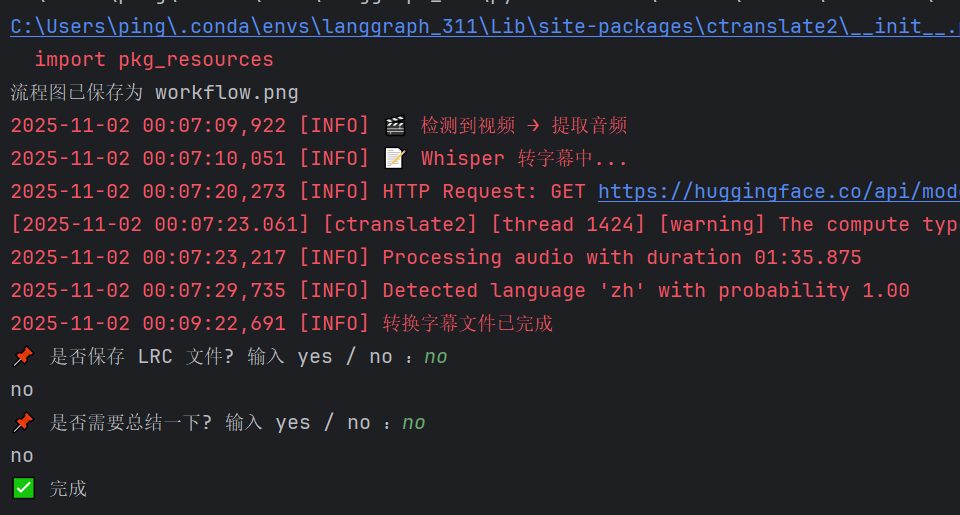
输出的lrc字幕文件为: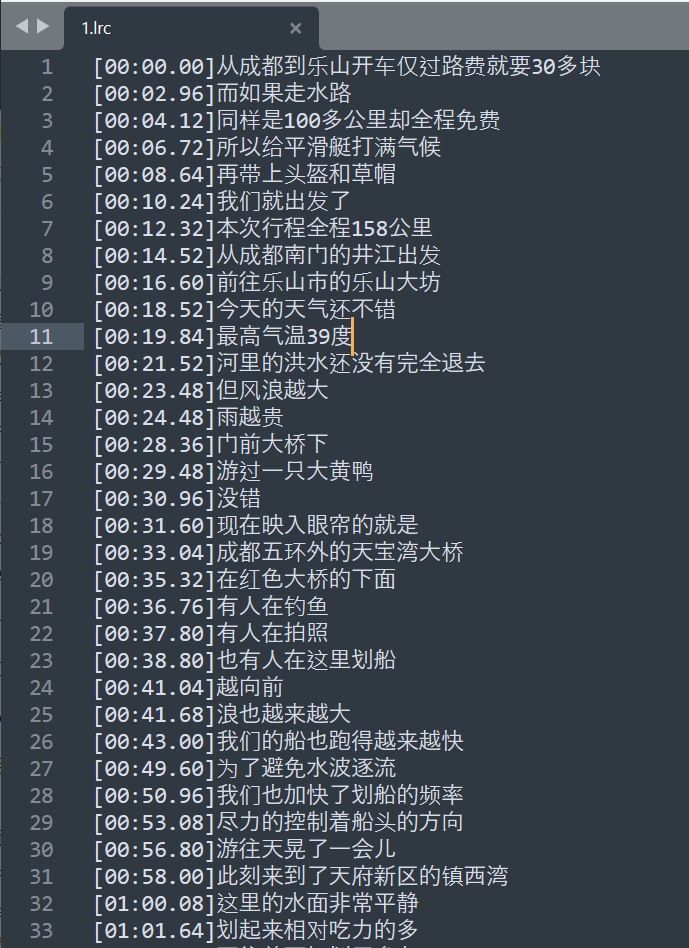
从运行结果来看,符合流程预期。
Tips:上面的代码实现中使用到了faster_whisper对视频和音频进行处理,底层会使用FFmpeg,运行前需要确保系统中已安装FFmpeg,并配置好环境变量。
6. LangGraphStudio
上面的代码中,我们使用LangGraph+LangChain完成一个AI工作流的开发。
也正是它是基于代码的,对于普通用户要读懂它们需要有一点的知识储备。
尽管langchain在官方博客中有说明过这篇文章:not-another-workflow-builder
但在他们也提供了对LangChain+LangGraph构建的工作流的可视化方式——LangGraph Studio。
通过Studio我们可以对LangChain和LangGraph构建的应用进行一个更好的观测与调试。
在本文中我们也来体验一下。
6.1 LangGraphStudio-LocalServer运行
参考链接langgraph-local-server中的步骤。
- 申请一个 LangSmith 的API Key
- 安装依赖:
pip install -U "langgraph-cli[inmem]" - 运行命令,创建LangGraph app:
langgraph new haiyang/app --template new-langgraph-project-python- 后面的new-langgraph-project-python是一个模板工程
- 上面命令创建的结构如下:
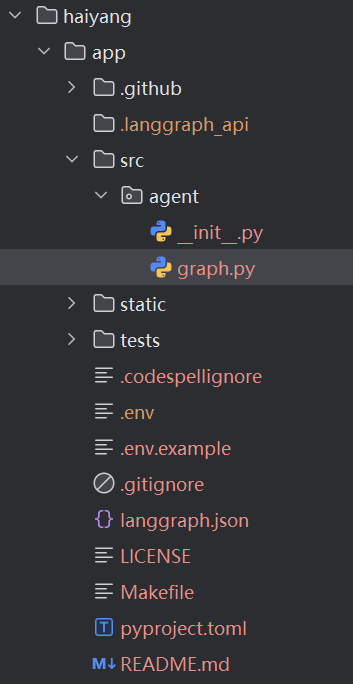
- 输入:
langgraph dev命令启动项目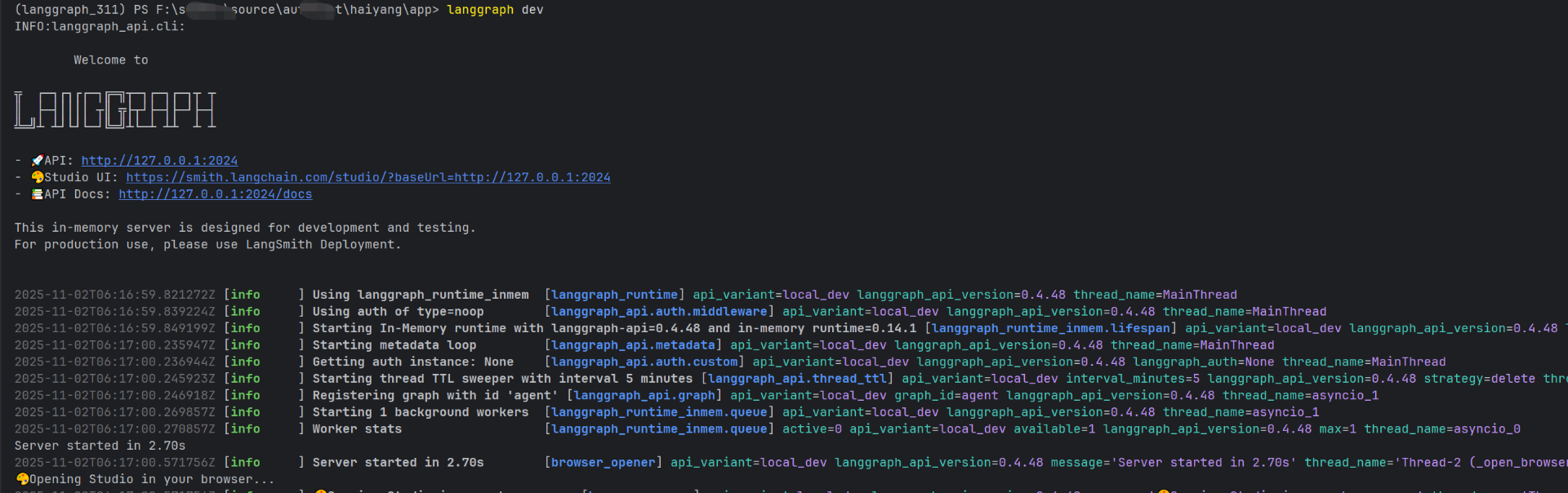
6.2 改造示例项目并运行
将5.2章节-实现代码部分的中的代码进行迁移,移动到haiyang/app/src/agent/graph.py中。
graph.py代码内容如下:
"""LangGraph single-node graph template.
Returns a predefined response. Replace logic and configuration as needed.
"""
from __future__ import annotations
import logging
import re
import subprocess
from dataclasses import dataclass
from http import HTTPStatus
from pathlib import Path
import dashscope
from faster_whisper import WhisperModel
from langgraph.graph import StateGraph, END
from langgraph.types import Command
from opencc import OpenCC
from typing_extensions import Literal, TypedDict, Optional
# ========== 工具函数 ==========
def ensure_file(f):
if not Path(f).exists():
raise FileNotFoundError(f"文件不存在: {f}")
def extract_audio(video_path, wav_path):
ensure_file(video_path)
# 🚨 创建目录
Path(wav_path).parent.mkdir(parents=True, exist_ok=True)
cmd = [
"ffmpeg", "-y", "-i", video_path,
"-vn", "-acodec", "pcm_s16le",
"-ar", "16000", "-ac", "1", wav_path
]
result = subprocess.run(cmd, stderr=subprocess.PIPE, stdout=subprocess.PIPE, text=True)
if result.returncode != 0:
raise RuntimeError(f"FFmpeg failed:\n{result.stderr}")
if not Path(wav_path).exists():
raise FileNotFoundError(f"FFmpeg failed to create audio file: {wav_path}")
return wav_path
def whisper_to_lrc(audio_path, model_size="medium", device="cpu"):
# 加载模型
model = WhisperModel(model_size, device=device)
# 繁体转简体工具
cc = OpenCC('t2s')
# 转写
segments, info = model.transcribe(audio_path)
# seg → LRC 格式函数
def seg_to_lrc(seg):
t = seg.start
m = int(t // 60)
s = t - m * 60
# 👇 这里对字幕文字做繁转简
text = cc.convert(seg.text.strip())
return f"[{m:02d}:{s:05.2f}]{text}"
# 拼接 LRC
lrc_lines = [seg_to_lrc(seg) for seg in segments]
lrc = "\n".join(lrc_lines)
return lrc
def save_text(path, txt):
Path(path).parent.mkdir(parents=True, exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(txt)
logging.info(f"✅ 文件写入: {path}")
def qwen_summarize(text: str):
text_clean = re.sub(r"\[\d{2}:\d{2}\.\d{2}\]", "", text).replace("\n", " ")
prompt = (
"总结以下字幕内容,要求简洁、中文,不超过200字,列出关键要点:\n\n"
f"{text_clean}"
)
resp = dashscope.Generation.call(
model="qwen-plus",
messages=[{"role": "user", "content": prompt}],
temperature=0.2
)
if resp.status_code != HTTPStatus.OK:
raise RuntimeError(f"Qwen 调用失败: {resp}")
return resp.output["text"].strip()
@dataclass
class State(TypedDict):
input_file: str
audio_file: Optional[str]
lrc_text: Optional[str]
summary: Optional[str]
output_dir: str
save_lrc: Optional[bool] # ← 由用户决定是否需要将字幕文件写入到磁盘
need_call_summarize: Optional[bool] # ← 由用户决定是否需要总结一下
# ========== 节点函数 ==========
def decide_and_extract(state: State):
f = state["input_file"]
suffix = Path(f).suffix.lower()
out_dir = state["output_dir"]
wav = f"{out_dir}/{Path(f).stem}.wav"
if suffix in {".mp4", ".mkv", ".mov", ".avi"}:
logging.info("🎬 检测到视频 → 提取音频")
audio = extract_audio(f, wav)
else:
logging.info("🎧 音频文件,跳过提取")
audio = f
state["audio_file"] = audio
logging.info("📝 Whisper 转字幕中...")
lrc = whisper_to_lrc(state["audio_file"])
state["lrc_text"] = lrc
logging.info("转换字幕文件已完成")
return state
def generate_lrc(state: State):
logging.info("📝 Whisper 转字幕中...")
lrc = whisper_to_lrc(state["audio_file"])
state["lrc_text"] = lrc
return state
def ask_save_lrc(state: State):
from langgraph.types import interrupt
decision = interrupt("📌 是否保存 LRC 文件? 输入 yes / no :")
print(decision)
# ✅ 支持布尔 或 字符串
if isinstance(decision, bool):
state["save_lrc"] = decision
else:
state["save_lrc"] = decision.lower() in ["yes", "y"]
return state
def ask_summarize(state: State):
from langgraph.types import interrupt
decision = interrupt("📌 是否需要总结一下? 输入 yes / no :")
print(decision)
# ✅ 支持布尔 或 字符串
if isinstance(decision, bool):
state["need_call_summarize"] = decision
else:
state["need_call_summarize"] = decision.lower() in ["yes", "y"]
return state
def save_lrc_if_needed(state: State):
if state.get("save_lrc"):
path = f"{state['output_dir']}/{Path(state['input_file']).stem}.lrc"
save_text(path, state["lrc_text"])
else:
logging.info("🚫 用户选择不保存字幕文件")
return state
def summarize(state: State):
logging.info("🤖 Qwen 总结中...")
summary = qwen_summarize(state["lrc_text"])
state["summary"] = summary
return state
def should_save_lrc(state: State) -> Literal["save_lrc", "ask_summarize"]:
# If the LLM makes a tool call, then perform an action
if state["save_lrc"]:
return "save_lrc"
return "ask_summarize"
def should_call_summarize(state: State) -> Literal["summarize", END]:
# If the LLM makes a tool call, then perform an action
if state["need_call_summarize"]:
return "summarize"
return END
# ========== 运行入口 ==========
def run_pipeline(file, out="./output"):
config = {"configurable": {"thread_id": "thread-1"}}
# 第一次执行
step = graph.invoke(input={"input_file": file, "output_dir": out},
config=config)
while "__interrupt__" in step:
prompt = step["__interrupt__"][0].value
answer = input(prompt)
# 继续执行
step = graph.invoke(Command(resume=answer), config=config)
# 全流程结束
print("✅ 完成")
if step.get("summary"):
print("\n📘 总结内容:\n", step["summary"])
class Context(TypedDict):
"""Context parameters for the agent.
Set these when creating assistants OR when invoking the graph.
See: https://langchain-ai.github.io/langgraph/cloud/how-tos/configuration_cloud/
"""
my_configurable_param: str
graph = (
StateGraph(State, context_schema=Context)
.add_node("extract_wav", decide_and_extract)
.add_node("ask_save_lrc", ask_save_lrc)
.add_node("save_lrc", save_lrc_if_needed)
.add_node("ask_summarize", ask_summarize)
.add_node("summarize", summarize)
.add_edge("__start__", "extract_wav")
.add_edge("extract_wav", "ask_save_lrc")
.add_conditional_edges("ask_save_lrc",
should_save_lrc,
["save_lrc", "ask_summarize"])
.add_edge("save_lrc", "ask_summarize")
.add_conditional_edges("ask_summarize",
should_call_summarize,
["summarize", END])
.add_edge("summarize", END)
.compile(name="New Graph")
)
并替换.env中的LANGSMITH_API_KEY为真实的LangSmith的key。
之后再运行,并进入Studio的界面: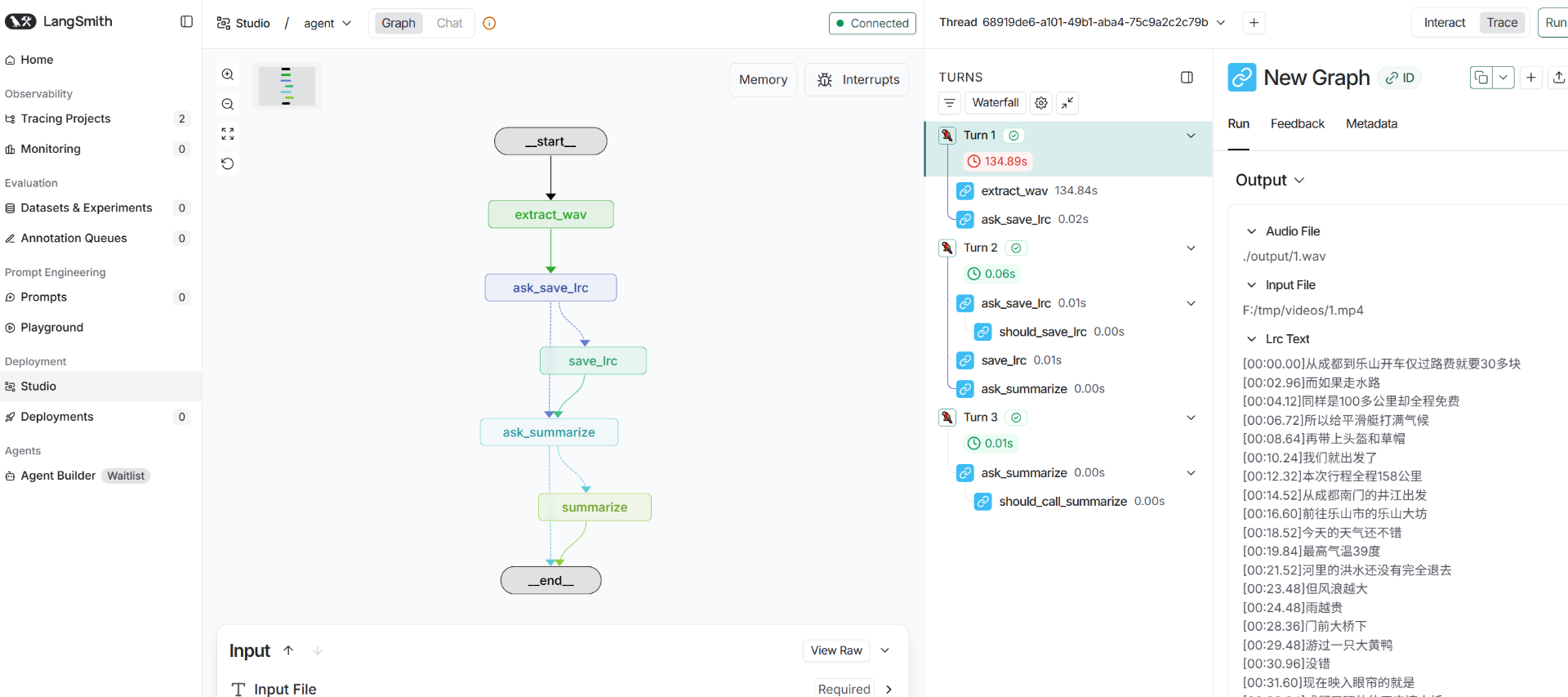
每一项的运行过程步骤与更新均可在Studio界面中显示,且非常直观,截图如下: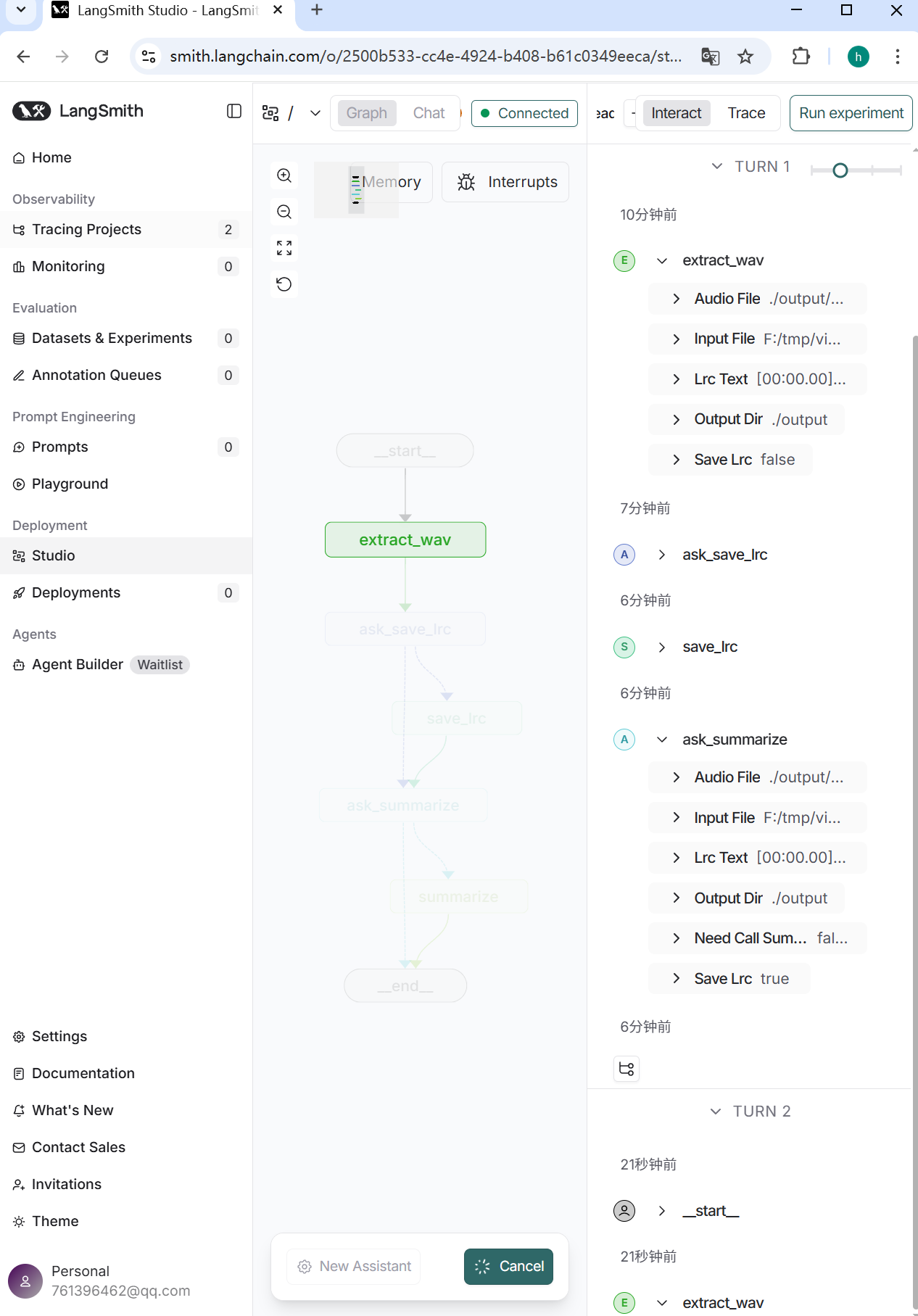
7.总结
在本文中的示例中,结合LangChain、LangGraph、LangSmith逐步完成了一个多智能体应用的实现。
通过LangSmith中Studio的可视化与可观测的功能,以让我们能对所构建的具体Graph的理解都能有所帮助。
不得不说,LangGraph是真的强!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)