ollama本地化部署deepseek/大模型及其api流式调用
Ollama 是一个轻量级本地大模型运行环境,可以在 Windows / macOS / Linux 上运行主流开源模型。它支持:前往官网:🔗 https://ollama.com/download选择 Windows Installer (.exe) 下载。安装完成后,Ollama 会自动在系统中注册命令行工具 。打开 PowerShell 或 CMD,执行:如果输出版本号(例如 ),说明安装
目录
Windows下使用 Ollama 安装并调用 DeepSeek 等大模型全流程(含API与Java流式调用)
一、Ollama 简介
Ollama 是一个轻量级本地大模型运行环境,可以在 Windows / macOS / Linux 上运行主流开源模型。它支持:
- DeepSeek、Qwen、LLaMA、Phi-3、Gemma 等模型;
- 本地推理,无需联网;
- 提供 HTTP REST API;
- 支持 流式输出,适合集成前后端聊天应用。
二、环境准备与安装
1. 下载 Ollama 安装包
前往官网:
选择 Windows Installer (.exe) 下载。
安装完成后,Ollama 会自动在系统中注册命令行工具 ollama。
2. 验证安装是否成功
打开 PowerShell 或 CMD,执行:
ollama --version
如果输出版本号(例如 ollama 0.3.12),说明安装成功。
三、模型管理与路径调整
1. 默认模型存放位置
Ollama 默认会把模型文件放在:
C:\Users\<用户名>\.ollama\models
如果系统盘空间有限,可以修改模型文件路径。
2. 修改模型文件存储路径变更
2.1 迁移下载的模型
关闭 Ollama 服务:
taskkill /F /IM ollama.exe
移动模型文件夹:
move "C:\Users\<用户名>\.ollama" "D:\OllamaModels"
配置环境变量(让 Ollama 指向新目录):
打开 系统环境变量 → 新建:
| 变量名 | 值 |
|---|---|
| OLLAMA_MODELS | D:\LLM\models |
或者使用命令行方式:
setx OLLAMA_MODELS "D:\LLM\models"
修改后需重启命令行窗口生效。
2.2 安装时就设定模型下载路径
可以在找到下载的文件(.exe)然后执行如下命令,在安装时即可默认更改下载模型的路径
OllamaSetup.exe /DIR="D:\LLM\models"
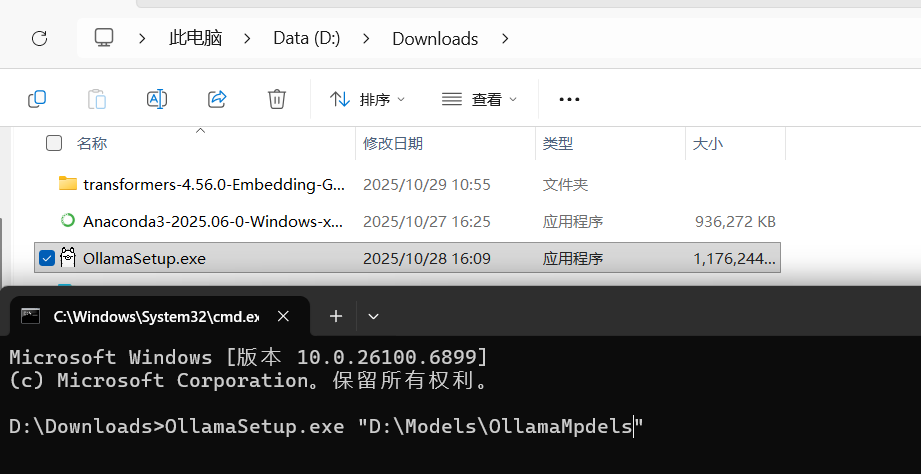
2.3 页面更改下载模型路径
打开桌面上
ollama安装后的图标,找到设置-》更改模型下载位置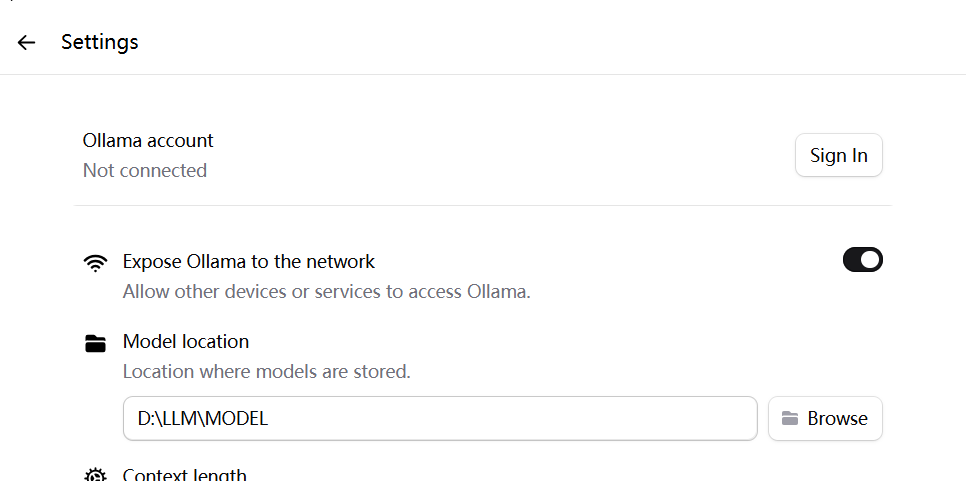
四、Ollama 服务启动与模型安装
1. 启动 Ollama 服务
执行命令:
ollama serve & //&保持后台启动,不会因为窗口关闭就停止
默认监听在:
http://localhost:11434
2. 拉取 DeepSeek 模型
2.1 手动拉取模型
以 DeepSeek 为例:
ollama pull deepseek-coder
其它模型可选:
ollama pull deepseek-llm
ollama pull qwen2
ollama pull llama3
ollama pull gemma2
下载完成后,模型文件会保存在 OLLAMA_MODELS 所指的目录。
2.1 页面下载模型
当进行聊天的时候,选择的模型如果没有下载,后台会默认进行下载,等带下载完成后即可使用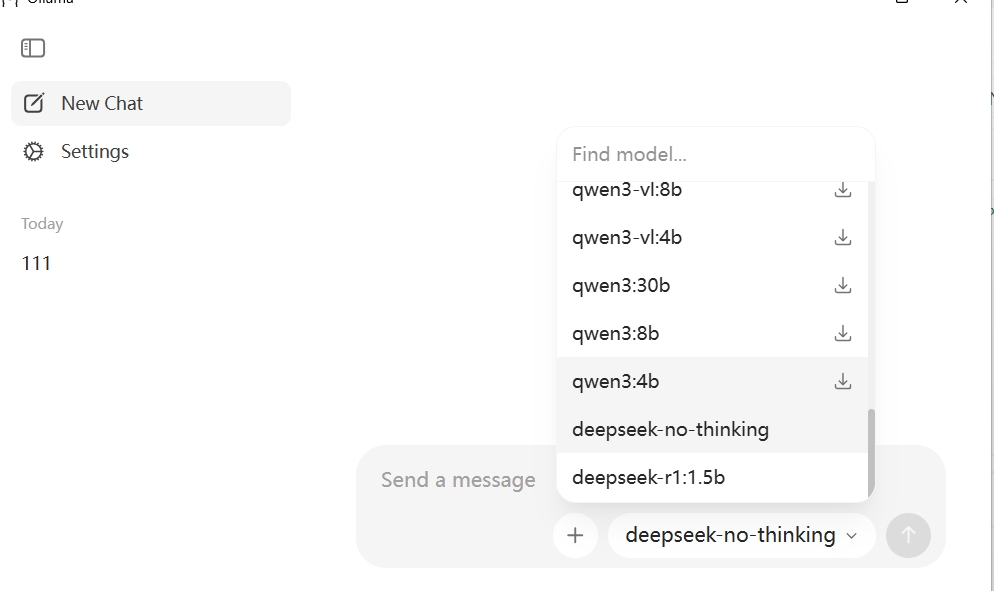
3. 查看本地模型
ollama list
示例输出:

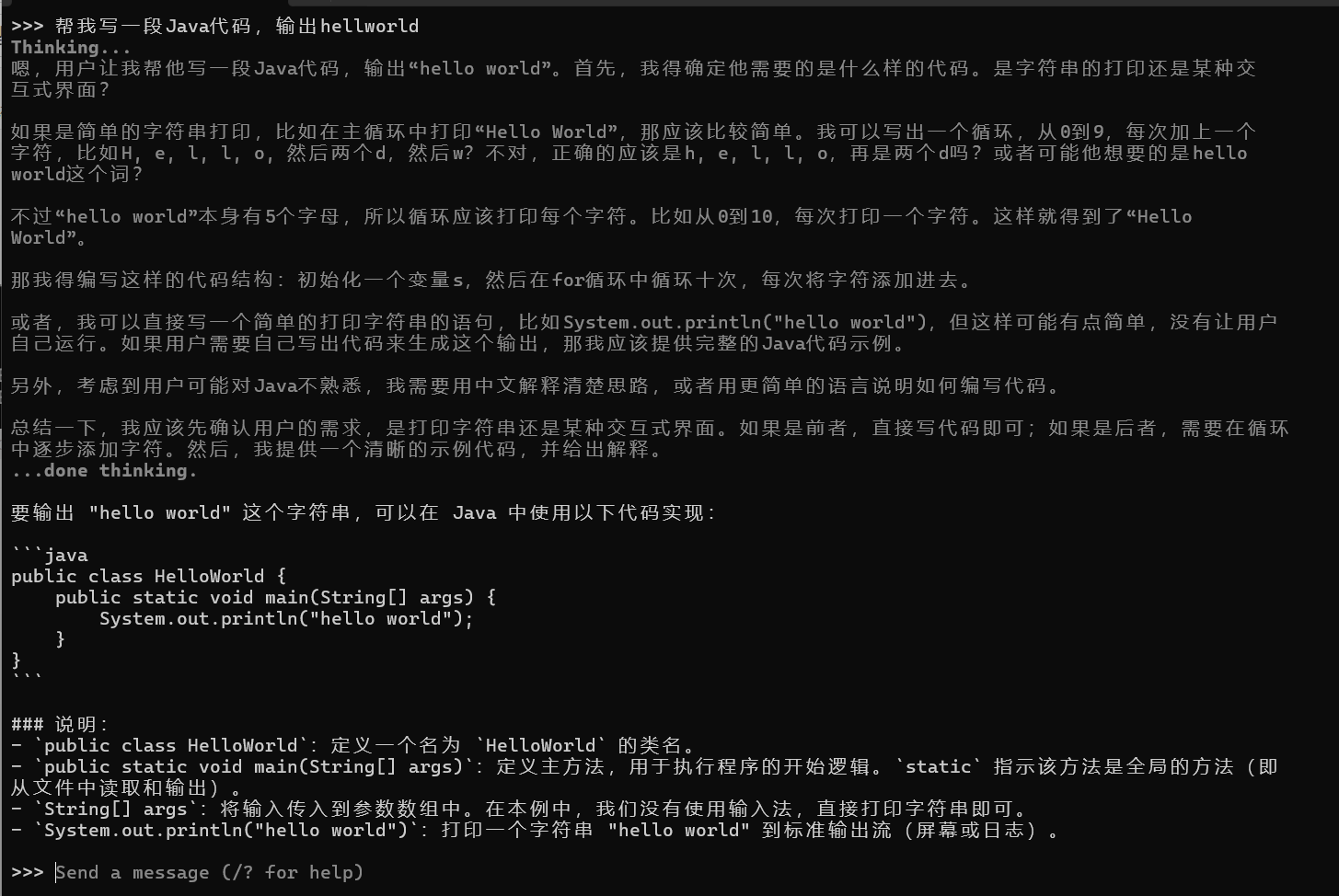
4. 测试模型运行
ollama run deepseek-r1:1.5b
进入交互模式:
>>> 帮我写一段Java代码,输出Hello World。
六、自定义模型构建与管理(Modelfile 教程)
除了直接使用官方模型(如 DeepSeek、Qwen、LLaMA 等),
Ollama 还支持通过 Modelfile 构建自定义模型。
你可以在现有模型基础上添加:
- 自定义系统提示词(System Prompt)
- 预定义上下文内容
- 模型参数(如温度、top_p 等)
- LoRA 微调文件
这样可以快速创建一个“专属助理”或“行业知识模型”。
1. 什么是 Modelfile?
Modelfile 类似于 Dockerfile,用来描述一个模型的构建规则。
一个简单示例如下:
##该行表示我下载的模型代码在DeepSeek-R1-Distill-Qwen-1.5B文件下,也可以使用全路径
FROM ./DeepSeek-R1-Distill-Qwen-1.5B
PARAMETER temperature 0.7
PARAMETER top_p 0.9
SYSTEM """
你是一个专业的Java开发助手,擅长Spring Boot和分布式系统设计。
请用清晰、准确的代码和注释回答问题。
"""
# 可选:添加预置知识内容
MESSAGE """
你好!我是DeepSeek-Java助手,请问你需要我帮你写什么Java代码?
"""
FROM:指定基础模型的代码路径,需要包含保包含以下关键文件(文件名可能因模型版本略有差异):
1.模型权重文件(如 .bin 或 .safetensors 格式)2.配置文件(config.json)3.分词器文件(tokenizer_config.json、tokenizer.model 或 vocab.json 等)。PARAMETER:设定生成参数。SYSTEM:定义模型的角色或系统提示词。MESSAGE:定义模型启动时的初始输出。
2. 创建自定义模型
2.1. 生成Modefile文件
在Ollama中,Modelfile并非默认自动生成的文件,而是需要手动创建或通过命令导出的。如果找不到Modelfile,可能是因为你尚未导出模型配置或未手动创建,具体解决方法如下:
情况1:需要导出已下载模型的Modelfile
如果你想修改已下载的模型(如DeepSeek、Llama等)的配置,需要先通过ollama show命令导出该模型的Modelfile:
-
列出已有的模型,确认模型名称和标签:
ollama list例如,假设显示有
deepseek-r1:1.5b或deepseek-coder:6b。 -
导出模型的Modelfile:
执行以下命令,将模型的配置导出到本地文件(文件名可自定义,如my_modelfile):ollama show deepseek-r1:1.5b--modelfile > my_modelfile- 替换
deepseek-r1:1.5b为你的模型名称(如llama3:8b)。 - 执行后,当前目录会生成
my_modelfile文件,这就是该模型的配置文件(包含TEMPLATE等关键信息)。
- 替换
情况2:需要手动创建新的Modelfile
如果你想导入自己的模型或自定义新模型,需要手动创建Modelfile:
- 在任意目录新建文本文件,命名为
Modelfile(无后缀,或自定义名称如my_model.txt)。 - 按格式编写内容,例如基础结构:
具体格式参考Ollama官方文档的Modelfile语法。FROM /path/to/your/model.gguf # 本地模型权重路径 TEMPLATE "{{ .Prompt }} {{ .Response }}" # 自定义提示词模板 PARAMETER temperature 0.5
常见问题解决
- 提示“model not found”:确保模型名称正确(通过
ollama list确认),且已成功下载(未下载的模型无法导出Modelfile)。 - 导出后文件为空:可能是模型版本过旧或格式特殊,尝试更新模型(
ollama pull 模型名)后重新导出。 - 找不到导出的文件:检查命令执行的目录(默认在当前终端的工作目录),或通过
ls(Linux/macOS)、dir(Windows)查看当前目录文件。
通过以上方法,可以获取或创建Modelfile,进而修改模型配置。
2.2 根据Modefile文件创建新模型
打开my_modelfile,找到TEMPLATE字段,查看是否有引导模型输出思考过程的内容。例如:
# 原始模板可能包含类似内容(示例)
TEMPLATE """
用户问:{{ .Prompt }}
请先思考,再回答:
思考:...
回答:{{ .Response }}
"""
修改为仅输出最终回答的模板,例如:
# 修改后的模板(仅保留回答部分)
TEMPLATE """
{{ .Prompt }}
{{ .Response }}
"""
或根据DeepSeek模型的原生格式调整。
用修改后的Modelfile重新构建模型(自定义一个新名称,避免覆盖原模型):
ollama create deepseek-no-thinking -f my_modelfile
deepseek-no-thinking是新模型的名称,可自定义。
我这里是像做一个不带思考过程的大模型,于是我将原来安装的deepseek-r1:1.5b的模型的语法去除掉思考过程。
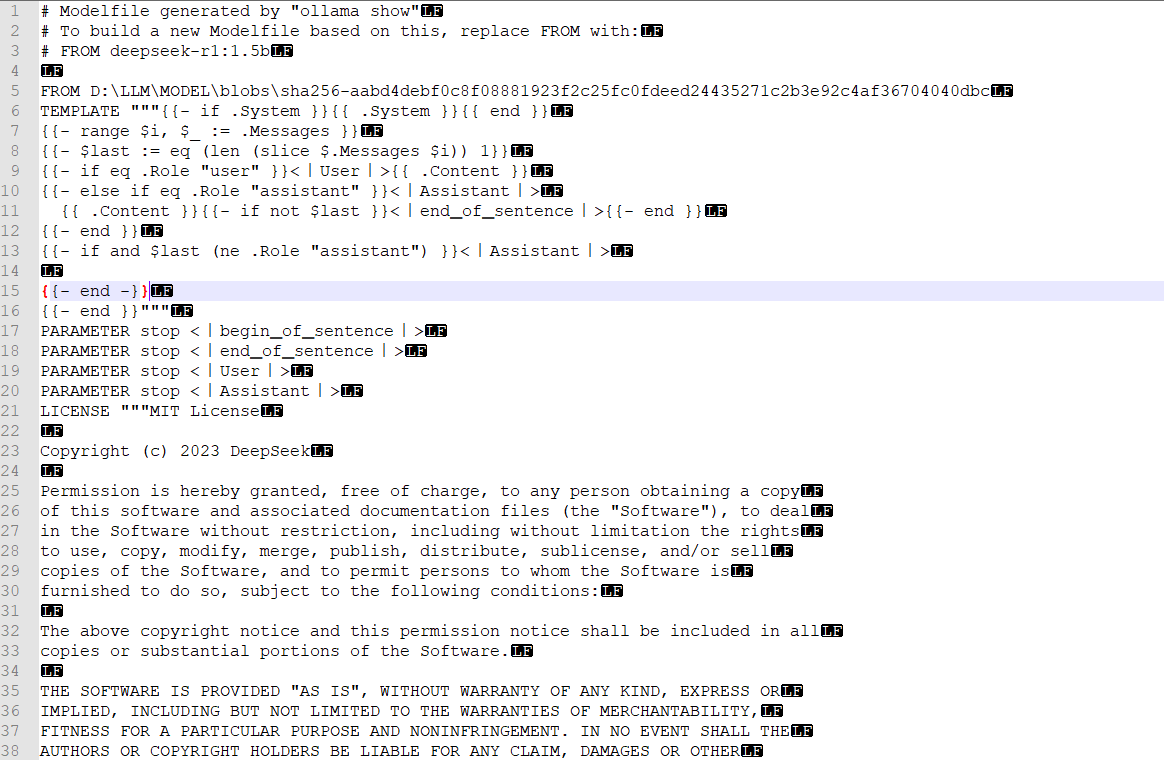
验证是否成功:
ollama list
输出示例:
使用新创建的模型,此时应不再输出“thinking”:
ollama run deepseek-no-thinking
通过以上步骤,即可去除Ollama调用DeepSeek模型时的“thinking”输出。
3. 删除模型
删除模型:
ollama rm deepseek-algo
重新构建(更新)模型:
ollama create deepseek-algo -f Modelfile --force
七、API 调用(REST 接口)
Ollama 启动后自动提供 API 服务。
默认接口地址为:
http://localhost:11434/api/generate
1. 基本调用示例(curl)
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-coder",
"prompt": "写一个Python程序读取CSV文件并统计行数。"
}'
返回结果:
{
"model": "deepseek-coder",
"response": "```python\nimport csv\n...```",
"done": true
}
2. apipost调用
2.1 单次对话
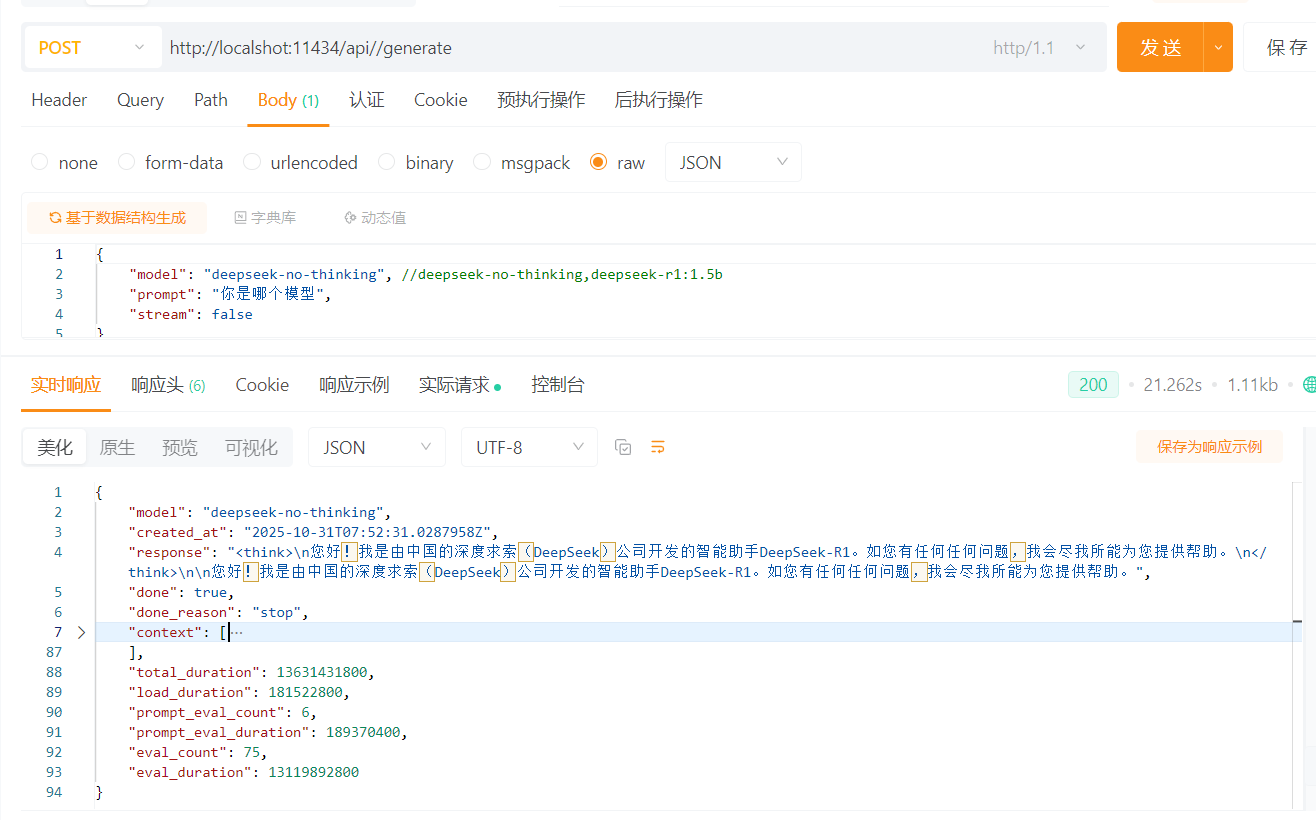
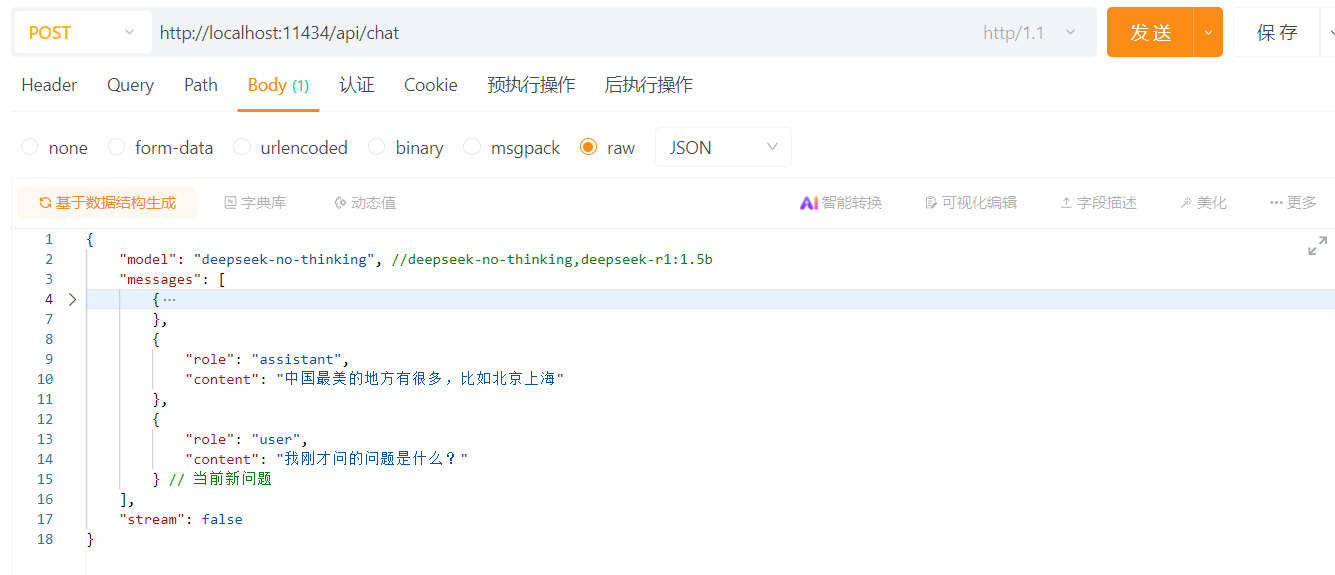
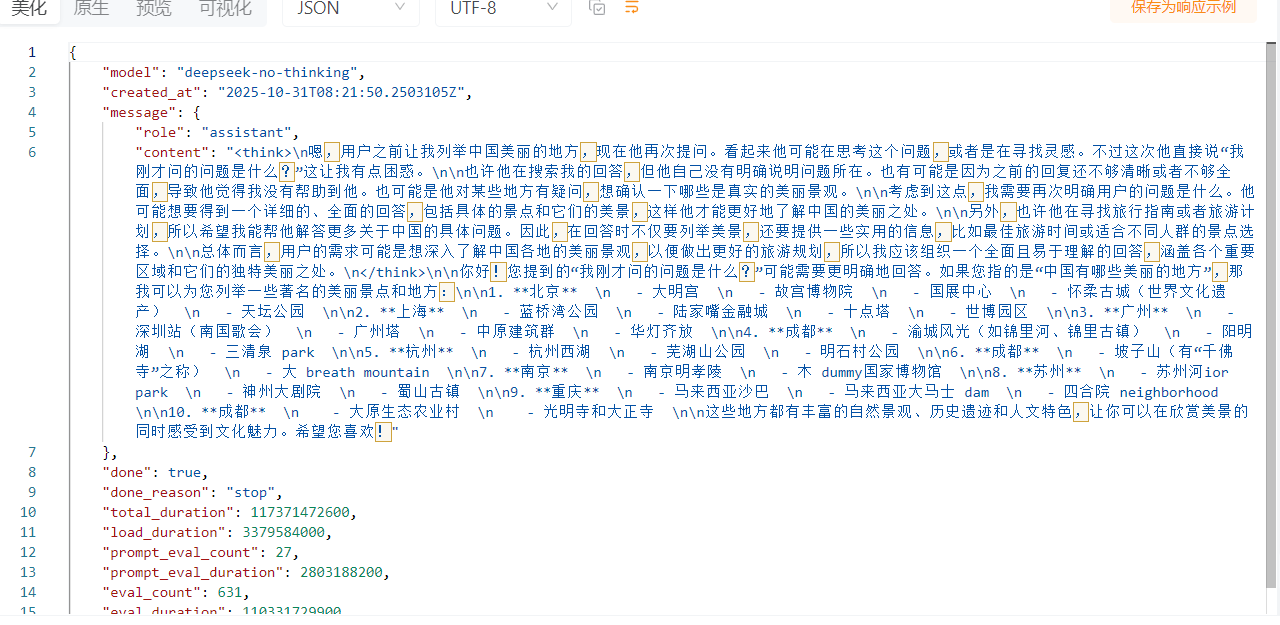
2.2 多次对话
3.用 Docker 快速部署 Open-WebUI:轻松实现本地 Ollama 模型可视化交互
在本地部署大语言模型时,命令行交互总是不够直观。今天给大家分享一个实用方案:通过 Docker 快速搭建 Open-WebUI 可视化界面,轻松连接本地 Ollama 运行的模型,实现像 ChatGPT 一样的网页交互体验。全程无需复杂配置,新手也能快速上手。
3.1 什么是 Open-WebUI?
Open-WebUI 是一款开源的大语言模型可视化交互工具,支持连接 Ollama、OpenAI 等多种模型服务。它的优势在于:
- 界面简洁美观,支持对话历史、模型切换、参数调整
- 完全本地化部署,数据不泄露
- 兼容主流开源模型(如 Llama 3、Gemma、Qwen 等)
- 可通过 Docker 一键部署,省去环境配置麻烦
3.2 准备工作
在开始前,请确保你的环境满足以下条件:
- 已安装 Docker(Docker 安装教程)
- 已安装 Ollama 并下载至少一个模型(Ollama 安装教程)
- 例如已运行
ollama pull llama3下载 Llama 3 模型
- 例如已运行
- 基础命令行操作能力
3.3 步骤 1:让 Ollama 允许外部访问
Ollama 默认只允许本地(127.0.0.1)访问,而 Docker 容器中的 Open-WebUI 属于“外部程序”,需要先配置 Ollama 允许局域网访问。
3.3.1 不同系统的配置方法:
- 👉 Windows/macOS 用户
直接在终端中重启 Ollama 并指定监听所有 IP:
# 先关闭正在运行的 Ollama(若已启动)
# 然后执行以下命令,让 Ollama 监听所有网络接口,&支持后台运行
ollama serve & --host 0.0.0.0
(如果习惯用后台服务启动,可在服务配置中添加 --host 0.0.0.0 参数)
- 👉 Linux 用户
通过系统服务配置永久生效:
# 编辑 Ollama 服务配置
sudo nano /etc/systemd/system/ollama.service
# 在 ExecStart 行末尾添加 --host 0.0.0.0,如下:
ExecStart=/usr/local/bin/ollama serve --host 0.0.0.0
# 重启服务使配置生效
sudo systemctl daemon-reload
sudo systemctl restart ollama
配置完成后,Ollama 会监听 0.0.0.0:11434,允许同一网络中的设备(包括 Docker 容器)访问。
3.4 用 Docker 启动 Open-WebUI
打开终端,执行以下命令一键部署 Open-WebUI:
docker run -d \
-p 3000:8080 \ # 宿主机端口:容器内端口,3000 可自定义
--add-host=host.docker.internal:host-gateway \ # 让容器访问宿主机
-v open-webui:/app/backend/data \ # 持久化存储数据(对话历史、配置等)
--name open-webui \ # 容器名称
--restart always \ # 开机自启动
ghcr.io/open-webui/open-webui:main
## 单行命令
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
命令参数说明:
-p 3000:8080:将容器内的 8080 端口映射到宿主机的 3000 端口,后续通过http://localhost:3000访问界面--add-host:解决 Docker 容器访问宿主机的网络问题(关键配置)-v open-webui:/app/backend/data:创建数据卷,确保重启容器后对话历史不丢失--restart always:宿主机重启后,容器自动启动
3.5:连接 Ollama 模型
部署完成后,开始配置 Open-WebUI 连接本地 Ollama:
-
访问界面
打开浏览器,输入http://localhost:3000(如果是服务器部署,替换为服务器 IP:3000)。首次访问需要创建管理员账号(输入用户名、密码即可)。 -
添加 Ollama 模型源
- 登录后,点击左侧菜单 「Settings」(设置) → 「Models」(模型)
- 点击 「Add Model Source」(添加模型源),选择 「Ollama」
- API Base URL 填写:
http://宿主机IP:11434(例如你的电脑本地 IP 是 192.168.1.100,则填写http://192.168.1.100:11434)
✅ 小技巧:如果是本地部署,也可直接填http://host.docker.internal:11434(Docker 自动解析宿主机 IP) - 无需填写 API Key(Ollama 默认无认证),点击 「Save」保存。
-
加载模型
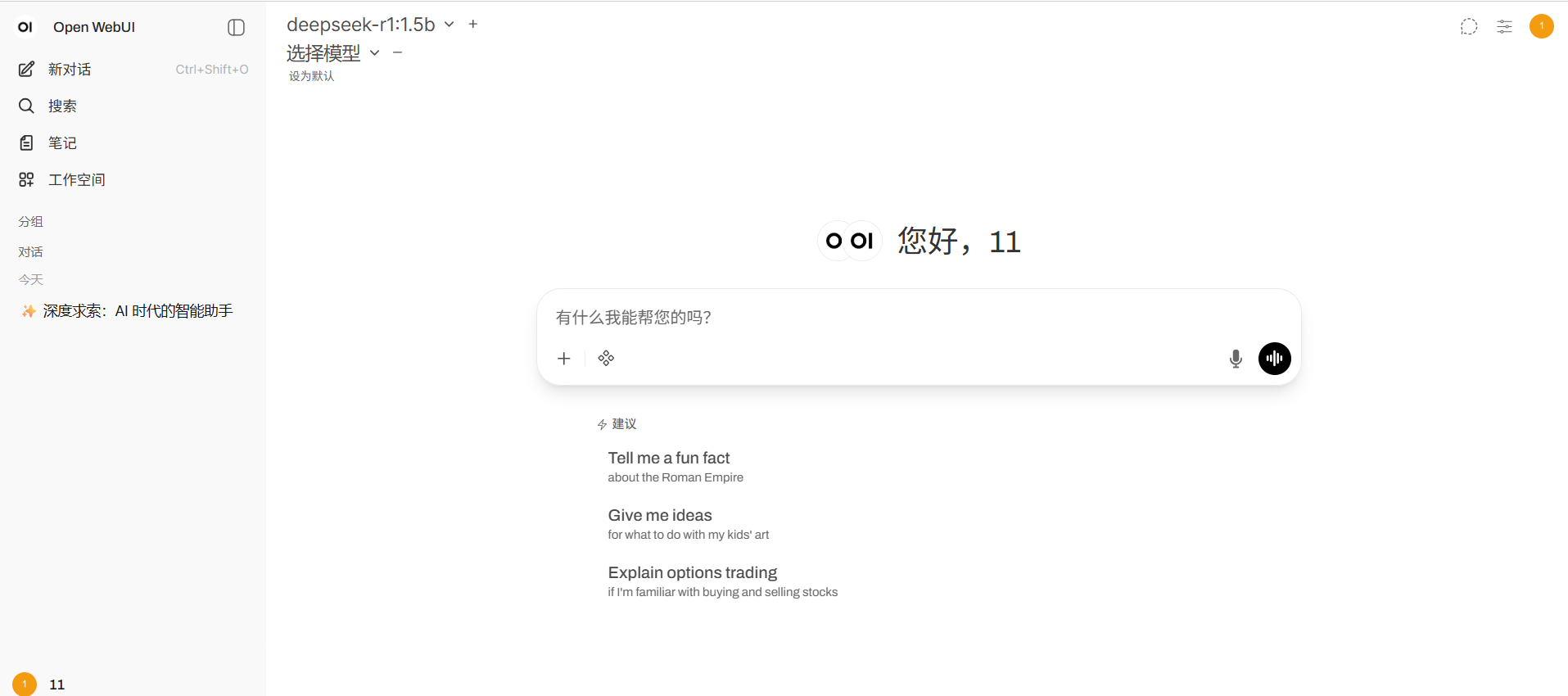
保存后,Open-WebUI 会自动同步 Ollama 中已下载的模型(如 llama3、gemma 等)。在左侧模型列表中选择一个模型,即可开始对话!
- 效果展示
4. 前后端流式调用,使用Java/Nginx后台做转发
流式调用需要将参数stream设置为true。
4.1 使用 WebFlux-JAVA后端转发
添加依赖(Maven):
<!-- Spring WebFlux 核心依赖(响应式Web框架) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<!-- Reactor Netty(WebFlux默认的HTTP客户端/服务器) -->
<dependency>
<groupId>io.projectreactor.netty</groupId>
<artifactId>reactor-netty-core</artifactId>
</dependency>
示例代码:
- .流配置文件WebClientConfig
import io.netty.channel.ChannelOption;
import io.netty.handler.timeout.ReadTimeoutHandler;
import io.netty.handler.timeout.WriteTimeoutHandler;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.client.reactive.ReactorClientHttpConnector;
import org.springframework.web.reactive.function.client.WebClient;
import reactor.netty.http.client.HttpClient;
import reactor.netty.resources.ConnectionProvider;
import java.time.Duration;
import java.util.concurrent.TimeUnit;
@Configuration
public class WebClientConfig {
@Bean
public WebClient efficientOllamaWebClient() {
// 为旧版本Reactor Netty配置连接池
ConnectionProvider connectionProvider = ConnectionProvider.builder("ollama-pool")
.maxConnections(100) // 增加最大连接数
.pendingAcquireTimeout(Duration.ofSeconds(30)) // 增加获取连接的等待超时
.maxIdleTime(Duration.ofMinutes(8)) // 增加连接最大空闲时间到30分钟
.evictInBackground(Duration.ofMinutes(5)) // 后台清理间隔
.build();
// 配置HTTP客户端
HttpClient httpClient = HttpClient.create(connectionProvider)
// 连接超时设置
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 30000) // 增加连接超时到30秒
// 读写超时设置
.doOnConnected(conn -> conn
.addHandlerLast(new ReadTimeoutHandler(8, TimeUnit.MINUTES)) // 增加到30分钟
.addHandlerLast(new WriteTimeoutHandler(8, TimeUnit.MINUTES)) // 增加到30分钟
)
// 禁用自动释放响应内容
.disableRetry(true); // 禁用重试
// 构建WebClient
return WebClient.builder()
.baseUrl("http://127.0.0.1:11434")
.clientConnector(new ReactorClientHttpConnector(httpClient))
.codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(16 * 1024 * 1024)) // 增加内存大小到16MB
.build();
}
}
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.reactive.function.BodyInserters;
import org.springframework.web.reactive.function.client.WebClient;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
@RestController
public class OllamaController {
private final WebClient ollamaWebClient;
// 修改构造函数,使用配置好的WebClient Bean
public OllamaController(WebClient efficientOllamaWebClient) {
this.ollamaWebClient = efficientOllamaWebClient;
}
@PostMapping(value = "/api/model/generate", produces = MediaType.APPLICATION_STREAM_JSON_VALUE)
// 关键:返回类型设为APPLICATION_STREAM_JSON_VALUE,而非TEXT_EVENT_STREAM_VALUE
public Flux<String> streamOllamaReactiveGenerate(@RequestBody String requestBody) {
return Mono.just(requestBody)
.flatMapMany(body ->
ollamaWebClient.post()
.uri("/api/generate")
.contentType(MediaType.APPLICATION_JSON)
.body(BodyInserters.fromValue(body))
.retrieve()
.bodyToFlux(String.class) // 直接处理为字符串流
.onErrorContinue((throwable, o) -> {
System.err.println("Error in stream: " + throwable.getMessage());
throwable.printStackTrace();
})
.map(line -> {
// 关键修复:移除SSE的data:前缀(如果存在)
if (line.startsWith("data:")) {
line = line.substring("data:".length()).trim();
}
System.out.println("line: " + line);
return line;
})
.filter(line -> !line.isEmpty()) // 过滤空行
)
.onErrorContinue((throwable, o) -> {
System.err.println("Error in outer stream: " + throwable.getMessage());
throwable.printStackTrace();
});
}
@PostMapping(value = "/api/model/chat", produces = MediaType.APPLICATION_STREAM_JSON_VALUE)
// 关键:返回类型设为APPLICATION_STREAM_JSON_VALUE,而非TEXT_EVENT_STREAM_VALUE
public Flux<String> streamOllamaReactiveChat(@RequestBody String requestBody) {
return Mono.just(requestBody)
.flatMapMany(body ->
ollamaWebClient.post()
.uri("/api/chat")
.contentType(MediaType.APPLICATION_JSON)
.body(BodyInserters.fromValue(body))
.retrieve()
.bodyToFlux(String.class) // 直接处理为字符串流
.onErrorContinue((throwable, o) -> {
System.err.println("Error in stream: " + throwable.getMessage());
throwable.printStackTrace();
})
.map(line -> {
// 关键修复:移除SSE的data:前缀(如果存在)
if (line.startsWith("data:")) {
line = line.substring("data:".length()).trim();
}
System.out.println("line: " + line);
return line;
})
.filter(line -> !line.isEmpty()) // 过滤空行
)
.onErrorContinue((throwable, o) -> {
System.err.println("Error in outer stream: " + throwable.getMessage());
throwable.printStackTrace();
});
}
}
- 前端h5+js
以下前端代码存在部分错误,gpt快速生成的接收流式响应的代码。仅作为案例
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Ollama Chat Web</title>
<style>
body {
background-color: #f7f9fb;
font-family: "Segoe UI", "Microsoft YaHei", Arial, sans-serif;
margin: 0;
display: flex;
flex-direction: column;
height: 100vh;
}
header {
background-color: #1e88e5;
color: white;
padding: 10px 20px;
display: flex;
justify-content: space-between;
align-items: center;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
}
header .options {
display: flex;
align-items: center;
gap: 12px;
}
header select, header input[type="checkbox"] {
padding: 5px;
border-radius: 6px;
border: none;
}
#chat {
flex: 1;
overflow-y: auto;
padding: 15px;
}
.message {
margin: 10px 0;
padding: 10px 14px;
border-radius: 12px;
max-width: 80%;
word-wrap: break-word;
white-space: pre-wrap;
box-shadow: 0 1px 2px rgba(0,0,0,0.05);
}
.user {
background-color: #d1e7ff;
align-self: flex-end;
margin-left: auto;
}
.bot {
background-color: #ffffff;
border: 1px solid #ddd;
}
.think {
background-color: #f0f0f0;
color: #555;
font-style: italic;
border-left: 4px solid #aaa;
margin: 6px 0 6px 20px;
padding: 6px 10px;
border-radius: 8px;
max-width: 75%;
white-space: pre-wrap;
}
#input-area {
display: flex;
padding: 10px;
border-top: 1px solid #ddd;
background-color: white;
}
#messageInput {
flex: 1;
padding: 10px;
border-radius: 8px;
border: 1px solid #ccc;
font-size: 15px;
font-family: "Segoe UI", "Microsoft YaHei", Arial, sans-serif;
}
#sendBtn {
margin-left: 10px;
padding: 10px 20px;
background-color: #1e88e5;
color: white;
border: none;
border-radius: 8px;
cursor: pointer;
transition: background-color 0.2s;
}
#sendBtn:hover {
background-color: #1565c0;
}
#sendBtn:disabled {
background-color: #90caf9;
cursor: not-allowed;
}
.loading-indicator {
display: inline-block;
width: 16px;
height: 16px;
border: 3px solid rgba(255,255,255,.3);
border-radius: 50%;
border-top-color: white;
animation: spin 1s ease-in-out infinite;
}
@keyframes spin {
to { transform: rotate(360deg); }
}
.status-bar {
font-size: 12px;
color: #666;
padding: 5px 15px;
border-top: 1px solid #eee;
}
</style>
</head>
<body>
<header>
<h3>Ollama Chat Web</h3>
<div class="options">
<label>模型:
<select id="modelSelect">
<option value="deepseek-r1:1.5b">deepseek-r1:1.5b</option>
<option value="deepseek-no-thinking">deepseek-no-thinking</option>
</select>
</label>
<label>
<input type="checkbox" id="dialogueMode" /> 连续对话
</label>
</div>
</header>
<div id="chat"></div>
<div class="status-bar" id="statusBar">就绪</div>
<div id="input-area">
<input id="messageInput" placeholder="输入消息..." />
<button id="sendBtn">
<span id="sendBtnText">发送</span>
<span class="loading-indicator" style="display:none;"></span>
</button>
</div>
<script>
const API_PROXY = "http://10.100.0.106:18089"; // 基础地址分离,方便拼接接口
let chatHistory = [];
let isProcessing = false;
let statusRestored = false;
// 滚动到底部
function scrollToBottom() {
const chat = document.getElementById("chat");
chat.scrollTop = chat.scrollHeight;
}
// 更新状态
function updateStatus(text) {
document.getElementById("statusBar").textContent = text;
}
// 添加消息:返回消息容器,方便后续插入思考块
function appendMessage(role, text, type = "bot") {
const chat = document.getElementById("chat");
const div = document.createElement("div");
div.classList.add("message", type);
div.textContent = text;
chat.appendChild(div);
scrollToBottom();
return div; // 返回消息容器,用于插入思考块
}
// 创建思考块:改为作为botDiv子元素,确保样式生效
function createThinkBlock() {
const thinkDiv = document.createElement("div");
thinkDiv.classList.add("think");
thinkDiv.textContent = "";
thinkDiv.style.marginTop = "8px"; // 增加顶部间距,优化显示
return thinkDiv;
}
// 构建请求体:按接口类型区分参数
function buildRequest(model, text, isDialogue) {
const baseParams = {
model: model, // 模型参数通用
stream: true // 流式请求通用
};
if (isDialogue) {
// 多次聊天(chat):用messages传递历史+当前消息,无prompt
return {
...baseParams,
messages: [...chatHistory, { role: "user", content: text }]
};
} else {
// 单次聊天(generate):用prompt传递当前消息,无messages
return {
...baseParams,
prompt: text
};
}
}
// 实时更新文本
function updateText(element, newText) {
if (element.textContent !== newText) {
element.textContent = newText;
scrollToBottom();
}
}
// 解码HTML实体
function decodeHtmlEntities(text) {
console.log("解码前:", text); // 调试信息
if (typeof text !== 'string') {
console.log("文本不是字符串类型:", typeof text); // 调试信息
return '';
}
// 先尝试解码HTML实体
let decoded = text.replace(/</g, '<').replace(/>/g, '>').replace(/&/g, '&').replace(/"/g, '"').replace(/'/g, "'");
// 再处理Unicode转义序列
decoded = decoded.replace(/\\u003c/g, '<').replace(/\\u003e/g, '>').replace(/\\n/g, '\n');
// 处理多个换行符
decoded = decoded.replace(/\n+/g, '\n');
console.log("解码后:", decoded); // 调试信息
return decoded;
}
// 统一恢复UI状态
function restoreUIStatus(isSuccess = true, errorMsg = "") {
if (statusRestored) return;
const sendBtn = document.getElementById("sendBtn");
const sendBtnText = document.getElementById("sendBtnText");
const loadingIndicator = document.querySelector(".loading-indicator");
sendBtn.disabled = false;
sendBtnText.style.display = "inline";
loadingIndicator.style.display = "none";
statusRestored = true;
isProcessing = false;
updateStatus(isSuccess ? "处理完成" : `错误: ${errorMsg}`);
}
// 发送消息:区分接口地址
async function sendMessage() {
if (isProcessing) return;
statusRestored = false;
isProcessing = true;
const input = document.getElementById("messageInput");
const text = input.value.trim();
if (!text) return alert("请输入消息内容");
// 显示加载状态
const sendBtn = document.getElementById("sendBtn");
const sendBtnText = document.getElementById("sendBtnText");
const loadingIndicator = document.querySelector(".loading-indicator");
sendBtn.disabled = true;
sendBtnText.style.display = "none";
loadingIndicator.style.display = "inline-block";
updateStatus("正在处理...");
const model = document.getElementById("modelSelect").value;
const isDialogue = document.getElementById("dialogueMode").checked;
// 1. 区分接口地址:单次用generate,多次用chat
const apiUrl = isDialogue
? `${API_PROXY}/api/model/chat` // 多次聊天接口
: `${API_PROXY}/api/model/generate`; // 单次聊天接口
// 2. 构建对应参数
const requestBody = buildRequest(model, text, isDialogue);
// 添加用户消息
appendMessage("user", text, "user");
input.value = "";
// 准备bot容器
const botDiv = appendMessage("bot", "");
let thinkDiv = null;
let fullAnswer = "";
let jsonBuffer = "";
const timeoutTimer = setTimeout(() => {
console.warn("超时未收到响应,自动恢复状态");
restoreUIStatus(true, "响应超时,已自动完成");
}, 30000);
try {
// 发送请求
const response = await fetch(apiUrl, {
method: "POST",
headers: {
"Content-Type": "application/json;charset=utf-8",
"Accept": "application/stream+json"
},
body: JSON.stringify(requestBody)
});
if (!response.ok) {
const errorText = await response.text().catch(() => "未知错误");
throw new Error(`[${response.status}] ${errorText}`);
}
// 处理流式响应
const reader = response.body.getReader();
const decoder = new TextDecoder("utf-8");
while (true) {
const { done, value } = await reader.read();
if (done) {
clearTimeout(timeoutTimer);
// 处理剩余JSON
if (jsonBuffer.trim()) {
tryParseJson(jsonBuffer, botDiv, thinkDiv, model, (content) => fullAnswer += content);
}
restoreUIStatus(true);
break;
}
jsonBuffer += decoder.decode(value, { stream: true });
let jsonEndIndex;
while ((jsonEndIndex = jsonBuffer.indexOf('}')) !== -1) {
const jsonStartIndex = jsonBuffer.lastIndexOf('{', jsonEndIndex);
if (jsonStartIndex === -1) {
jsonBuffer = jsonBuffer.substring(jsonEndIndex + 1);
continue;
}
const fullJson = jsonBuffer.substring(jsonStartIndex, jsonEndIndex + 1);
jsonBuffer = jsonBuffer.substring(jsonEndIndex + 1);
// 修复:传递当前选中的模型,用于判断是否清理思考块
const parseResult = tryParseJson(fullJson, botDiv, thinkDiv, model, (content) => {
fullAnswer += content;
});
thinkDiv = parseResult.thinkDiv;
if (parseResult.isDone) {
clearTimeout(timeoutTimer);
restoreUIStatus(true);
}
}
}
// 更新连续对话历史(仅多次聊天模式)
if (isDialogue && fullAnswer) {
chatHistory.push({ role: "user", content: text });
chatHistory.push({ role: "assistant", content: fullAnswer });
}
} catch (e) {
clearTimeout(timeoutTimer);
console.error("请求错误:", e);
updateText(botDiv, `❌ 错误: ${e.message}`);
restoreUIStatus(false, e.message);
}
}
/**
* 增强版JSON解析:只处理内容显示
*/
function tryParseJson(jsonStr, botDiv, thinkDiv, model, appendAnswer) {
let isDone = false;
try {
const data = JSON.parse(jsonStr);
console.log("收到数据:", data); // 调试信息
// 1. 处理结束标记
if (data.done === true) {
isDone = true;
}
// 2. 处理回答内容:支持多种格式
let responseContent = "";
// 格式1: generate接口 - 顶层response字段
if (data.response !== undefined) {
responseContent = data.response;
console.log("单次对话内容:", responseContent); // 调试信息
}
// 格式2: chat接口 - 顶层content字段(根据你的调试信息)
else if (data.content !== undefined) {
responseContent = data.content;
console.log("多次对话内容(顶层):", responseContent); // 调试信息
}
// 格式3: chat接口 - message.content字段(之前的预期格式)
else if (data.message && data.message.content !== undefined) {
responseContent = data.message.content;
console.log("多次对话内容(嵌套):", responseContent); // 调试信息
} else {
console.log("未找到内容字段,完整数据:", data); // 调试信息
}
console.log("准备解码的内容:", responseContent); // 调试信息
// 3. 更新内容显示
if (responseContent !== undefined) {
const decodedContent = decodeHtmlEntities(responseContent);
console.log("解码后内容:", decodedContent); // 调试信息
if (decodedContent || responseContent) { // 即使解码后为空也尝试显示原始内容
appendAnswer(decodedContent || responseContent);
updateText(botDiv, botDiv.textContent + (decodedContent || responseContent));
console.log("更新显示内容:", botDiv.textContent); // 调试信息
}
}
} catch (e) {
console.warn("解析JSON失败,跳过:", e.message, "内容:", jsonStr);
}
return { thinkDiv, isDone };
}
// 事件监听
document.getElementById("sendBtn").addEventListener("click", sendMessage);
document.getElementById("messageInput").addEventListener("keydown", e => {
if (e.key === "Enter" && !e.shiftKey) {
e.preventDefault();
sendMessage();
}
});
document.getElementById("dialogueMode").addEventListener("change", function() {
updateStatus(this.checked ? "已切换到连续对话模式" : "已切换到单次对话模式");
});
</script>
</body>
</html>
- 运行效果:
后端终端会实时打印模型输出内容,就像使用 ChatGPT 一样逐字生成。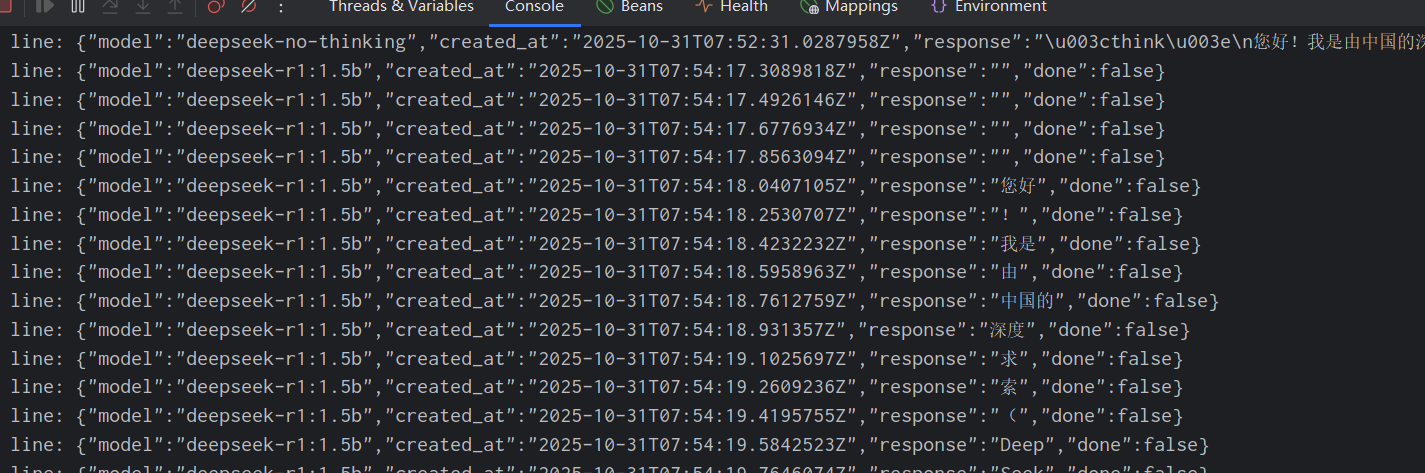
前端调用: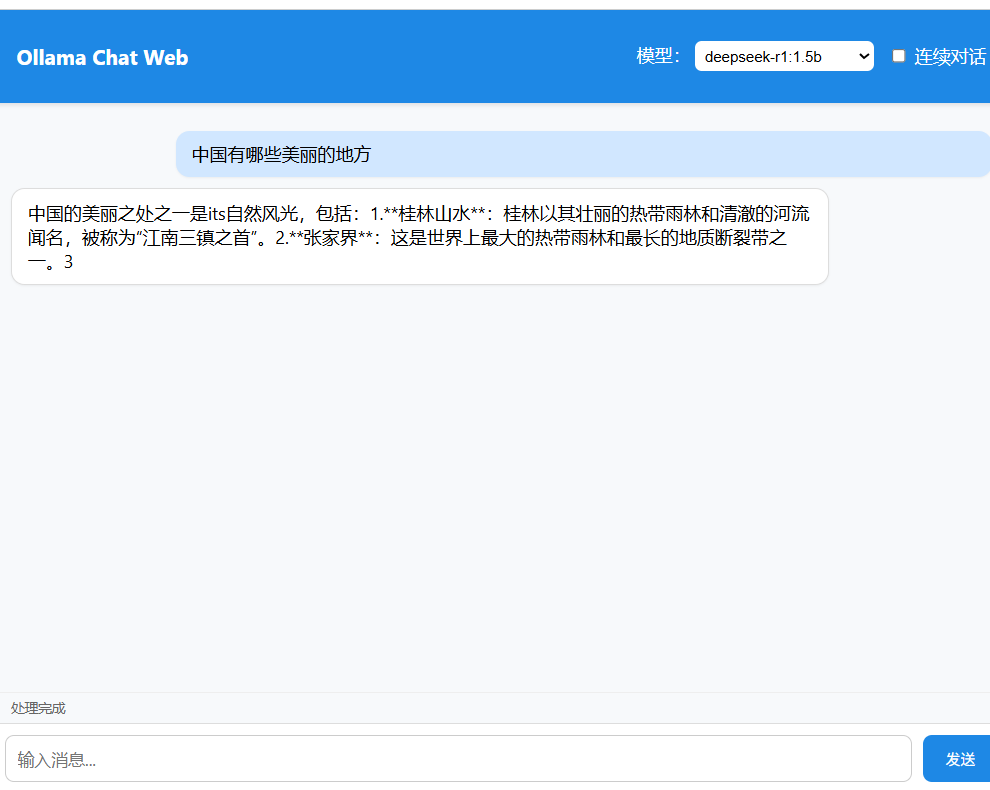
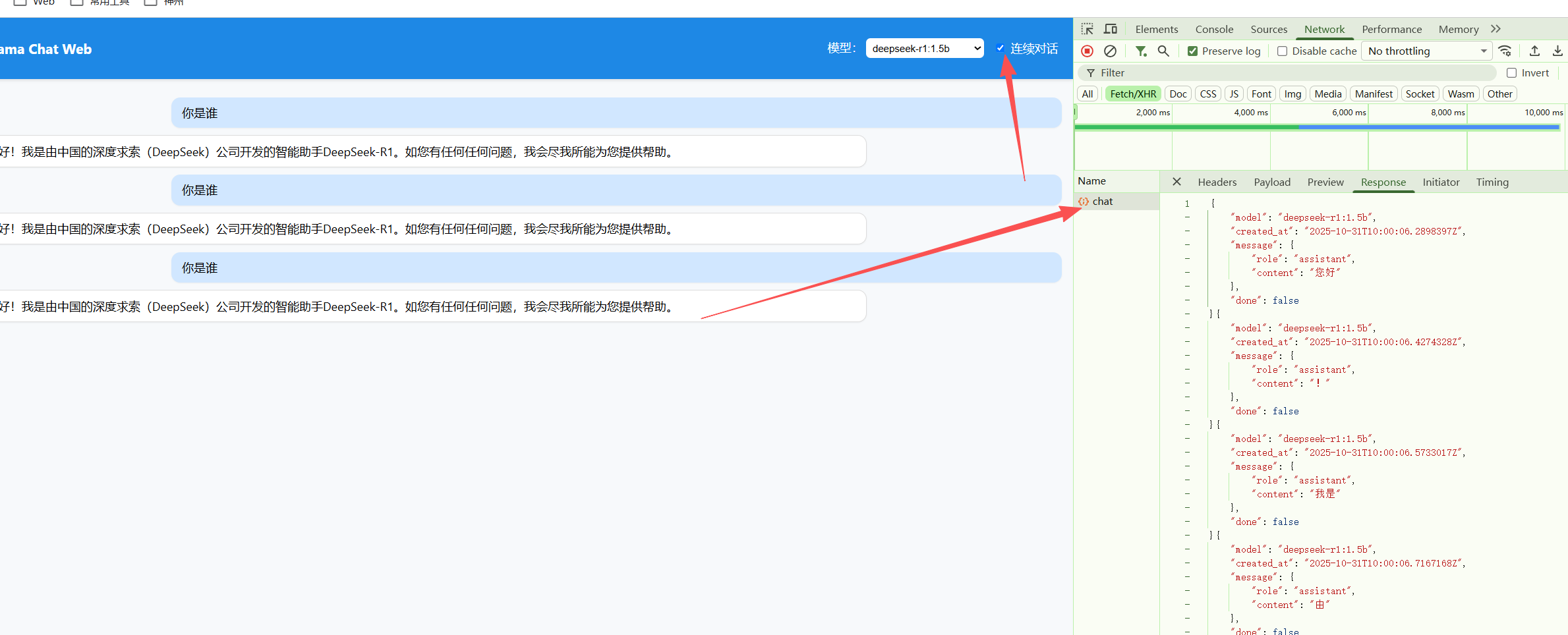
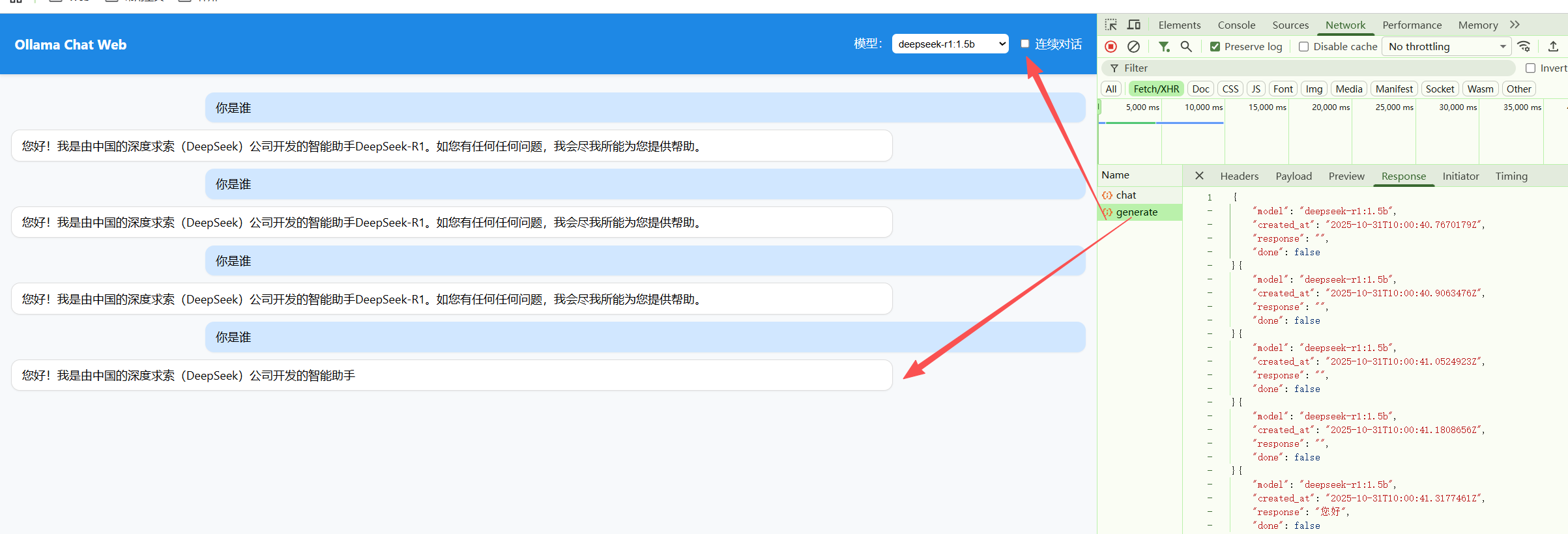
4.2 使用 nginx转发至ollama
- 首先对nginx在server模块做配置,前端访问http://ip+port/ollama/api/generate,会被nginx自动转发到11434
location /ollama/ {
rewrite ^/ollama/(.*)$ /$1 break;
proxy_pass http://127.0.0.1:11434/;
# 延长超时时间(根据实际需求调整,这里设置为60秒)
proxy_connect_timeout 60s; # 连接超时
proxy_send_timeout 60s; # 发送超时
proxy_read_timeout 60s; # 读取超时(关键:Ollama生成内容可能较慢)
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_set_header Origin "";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# 流式响应相关设置(Ollama可能使用流式输出)
proxy_buffering off;
proxy_cache off;
chunked_transfer_encoding on;
proxy_pass_request_headers on;
# CORS设置
add_header Access-Control-Allow-Origin * always;
add_header Access-Control-Allow-Headers "Origin, X-Requested-With, Content-Type, Accept, Authorization" always;
add_header Access-Control-Allow-Methods "GET, POST, OPTIONS" always;
add_header Access-Control-Allow-Credentials true always;
# 处理OPTIONS请求
if ($request_method = OPTIONS) {
add_header Access-Control-Allow-Origin * always;
add_header Access-Control-Allow-Headers "Origin, X-Requested-With, Content-Type, Accept, Authorization" always;
add_header Access-Control-Allow-Methods "GET, POST, OPTIONS" always;
add_header Access-Control-Allow-Credentials true always;
add_header Content-Length 0;
add_header Content-Type text/plain;
return 204;
}
- 前端页面展示调用过程,这里我用nginx监听的是18088端口
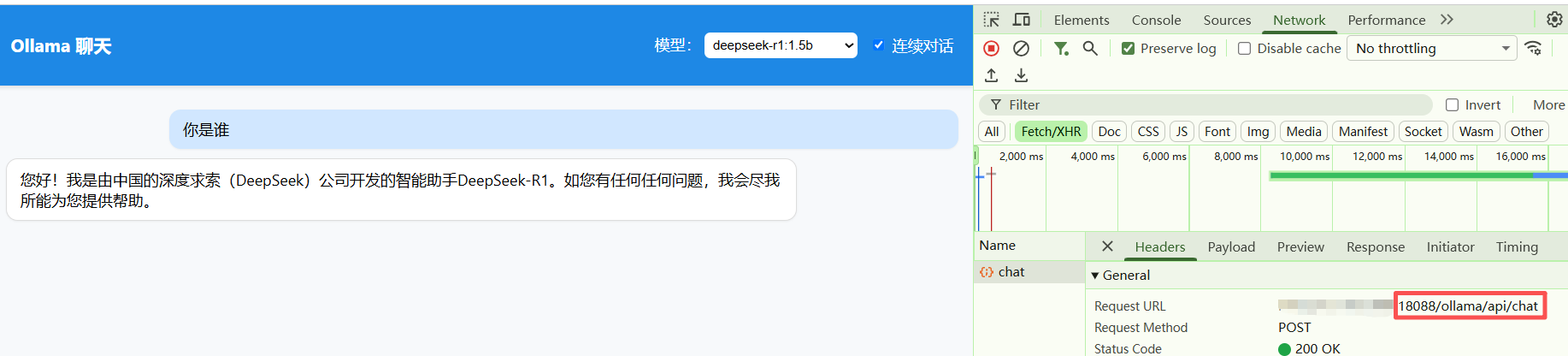
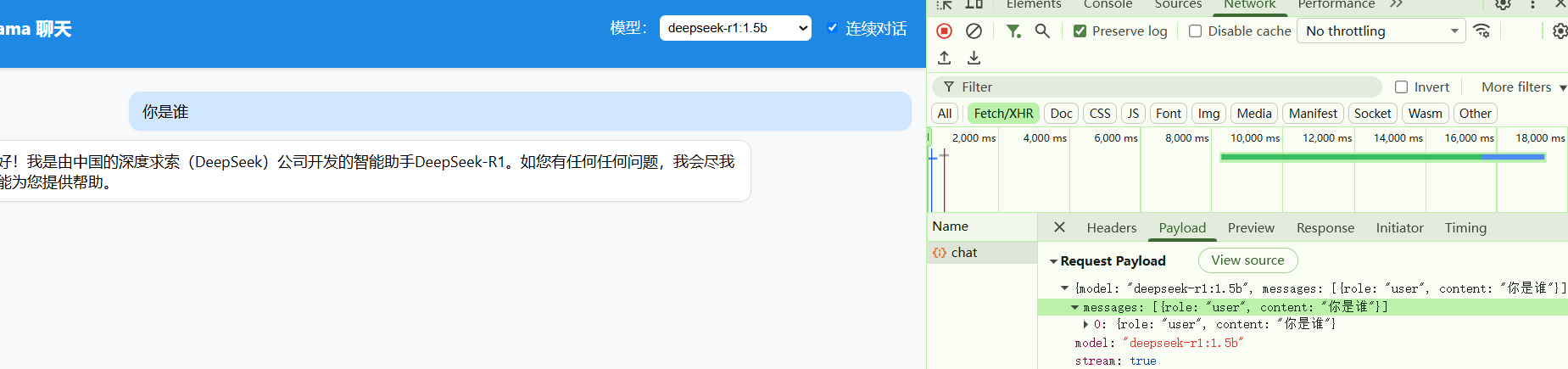
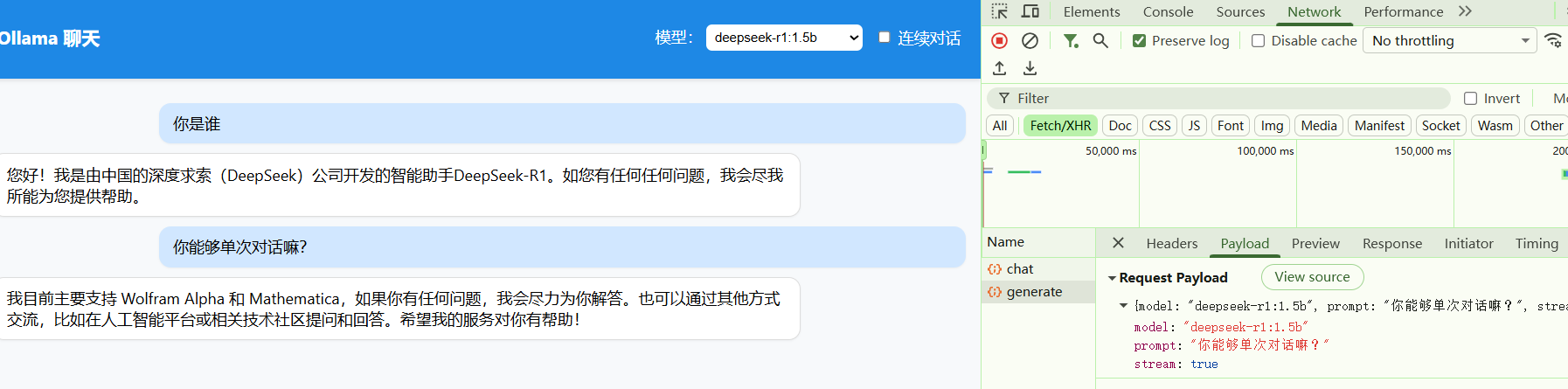
七、常见问题汇总
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 后端流式返回一段时间后自动停止 | Java或Nginx中设置的时间过短/本地电脑没有GPU,模型推理很慢 | 增大Java/Nginx后台中的对时间的配置 |
| API 无响应 | 服务未启动 | 运行 ollama serve & |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)