从一到无穷大 #53 Beyond TSDB Query performance: Homomorphic Compression
同态压缩的本质是让压缩与计算具备代数同态性(algebraic homomorphism)
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言:压缩与查询的矛盾
OLAP 引擎依赖于列式格式,例如 Apache Parquet、Apache ORC、和 Apache Arrow来进行物理数据布局。这三种格式都共享一个共同的三级层次结构。一个文件(或内存缓冲区)被分割成RowBatch。每个RowBatch包含每个属性一个连续的Chunk,每个Chunk又进一步分割成Page。首先应用轻量级编码,例如字典编码、RLE、delta、bit-packing。Parquet 和 ORC 随后可以使用通用编解码器(例如 Snappy,GZip,ZSTD,BROTLI,BZ2,LZO)压缩每个Page或Chunk。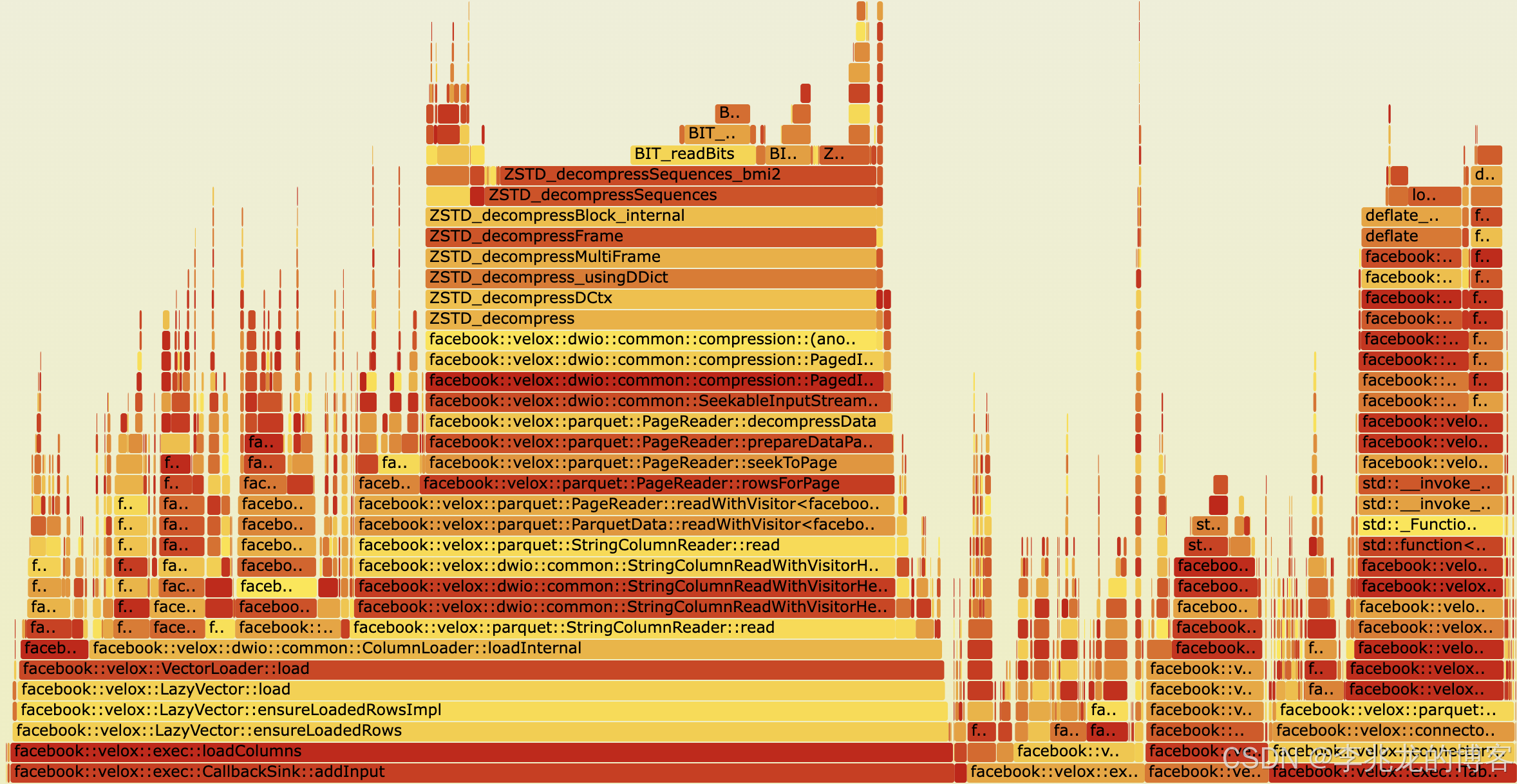
以velox框架为例,从我们内部的数据实际测试来看,压缩步骤可以将数据压缩90%以上,但是查询和Compact(可以被抽象为查询计划)在执行时解码开销却非常重,因为虽然应用了LazyVector这样的Late materialization能力,但是数据本身还是要做全量解压,其开销甚至可以占到30%以上。

从上图中也可以看到在Apache IotDB中RLE+LZ4的流程中对于查询性能的影响也在15%以上
因此,针对压缩数据直接执行运算成为提升TSDB查询性能的一个有效手段。
Analysis Homomorphic compression(同态压缩)
同态压缩的本质是让压缩与计算具备代数同态性(algebraic homomorphism),即:
对压缩后的数据执行某些算子操作的结果,与对原始数据执行该操作后再压缩的结果一致。
形式化定义如下:
f ( C ( x ) ) = C ( f ( x ) ) f(C(x)) = C(f(x)) f(C(x))=C(f(x))
其中:
- 𝐶 ( ⋅ ) 𝐶(⋅) C(⋅)是压缩函数(如 RLE、Delta、Dictionary 编码等),
- f ( . ) f(.) f(.)是算子(如 SUM、AVG、COUNT、FILTER 等)
- 若上述等式成立,则称 C C C 对算子 f f f 具有homomorphism(同态性)。
也就是说不需要还原数据,只需在压缩表示上进行代数计算,即可得到与原始数据相同的结果

论文把时间序列常见的四类基本编码抽象为: Delta, Repeat, Bit-packing,Dictionary,并给出了对应算法的支持情况,接下来我们分析下如何在这四类算法上做六种计算操作,直观的理解同态压缩。
Repeat 压缩(Run-Length Encoding, RLE)
RLE利用相同值连续重复的特征,将重复片段压缩为“值+重复次数”的对,设原序列: X = [ 10 , 10 , 10 , 8 , 8 , 9 , 9 , 9 , 9 ] X = [10,10,10,8,8,9,9,9,9] X=[10,10,10,8,8,9,9,9,9] RLE 表示: X ′ = [ ( 10 , 3 ) , ( 8 , 2 ) , ( 9 , 4 ) ] X ′ =[(10,3),(8,2),(9,4)] X′=[(10,3),(8,2),(9,4)]
- Filter:若 (value, count) 中 value 满足条件 → 整段保留;否则跳过。
- Aggregation: S U M = Σ v × c o u n t SUM=Σv×count SUM=Σv×count, C O U N T = Σ c o u n t COUNT=Σcount COUNT=Σcount, A V G = Σ ( v × c ) / Σ c AVG=Σ(v×c)/Σc AVG=Σ(v×c)/Σc。
- Group-by:天然分组,可直接聚合。
- Expression:对每个数值对执行算术或逻辑操作,如 (v/2, count)。
- Slicing: 借助 Compression Offset Index,精确跳转下标。
Pack 压缩(Bit-Packing)
Bit-pack 压缩将数值列的每个值以最小可能比特宽度打包,适合高密度整数型数据。例如:若某列最大值 < 255,仅需 8 bit。设原序列 X = [ 3 , 5 , 7 , 8 , 12 , 15 ] X = [3,5,7,8,12,15] X=[3,5,7,8,12,15],最大值 15(二进制 1111),需 4 位。压缩后序列为 [ 0001 , 0101 , 0111 , 1000 , 1100 , 1111 ] [0001,0101,0111, 1000,1100,1111] [0001,0101,0111,1000,1100,1111]
- Filter:用掩码与阈值直接比较,无需解码整块。
- Aggregation:位段直接加载入寄存器,向量化累积求和(SIMD 支持)。
- Group-by:块内分桶统计后汇总(ID→桶映射)。
- Expression:位操作支持快速逻辑/算术,如 XOR、SHIFT、ADD。
- Slicing:根据 bit-offset 定位起止位置,O(1) 随机访问。
Dictionary 压缩(Dic + RLE 混合)
Dictionary 编码通过构建“值到索引”映射表,把重复字符串替换为紧凑整数 ID。原序列[“ON”,“ON”,“OFF”,“ON”,“ERROR”,“ERROR”,“ERROR”],字典为ON→0, OFF→1, ERROR→2,RLE后序列为 [ 0 , 0 , 1 , 0 , 2 , 2 , 2 ] [0,0,1,0,2,2,2] [0,0,1,0,2,2,2],RLE后为 [ ( 0 , 2 ) , ( 1 , 1 ) , ( 0 , 1 ) , ( 2 , 3 ) ] [(0,2),(1,1),(0,1),(2,3)] [(0,2),(1,1),(0,1),(2,3)]
- Filter:等值过滤直接在 ID 上比较(WHERE col=‘ON’ ⇒ ID=0);RLE 层跳过不匹配游程。
- Aggregation:COUNT / MODE 通过统计 ID 频率完成;不需解码字符串。Min Max直接从字典中获取
- Group-by:GROUP BY 在 ID 空间完成(ID→Group 映射)。
- Expression:对字符串仅支持逻辑运算(=, ≠, LIKE);对枚举值可逻辑推断。
- Slicing:依游程偏移提取部分片段。
Delta 压缩(Ts_2Diff)
Delta 编码(差分编码)是 IoTDB 中处理数值型时间序列的核心轻量算法。它基于“相邻时间点变化平稳”的假设,将原序列转换为相邻差值序列,从而减少冗余。
设原始序列为 X = [ x 1 , x 2 , x 3 , … , x n ] X=[x1,x2,x3,…,xn] X=[x1,x2,x3,…,xn],差分序列定义为 Δ i = x i − x i − 1 , i ≥ 2 Δi=x_i−x_{i−1},i≥2 Δi=xi−xi−1,i≥2
在 IoTDB 的 Ts_2Diff 算法中,还使用“二阶差分”(second-order difference): Δ 𝑖 2 = Δ 𝑖 − Δ 𝑖 − 1 = ( 𝑥 𝑖 − 𝑥 𝑖 − 1 ) − ( 𝑥 𝑖 − 1 − 𝑥 𝑖 − 2 ) Δ_𝑖^2 = Δ 𝑖 − Δ_{𝑖 − 1} = ( 𝑥_𝑖 − 𝑥_{𝑖 − 1} ) − ( 𝑥_{𝑖 − 1} − 𝑥_{𝑖 − 2} ) Δi2=Δi−Δi−1=(xi−xi−1)−(xi−1−xi−2),用于进一步压缩连续变化的趋势。由于二阶差分分布范围比较小,可以用极少bytes表示。
举例子,原序列为 X = [ 100 , 101 , 103 , 106 , 110 ] X = [100, 101, 103, 106, 110] X=[100,101,103,106,110],差分为 Δ = [ 1 , 2 , 3 , 4 ] Δ=[1,2,3,4] Δ=[1,2,3,4],二阶差分为 Δ 2 = [ 1 , 1 , 1 ] Δ^2=[1,1,1] Δ2=[1,1,1],存储结果为:
Header: [100, 101]
Body: [1, 1, 1]
- Aggregation: S U M ( X ) = Σ Δ + x 1 SUM(X) = ΣΔ + x_1 SUM(X)=ΣΔ+x1; 平均可由 x e n d − x s t a r t x_{end} - x_{start} xend−xstart 推导。
- Expression:对 Δ 直接执行线性算术操作
实现难点
将同态压缩从理论转化为时序数据库的实际能力,核心挑战在于传统TSDB的执行流程是“TableScan读取压缩块→全量解压(延迟物化)→算子处理→结果输出”,而同态压缩需要将算子执行逻辑下推到TableScan层,实现“读取压缩块→压缩态算子执行→结果输出”的新流程。这和现有的计算引擎实现完全不同。
也正是因为这种情况[4]和[3]中都没有基于现有的计算引擎来做,而是设计了CompressIoTDB和EBI框架来实现同态压缩。
[4]也对直接查询压缩数据的思路进行了探索。该工作基于多种浮点压缩算法(如Gorilla、Buff、Sprintz等)实现了支持列式引擎的查询库 。其中,Buff 压缩通过对浮点数执行位掩码量化,并将数据切分为若干“子列”逐字节存储,允许在解压时只读取必要的高位比特以满足查询精度要求 。Buff 结合这种格式和算子优化,提供了 BuffReader 专门在量化后的整数上执行聚合、筛选等操作,不需要完整解码原浮点值。Sprintz 等方法也采用类似思路,在量化域上支持部分就地运算,这其实也是同态压缩。
所以在一众非同态压缩的压缩算法中,BUFF在数据库操作的吞吐量测试中一骑绝尘。
压缩算法适配复杂性
这其实也引出重点,同态压缩的核心前提是“压缩算法支持算子的同态执行”,但正如前文的算子支持矩阵所示,不同压缩算法的适配能力差异巨大,而[4]中的在float格式的压缩与查询性能权衡测试中清晰表明,所有压缩算法都存在场景依赖性:
这种场景依赖性导致同态压缩必须为每种压缩算法定制特定的算子执行逻辑,开发成本极高。例如,要支持10种主流压缩算法的6种核心算子,需要开发60套独立的适配逻辑;更复杂的是,当算子组合使用时(如“过滤+聚合+窗口分组”),还需验证不同压缩算法的适配逻辑是否兼容。
更关键的是,现有同态压缩研究仅覆盖了少数基础压缩算法,大量新兴高效算法尚未实现同态适配。这些算法往往采用更复杂的编码逻辑(如多层级差分、自适应字典),与算子的同态性兼容难度更高,进一步加剧了适配难题。
计算引擎适配复杂性
同态压缩需要对计算引擎核心架构(如TableScan、算子层)进行修改,属于侵入式优化,极其可能影响现有系统的稳定性。除此之外还需要修改Plan层,因为现在Tablescan和上层算子的逻辑耦合在一起了。虽然IotDB中通过CompressColumn将压缩列融入了现有的设计中(velox中也有Column这样的基础列),但是还是需要将计算逻辑下沉。
对于开源社区而言,这种修改需要经过严格的评审和大量的测试验证,投入成本高;对于我司这样的商业厂商而言,同态压缩带来的优化有限,在高性能场景已然将时延降到10ms量级,长时间执行的任务并没有要求一定要减小30%,而且也可以通过并行的思路解决,还对引擎侵入性较高。
简而言之,没有极端的场景需要牺牲稳定性和大把的人力来优化这30%的性能。
结束语
从Perplexity搜索来看,同态压缩在数据库领域还处于小众的领域,仅在[3][5]中看到了应用,而在机器学习领域则更为活跃,主要用于解决GPU计算吞吐增速快于网络带宽增速,在分布式深度学习中的梯度聚合使用同态压缩降低GPU解码,从而增加整体带宽。
以目前的研究成果来说,需要减小包体积的同时减小CPU/GPU计算的场景可以使用这种方法(不限制压缩算法,不绑定计算引擎,逻辑简单),可以发光发热的领域还是很多的。
参考:
- 同态压缩数据库技术的探索应用 | DBTalk 技术公开课
- Time Series Data Encoding for Efficient Storage: A Comparative Analysis in Apache IoTDB
- Improving Time Series Data Compression in Apache IoTDB
- Beyond Compression: A Comprehensive Evaluation of Lossless Floating-Point Compression
- HocoPG: A Database System with Homomorphic Compression for Text Processing
- HoSZp: An Efficient Homomorphic Error-bounded Lossy Compressor for Scientific Data

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)