20252803《Linux内核原理与分析》第七周作业
阅读学习教材「庖丁解牛Linux分析 」第7章,,有问题优先使用chatgpt等AI工具。或者到蓝墨云班课中提问24小时内回复,鼓励解答别人问题,提问前请阅读「如何提问」。教材深入学习关注豆列「Linux内核及安全」。学习蓝墨云班课中第七周视频「进程的执行和进程的切换」,并完成实验楼上配套实验六。,注意从下往上看。基于树莓派或其他平台完成ARM相关内容。
作业要求
阅读学习教材「庖丁解牛Linux分析 」第7章,,有问题优先使用chatgpt等AI工具。或者到蓝墨云班课中提问24小时内回复,鼓励解答别人问题,提问前请阅读「如何提问」。
教材深入学习关注豆列「Linux内核及安全」。
学习蓝墨云班课中第七周视频「进程的执行和进程的切换」,并完成实验楼上配套实验六。,注意从下往上看。基于树莓派或其他平台完成ARM相关内容。
作业标题 “学号《Linux内核原理与分析》第X周作业”,重点是遇到的问题和解决方案内容涵盖教材学习和视频,提交格式用Markdown,同时提交转换的 PDF(VSCode 有相关插件)。
实验六:分析 Linux 内核创建一个新进程的过程、
1、阅读理解 task_struct 数据结构 https://github.com/torvalds/linux/blob/v3.18-rc6/include/linux/sched.h#L1235;
2、分析 fork 函数对应的内核处理过程 sys_clone,理解创建一个新进程如何创建和修改 task_struct 数据结构;
3、使用 gdb 跟踪分析一个fork系统调用内核处理函数 sys_clone ,验证您对 Linux 系统创建一个新进程的理解,推荐在实验楼 Linux 虚拟机环境下完成实验。 特别关注新进程是从哪里开始执行的?为什么从那里能顺利执行下去?即执行起点与内核堆栈如何保证一致。
一、理解task_struct数据结构
在 Linux 内核中,task_struct是一个非常重要的数据结构,它被称为 “进程描述符”(Process Descriptor),用于描述和管理进程的所有信息,其中一些关键字段包括进程状态、内核堆栈、引用计数、进程标志、调试标志、唤醒信息、CPU信息等。每个进程在内核中都对应一个task_struct结构体实例,内核通过操作这个结构体来实现对进程的调度、管理和跟踪。
咨询AI:

二、分析fork函数对应的内核处理过程sys_clone,理解创建一个新进程如何创建和修改task_struct数据结构
在Linux内核中,fork() 系统调用最终会通过sys_clone() 内核函数处理(fork是clone的特殊情况)。创建新进程的核心是复制父进程的task_struct并进行必要修改,形成独立的进程描述符。
1、sys_clone内核处理过程与task_struct操作
(1)创建新的 task_struct
内核通过copy_process() 函数创建新进程,首先分配空白的task_struct 结构体(通过 alloc_task_struct_node() 实现)。
复制父进程的 task_struct大部分字段(如文件描述符、信号处理、内存映射等),但通过写时复制(COW)机制延迟实际内存复制。
(2)修改关键标识信息
分配新的pid(通过alloc_pid()),设置tgid(与pid相同,因新进程是独立线程组)。
重置进程关系:real_parent和parent指向父进程,父进程的children链表加入新进程,新进程的 sibling 指针链接兄弟进程。
(3)调整状态与调度信息
设置新进程状态为TASK_RUNNING(就绪态)。
重置调度相关字段:prio 继承父进程,但sched_entity初始化以独立参与调度;
(4)内存空间处理
复制父进程的mm_struct(地址空间),但设置mm->count引用计数,实现写时复制(仅当父子进程修改内存时才实际复制页)。
内核线程无用户空间,mm 字段设为 NULL,复用父进程的 active_mm。
2、实践代码:用户态模拟fork行为(观察进程标识变化)
以下代码通过fork()系统调用创建子进程,并打印父子进程的PID(对应task_struct中的pid字段)
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork(); // 触发sys_clone,创建子进程
if (pid < 0) {
// fork失败
perror("fork failed");
return 1;
} else if (pid == 0) {
// 子进程:task_struct中的pid为新分配值,parent指向父进程
printf("子进程: PID=%d, 父进程PID=%d\n", getpid(), getppid());
} else {
// 父进程:task_struct中的children链表加入子进程
printf("父进程: PID=%d, 子进程PID=%d\n", getpid(), pid);
wait(NULL); // 等待子进程结束,避免子进程成为僵尸进程
}
return 0;
}
编译运行后,父进程和子进程会打印各自的PID,可见子进程的PID是内核新分配的(对应task_struct中 pid 字段的修改)。
子进程的getppid()结果等于父进程的PID,体现task_struct 中 parent指针的设置。
父进程通过wait() 回收子进程资源,避免子进程进入僵尸状态。
三、使用 gdb 跟踪分析一个fork系统调用内核处理函数 sys_clone ,验证对Linux系统创建一个新进程的理解
1、先重新编译新内核的menu,再将test_fork.c覆盖在运行程序test.c上
cd ~/LinuxKernel
rm menu -rf
git clone https://github.com/mengning/menu.git
cd menu
mv test_fork.c test.c
make rootfs

2、使用gdb对fork()函数进行跟踪分析
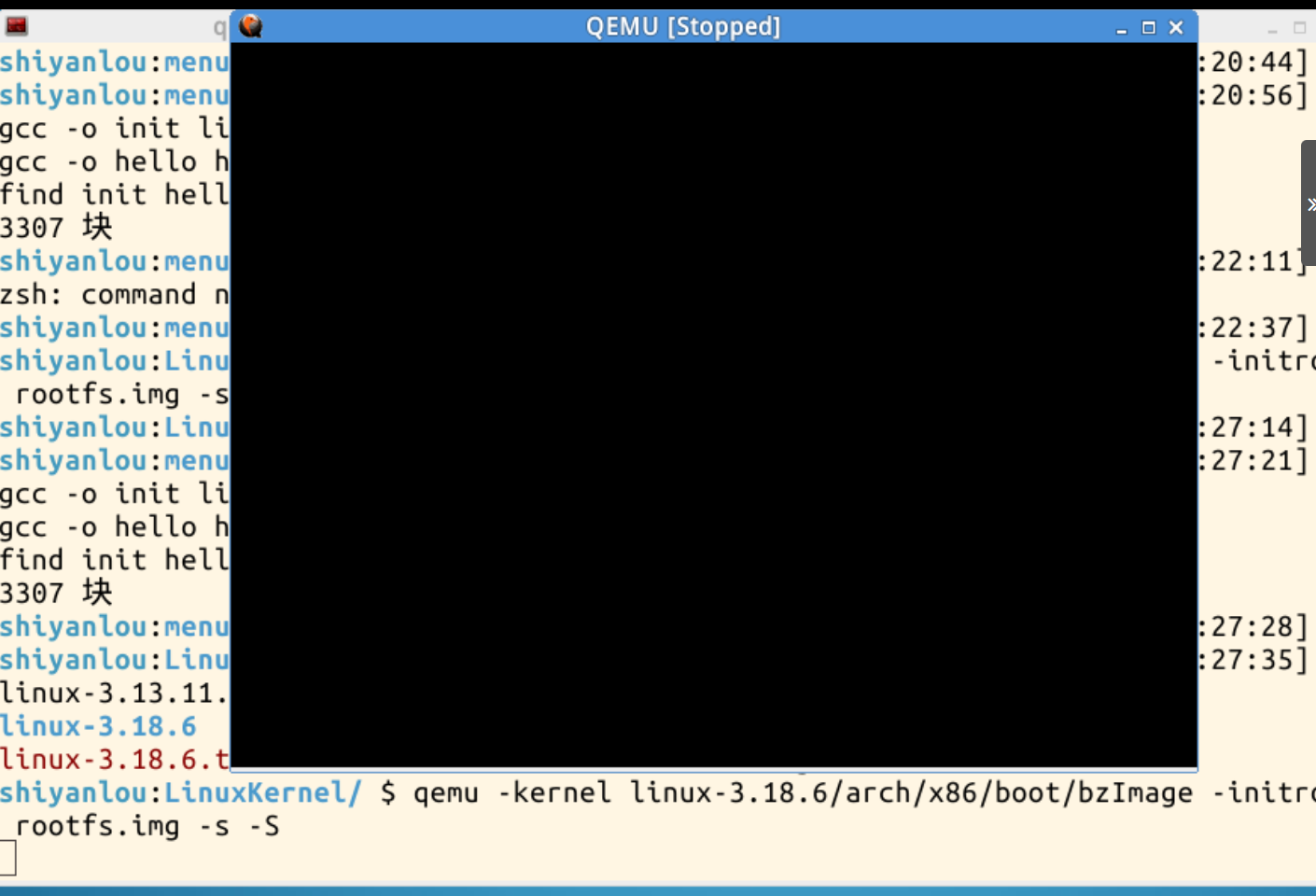
与之前几次实验一样,首先进入一个冻结内核,然后打开一个空shell,再进行gdb调试:
进入冻结内核:
cd LinuxKernel
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S //冻结内核的启动
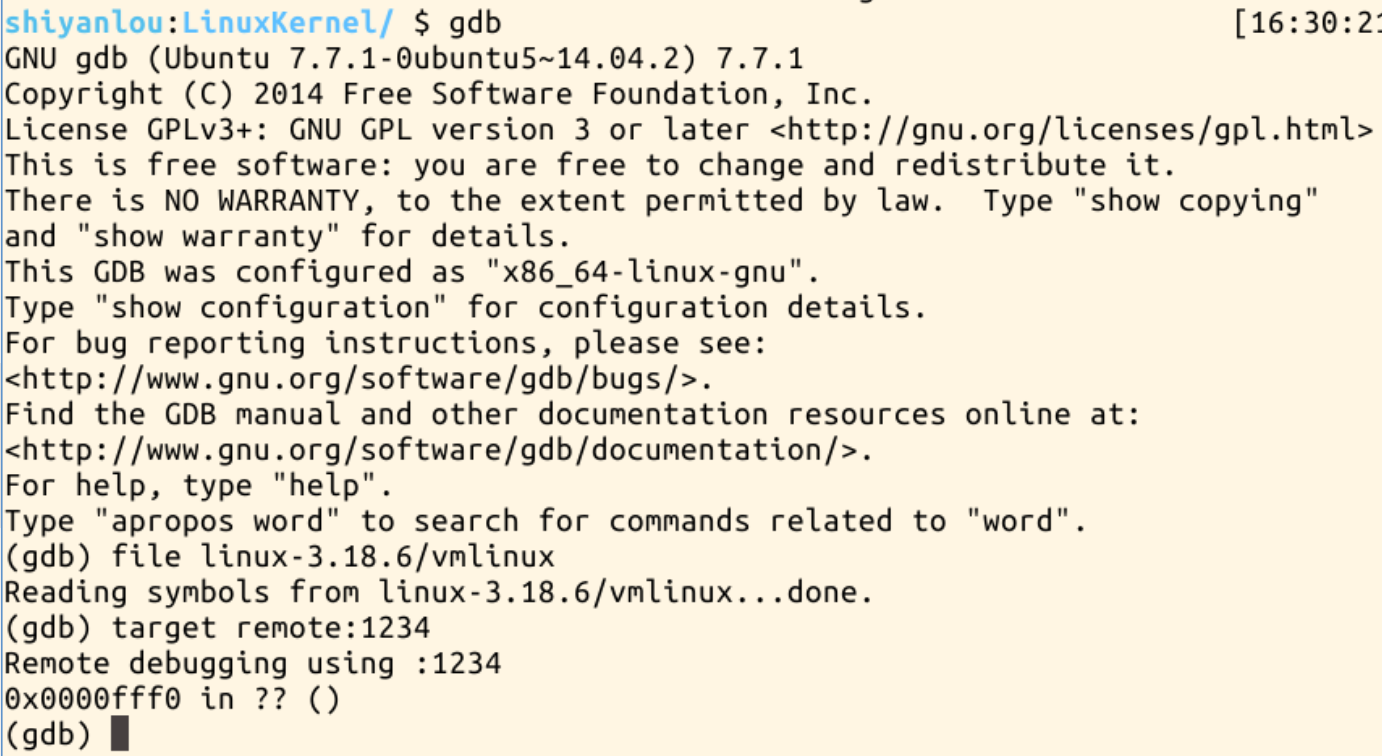
新打开一个空shell,进入gdb调试,并建立连接:
cd LinuxKernel
gdb
(gdb)file linux-3.18.6/vmlinux
(gdb)target remote:1234
冻结的内核开始运行后,输入fork可发现fork输出了父进程和子进程,说明fork调用成功。
3、下面进入fork的调试:
分别对系统调用sys_clone、do_fork、dup_task_struct、copy_process、copy_thread、ret_from_fork设置断点进行单步调试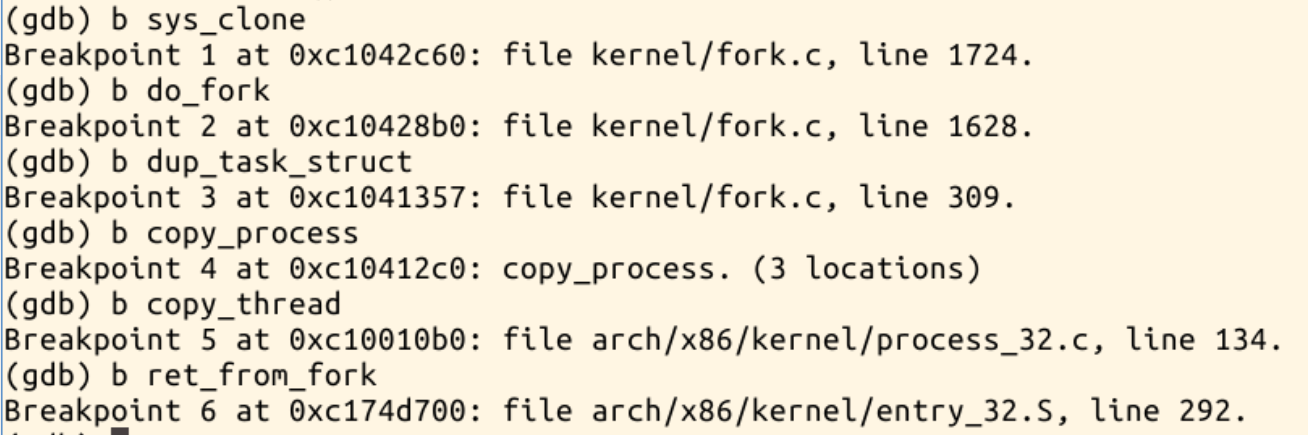
continue执行: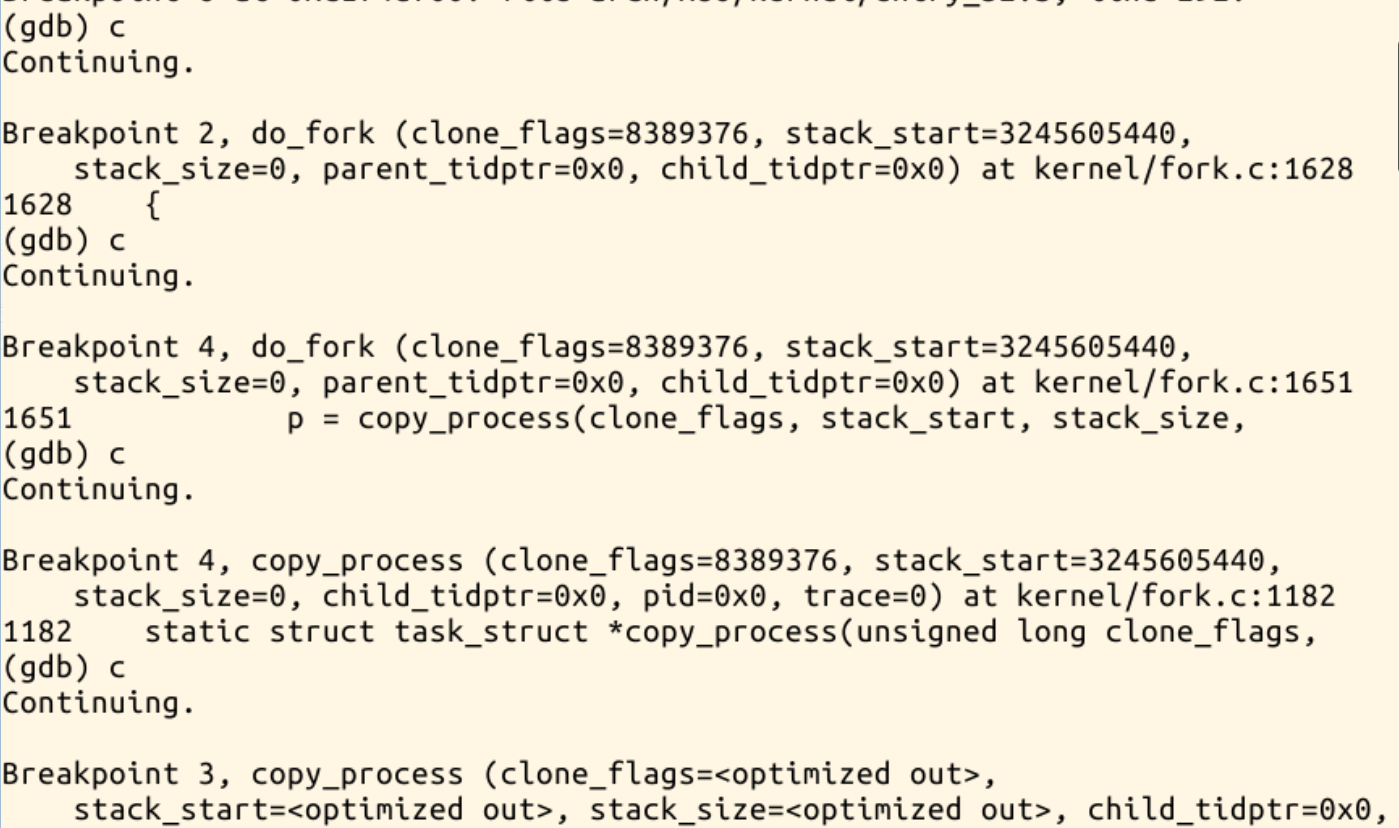
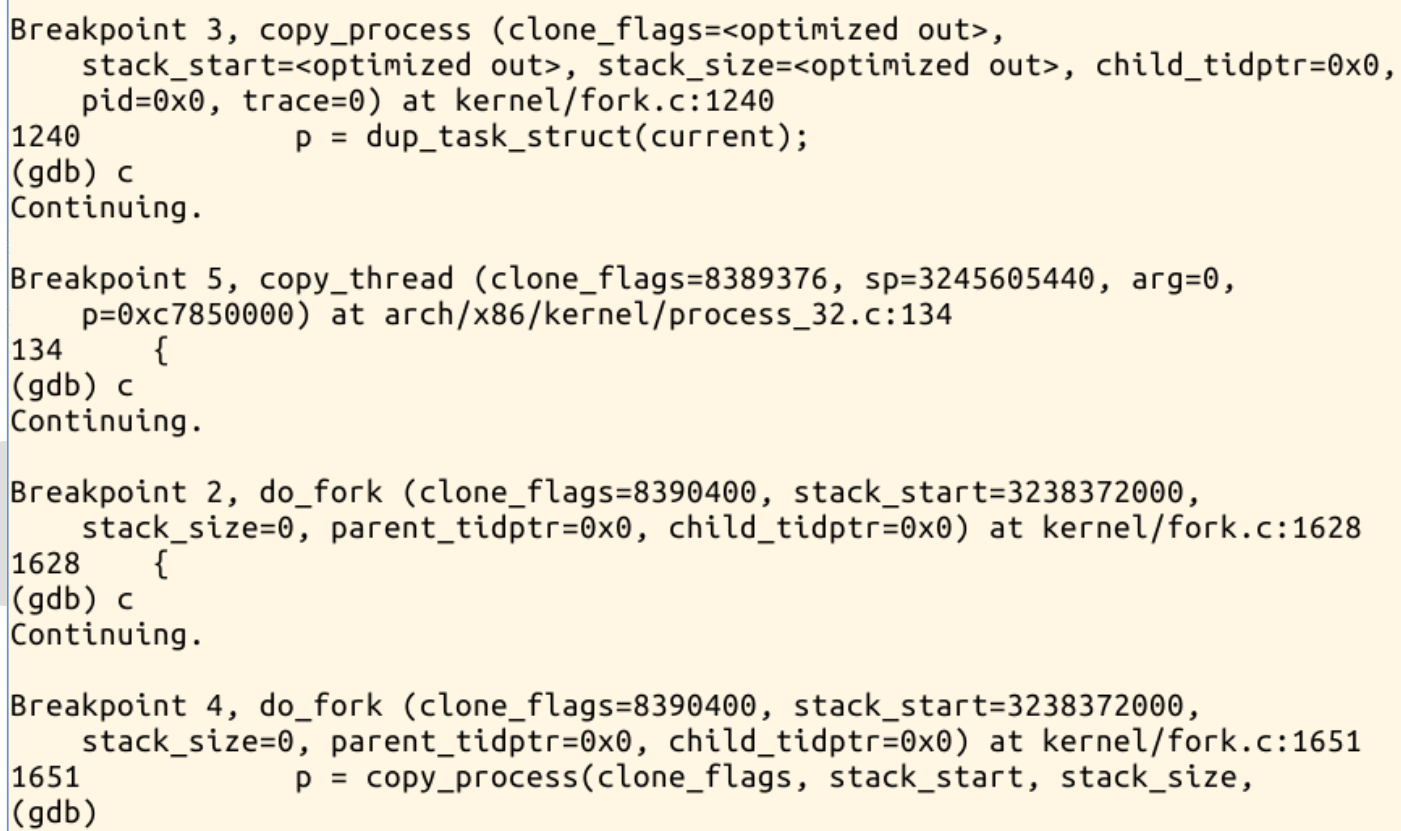
回到QEMU查看: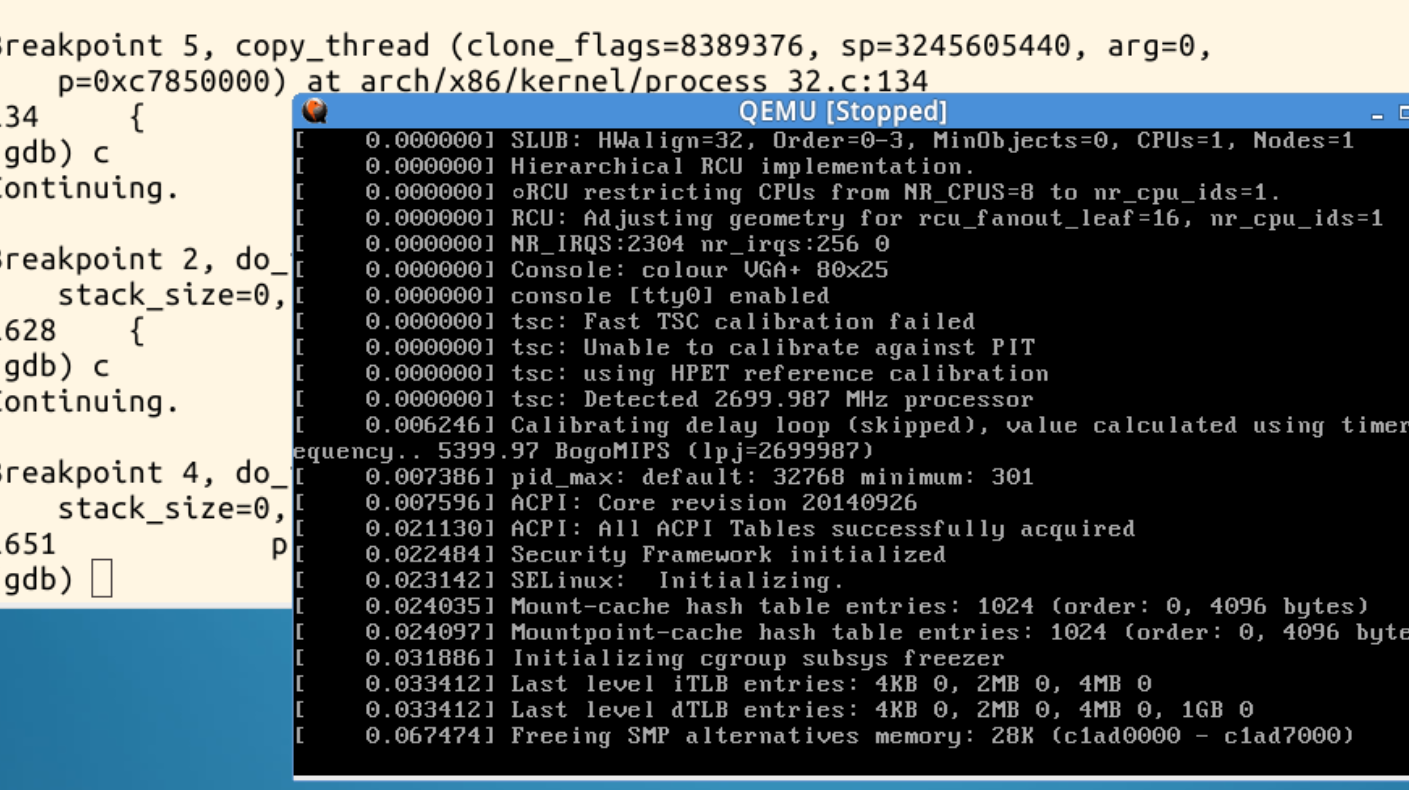
4.分析 fork 函数对应的系统调用处理过程
在 Linux 内核里,fork 函数作为创建新进程的系统调用,其核心逻辑是通过复制当前父进程的状态生成子进程。这一系统调用的处理流程涉及多个内核函数,其中 do_fork 承担着核心职责:它负责子进程的创建与初始化工作,并会调用 copy_process 函数来复制父进程的关键数据结构——像文件描述符表、内存映射关系、信号处理程序等都在复制范围内。此外,copy_thread 函数也扮演着重要角色,它的作用是复制内核堆栈内容,从而保证新进程能拥有独立的内核堆栈,确保父子进程在 kernel 态运行时的栈空间相互隔离。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)