如何搭建属于自己的私密机器人?只属于自己的聊天智能体?
本文介绍了如何快速搭建基于大模型的本地知识库系统。使用Python的Streamlit和Langchain框架实现前后端交互,通过阿里百炼API或本地DeepSeek-R1模型提供AI服务。核心步骤包括:1)用Langchain封装大模型调用逻辑;2)通过Streamlit构建Web界面实现对话交互;3)利用会话记忆体实现多轮对话。文章还探讨了商业化应用场景,如政务模型服务和电商客服机器人,并提示
这两天,有同事问我:
“那些市面上的AI聊天机器人太贵了,有啥平替吗?”
“我想让AI帮我处理点私密文件,但又怕数据泄露,咋办?”
“能不能搞个完全属于自己的AI,让它只听我的话?”
问得好!
说实话,现在市面上的AI工具,要么死贵,要么限制多,要么就是把你的数据当成它们的训练集
用起来总感觉不爽,像是被“包养”的,一点自由都没有。
今天,我就手把手教大家,怎么花1个小时,用最简单粗暴的方法,搭建一个只属于你自己的、私密的、想怎么玩就怎么玩的AI聊天机器人。
全程大部分代码都可以让AI(Cursor)帮你写,你只需要动动嘴、跑跑代码就行。
信我,这事儿比你想象的简单一百倍!
搞定“兵器谱”:我们需要哪些骚操作工具?
在开干之前,我们先亮一下我们的“兵器谱”,别被名字吓到,都是纸老虎:
1. **Cursor编程工具**:这玩意儿就是你的AI程序员,你用大白话跟它说想要啥,它直接帮你把代码敲出来。神器!
2. **Python**:胶水语言,不多说,就是把所有东西粘在一起的那个。
3. **Streamlit框架**:一个能让你用几行代码就变出一个漂亮网页的魔法工具。咱们的机器人就靠它长脸了。
4. **Langchain框架**:机器人的“大脑框架”,负责连接我们的大模型和记忆体,让机器人能记住你说过的话。
5. **一个大模型API KEY**:这就是机器人的“灵魂”了。文章里用的是阿里百炼的,你自己有别的也一样用,比如DeepSeek的。
今天来就来实践一下,记录一下普通人如何快速搭建起来
简单介绍一下
首先,需要会使用cursor编程工具,使用具体的大白话让cursor通过python语言来实现,具体很简单,使用streanlit ,Langchain框架,来完成前后端的工作,之前有说过如何使用ollama 来下载开源的LLM大模型,包括如何使用ollama来搭建属于自己本地的知识库。这一期可以融会贯通。
这一期直接使用阿里百炼的API_KEY(使用自己本地的DeepSeek-R1模型也是一样的)
当然了,如果你有兴趣的话,可以把你本地的模型提供API_KEY给其他的小伙伴,通过对秘钥算力token的数量来收费,是完全没有问题的,现在很多的公司再某些垂直领域是这么玩的,比如:某某威公司,通过自己封装的政务相关的大模型来提供硬件的支持,和软件api的服务费用。
也有一些电商行业的新的科技公司,给其他电商平台提供客服机器人。
当然了这里只是提供可行方案思路,具体细节还需要根据自身,或者客户的需求来进行打磨,这里的知识牵扯到很多,这里不展开赘述。
感兴趣的点个关注,后面会娓娓道来这里面的具体落地细节和可实操思路!
(包括如何让大模型处理更长的文本?如何对数据进行标签划分?微调过程中如何找到高效的方案?以及为什么LLM会产生幻觉问题)
废话不多说,直接开干。简单粗暴,先上源码(代码是最好的语言):
第一步:先让机器人“有脑子”—搞定核心逻辑
让我们来完成最简单的通过Python调用模型:(全是cursor完成,我只负责运行)
# 这里写的是:核心业务逻辑,即:接收用户录入的_提示词(prompt),调用模型,然后获取结果。
# 1、导包
from langchain_community.llms import Tongyi # 通义大语言模型
from langchain_core.prompts import ChatPromptTemplate #提示词模板
from langchain_classic.chains import ConversationChain # 会话链,llm模型 + 记忆体
from langchain_classic.memory import ConversationBufferMemory # 会话记忆体
# 2、定义函数,根据用户录入的提示词,调用模型,获取结果
def get_response(prompt,memory,api_key):
"""
该西数用于根据用户录入的提示词, 调用模型, 获取结果.
:param prompt: 用户录入的提示词
:param memory: 会话记忆体
:param api_key:型API密钥
:return: 模型返回的结果
"""
# 3、创建模型对象
llm = Tongyi(model = "qwen-max",dashscope_api_key = api_key)
# 4、创建调用链
chain = ConversationChain (llm=llm,memory=memory)
# 5、调用会话链,获取结果
responst = chain.invoke({'input':prompt})
# 6、返回结果
# return responst # 返回模型处理后的结果值
return responst['response'] # 返回模型处理后的结果值
# 在main函数中测试代码
if __name__ == '__main__':
# 1、创建提示词对象
prompt = "世界上最高的人是谁?"
# 2、创建会话记忆体
memory = ConversationBufferMemory(return_messages=True)
# 3、指定apiKey
api_key = "sk-xxxxxxxxxx"
# 4、调用函数
result = get_response(prompt,memory,api_key)
# 5、打印结果
print(result)
说白了,就是定义了一个管道:**你的问题 → 管道(get_response函数)→ AI大脑 → 管道 → 答案**。咱们机器人的“脑子”就有了。
第二步:给机器人“一张脸”——用Streamlit画个网页
通过Python Streamlit 绘制页面
代码如下:
# 这里写的是: Python代码 ->通过Streamlit,绘制Web页面
# 导包
import streamlit as st
from langchain_classic.memory import ConversationBufferMemory
from utils import get_response
# 1、设置左侧的侧边栏
with st.sidebar:
# 让用户输入自己的 api_key
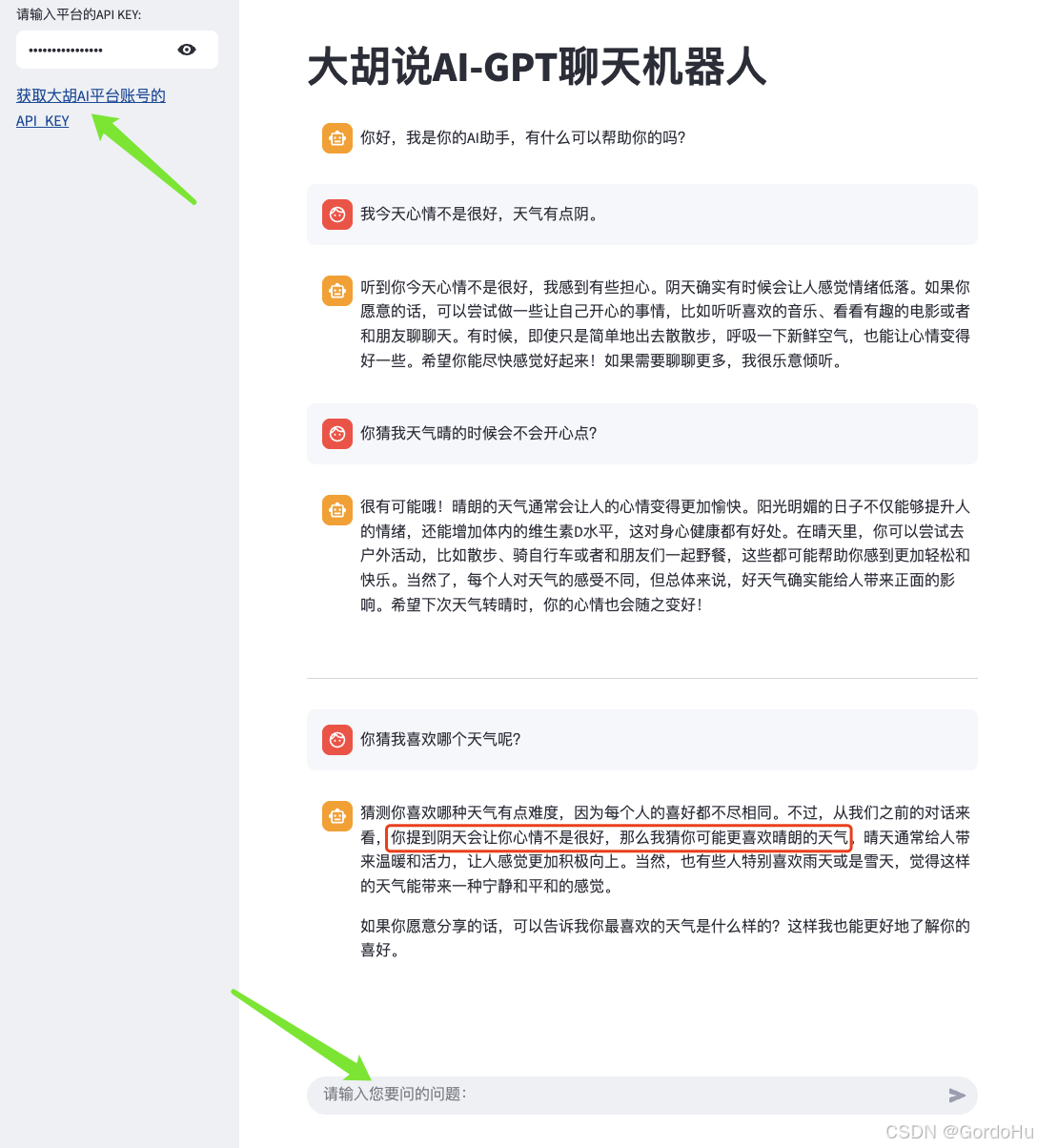
api_key = st.text_input("请输入平台的API KEY:",type="password")
# 设置连接提示,用户点击后,会跳转到获取API_KEY的页面
st.markdown('[获取大胡AI平台账号的API_KEY](https://bailian.console.aliyun.com/?apiKey=1#/api-key)')
# 2、设置标题
st.title("大胡说AI-GPT聊天机器人")
# 创建会话记忆体,即:会话保持对象,记录:聊天记录
if 'memory' not in st.session_state:
# 第一次访问,创建记忆体,初始化信息
st.session_state['memory'] = ConversationBufferMemory()
st.session_state['messages'] = [{'role':'ai','content':'你好,我是你的AI助手,有什么可以帮助你的吗?'}
# ,{'role':'human','content':'世界上最帅的人'}
]
# 如果不是第一次,则拉取历史信息
# 创建消息区,即:编辑会话记忆体中的所有聊天记录,并打印到消息区即可
for message in st.session_state['messages']:
with st.chat_message(message['role']):#设置角色,即:显示消息来源
st.write(message['content']) #显示消息内容
# 分割线
st.divider()
prompt = st.chat_input("请输入您要问的问题:")
# 判断用户录入的内容不为空
if prompt:
if not api_key:
st.warning("请先输入您的API_KAY")
st.stop() #直接停止运行
# 如果用户录入的内容不为空,就显示到:页面消息区
# st.chat_message("human").markdown(prompt)
st.session_state['messages'].append({'role':'human','content':prompt})
#把用户录入的信息,打印到:消息区中
st.chat_message('human').markdown(prompt)
#调用自定义函数,获取AI回复的结果
with st.spinner('稍等,思考中...'):
content = get_response(prompt,st.session_state['memory'],api_key)
#把AI回复的信息,添加到 会话记忆体中,并打印到:消息区中
st.session_state['messages'].append({'role':'ai','content':content})
st.chat_message('ai').markdown(content)
这段代码更简单,全是搭积木:
- `st.sidebar`:在旁边搞个侧边栏。
- `st.title`:放个标题。
- `st.chat_message`:显示一条聊天气泡。
- `st.chat_input`:在底下搞个输入框。
这玩意的价值在哪?
看到这里,你可能会问,搞这么一出,不还是个聊天机器人吗?
不,完全不一样。
第一,数据绝对私密。
因为API KEY是你自己的,所有的对话数据只经过你和模型提供方,没有任何第三方掺和。如果你更极端一点,用Ollama在本地跑模型,那你的数据连网都不出,绝对安全。
第二,功能无限扩展。
今天我们只做了个聊天机器人。但有了这个框架,你想让它干啥都行。接个文件上传接口,它就能帮你分析财报;给它加上联网能力,它就能帮你搜集最新资料。它就是你的一个AI员工,7x24小时待命,还不要工资。
真正的强大,不是你会用多少工具,而是你能把多少强大的工具,组合成只属于你自己的武器。
这个私人AI助理,就是你的第一件“可组合”的AI武器。
很多时候,技术本身并不难,难的是打破“我不会”、“这很难”的思维定势。
AI时代,最贵的不是算力,而是你的想象力和行动力。别再观望了,现在就动手,去打造属于你自己的AI助理吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)