面向智能体与大语言模型的 AI 基础设施:选项、工具与优化
本文探讨了用于部署和优化 AI 智能体(AI Agents)与大型语言模型(LLMs)的各类基础设施选项及工具。无论采用云、本地还是混合云部署,基础设施在 AI 架构落地过程中都起着关键作用。本文是 AI 基础设施系列文章的一部分,聚焦于部署和优化 AI 智能体与大语言模型的多样化基础设施选择,深入剖析了基础设施在 AI 架构(尤其是推理环节)实现中的核心价值。我们将详细介绍包括开源解决方案在内的
本文探讨了用于部署和优化 AI 智能体(AI Agents)与大型语言模型(LLMs)的各类基础设施选项及工具。
无论采用云、本地还是混合云部署,基础设施在 AI 架构落地过程中都起着关键作用。本文是 AI 基础设施系列文章的一部分,聚焦于部署和优化 AI 智能体与大语言模型的多样化基础设施选择,深入剖析了基础设施在 AI 架构(尤其是推理环节)实现中的核心价值。我们将详细介绍包括开源解决方案在内的各类工具,通过图表展示推理流程,并强调高效、可扩展 AI 部署的关键考量因素。
现代 AI 应用对基础设施提出了精密化要求——需承载大语言模型的计算强度、多智能体系统的复杂性,以及交互式应用的实时性需求。核心挑战不仅在于选择合适的工具,更在于理解这些工具如何在整个技术栈中协同集成,从而交付可靠、可扩展且经济高效的解决方案。
本指南涵盖 AI 基础设施的全维度内容,从硬件加速、模型服务到监控与安全,详细解析了经过生产环境验证的开源工具、架构模式及实施策略。
一、AI 基础设施在架构中的核心作用
AI 架构定义了 AI 系统构建与部署的蓝图,而基础设施则是支撑该架构落地的基石。对于 AI 智能体与大语言模型而言,基础设施直接影响系统性能、可扩展性、成本与可靠性。设计精良的基础设施能够实现:
- 更快的推理速度:低延迟对交互式 AI 智能体和实时应用至关重要
- 更强的可扩展性:在用户需求增长时保持性能稳定
- 更高的成本效益:优化资源利用率以降低运营支出
- 更优的可靠性:确保高可用性和容错能力
二、AI 基础设施栈:分层架构设计
现代 AI 基础设施栈由七个相互关联的层级构成,每个层级承担特定功能,同时与相邻层级实现无缝集成。理解这一分层架构,对于工具选型、资源分配及运维策略制定具有重要指导意义。
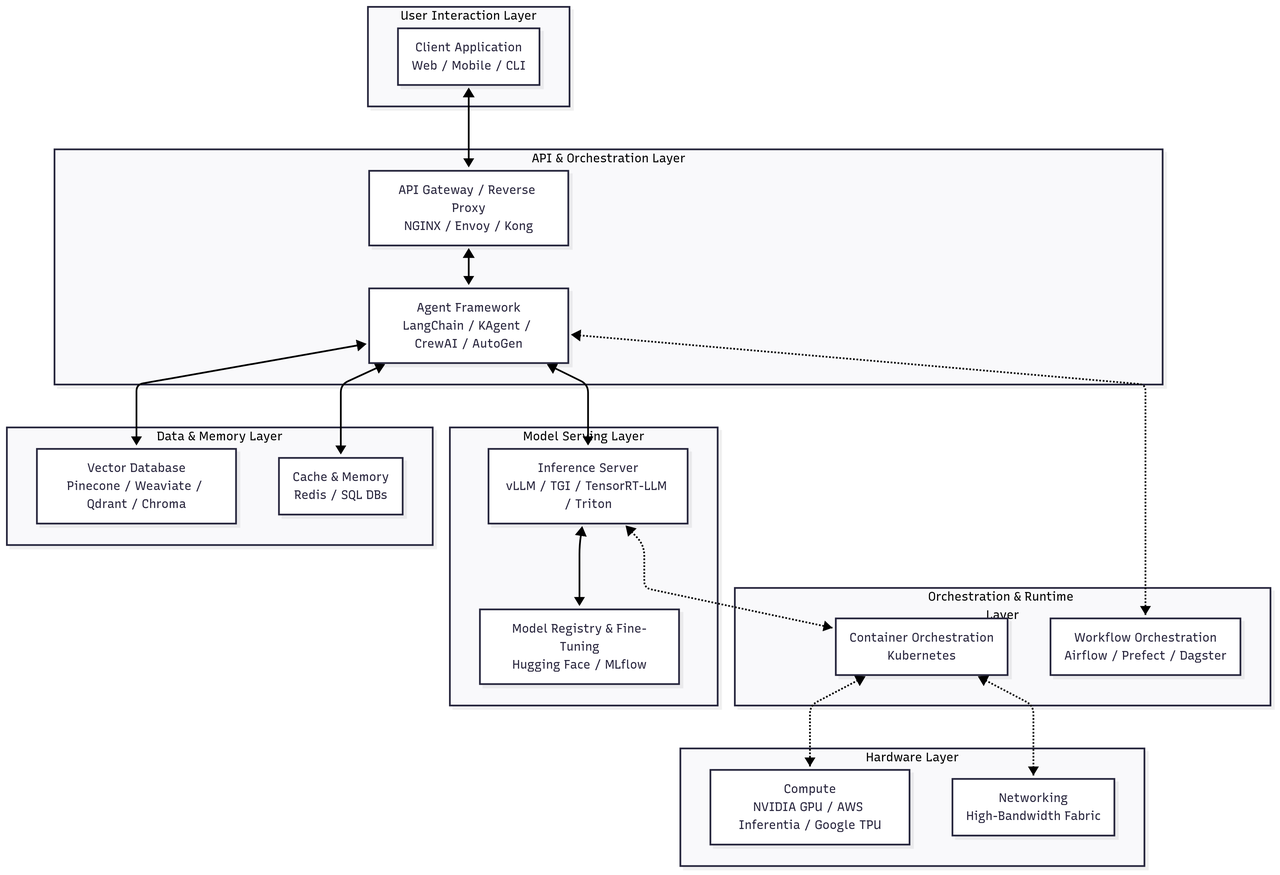
(一)层级解析与核心工具
- 用户交互层:用户请求的入口,客户端可包括 Web 界面、移动应用或命令行工具。核心需求是与后端 API 层建立稳定、低延迟的连接。
- API 与编排层:负责管理用户请求并编排复杂工作流
- API 网关(NGINX、Envoy、Kong):作为统一入口,处理流量接入、身份认证、限流及路由
- 智能体框架(LangChain、KAgent、CrewAI、AutoGen):AI 业务逻辑核心,其中 KAgent 是专为高效编排设计的专用工具,支持 AI 任务的动态路由与工作流管理
- 数据与内存层:提供上下文支持和持久化存储,将无状态模型转化为具备知识储备的助手
- 向量数据库(Pinecone、Weaviate、Qdrant、Chroma):用于存储和查询高维向量的专用数据库,是检索增强生成(RAG)的核心组件
- 缓存与内存(Redis、SQL 数据库):Redis 用于低延迟缓存和短期内存存储,SQL 数据库则存储对话历史、用户偏好等长期数据
- 模型服务层:推理核心层级,负责模型加载与执行
- 推理服务器(vLLM、TGI、TensorRT-LLM、Triton):专为高吞吐量、低延迟推理优化的服务器,支持动态批处理和量化
- 模型注册与微调(Hugging Face、MLflow):集中式仓库,管理从训练到部署的全模型生命周期
- 编排与运行时层:抽象底层硬件的基础层级
- 容器编排(Kubernetes):管理容器生命周期,提供可扩展性、弹性及高效资源利用率
- 工作流编排(Airflow、Prefect、Dagster):编排复杂的数据和机器学习流水线,支持训练任务、数据摄入等操作
- 硬件层:计算的物理载体
- 计算资源(NVIDIA GPU、AWS Inferentia、Google TPU):大语言模型推理必需的专用加速器
- 网络设备(NVLink、InfiniBand):支持多 GPU 和多节点通信的高速互联设备

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)