具身人工智能世界模型:综述
25年10月来自南开大学、天津大学和中科大的论文“A Comprehensive Survey on World Models for Embodied AI”。具身人工智能需要能够感知、行动并预测行动如何重塑未来世界状态的智体。世界模型充当内部模拟器,捕捉环境动态,支持前向和反事实部署,以支持感知、预测和决策。本综述提出具身人工智能中世界模型的统一框架。具体而言,将问题设定和学习目标形式化,
25年10月来自南开大学、天津大学和中科大的论文“A Comprehensive Survey on World Models for Embodied AI”。
具身人工智能需要能够感知、行动并预测行动如何重塑未来世界状态的智体。世界模型充当内部模拟器,捕捉环境动态,支持前向和反事实部署,以支持感知、预测和决策。本综述提出具身人工智能中世界模型的统一框架。具体而言,将问题设定和学习目标形式化,并提出一个三轴分类法,涵盖:(1) 功能性、决策耦合 vs. 通用性;(2) 时间建模、顺序模拟和推理 vs. 全局差异预测;(3) 空间表征、全局潜向量、token 特征序列、空间潜网格和分解渲染表征。其系统化机器人、自动驾驶和通用视频设置中的数据资源和指标,涵盖像素预测质量、状态级理解和任务性能。此外,对最先进的模型进行定量比较,并提炼出关键的开放性挑战,包括统一数据集的稀缺性和评估像素保真度的物理一致性评估指标必要性、模型性能与实时控制所需的计算效率之间的权衡,以及在减轻误差累积的同时实现长期时间一致性的核心建模难度。
如图是本文的综述结构:
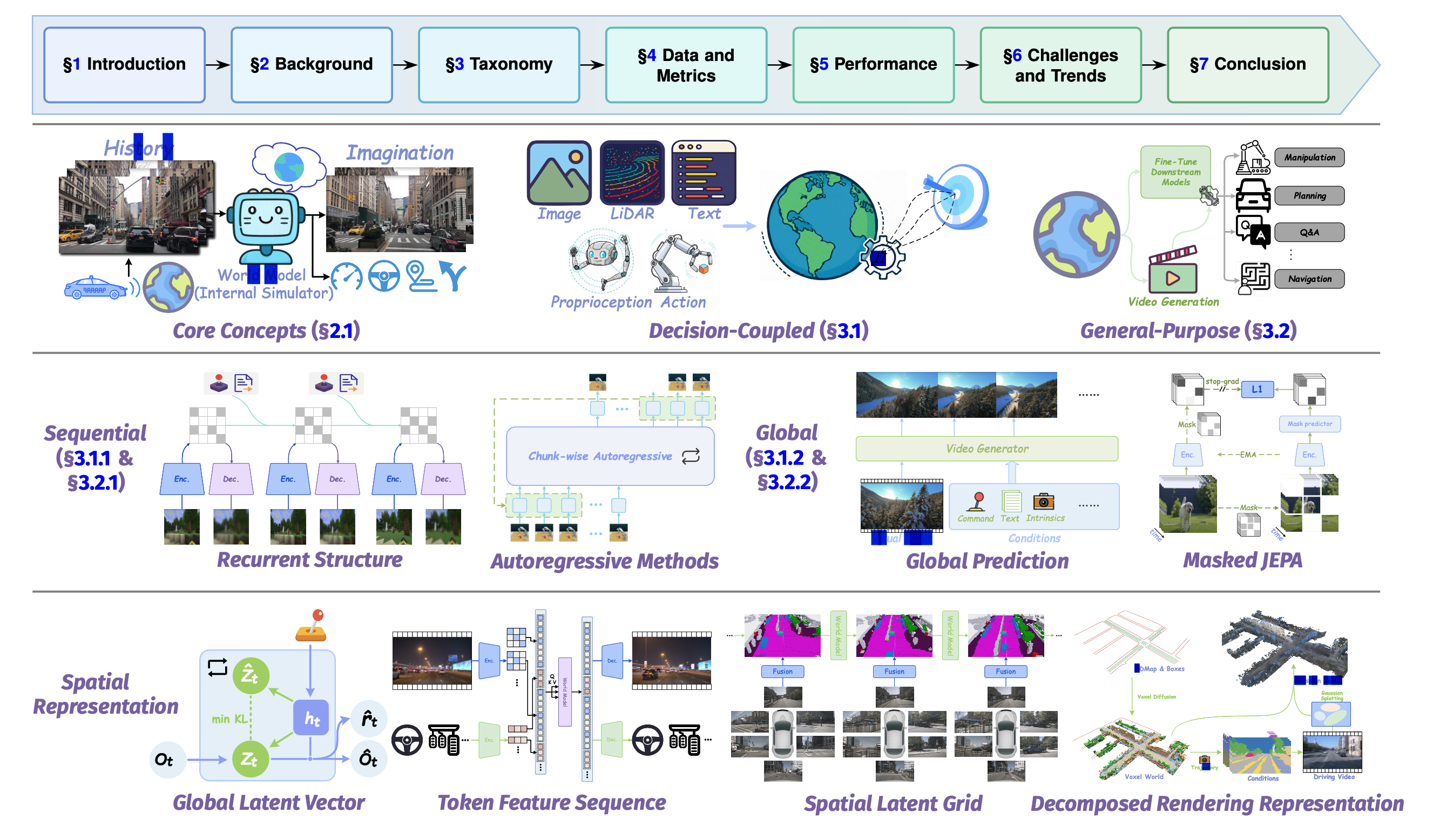
本文根据三个核心维度对世界模型进行分类。
第一个维度,决策耦合,区分决策耦合世界模型和通用世界模型。决策耦合模型是针对特定任务的,其学习动态针对特定的决策任务进行优化。相比之下,通用模型是与任务无关的模拟器,专注于广泛的预测,能够在各种下游应用中进行泛化。
第二个维度,时间推理,描述两种不同的预测范式。顺序模拟和推理以自回归的方式对动态进行建模,一步一步地展开未来状态。相比之下,全局差异预测直接并行估计整个未来状态,以降低时间一致性为代价,提供更高的效率。
第三个维度,空间表示,包括当前研究中用于建模空间状态的四种主要策略:
- 全局潜向量表示将复杂的世界状态编码为紧凑的向量,从而能够在物理设备上进行高效的实时计算。
2)token 特征序列表示将世界状态建模为 token 序列,侧重于捕捉 token 之间复杂的空间、时间和跨模态依赖关系。空间潜网格表示利用几何先验,例如鸟瞰图 (BEV) 特征或体素网格,将空间归纳偏差融入世界模型。分解渲染表示涉及将 3D 场景分解为一组可学习的基元,例如 3D 高斯溅射 (3DGS) [36] 或神经辐射场 (NeRF) [37],然后使用可微分渲染实现高保真新视图合成。
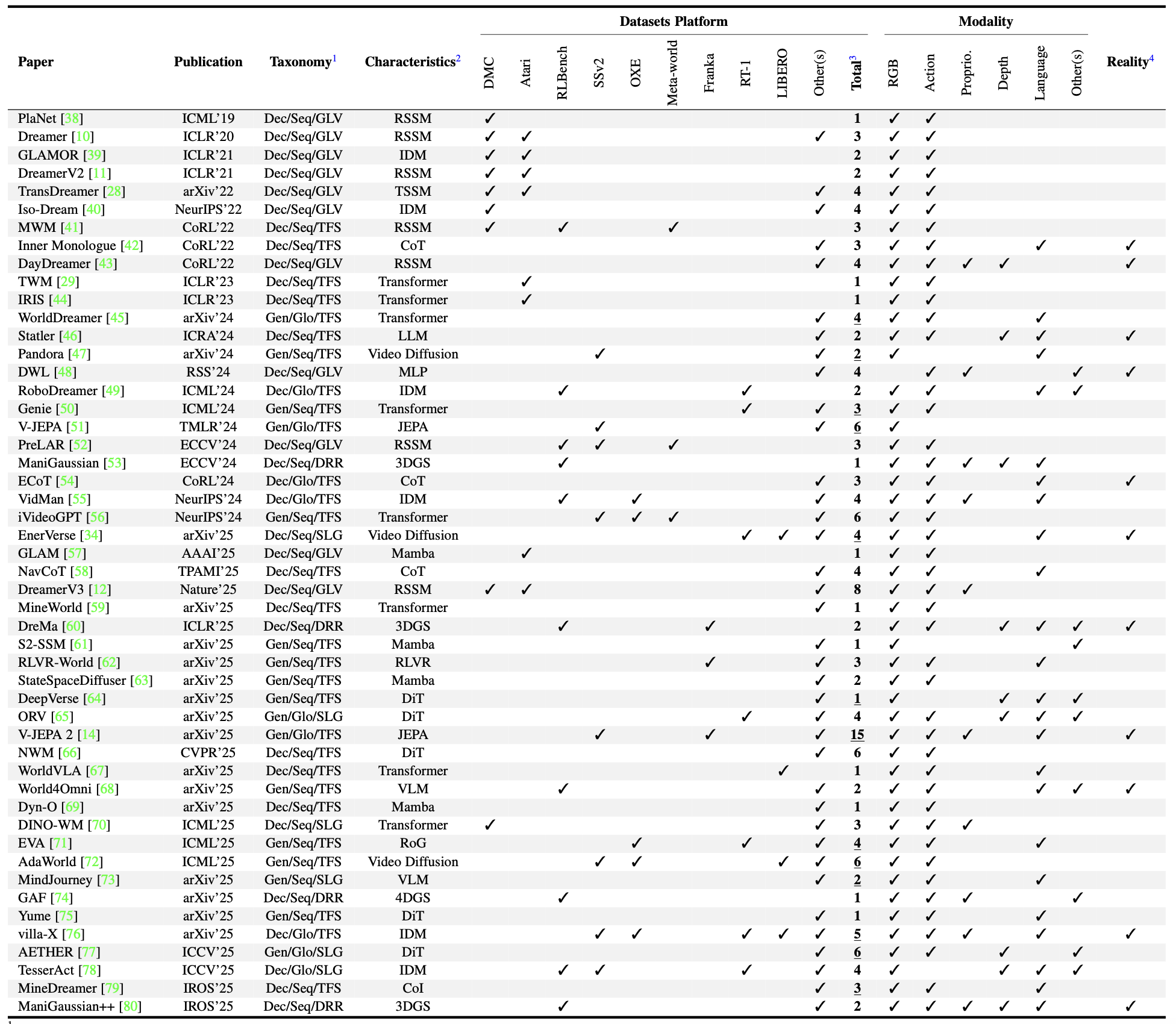
应用此分类法对代表性研究进行分类。下表回顾机器人技术领域的方法:
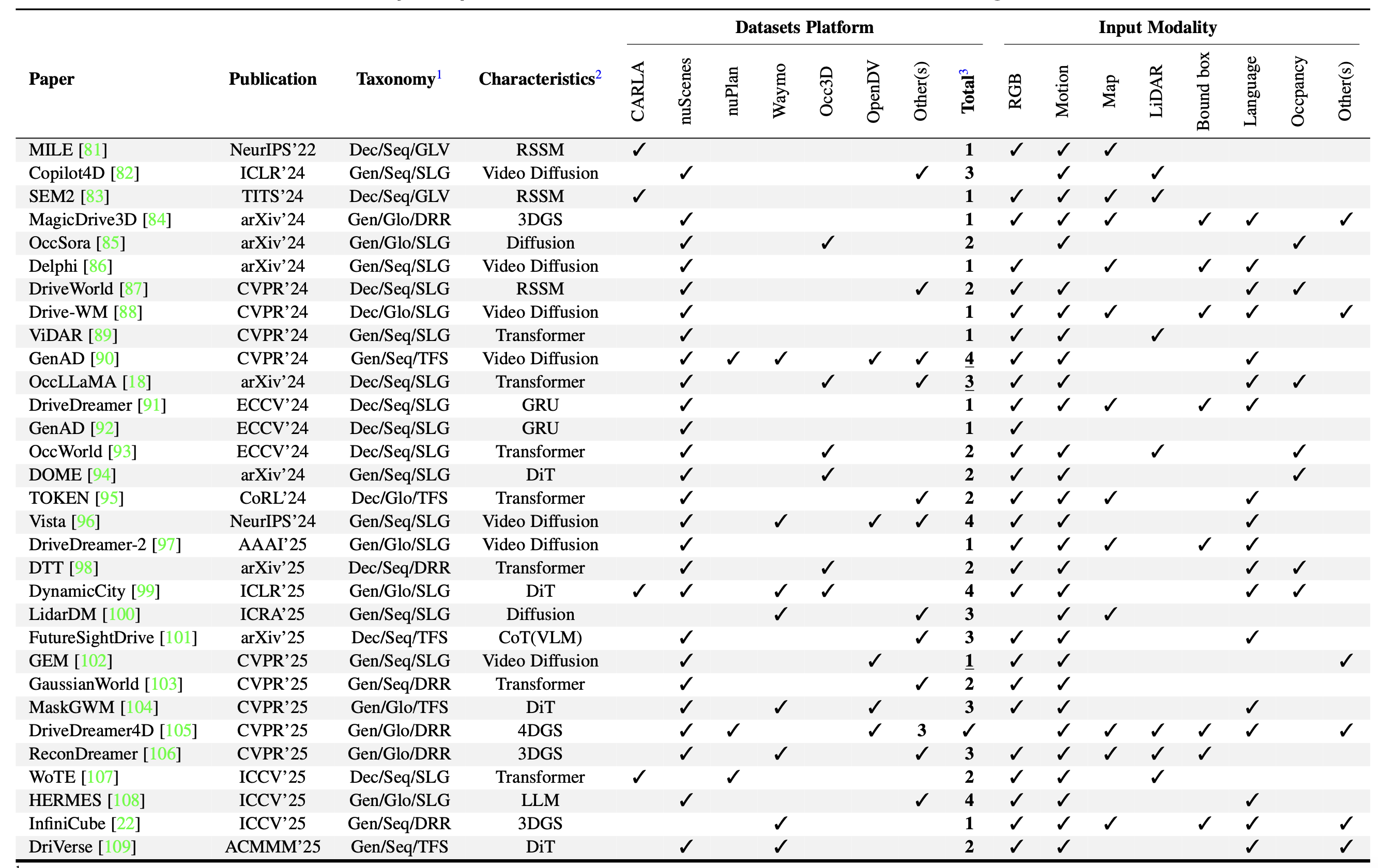
下表则重点关注自动驾驶:
决策耦合世界模型
顺序模拟与推理
全局潜向量。早期的决策耦合世界模型将顺序推理与全局潜在状态相结合。这些方法主要使用循环神经网络 (RNN) 进行高效的实时和长期预测。递归状态空间法(RSSM)是一个典型例子,将确定性记忆与随机成分融合,以实现强大的长远想象力。
近年来,以 Mamba 为代表的状态空间模型 (SSM) 已成为 RNN 和 Transformer 的替代方案,将线性时间复杂度与长时域建模能力相结合。
除了前向时间建模之外,逆向动态建模 (IDM) 也是构建世界模型的关键范式。IDM 推断在初始状态和目标状态之间转换所需的动作。
token 特征序列。token 特征序列范式的核心在于对离散 token 之间的依赖关系进行建模。这种表示支持因果推理、多模态集成以及大语言模型 (LLM) 的复用。
近期以 RSSM 为中心的研究已开始利用 token 级依赖关系来增强表示学习和时间推理。在自动驾驶领域,基于 token 的序列表示越来越多地用于建模跨模态交互和时空结构。基于 token 的范式也扩展到了更广泛的机器人技术领域。最近的研究将环境状态编码为离散的符号 token,并根据动作对下一个 token 进行条件预测。
最近的研究加强 token 化表示与规划之间的联系,特别是通过以目标为中心的方法。基于 token 化,一些研究采用自回归扩散来实现稳定的生成和长期规划。
另一个新兴方向是使用 LLM 和思维链 (CoT) 将显式推理注入世界模型。其他方法直接将 LLM 与世界模型耦合,以实现规划和数据生成的操作。
空间潜网格。通过在几何对齐的网格上编码特征或结合显式空间先验,该范式可以保留局部性,实现高效的卷积或基于注意力机制的更新和流式部署。
在自动驾驶领域,许多研究将基于循环神经网络 (RNN) 的动态过程与空间网格相结合,以指导规划。许多研究专注于自回归预测未来的 3D 占用表征,以实现自动驾驶的运动规划。其中一条链将场景离散化为占用 token 以进行顺序预测。另一条链直接预测体特征或嵌入。自监督变型则根据当前线索预测未来的表征。
除了自动驾驶之外,类似的方案已扩展到更广泛的机器人领域。
分解渲染表示。该范式使用显式可渲染基元(例如 NeRF 和 3DGS)来表示场景,并对其进行更新以模拟动态并渲染未来的观测结果。它提供视图一致的预测、目标级组合性,以及与物理先验和数字孪生的无缝集成,从而支持长期部署。
全局差异预测
token 特征序列。紧凑的全局潜向量表示舍弃细粒度的时空细节,因此很少用于全局预测。相比之下, token 特征序列可以并行预测未来序列,从而减少误差累积,同时实现多模态多样性。
空间潜网格。空间网格模型从自我稳定视角并行预测BEV或体素图,在保留局部性和不确定性的同时,生成可用于规划器的地图以实现快速控制。
通用世界模型
顺序模拟与推理
token 特征序列。通用模型预训练与任务无关的动态模型,以捕捉环境物理并生成未来场景,优先考虑可迁移性而非特定任务。一些通用世界模型越来越多地在未标记视频上进行预训练,并使用 token 化的潜空间进行稳健的预测和生成。
最近的研究将视频扩散模型改编为可控世界模型,这些模型可以自回归地想象未来场景。
为了保持几何保真度和长期稳定性,近期的方法将显式三维先验与基于扩散的世界模型中的时间一致性模块相结合。
序列世界模型越来越多地充当学习模拟器的角色,为策略评估和训练提供基于动作条件的部署。除了扩散之外,序列模型还拓展长期一致性的能力。
空间潜网格。空间潜网格范式通过预训练几何对齐的空间地图,并采用自监督时空目标,保留局部性,并实现高效的rollout、多模态融合和可迁移的规划器就绪地图。基于此范式,结构化网格和基于物理信息的方法对几何和动态进行编码,以实现可控的rollout。
基于网格表征的扩散预测已成为稳定长视域生成的主导方法。
分解渲染表征。场景被分解为显式基元,以合成视图一致、可模拟的长视域轨迹。
全局差异预测
token 特征序列。对于通用世界模型,token 化特征序列通过掩码和生成模型支持全局预测,从而实现具有全局约束和多模态条件的并行长视域rollout。
与此同时,基于扩散的方法已成为全局差异建模的核心。
空间潜网格。空间网格模型并行预测体素网格,并将多视角视觉特征融合成统一的地图,从而学习通用的世界模型。近期研究致力于统一的场景理解和未来预测。在生成方面,token 化的四维表征实现可控的场景合成。
分解渲染表征。该范式通过将显式三维结构与视频生成先验相结合来进行全局预测。
具身人工智能中的世界模型需要处理涵盖操控、导航和自动驾驶等各种任务,这需要异构资源和严格的评估。
数据资源
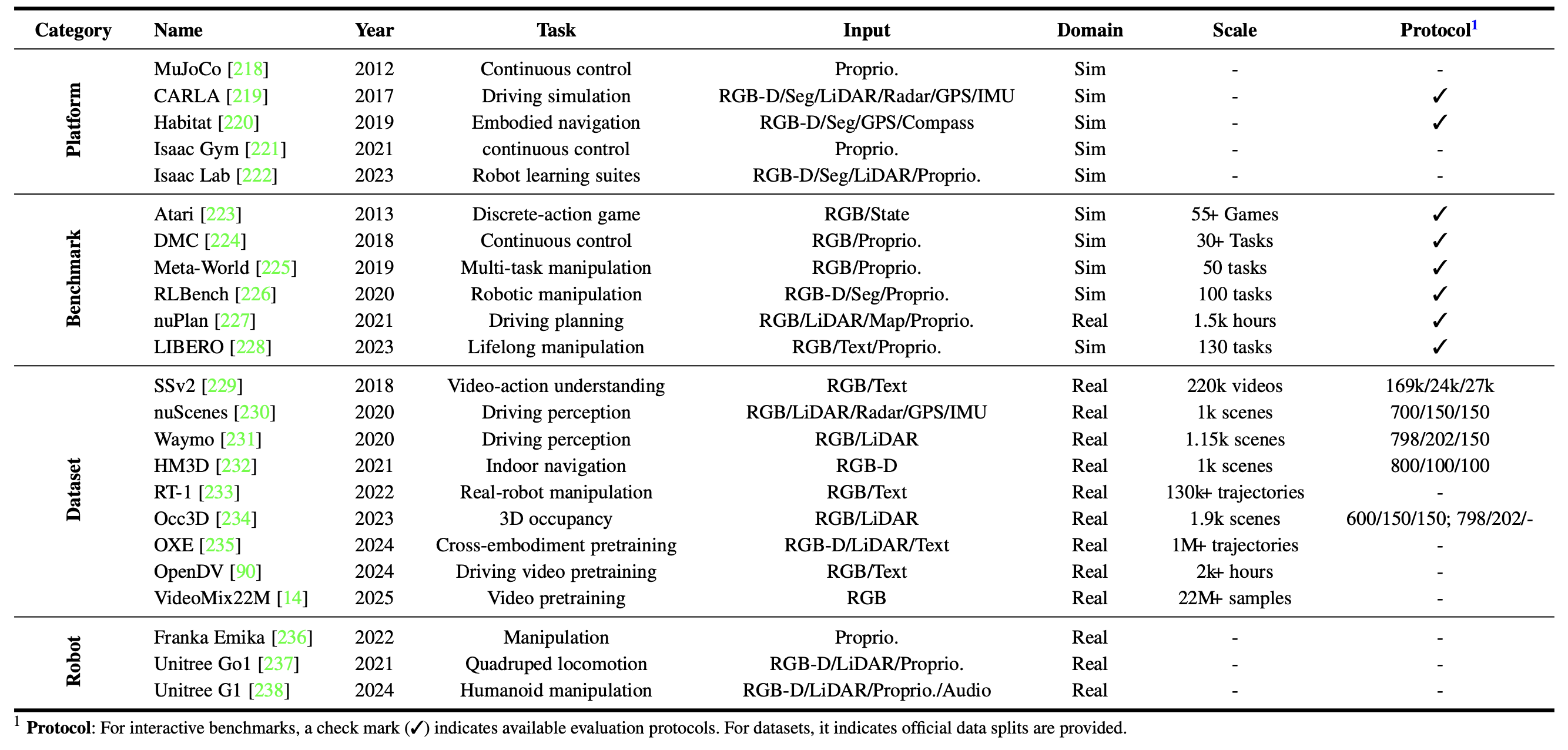
为了满足具身人工智能的多样化需求,将数据资源分为四类:仿真平台、交互式基准测试、离线数据集和真实世界机器人平台。下表对这些资源进行全面概述:
仿真平台
仿真平台提供可控且可扩展的虚拟环境,用于训练和评估世界模型。
• MuJoCo[218] 是一款可定制的物理引擎,因其在机器人和控制研究中对铰接系统和接触动力学的高效机器人仿真而被广泛采用。
• NVIDIA ISAAC 是一个端到端的 GPU 加速仿真堆栈,包含 ISAAC Sim、ISAAC Gym[221] 和 ISAAC Lab[222]。它提供照片级逼真的渲染和大规模强化学习功能。
• CARLA[219] 是一款基于虚幻引擎的城市自动驾驶开源模拟器,提供逼真的渲染、多样化的传感器和闭环评估协议。
• Habitat[220] 是一款高性能的 embodiedAI 模拟器,专注于照片级逼真的 3D 室内导航。
交互式基准测试
交互式基准测试提供标准化的任务套件和协议,用于可重复的闭环评估世界模型。
• DeepMindControl (DMC)[224] 是一个基于 MuJoCo 的标准控制任务套件,为比较从状态或基于像素的观察中学习的智体提供一致的基础。
• Atari[223] 是一个基于像素的离散动作游戏套件,用于评估智体的性能。Atari100k [239] 通过将交互限制在 10 万步来专门评估样本效率。
• Meta-World[225] 是一个多任务和元强化学习的基准测试,在标准化评估协议下,使用 MuJoCo 中的 Sawyer 机械臂执行 50 个不同的机器人操作任务。
• RLBench [226] 提供 100 个模拟桌面操作任务,这些任务具有稀疏奖励和丰富的多模态观察,旨在测试复杂的技能和快速适应能力。
• LIBERO [228] 是机器人终身操控的基准测试,它提供 130 个程序生成的任务和人工演示,用于评估样本效率和持续学习。
• nuPlan [227] 是自动驾驶的规划基准测试,它使用轻量级闭环模拟器和超过 1500 小时的真实驾驶日志来评估长视野性能。
离线数据集
离线数据集是预收集的大规模轨迹,它消除交互式部署,并为可重复的评估和数据高效的世界模型预训练奠定基础。
• RT-1[233] 是一个用于机器人学习的真实世界数据集,由 13 个 Everyday Robots 移动机械手历时 17 个月收集而成。它包含 130,000 个演示,涵盖 700 多个任务,将语言指令和图像观察与离散化的 11-DoF 动作配对,用于机械臂和移动基座。
• OpenX-Embodiment(OXE)[235] 是一个语料库,汇集来自 21 个机构的 60 个数据源,涵盖 22 个机器人实例、527 种技能和超过一百万条轨迹,并以统一的格式用于跨实例训练。在 OXE 上训练的模型表现出超越单机器人基线的强大迁移能力,凸显跨平台数据共享的有效性。
• Habitat-Matterport3D(HM3D)[232] 是一个包含 1,000 个室内重建图像的大规模数据集,可导航面积为 112,500 平方米,大大扩展具身人工智能模拟的范围和多样性。该数据集面向 Habitat 平台发布,提供无缝使用所需的元数据和资源。
• nuScenes[230] 是一个大规模多模态驾驶数据集,其 360 度传感器套件包含六个摄像头、五个雷达、一个激光雷达和 GPS/IMU。它包含在波士顿和新加坡收集的 1000 个 20 秒场景,包含 23 个类别的密集 3D 注释和高清地图,为多模态融合和长期预测提供了核心基准。
• Waymo [231] 是一个多模态自动驾驶基准,包含来自旧金山、凤凰城和山景城的 1150 个 10 Hz 的 20 秒场景。它包含五个激光雷达和五个摄像头,拥有约 1200 万个 3D 和 2D 注释,使其成为交通动态建模的大规模资源。
• Occ3D [234] 定义了基于环视图像的 3D 占用预测,提供区分空闲、占用和未观测状态的体素标签。 Occ3D-nuScenes 包含约 40 000 帧分辨率为 0.4 米的视频,而 Occ3D-Waymo 则提供约 200 000 帧分辨率为 0.05 米的视频。这种体素级监督使得能够超越边界框进行整体场景理解。
• Something-Something v2 (SSv2) [229] 是一个用于细粒度动作理解的视频数据集。它包含 174 个类别的 220 847 个视频片段,这些片段由众包工作者根据文本提示(例如,将某物放入某物中)收集,其中训练集为 168 913 个,验证集为 24 777 个,测试集为 27 157 个。
• OpenDV [90] 是由 GenAD 提出的最大的大规模自动驾驶视频文本数据集,支持视频预测和世界模型预训练。它包含来自 YouTube 和七个公开数据集的 2059 小时视频和 6510 万帧,覆盖 40 多个国家/地区和 244 个城市。该数据集提供命令和上下文注释,以支持基于语言和动作的预测和规划。
• VideoMix22M [14] 是 V-JEPA 2 引入的用于自监督预训练的大规模数据集。其样本量从 200 万到 2200 万不等,分别来自 YT-Temporal-1B [240]、HowTo100M [241]、Kinetics [242]、SSv2 和 ImageNet [243]。其中,最大的来源 YT-Temporal-1B 采用基于检索的滤波技术进行筛选,以抑制噪声;而 ImageNet 图像则被转换为静态视频片段,以保持一致性。
现实世界机器人平台
现实世界机器人平台为交互提供物理具身,能够在现实世界约束条件下进行闭环评估、高保真数据收集和S2R验证。
• Franka Emika [236] 是一款7自由度协作机械臂,配备关节扭矩传感器,可实现精确的力控制。通过控制接口,它支持1 kHz扭矩控制,可执行接触密集型任务,同时其ROS集成使其成为一个多功能平台。
• Unitree Go1 [237] 是一款经济高效且广泛采用的四足机器人,配备全景深度感知套件,机载计算能力达1.5 TFLOPS,最大速度达4.7 m/s,使其成为运动和具身人工智能研究的标准平台。
• Unitree G1 [238] 是一款用于研究的紧凑型人形机器人,提供高达43自由度和120 N·m的膝关节扭矩,并集成了3D激光雷达和深度摄像头。该低成本平台具备多模态感知、板载计算、ROS 支持和可更换电池等特性,为训练和评估具身世界模型提供了一个实用的真实机器人测试平台。
指标
指标评估世界模型捕捉动态、泛化至未知场景以及利用额外资源进行扩展的能力。
本文给出三个抽象级别指标:像素预测质量、状态级理解和任务性能,代表从低级信号保真度到高级目标实现的进展。
(略)
鉴于世界模型变体和异构指标的激增,根据任务目标组织比较,并依赖标准化基准,报告简明的表格,突出每种方法的优势和局限性。
像素生成
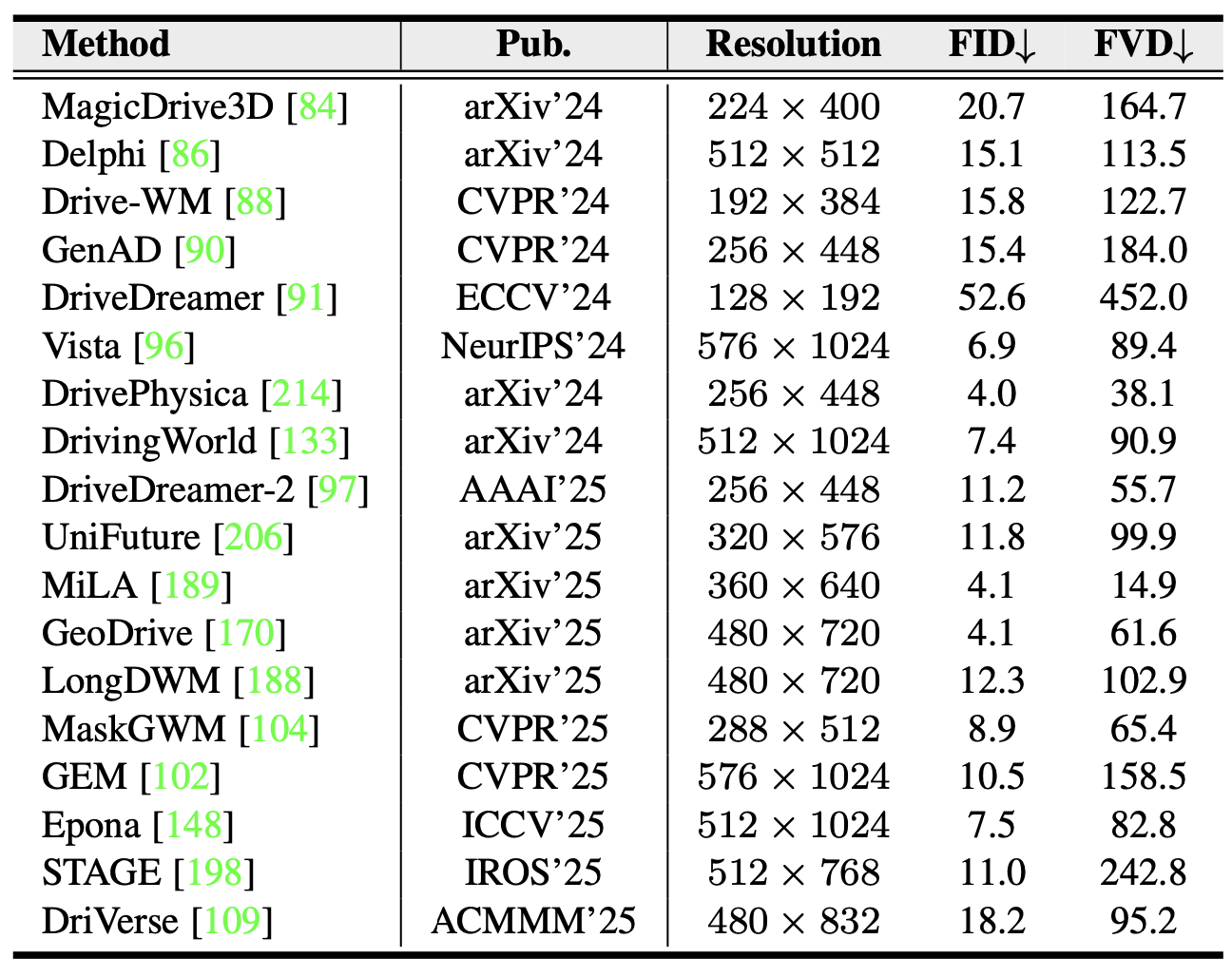
nuScenes 上的生成。驾驶视频生成被视为一项世界建模任务,在固定长度的片段中合成合理的场景动态。典型的协议会生成短序列,并使用 FID(外观保真度)和 FVD(时间一致性)来评估质量。为了公平地比较 nuScenes 验证集的划分,近期方法取得显著进展,如表所示。DrivePhysica 提供最佳的视觉保真度,而 MiLA 实现最强的时间一致性,两者共同建立了新的最佳性能。
场景理解
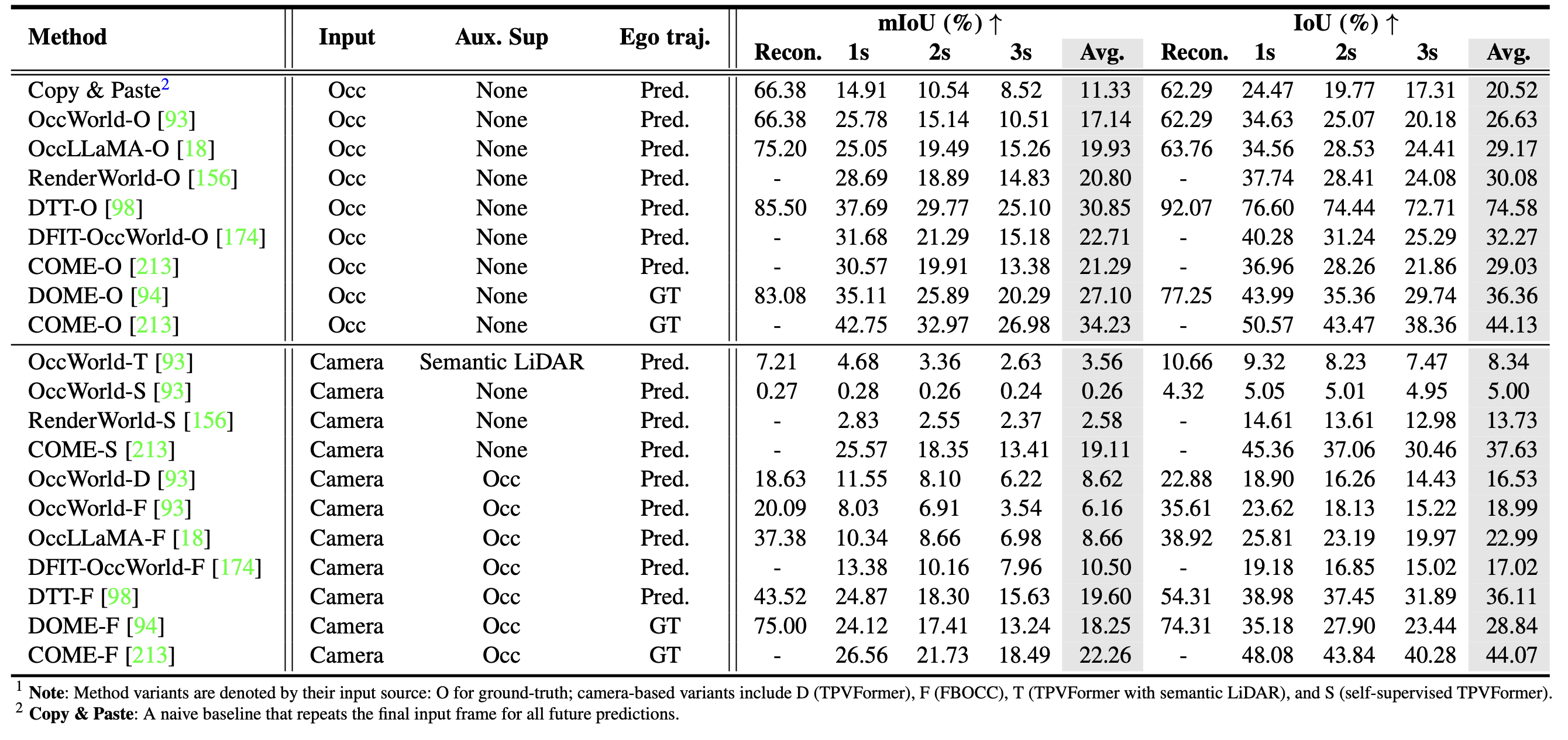
基于 Occ3D-nuScenes 的 4D 占用预测。4D 占用预测被视为一项代表性世界建模任务。给定过去 2 秒的 3D 占用情况,模型预测接下来 3 秒的场景动态。评估遵循 Occ3D-nuScenes 协议,并报告 mIoU 和每个视界的 IoU。如表所示,通过输入模态、辅助监督和自我轨迹的使用情况比较各种方法,以揭示时空预测的设计选择。使用占用输入的方法优于仅使用摄像头的变型,并且添加带有 GT 自我轨迹的辅助监督可以进一步缓解 2-3 秒的性能衰减。在所有方法中,COME(带有 GT 自我)实现最佳的平均 mIoU 和每个视界的 IoU。
控制任务
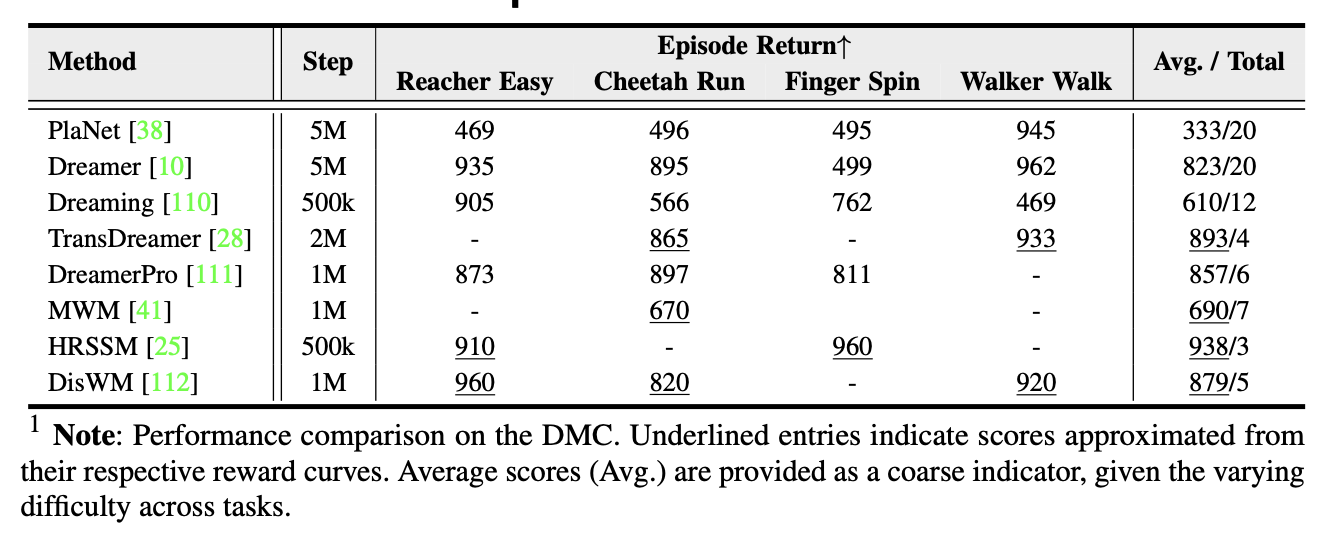
基于动态矩阵模型 (DMC) 的评估。大多数研究探讨世界模型学习控制相关动态的能力,通常采用基于像素的设置,包含 64×64×3 个观测值。主要指标是情节回报 (Episode Return),定义为 1000 步内的累积奖励,在 r/t ∈ [0, 1] 的情况下,理论最大值为 1000。为了便于比较,下表报告步骤预算,并按任务分数和任务数量总结了性能。结果表明数据效率有所提高,最近的模型在更少的训练步骤中达到了强劲的性能。然而,不一致的评估协议和任务子集阻碍了对泛化能力的公平评估,构建一个跨任务、模态和数据集的广泛可迁移的模型仍然是一个悬而未决的挑战。
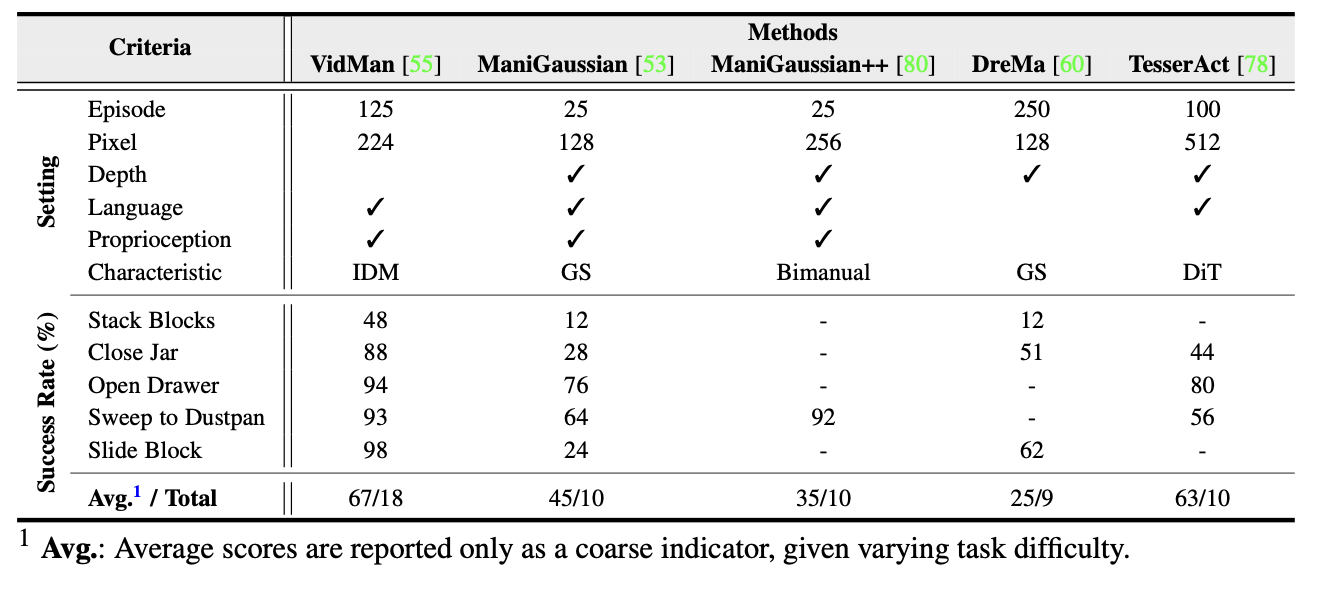
RLBench 上的评估。RLBench 使用 7 自由度模拟的 Franka 手臂来评估操作,并广泛用于评估世界模型是否捕捉到与任务相关的动态并支持条件动作生成。主要指标是成功率,定义为在步长限制内达到目标的场景比例。如表所示,不同实现在场景预算、分辨率和模态方面存在差异,这使得同类比较变得复杂。尽管存在这种异质性,但仍有几个趋势显而易见。近期方法越来越多地利用多模态输入,并采用更强大的主干网络,例如 3DGS 和 DiT。VidMan 在最广泛的任务上实现了较高的平均成功率,表明 IDM 是一个很有前景的架构方向。
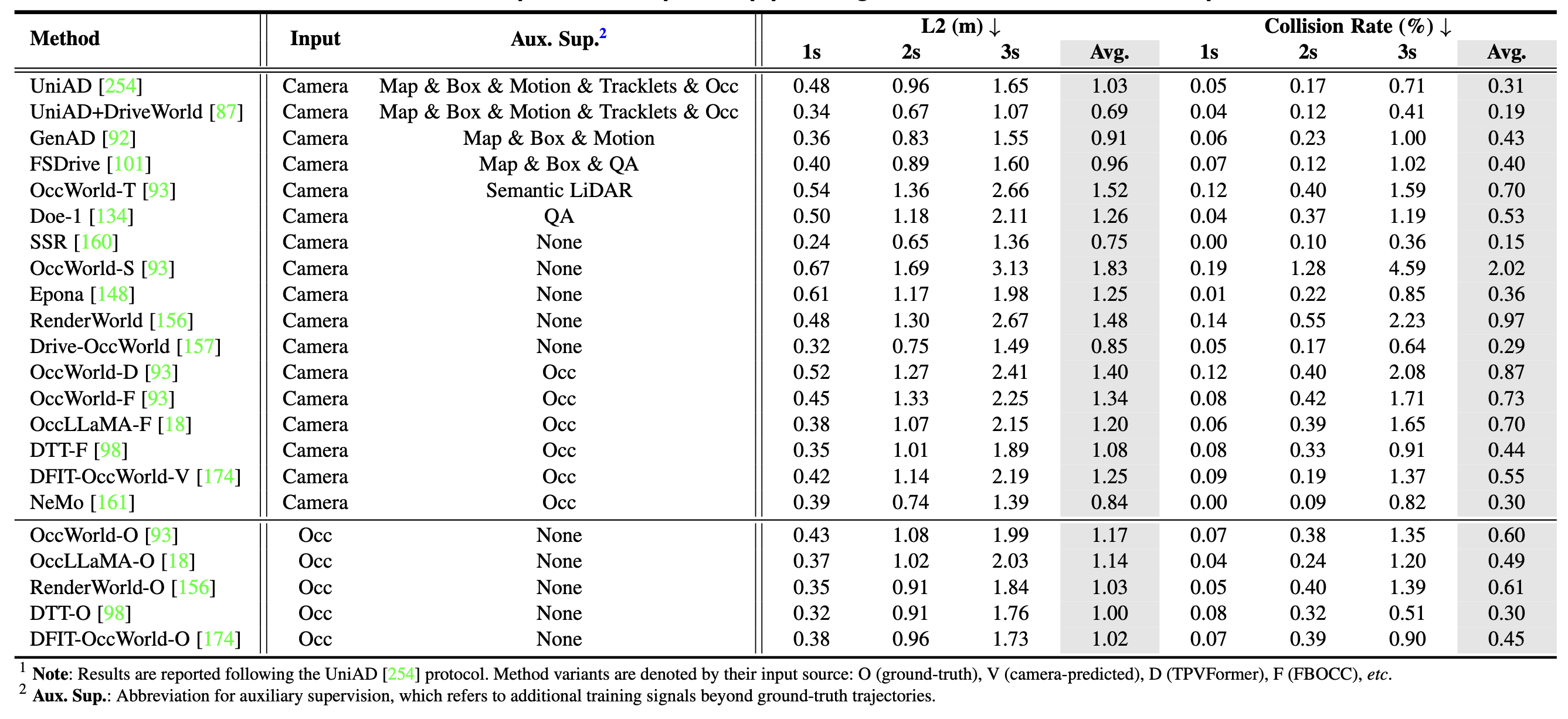
nuScenes 上的规划。开环规划在 nuScenes 验证集上被视为世界建模任务,其中模型根据有限的历史记录预测自我运动。方法观察过去 2 秒的轨迹,并将接下来的 3 秒预测为 2D BEV 航点。评估报告了多个视域下的 L2 误差和碰撞率,下表总结按输入模态、辅助监督和指标设置划分的结果。在此共享协议下,出现了明显的权衡。UniAD + DriveWorld 在广泛的辅助监督下实现了最低的 L2 误差,而 SSR 在没有额外监督的情况下实现了最佳的碰撞率和竞争性的 L2 误差。基于摄像头的方法现在超越了使用特权占用的模型,这反映了 E2E 规划的日益成熟。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献123条内容
已为社区贡献123条内容

所有评论(0)