《SimAC: A Simple Anti-Customization Method againstText-to-Image Synthesis of Diffusion Models》论文(侵删)
https://doi.org/10.1109/cvpr52733.2024.01145
author={Feifei Wang and Zhentao Tan and Tianyi Wei and Yue Wu and Qidong Huang}
摘要
尽管基于扩散的定制方法在视觉内容创作上取得了成功,但从隐私和政治的角度来看,人们对这种技术的关注越来越多。为了解决这个问题,最近几个月提出了几种反定制方法,主要是基于对抗性攻击。遗憾的是,这些方法大多采用简单的设计,例如端到端优化,关注的是相反地最大化原始训练损失,从而忽略了扩散模型固有的微妙的内在属性,甚至导致在一些扩散时间步长内的无效优化。在本文中,我们努力通过对这些固有属性的全面探索来弥合这一差距,以提高当前反定制方法的性能。研究了两个方面的性质:1)在图像的频域中,我们考察了时间步长选择与模型感知之间的关系,发现时间步长越低,对对抗性噪声的贡献越大。这启发了我们提出了一种自适应贪婪搜索来寻找最优时间步长,并与现有的反定制方法无缝集成。2)我们仔细研究了不同层次的特征在去噪过程中的作用,并设计了一个复杂的基于特征的反定制优化框架。在面部基准上的实验表明,我们的方法显著增加了身份破坏,从而增强了用户隐私和安全性。
一、Introduction
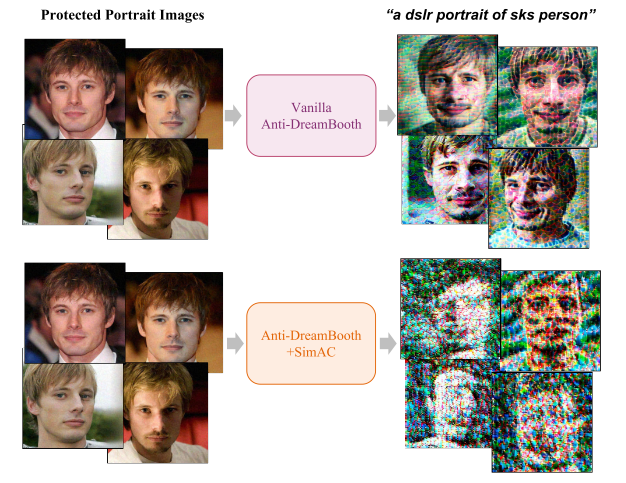
图1.添加SIMAC前后Anti-DreamBooth的比较。我们的方法进一步增强了它去身份的能力。
扩散模型(DM)[12,27,28]最近被证明是一种产生更逼真的视觉内容的强大范例。开源实现稳定扩散的出现鼓励用户利用LDM探索创造性的可能性。用户只需要提供代表同一对象的多个图像以及罕见的标识符来定制他们的扩散模型[7,13,17,24]。在微调模型或优化稀有识别符的文本嵌入后,可以生成包含指定对象的无数高质量图像。
尽管多样化的视觉内容创作带来了便利,但大规模文本到图像模型的定制也允许一些恶意用户创建违背事实的图像。一些滥用者未经许可就利用它窃取他人的绘画风格,并生成新的绘画内容。此外,一些不法分子可以收集发布在社交平台上的个人肖像照片,并通过定制生成该人的虚假图像。制造包含名人照片的假新闻变得更加容易,这极大地误导了公众。这种侵权行为对用户隐私和知识产权构成了威胁。因此,制定有效的对策来保护用户免受这种恶意使用是至关重要的。
目前的反定制方法一般基于对抗性攻击[9,29]。AdvDM[18]是一项开创性的工作,它使用对抗性噪声来保护用户图像不被扩散模型定制。它巧妙地将扩散模型与对抗性样本相结合,首先实现了用户隐私保护。反梦想展台[32]通过使用Alter Nate训练进一步增强了保护效果。
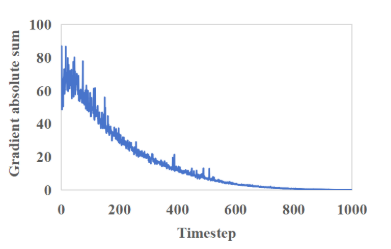
图2.实施AntiDreamBooth时获得的时间点和梯度的分布(梯度的绝对值之和)。在较大的时间步长上出现几乎为零的值。

图5.为了进一步探索图像在不同扰动时间步的梯度分布,(A)计算每个时间步低于阈值1e−10的绝对梯度的数量,(B)显示不同时间步的最大绝对梯度,以及(C)演示绝对梯度的平均值和中位数如何随时间步而变化。这些都证明,随着时间步长的增加,绝对梯度下降,从而导致噪声优化效果不佳。
这两种算法都是从(0,最大去噪步数)中随机选取加入LDM潜伏期噪声的时间步长,直接以LDM训练损失最大化为优化目标。然而,如图2所示,我们注意到,当随机采样的时间步长相对较大时,扰动图像的梯度很小,甚至为零,即噪声潜伏期更接近于高斯噪声。这意味着在对抗性攻击的有限步骤中,很大一部分步骤是无效的,因为扰动图像不能以这样的零梯度来优化目标,从而导致保护有效性和效率的降低。因此,受这些当前方法保护的图像在定制时仍然允许模型从用户输入的图像中捕获许多细节,并泄露用户的隐私,如图5所示。
其根本原因是这些方法未能将对抗性攻击与扩散模型固有的性质结合起来。我们的目标是深入分析为什么扰动图像的梯度在不同的时间步长上不同,以及扩散模型如何在不同的中间层感知输入图像。然后,在深入分析的基础上,从时间维度和特征维度两个方面对现有的定制方法进行了改进。
为了观察扰动图像的时间步长和梯度之间的关系,我们首先重建由不同时间步长的噪声潜伏期预测的图像,并将它们与输入图像进行比较。考虑到规则的对抗性噪声主要影响图像的高频,我们在频域进行比较,目的是考察模型的感知是在较低级别还是在较高级别。我们观察到,当选择较小的时间步长时,该模型侧重于图像的高频分量,反之亦然。因此,在更大的时间步长上引入对抗性噪声是无效的,因为图像上的细微变化几乎不会影响生成图像的低频。为了更有效地选择时间步长,我们提出了一种自适应时间选择方法来寻找最优的时间间隔。它可以集成任何迭代攻击方法,并在每次迭代过程中贪婪地选择更有效的时间步长。此外,为了直观地分析U-Net解码器的不同层特征在去噪过程中对输入图像提取的影响,我们使用主成分分析(PCA)对其进行可视化。对比可视化后发现,在解码器内部,随着层数的增加,特征提取逐渐从低频向高频转移。这表明较高的层可能更集中在图像的纹理上。因此,我们选择代表攻击过程中高频信息的特征,因为常规的对抗性噪声集中在图像的高频上。将特征干扰损失和扩散去噪损失相结合,提高了对输入图像身份干扰的有效性。
我们的主要贡献:
·我们发现了以前的反习惯方法在保护隐私方面的不足之处。通过深入分析扩散模型在不同时间和不同中间层感知图像的方式,我们可以更好地将对抗性攻击与扩散模型结合起来。
·在分析的基础上,提出了一种简单而有效的防定制方法,包括自适应贪婪时间选择和特征干扰损失,以提高安全保护。我们的方法可以很容易地推广到不同的反定制框架,并提高它们的性能。
·在两个人脸数据集上的广泛评估表明,该方法对用户身份的破坏更加明显,增强了信息安全。
二、Related work
2.1Generative Models and Diffusion Models
变分自动编码器(VAEs)[16]和产生式对抗网络(GANS)[8]是产生式模型中流行的框架,它们具有很强的产生性。这些模型将数据x编码为潜在变量z,并对联合分布pθ(x,z)进行建模。然而,VAE样本的质量并不具有Gans的竞争力,Gans受到训练不稳定的影响[10]。由于扩散概率模型(DM)[27]逐渐向来自联合分布Qθ(X0:T|X0)的数据添加噪声并逐步去噪,因此训练效率和样本质量已经达到工作状态。
无条件生成模型不能产生期望的样本,于是模型以不同的输入作为指导而涌现出来。基于GAN,cGAN[20]生成以给定标签y为条件的图像,并且Cycle-GAN[34]实现考虑给定图像的未配对图像平移。该扩散模型配备了一些技术,如无分类指导[11],在生成过程中获得了根据不同提示作为条件进行跟踪的能力。
开源的潜在扩散模型(LDM)[23]在低维的潜在空间而不是像素空间中操作图像,这大大减少了训练计算量。为了支持不同的条件输入,他们将交叉关注层添加到基础U网主干中作为条件机制τθ。上面精致的设计让扩散更友好地让用户创造出他们需要的东西。它还可以帮助他们设计他们的扩散,这些扩散合成了包含用户在推理过程中给出的特定概念(例如,对象或风格)的视觉内容。
2.2Customization
DreamBoth[24]作为一种流行的基于扩散的方法脱颖而出,用于定制文本到图像的生成。该方法包括在相应的标识符旁呈现描述特定概念(例如,特定的狗)的3个∼5图像(例如,“SKS狗”)。DreamBoth利用这些图像来微调预先训练的稳定扩散模型。这一微调过程鼓励模型“记忆”概念及其识别符,使其能够在推理过程中在新的上下文中重现该概念。
另一方面,文本倒排[7]采用了一种不同的方法。这种方法冻结了U-Net,并独占地优化了表示输入概念的唯一标识符(例如“SKS”)的文本嵌入。
在DreamBoth的启发下,许多创新的作品如雨后春笋般涌现,如定制扩散[17],Sine[33]等。在寻求更高效的微调的过程中,DreamBoth成功地与Lora[13]进行了整合,并成为了社区中一个非常有影响力的定制项目。LORA特别将视觉转换器模型[6]的关注层分解为低阶矩阵,从而降低了与精细调整相关的成本。
2.3. Privacy Protection for Diffusion Models
为了缓解基于稳定扩散的定制(即所谓的反定制)滥用私人图像的问题,最近一些研究人员[18,26,32]深入研究了扩散模型的隐私保护。AdvDM[18]误导了扩散模型的特征提取。分析了精调的训练目标,提出了以去噪损失梯度为指导对去噪过程中采样的潜在变量进行优化的直接方法。生成的高级示例降低了DreamBoth或其他基于DM的定制方法的生成能力。受[14]的启发,反梦想亭[32]使用交替代理和扰动学习(ASPL)来逼近真实训练的模型。他们在干净的数据上训练模型,并使用这些模型作为代理模型来计算添加到用户提供的图像的噪声。然后将扰动后的图像作为训练数据进行模拟真实场景的代理模型微调。PhotoGuard[25]专门关注误导公众并损害个人声誉的未经授权的图像修复。他们同时使用针对灰色图像的VAE编码器攻击和UNT攻击来阻止侵权者制造假新闻。
虽然这些方法可以部分缓解稳定扩散定制的恶意使用,但一些担忧限制了其在更实际场景中的应用。其主要缺陷可以分为两个方面。首先,我们观察到,atiDreamBoth主要倾向于扰乱生成图像的全局纹理,而用户提供的概念和结构信息的身份通常被保留。由此产生的反定制性能通常不尽如人意,因为用户仍然是一种不愉快的体验,因为在定制生成的虚假图像或视频上,他们的私人概念很容易被其他人区分开来。
其次,这些方法简单地使用重构损失作为指导来生成对抗性示例,因为大多数流行的基于DM的定制方法在微调过程中将此作为训练目标。然而,UNT区块内部的特征还没有得到充分的探索。
三、Method
3.1. Preliminaries
3.1.1 Diffusion Model
扩散模型是一种概率生成模型,它从高斯分布的样本中提取样本,然后逐步去噪,以学习期望的数据分布。给定x0∼q(X),前向过程在每个时间步长t∈(0,T)向输入图像添加增加的噪声,这产生噪声潜伏序列{x0,x1,...,xt}。反向过程训练模型ϵθ(XT,t,c)以预测XT中添加的噪声以推断XT−1。在去噪过程中,训练损失为L2距离,如公式(1)、公式(2)所示。虽然有很多文本到图像扩散模型的实现,但稳定扩散是为数不多的开源扩散模型之一,并在社区中得到了广泛的应用。因此,我们的方法主要是基于在Hugging Face上提供的稳定扩散的检查点。
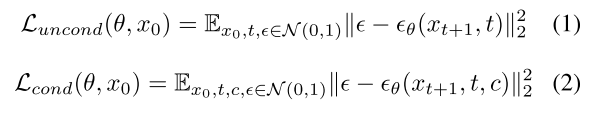
其中x是输入图像,t是相应的时间步长,c是条件输入(例如,文本或图像),ϵ∼N(0,1)是噪声项。
3.1.2 Adversarial Attacks
用于分类的对抗性示例被精心制作以误导模型将给定的输入分类到错误的标签。然而,传统的攻击策略在处理产生式模型时并不有效。对于扩散模型,对抗性的例子是一些图像被添加到不可感知的噪声上,导致扩散模型将它们从生成的分布中考虑出来。具体来说,这种噪声增加了图像重建的挑战,并阻碍了基于扩散模型(DM)的应用程序的定制能力。优化的噪波通常被约束为小于常量值η。δ通过以下形式确定:

其中X是输入图像,yreal是真实图像,L是用于评估对抗性例子的性能的损失函数。
投影梯度下降(PGD)[19]是一种广泛使用的迭代优化对抗性实例的方法。该过程如公式(4)所示。
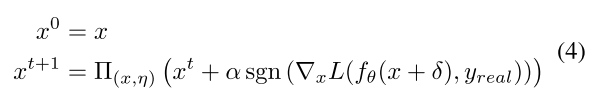
其中x是输入图像,sgn(·)是符号函数,(∇xL(fθ(x+δ),yReal)是损失函数相对于x+δ的梯度。α表示每次迭代期间的步长,t是迭代次数。通过Π(x,η)运算,噪声被限制在η球内,确保对抗性例子是可接受的。
3.2. Overview
在这里,我们深入研究LDM的属性,并分析可能对攻击有利的潜在漏洞。在Sec.3.3,对其性能进行了全面的分析。在Sec.3.4,在这些分析的基础上提出了我们的方法,主要包括两个部分,即自适应贪婪时间间隔选择和特征干扰损失。整个流水线如图3所示。
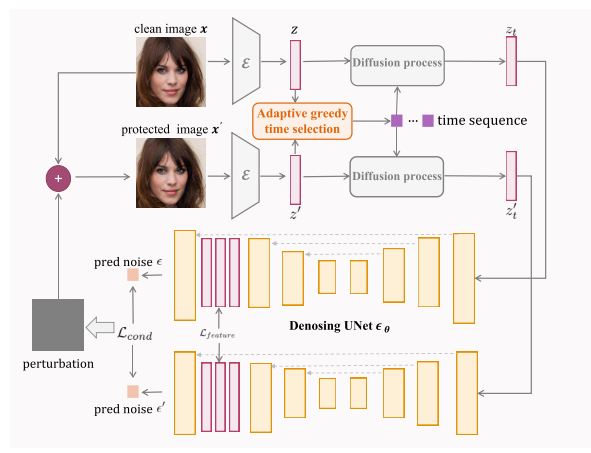
图3.我们建议的SIMAC的管道。在前馈阶段,我们首先用自适应策略贪婪地选择时间步长。然后将特征干扰损失与基线的原始目标相结合,作为最终目标。扰动是迭代优化。
3.3. Analysis on Properties of LDMs
Differences at different time step
如公式(5)所示,前向处理允许在任意时间步长t处采样Xt。对应于时间步长的噪声的大小由预定义的噪声调度来确定。为了确保最终的潜伏期XT服从标准正态分布,噪声注入的幅度随着时间步长逐渐增加。
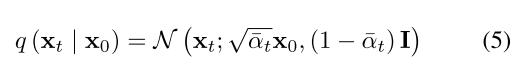
在去噪过程中,我们基于噪声潜伏期zt重建输入图像X0,并在不同的时间步长上可视化重建图像与输入图像在频域中的差异。如图4所示,当t∈[0,100]时,原始图像和重建图像之间的主要区别在于高频分量。我们最初的期望是通过引入高频对抗性噪声来扰乱原始图像的重建,旨在实现反定制。然而,当t增加时,例如t∈[700,800],重建图像和输入图像之间的低频分量的差异主导了两者之间的大部分频域差异。因此,这可以解释为什么当噪声调度器的时间步长较大时,扰动图像的梯度接近于零,从而导致噪声优化效果不佳。
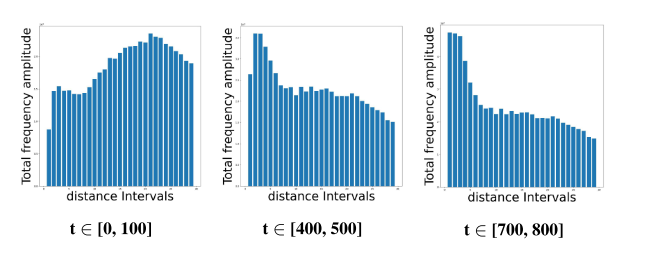
图4.频域残差分析X轴是到低频中心(从低频到高频)的距离,Y轴表示频率残差的总幅度。可以看出,当t较小时,高频差超过低频差。随着t的增大,低频差逐渐占据主导地位。
Impacts ofTime Step Selection on The Gradients of Perturbed Images
在这一部分中,我们详细地阐明了我们选择自适应时间间隔的动机。如第1节所述,我们发现在以前的反定制方法(例如,反DreamBooth)中,当选择噪声调度器的大时间步长时,扰动图像的梯度非常接近于零。我们发现,不适当的时间步长选择会导致对抗性噪声优化的许多低效甚至无效的步骤。在这里,我们提供了我们探索的细节,关于不同的时间步长选择如何影响反定制的性能。
我们的探索集中于从统计学的角度分析不同时间间隔的梯度。我们已经建立了1E−10的阈值,以评估不同时间步长的扰动图像中绝对值低于该阈值的渐变数量。图5显示了一个显著的趋势:在总时间间隔的后半部分(0,MaxTrainStep),低于指定阈值的绝对渐变计数急剧增加。此外,图5显示了当时间步长变大时,扰动图像中绝对梯度的最大值、平均值和中位数减少。
我们的方法依赖于PGD[19](投影梯度下降),这是一种用于对抗攻击的迭代方法。在每次迭代中,计算梯度变得关键,因为它表示关于扰动图像的目标函数的变化率。接近零的梯度意味着迭代优化的可能性,但对目标函数的改变最小。这最终会导致攻击效率和有效性的降低。因此,随机选择时间步长使得在相同的噪声预算下优化目标函数变得更具挑战性,并导致对抗定制的效率和有效性降低。这突出了使用我们的自适应、贪婪的时间间隔选择来进行扰动的迫切需要。
Differences at Different UNet Layers.

图6.特征的PCA可视化。剩余块的输出特征在TimeStep=500处可视化。随着特征的深入,特征捕获的高频信息变得更加重要。
受[31]的启发,在去噪过程中,我们利用主成分分析来可视化U-Net解码块中每一层的输出特征。解码块由自我注意块、交叉注意块和残差块组成,我们选择残差块的特征。总共有11个层,这些层在TimeStep=500处可视化。如图6所示,随着UNet解码器块输出特征的增加,可视化特征逐渐从描述结构等低频信息转变为捕捉纹理和类似的高频信息。由于我们的噪声是为了扰乱高频信息,所以更深的特征是我们的对抗性噪声的良好扰动对象,以加强试图扰动生成的图像中的高频分量的干扰。
3.4. Adaptive Greedy Time Interval Selection
为了在有限的噪声注入步骤中实现更有效的隐私保护,我们提出了一种快速自适应时间间隔选择策略。首先,在输入图像的基础上,从区间(0,最大训练步长)中随机选取5个时间点。对于每个时间步长,我们计算关于输入图像的梯度。对梯度的绝对值求和。如果绝对梯度值的和在时间步长t是最小的,则相应的间隔(t−20,t+20)被移除。对于具有最大和的时间步长,计算噪声并将其添加到图像中,该噪声图像成为下一轮梯度计算的输入。重复该过程,直到最终时间间隔长度不大于100。我们得到了用于噪声注入的最终间隔。

3.5. Feature Interference Loss
利用L2范数,我们提出了特征干扰损失,其中ft L∗是输入图像在时间步长t的选定层集合L的输出特征,ft L是当前扰动图像的输出特征。上述两个损失的组合如公式(7)所示,其中λ表示特征干扰损失的加权系数。

我们可视化了第7层在不同时间步长的输出特征。如图7所示,当时间步长增加时,更多的噪声被添加到潜伏期,并且对输入图像的高频分量的响应逐渐降低。因此,利用特征干扰损失作为小时间间隔对抗性噪声的优化目标,是保持对抗性噪声干扰高频信息有效性的较好选择。第3.4节中提到的自适应贪婪时间间隔选择正是帮助我们实现这一点的。

图7.不同时间步长上的扩散特性当噪声调度器的时间步长增加时,部分高频信息丢失,这不利于我们的防御,因为添加了高频对抗性噪声。这意味着选择适当的时序也有利于特征干扰损失
四. Experiments
人脸质量指标我们从定性和定量两个角度评估保护用户形象的有效性。我们希望达到的理想效果是在不影响输入图像质量和误导扩散模型的情况下添加一个小的扰动,这样就不会提取输入图像的身份信息,干扰图像的生成。因此,列出的评价指标主要分为两个方面,一是用来衡量生成图像的人脸质量,二是用来测试与输入图像的身份相似性。
我们利用人脸检测器RetinaFace[5]来检测图像中是否有人脸,并使用人脸检测失败率(FDFR)来评估生成的人脸受到的干扰程度。在检测到人脸后,我们使用ArcFace[4]对其进行编码,并计算噪声图像和干净输入之间的余弦相似度,该相似度衡量了生成图像中检测到的人脸与用户的身份相似度。该矩阵被定义为身份得分匹配(ISM)。此外,通过BRISQE[21]对图像质量进行量化,并通过SER-FIQ[30]来测量检测到的面部图像的质量。
4.2. Comparison with Baseline Methods
4.2.1 Quantitative Results
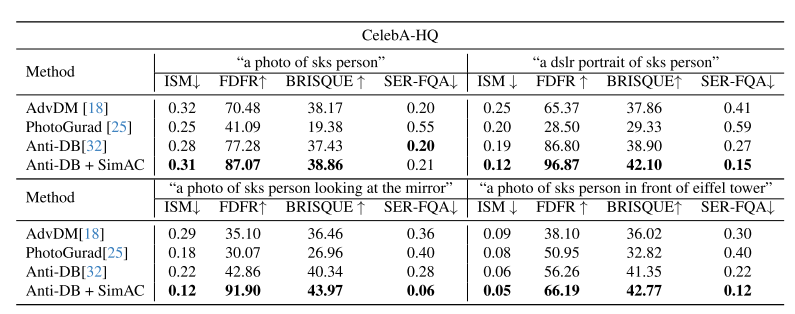
表1.在CelebA-HQ数据集上与其他开源反定制方法的比较。在定制过程中,我们评估了四种不同提示下的性能,其中ISM和SER-FQA越低越好,FDFR和BRISQUE越高越好。

表2.在VGG-Face2数据集上与其他开源反定制方法的比较。我们评估了定制过程中四种不同提示下的性能,SIMAC+anti-customization的性能优于其他基线,其中ISM和SER-FIQ越低越好,FDFR和BRISQUE越高越好。
为了测试我们的方法在增强用户肖像图像保护方面的有效性,我们在表1和表2中的三个提示下进行了定量比较。为了更实用,我们列出了四个文本提示进行推理,第一个提示与培训中使用的提示相同,另外三个提示是以前没有见过的提示。对于每个提示,我们随机选择30个生成的图像来计算每个指标,并报告它们的平均值。
我们可以发现,我们的方法大大提高了anti-customization性能,并在所有提示下都优于其他基线。由于我们分析了扩散模型在去噪和有效加入高频噪声时的独特性质,人脸检测的失败率大大增加,被检测人脸与输入图像之间的身份匹配分数是所有方法中最低的。这意味着我们的方法在抵抗像DreamBooth这样的定制滥用方面更有效。
4.2.2 Qualitative Results
我们在图8和图9中展示了一些结果。显然,SIMAC与anti-customization结合实现了强大的图像干扰效果,为输入肖像提供了最佳的隐私保护。

图8.四个提示下的量化结果。第一行是《SKS人的照片》,第二行是《SKS人的单反肖像》,第三行是《SKS人看镜子的照片》,最后一行是《SKS人在埃菲尔铁塔前的照片》。

图9.在VGG-Face2数据集上四个提示下的两个人的量化结果。对于每个人来说,第一行是《SKS人的照片》,第二行是《SKS人的单反肖像》,第三行是《SKS人看镜子的照片》,最后一行是《SKS人在埃菲尔铁塔前的照片》。
由于PhotoGuard对潜在空间进行攻击,因此产生的图像往往会生成类似于目标潜在的图案。这种攻击不能有效地降低面部出现的概率,也不能提高生成的图像的质量。
AdvDM和Anti-DreamBooth都使用DM的训练损失作为优化噪声的目标,正如所看到的,产生了类似的结果。这两种方法旨在通过对抗性噪声扰乱图像中的高频成分,以制造伪像,并提高用户照片可能被滥用的门槛。虽然生成的图像质量降低,但AdvDM和Anti-DreamBooth的结果都保留了用户输入图像的许多细节。这表明一些用户的隐私被泄露了,而且对用户不友好。
根据我们的分析,这两种方法都遵循DM的训练过程,随机选择时间戳进行优化。这导致了一些噪声添加步骤的浪费,从而降低了攻击的效率和防护的有效性。我们发现了这一现象,并试图克服其弊端。如图8和图9中的最后一列所示,在相同的噪声预算下,SIMAC+anti-customization比所有其他方法实现了更好的面部隐私保护。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)