初识ConfyUI——本地生成你的第一张图片
将你的模型下载好,放入\ComfyUI\models\checkpoints,在网页端选择,并输入正反提示词,就可以开始生成你的第一张图了。在 Stable Diffusion 的世界里,图像不是直接在像素空间(我们看到的 RGB 图像)中生成的,而是在一个更抽象、更高效的。12.0 是一个偏高的值,适合要求严格遵循提示词的场景。○ 数值过低: AI 会更自由发挥,可能忽略提示词的关键内容(比如“
下载(win)
我是直接在github上面下载压缩包
作为参照,我的显卡是4060,下的是
ComfyUI_windows_portable_nvidia.7z
解压缩后目录如下
(提示词文件夹是我自己搞得)
启动
我们可以选择cpu/gpu启动
启动成功终端如下:
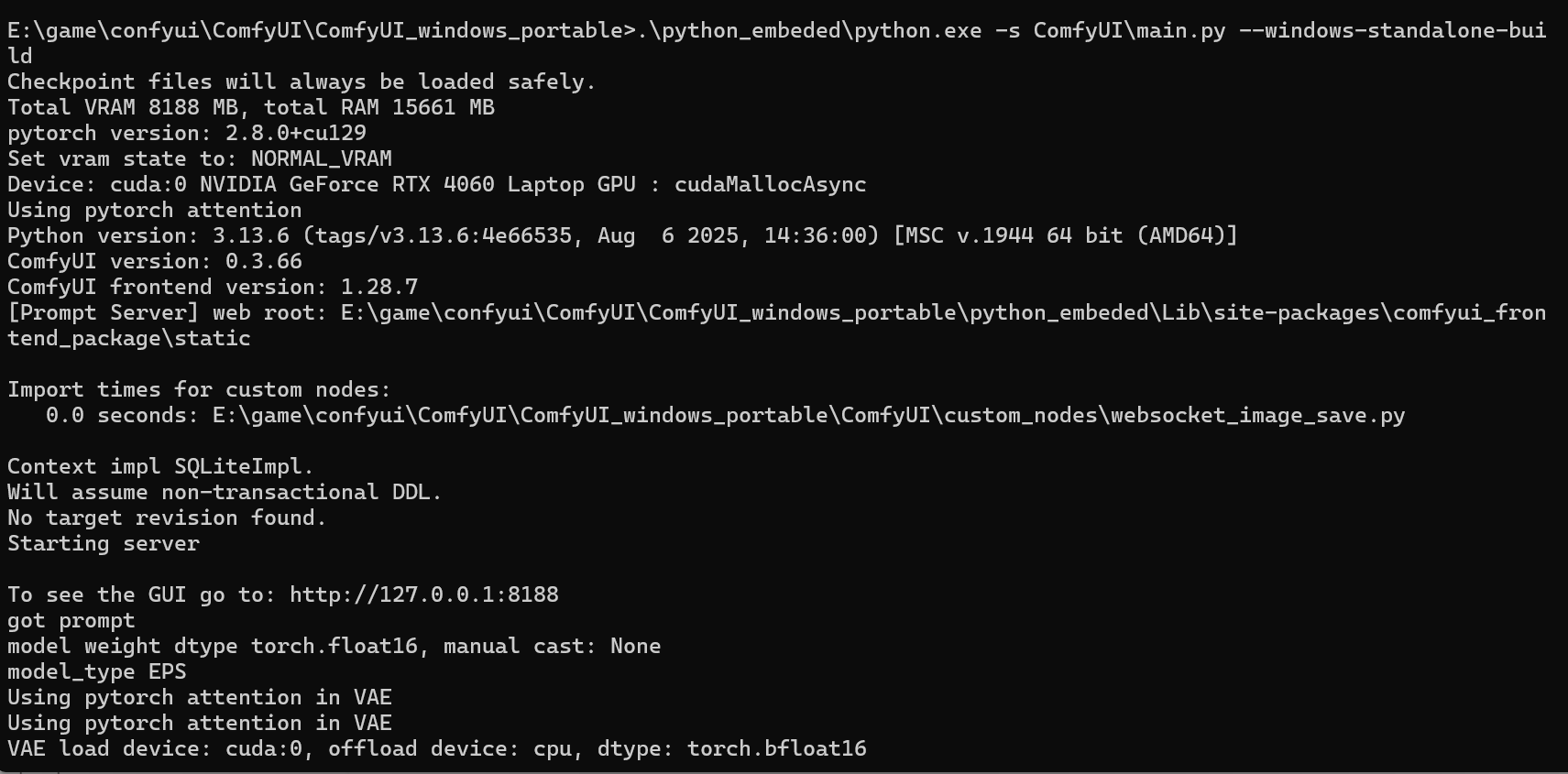
可以看到这里有一个127.0.0.1:8188,如果没有自动跳转的话浏览器访问即可
看看他默认的框架:
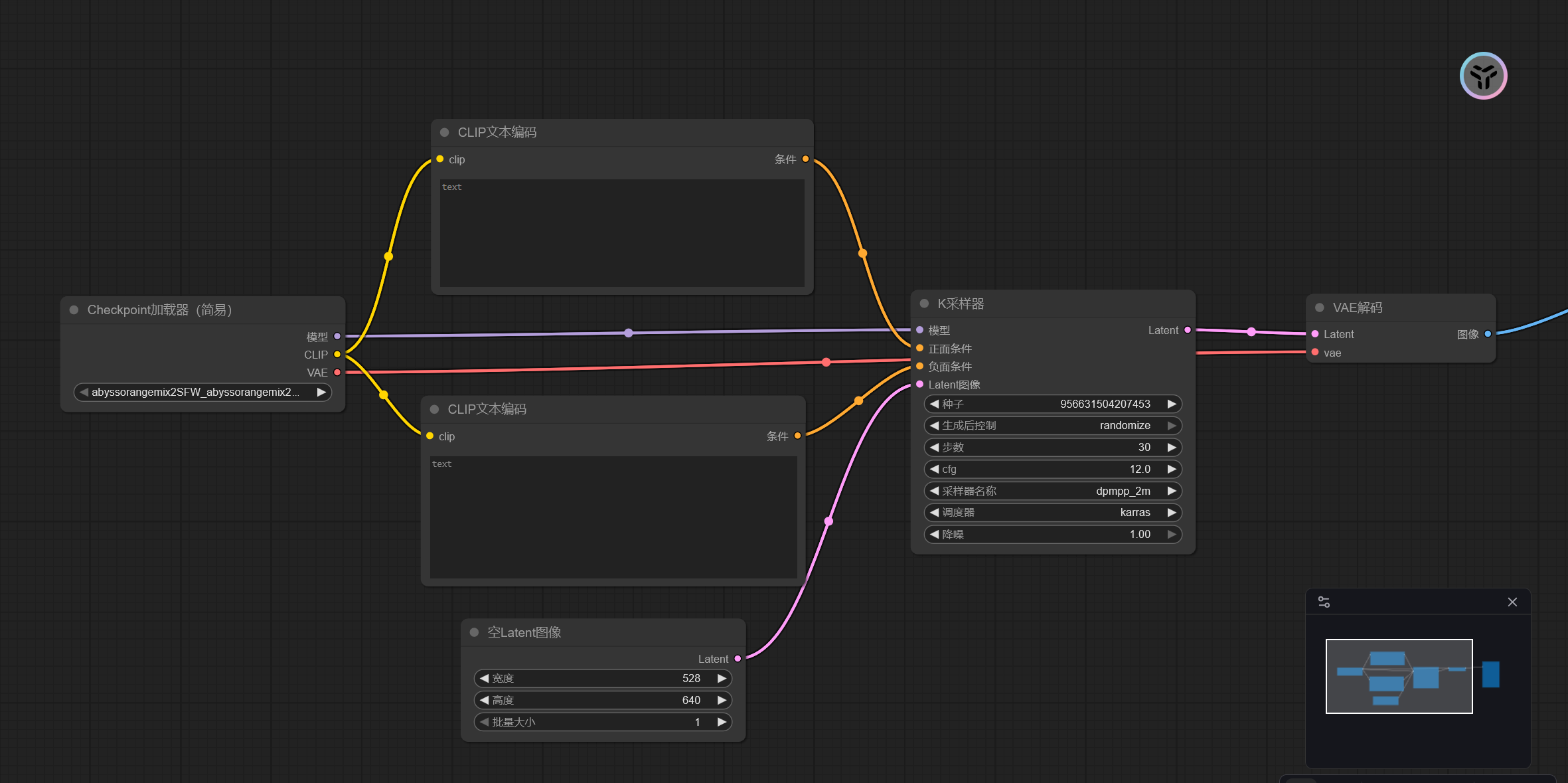
这里看看分别是什么功能
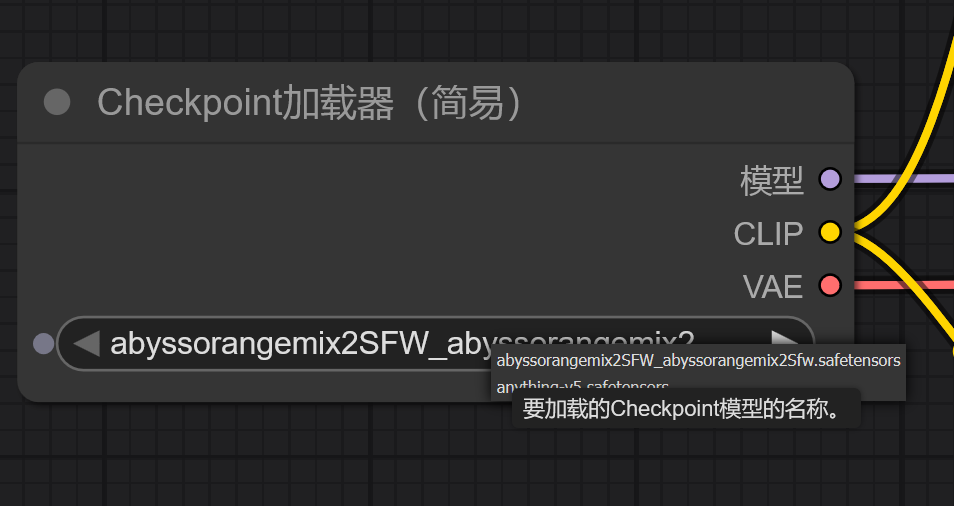
这个就是选择我们用什么图片生成的ai
这个model存放路径如下(根据项目根目录推算):
\ComfyUI\models\checkpoints
可以选择用哪个模型
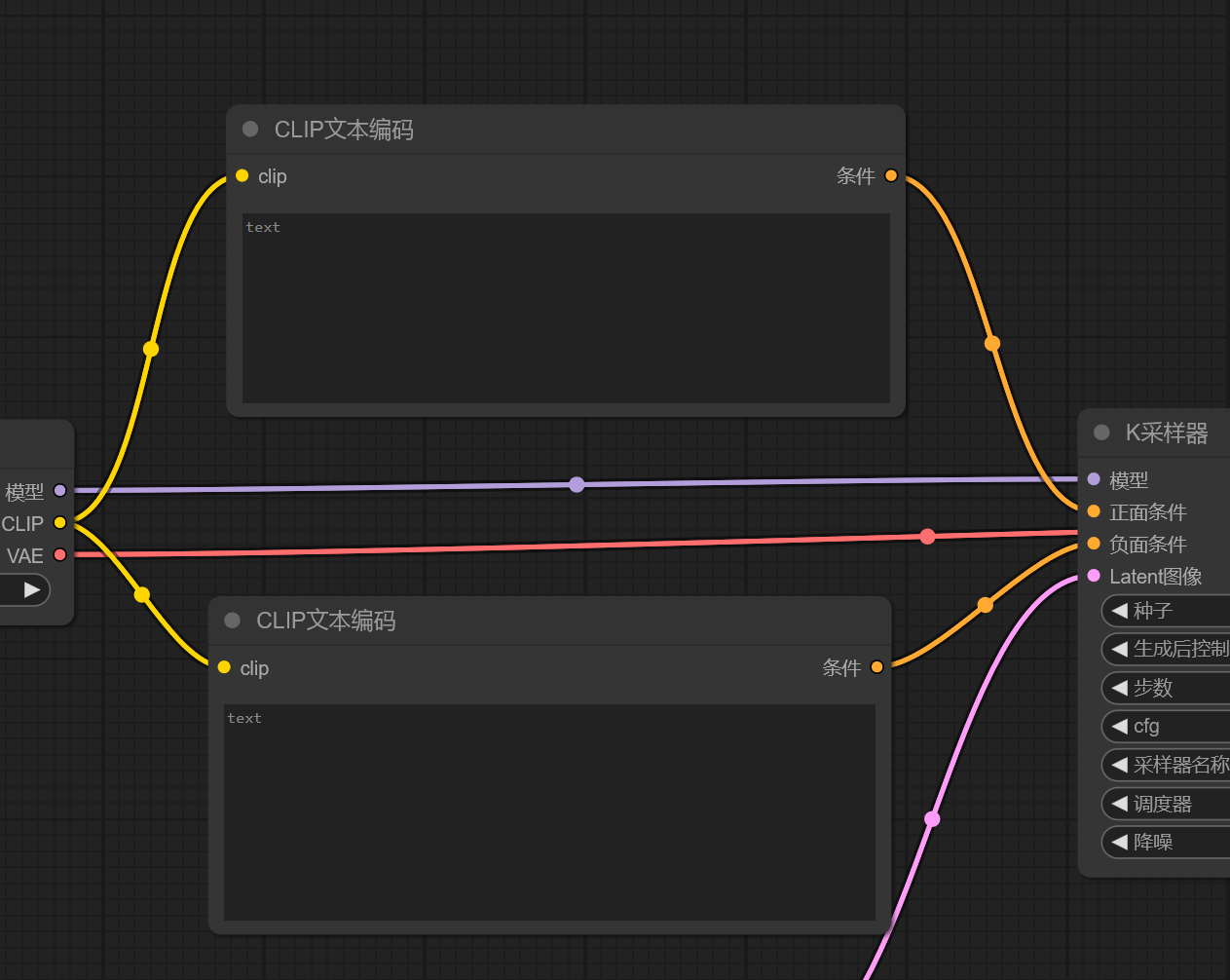
上面的框是正面条件,下面是负面,就字面意思
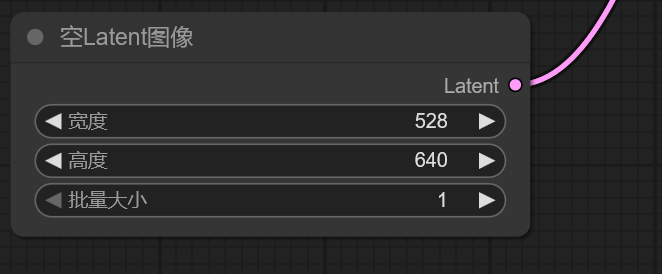
初始图像的宽高,张数
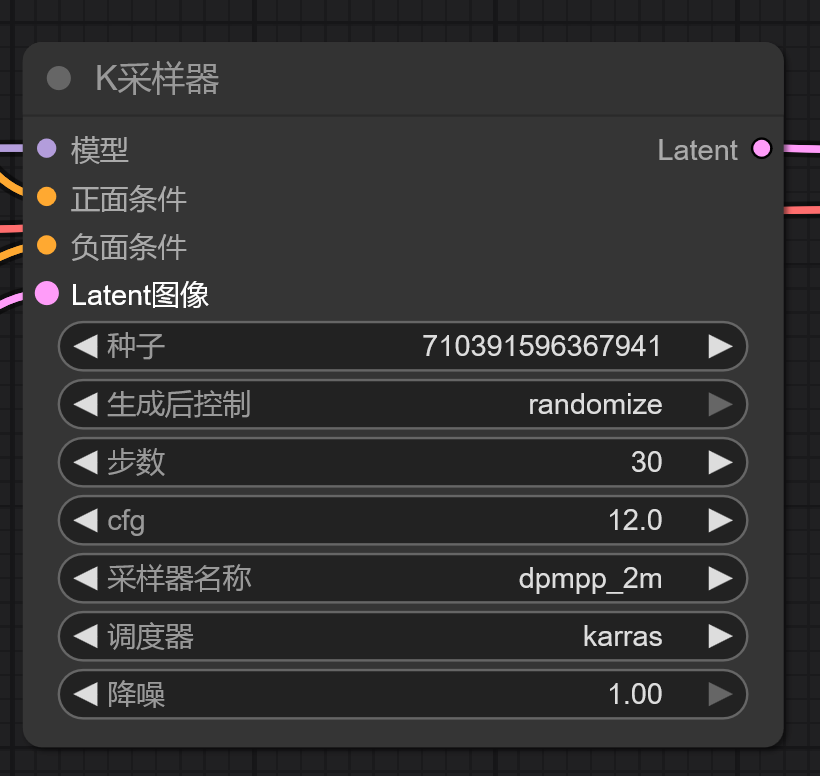
采样器
种子 (Seed)
● 功能: 这是一个随机数种子,用于控制生成过程中的随机性。
设置为 randomize 或更改数字,每次运行都会得到不同的画面
步数 (Steps)
指的是去噪算法执行的迭代次数。
cfg (Classifier-Free Guidance Scale)
功能: 这是最重要的参数之一,称为“无分类器引导尺度”。它决定了 AI 在多大程度上遵循您的提示词。
● 作用:
○ 数值越高: AI 越严格地按照提示词生成,但可能导致画面生硬、色彩失真或过度锐化。
○ 数值过低: AI 会更自由发挥,可能忽略提示词的关键内容(比如“泳装”)。
○ 常用范围: 7.0 - 13.0。12.0 是一个偏高的值,适合要求严格遵循提示词的场景。
采样器名称 (Sampler Name)
● 当前值: dpmpp_2m
● 功能: 指定使用的去噪算法。不同的采样器在速度、质量和稳定性上有差异。
● 常见采样器对比:
euler 速度快,质量尚可 快速预览
heun 比 Euler 更稳定 平衡速度与质量
dpmpp_2m 高质量、稳定、推荐 主流首选
ddim 速度快,但细节可能不足 需要快速出图
lms 较老的算法,现在较少使用 兼容性测试
调度器 (Scheduler)
● 当前值: karras
● 功能: 决定在每一步去噪过程中,如何调整噪声的强度。它影响图像的锐度、对比度和整体质感。
● 常见调度器对比:
normal 标准调度,效果均衡 通用
karras 增强细节和锐度,推荐 提升画面质感
exponential 前期降噪快,后期慢 特殊艺术风格
polyexponential 多项式变化,比较实验性 尝试新效果
降噪 (Denoise)
● 当前值: 1.00
● 功能: 这个参数主要用于“图生图”(img2img)或“局部重绘”(inpainting)场景。
● 作用:
○ 1.00: 完全从头开始生成,不参考任何现有图像。
○ 0.50: 只改变原始图像的 50%。
○ 0.00: 完全不改变原始图像。
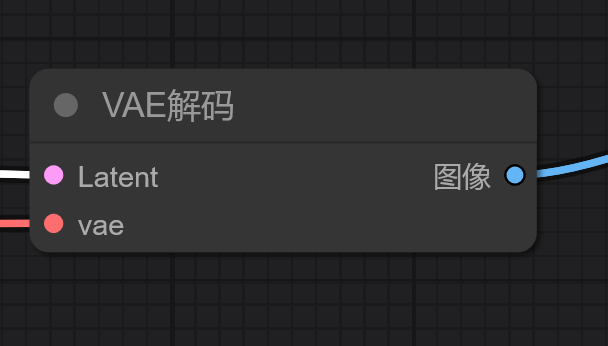
在 Stable Diffusion 的世界里,图像不是直接在像素空间(我们看到的 RGB 图像)中生成的,而是在一个更抽象、更高效的潜空间 (Latent Space) 中进行计算和去噪。
K采样器生成的是一个潜变量 (Latent),它是一个压缩后的、数学化的数据表示。VAE解码的作用就是将这个潜变量,通过一个名为 VAE (Variational Autoencoder, 变分自编码器) 的模型,解码还原成我们肉眼可见的、完整的像素图像。
生图
将你的模型下载好,放入\ComfyUI\models\checkpoints,在网页端选择,并输入正反提示词,就可以开始生成你的第一张图了
保存
保存模型为json文件,相对路径:
\ComfyUI\user\default\workflows\try_1.json
然后生成的图片就在\ComfyUI/output里
然后可以通过社区选择自己要用什么model

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)