又被小红书判违规了?我用影刀RPA扒光了它的规则库喂给AI当“审核专家” ,再也不担心限流&被同行举报了 | 影刀RPA
最大的安全感,来自你对“规则”的极限掌握。再也不担心因小红书内容违规被隐形限流、同行举报、平台巡检判罚甚至封号了 | 影刀RPA手机懒加载实操
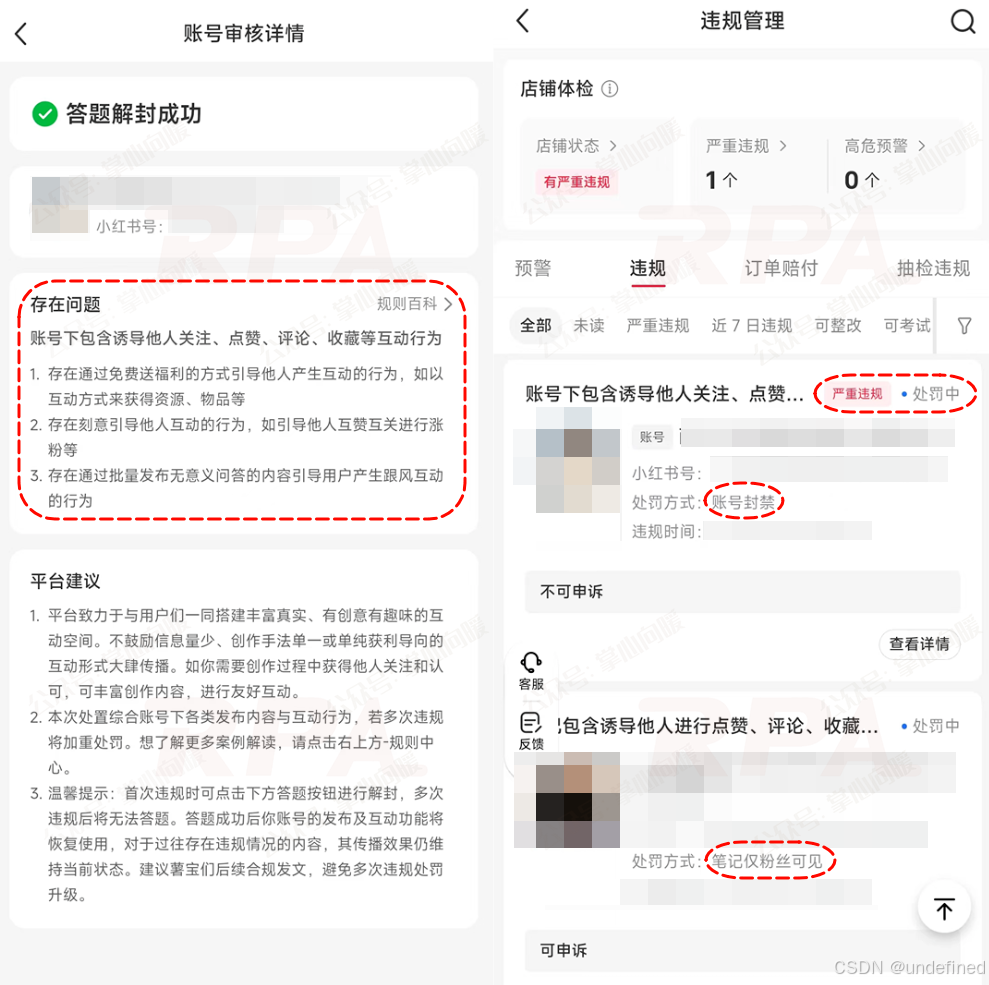
辛苦写的小红书笔记发出后数据惨淡,不知道是内容不行,还是被“隐形限流”了
好不容易火了一篇,转眼又被同行举报违规
平台的内容巡检持续在线,哪天一觉醒来,轻则删帖,重则封号
收到“涉嫌XXX”的通知,却没人告诉你到底哪句话触雷
……
很多人还在靠"经验"发小红书笔记,但经验在算法面前其实挺脆弱。有时候根本不是内容不好,而是你踩了平台规则的“雷区”。
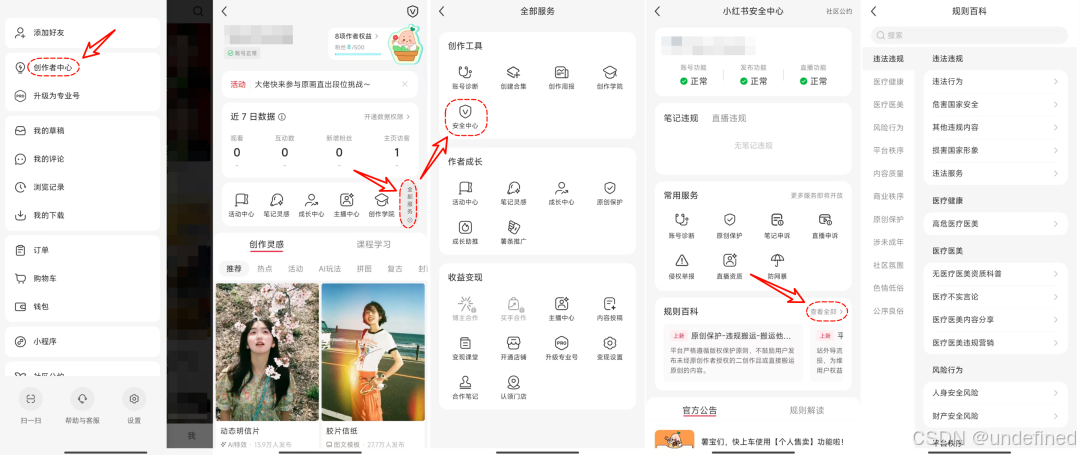
小红书官方的规则其实摆得很明白(*查看路径:创作者中心 → 全部服务 → 安全中心 → 规则百科),可问题是,你真的会一个个点开、把上百条细则背下来吗?显然不现实!
AI时代,我们完全可以用一种更“聪明”的方式来实现“内容合规审查”,比如:用影刀RPA把平台所有内容规则一条不漏地扒下来,形成一个知识库,然后投喂给AI大模型,训练出一个“小红书内容合规审核专家” 的智能体。
这样,以后在发布笔记前直接把文案丢给它,它就会基于规则知识库和智能体设定来智能判断:哪些词敏感,哪些容易被限流,哪些表达不合规并提供修改建议。

这是一个涉及“嵌套循环 + 手机懒加载处理”的自动化实战案例,真正难的不是“能不能抓到”,而是怎么在不断加载新内容的同时,不重、不漏、不断线。
一、开发思路
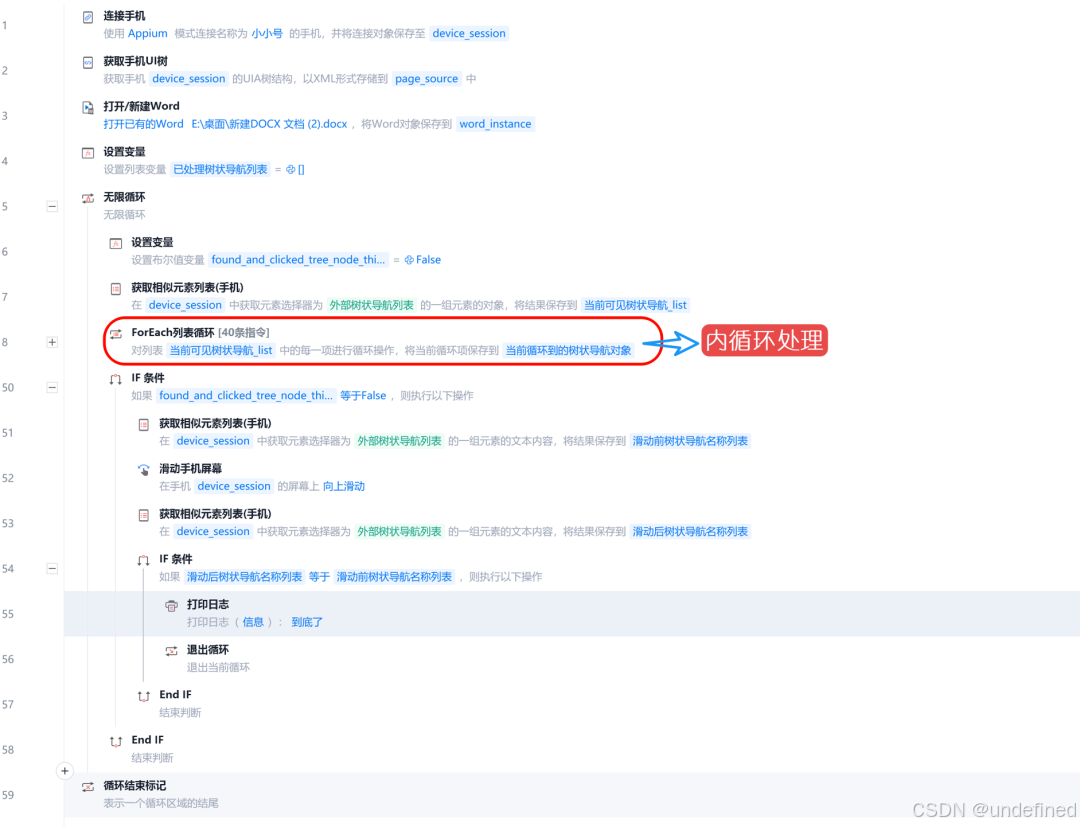
打开小红书App的“规则百科”页面,我们会发现,这是一个典型的“双重嵌套循环”结构 :
1. 外层循环
页面左侧是“违法违规”、“医疗健康”、“商业秩序”等大类,右侧是对应大类下的子规则项,比如“行业不规范”、“虚假营销”等等。

2. 内层循环
当你点击任何一个子规则(比如“虚假种草行为”),进入详情页后,会发现顶部还可能存在多个标签页,比如“招募虚假体验写手”、“发布虚假种草体验”。

对应的,我们的RPA流程设计是:依次遍历右侧规则列表 → 进入每个规则项详情页→ 遍历循环顶部所有Tab标签页,提取文本&写入Word → 返回上一层,继续下一项…直到把所有类目、所有子规则、所有Tab页的内容全部采集完毕。
二、关键流程指令
整个流程的核心逻辑,是一个“外循环(规则分类遍历)、内循环(标签页采集)、懒加载控制(动态内容加载检测)”的多层自动化结构。
1. 外循环
2. 内循环(Tab)
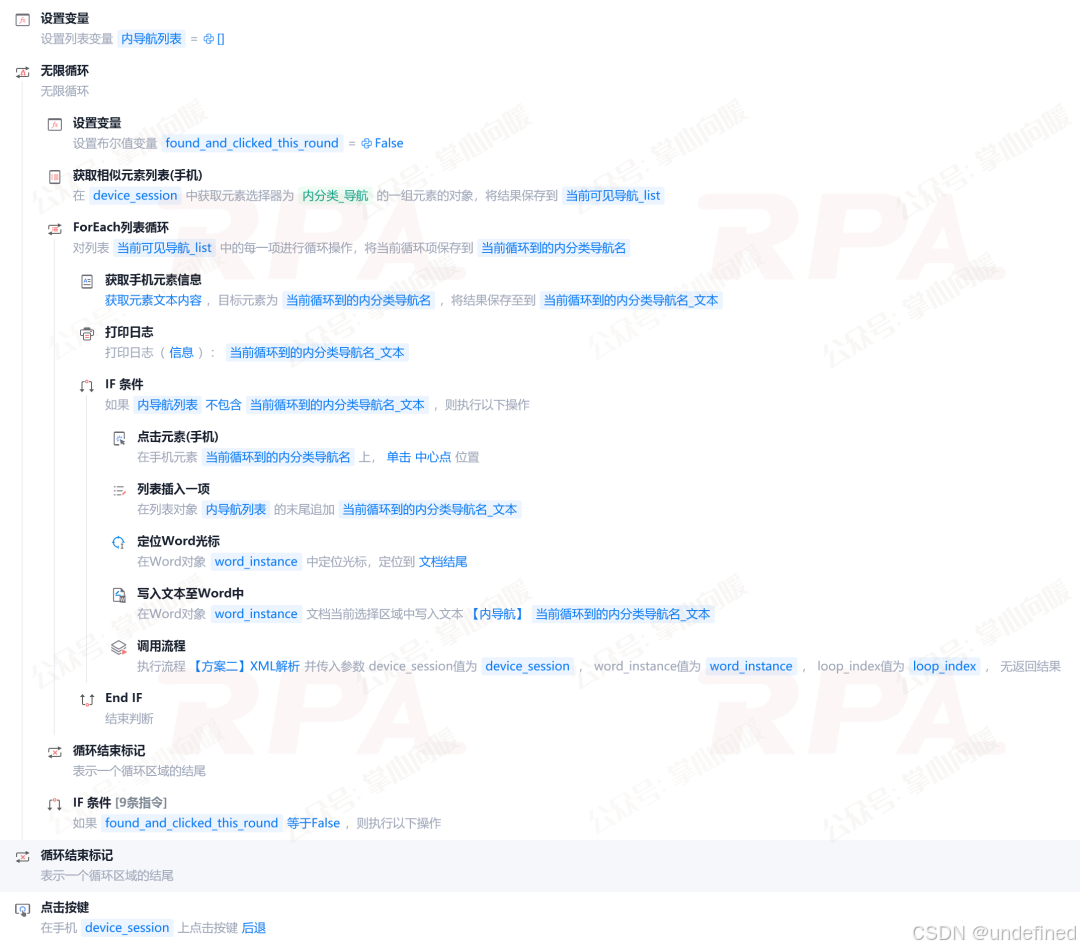
3. 内循环(详情页)
小红书的规则页面是手机端懒加载结构,即需要不断下拉才能加载出完整内容。这里提供两种实现思路参考:
- 方案01:基于文本内容的去重与判断。每次滚动都抓相似元素(文本),并根据页面模块分区和文本内容做判断、写入。
- 方案02:基于UI树结构的去重与判断。每次滚动获取一次UI树(XML源码),拼接所有滚动结果形成完整结构,然后通过resource_id + index值逐级解析与写入。下图为"方案02"指令流程。
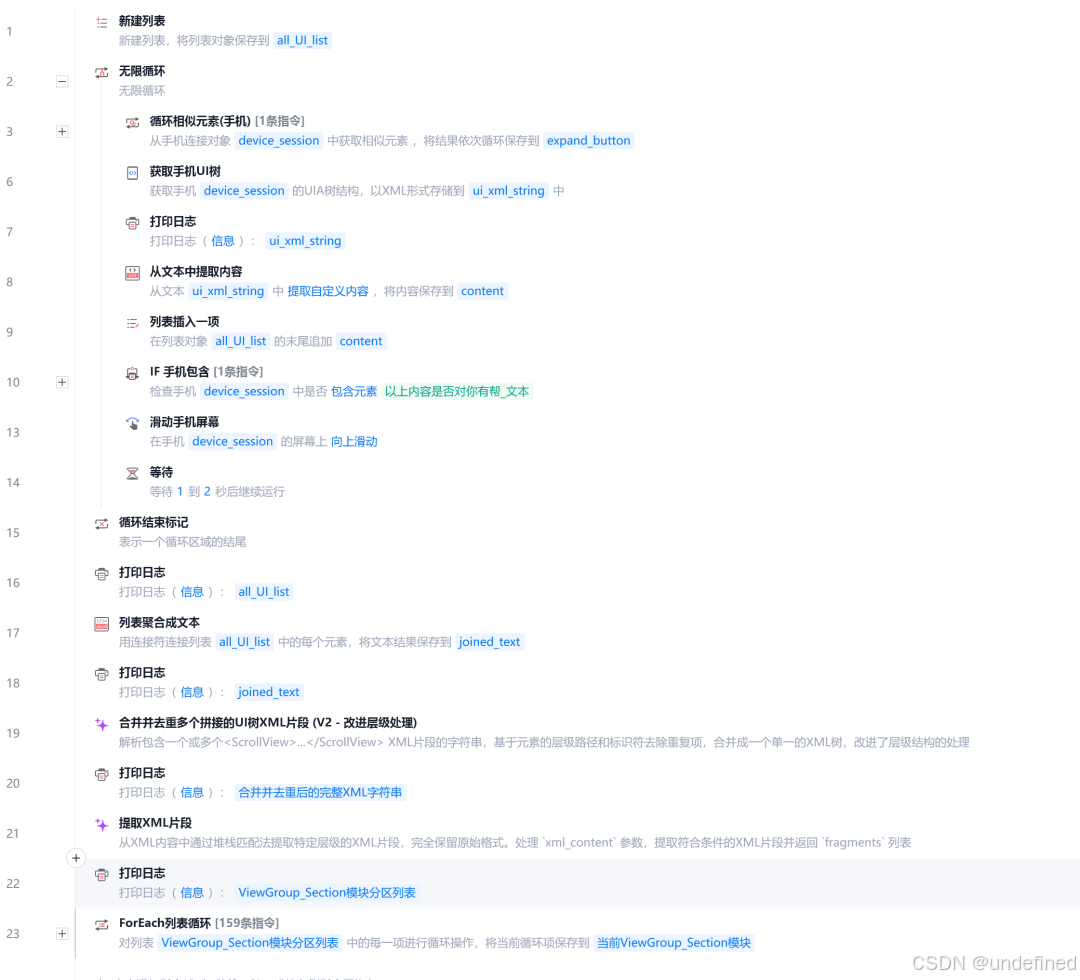
三、效果演示
连接手机,直接启动运行,无需配置参数
(*视频审核没通过……)
四、如何获取&使用?
1. 环境/工具配置
- 需要影刀RPA账号:https://www.yingdao.com
- 手机自动化环境安装配置:https://www.yingdao.com/yddoc/rpa/zh-CN/816951335441428480
2. 注意事项
- 运行过程中,电脑可以干别的,手机不要动
- 运行前,确保手机停留在小红书规则百科界面
3. 获取应用
这个案例非常有代表性,它覆盖了RPA开发中最常见、也是最容易出问题的逻辑模块:嵌套循环、懒加载页面解析、UI树节点判断、动态文本提取与数据去重。如果你正在学RPA,可以按照上面分享的思路,自己动手搭一次。
当然,如果你只是想直接使用,我也准备了两种方式:智能体版和应用迁移版.
不懂规则就像开车不看红绿灯,见过太多小红书号“死”在内容违规上。你发文前用它检测一次,可能就救下一个号!
除了小红书,你还被哪个平台的“规则黑盒”困扰过?欢迎在评论区留言,或许你的痛点,就是我开发的下一个自动化应用。以上。下期分享见!

-END-
- 爱练字的96年ISTJ型互联网人/信息整合怪/工具人/影刀高级认证工程师。
- 专注分享:RPA&AI自动化场景提效方案、效率软件安利、实用技能。"所有的生产要素都可以被构建,只有认知是壁垒",欢迎関注
推荐阅读:
- 影刀RPA | 小红书笔记“图片/视频“无水印轻松下载本地
- 那些拥有上千浏览器书签/收藏夹的电脑用户,是怎么管理书签的?
- 不会编程的我开发了一款近900行指令的自动化RPA应用,完美解决98%以上复制受限的飞书文档!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)