英伟达GPU服务器训练前环境sop检查
摘要:本文详细介绍了N卡GPU服务器在AI模型训练前的系统性环境检查SOP,涵盖硬件状态、驱动与CUDA环境、深度学习框架依赖及性能基准测试等关键环节。重点包括:1)通过nvidia-smi检查GPU状态、拓扑和NVLINK连接;2)确认IB网卡名称与状态,确保NUMA平衡;3)设置GPU主频和CPU性能模式;4)验证RDMA网络性能;5)使用nccl-tests进行多机通信测试。通过这套标准化检
摘要:在使用N卡GPU进行AI模型训练任务之前,对GPU服务器进行系统性的环境检查,是确保训练过程稳定、高效和可复现的关键第一步。这并非简单的“能开机就行”,而是一套需要严谨执行的标准化操作程序(SOP)。本文从硬件状态(包括GPU型号、数量、温度及功耗健康状况)、驱动与CUDA环境(验证驱动版本、CUDA Toolkit及cuDNN的兼容性与正确安装)、深度学习框架与依赖(如PyTorch或TensorFlow是否与CUDA版本匹配)以及性能基准测试(通过nccl-tests等工具验证多卡通信,并使用简单的矩阵运算检验计算性能)等环节详细阐述这套训练前的环境检查SOP,旨在帮助开发者和运维人员规避常见的“坑”,将因环境问题导致的训练中断、性能损失或结果异常风险降至最低。
一、基础配置检查
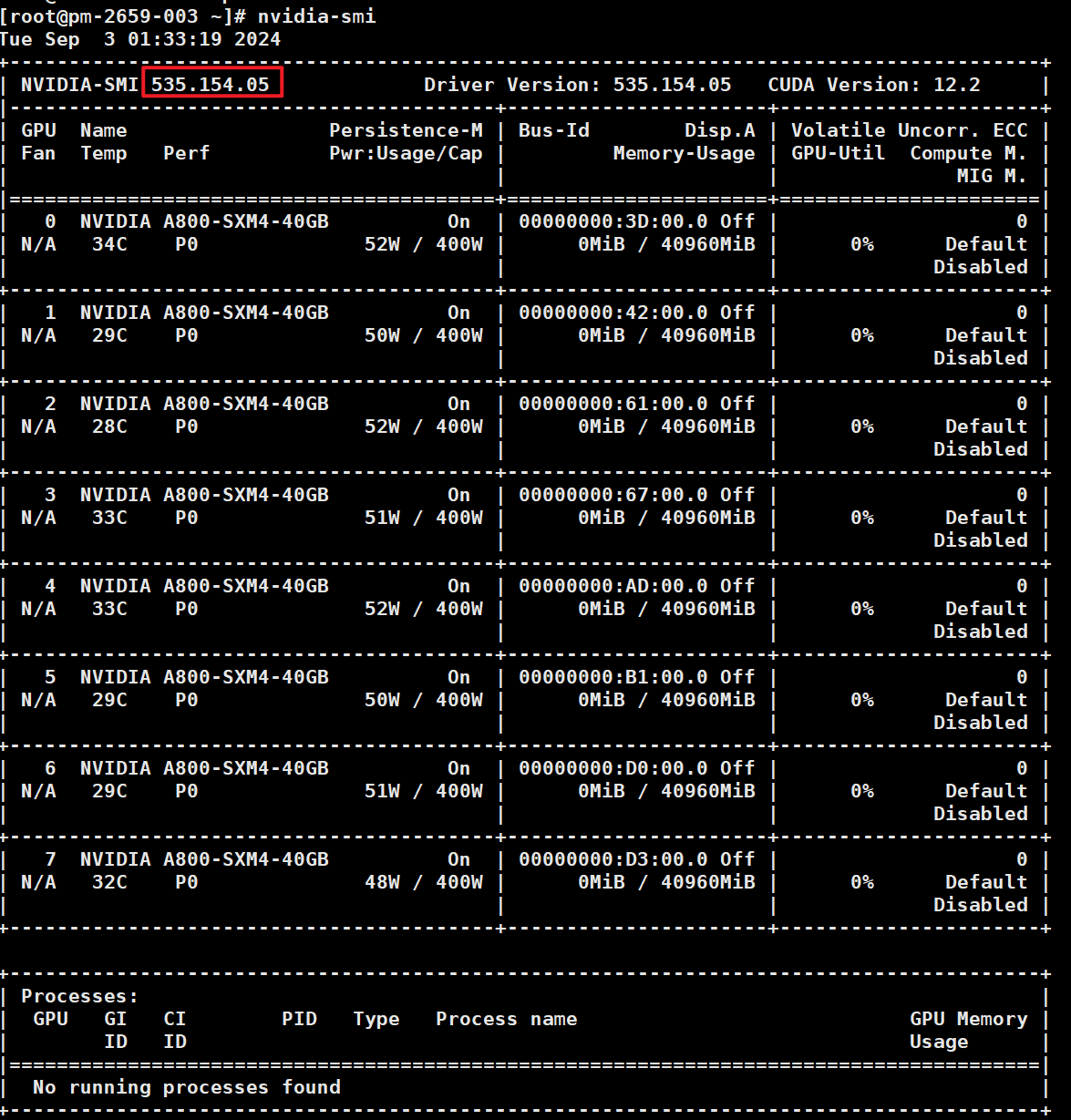
1.查看驱动版本和GPU卡在位情况
nvidia-smi
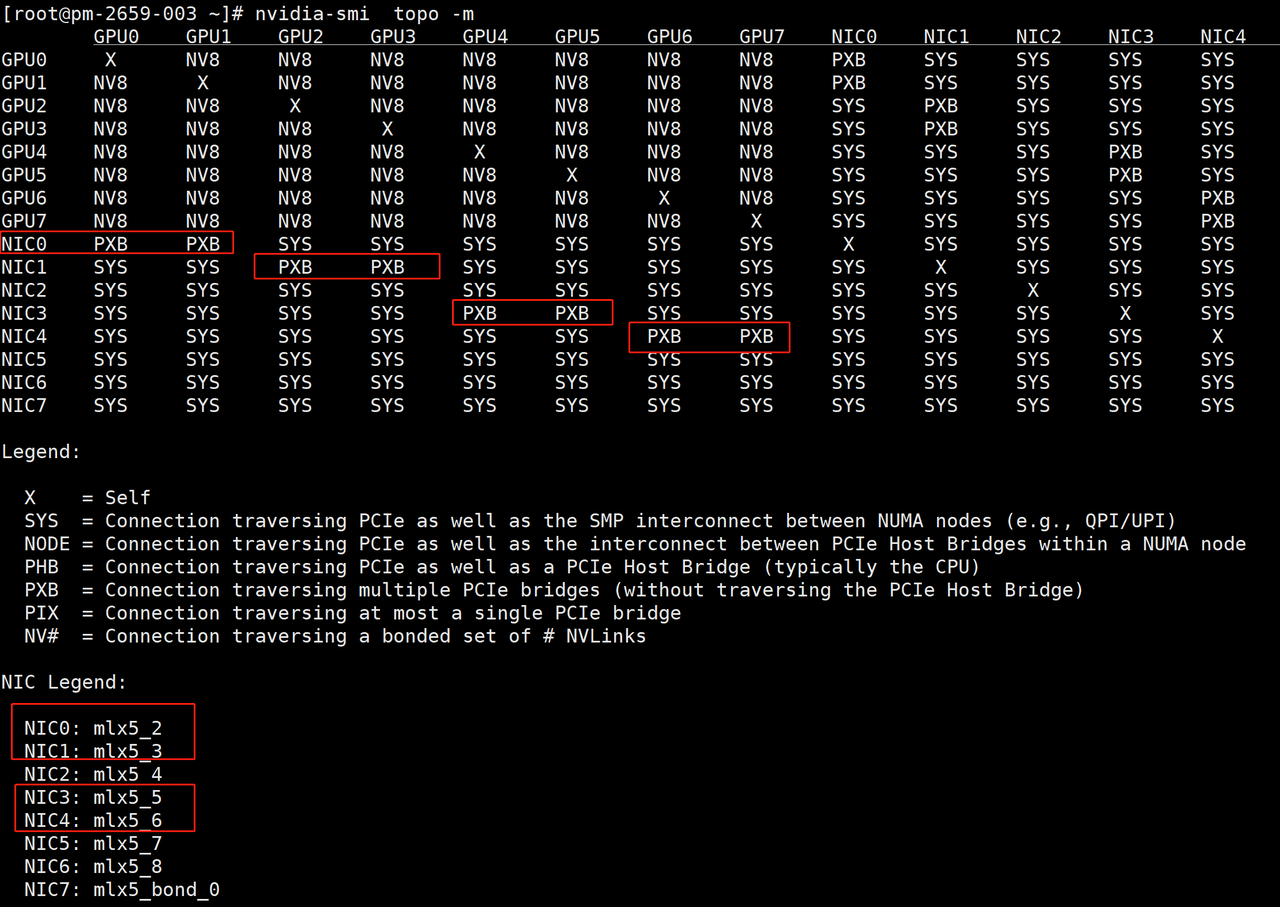
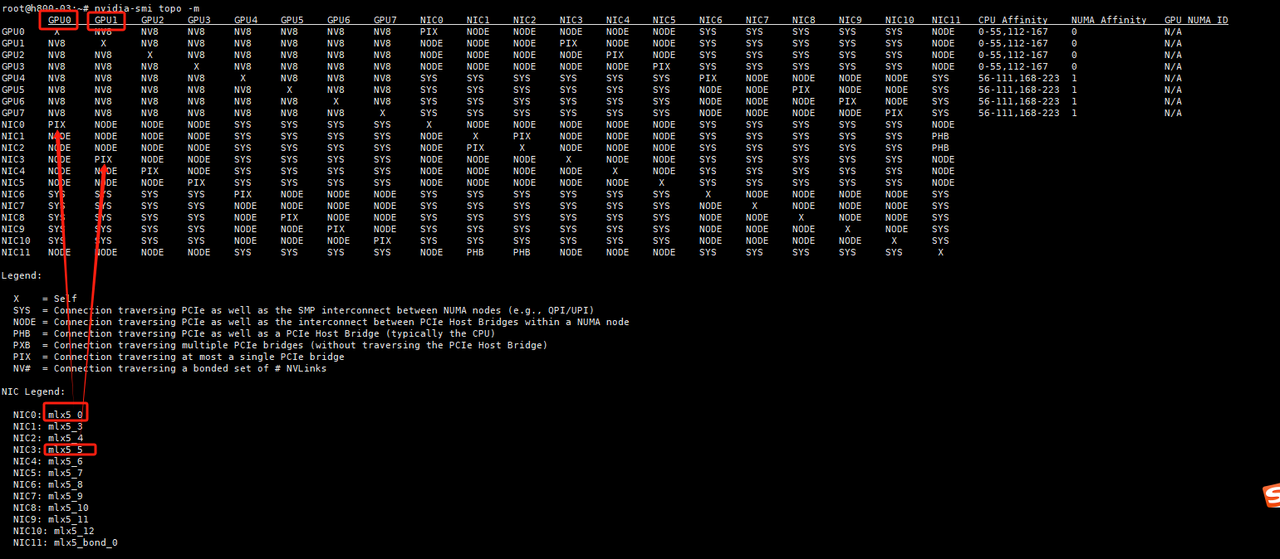
2.查看GPU拓扑、确认IB网卡名
nvidia-smi topo -m
-
节点内通信:如果是NVLINK版本的GPU服务器,拓扑输出可以看到GPU之间通过NV#连接,例如NV8代表单节点内卡间通过8根NVLINK相连,单根NVLINK的单向带宽为25GB/s(双向50GB/s),所以卡间NVLINK通信带宽理论单向200GB/s(双向400GB/s);
-
节点间通信:确保每张GPU均有对应IB网卡与其通过PXB或者PIX连接。
上图中mlx5_2、mlx5_3、mlx5_5、mlx5_6为计算用的IB网卡,需要确保所有待测机器的IB网卡名称一致。(遇到过H800 PCIe版本的服务器仅根据拓扑无法确认IB网卡名称,可进一步结合1.2.2的方法进行交叉验证)
2.2.1确认IB网卡名称
查询所有IB网卡名
mst status -v |grep ib
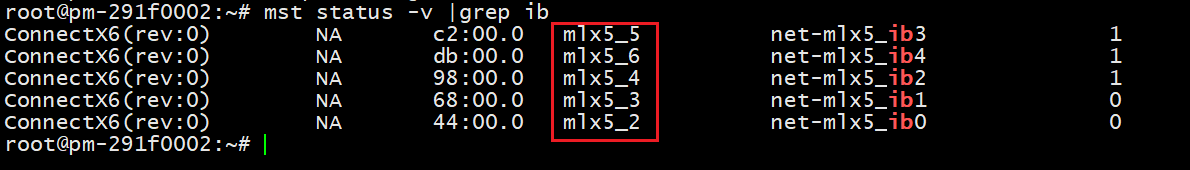
上述mst命令输出机器上所有IB网卡名称,包括用于存储的IB网卡以及用于计算的IB网卡,需要进一步区分计算IB网卡和存储IB网卡。
2.2.2确认存储IB网卡
ip a |grep 100.9 #本项目中高性能存储网络为100.9网段
用ip a命令找到100.9x开头的对应网卡,然后结合mst status -v命令的输出可以确定存储IB卡,如下图:
100.9x开头的对应网卡名为mlx5_ib2,对应的IB网卡名为mlx5_4,因此:
存储IB网卡:mlx5_4
计算IB网卡:mlx5_2、mlx5_3、mlx5_5、mlx5_6
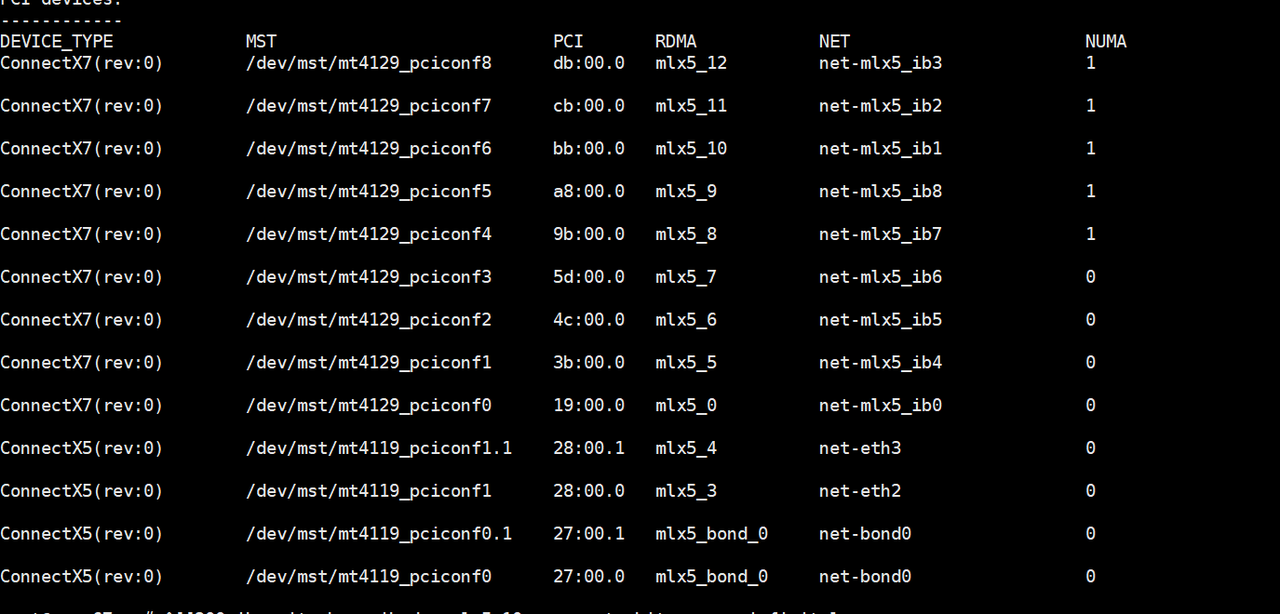
2.2.3检查NUMA情况
确保IB网卡NUMA平衡
mst stasus -v
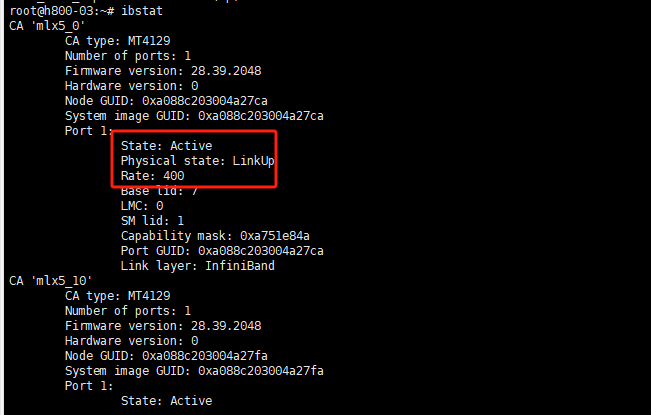
2.2.4 查看 IB网卡状态
state必须为active状态
ibstat
2.2.5 查看确认计算IB卡
通过status确认所有的IB卡
mst status -v |grep ib

根据2.2.1的topo状态根据NIC对应关系可以确认哪些是计算卡
3.确认机器业务面网卡名称
ip a |grep ${ip_address}
${ip_address}为机器 内网ip,需要确保所有待测机器的业务面网卡名称一致。

注意:1.2和1.3分别获取了IB网卡名称和业务面网卡名称后,需要在多机训练代码里指定机间通信相关环境变量,bond0对应业务面网卡名称,"mlx5_2,mlx5_3,mlx5_5,mlx5_6"对应IB网卡名称:
CUDA_DEVICE_MAX_CONNECTIONS=1 UCX_NET_DEVICES=bond0 GLOO_SOCKET_IFNAME=bond0 NCCL_SOCKET_IFNAME=bond0 NCCL_IB_HCA="mlx5_2,mlx5_3,mlx5_5,mlx5_6"
4.检查IB网卡状态
ibstatus
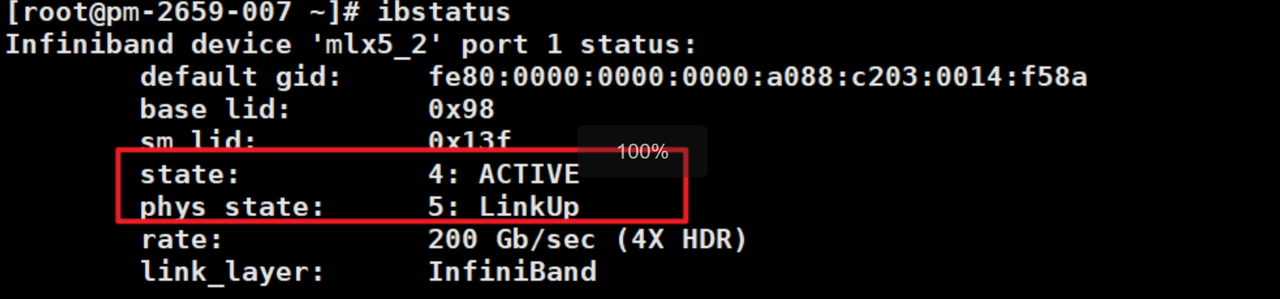
确保1.2中查询的ib网卡状态均为“ACTIVE”和"LinkUp"。
5.关闭防火墙
#centos/ctyunos关闭防火墙
systemctl stop firewalld
systemctl stop iptables #ubuntu 关闭防火墙:
systemctl stop netfilter-persistent
systemctl disable netfilter-persistent
iptables -F
ufw disable6.GPU主频
确保每块GPU卡的设置为最大,否则会出现训练性能降低。例如查看0号GPU主频:
nvidia-smi -i 0 -q
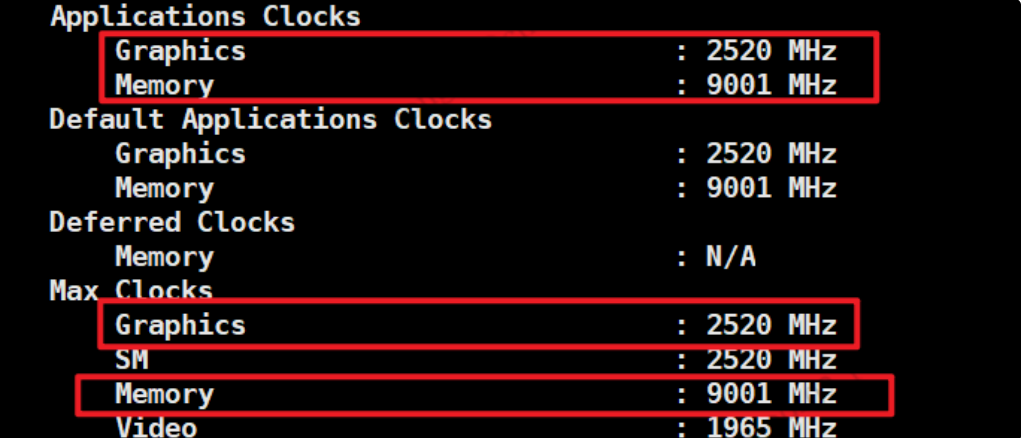
依次检查每一张GPU卡的Applications Clocks是否等于Max Clocks,如果不相等,用nvidia-smi -ac命令将Applications Clocks设置成Max Clocks,-ac参数用法如下:

设置命令如下:
nvidia-smi -ac 9001,2520
7.设置CPU为performance mode
先查看cpu当前的频率
sudo cpupower frequency-info
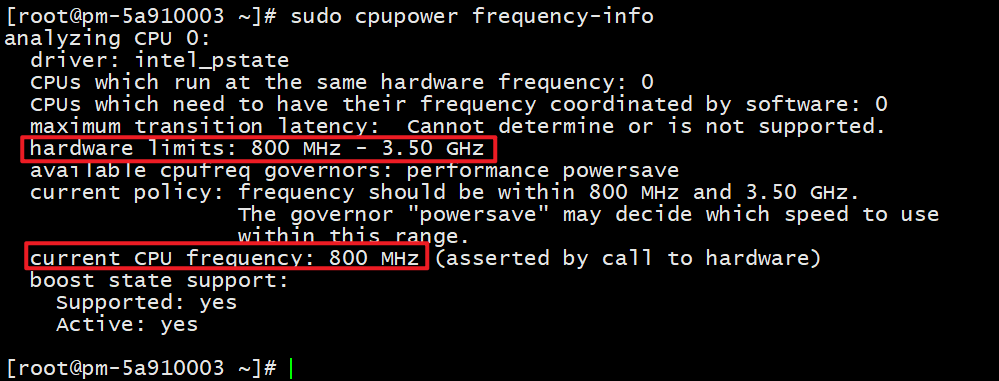
可以看到目前cpu频率为最小值。
设置cpu频率为performance模式
sudo cpupower frequency-set -g performance
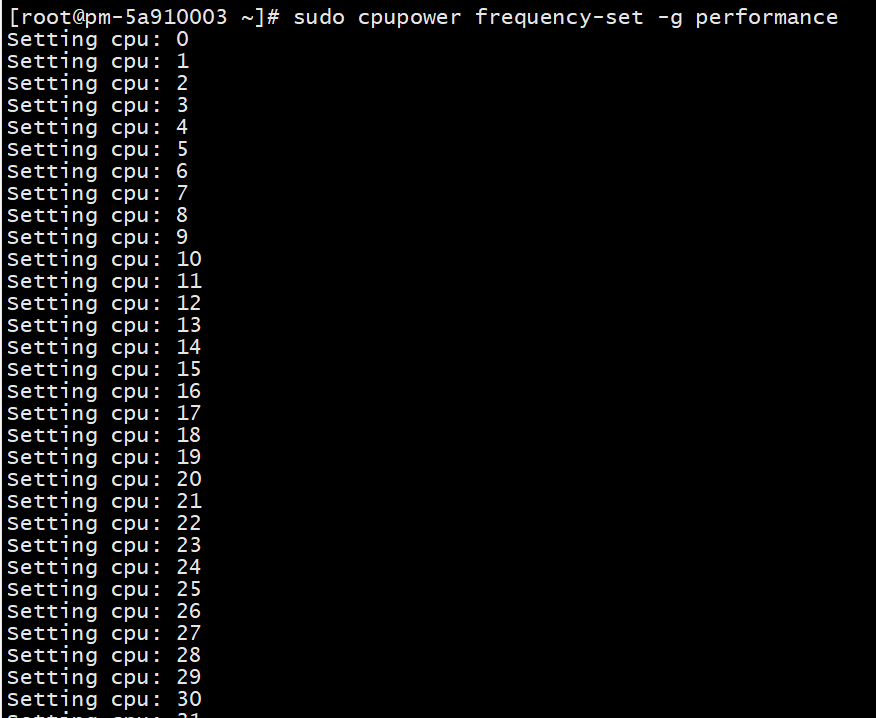
查看设置后的cpu频率
sudo cpupower frequency-info
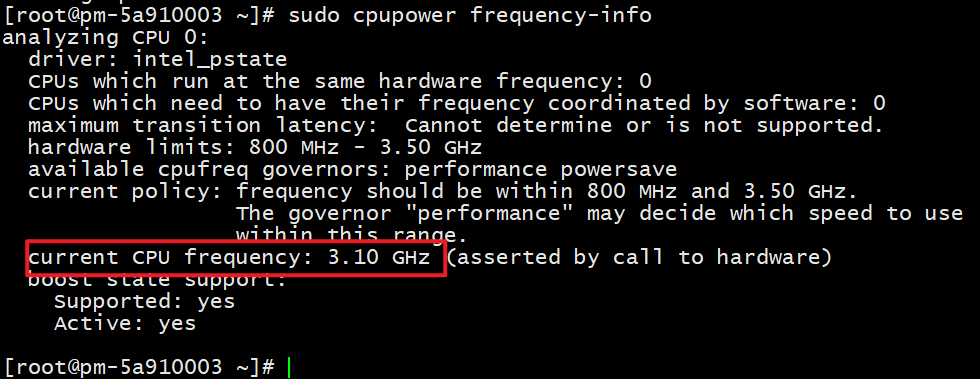
开启GPU persistant mode
nvidia-smi -pm 1
检查IB网卡驱动是否安装
ofed_info -s
检查Nvidia peer memory是否加载
lsmod |grep nvidia_peermem

二、环境依赖检查
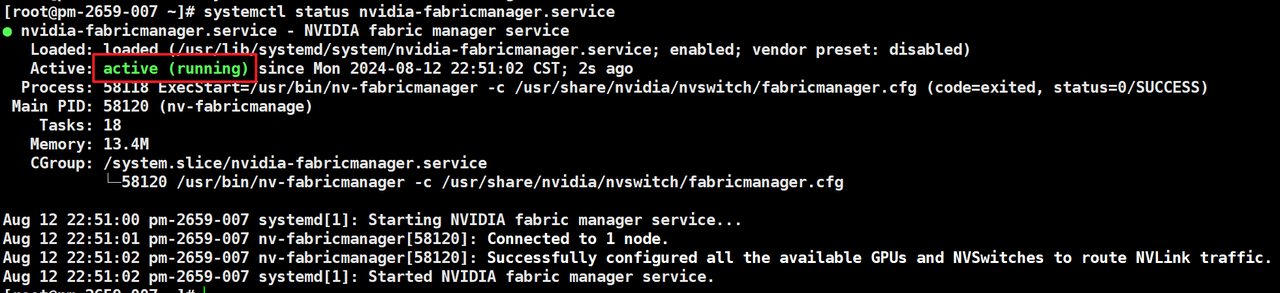
1.检查nvidia-fabricmanager服务是否启动
注:NVLINK的服务器需要安装nvidia-fabricmanager,PCIe的不需要安装。
systemctl status nvidia-fabricmanager.service
2.检查docker是否正常
docker ps
3.检查NVIDIA Container Toolkit是否安装
nvidia-ctk --version
4.检查p2p通信能力
nvidia-smi topo -p2p rawnp
5.检查RDMA网络读写速率IB基准测试服方法
主机(不指定网卡):
ib_write_bw --report_gbits从机:
ib_write_bw -a <服务器内网IP地址> --report_gbits
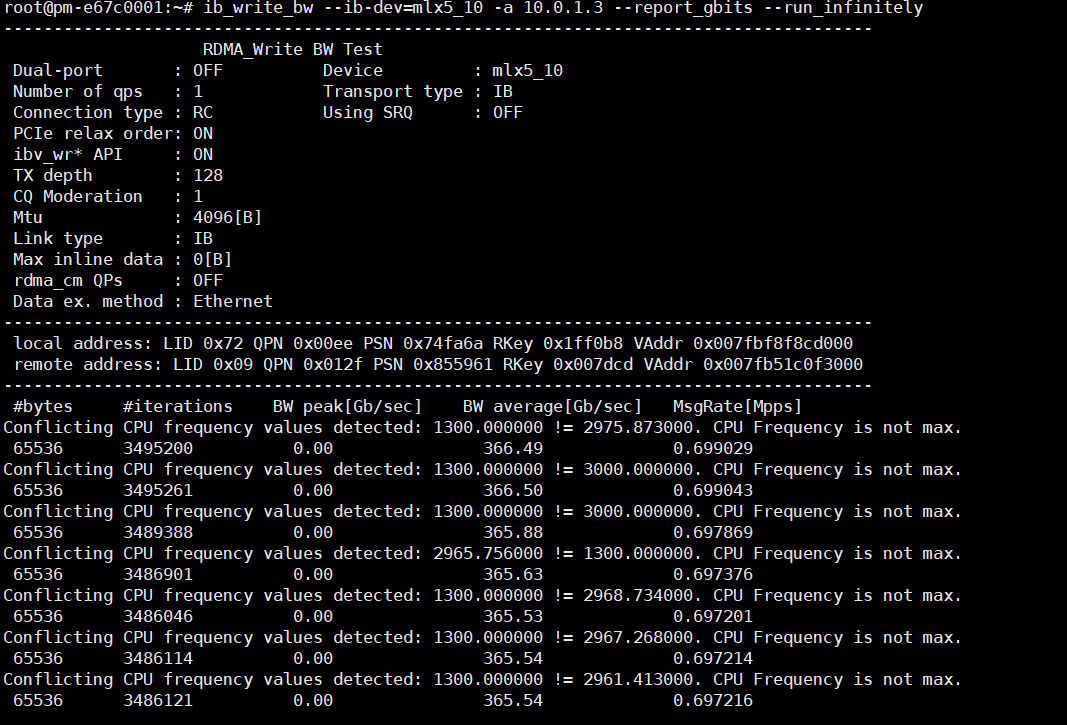
主机(指定网卡)
ib_write_bw --ib-dev=mlx5_10 --report_gbits --run_infinitely从机:
ib_write_bw --ib-dev=mlx5_10 -a <服务器内网IP地址> --report_gbits --run_infinitely
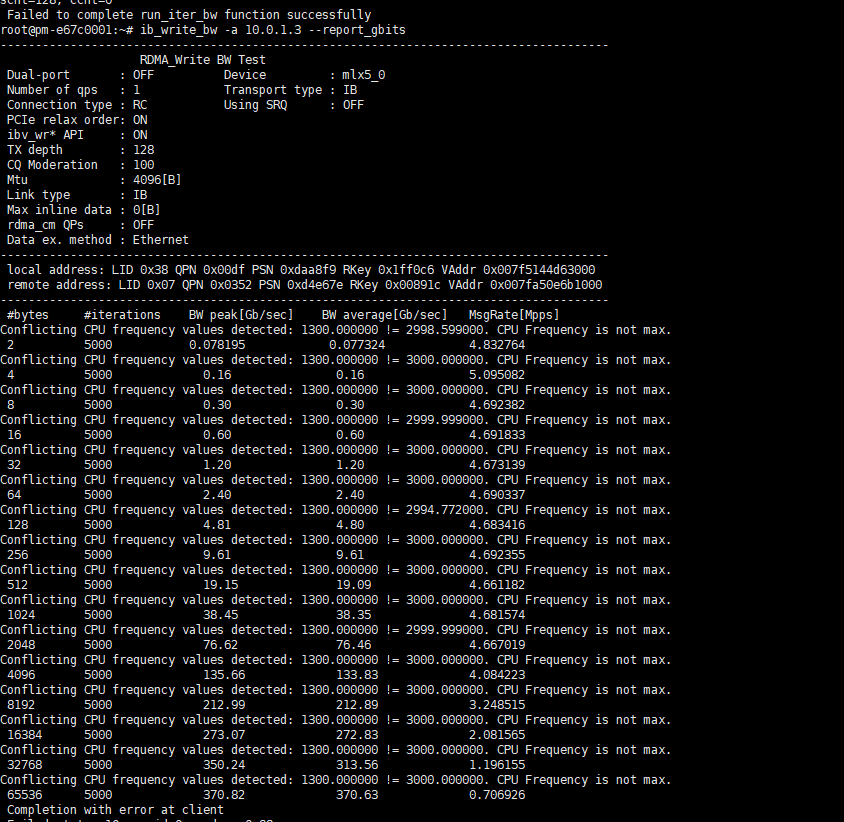
6.禁用 ACS (可选)
参考文档:
运行以下命令检查是否启用了ACS
sudo lspci -vvv | grep ACSCtl
如果输出中出现了“SrcValid+”,则启用了ACS。根据NCCL官方文档,启用ACS可能会影响GPU Direct,可用以下脚本禁用ACS:
for BDF in lspci -d "*:*:*" | awk '{print $1}'; do
skip if it doesn't support ACS
sudo setpci -v -s ${BDF} ECAP_ACS+0x6.w > /dev/null 2>&1
if [ $? -ne 0 ]; then
continue
fi
sudo setpci -v -s ${BDF} ECAP_ACS+0x6.w=0000
done三、性能基准测试
1.下载nccl-test镜像(每一台机器执行)
wget https://xinan2.zos.ctyun.cn/xinan2-cwai-img/ccl_images/nccl-test-cu12.2.2-cudnn8-devel-ubuntu20.04-nccl2.20.3-ssh.tar
2.加载镜像(每一台机器执行)
docker load -i nccl-test-cu12.2.2-cudnn8-devel-ubuntu20.04-nccl2.20.3-ssh.tar
3.启动容器(每一台机器执行)
docker run -itd -u root --gpus all --ipc=host --privileged --network=host --name nccl-test shaux/nccl-test:cu12.2.2-cudnn8-devel-ubuntu20.04-nccl2.20.3-ssh bash
4.开始测试(在其中一台机器执行)
-
进入容器
docker exec -it nccl-test bash
-
在容器内准备好待测机器的hostfile列表,格式如下:
172.16.100.26 slots=1 172.16.100.27 slots=1 172.16.100.24 slots=1 172.16.100.23 slots=1 172.16.100.22 slots=1 172.16.100.21 slots=1 172.16.100.20 slots=1 172.16.100.19 slots=1 172.16.100.18 slots=1 172.16.100.17 slots=1 172.16.100.16 slots=1 172.16.100.15 slots=1 172.16.100.14 slots=1 172.16.100.13 slots=1 172.16.100.12 slots=1 172.16.100.10 slots=1
-
执行测试命令
mpirun --allow-run-as-root \
-mca plm_rsh_args "-p 9001" \
-np 16 \
-hostfile hostfile \
-x NCCL_SOCKET_IFNAME=bond0 \
-x NCCL_TOPO_DUMP_FILE=NCCL_TOPO_FILE \
-x NCCL_IB_DISABLE=0 \
-x NCCL_TESTS_SPLIT_MASK=7 \
-x NCCL_IB_HCA=mlx5_2:1,mlx5_3:1,mlx5_5:1,mlx5_6:1 \
-mca btl_tcp_if_include bond0 \
-mca pml ob1 \
-mca btl ^openib \
-mca coll_hcoll_enable 0 \
--bind-to numa \
/opt/nccl_tests/build/all_reduce_perf -b 1G -e 8G -f 2 -g 8-mca plm_rsh_args:容器通信端口,在nccl-test镜像中默认配置为9001,如需修改,需要进入每一个容器中修改sshd配置文件然后重启sshd;
-np:节点数量;
-hostfile:指定hostfile文件;
-x NCCL_SOCKET_IFNAME:指定为机器的业务面网卡名称,根据1.3中查询结果进行配置;
-mca btl_tcp_if_include: 指定为机器的业务面网卡名称,根据1.3中查询结果进行配置;
-x NCCL_IB_HCA:指定IB网卡名称,根据1.2中查询的IB网卡进行配置;
-b指定测试的起始数据量,-e指定最大数据量,-f指定从-b到-e的乘法因子,-g指定为单节点GPU数量;
测试结果示例:
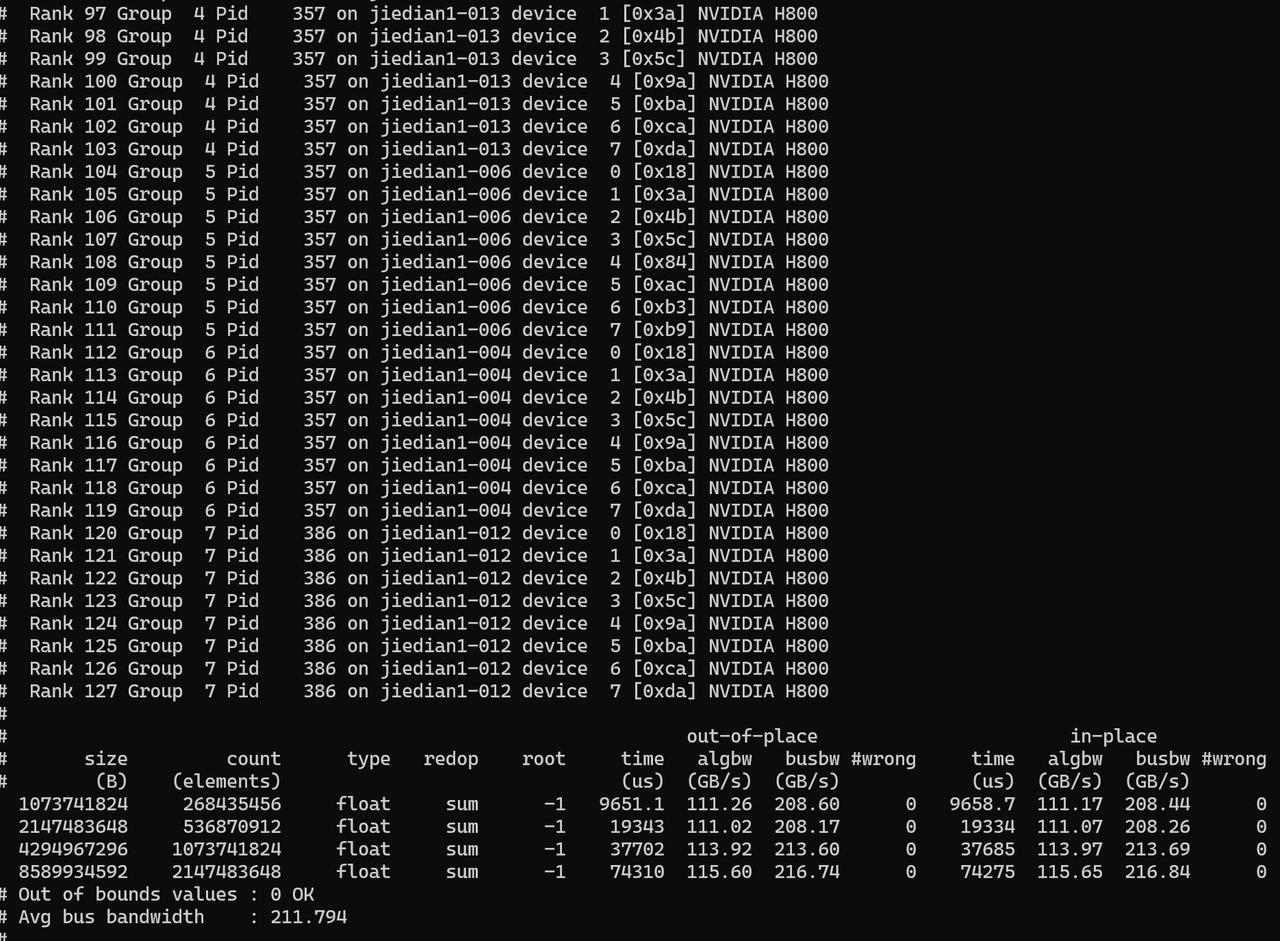
结束语:至此,GPU的检查步骤就结束了,可以交付给模型同事使用,在AI的世界里,最“玄学”的问题,往往都出自最基础的环境,愿你的GPU永远满负荷,loss一路向下!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)