【AI】模型为何要量化?LoRA 是什么?QLoRA 如何实现极致压缩?
《大模型时代的量化与微调技术:QLoRA的突破与实现》 文章摘要: 本文深入探讨大语言模型(LLM)在实际应用中的落地挑战与解决方案。随着模型参数规模膨胀至数十亿甚至数千亿,传统全参数微调方法面临严峻的硬件资源限制。为解决这一难题,研究社区提出了模型量化和参数高效微调(PEFT)两条路径。其中,QLoRA技术通过4-bit量化、分块处理、双重量化等创新方法,首次实现在24GB显存的消费级GPU上微
前言:大模型时代的“落地困境”
随着大语言模型(LLM)的迅猛发展,GPT、LLaMA、Qwen 等模型在自然语言理解、生成、推理等任务上展现出惊人能力。然而,这些模型的参数规模也急剧膨胀——从数十亿到数千亿不等,带来了严峻的部署与微调挑战。
一个现实问题摆在开发者面前:
这些庞大的模型,如何在有限的硬件资源(尤其是消费级 GPU)上进行训练和推理?
以典型模型为例:
- 一个 7B 参数的模型,使用 FP16 精度存储,需要约 14GB 显存
- 一个 65B 参数的模型,FP16 下则需 130GB 显存,远超主流消费级 GPU(如 RTX 3090/4090 的 24GB)
这意味着,全参数微调(Full Fine-Tuning)在普通设备上几乎不可行。
为应对这一挑战,研究社区提出了两条关键技术路径:
- 模型量化(Model Quantization):通过降低参数精度来减少显存占用
- 参数高效微调(PEFT, Parameter-Efficient Fine-Tuning):仅更新少量参数,如 LoRA
而 QLoRA 的出现,将两者结合,实现了极致压缩与高效微调的统一——它让我们首次能够在 24GB 显存的消费级 GPU 上微调 65B 的大模型,极大降低了大模型落地的门槛。
本文将从第一性原理出发,深入剖析:
- 为什么模型量化是必要的?
- LoRA 如何通过“低秩分解”大幅减少可训练参数?
- QLoRA 的“分块量化”与“双重量化”如何解决传统量化中的精度损失问题?
- 其背后的技术逻辑与工程价值
内容详尽,层层递进,适合希望深入理解大模型压缩与高效微调机制的开发者、研究者和爱好者。建议收藏后逐步阅读。
一、为什么需要模型量化?——从“参数大小”与“相对关系”说起
1.1 模型的“记忆”到底是什么?
大语言模型的“知识”存储在它的权重参数中。这些参数通常是 32 位浮点数(FP32)或 16 位(FP16/BF16)。
但研究发现:
模型的预测能力并不依赖于单个参数的“绝对大小”,而是依赖于参数之间的“相对关系”和“结构模式”。
举个例子:
- 如果你把一个模型的所有权重都乘以 0.1,它的行为几乎不会改变
- 但如果你打乱权重的顺序,模型就完全失效了
这说明:
“相对大小”比“绝对大小”更重要
这就为模型压缩提供了理论基础:我们可以降低参数的数值精度,只要保持它们的相对关系不变。
1.2 什么是模型量化?
模型量化(Model Quantization) 是指将高精度浮点数(如 FP32)转换为低精度表示(如 INT8、INT4、FP4)的过程。
常见量化类型对比:
| 类型 | 位宽 | 显存占用(相比 FP32) | 特点 |
|---|---|---|---|
| FP32 | 32-bit | 100% | 高精度,训练常用 |
| FP16/BF16 | 16-bit | 50% | 平衡精度与效率 |
| INT8 | 8-bit | 25% | 推理部署常用 |
| INT4 | 4-bit | 12.5% | 极致压缩,QLoRA 使用 |
| NF4(NormalFloat4) | 4-bit | 12.5% | 针对正态分布优化,精度更高 |
1.3 量化的基本原理:线性映射 + 缩放(Scale)
量化本质是一个线性映射过程。
假设原始浮点值范围为 [],我们要映射到 [0,
] 的整数空间(bb 为位宽):
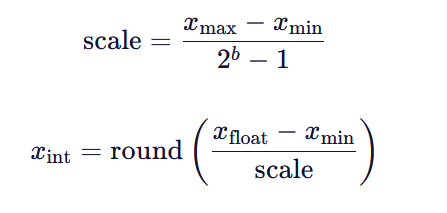
反量化(推理时恢复):
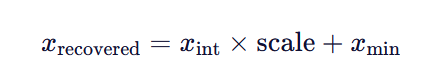
1.4 传统量化的致命问题:全局缩放导致“小值失真”
如果使用全局 scale(整个权重矩阵用一个 scale 值),会出现严重问题。
举个例子:
假设一个权重矩阵中:
- 99% 的值在 [−0.1,0.1]
- 1% 的异常值在 [−10,10]
使用全局量化:
- scale 值由最大值决定 → scale=20/15≈1.33(INT4)
- 小值 0.1 被映射为 round(0.1/1.33)=0
- 所有小值都被“压”到 0,信息完全丢失!
这会导致模型性能严重下降.
二、LoRA:低秩适配——用“因式分解”大幅减少参数
2.1 问题:全参数微调成本太高
在 RAG 系统中,我们需要对大模型进行领域适配微调(Domain Adaptation),比如让 Qwen 更擅长回答编程、数学或教育类问题。
传统方法是全参数微调:
- 更新所有参数
- 显存占用高
- 每个任务都要保存一整套模型副本
这显然不现实。
2.2 LoRA 的核心思想:权重更新是“低秩”的
LoRA(Low-Rank Adaptation)由 Microsoft Research 提出,其核心洞察是:
模型微调时的权重变化 ΔW 其实是一个“低秩矩阵”。
什么意思?
假设原始权重 ![]() ,我们希望更新它:
,我们希望更新它:
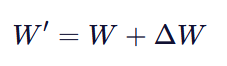
传统方法:直接学习 ΔW,参数量 d×k
LoRA 的思路:
ΔW 可以分解为两个小矩阵的乘积:
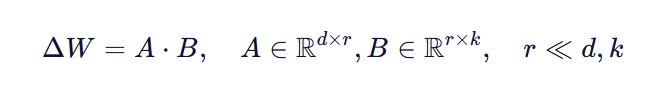
其中 rr 是秩(rank),通常设为 8~64。
2.3 参数量对比:LoRA 节省了多少?
以 LLaMA-7B 的注意力层为例:
- WQ 矩阵大小:4096×4096
- 参数量:16.8M
使用 LoRA(r=64):
- AA: 4096×64 → 262K
- BB: 64×4096 → 262K
- 总参数:524K,仅为原参数的 3.1%
节省了 97% 的可训练参数!
2.4 LoRA 的优势与工程价值
| 优势 | 说明 |
|---|---|
| 显存节省 | 只需训练 A 和 B,显存占用大幅降低 |
| 推理无开销 | 训练后可将 A⋅B 合并回 W,推理速度不变 |
| 多任务支持 | 基础模型不变,不同任务加载不同 LoRA 适配器 |
| 易部署 | 只需分发几 MB ~ 几百 MB 的 LoRA 权重文件 |
2.5 在 RAG 中的应用场景
在传智教育的智能答疑系统中,我们可以:
- 使用 LoRA 对 Qwen 模型进行多学科适配
- 为“Java”、“Python”、“前端”等学科分别训练 LoRA 适配器
- 用户提问时,根据问题类型动态加载对应 LoRA 模型
实现低成本、高灵活性的领域知识增强。
三、QLoRA:极致压缩——4-bit 量化 + 分块 + 双重量化
3.1 QLoRA 的目标:在 24GB GPU 上微调 65B 模型
QLoRA(Quantized LoRA)由 Tim Dettmers 等人提出,目标是:
在消费级 GPU 上实现大模型的高效微调
它结合了:
- 4-bit 量化(极致压缩)
- 分块量化(解决小值失真)
- 双重量化(压缩 scale 值)
- Paged Optimizers(防止显存峰值 OOM)
- NF4 数据类型(精度更高)
3.2 技术一:4-bit NormalFloat(NF4)
QLoRA 使用 NF4(NormalFloat4),一种针对正态分布权重优化的 4-bit 数据类型。
- 传统 INT4:均匀分布
- NF4:在 0 附近更密集,更适合大模型权重分布
在相同位宽下,NF4 比 INT4 更精确。
3.3 技术二:分块量化(Block-wise Quantization)
为了解决全局 scale 导致小值失真的问题,QLoRA 采用:
将权重矩阵划分为小块(如每 64 个元素一块),每块独立计算 scale
工作流程:
- 将权重向量划分为 N 个 block
- 对每个 block 计算局部:
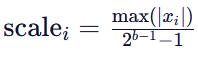
- 对每个 block 单独量化
这样,小值 block 使用小 scale,大值 block 使用大 scale,避免信息丢失。
3.4 技术三:双重量化(Double Quantization)
分块后会产生大量 scale 值(每个 block 一个),这些 scale 本身也需要存储。
QLoRA 提出:
对 scale 值再进行一次量化
例如:
- 第一次量化:权重 → 4-bit,得到 FP16 的 scale 值
- 第二次量化:scale 值 → 8-bit 或更低
进一步压缩元数据大小。
3.5 推理时:查表反量化(Dequantization)
在训练和推理时,系统通过查找表(Lookup Table) 快速完成反量化:
- 读取 4-bit 量化权重
- 读取对应 block 的量化 scale
- 反量化 scale:
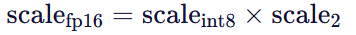
- 反量化权重:
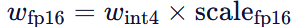
- 输入模型计算
整个过程在 GPU 上高效完成。
3.6 QLoRA 的效果(实测数据)
| 模型 | 方法 | 显存占用 | 性能(vs Full FT) |
|---|---|---|---|
| LLaMA-7B | Full FT | ~14GB | 100% |
| LLaMA-7B | LoRA | ~6GB | 98%~99% |
| LLaMA-7B | QLoRA | ~4.5GB | 96%~98% |
| LLaMA-65B | QLoRA | ~24GB | 95%~97% |
QLoRA 实现了性能几乎无损 + 显存大幅降低 + 可部署的三重目标。
我的深入理解与思考
模型的“语义”存在于参数的相对关系中,而非绝对值。
QLoRA 的“双重量化”和“查表反量化”机制。
- 量化不是简单的“缩小范围”,而是有损压缩 + 精度恢复
- “查表”是在 GPU 显存中完成的,速度极快
- 分块大小(如 64)是一个超参数,影响精度与效率的平衡
总结:从量化到 QLoRA 的技术演进
| 技术 | 核心思想 | 解决问题 | 显存节省 |
|---|---|---|---|
| 模型量化 | 降低参数精度 | 模型太大,无法部署 | 50%~87.5% |
| LoRA | 低秩分解,只训练小矩阵 | 全参数微调成本高 | 90%+ 可训练参数 |
| QLoRA | 4-bit + 分块 + 双重量化 | 在消费级 GPU 上微调大模型 | 极致压缩,24GB 跑 65B |
给 RAG 开发者的工程启示
- 量化是落地前提:RAG 系统中大模型是核心,但必须考虑部署成本。
- QLoRA 是理想选择:可在 24GB GPU 上微调 Qwen、LLaMA 等模型,适配各领域知识。
- 结合 LangChain 更灵活:基础模型 + QLoRA 适配器,实现多学科智能问答切换。
- 关注 HuggingFace PEFT 库:已集成 LoRA、QLoRA,开箱即用。
喜欢这篇文章?欢迎点赞、收藏、分享!
有问题?欢迎在评论区留言讨论!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)