解锁时序数据库选型密码,为何国产开源时序数据库 TDengine 脱颖而出?
工业 4.0 与物联网的深度融合,正将工业领域推入 “数据洪流” 时代。据工业互联网产业联盟统计,单条智能生产线每小时可产生数十万条设备状态数据,一座大型智慧工厂日均数据增量达 TB 级,全行业时序数据年增长率突破 60%。这些承载设备状态、生产工艺的时序数据,既是工业数字化的核心资产,也对数据管理方案提出了 “高写入、低延迟、低成本、易扩展” 的严苛要求。
传统数据管理方案在这场考验中逐渐力不从心:NoSQL 数据库(如 MongoDB)压缩率低,10 万辆车的车联网数据一年需 100TB 存储;关系型数据库(如 MySQL)单节点写入极限仅 1000TPS,难以承接峰值 10 万行 / 秒的工业数据;基于 Hadoop 的 HBase 架构复杂,实时查询延迟超分钟级,且需 6 台以上服务器支撑最小集群。当工业场景呼唤专业时序数据库时,国产开源时序数据库 TDengine 凭借对工业需求的深度贴合,从众多方案中脱颖而出,成为工业企业数字化转型的核心选择。
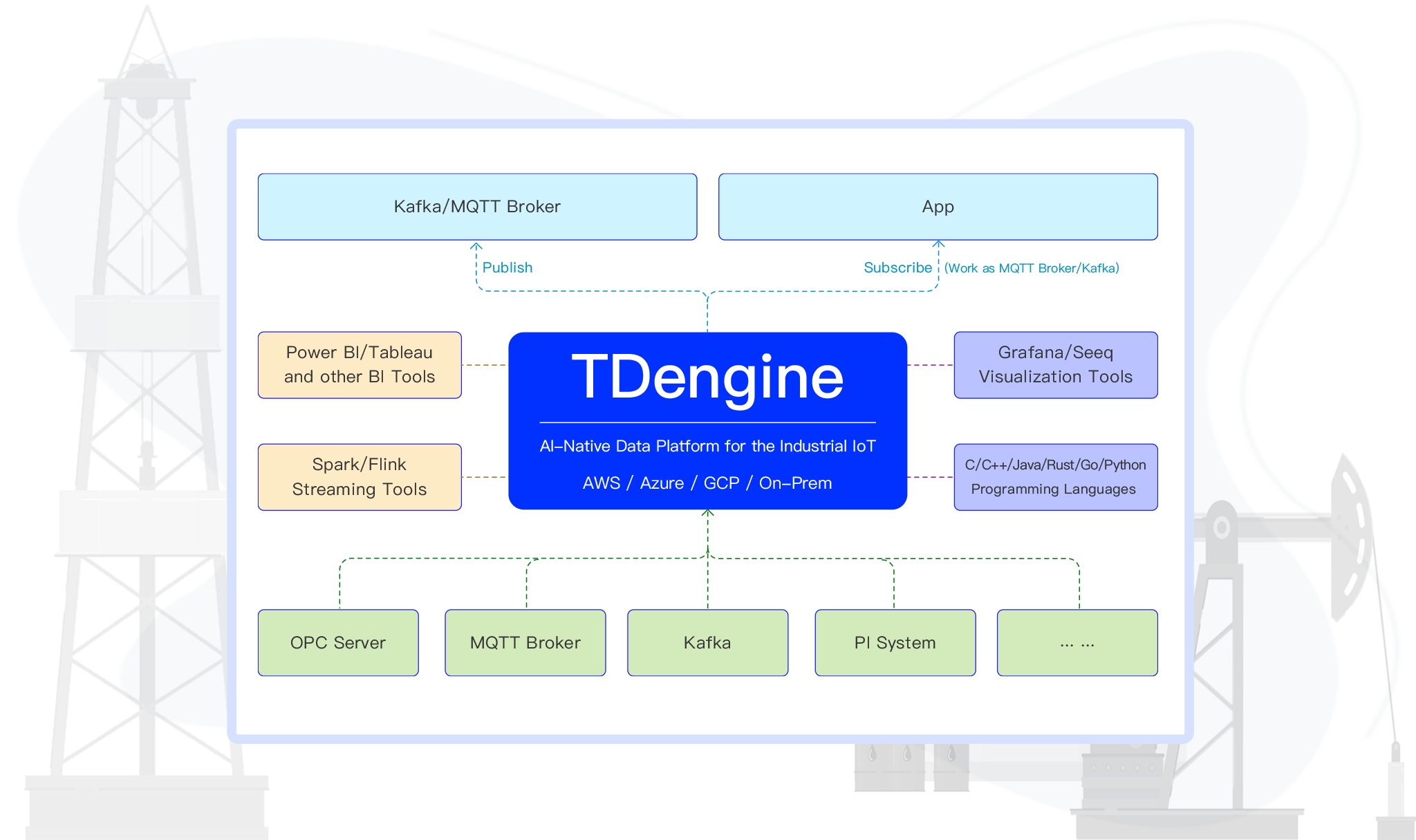
一、时序数据库选型:四大核心维度决定工业场景适配性
工业企业选择时序数据库,本质是寻找 “性能、成本、易用性、扩展性” 的最优解。脱离工业场景的技术参数毫无意义,真正适配的时序数据库需在四大核心维度满足需求:
1. 性能:能否承接工业级 “高并发写入 + 低延迟查询”
工业场景的核心性能诉求集中在两点:一是写入吞吐量需支撑百万级设备的高频数据采集,单机需达到 10 万点 / 秒以上,集群需突破百万点 / 秒;二是查询延迟需区分场景,单设备最新数据查询需 < 100ms(满足实时监控),1000 台设备日均值聚合需 < 2s(支撑运营分析)。更关键的是持续稳定性 —— 部分数据库短时间能达高吞吐量,但 1 小时后性能衰减超 50%,无法满足工业 24 小时不间断生产需求。
2. 存储效率:压缩比直接决定长期运营成本
工业时序数据量庞大,存储成本占比超 60%,而压缩比是成本控制的核心。传统关系型数据库压缩比仅 2:1-3:1,专业时序数据库通过列式存储、差值编码等技术可实现 8:1-10:1 压缩比。以 100 万点 / 秒的写入速度计算,8:1 压缩比的数据库每年仅需 38TB 存储,而 3:1 方案需 102TB,三年成本差距可达数十万元。此外,能否自动将冷数据迁移至 S3 等低成本介质(分级存储),也是降低长期成本的关键。
3. 数据模型:是否贴合 “设备 - 指标 - 时间” 工业逻辑
工业时序数据的核心关联是 “哪个设备(Who)、在什么时间(When)、产生了什么指标(What)”,理想的数据模型需支持三维关联:为设备定义静态标签(如型号、位置)、支持多指标批量写入、原生区分指标类型。部分数据库采用扁平表结构,将所有指标存储在单表中,导致查询过滤操作增加,性能下降 30% 以上;而贴合工业逻辑的模型可使开发效率提升 40%,查询性能翻倍。
4. 扩展性:能否应对设备与数据的持续增长
工业企业的设备数量会随数字化进程逐年增加,数据库需具备 “线性扩展” 能力 —— 节点数量翻倍时,写入吞吐量提升比例需达 80% 以上,且扩展过程无需重启集群、不中断业务。同时,需无缝集成工业生态工具:如 Telegraf、OPC UA(数据采集)、Grafana(可视化)、Flink(流处理),缺乏生态支持会导致集成成本增加,项目周期延长。
二、TDengine:从架构根源适配工业时序数据需求
TDengine 作为涛思数据自主研发的国产开源时序数据库,自 2017 年发布以来,始终以 “工业物联网场景” 为核心设计目标,其 “存储 - 计算 - 接入” 一体化架构从根源上解决了工业时序数据管理的痛点,这也是其脱颖而出的核心原因。
1. 架构创新:让每一层都贴合工业场景
TDengine 的架构并非简单的 “存储 + 计算” 叠加,而是针对工业数据 “采集端分散、写入频率高、查询维度多” 的特点分层优化:
-
客户端层:零门槛接入工业生态
提供 C/C++、Java、Python 等 10 余种语言 SDK,支持 JDBC/ODBC 标准接口,更内置 MQTT、Kafka、OPC UA 等工业协议接入能力 —— 企业无需开发适配插件,通过 taos-explorer 工具即可零代码接入传感器、PLC 等设备数据,大幅降低集成难度。
-
集群管理层:vnode 技术实现无缝扩展
基于虚拟节点(vnode)技术将数据分片,每个 vnode 负责特定设备的数据存储与计算,节点新增时无需调整应用配置,即可实现性能与存储容量的线性扩展。同时通过 Leader-Follower 模式构建冗余,故障恢复时间 <30 秒,满足工业场景 “7×24 小时不中断” 的需求。
-
存储引擎层:用多级压缩降低成本
采用列式存储架构,针对时序数据设计 “差值编码 + XOR 编码 + LZ4 压缩” 的多级压缩算法,典型压缩比达 8:1。支持按时间分区(如按天分区),超过保留期的数据自动删除;同时实现冷热数据分离,冷数据自动迁移至 S3 等低成本存储,存储成本可降低 70% 以上。
-
计算引擎层:分布式计算提升分析效率
内置滑动窗口、插值、聚合等丰富时序函数,支持实时计算与离线分析。聚合查询时先在各 vnode 内完成本地计算,再进行全局汇总 —— 这种分布式计算模式在 1000 台设备同时分析场景下,查询效率比传统集中式计算提升 3-5 倍。
2. 性能与成本双优:TSBS 测试与实战验证
国际权威时序数据库性能测评平台 TSBS(Time Series Benchmark Suite)的测试结果,为 TDengine 的性能优势提供了量化支撑。在 IoT 与 DevOps 两大核心场景中,TDengine 3.0 的表现全面领先 InfluxDB、TimescaleDB 等主流产品:
-
写入性能:碾压级优势
在 IoT 场景中,TDengine 写入速度是 InfluxDB 的 1.82-16.2 倍,是 TimescaleDB 的 1.04-7 倍;在 DevOps 场景中,写入速度最高达 TimescaleDB 的 6.7 倍、InfluxDB 的 10.6 倍,且写入过程中 CPU 与磁盘 IO 开销最低。以 10 万辆车的车联网场景为例,TDengine 单集群可轻松承接 3333 行 / 秒的写入需求,峰值达 10 万行 / 秒时仍保持稳定。
-
查询延迟:毫秒级响应复杂分析
在包含 4 天数据的 IoT 场景中,TDengine 的查询平均响应时间是 InfluxDB 的 2.4-155.9 倍,是 TimescaleDB 的 1.1-16.4 倍;面对复杂的多设备聚合查询(如 1000 台设备日均值统计),响应时间仍控制在 2 秒内,远超工业实时监控的需求。
-
存储成本:差距随数据量扩大
磁盘占用方面,TimescaleDB 在大数据量场景(100 万台设备)下的磁盘占用是 TDengine 的 26.9 倍;InfluxDB 在小数据量场景与 TDengine 接近,但数据量达百万级设备时,磁盘占用是 TDengine 的 4.5 倍。大理卷烟厂的实践印证了这一优势 —— 迁移至 TDengine 后,存储 7000 亿条历史数据的成本较原方案下降 60%。
三、不止于存储:TDengine 的差异化竞争力
在工业数字化转型中,企业需要的不仅是 “能存数据” 的数据库,更是 “能管数据、用数据” 的平台。TDengine 通过 “简化架构”“国产化适配”“AI 融合” 三大差异化能力,进一步拉大与同类产品的差距。
1. 简化架构:从 “多组件堆砌” 到 “一体化平台”
传统工业数据架构需部署 “数据采集(Kafka)+ 存储(HBase)+ 计算(Spark)+ 可视化(Grafana)” 等多套组件,架构复杂且运维成本高。TDengine 集成了数据采集、存储、计算、可视化全链路功能,无需额外部署第三方组件 —— 架构复杂度降低 50%,系统部署周期从数月缩短至数周。蔚来能源的实践显示,迁移至 TDengine 后,无需维护 ZooKeeper 与 HBase 预分区,运维负担大幅减轻,集群部署效率提升 60%。
2. 国产化适配:符合信创要求的全栈方案
在国产化替代的趋势下,工业企业对数据安全与供应链稳定的需求日益迫切。TDengine 完全自主研发,已适配麒麟、统信等国产操作系统,以及飞腾、鲲鹏等国产芯片,可提供从硬件到软件的全栈国产化解决方案。大理卷烟厂基于 TDengine 构建的制丝工艺数据平台,不仅实现了对国外 Wonderware historian 数据库的替代,更通过国产化适配获得 “玉溪品牌原料打叶复烤示范性区域加工中心” 认证。
3. AI 融合:从 “数据存储” 到 “智能决策”
AI 时代,时序数据的价值不仅在于记录,更在于预测与洞察。TDengine 通过内置 AI 能力,完成了从 “数据存储平台” 到 “智能数据管理平台” 的升级:
- TDgpt 时序数据分析 AI 智能体:支持用一条 SQL 调用预测、异常检测、数据补齐等能力。例如通过FORECAST(current, "algo=arima,rows=100")即可实现设备电流预测,通过ANOMALY_WINDOW(voltage, "algo=iqr")识别电压异常,零门槛降低 AI 应用难度。
- IDMP AI 原生工业数据管理平台:采用树状层次结构管理设备数据,结合 AI 技术实现 “无问智推”—— 无需用户发起查询,即可自动生成设备运行趋势、异常告警等分析面板。在电力负荷预测、设备预测性维护等场景中,IDMP 可帮助业务人员快速获得数据洞察,无需具备编程或数据分析能力。
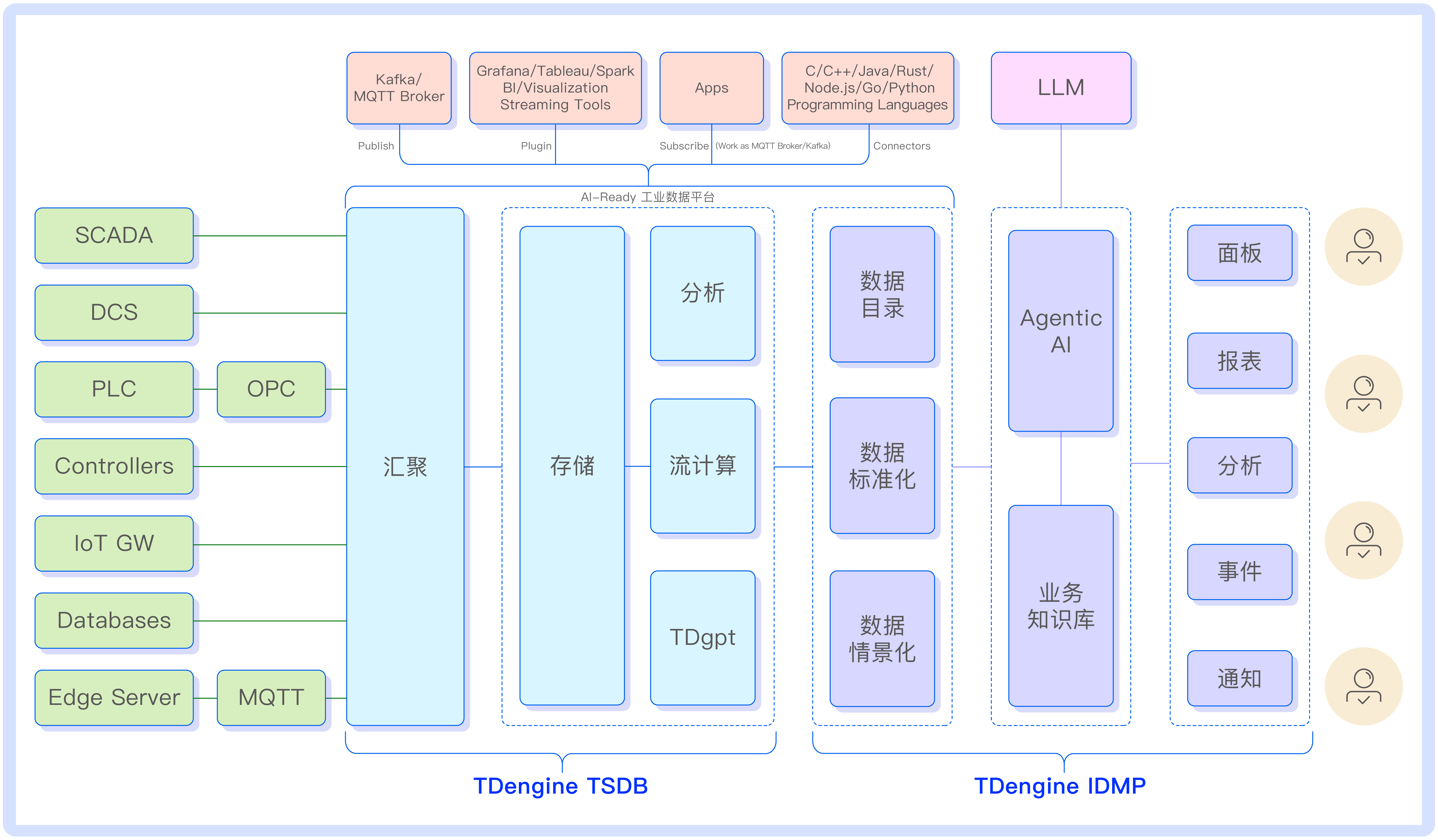
四、结语:TDengine 重新定义工业时序数据管理
从大理卷烟厂 “制丝工艺国产化智能升级”,到蔚来能源 “全国充换电网络数据高效管理”,TDengine 的实战案例证明:它早已超越传统数据库的范畴,成为工业数据的 “全路径管理平台”—— 既能用高压缩比、高吞吐量解决 “存得下、写得快” 的基础问题,又能用简化架构、国产化适配降低 “管得易、用得安” 的运维成本,更能用 AI 融合激活 “挖得深、判得准” 的数据价值。
在工业数字化转型的浪潮中,时序数据库的选型不仅是技术选择,更是战略选择。TDengine 以 “开源、国产、工业级” 的定位,既贴合了企业对成本与安全的需求,又通过架构创新与 AI 赋能满足了未来发展的潜力。当工业企业仍在为时序数据管理难题困扰时,TDengine 已然给出了 “高性能、低成本、易扩展、智能化” 的最优解 —— 这正是它在众多时序数据库中脱颖而出的核心密码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)