【珍藏】企业级AI智能体新技术架构全解析:Tasking AI与Dify实战指南
本文深入解析企业级AI智能体开发平台的核心架构,对比Tasking AI与Dify的设计差异与优势,详细拆解模块化管理、多租户隔离和任务编排等关键能力,探讨从简单应用到复杂场景的架构选择,并展望未来向意图驱动和自进化方向的发展趋势,为AI应用开发提供全面参考。
随着大语言模型(LLM)技术的爆发,AI 原生应用开发不再是 “模型调用 + 简单逻辑” 的浅层组合,而是需要一套能覆盖 “场景定义 - 系统设计 - 开发部署” 全流程的支撑平台。目前行业中,Tasking AI 与 Dify 是极具代表性的两款开发平台,前者以简洁架构适配轻量需求,后者则凭借强大的任务编排能力成为复杂场景的首选。
本文将聚焦两款平台的核心设计,尤其以 Dify 的架构为重点,拆解 AI 原生应用开发平台的关键能力、系统架构与任务编排引擎,帮你理清这类平台的设计逻辑与落地思路。
一、先搞懂:AI 原生应用开发平台的定位
在聊架构前,首先要明确这类平台的核心价值,降低 AI 应用开发门槛,解决 “模型选型难、工具集成散、流程编排繁” 三大痛点。目前行业中的平台主要分为两类,定位差异显著:
| 平台类型 | 代表产品 | 目标用户 | 核心特点 |
|---|---|---|---|
| 通用开发平台 | Dify、Tasking AI、Coze | 产品专家、业务开发(非 AI 专家) | 一站式可视化开发,无需关注底层技术,支持快速落地生产级应用 |
| 开发框架 | LangChain、OpenAI Assistant API | AI 技术开发者 | 需手动集成外部服务(如向量库),灵活性高但开发成本高 |
为什么 Dify 这类通用平台更受企业青睐?对比开发框架的局限性就能明白:
- LangChain:无内置数据管理与向量存储,开发者需额外集成,增加维护成本;
- OpenAI Assistant API:绑定 OpenAI 模型,工具与检索能力深度耦合,无法适配多租户场景,且参数配置自由度低。
而 Dify、Tasking AI 这类平台,通过 “统一模型接入、模块化工具管理、可视化流程编排”,让业务人员也能快速搭建 AI 应用,这正是其核心定位价值。
二、AI 原生应用开发平台的 4 大核心能力
无论 Tasking AI 还是 Dify,要支撑 AI 应用全流程开发,必须具备四大核心能力,这也是平台设计的基础:
1. 有状态 / 无状态应用双支持
AI 应用常需区分 “单次问答”(无状态)与 “多轮对话”(有状态),平台需提供灵活的会话与数据管理能力:
-
Tasking AI
采用 “本地内存 + Redis+PostgreSQL” 三级存储,自动管理会话历史与向量数据,开发者无需关注底层存储;
-
Dify
设计向量数据库统一接入框架,支持多种向量库(如 Milvus、FAISS)的动态加载 / 卸载,适配不同数据规模需求。
2. 模型、工具、RAG 模块化管理
突破开发框架的 “绑定限制”,实现模块自由组合:
- 模型层:支持数百种 LLM 接入(如 GPT、Qwen、DeepSeek),提供统一 API 调用 completion、embedding、rerank 能力;
- 工具层:提供插件化开发框架,支持系统内置工具(如搜索、Excel 分析)与用户自定义工具,标准化接入流程;
- RAG 层:统一管理知识库,支持文档上传、自动向量化、检索配置,无需单独开发检索逻辑。
3. 多租户隔离机制
企业场景中,不同团队 / 项目的数据、模型资源必须隔离,避免风险:Dify 的设计极具代表性,在数据模型层通过tenant_id字段标识租户,从 “应用创建 - 开发 - 部署” 全生命周期,为不同租户加载独立的模型实例、私有知识库,且实现成本低、灵活性高,特别适合中小型企业。
4. 复杂任务编排能力(Dify 独有优势)
这是 Dify 区别于 Tasking AI 的核心亮点:支持可视化 Workflow 编排,通过拖拽节点(LLM 节点、分支判断、Tool 节点、Code 节点等),快速构建复杂流程。例如 “用户提问→Question Classifier 判断意图→调用 RAG 检索→LLM 生成回答→工具补充数据” 的多步骤流程,无需写代码即可完成。
三、系统架构拆解:从 Tasking AI 看基础设计,从 Dify 看复杂扩展
两款平台的架构设计各有侧重:Tasking AI 以 “简洁分层” 适配轻量需求,Dify 以 “异步化 + 任务编排” 支撑复杂场景。我们先从 Tasking AI 的基础架构入手,再深入 Dify 的进阶设计。
1. Tasking AI:微服务架构,分层清晰
Tasking AI 采用微服务拆分,按业务领域分为三大核心服务,代码可读性与可维护性极佳:
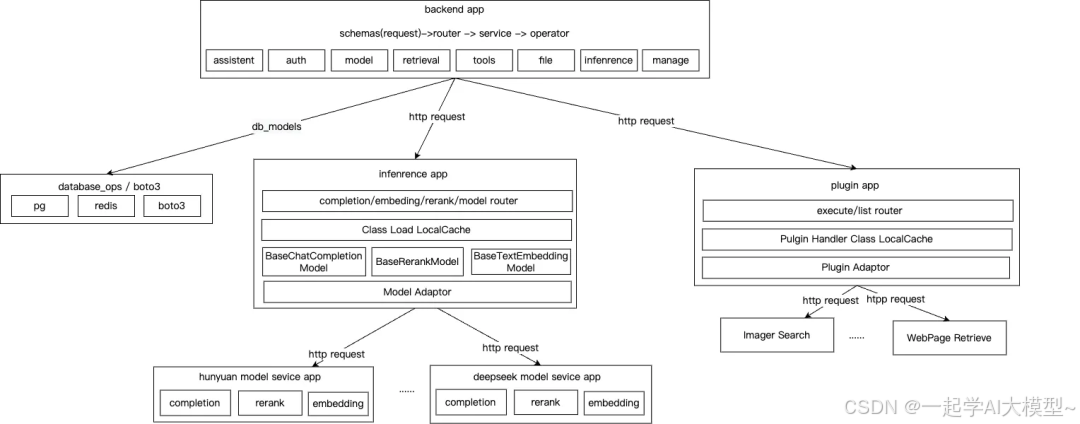
(1)Backend App:应用开发入口
作为用户交互与业务编排的核心,负责:
- 管理 AI 应用(Assistant)、模型、知识库、插件的配置;
- 提供版本控制、日志追踪能力,支撑应用部署运维;
- 本地缓存模型 / 插件配置,定时刷新,提升响应速度。
代码架构遵循 DDD 领域驱动设计,分为三层:
-
Infra 层
封装 PostgreSQL/Redis/Boto3 的 CRUD 操作,隔离数据访问细节;
-
Domain 层
基于 Infra 层能力,封装 Assistant、模型、检索、工具的核心业务逻辑;
-
Interface 层
处理前端请求(参数校验、Request/Response 转换),对应 MVC 的 Controller 层。
注意:Tasking AI 的 Interface 层承载了部分业务编排逻辑,略增加复杂度。理想设计应将业务编排抽象到独立的 App 层,让 Interface 层仅负责请求处理。
(2)Inference App:模型推断服务
构建模型接入的 “抽象层”,解决多模型适配问题:
- 定义三大基础模型类:
BaseChatCompletion(对话生成)、BaseTextEmbeddingModel(文本向量化)、BaseRerankModel(结果重排); - 不同模型提供商(如 OpenAI、阿里云)通过实现基础类的
prepare_request、handle_response等方法,适配输入输出格式; - 启动时自动扫描模型配置文件,动态加载适配器,路由层根据应用配置的模型 ID,调用对应模型服务。
(3)Plugin App:工具插件服务
作为 Backend App 的下游服务,提供工具执行能力:
- 设计
PluginHandler基础类,第三方插件需实现execute方法触发逻辑; - 统一插件输入 / 输出 Schema,自动转换为 LLM 可识别的 Function Call 参数格式;
- 隔离应用开发与插件管理,Backend App 根据模型推断结果,决定是否调用插件。
2. Dify:异步化 + 任务编排,支撑复杂场景
Dify 在 Tasking AI 基础架构上,增加了 “异步任务处理” 与 “GraphEngine 任务编排引擎”,更适合复杂 AI 应用(如批处理任务、多步骤对话流程)。
(1)整体架构:MVC 分层 + Celery 异步
- 核心模块
- Controllers 层:处理 API 请求,负责参数校验与响应封装;
- Services 层:核心业务逻辑(如应用创建、模型调用、任务编排);
- Models 层:数据模型定义(如应用配置、会话记录、插件信息);
- Core 层:底层能力封装(模型适配器、插件框架、RAG 引擎);
-
异步优化
通过 Celery 将 IO 密集型任务(如文档向量化、批量推理)异步处理,提升系统响应速度与吞吐量。
(2)模型接入:统一适配器设计
与 Tasking AI 思路一致,但更强调通用性:
- 定义
LargeLanguageModel基础类,统一模型调用接口; - 各模型提供商实现
invoke方法,处理参数预处理(如 Prompt 格式化)、API 调用、响应解析,输出统一格式结果; - 支持模型动态切换,应用开发时可随时替换模型,无需修改业务逻辑。
(3)关键差异:GraphEngine 任务编排引擎
这是 Dify 支撑复杂场景的核心,能将 AI 应用流程解析为可执行的 DAG(有向无环图),通过事件驱动实现节点调度。
① GraphEngine 的核心设计
-
节点类型全覆盖
通过
NODE_TYPE_CLASSES_MAPPING维护所有节点,包括 Start/End 节点、LLM 节点、IFElse 分支节点、Knowledge Retrieval 节点、Tool 节点、Loop 循环节点等,满足复杂流程语义; -
事件驱动调度
采用 “事件生成 - 发布 - 监听” 模式,关键事件包括
GraphRunStartedEvent(工作流启动)、NodeRunStartedEvent(节点执行)、GraphRunSucceededEvent(工作流成功),由WorkflowAppGenerator监听事件并更新状态; -
DAG 执行流程
从根节点(Source Node)开始,按拓扑排序逐层执行节点,自动处理节点依赖关系。
② GraphEngine 执行步骤(以 Workflow 应用为例)
-
初始化
用户触发 Workflow 运行时,
AppGenerateService根据应用类型(如 Workflow)调用WorkflowAppGenerator,初始化队列管理器(QueueManager)、变量加载器(VariableLoader); -
构建 DAG
WorkflowAppRunner根据用户配置的节点关系、输入参数,生成可执行的 DAG 图; -
启动引擎
WorkflowEntry封装GraphEngine,触发 DAG 执行,同时监听节点事件; -
节点执行
按拓扑序执行节点,若触发工具调用则请求 Plugin 服务,执行结果存入变量池;
-
状态管理
WorkflowAppGenerator监听事件,持久化节点执行状态与日志,支持失败重试。
优化建议:Dify 默认采用本地消息队列实现事件调度,增加了故障恢复复杂度。建议引入 Redis/Pulsar 等分布式消息队列,实现无状态设计,提升扩展性与容错能力。
四、典型 AI Assistant 核心流程:从用户提问到输出
理解架构后,我们以 “多轮对话 + RAG + 工具调用” 的 AI Assistant 为例,看 Dify/Tasking AI 如何编排流程(以 Tasking AI 为例,Dify 逻辑类似但支持更复杂节点):
-
会话初始化
Backend App 根据 Assistant ID 与 Chat ID,从本地缓存加载模型配置、插件列表、历史会话;
-
分布式锁开启
基于 Redis 开启分布式锁,防止多请求冲突;
-
Query 处理
- 调用 Inference App 的 Embedding 模型,将用户 Query 向量化;
- 基于向量化结果检索知识库,获取相关文档片段;
- 调用 Rerank 模型对检索结果重排,提升相关性;
-
Prompt 构建
结合重排后的检索结果、历史会话、插件信息,按 Prompt 模板生成系统提示词;
-
模型推断
将 Prompt 提交给 Inference App 的 Chat 模型,获取推断结果;
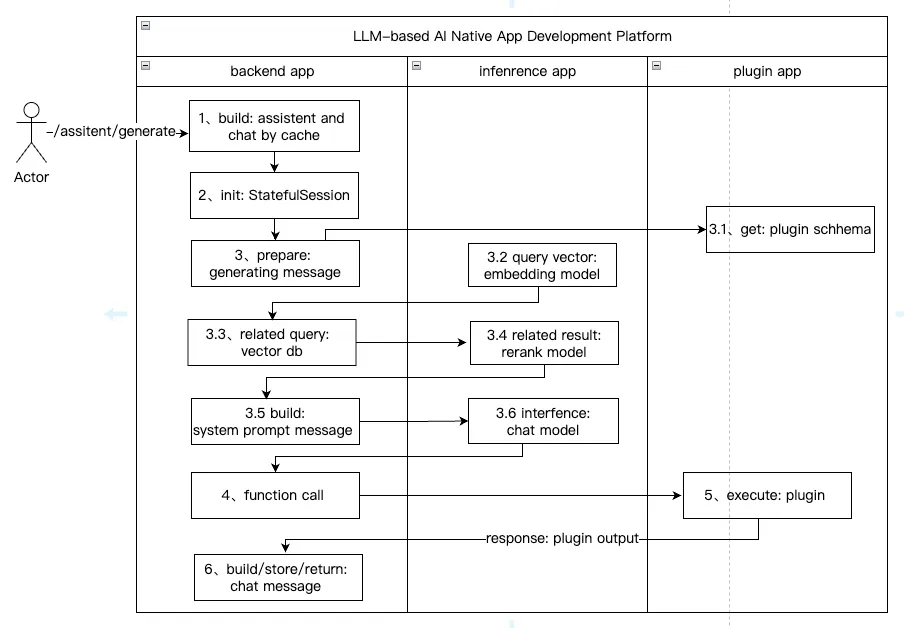
-
工具调用判断
若模型返回 Function Call 指令,Backend App 请求 Plugin App 执行对应工具(如搜索实时数据),将工具输出再次传入模型;
-
结果返回
组装最终回答,持久化会话记录,返回给用户。
五、总结与展望:AI 原生应用开发平台的未来
1. 两款平台的对比与选择
| 维度 | Tasking AI | Dify |
|---|---|---|
| 架构复杂度 | 低,微服务拆分清晰,DDD 分层合理 | 中,支持异步与复杂编排,但部分代码耦合 |
| 核心优势 | 轻量、易维护,适合快速验证轻量应用 | 复杂任务编排能力强,适合生产级复杂应用 |
| 目标场景 | 简单 AI 助手、知识库问答 | 多步骤 Workflow、批处理任务、Advanced Chat |
| 代码可读性 | 高,分层明确 | 中,存在部分上下层代码穿透 |
2. 未来发展趋势
(1)开发模式:从 “人工编排” 到 “意图驱动自动生成”
未来平台将支持通过自然语言描述需求(如 “构建一个客户服务 AI,能检索产品文档并生成工单”),自动解析意图、获取领域知识、生成应用流程,并持续优化验证,进一步降低开发门槛。
(2)系统架构:向 “自愈型、自进化” 演进
- 自愈能力:自动检测故障(如模型服务不可用),切换备用资源,降低人工干预成本;
- 自进化能力:通过机器学习分析应用运行数据,优化模型参数、检索策略、流程编排,提升应用效果。
AI 原生应用开发平台的核心价值,始终是 “让 AI 技术更高效地落地业务”。无论是 Dify 的复杂编排,还是 Tasking AI 的轻量设计,其架构思路都围绕这一核心展开。对于开发者而言,理解这些设计逻辑,不仅能更好地使用平台,更能为自定义 AI 应用架构提供参考,这正是本文的最终目的。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
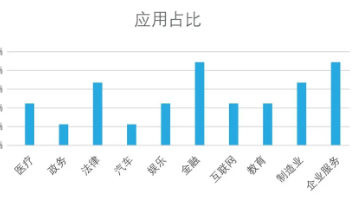
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献220条内容
已为社区贡献220条内容

所有评论(0)