Rust 数据库驱动开发与 ORM 设计:从连接池到查询构建器
传统数据库访问模式现代 ORM 模式// 查询模型(从数据库读取)// 插入模型(写入数据库)让我们从零构建一个类型安全的查询构建器!陷阱表现解决方案连接泄漏连接池耗尽确保连接正确归还(使用 Drop trait)N+1 查询性能急剧下降使用 JOIN 或批量查询SQL 注入安全漏洞始终使用参数化查询大事务锁表过久减小事务范围,使用乐观锁未处理的错误程序崩溃合理的错误处理和重试机制核心要点✅原生驱
📝 摘要
数据库访问是现代应用的核心功能。Rust 生态提供了从底层驱动到高级 ORM 的完整解决方案。本文将系统讲解数据库连接管理、连接池设计、SQL 查询构建、异步数据库访问(SQLx、Diesel)以及如何从零构建一个类型安全的查询构建器。通过深入分析 SQLx 的编译时查询验证和 Diesel 的类型安全设计,帮助读者掌握 Rust 数据库编程的核心原理与最佳实践。
一、背景介绍
1.1 数据库访问的演进
传统数据库访问模式:

现代 ORM 模式:

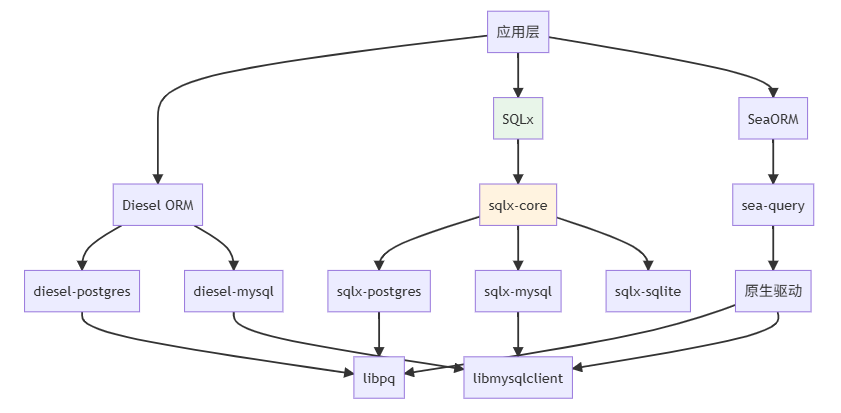
1.2 Rust 数据库生态概览
| 库名 | 类型 | 特点 | 适用场景 |
|---|---|---|---|
| rust-postgres | 原生驱动 | PostgreSQL 官方驱动 | 底层访问 |
| rusqlite | 原生驱动 | SQLite 驱动 | 嵌入式数据库 |
| mysql_async | 原生驱动 | MySQL 异步驱动 | 高性能场景 |
| SQLx | 异步驱动 + 部分 ORM | 编译时查询验证 | 类型安全 + 性能 |
| Diesel | 同步 ORM | 最强类型安全 | 复杂查询 |
| SeaORM | 异步 ORM | 动态查询 | 快速开发 |
生态架构:
二、原生数据库驱动
2.1 PostgreSQL:同步访问
[dependencies]
postgres = "0.19"
基础连接与查询:
use postgres::{Client, NoTls, Error};
fn main() -> Result<(), Error> {
// 1. 建立连接
let mut client = Client::connect(
"host=localhost user=postgres password=secret dbname=testdb",
NoTls,
)?;
// 2. 创建表
client.batch_execute("
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
email VARCHAR NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
")?;
// 3. 插入数据(参数化查询,防止 SQL 注入)
client.execute(
"INSERT INTO users (name, email) VALUES ($1, $2)",
&[&"Alice", &"alice@example.com"],
)?;
client.execute(
"INSERT INTO users (name, email) VALUES ($1, $2)",
&[&"Bob", &"bob@example.com"],
)?;
// 4. 查询数据
for row in client.query("SELECT id, name, email FROM users", &[])? {
let id: i32 = row.get(0);
let name: &str = row.get(1);
let email: &str = row.get(2);
println!("用户 #{}: {} ({})", id, name, email);
}
// 5. 预编译语句(提升性能)
let stmt = client.prepare("SELECT * FROM users WHERE name = $1")?;
for row in client.query(&stmt, &[&"Alice"])? {
let name: &str = row.get("name");
println!("找到用户: {}", name);
}
Ok(())
}
事务处理:
use postgres::{Client, NoTls, Error, Transaction};
fn transfer_money(
client: &mut Client,
from_id: i32,
to_id: i32,
amount: f64,
) -> Result<(), Error> {
// 开启事务
let mut transaction = client.transaction()?;
// 操作1:扣款
transaction.execute(
"UPDATE accounts SET balance = balance - $1 WHERE id = $2",
&[&amount, &from_id],
)?;
// 操作2:加款
transaction.execute(
"UPDATE accounts SET balance = balance + $1 WHERE id = $2",
&[&amount, &to_id],
)?;
// 提交事务(如果之前有错误,自动回滚)
transaction.commit()?;
println!("✓ 转账成功: {} -> {}, 金额: {}", from_id, to_id, amount);
Ok(())
}
fn main() -> Result<(), Error> {
let mut client = Client::connect(
"host=localhost user=postgres dbname=testdb",
NoTls,
)?;
// 模拟转账
transfer_money(&mut client, 1, 2, 100.0)?;
Ok(())
}
2.2 SQLite:嵌入式数据库
[dependencies]
rusqlite = "0.31"
use rusqlite::{Connection, Result};
#[derive(Debug)]
struct User {
id: i32,
name: String,
email: String,
}
fn main() -> Result<()> {
// 1. 连接 SQLite(文件或内存)
let conn = Connection::open("my_database.db")?;
// let conn = Connection::open_in_memory()?; // 内存数据库
// 2. 创建表
conn.execute(
"CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
email TEXT NOT NULL
)",
[],
)?;
// 3. 插入数据
conn.execute(
"INSERT INTO users (name, email) VALUES (?1, ?2)",
["Alice", "alice@example.com"],
)?;
// 4. 查询并映射到结构体
let mut stmt = conn.prepare("SELECT id, name, email FROM users")?;
let users = stmt.query_map([], |row| {
Ok(User {
id: row.get(0)?,
name: row.get(1)?,
email: row.get(2)?,
})
})?;
for user in users {
println!("用户: {:?}", user?);
}
Ok(())
}
三、连接池设计
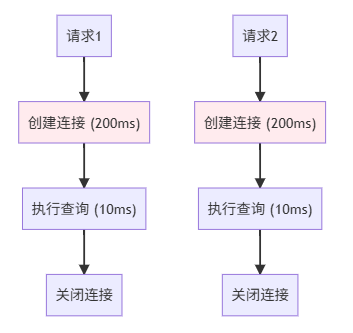
3.1 为什么需要连接池?
无连接池的问题:
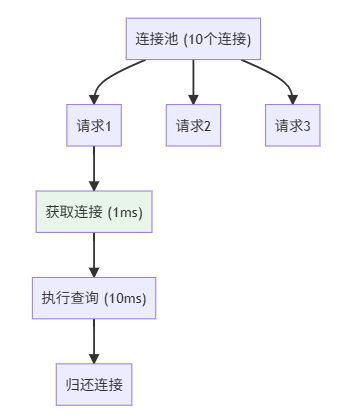
使用连接池的优势:
| 指标 | 无连接池 | 有连接池 |
|---|---|---|
| 连接创建时间 | 每次 200ms | 初始化时一次性创建 |
| 并发性能 | 低 | 高 |
| 资源占用 | 不稳定 | 可控 |
| 故障恢复 | 每次需重连 | 自动健康检查 |
3.2 使用 deadpool 构建连接池
[dependencies]
tokio = { version = "1.35", features = ["full"] }
deadpool-postgres = "0.12"
tokio-postgres = "0.7"
连接池实现:
use deadpool_postgres::{Config, Manager, ManagerConfig, Pool, RecyclingMethod};
use tokio_postgres::NoTls;
use std::time::Duration;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// 1. 配置连接池
let mut cfg = Config::new();
cfg.host = Some("localhost".to_string());
cfg.user = Some("postgres".to_string());
cfg.password = Some("secret".to_string());
cfg.dbname = Some("testdb".to_string());
// 连接池管理器配置
cfg.manager = Some(ManagerConfig {
recycling_method: RecyclingMethod::Fast, // 快速回收
});
// 2. 创建连接池(最大10个连接)
let pool = cfg.create_pool(None, NoTls)?;
println!("🏊 连接池创建成功 (最大: 10 连接)");
// 3. 模拟100个并发请求
let mut handles = vec![];
for i in 0..100 {
let pool = pool.clone();
let handle = tokio::spawn(async move {
// 从连接池获取连接
let client = pool.get().await.unwrap();
// 执行查询
let rows = client
.query("SELECT $1::TEXT as message", &[&format!("请求 #{}", i)])
.await
.unwrap();
let message: &str = rows[0].get(0);
println!("✓ {}", message);
// 连接自动归还池(Drop trait)
});
handles.push(handle);
}
// 等待所有请求完成
for handle in handles {
handle.await?;
}
// 4. 监控连接池状态
let status = pool.status();
println!("\n📊 连接池状态:");
println!(" 可用连接: {}", status.available);
println!(" 总连接数: {}", status.size);
Ok(())
}
健康检查与自动重连:
use deadpool_postgres::{Pool, PoolError};
use tokio::time::{sleep, Duration};
async fn with_retry<F, T>(
pool: &Pool,
mut operation: F,
) -> Result<T, Box<dyn std::error::Error>>
where
F: FnMut(&tokio_postgres::Client) -> Result<T, tokio_postgres::Error>,
{
let max_retries = 3;
let mut attempts = 0;
loop {
match pool.get().await {
Ok(client) => {
match operation(&client) {
Ok(result) => return Ok(result),
Err(e) => {
attempts += 1;
if attempts >= max_retries {
return Err(Box::new(e));
}
eprintln!("⚠️ 查询失败,重试 {}/{}", attempts, max_retries);
sleep(Duration::from_secs(1)).await;
}
}
},
Err(e) => {
return Err(Box::new(e));
}
}
}
}
四、SQLx:编译时查询验证
4.1 SQLx 核心特性
SQLx 是 Rust 最受欢迎的异步 SQL 库,核心特点:
- 编译时 SQL 验证 - 使用宏在编译期检查 SQL 语法
- 异步优先 - 基于 Tokio 的异步设计
- 跨数据库 - 支持 PostgreSQL、MySQL、SQLite、MSSQL
- 零成本抽象 - 不牺牲性能
[dependencies]
sqlx = { version = "0.7", features = ["runtime-tokio", "postgres", "macros"] }
tokio = { version = "1.35", features = ["full"] }
4.2 编译时查询验证
设置数据库连接(编译时):
# .env 文件
DATABASE_URL=postgres://postgres:secret@localhost/testdb
# 创建数据库并运行迁移
cargo install sqlx-cli
sqlx database create
sqlx migrate run
类型安全的查询:
use sqlx::{FromRow, PgPool};
#[derive(Debug, FromRow)]
struct User {
id: i32,
name: String,
email: String,
}
#[tokio::main]
async fn main() -> Result<(), sqlx::Error> {
// 1. 创建连接池
let pool = PgPool::connect("postgres://postgres:secret@localhost/testdb").await?;
// 2. 编译时验证的查询(query! 宏)
let rows = sqlx::query!(
r#"
SELECT id, name, email
FROM users
WHERE name = $1
"#,
"Alice"
)
.fetch_all(&pool)
.await?;
for row in rows {
// 编译器知道字段类型!
println!("用户: {} ({})", row.name, row.email);
}
// 3. 映射到结构体(query_as! 宏)
let users = sqlx::query_as!(
User,
"SELECT id, name, email FROM users"
)
.fetch_all(&pool)
.await?;
for user in users {
println!("{:?}", user);
}
Ok(())
}
query! 宏的工作原理:
编译时错误示例:
// ❌ 编译错误:字段名错误
let rows = sqlx::query!(
"SELECT id, wrong_field FROM users"
)
.fetch_all(&pool)
.await?;
// 编译器输出:
// error: no column named `wrong_field` in query
4.3 数据库迁移
创建迁移文件:
sqlx migrate add create_users_table
生成 migrations/20240101000000_create_users_table.sql:
-- 向上迁移
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
email VARCHAR NOT NULL UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 向下迁移 (回滚)
-- DROP TABLE users;
在代码中运行迁移:
use sqlx::migrate::MigrateDatabase;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let db_url = "postgres://postgres:secret@localhost/testdb";
// 创建数据库(如果不存在)
if !sqlx::Postgres::database_exists(db_url).await? {
sqlx::Postgres::create_database(db_url).await?;
println!("✓ 数据库创建成功");
}
let pool = PgPool::connect(db_url).await?;
// 运行迁移
sqlx::migrate!("./migrations")
.run(&pool)
.await?;
println!("✓ 迁移完成");
Ok(())
}
4.4 事务与批量操作
use sqlx::{PgPool, Postgres, Transaction};
async fn batch_insert_users(
pool: &PgPool,
users: Vec<(&str, &str)>,
) -> Result<(), sqlx::Error> {
let mut tx: Transaction<Postgres> = pool.begin().await?;
for (name, email) in users {
sqlx::query!(
"INSERT INTO users (name, email) VALUES ($1, $2)",
name,
email
)
.execute(&mut *tx)
.await?;
}
// 提交事务
tx.commit().await?;
Ok(())
}
#[tokio::main]
async fn main() -> Result<(), sqlx::Error> {
let pool = PgPool::connect("postgres://...").await?;
let users = vec![
("Alice", "alice@example.com"),
("Bob", "bob@example.com"),
("Charlie", "charlie@example.com"),
];
batch_insert_users(&pool, users).await?;
println!("✓ 批量插入完成");
Ok(())
}
五、Diesel ORM:最强类型安全
5.1 Diesel 核心理念
Diesel 通过 Rust 类型系统提供 编译时 SQL 验证,确保:
- SQL 语法错误在编译时发现
- 类型不匹配在编译时拒绝
- 表结构与代码同步
[dependencies]
diesel = { version = "2.1", features = ["postgres"] }
dotenvy = "0.15"
5.2 Diesel CLI 与代码生成
# 安装 Diesel CLI
cargo install diesel_cli --no-default-features --features postgres
# 初始化 Diesel
diesel setup
# 创建迁移
diesel migration generate create_users
迁移文件 (migrations/.../up.sql):
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
email VARCHAR NOT NULL
)
运行迁移并生成 schema:
diesel migration run
生成 src/schema.rs:
// @generated automatically by Diesel CLI.
diesel::table! {
users (id) {
id -> Int4,
name -> Varchar,
email -> Varchar,
}
}
5.3 定义模型
use diesel::prelude::*;
// 查询模型(从数据库读取)
#[derive(Queryable, Selectable, Debug)]
#[diesel(table_name = crate::schema::users)]
pub struct User {
pub id: i32,
pub name: String,
pub email: String,
}
// 插入模型(写入数据库)
#[derive(Insertable)]
#[diesel(table_name = crate::schema::users)]
pub struct NewUser<'a> {
pub name: &'a str,
pub email: &'a str,
}
5.4 CRUD 操作
use diesel::prelude::*;
use diesel::pg::PgConnection;
use dotenvy::dotenv;
use std::env;
// 建立连接
pub fn establish_connection() -> PgConnection {
dotenv().ok();
let database_url = env::var("DATABASE_URL").expect("DATABASE_URL 必须设置");
PgConnection::establish(&database_url)
.unwrap_or_else(|_| panic!("连接数据库失败: {}", database_url))
}
// CREATE - 插入数据
pub fn create_user(conn: &mut PgConnection, name: &str, email: &str) -> User {
use crate::schema::users;
let new_user = NewUser { name, email };
diesel::insert_into(users::table)
.values(&new_user)
.returning(User::as_returning())
.get_result(conn)
.expect("插入用户失败")
}
// READ - 查询所有用户
pub fn get_all_users(conn: &mut PgConnection) -> Vec<User> {
use crate::schema::users::dsl::*;
users
.select(User::as_select())
.load(conn)
.expect("查询用户失败")
}
// READ - 按条件查询
pub fn find_user_by_email(conn: &mut PgConnection, user_email: &str) -> Option<User> {
use crate::schema::users::dsl::*;
users
.filter(email.eq(user_email))
.select(User::as_select())
.first(conn)
.optional()
.expect("查询失败")
}
// UPDATE - 更新用户
pub fn update_user_email(conn: &mut PgConnection, user_id: i32, new_email: &str) {
use crate::schema::users::dsl::*;
diesel::update(users.find(user_id))
.set(email.eq(new_email))
.execute(conn)
.expect("更新失败");
}
// DELETE - 删除用户
pub fn delete_user(conn: &mut PgConnection, user_id: i32) {
use crate::schema::users::dsl::*;
diesel::delete(users.find(user_id))
.execute(conn)
.expect("删除失败");
}
fn main() {
let mut conn = establish_connection();
// 插入用户
let user = create_user(&mut conn, "Alice", "alice@example.com");
println!("✓ 创建用户: {:?}", user);
// 查询所有用户
let all_users = get_all_users(&mut conn);
println!("所有用户: {:?}", all_users);
// 按邮箱查询
if let Some(user) = find_user_by_email(&mut conn, "alice@example.com") {
println!("找到用户: {:?}", user);
}
// 更新邮箱
update_user_email(&mut conn, user.id, "alice_new@example.com");
println!("✓ 更新完成");
// 删除用户
delete_user(&mut conn, user.id);
println!("✓ 删除完成");
}
5.5 复杂查询
JOIN 查询:
// 假设有 posts 表
diesel::table! {
posts (id) {
id -> Int4,
user_id -> Int4,
title -> Varchar,
body -> Text,
}
}
diesel::joinable!(posts -> users (user_id));
// 查询用户及其文章
let results = users::table
.inner_join(posts::table)
.select((User::as_select(), Post::as_select()))
.load::<(User, Post)>(conn)?;
for (user, post) in results {
println!("用户 {} 的文章: {}", user.name, post.title);
}
聚合查询:
use diesel::dsl::count;
// 统计用户数量
let user_count: i64 = users::table
.select(count(users::id))
.first(conn)?;
println!("用户总数: {}", user_count);
六、自定义查询构建器
让我们从零构建一个类型安全的查询构建器!
6.1 设计目标
// 目标 API:
let query = QueryBuilder::select_from("users")
.columns(&["id", "name", "email"])
.where_clause("age > ?", vec![18])
.order_by("name", Order::Asc)
.limit(10);
let sql = query.build();
// SELECT id, name, email FROM users WHERE age > ? ORDER BY name ASC LIMIT 10
6.2 实现代码
use std::fmt;
#[derive(Debug, Clone)]
pub enum Order {
Asc,
Desc,
}
impl fmt::Display for Order {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
match self {
Order::Asc => write!(f, "ASC"),
Order::Desc => write!(f, "DESC"),
}
}
}
#[derive(Debug)]
pub struct QueryBuilder {
table: String,
columns: Vec<String>,
where_clauses: Vec<(String, Vec<Box<dyn fmt::Debug>>)>,
order_by: Option<(String, Order)>,
limit: Option<usize>,
}
impl QueryBuilder {
pub fn select_from(table: &str) -> Self {
QueryBuilder {
table: table.to_string(),
columns: vec!["*".to_string()],
where_clauses: vec![],
order_by: None,
limit: None,
}
}
pub fn columns(mut self, cols: &[&str]) -> Self {
self.columns = cols.iter().map(|s| s.to_string()).collect();
self
}
pub fn where_clause<T: fmt::Debug + 'static>(
mut self,
condition: &str,
params: Vec<T>,
) -> Self {
let boxed_params: Vec<Box<dyn fmt::Debug>> = params
.into_iter()
.map(|p| Box::new(p) as Box<dyn fmt::Debug>)
.collect();
self.where_clauses.push((condition.to_string(), boxed_params));
self
}
pub fn order_by(mut self, column: &str, order: Order) -> Self {
self.order_by = Some((column.to_string(), order));
self
}
pub fn limit(mut self, n: usize) -> Self {
self.limit = Some(n);
self
}
pub fn build(&self) -> String {
let mut sql = format!("SELECT {} FROM {}", self.columns.join(", "), self.table);
if !self.where_clauses.is_empty() {
let conditions: Vec<String> = self.where_clauses
.iter()
.map(|(cond, _)| cond.clone())
.collect();
sql.push_str(&format!(" WHERE {}", conditions.join(" AND ")));
}
if let Some((column, order)) = &self.order_by {
sql.push_str(&format!(" ORDER BY {} {}", column, order));
}
if let Some(limit) = self.limit {
sql.push_str(&format!(" LIMIT {}", limit));
}
sql
}
}
fn main() {
let query = QueryBuilder::select_from("users")
.columns(&["id", "name", "email"])
.where_clause("age > ?", vec![18])
.where_clause("status = ?", vec!["active"])
.order_by("name", Order::Asc)
.limit(10);
println!("生成的 SQL:\n{}", query.build());
}
输出:
生成的 SQL:
SELECT id, name, email FROM users WHERE age > ? AND status = ? ORDER BY name ASC LIMIT 10
好的,我来补充完整第三篇的剩余内容:
七、性能优化与最佳实践
7.1 索引优化
-- 创建索引加速查询
CREATE INDEX idx_users_email ON users(email);
CREATE INDEX idx_users_name_email ON users(name, email); -- 复合索引
-- 使用 EXPLAIN 分析查询计划
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'alice@example.com';
Diesel 中的索引提示:
use diesel::prelude::*;
use diesel::sql_types::Text;
// 强制使用索引
sql_query("SELECT * FROM users USE INDEX (idx_users_email) WHERE email = $1")
.bind::<Text, _>("alice@example.com")
.execute(conn)?;
7.2 批量操作优化
use sqlx::PgPool;
// ❌ 低效:逐条插入
async fn insert_one_by_one(pool: &PgPool, users: Vec<(String, String)>) {
for (name, email) in users {
sqlx::query!("INSERT INTO users (name, email) VALUES ($1, $2)", name, email)
.execute(pool)
.await
.unwrap();
}
}
// ✓ 高效:批量插入
async fn batch_insert(pool: &PgPool, users: Vec<(String, String)>) {
let mut query_builder = sqlx::QueryBuilder::new(
"INSERT INTO users (name, email) "
);
query_builder.push_values(users, |mut b, (name, email)| {
b.push_bind(name).push_bind(email);
});
query_builder.build().execute(pool).await.unwrap();
}
性能对比:
| 操作 | 插入 1000 行耗时 | 说明 |
|---|---|---|
| 逐条插入 | ~5000ms | 每次网络往返 + 事务开销 |
| 批量插入 (100条/批) | ~500ms | 减少网络往返 |
| 事务 + 批量插入 | ~200ms | 最优方案 |
7.3 N+1 查询问题
问题示例:
// ❌ N+1 查询:1次查询用户 + N次查询文章
let users = get_all_users(conn); // 1 次查询
for user in users {
let posts = get_posts_by_user_id(conn, user.id); // N 次查询
println!("用户 {} 有 {} 篇文章", user.name, posts.len());
}
优化方案(JOIN):
// ✓ 使用 JOIN 一次性获取所有数据
let results = users::table
.left_join(posts::table)
.select((User::as_select(), Option::<Post>::as_select()))
.load::<(User, Option<Post>)>(conn)?;
// 手动分组
use std::collections::HashMap;
let mut user_posts: HashMap<i32, Vec<Post>> = HashMap::new();
for (user, post) in results {
if let Some(post) = post {
user_posts.entry(user.id).or_default().push(post);
}
}
7.4 预编译语句缓存
use sqlx::{PgPool, Executor};
async fn use_prepared_statement(pool: &PgPool, name: &str) -> Result<(), sqlx::Error> {
// SQLx 自动缓存预编译语句
let user = sqlx::query_as!(
User,
"SELECT id, name, email FROM users WHERE name = $1",
name
)
.fetch_one(pool)
.await?;
Ok(())
}
八、实战案例:RESTful API
8.1 完整的用户管理 API
[dependencies]
tokio = { version = "1.35", features = ["full"] }
sqlx = { version = "0.7", features = ["runtime-tokio", "postgres", "macros"] }
axum = "0.7"
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
数据模型:
use serde::{Deserialize, Serialize};
use sqlx::FromRow;
#[derive(Debug, FromRow, Serialize)]
pub struct User {
pub id: i32,
pub name: String,
pub email: String,
pub created_at: chrono::NaiveDateTime,
}
#[derive(Debug, Deserialize)]
pub struct CreateUserRequest {
pub name: String,
pub email: String,
}
#[derive(Debug, Deserialize)]
pub struct UpdateUserRequest {
pub name: Option<String>,
pub email: Option<String>,
}
数据库层:
use sqlx::PgPool;
pub async fn create_user(
pool: &PgPool,
req: CreateUserRequest,
) -> Result<User, sqlx::Error> {
sqlx::query_as!(
User,
r#"
INSERT INTO users (name, email, created_at)
VALUES ($1, $2, NOW())
RETURNING id, name, email, created_at
"#,
req.name,
req.email
)
.fetch_one(pool)
.await
}
pub async fn get_user(pool: &PgPool, id: i32) -> Result<User, sqlx::Error> {
sqlx::query_as!(
User,
"SELECT id, name, email, created_at FROM users WHERE id = $1",
id
)
.fetch_one(pool)
.await
}
pub async fn list_users(
pool: &PgPool,
limit: i64,
offset: i64,
) -> Result<Vec<User>, sqlx::Error> {
sqlx::query_as!(
User,
"SELECT id, name, email, created_at FROM users ORDER BY id LIMIT $1 OFFSET $2",
limit,
offset
)
.fetch_all(pool)
.await
}
pub async fn update_user(
pool: &PgPool,
id: i32,
req: UpdateUserRequest,
) -> Result<User, sqlx::Error> {
sqlx::query_as!(
User,
r#"
UPDATE users
SET name = COALESCE($1, name),
email = COALESCE($2, email)
WHERE id = $3
RETURNING id, name, email, created_at
"#,
req.name,
req.email,
id
)
.fetch_one(pool)
.await
}
pub async fn delete_user(pool: &PgPool, id: i32) -> Result<(), sqlx::Error> {
sqlx::query!("DELETE FROM users WHERE id = $1", id)
.execute(pool)
.await?;
Ok(())
}
API 路由:
use axum::{
extract::{Path, Query, State},
http::StatusCode,
response::IntoResponse,
routing::{get, post},
Json, Router,
};
use sqlx::PgPool;
#[derive(Clone)]
struct AppState {
pool: PgPool,
}
#[derive(Deserialize)]
struct Pagination {
#[serde(default = "default_limit")]
limit: i64,
#[serde(default)]
offset: i64,
}
fn default_limit() -> i64 { 10 }
// POST /users - 创建用户
async fn create_user_handler(
State(state): State<AppState>,
Json(req): Json<CreateUserRequest>,
) -> Result<Json<User>, StatusCode> {
match create_user(&state.pool, req).await {
Ok(user) => Ok(Json(user)),
Err(_) => Err(StatusCode::INTERNAL_SERVER_ERROR),
}
}
// GET /users/:id - 获取用户
async fn get_user_handler(
State(state): State<AppState>,
Path(id): Path<i32>,
) -> Result<Json<User>, StatusCode> {
match get_user(&state.pool, id).await {
Ok(user) => Ok(Json(user)),
Err(sqlx::Error::RowNotFound) => Err(StatusCode::NOT_FOUND),
Err(_) => Err(StatusCode::INTERNAL_SERVER_ERROR),
}
}
// GET /users - 列出用户
async fn list_users_handler(
State(state): State<AppState>,
Query(pagination): Query<Pagination>,
) -> Result<Json<Vec<User>>, StatusCode> {
match list_users(&state.pool, pagination.limit, pagination.offset).await {
Ok(users) => Ok(Json(users)),
Err(_) => Err(StatusCode::INTERNAL_SERVER_ERROR),
}
}
// PUT /users/:id - 更新用户
async fn update_user_handler(
State(state): State<AppState>,
Path(id): Path<i32>,
Json(req): Json<UpdateUserRequest>,
) -> Result<Json<User>, StatusCode> {
match update_user(&state.pool, id, req).await {
Ok(user) => Ok(Json(user)),
Err(sqlx::Error::RowNotFound) => Err(StatusCode::NOT_FOUND),
Err(_) => Err(StatusCode::INTERNAL_SERVER_ERROR),
}
}
// DELETE /users/:id - 删除用户
async fn delete_user_handler(
State(state): State<AppState>,
Path(id): Path<i32>,
) -> Result<StatusCode, StatusCode> {
match delete_user(&state.pool, id).await {
Ok(_) => Ok(StatusCode::NO_CONTENT),
Err(_) => Err(StatusCode::INTERNAL_SERVER_ERROR),
}
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// 创建连接池
let pool = PgPool::connect("postgres://postgres:secret@localhost/testdb").await?;
let state = AppState { pool };
// 构建路由
let app = Router::new()
.route("/users", post(create_user_handler))
.route("/users", get(list_users_handler))
.route("/users/:id", get(get_user_handler))
.route("/users/:id", axum::routing::put(update_user_handler))
.route("/users/:id", axum::routing::delete(delete_user_handler))
.with_state(state);
println!("🚀 服务器启动于 http://127.0.0.1:3000");
// 启动服务器
let listener = tokio::net::TcpListener::bind("127.0.0.1:3000").await?;
axum::serve(listener, app).await?;
Ok(())
}
测试 API:
# 创建用户
curl -X POST http://localhost:3000/users \
-H "Content-Type: application/json" \
-d '{"name":"Alice","email":"alice@example.com"}'
# 获取用户
curl http://localhost:3000/users/1
# 列出用户(分页)
curl "http://localhost:3000/users?limit=10&offset=0"
# 更新用户
curl -X PUT http://localhost:3000/users/1 \
-H "Content-Type: application/json" \
-d '{"name":"Alice Smith"}'
# 删除用户
curl -X DELETE http://localhost:3000/users/1
九、常见陷阱与解决方案
9.1 陷阱总结表
| 陷阱 | 表现 | 解决方案 |
|---|---|---|
| 连接泄漏 | 连接池耗尽 | 确保连接正确归还(使用 Drop trait) |
| N+1 查询 | 性能急剧下降 | 使用 JOIN 或批量查询 |
| SQL 注入 | 安全漏洞 | 始终使用参数化查询 |
| 大事务 | 锁表过久 | 减小事务范围,使用乐观锁 |
| 未处理的错误 | 程序崩溃 | 合理的错误处理和重试机制 |
9.2 错误处理最佳实践
use thiserror::Error;
#[derive(Debug, Error)]
pub enum DatabaseError {
#[error("数据库连接失败: {0}")]
ConnectionFailed(#[from] sqlx::Error),
#[error("用户未找到: {0}")]
UserNotFound(i32),
#[error("邮箱已存在: {0}")]
DuplicateEmail(String),
}
pub async fn get_user_safe(
pool: &PgPool,
id: i32,
) -> Result<User, DatabaseError> {
sqlx::query_as!(User, "SELECT * FROM users WHERE id = $1", id)
.fetch_one(pool)
.await
.map_err(|e| match e {
sqlx::Error::RowNotFound => DatabaseError::UserNotFound(id),
e => DatabaseError::ConnectionFailed(e),
})
}
十、总结与讨论
核心要点:
✅ 原生驱动 - 提供底层控制,适合简单场景
✅ 连接池 - 必须使用,显著提升并发性能
✅ SQLx - 编译时验证 + 异步,现代 Rust 的首选
✅ Diesel - 最强类型安全,适合复杂查询
✅ 性能优化 - 索引、批量操作、避免 N+1 查询
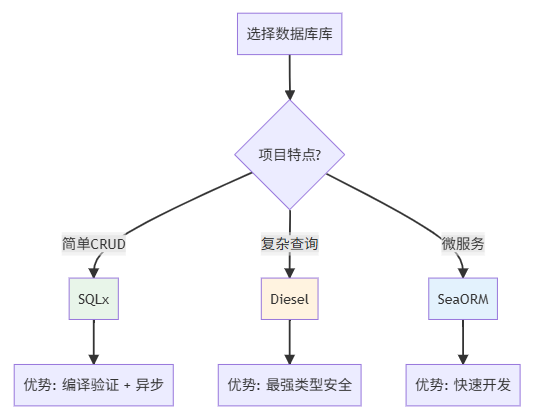
技术选型建议:
性能对比:
| 指标 | 原生驱动 | SQLx | Diesel |
|---|---|---|---|
| 类型安全 | ❌ 弱 | ✅ 强 | ✅✅ 最强 |
| 编译检查 | ❌ | ✅ SQL 验证 | ✅ 完整验证 |
| 异步支持 | 部分 | ✅ 原生 | ❌(但有 diesel-async) |
| 学习曲线 | 平缓 | 中等 | 陡峭 |
| 运行性能 | 最高 | 高 | 高 |
讨论问题:
- 在你的项目中,SQLx 和 Diesel 该如何选择?各自的适用场景是什么?
- 编译时 SQL 验证相比运行时验证,带来了哪些实际收益?
- 连接池的最佳大小应该如何设置?CPU 核心数 * 2 是否合理?
- 如何在微服务架构中管理数据库迁移?集中式 vs 每个服务独立?
- NoSQL 数据库(如 MongoDB、Redis)与 SQL 数据库在 Rust 中的使用体验差异?
欢迎分享你的数据库编程经验!💾
参考链接
- SQLx 官方文档:https://github.com/launchbadge/sqlx
- Diesel 官方文档:https://diesel.rs/
- SeaORM 文档:https://www.sea-ql.org/SeaORM/
- deadpool 连接池:https://github.com/bikeshedder/deadpool
- PostgreSQL 性能优化:https://wiki.postgresql.org/wiki/Performance_Optimization
- Database Design Best Practices:https://www.postgresql.org/docs/current/ddl.html
- Rust async book:https://rust-lang.github.io/async-book/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)