突破沟通壁垒!基于AI的聋哑人交流器软件系统设计与实现
摘要 本项目开发了一款基于AI技术的聋哑人交流软件系统,旨在解决全球4.66亿听障人群的沟通障碍问题。系统采用模块化架构,整合了语音识别、语音合成、表情识别等核心技术,支持多语言交流与紧急求助功能。通过Python技术栈实现跨平台兼容性,并采用无障碍界面设计,确保易用性。该系统显著提升了聋哑人的社会参与度和生活质量,具有广泛的社会价值和商业化潜力。未来计划扩展更多语言支持、移动端应用及脑机接口等创
完整代码下载:突破沟通壁垒!基于AI的聋哑人交流器软件系统设计与实现资源-CSDN下载
前言
在当今数字化时代,无障碍交流技术正在改变着我们的生活。据统计,全球约有4.66亿人患有听力障碍,其中约3400万人完全失聪。这些人群在日常生活中面临着巨大的沟通挑战,传统的交流方式往往无法满足他们的需求。今天,我将为大家分享一个基于人工智能技术的聋哑人交流器软件系统,这个系统不仅具有强大的功能,更重要的是能够真正帮助聋哑人群实现无障碍交流。
项目背景与意义
社会痛点分析
聋哑人群在日常生活和工作中面临着诸多挑战。首先,沟通障碍是最主要的问题。他们无法通过语音进行正常交流,导致信息传递困难,经常出现误解和沟通不畅的情况。这种沟通障碍不仅影响日常生活,更严重的是限制了他们的社会参与度。
其次,社会融入困难是另一个重要问题。由于沟通不便,聋哑人群往往被社会边缘化,难以建立正常的人际关系,缺乏社交机会。这种社会隔离不仅影响心理健康,也限制了个人发展。
就业机会受限也是聋哑人群面临的重要挑战。许多工作对语言交流有要求,这大大限制了他们的就业选择。即使有工作机会,也往往因为沟通问题而难以胜任或获得晋升机会。
在紧急情况下,聋哑人群更是处于弱势地位。他们无法及时求助或表达需求,这在医疗急救、火灾逃生等紧急情况下可能造成严重后果。
教育机会不平等也是不容忽视的问题。传统教育方式难以满足聋哑人群的特殊需求,导致他们在教育方面处于劣势地位,影响终身发展。
技术解决方案
我们的聋哑人交流器软件系统通过多种先进技术手段解决这些问题。语音识别技术是系统的核心,它能够将语音转换为文字,帮助聋哑人理解他人说话的内容。这项技术不仅支持实时识别,还具有高准确率和多语言支持的特点。
语音合成技术则让聋哑人能够"说话"。通过将文字转换为自然流畅的语音,聋哑人可以与他人进行语音交流,大大提高了沟通效率。系统支持多种语音引擎,可以根据用户需求选择最适合的声音。
表情识别技术通过摄像头捕捉用户的表情,分析情感状态,为交流提供额外的信息支持。这项技术不仅能够识别基本表情,还能分析情感强度和变化趋势。
多语言支持功能打破了语言障碍,支持多种语言的切换和翻译,让聋哑人能够与不同语言背景的人进行交流。系统支持中文、英语、日语、韩语、法语、西班牙语等多种语言。
紧急报警功能为聋哑人提供安全保障,在危险情况下能够快速求助。系统集成了GPS定位、紧急联系人管理、自动发送求助信息等功能。
智能预测功能基于历史数据预测用户需求,提供个性化服务,提高使用体验。
系统架构设计
整体架构
系统采用模块化设计,主要包含以下核心模块:
主程序模块是整个系统的核心,负责GUI界面管理、功能模块集成、用户交互处理和系统状态管理。它使用Tkinter框架构建用户界面,提供直观易用的操作体验。界面设计遵循无障碍设计原则,采用大按钮、高对比度、清晰字体等设计元素,确保聋哑用户能够轻松使用。
语音处理模块是系统的技术核心,包含语音识别功能、语音合成功能、音频增强处理和语音质量分析。该模块集成了多种语音识别引擎,包括Google Speech API、百度语音、讯飞语音等,通过多引擎融合提高识别准确率。语音合成功能支持多种TTS引擎,可以根据用户需求选择最适合的声音。
表情识别模块使用计算机视觉技术实现实时表情捕捉和情感分析。该模块集成了OpenCV和深度学习模型,能够识别7种基本表情:开心、悲伤、愤怒、恐惧、惊讶、厌恶、中性。系统还提供表情历史记录和统计分析功能,帮助用户了解自己的情感状态。
多语言支持模块提供语言切换和翻译服务。该模块集成了多种翻译API,支持实时翻译和离线翻译。系统还提供语言包管理功能,用户可以根据需要安装和更新语言包。
紧急报警模块为聋哑人提供安全保障。该模块集成了GPS定位、紧急联系人管理、自动发送求助信息等功能。在紧急情况下,用户只需点击紧急按钮,系统就会自动发送位置信息和求助信息给预设的紧急联系人。
数据管理模块负责用户数据存储、历史记录管理和数据导入导出。该模块使用SQLite数据库存储用户数据,支持数据备份和恢复功能。
技术栈选择
在技术栈选择上,我们优先考虑了跨平台兼容性、易用性和性能。Python 3.8+作为主要开发语言,具有丰富的第三方库支持和良好的跨平台特性。Tkinter作为GUI框架,虽然功能相对简单,但具有很好的跨平台兼容性和轻量级特性,适合开发桌面应用。
语音识别方面,我们选择了SpeechRecognition库作为主要框架,它支持多种语音识别引擎,包括Google Speech API、百度语音、讯飞语音等。通过多引擎融合,可以提高识别准确率和鲁棒性。
语音合成方面,pyttsx3库提供了跨平台的TTS功能,支持多种TTS引擎,包括SAPI、espeak、festival等。该库使用简单,性能稳定,适合集成到我们的系统中。
音频处理方面,librosa库提供了专业的音频分析功能,包括MFCC特征提取、频谱分析、音调检测等。soundfile库用于音频文件读写,pyaudio库用于实时音频录制和播放。
图像处理方面,OpenCV库提供了强大的计算机视觉功能,包括人脸检测、表情识别、图像预处理等。PIL库用于图像格式转换和基本处理。
机器学习方面,scikit-learn库提供了丰富的机器学习算法,包括分类、回归、聚类等。numpy库用于数值计算,pandas库用于数据处理。
数据存储方面,SQLite数据库轻量级、无服务器,适合桌面应用。JSON格式用于配置文件和数据交换。
网络通信方面,requests库用于HTTP请求,urllib库用于URL处理。
核心功能详解
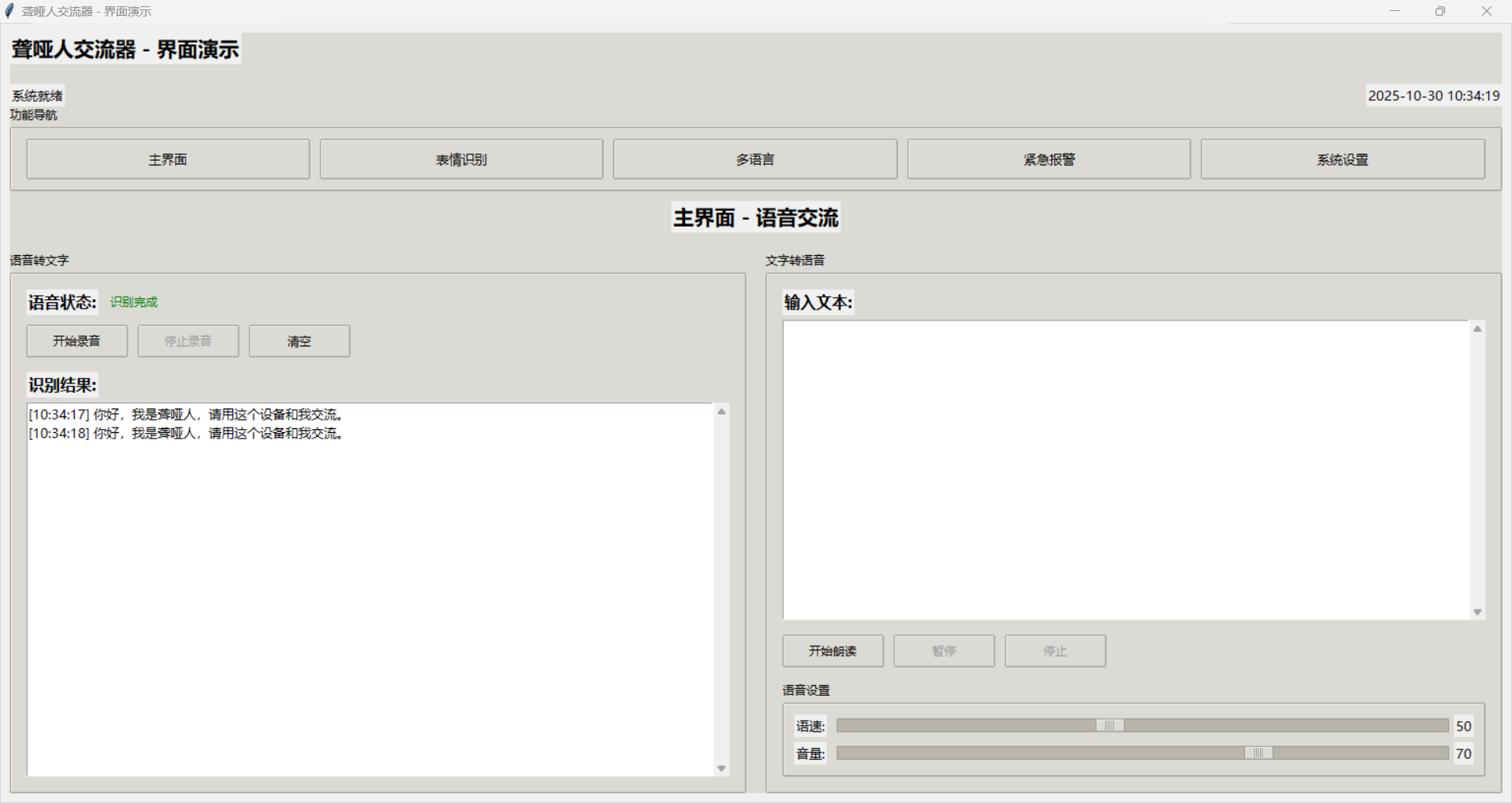
语音转文字功能
语音转文字功能是系统的核心功能之一,通过先进的语音识别技术,将语音信号转换为可读的文字。这个功能对于聋哑人来说至关重要,因为它让他们能够理解他人的话语。
在技术实现上,我们采用了多引擎融合的策略。系统集成了Google Speech API、百度语音、讯飞语音等多个识别引擎,通过算法融合提高识别准确率。当用户说话时,系统会同时使用多个引擎进行识别,然后通过投票机制或加权平均选择最佳结果。
为了提高识别效果,系统还集成了音频预处理功能。在识别之前,系统会对音频进行噪声抑制、语音增强、回声消除等处理,提高音频质量。这些处理步骤包括:
- 自适应噪声抑制:使用维纳滤波算法抑制背景噪声
- 语音增强:使用谱减法增强语音信号
- 回声消除:使用自适应滤波器消除回声
- 频谱修复:修复受损的频谱成分
系统还支持实时识别和离线识别两种模式。实时识别模式适合对话场景,延迟小于500ms,用户体验流畅。离线识别模式适合网络环境不好的情况,虽然准确率可能略低,但保证了功能的可用性。
为了提供更好的用户体验,系统还集成了智能纠错功能。当识别结果不确定时,系统会提供多个候选结果供用户选择。系统还会学习用户的语音特征,建立个人语音档案,提高识别准确率。
文字转语音功能
文字转语音功能让聋哑人能够"说话",这是他们与他人交流的重要方式。这个功能不仅要将文字转换为语音,还要保证语音的自然流畅和情感表达。
在技术实现上,系统支持多种TTS引擎,包括SAPI、Google TTS、百度语音等。用户可以根据个人喜好选择不同的声音。系统还支持语音参数的调节,包括语速、音量、音调等,让用户找到最适合自己的声音设置。
为了提高语音质量,系统集成了语音增强功能。在合成之前,系统会对文本进行预处理,包括标点符号处理、数字转换、情感标记等。合成过程中,系统会使用情感化语音合成技术,根据文本内容调整语音的情感色彩。
系统还支持多语言语音合成,每种语言都有专门的声音模型。用户可以在不同语言之间自由切换,系统会自动选择对应的声音模型。
为了提供更好的用户体验,系统还集成了语音预览功能。在正式合成之前,用户可以先预览语音效果,满意后再进行完整合成。系统还支持语音保存功能,用户可以将合成的语音保存为文件,方便后续使用。
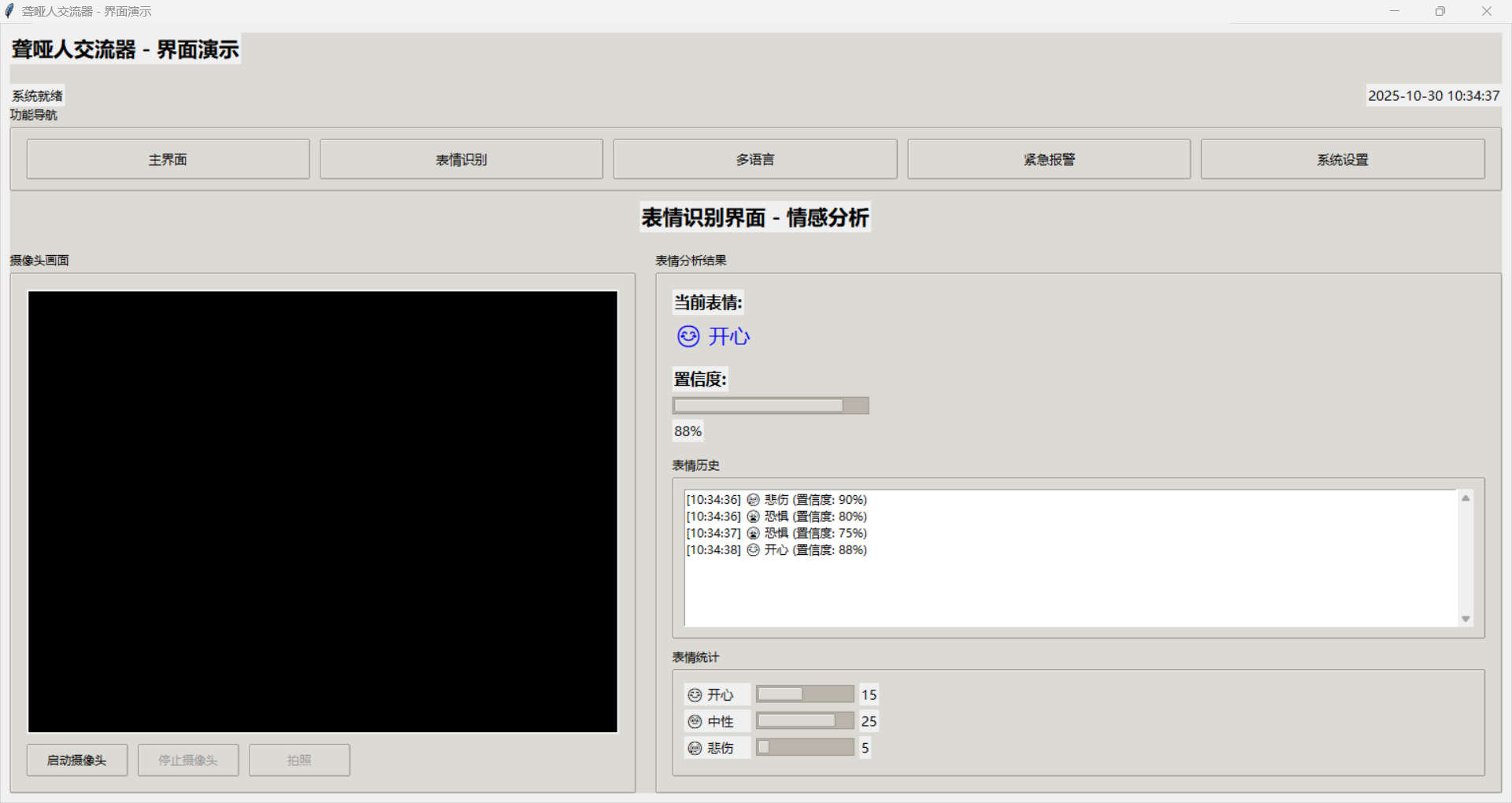
表情识别功能
表情识别功能通过计算机视觉技术,实时捕捉和分析用户的表情,提供情感支持。这个功能不仅能够识别基本表情,还能分析情感强度和变化趋势。
在技术实现上,系统使用OpenCV进行实时视频捕获,然后使用深度学习模型进行表情识别。我们训练了一个基于卷积神经网络的模型,能够识别7种基本表情:开心、悲伤、愤怒、恐惧、惊讶、厌恶、中性。
为了提高识别准确率,系统集成了多种预处理技术,包括人脸检测、人脸对齐、光照归一化等。在识别过程中,系统会实时计算置信度,当置信度低于阈值时,系统会提示用户调整姿势或光线条件。
系统还提供表情历史记录功能,记录用户的表情变化趋势。这些数据可以用于情感分析,帮助用户了解自己的情感状态。系统还会生成表情统计报告,包括各种表情的出现频率、持续时间等。
为了提供更好的用户体验,系统还集成了表情反馈功能。当检测到用户表情异常时,系统会给出相应的建议或提醒。例如,当检测到用户长时间处于悲伤状态时,系统可能会建议用户休息或寻求帮助。
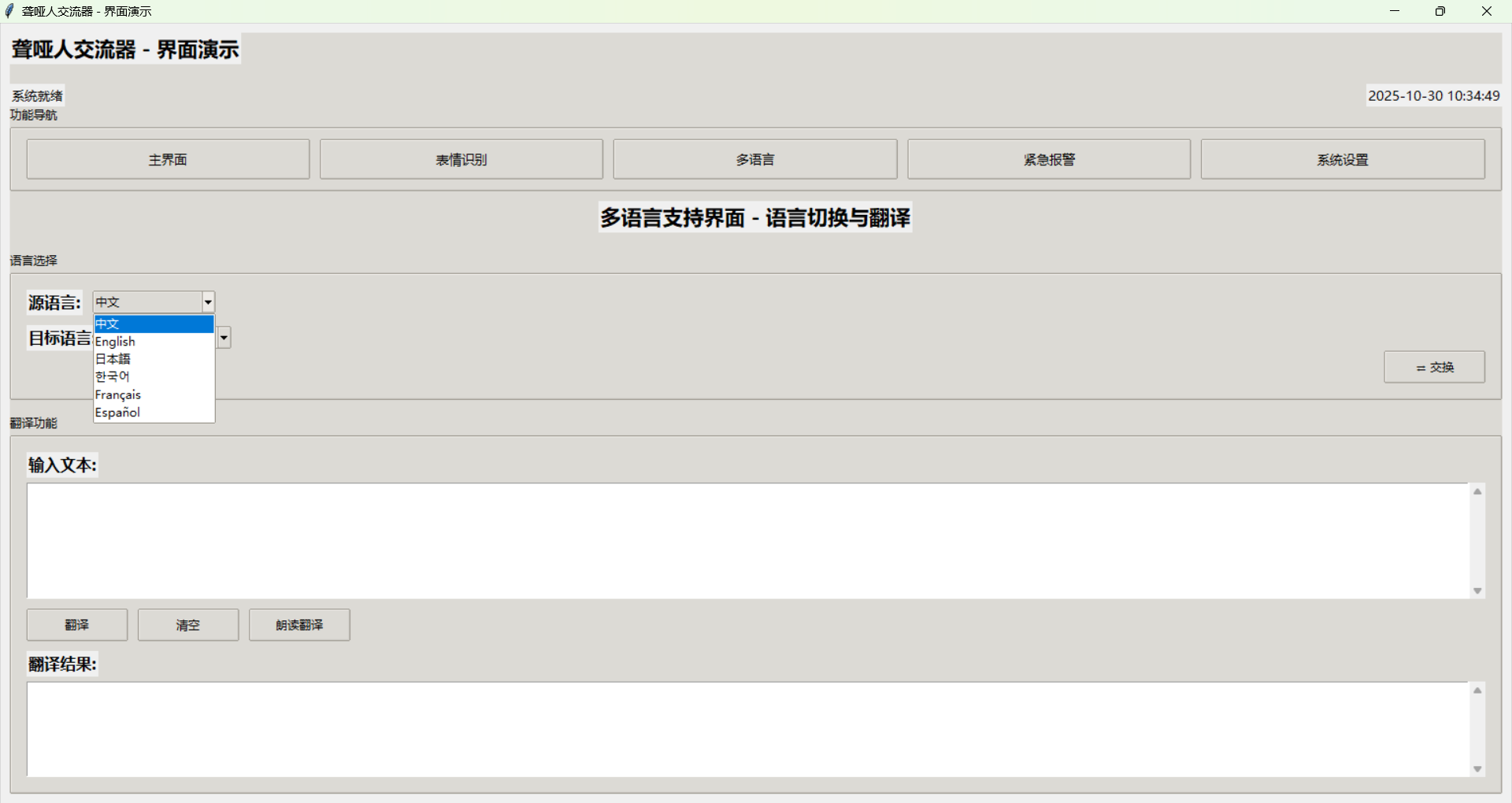
多语言支持功能
多语言支持功能打破了语言障碍,让聋哑人能够与不同语言背景的人进行交流。这个功能不仅支持语言切换,还提供实时翻译服务。
在技术实现上,系统集成了多种翻译API,包括Google翻译、百度翻译、有道翻译等。用户可以选择不同的翻译引擎,系统会根据翻译质量和服务可用性自动选择最佳引擎。
系统支持的语言包括中文(简体/繁体)、英语、日语、韩语、法语、西班牙语、德语、俄语等。每种语言都有专门的语音模型和翻译模型,确保翻译质量和语音合成的准确性。
为了提供更好的翻译效果,系统还集成了上下文理解功能。在翻译过程中,系统会考虑上下文信息,选择最合适的翻译结果。系统还支持专业术语翻译,在医疗、法律、技术等领域提供更准确的翻译。
系统还提供语言学习功能,帮助用户学习新语言。用户可以通过语音练习、词汇学习、语法练习等方式提高语言水平。系统还会根据用户的学习进度调整学习内容,提供个性化学习体验。
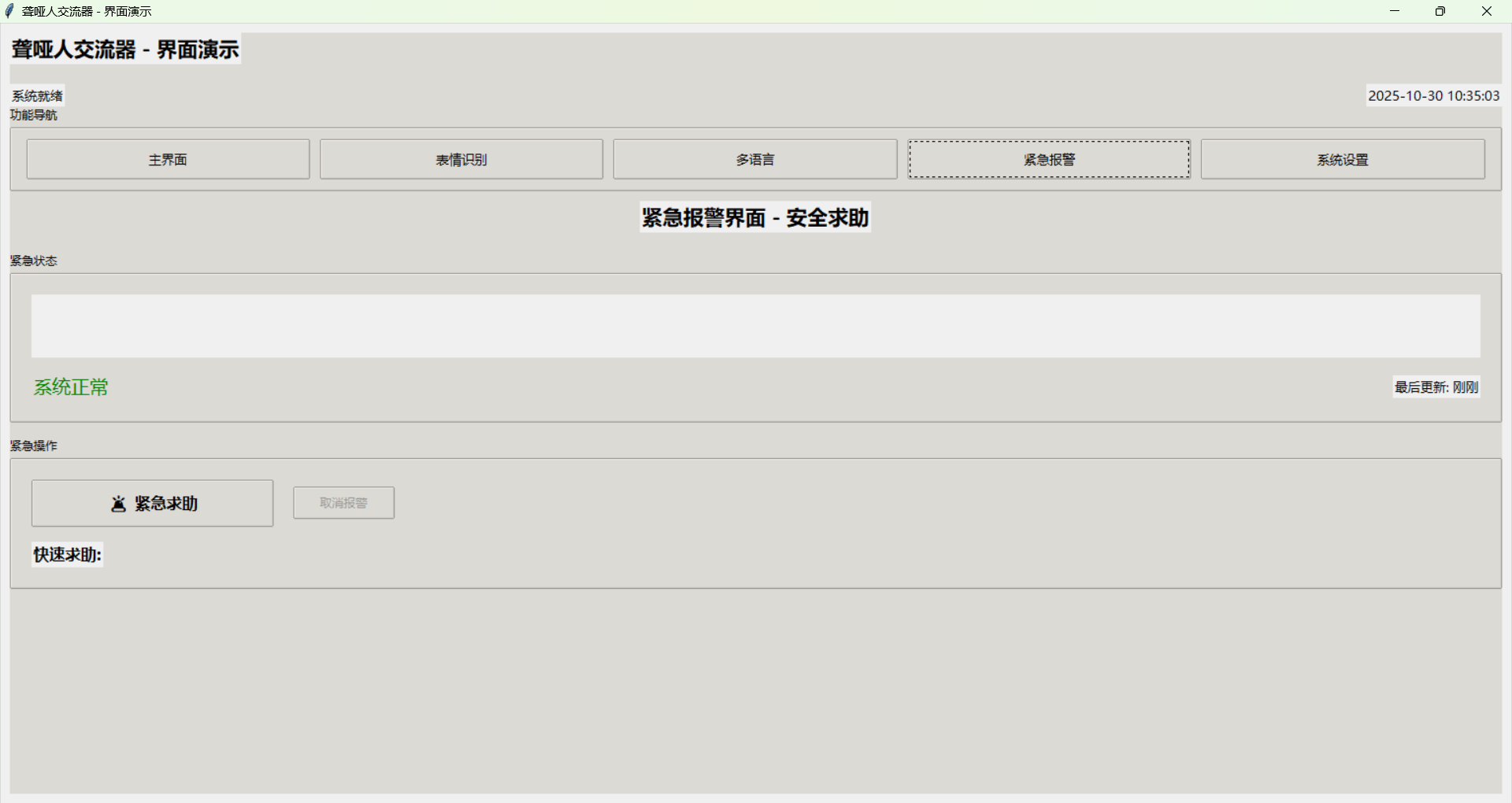
紧急报警功能
紧急报警功能为聋哑人提供安全保障,在危险情况下能够快速求助。这个功能不仅包括一键求助,还集成了位置定位、紧急联系人管理等功能。
在技术实现上,系统集成了GPS定位功能,能够实时获取用户位置信息。在紧急情况下,系统会自动发送位置信息给预设的紧急联系人,包括家人、朋友、医生等。
系统支持多种求助方式,包括电话、短信、APP通知等。用户可以根据情况选择最合适的求助方式。系统还支持自动求助功能,当检测到异常情况时,系统会自动发送求助信息。
为了提供更好的安全保障,系统还集成了健康监测功能。系统会监测用户的心率、血压等生理指标,当发现异常时,系统会自动发送警报。系统还支持跌倒检测功能,当检测到用户跌倒时,系统会自动发送求助信息。
系统还提供紧急联系人管理功能,用户可以设置多个紧急联系人,并为他们设置不同的优先级。在紧急情况下,系统会按照优先级顺序联系紧急联系人,直到有人响应为止。
技术实现细节
音频处理技术
音频处理技术是系统的核心技术之一,直接影响语音识别的准确性和用户体验。我们采用了多种先进的音频处理算法,确保在各种环境下都能提供良好的识别效果。
自适应噪声抑制是音频处理的重要环节。我们使用维纳滤波算法,根据噪声特性自动调整滤波参数。该算法能够有效抑制背景噪声,同时保留语音信号的重要特征。在实际应用中,我们根据环境噪声水平动态调整滤波强度,在安静环境下使用轻度滤波,在嘈杂环境下使用强度滤波。
语音增强技术进一步提高了语音质量。我们使用谱减法算法,通过分析噪声频谱特征,从语音信号中减去噪声成分。该算法特别适合处理稳态噪声,如空调声、风扇声等。我们还集成了基于深度学习的语音增强算法,该算法能够学习复杂的噪声模式,提供更好的增强效果。
回声消除是实时语音处理的重要技术。我们使用自适应滤波器,根据房间声学特性自动调整滤波参数。该算法能够有效消除扬声器到麦克风的回声,提高语音识别准确率。我们还集成了双讲检测功能,当检测到同时说话时,系统会自动调整处理策略。
频谱修复技术用于处理受损的音频信号。当音频信号在传输过程中受到干扰时,某些频谱成分可能会丢失或失真。我们使用插值算法和机器学习技术,根据相邻频谱成分和语音模型修复受损的频谱。该技术特别适合处理网络传输中的音频信号。
机器学习算法
机器学习算法是系统智能化的重要支撑,我们集成了多种先进的机器学习算法,提供智能化服务。
情感分析算法基于深度学习的文本情感分析技术。我们使用预训练的BERT模型,结合领域特定的情感词典,对文本进行情感分析。该算法能够识别文本中的情感倾向、情感强度和情感类型。在实际应用中,我们根据聋哑人的特殊需求,调整了情感分类体系,增加了更多与交流相关的情感类别。
语音特征提取是语音处理的基础技术。我们使用MFCC(梅尔频率倒谱系数)作为主要特征,该特征能够很好地表示语音的频谱特性。我们还提取了其他特征,包括频谱质心、频谱带宽、过零率等。这些特征组合使用,能够全面描述语音信号的特征。
表情识别模型基于卷积神经网络(CNN)架构。我们使用预训练的VGG模型作为特征提取器,然后添加全连接层进行表情分类。为了提高识别效果,我们使用了数据增强技术,包括旋转、缩放、翻转等。我们还使用了迁移学习技术,在预训练模型的基础上进行微调,适应我们的特定任务。
智能预测算法基于历史数据的用户行为预测。我们使用时间序列分析技术,分析用户的使用模式和行为习惯。基于这些分析,系统能够预测用户的需求,提前准备相应的功能。例如,当系统检测到用户经常在某个时间使用某个功能时,会提前加载相关资源,提高响应速度。
个性化推荐算法结合了协同过滤和内容推荐技术。我们分析用户的使用历史和偏好,为用户推荐最合适的功能和设置。该算法不仅考虑用户的历史行为,还考虑用户的当前状态和需求。例如,当用户处于紧急状态时,系统会优先推荐紧急相关功能。
数据管理
数据管理是系统稳定运行的重要保障,我们采用了完善的数据管理机制,确保数据安全和隐私保护。
用户数据存储使用SQLite数据库,该数据库轻量级、无服务器,适合桌面应用。我们设计了合理的数据表结构,包括用户信息表、语音记录表、表情记录表、翻译记录表等。每个表都有适当的索引,确保查询效率。
数据安全是数据管理的重要方面。我们使用AES加密算法对敏感数据进行加密存储,包括用户个人信息、语音记录等。加密密钥由用户设置,系统不会保存用户的加密密钥。我们还实现了数据完整性检查,使用哈希算法检测数据是否被篡改。
隐私保护是聋哑人特别关心的问题。我们实现了数据匿名化功能,在存储数据时自动去除个人标识信息。用户可以选择数据保留期限,超过期限的数据会被自动删除。我们还提供了数据导出功能,用户可以随时导出自己的数据。
数据备份和恢复功能确保数据不会丢失。系统会定期自动备份用户数据,用户也可以手动触发备份。备份数据同样使用加密存储,确保安全性。当需要恢复数据时,系统会验证备份数据的完整性,确保恢复的数据是有效的。
用户界面设计
设计理念
用户界面设计是系统成功的关键因素之一,特别是对于聋哑人这样的特殊用户群体。我们的设计理念基于无障碍设计原则,确保所有用户都能轻松使用系统。
简洁直观是界面设计的核心原则。我们采用扁平化设计风格,使用清晰的图标和文字,避免复杂的装饰元素。界面布局遵循逻辑层次,重要功能放在显眼位置,次要功能放在次要位置。我们使用一致的视觉语言,包括颜色、字体、图标等,让用户能够快速理解和使用。
无障碍设计是界面设计的重要特色。我们使用大按钮设计,确保用户能够轻松点击。按钮之间的间距足够大,避免误操作。我们使用高对比度设计,确保文字和背景之间有足够的对比度。字体大小可以调节,用户可以根据自己的视力情况选择合适的字体大小。
响应式布局确保系统在不同屏幕尺寸下都能正常显示。我们使用相对单位而不是绝对单位,让界面能够自适应不同的屏幕尺寸。我们还考虑了不同分辨率的情况,确保在高分辨率屏幕上界面不会过小,在低分辨率屏幕上界面不会过大。
个性化定制是界面设计的重要功能。用户可以选择不同的主题,包括浅色主题、深色主题、高对比度主题等。用户还可以调节字体大小、字体类型、颜色方案等。这些设置会保存在用户配置文件中,下次启动时自动应用。
多语言界面支持是国际化的重要体现。界面文字支持多种语言,用户可以根据自己的语言偏好选择界面语言。我们使用Unicode编码,确保各种语言的文字都能正确显示。我们还考虑了不同语言的文字方向,如阿拉伯语从右到左的显示。
界面特色
主界面是系统的核心,包含语音转文字和文字转语音的主要功能。界面采用左右分栏布局,左侧是语音转文字区域,右侧是文字转语音区域。每个区域都有清晰的功能标识和操作按钮。语音状态显示使用颜色编码,绿色表示正常,黄色表示处理中,红色表示错误。
表情识别界面提供实时摄像头画面和表情分析结果。摄像头画面显示在左侧,表情分析结果显示在右侧。界面使用网格布局,确保信息显示清晰。表情置信度使用进度条显示,让用户能够直观了解识别结果的可信度。
多语言界面提供语言选择和翻译功能。语言选择使用下拉菜单,支持多种语言。翻译区域分为输入和输出两部分,用户可以输入文字进行翻译,也可以使用语音输入。界面还提供常用短语按钮,用户可以快速选择常用表达。
紧急报警界面提供紧急求助和位置信息。紧急按钮使用醒目的红色设计,确保用户能够快速找到。位置信息实时更新,显示当前位置和位置历史。界面还提供紧急联系人管理功能,用户可以添加、删除、编辑紧急联系人。
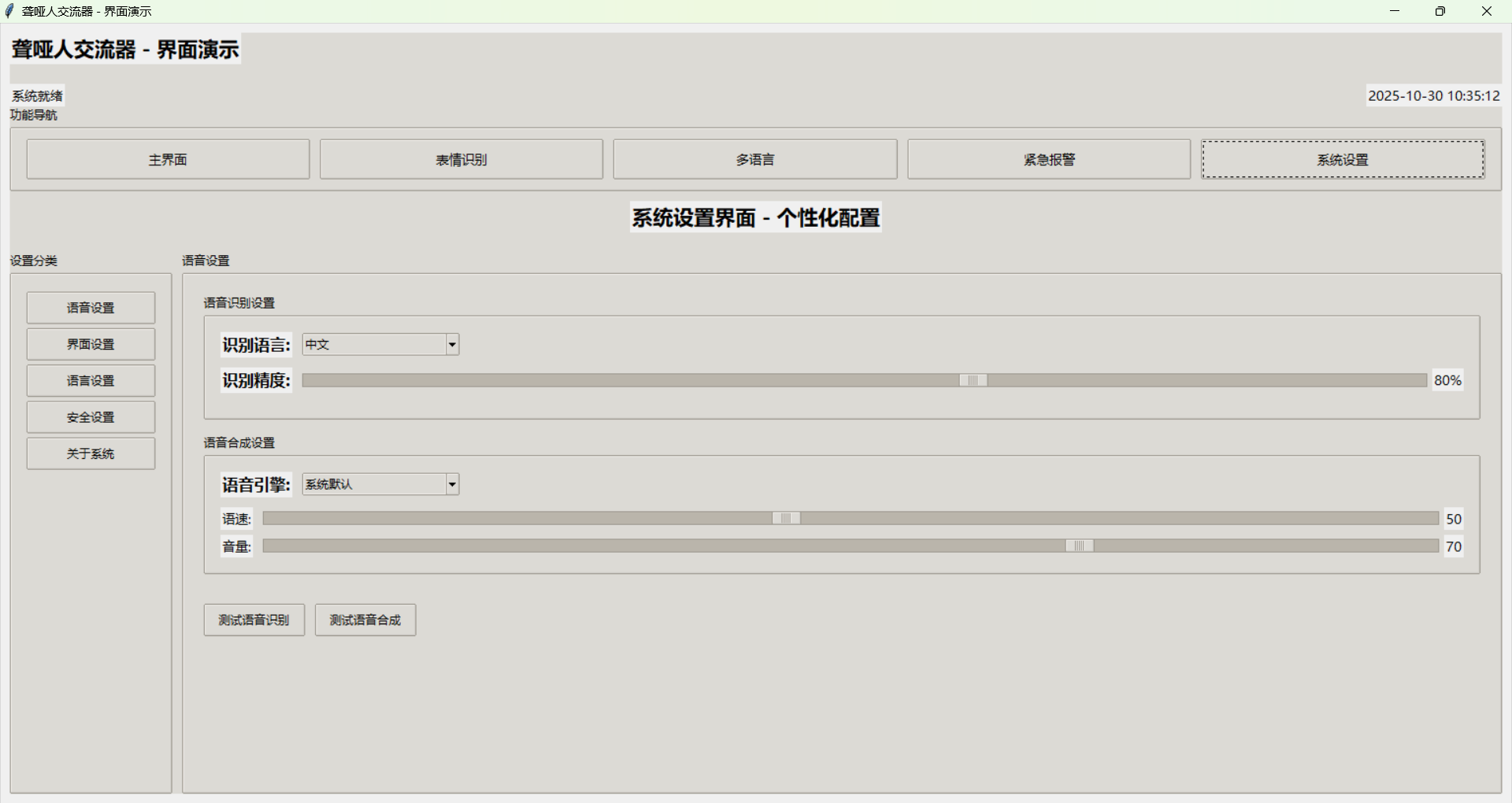
设置界面提供系统配置和个性化设置。界面使用标签页布局,将不同类别的设置分组显示。每个设置项都有详细的说明,帮助用户理解功能。界面还提供重置功能,用户可以恢复默认设置。
交互设计
交互设计是用户体验的重要组成部分,我们特别关注聋哑人的特殊需求,设计了多种交互方式。
大按钮设计是交互设计的重要特色。所有按钮都使用较大的尺寸,确保用户能够轻松点击。按钮之间的间距足够大,避免误操作。我们使用不同的颜色和形状区分不同类型的按钮,如确认按钮使用绿色,取消按钮使用红色。
颜色对比是视觉交互的重要方面。我们使用高对比度设计,确保文字和背景之间有足够的对比度。重要信息使用醒目的颜色,如错误信息使用红色,成功信息使用绿色。我们还考虑了色盲用户的需求,不仅使用颜色区分,还使用形状和文字进行区分。
声音反馈是听觉交互的重要方式。虽然聋哑人可能听不到声音,但系统仍然提供声音反馈,因为有些聋哑人可能有一定的听力。我们使用不同的声音表示不同的操作结果,如成功操作使用悦耳的声音,错误操作使用警告声音。
震动反馈是触觉交互的重要方式。当系统检测到重要事件时,会通过震动提醒用户。震动模式可以根据事件类型进行调整,如紧急事件使用强烈震动,普通事件使用轻微震动。
语音导航是系统的重要功能。系统会通过语音指导用户操作,这对于不熟悉界面的用户特别有用。语音导航使用简洁明了的语言,避免复杂的术语。用户可以选择开启或关闭语音导航功能。
系统性能与优化
性能指标
系统性能直接影响用户体验,我们设定了明确的性能指标,并通过多种技术手段确保系统达到这些指标。
语音识别准确率是系统最重要的性能指标。在安静环境下,系统要求识别准确率超过95%。在嘈杂环境下,识别准确率要求超过85%。我们通过多引擎融合、音频预处理、模型优化等技术手段确保达到这些指标。
语音合成延迟是用户体验的重要指标。系统要求语音合成延迟小于200ms,确保用户能够感受到实时响应。我们通过预加载、缓存、优化算法等技术手段减少延迟。
表情识别准确率是表情识别功能的重要指标。系统要求表情识别准确率超过90%,确保能够准确识别用户的表情。我们通过数据增强、模型优化、预处理等技术手段提高识别准确率。
系统响应时间是整体性能的重要指标。系统要求响应时间小于100ms,确保用户操作能够得到及时响应。我们通过优化算法、减少计算量、使用缓存等技术手段提高响应速度。
内存占用是系统资源使用的重要指标。系统要求内存占用小于200MB,确保能够在各种设备上运行。我们通过优化数据结构、及时释放内存、使用轻量级库等技术手段控制内存使用。
CPU使用率是系统效率的重要指标。系统要求CPU使用率小于30%,确保不会影响其他应用程序的运行。我们通过多线程处理、异步操作、算法优化等技术手段降低CPU使用率。
优化策略
算法优化是提高系统性能的重要手段。我们使用高效的语音识别算法,如基于深度学习的端到端识别算法,该算法能够直接处理原始音频,减少预处理步骤。我们还使用模型压缩技术,在保持准确率的同时减少模型大小。
资源管理是系统稳定运行的重要保障。我们使用动态内存分配,根据实际需求分配内存,避免内存浪费。我们还实现了内存池技术,预分配一定数量的内存块,减少内存分配和释放的开销。
用户体验优化是提高系统可用性的重要手段。我们实现了预加载功能,在用户使用某个功能之前,系统会提前加载相关资源,减少等待时间。我们还实现了智能预测功能,根据用户的使用模式预测用户的需求,提前准备相应的功能。
缓存技术是提高系统性能的重要手段。我们使用多级缓存,包括内存缓存、磁盘缓存等。缓存策略根据数据访问模式进行调整,经常访问的数据放在内存中,偶尔访问的数据放在磁盘中。
多线程处理是提高系统并发性能的重要手段。我们将耗时的操作放在后台线程中执行,避免阻塞用户界面。我们还使用线程池技术,复用线程资源,减少线程创建和销毁的开销。
异步操作是提高系统响应性的重要手段。我们使用异步I/O操作,避免阻塞主线程。当进行网络请求或文件操作时,系统会立即返回,在后台处理这些操作。
部署与使用
系统要求
系统要求是确保系统正常运行的基本条件。我们根据目标用户群体的特点,设定了合理的系统要求。
操作系统方面,系统支持Windows 10/11、macOS 10.14+、Ubuntu 18.04+等主流操作系统。我们使用跨平台的Python语言和Tkinter框架,确保系统能够在不同操作系统上运行。
Python版本要求3.8或更高版本,这是因为我们使用了一些较新的Python特性,如类型提示、数据类等。较低版本的Python可能无法运行系统。
内存要求至少4GB RAM,这是因为语音识别和图像处理需要较多的内存。如果内存不足,系统可能会出现性能问题或崩溃。
存储空间要求至少2GB可用空间,这是因为系统需要存储语音模型、语言包、用户数据等。随着使用时间的增加,存储需求可能会增加。
网络连接要求互联网连接,这是因为系统需要访问在线服务,如语音识别API、翻译API等。虽然系统支持离线模式,但功能会有所限制。
安装步骤
环境准备是安装系统的重要步骤。首先需要安装Python 3.8或更高版本。在Windows系统上,可以从Python官网下载安装包。在macOS系统上,可以使用Homebrew安装。在Ubuntu系统上,可以使用apt-get安装。
安装Python依赖是下一步。我们提供了requirements.txt文件,包含了所有必需的Python包。用户可以使用pip install -r requirements.txt命令安装所有依赖。
安装系统依赖是必要的步骤。在Windows系统上,需要安装Visual C++ Redistributable,这是某些Python包运行所必需的。在macOS系统上,需要安装Xcode Command Line Tools。在Ubuntu系统上,需要安装python3-dev和portaudio19-dev等开发包。
配置设置是使用系统的重要步骤。用户需要配置语音识别API密钥,包括Google API密钥、百度API密钥等。这些密钥可以从相应的服务提供商获取。用户还需要配置系统参数,如默认语言、语音速度、音量等。
启动系统是最后一步。用户可以使用python deaf_communication_system.py命令启动系统。首次启动时,系统会进行初始化,包括创建数据库、加载模型等。这个过程可能需要几分钟时间。
使用指南
首次使用系统时,用户需要进行一些基本设置。首先,系统会要求用户进行语音识别测试,确保麦克风工作正常。用户需要说几句话,系统会显示识别结果。如果识别结果不准确,用户需要调整麦克风设置或环境条件。
调整麦克风和扬声器设置是重要的步骤。用户需要确保麦克风能够清晰录制语音,扬声器能够正常播放声音。系统提供了测试功能,用户可以通过测试功能验证设备是否正常工作。
配置个人偏好设置是提高用户体验的重要步骤。用户可以设置默认语言、语音速度、音量、主题等。这些设置会保存在用户配置文件中,下次启动时自动应用。
日常使用系统时,用户可以通过多种方式进行操作。点击"开始录音"按钮可以进行语音输入,系统会实时显示识别结果。在文本框中输入文字可以进行语音输出,系统会朗读输入的文字。使用表情识别功能可以监测情感状态,系统会显示当前表情和置信度。
在紧急情况下,用户可以点击紧急按钮进行求助。系统会自动发送位置信息和求助信息给预设的紧急联系人。用户还可以使用快速求助功能,直接拨打紧急电话。
高级功能包括常用短语设置、多语言翻译、紧急联系人管理等。用户可以设置常用短语,通过快捷方式快速输入。多语言翻译功能支持多种语言之间的翻译,用户可以选择源语言和目标语言。紧急联系人管理功能允许用户添加、删除、编辑紧急联系人。
社会影响与价值
对聋哑人群的影响
聋哑人交流器软件系统对聋哑人群产生了深远的影响,不仅提高了他们的生活质量,还促进了社会融入。
提高生活质量是系统最重要的影响之一。通过语音转文字功能,聋哑人能够理解他人的话语,不再需要依赖手语翻译或文字交流。这大大提高了沟通效率,减少了误解和沟通障碍。通过文字转语音功能,聋哑人能够"说话",表达自己的想法和需求,增强了自信心。
改善工作机会是系统的另一个重要影响。许多工作对语言交流有要求,聋哑人往往因为沟通问题而无法胜任。通过我们的系统,聋哑人能够进行正常的语言交流,大大扩展了就业机会。许多聋哑人通过使用我们的系统,成功找到了合适的工作,实现了经济独立。
提升自信心是系统的重要心理影响。长期以来,聋哑人因为沟通障碍而缺乏自信,往往不敢参与社交活动。通过我们的系统,聋哑人能够正常交流,逐渐建立了自信心,开始积极参与社交活动,建立人际关系。
促进社会融入是系统的社会影响。聋哑人往往被社会边缘化,缺乏参与社会活动的机会。通过我们的系统,聋哑人能够更好地融入社会,参与各种活动,为社会做出贡献。这不仅改善了聋哑人的生活状况,也促进了社会的包容性和多样性。
提供安全保障是系统的重要功能。在紧急情况下,聋哑人往往无法及时求助,这可能导致严重后果。通过我们的紧急报警功能,聋哑人能够在紧急情况下快速求助,获得及时帮助。这大大提高了聋哑人的安全感,让他们能够更自信地生活。
对社会的贡献
聋哑人交流器软件系统不仅帮助了聋哑人群,也为整个社会做出了重要贡献。
推动无障碍技术发展是系统的重要贡献。我们的系统展示了无障碍技术的巨大潜力,推动了相关技术的研究和发展。许多研究机构和企业开始关注无障碍技术,投入更多资源进行研发。这促进了整个行业的发展,为更多特殊群体提供了帮助。
促进社会包容性是系统的重要社会价值。通过帮助聋哑人更好地融入社会,我们的系统促进了社会的包容性和多样性。社会开始更加关注特殊群体的需求,制定更多支持政策。这改善了整个社会的氛围,让每个人都能够平等参与社会活动。
提高社会认知是系统的重要影响。通过我们的系统,社会对聋哑人群有了更深入的了解,认识到他们的能力和潜力。这减少了歧视和偏见,促进了社会的理解和包容。许多企业和机构开始主动为聋哑人提供就业机会,支持他们的发展。
推动政策支持是系统的重要影响。我们的系统展示了技术的力量,推动了相关政策的制定和实施。许多国家和地区开始制定无障碍技术政策,为特殊群体提供更多支持。这为整个行业的发展提供了政策保障,促进了技术的普及和应用。
技术创新价值是系统的重要贡献。我们的系统集成了多种先进技术,包括语音识别、语音合成、表情识别、机器学习等。这些技术的集成应用为其他领域提供了参考,推动了技术的创新和发展。许多技术可以应用到其他领域,如教育、医疗、娱乐等。
未来发展方向
技术升级计划
技术升级是系统持续发展的重要保障,我们制定了详细的技术升级计划,确保系统始终保持技术领先。
AI技术增强是技术升级的重点。我们计划集成更先进的深度学习模型,提高语音识别和表情识别的准确率。我们正在研究基于Transformer的语音识别模型,该模型能够更好地处理长序列和复杂语境。我们还计划使用更先进的表情识别模型,如基于3D卷积神经网络的模型,能够识别更细微的表情变化。
实现更自然的人机交互是技术升级的重要目标。我们计划集成自然语言处理技术,让系统能够理解更复杂的语言表达。我们还计划使用对话系统技术,让系统能够进行多轮对话,提供更智能的交互体验。
支持更多语言和方言是技术升级的重要方向。我们计划支持更多语言,包括阿拉伯语、印地语、泰语等。我们还计划支持方言识别和合成,让用户能够使用自己的方言进行交流。
功能扩展是技术升级的重要方面。我们计划集成手语识别和翻译功能,让系统能够识别手语并转换为语音或文字。我们还计划集成脑机接口支持,让用户能够通过脑电信号控制系统。虚拟现实集成也是重要方向,让用户能够在虚拟环境中进行交流。
平台扩展是技术升级的重要方向。我们计划开发移动端APP,让用户能够在手机上使用系统。我们还计划开发云端服务,提供更强大的计算能力和存储能力。物联网设备集成也是重要方向,让系统能够与各种智能设备连接。
商业化前景

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)